注意:以下翻译的准确性尚未经过验证。这是使用 AIP ↗ 从原始英文文本进行的机器翻译。
公告
提醒: 您现在可以注册 Foundry 新闻通讯,以直接在您的收件箱中收到平台上新产品、功能和改进的摘要。有关如何订阅的更多信息,请参阅 Foundry 新闻通讯和产品反馈渠道公告。
引入值类型 [Beta]
发布日期:2024-02-28
此功能现在已普遍可用。阅读最新公告。
Foundry Connector 2.0 for SAP Applications v2.30.0 (SP30) 现已可用
发布日期:2024-02-27
用于连接 Foundry 到 SAP 系统的 Foundry Connector 2.0 for SAP Applications 插件 的版本 2.30.0 (SP30) 现已可用。
此最新版本包含错误修复和小幅增强,包括:
- 扩展的后安装向导,涵盖远程代理(NetWeaver 7.0 及以上版本)并简化远程代理的设置过程。
- 扩展的 API,指示表是否为丰富表,Palantir HyperAuto(所有版本)将使用此功能。
- 修复了当代理名称和代理系统的 RFC 名称不同时自定义角色的授权问题。
- 在 CDPOS 增量类型中实施了逻辑更改,以解决在仅使用 CDPOS 类型进行增量同步期间可能导致数据丢失的问题。
直接从 Foundry 的平台内自定义文档下载
从 SP29 开始,可以直接从 Palantir 平台内下载插件安装包。要访问 SP29:
- 从 Foundry 导航栏底部打开平台内自定义文档。
- 在文档中搜索
SAP并选择 Foundry SAP Connector。 - 在文档的 How To 部分,选择 Download the Add-On。
我们建议将此通知分享给贵组织的 SAP Basis 团队。
有关下载插件的更多信息,请查阅文档中的 Download the Palantir Foundry Connector 2.0 for SAP Applications add-on。
介绍 Code Workspaces GA 中的 JupyterLab® 和 RStudio® 支持,将于 2024 年 3 月推出
发布日期:2024-02-22
Code Workspaces 中的 JupyterLab® 和 RStudio® 支持现已 GA。有关详细信息,请参阅 四月公告。
引入在 Code Workspaces 中支持 Palantir 提供的语言模型
发布日期:2024-02-22
Palantir 提供的 语言和嵌入模型集 现在可以在 Jupyter® notebooks 中通过 Code Workspaces 使用,类似于变换。通过这一新功能,用户可以交互式地对 Palantir 提供的模型进行推理,以生成文本完成和嵌入,并可以在部署完整的生产管道之前快速使用语言模型进行原型设计。
在 Code Workspaces 中使用语言模型
使用 Models 视图,Notebook 作者可以轻松地将 Palantir 提供的模型导入其代码工作区,并使用 palantir_models Python SDK 访问这些模型的绑定。

从 Models 菜单中将 Palantir 提供的模型导入 Code Workspace。
示例 notebook 单元格
下面的代码片段演示了开发人员如何在其 notebook 中使用 Open AI 的 GPT-4 ↗。在将模型导入 Code Workspace 后,复制并粘贴提供的代码片段到单元格中运行推理。
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16from language_model_service_api.languagemodelservice_api_completion_v3 import GptChatCompletionRequest from language_model_service_api.languagemodelservice_api import ChatMessage, ChatMessageRole from palantir_models.models import OpenAiGptChatLanguageModel # 获取GPT-4模型实例 model = OpenAiGptChatLanguageModel.get("gpt_v4") # 创建聊天完成请求,包含用户消息“为什么天空是蓝色的?” response = model.create_chat_completion( GptChatCompletionRequest( [ChatMessage(ChatMessageRole.USER, "why is the sky blue?")] ) ) # 获取并输出响应的第一个选择项的消息内容 response.choices[0].message.content
有关使用 Palantir 提供的模型的更多信息,请查阅 Jupyter® 笔记本中的 Palantir 提供模型文档。
Jupyter®、JupyterLab® 和 Jupyter® 标志是 NumFOCUS 的商标或注册商标。 所有引用的第三方商标(包括标志和图标)仍归其各自所有者所有。不暗示任何关联或认可。
停用 foundry_ml Python 库以支持 palantir_models 库,并将于 2025 年 10 月 31 日删除
发布日期:2024-02-22
从今天起,Python 库 foundry_ml 已进入其 停用期。foundry_ml 库将于 2025 年 10 月 31 日弃用,这与 Python 3.9 的计划弃用相对应。取而代之,我们建议使用 palantir_models 框架在平台中开发、测试和服务模型。
什么是 palantir_models 框架?
palantir_models 框架提供了更多的灵活性,以便为 Foundry 工作流程自定义模型,包括:
- 自定义序列化、API 和推理逻辑,以轻松支持更广泛的模型和推理模式
- 多输入和多输出模型
- 自动打包 Python 依赖项以便立即部署
- 为 Foundry 中的模型评估和推理提供一流的 外部托管模型 包装
- 支持非常大或非常自定义的建模框架的容器支持模型
- 直接访问媒体集进行模型推理

palantir_models 在 Foundry 中的使用架构图。
许多使用 foundry_ml 开发的模型可以使用代码库中的模型训练模板和文档中提供的示例模型适配器,通过编写最少的额外代码迁移到 palantir_models,如下所示:
请注意,其他模型可能需要手动迁移到 palantir_models 框架。要了解更多信息,请查看以下内容:
如何迁移到 palantir_models?
使用 foundry_ml 训练的模型需要在 2025 年 10 月 31 日之前更新为使用 palantir_models 框架。同样,使用 foundry_ml 开发的模型将不支持建模目标、Python 变换或建模目标部署。有关通过 palantir_models 构建新模型的迁移指南,请查看 如何在代码库中训练模型。
提醒一下,Palantir 将于 2024 年 10 月启动 升级助理干预活动,以通知使用受影响模型的团队。如果您对将工作流程迁移到 palantir_models 框架有任何疑虑,请联系 Palantir 客服支持。
引入 Automate AIP Logic 集成和手动执行功能 [GA]
发布日期:2024-02-20
AIP Logic 功能现在支持自动化,使得可以自动应用或计划用户审核的 Ontology 更改。这些自动化可以在现有对象上触发,也可以在创建新对象时触发。此功能允许您将 AIP Logic 功能支持的操作(例如大规模进行 Ontology 更改)自动应用于多达 100,000 个对象。
如何开始?
您可以使用右侧菜单中的 Automations 选项从 AIP Logic 仪表盘创建新自动化。选择此选项会打开一个新的视图,其中预填充了基于您的逻辑指令的自动化流程。条件将监控一个对象集,并为添加的每个新对象或现有对象触发 AIP Logic 功能效果。
您还可以直接从 Automate 用户界面创建自动化,如下图所示。

通过导航到右侧菜单中的 Automation 图标创建自动化。
使用 Automate 手动执行在一组现有对象上运行效果
Automate 现在还支持在现有对象集上运行效果,例如操作和 AIP Logic 功能,并触发通知。如果您希望自动在一批现有对象上运行 AIP Logic 功能,无论是生成 Ontology 编辑提案还是直接进行 Ontology 编辑,此功能都非常有用。
如何配置效果?
创建自动化后,选择左侧菜单中的 Execute。然后,定义对象以立即执行效果。对象集中的对象类型必须与设置自动化时使用的对象集类型匹配。要开始,配置所需的批次大小,然后选择 Execute。可以在多达 100,000 个对象的对象集上执行自动化。然后将显示计划任务,允许您查看现有批次的进度详细信息。
请记住,如果您希望防止在新对象上执行效果,必须通过选择屏幕右上角下拉菜单中的 Mute 选项来停用自动化。

要防止在新对象上执行自动化效果,请从下拉菜单中静音自动化。
有关设置自动化的更多信息,请查看 Automate 文档。
引入 Foundry DevOps 对 Quiver 仪表盘的支持 [Beta]
发布日期:2024-02-20
Foundry DevOps 和 Marketplace 是快速开发和部署在 Foundry 中构建的数据支持工作流程包的工具。我们很高兴地宣布对 Quiver 仪表盘 的初步支持,将于二月中旬在所有注册中可用。
使用对象分析卡片、基于对象的可视化和变换表的仪表盘现在可以通过 Foundry DevOps 作为 Marketplace 产品进行打包和部署。此外,仪表盘可以与其他内容一起打包。例如,现在可以将 Workshop 模块和嵌入的 Quiver 仪表盘一起打包。
如何打包仪表盘
从仪表盘设置面板的右侧,选择启用 Marketplace 模板化选项。然后,使用标题中可用的 Run Validation 选项识别潜在的 Marketplace 模板化问题(如果有)。

在 Workshop 中启用 Marketplace 模板化和模板验证的选项。
如果验证器未显示任何错误,则仪表盘的 Publish 或 Republish 选项将保存一个 Marketplace 准备就绪的仪表盘版本,以用于新的或现有的 Marketplace 产品。
查看仪表盘历史
分析历史 对话框的仪表盘部分还显示了哪些仪表盘版本已验证可进行打包。

仪表盘历史指示何时已验证版本可进行 Marketplace 打包。
开发路线图上有什么?
我们正在积极扩展支持的卡片数量,目标是在不久的将来添加时间序列和物化卡片。此外,我们计划提供一种从已安装的仪表盘创建新 Quiver 分析的方法。
有关更多信息,请参阅 将 Quiver 仪表盘添加到 Marketplace 产品 [Beta] 文档。
引入 Slate 的健康检查对话框 [GA]
发布日期:2024-02-20
借助新的 Slate 健康检查 对话框,应用程序构建者现在可以快速识别和解决失败的查询和函数,同时防止微件中的过时或不准确数据。以前,错误可能会被忽视,因为它们仅在查询或函数面板中可见,而此新功能将 Slate 查询和函数中的所有错误和警告整合在一起。通过这样做,它简化了发现错误的过程,并促进了对其他应用程序组件下游影响的更好理解。
立即发现问题
当以编辑模式打开 Slate 应用程序时,应用程序会在加载时自动检查所有查询和函数的成功运行时。然而,用户应该注意,如果在默认应用程序状态下未满足条件,则带有条件的查询可能不会运行。任何遇到的错误或警告将出现在页面顶部的操作栏中。

Slate 应用程序中的错误和警告将出现在操作栏中。
选择问题图标以打开 健康检查 对话框。从这里,直接跳转到引发问题的查询或函数,无论是在画布上还是在依赖关系图视图中,以便进一步调查。

直接跳转到引发问题的查询或函数。
借助此功能,新的 健康检查 对话框提高了 Slate 应用程序的可维护性,特别是对于拥有数百个查询的大型应用程序而言。此增强功能使得更容易发现和解决问题,确保更流畅的用户体验。
有关更多信息,请查阅 调试 Slate 应用程序 文档。
引入 Claude、Llama2 和其他 Palantir 托管的开源模型在批准的注册中使用
发布日期:2024-02-15
Palantir AIP 现在默认支持 Claude、Llama2 和其他 Palantir 托管的 LLM 模型,如 Mistral 等。每个注册中启用的默认模型可能不同,并且某些注册可以在适用时利用在更宽松的开源许可证下发布的替代模型。
一个新的控制面板功能正在开发中,用于批准条款和启用新模型,并将在二月底前准备就绪。

这些模型现在支持在 Functions 和变换中使用。
有关更多详细信息,请查看 Palantir 提供的大型语言模型。
引入 Vega-Lite 图表选择
发布日期:2024-02-13
Quiver 允许用户使用 Vega-Lite ↗ 或 Vega ↗ 库创建完全自定义的可视化。之前,Vega 图表不支持选择 - 这是一个功能强大且高度可定制的功能,用于构建交互式可视化。 我们很高兴地宣布,现在可以配置 Vega-Lite 图表以输出选择数据。用户可以利用选择数据来参数化下游卡片、构建钻取工作流程并继续分析。 Vega-Lite 选择允许用户通过两种选择与图表进行交互:
- 点选择: 选择单个点,或
Shift+click选择多个点。 - 区间选择: 拖动以在画布上选择一个有界矩形区域。
定义选择参数
在您的 Vega-Lite 规范中编写自定义选择参数,并通过命名为 quiverDefaultClick 或 quiverDefaultBrush 将它们连接到变换表输出。定义您希望选择的编码字段,例如 x、y 或 shape。

在 Vega-Lite 规范中编写自定义选择参数。
将选择数据输出为变换表
点选择作为字段和值的表输出,其中每一列对应一个字段,每一行代表一个选定点。

区间选择作为区间边界的范围输出,如果字段是连续的,或作为值的数组输出,如果字段是离散的。

构建钻取工作流程
来自 Vega-Lite 图表的选择数据可用于构建钻取工作流程,其中图表选择作为筛选,用户可以根据上游的选择继续分析数据子集。
例如,下图展示了一个工作流程,其中 Vega 图表中的选择作为对下游变换表的实时筛选。

Vega 图表中的选择作为实时筛选。
自定义选择行为
选择参数还可以自定义为选择不同的字段,或在不同的鼠标事件上触发。

在散点图中按颜色分段选择。

在折线图中按颜色分段选择。

按地理区域选择。
有关在 Quiver 中使用 Vega 图表的更多信息,请查阅 文档。
引入敏感数据扫描器 [GA]
发布日期:2024-02-08
敏感数据扫描器(“SDS”,以前称为 "Foundry Inference")帮助组织在 Foundry 中跨数据集发现和保护敏感数据。治理用户可以使用 SDS 定义敏感数据模式,识别它们,并在发现匹配数据时自动采取行动。此外,用户还可以使用更新的界面来准确跟踪和监控启动的扫描。
敏感数据扫描器将在 2 月 19 日这一周内在 Foundry 注册中普遍可用。

敏感数据扫描器一次性扫描概览。
自动发现和保护敏感数据
敏感数据扫描器 (SDS) 使管理员能够在 Foundry 中发现和保护敏感数据。设置敏感数据扫描非常简单,可以由技术和非技术用户完成。首先,为 AIP 提供一个自然语言提示,或直接输入正则表达式以指定敏感数据模式。然后,配置 Foundry 在发现匹配模式的数据时要采取的自动化操作。

创建 SDS 匹配条件。
SDS 可用于临时扫描,或在将新数据添加到平台时安排定期运行。
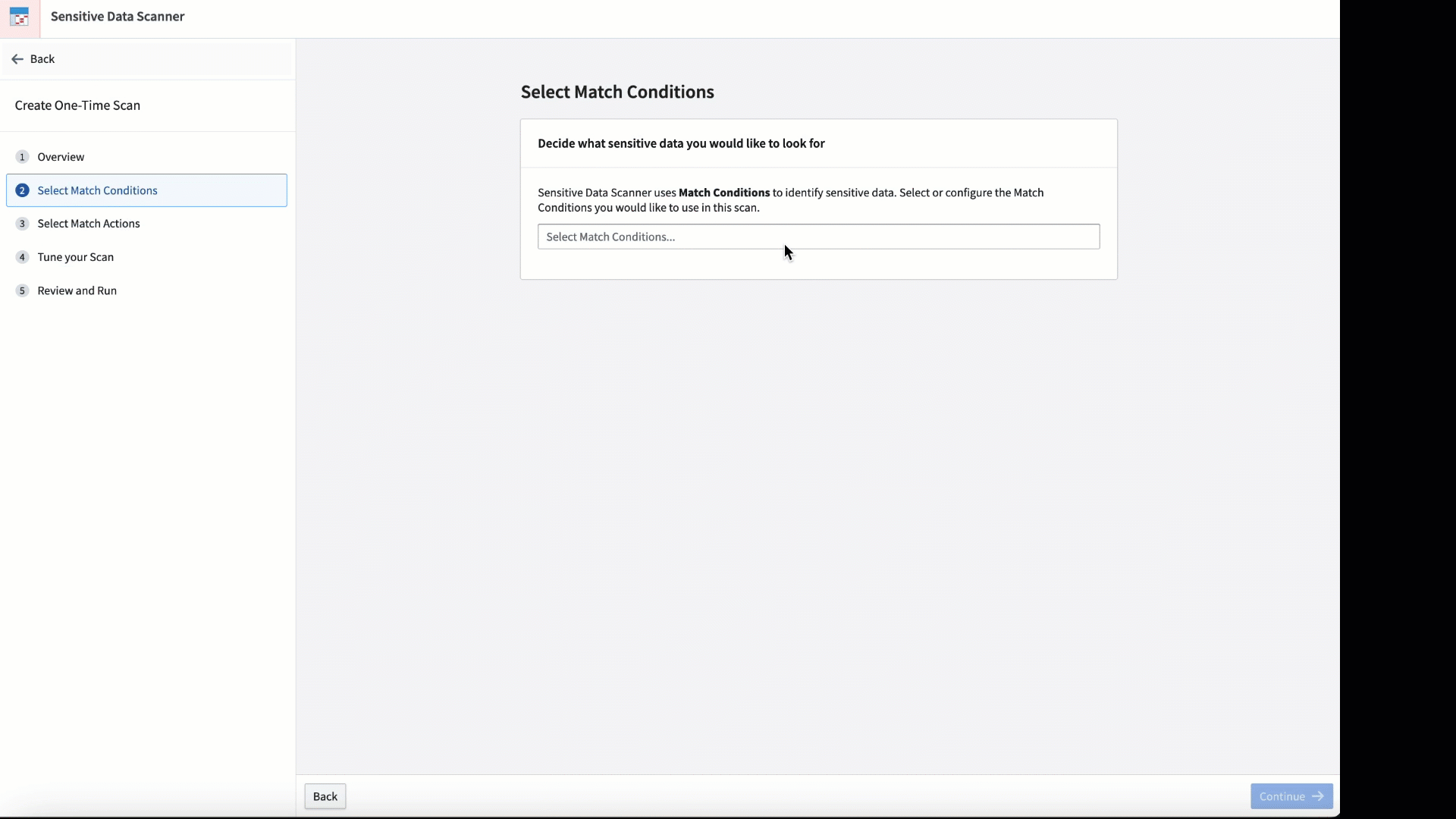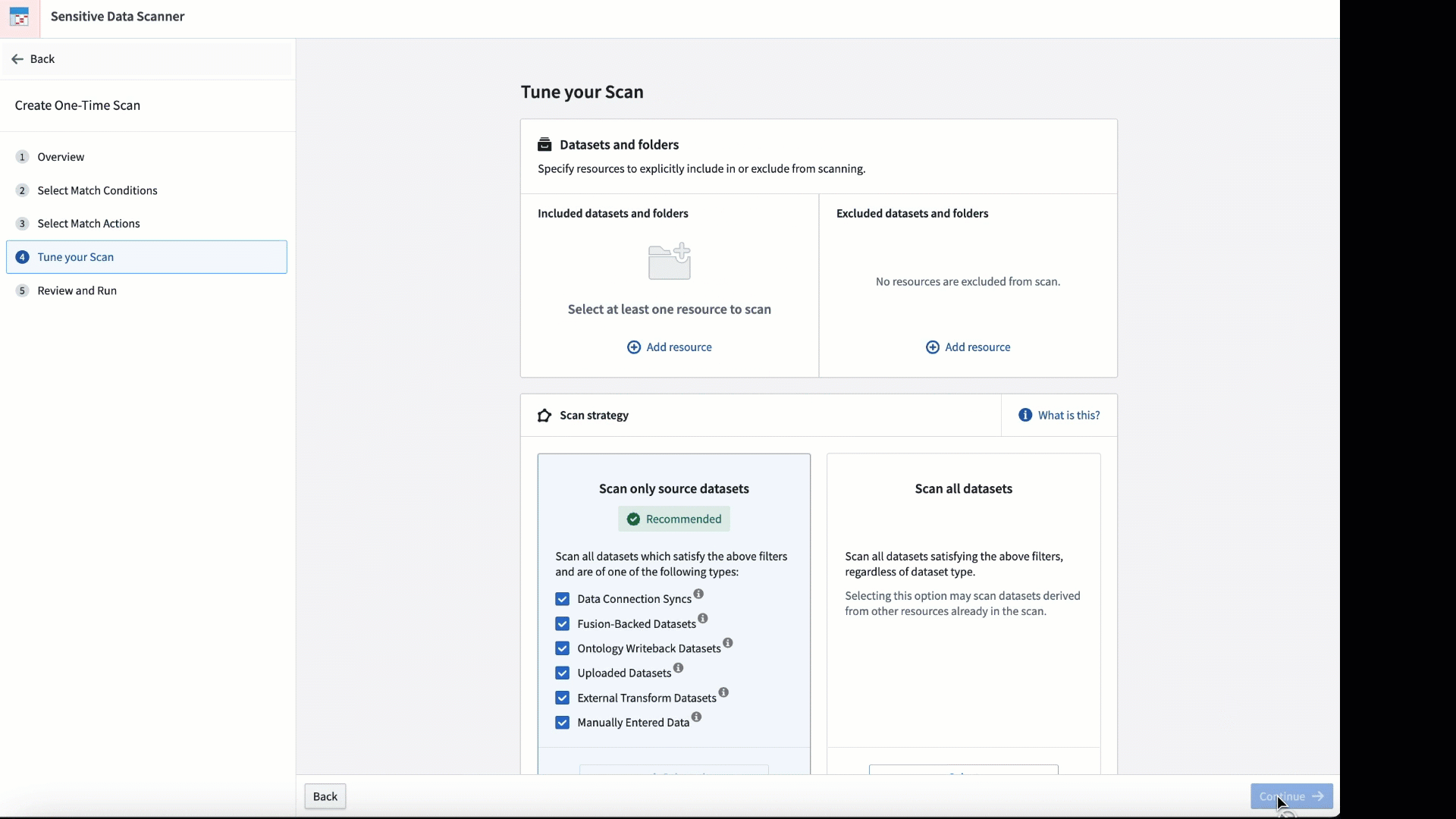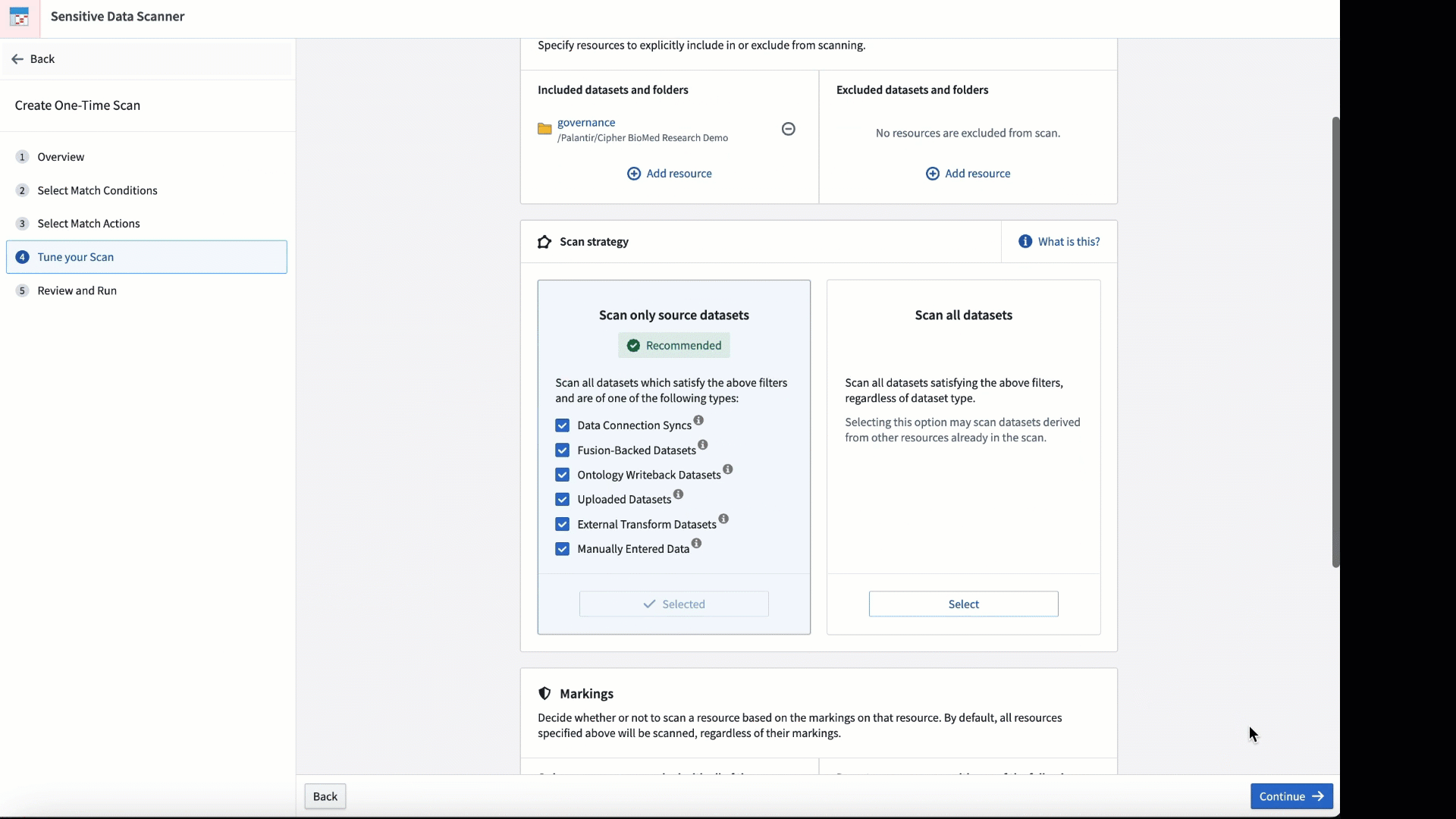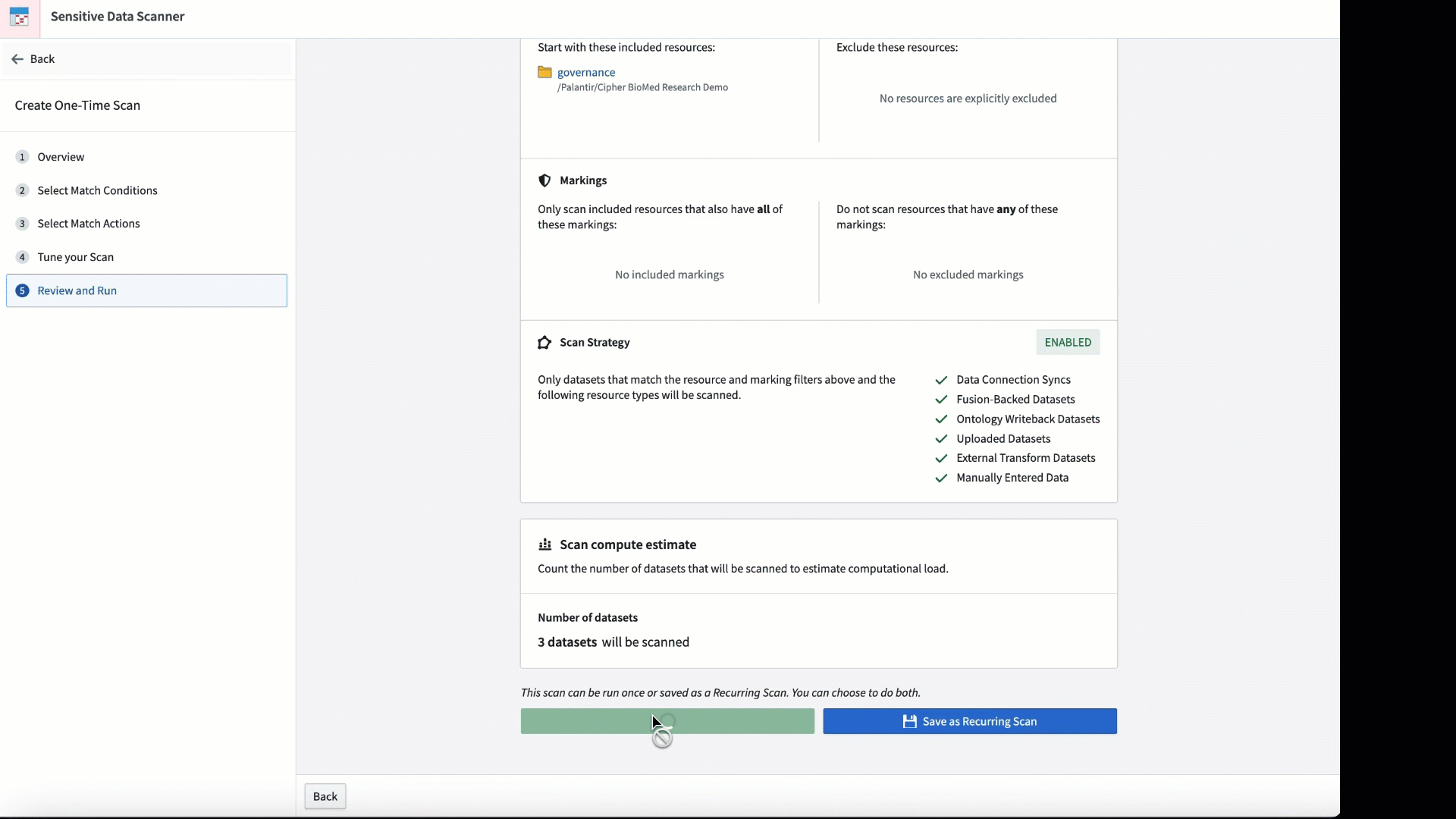
通过调整匹配条件和扫描进行的频率来个性化扫描。
多个应用程序的安心
敏感数据扫描器可用于保护您的数据。请考虑以下概念示例:
- 一个定期通过手动上传以及 Magritte 引入的数据的组织可能会忘记在新数据集上设置 权限标记。经常性的 SDS 扫描可以防止 PII 被无意中泄露给未授权用户。
- 处理敏感数据的组织的数据治理团队可以使用 SDS 通过对数据集执行定期扫描来锁定高度敏感的信息,使用适当的参数集。团队成员可以为扫描创建一个 重叠匹配条件,确保最敏感的数据保持安全并限制用于分析。
- 一个利用 AIP 开发 LLMs 运营工作流程的组织可以应用 SDS 来检查通过光学字符识别 (OCR) 从文档中提取的文本,然后再将其集成到 Ontology 对象中,这可以帮助防止向 LLM 发送敏感信息。
有关更多信息,请查看 敏感数据扫描器 文档。
在开发者控制台中引入网站托管 [Beta]
发布日期:2024-02-08
开发者控制台即将支持静态网站托管。静态网站包含预定义数量的文件(例如,HTML、CSS、JavaScript),这些文件将被下载并直接按存储方式呈现到最终用户的浏览器中。以前,要使用 OSDK 构建的静态 Web 应用程序进行托管,用户必须使用诸如 React ↗ 等框架的自己的外部 Web 托管解决方案。此新功能允许开发者直接使用 Foundry 托管和服务网站,简化工作流程,无需外部 Web 托管基础设施。
此功能将在二月中旬作为所有 Foundry 管理的域的 Beta 功能可用,并计划在今年晚些时候普遍可用。
直接在 Foundry 上托管您的网站
在开发者控制台中配置静态网站托管只需几个简单步骤。首先,选择左侧菜单中的 网站托管,然后:
- 为该站点设置一个应用程序域,以定义用户将从中访问该站点的 URL。
- 将包含站点的资产上传到 Foundry。
- 预览您的上传结果并发布到该站点。
您还可以直接从设置页面配置对网站的访问权限,并为您的站点设置高级 内容安全政策 (CSP) 设置。
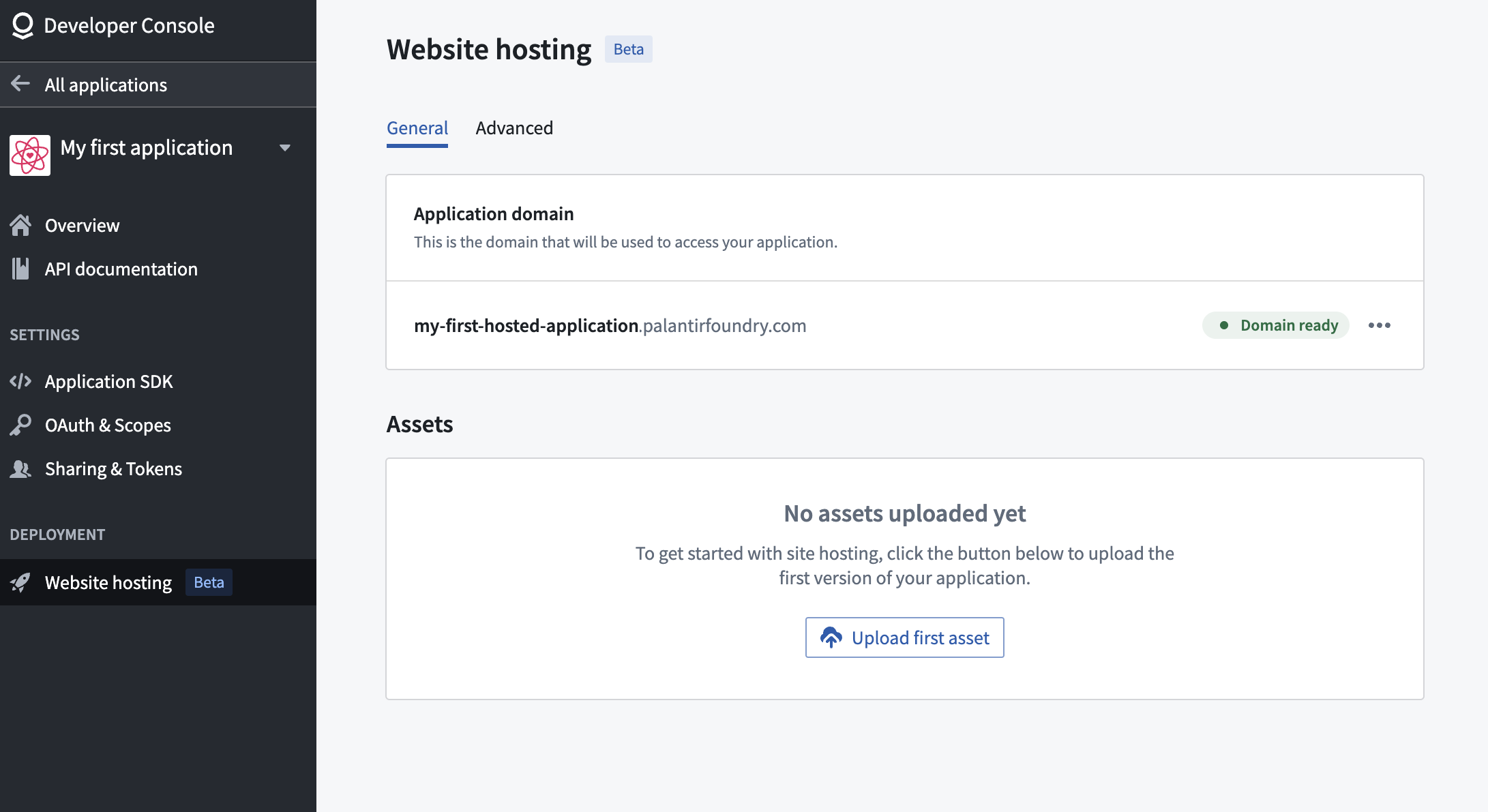
开发者控制台即将支持静态网站托管。
谁可以配置网站托管?
任何具有开发者控制台编辑权限或所有者角色的用户都可以配置静态网站托管。应用程序的子域地址必须获得注册信息官 (EIO) 的批准。批准请求可以在开发者控制台设置中进行管理,而 EIOs 可以通过控制面板授予批准。
开发路线图上有什么?
我们正在努力为客户拥有的域启用 Web 托管。此外,正在积极开发 API,以便从您的持续集成和持续交付 (CI/CD) 管道中将站点部署集成到此 Web 托管服务。
要了解有关网站托管配置的更多信息,请查看 在 Foundry 上部署 Ontology SDK 应用程序 (Beta)。
Python 代码库中代码助手启动和检查显著加快
发布日期:2024-02-01
代码助手和 Python 代码库中的检查现在共享 Python 环境缓存,从而显著提升了代码助手启动和检查(CI)的性能。要利用此改进,请升级您的代码库。
以下工作流程受益于新的性能增强:
-
运行检查: 当用户触发检查时,会构建并缓存一个环境。代码助手启动现在通过使用检查发布的缓存环境来执行得更快。
-
代码助手启动: 创建并缓存 Python 环境,由于代码助手发布的缓存环境,检查运行更快。此外,任何后续的代码助手启动也将使用相同的缓存以优化性能。
请考虑以下两个示例的时间图:
- 使用检查缓存的代码助手启动:

- 使用代码助手缓存的检查性能:

请注意,当使用 任务运行器 安装依赖项时,此功能当前不可用。
轻量级变换的新扩展功能
发布日期:2024-02-01
轻量级变换现在支持广泛的数据处理引擎和自带容器 (BYOC) 工作流程。
除了速度之外,轻量级变换易于与任意数据处理解决方案连接。我们引入了一组新的 API,使您能够快速将 Foundry 数据集与不仅仅是 Pandas 和 Polars,还包括 DuckDB、Ibis、DataFusion、cuDF 和其他依赖于行业标准数据格式(如 Arrow 和 Parquet)的数据处理引擎集成。 新的 API 为您提供更多选项,根据需要选择使用的引擎运行变换。与 Spark 变换不同,通过 @lightweight 变换集成这些系统不会产生额外的序列化和反序列化开销。 例如,以下代码片段演示了使用轻量级 API 与 Apache DataFusion 集成:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13@lightweight @transform(my_input=Input('/input'), my_output=Output("/output")) def my_datafusion_transform(my_input, my_output): # 创建 DataFusion 会话上下文 ctx = datafusion.SessionContext() # 从输入路径读取 Parquet 格式的数据表 table = ctx.read_parquet(my_input.path()) # 对数据进行过滤,筛选出 "name" 字段以 "John" 开头的行,并写入输出路径 my_output.write_table( table .filter(starts_with(col("name"), literal("John"))) .to_arrow_table() # 转换为 Arrow 表格式 )
此外,轻量级变换现在支持BYOC工作流,您可以将任意环境带到Foundry,并运行之前不支持的可执行文件。以下代码片段展示了您如何编译并运行一个COBOL程序以生成数据:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13@lightweight(container_image='my-image', container_tag='0.0.1') @transform(my_output=Output('my_output')) def compile_cobol_data_generator(my_output): """展示如何引入通过 Conda 难以获得的依赖项。""" # 编译 Cobol 程序 # (src 文件夹中的所有内容都在 $USER_WORKING_DIR/user_code 中可用) os.system("cobc -x -free -o data_generator $USER_WORKING_DIR/user_code/resources/data_generator.cbl") # 运行程序以创建和填充 data.csv os.system('$USER_WORKING_DIR/data_generator') # 将结果存储到 Foundry my_output.write_table(pd.read_csv('data.csv'))
@lightweight和@transform是装饰器,用于指定容器镜像和输出。os.system("cobc -x -free -o data_generator $USER_WORKING_DIR/user_code/resources/data_generator.cbl")用于编译 Cobol 源代码生成可执行文件data_generator。os.system('$USER_WORKING_DIR/data_generator')执行编译后的程序以生成数据文件data.csv。my_output.write_table(pd.read_csv('data.csv'))将生成的 CSV 文件读取为数据表,并存储到 Foundry 输出。 对于上述两个示例的完整演练,请查看轻量级示例。此外,可以在参考资源市场商店的轻量级示例产品中找到更多示例。 要开始使用新轻量级API的完整功能集,请升级您的存储库到最新版本,并安装最新版本的foundry-transforms-lib-python。有关更多详细信息,请查看我们的文档。
介绍 SMB 连接器 [Beta]
发布日期:2024-02-01
SMB连接器 [Beta]允许您连接到服务器消息块(SMB)文件共享并将文件摄取到Palantir平台。 SMB文件共享的常见示例包括Windows文件服务器、Samba文件服务器和大多数商用NAS设备。
到目前为止,我们推荐的连接SMB文件共享的模式是将共享挂载为Foundry代理服务器上的目录,然后使用目录连接器来摄取文件。我们鼓励使用旧模式的任何人迁移到新的SMB连接器。
SMB连接器相对于文件系统挂载的优势:
- 不需要SSH访问您的代理
- 可以作为直接连接运行
- 不会将凭据以明文形式存储在代理服务器上
- 在服务器重启时保持持久
有关更多信息,请查看公共文档中的服务器消息块 (SMB) [Beta]。
其他亮点
管理 | 工作区
发布日期:2024-02-29
帮助中心侧边栏的弃用 | 帮助中心侧边栏已弃用,并被与Foundry文档和Foundry问题的类似集成所取代。
分析 | Contour
发布日期:2024-02-27
Contour中的新可视化时区设置 | Contour现在具有新的设置,可视化时区,允许用户控制在分析中的所有看板上如何显示日期时间。此设置可以配置为用户的本地时区或固定时区,提供统一的时区行为方法。对于新分析,默认设置将是用户的本地时区。然而,对于现有分析,用户需要手动选择可视化时区。查看文档。

应用构建 | Workshop
发布日期:2024-02-27
改进的Workshop筛选:GA链接对象筛选 | Workshop的筛选列表中的链接属性筛选现在已普遍可用,允许用户基于链接对象属性进行筛选,提供更精确和集中的搜索体验。
分析 | Quiver
发布日期:2024-02-27
Quiver中的新聚合指标:精确唯一计数、标准差和方差 | Quiver现在支持新的聚合指标:精确唯一计数、标准差和方差。用户可以计算属性类型上的精确唯一计数,但这不支持由对象存储V1支持的对象类型,并且可能会降低超过10,000个结果的性能。此外,用户现在可以计算属性类型上的标准差和方差,并可以选择在计算样本或总体标准差和方差之间切换。有关详细信息,请查看Quiver图表文档。
模型集成 | 建模
发布日期:2024-02-27
Python 3.9支持已添加到foundry_ml库 | 我们已更新foundry_ml库以添加对Python 3.9的支持。根据我们的公告,这将是foundry_ml库支持的最后一个Python版本。
应用构建 | Workshop
发布日期:2024-02-27
在对象集编辑器中增强的链接对象筛选 | 对象集编辑器现在支持对链接对象进行筛选,允许构建者轻松配置链接筛选,例如检索所有链接到具有“高优先级”的“警报”的“航班”。
安全 | 审批
发布日期:2024-02-27
已完成请求现在在审批收件箱中显示完成日期 | 审批收件箱中的已完成请求现在将显示“完成于”消息,以帮助审计流程。请注意,当前正在开发显示完成任务的用户功能,并将在未来的更新中提供。
分析 | Notepad
发布日期:2024-02-27
在Notepad中改进的“锁定数据”快照安全性 | Notepad中的锁定数据功能现在要求在创建静态快照时对提供数据给微件的所有资源进行权限标记,以增强数据安全性。请注意,接收来自受限视图或无法确定访问控制的资源数据的微件的锁定数据不再可能。有关更多详细信息,请参阅快照微件文档。
应用构建 | Ontology SDK
发布日期:2024-02-27
增强的网站样式自定义 | 用户现在可以在其托管网站的内容安全策略(CSP)中配置“style-src”,以实现更广泛的网站样式自定义。

安全 | 审批
发布日期:2024-02-27
审批任务中增强的权限标记弹出窗口可访问性 | 审批组件现在提供了对权限标记访问任务中标记弹出窗口的改进访问,例如“添加成员到标记”和“将标记添加到项目约束”。此改进使用户能够轻松导航到设置以查看标记或其他元数据,提供更无缝和高效的用户体验。
模型
发布日期:2024-02-27
模型训练模板现在支持PyPI依赖项 | 代码存储库中的模型训练模板中生成的模型现在支持PyPI依赖项。这些依赖项将通过建模目标应用程序自动包括在批处理和实时部署中。
Ontology | Vertex
发布日期:2024-02-27
在Workshop中改进的Vertex微件体验 | Workshop中的Vertex微件已升级,以提供更动态的用户体验。现在,每当由其他微件更新Selected Objects变量时,Vertex微件将自动刷新。这确保了用户始终拥有最新的信息。
Ontology | Vertex
发布日期:2024-02-27
地图的自定义标签名称 | 用户现在可以在地图中定义自定义标签名称,提供更多的灵活性和个性化。此更新允许用户通过使用对他们更有意义的标签来更好地组织和管理他们的数据。
模型集成 | 建模
发布日期:2024-02-22
Python 3.9支持已添加到建模 | 我们在建模中引入了对Python 3.9的支持,使用户能够利用Python 3.9中的最新功能和增强功能,并进一步提高他们在Foundry中创建和管理模型的能力。
应用构建 | Workshop
发布日期:2024-02-22
图像注释微件现在普遍可用 | Workshop图像注释微件现在普遍可用,允许用户通过媒体URL或媒体引用属性显示图像,并通过标记感兴趣的区域来创建注释。注释可以轻松引用为操作参数,用于创建、修改或删除注释对象,并支持每张图像最多1000个注释。微件还提供用于注释着色和触发注释创建事件的可选配置。了解更多
应用构建 | Workshop
发布日期:2024-02-22
Markdown中的对象引用:普遍可用 | Workshop中的Markdown微件现在包含对象引用,允许用户将对象链接到文本并设置点击事件。此更新通过将其连接到Ontology中的权威对象来提高书面或AI生成内容的可靠性。对象引用的自定义渲染与标准Markdown功能兼容,例如列表、反引号、表格等。在文档中查找更多详细信息

数据集成 | 代码存储库
发布日期:2024-02-22
增强的TypeScript函数调试功能 | 代码存储库现在为TypeScript函数提供增强的调试功能。借助新的TypeScript函数调试器工具,您可以实时检查单元测试,设置断点暂停执行,并更深入地了解您的函数和库。有关如何使用此功能的分步指南,请参阅设置断点文档。
分析 | Quiver
发布日期:2024-02-22
在Quiver中创建持续时间单位参数 | Quiver现在支持创建持续时间单位参数,允许用户指定他们希望包含或排除的持续时间单位类型。配置过程与其他Quiver参数配置一致,确保用户体验无缝。
分析 | Notepad
发布日期:2024-02-15
模板中的增强排序功能 | Notepad模板现在在每个行或部分生成器中包含一个排序配置字段。此新功能允许用户按对象属性值排序这些生成器的输出,提供额外的配置选项,如大小写敏感性和升序或降序。当Notepad从模板生成时,生成的行和部分将根据配置的属性进行排序,提供更有组织和可定制的用户体验。
安全 | 项目
发布日期:2024-02-15
增强的权限检查 | 数据沿袭应用程序现在为对象类型和Ontology操作提供增强的权限检查。用户可以验证他们是否有能力查看对象类型或该类型内的对象。来自上游数据源的任何限制也将可见。用户还可以检查他们是否有权限查看和提交操作,以及任何潜在的提交限制。
安全 | 检查点
发布日期:2024-02-13
检查点现在支持重新认证理由 | 检查点现在包括重新认证作为理由类型,以及确认、自由文本响应和下拉选择。此功能允许用户在执行敏感操作时通过重新认证平台来证明检查点的合理性。在遇到需要重新认证的检查点时,用户将被提示在单独的窗口中通过其配置的身份提供者(IdP)重新认证。完成重新认证过程后,用户可以继续其预期的操作。此重新认证理由的记录将由授权用户在检查点应用程序中查看。重新认证理由与所有检查点类型兼容,除了登录和范围会话选择类型。有关使用此理由创建检查点的指南,请参阅检查点文档。

分析 | Quiver
发布日期:2024-02-13
Quiver时间序列图表显示部分 | 为Quiver时间序列图表编辑器添加了一个坐标轴选项部分,并重命名了Y轴压缩编辑器。
数据集成 | 数据沿袭
发布日期:2024-02-13
数据沿袭中的增强权限检查 | 数据沿袭应用程序现在包括对对象类型和操作的改进权限检查。用户可以查看他们是否有权访问对象类型,以及来自上游数据源的任何限制。此外,用户可以查看他们是否可以查看或提交操作,以及任何提交限制。要查看其他用户权限,用户必须拥有对用户、底层对象类型、操作和支持数据集的访问权限。
分析 | Contour
发布日期:2024-02-13
在更高规模下增强的参数交叉筛选 | Contour中的参数交叉筛选已显著改进以处理更高规模。此增强减少了当参数值由另一个参数筛选时达到基数限制的可能性。用户现在可以创建参数筛选组,并在编辑或处理数字参数时体验到更无缝的与建议值的互动。
模型集成 | 建模
发布日期:2024-02-13
模型资产自动序列化 | palantir_models包已更新,包括模型工件的自动序列化和反序列化的默认方法。使用新的auto_serialize注解在模型适配器中消除了在模型适配器中手动编写save()和load()方法的需要。
应用构建 | Ontology SDK
发布日期:2024-02-13
开发者控制台中的应用搜索可用 | 用户现在可以在开发者控制台中搜索应用程序,提供更高效的方式查找和访问特定应用程序。
分析 | Quiver
发布日期:2024-02-13
Quiver中的新布尔筛选变换 | Quiver现在支持两个新的布尔比较变换,用于变换表,允许用户基于布尔列值比较和筛选行。
Foundry 高级搜索
发布日期:2024-02-07
高级搜索增强 | 高级搜索是Foundry的综合性全屏扩展,用于查找难以找到的资源。高级搜索包括对人工智能平台支持查询的支持、复制粘贴查询共享以及广泛的搜索筛选。

安全 | 项目
发布日期:2024-02-07
添加请求访问按钮以获取数据标记权限 | 面临由于缺少数据或文件标记而导致的权限障碍的用户现在可以使用审批应用程序请求访问缺少的标记。有关审批的更多信息,请参阅审批文档。

应用构建 | Workshop
发布日期:2024-02-06
在workshop中更容易的语义搜索设置 | 现在在Workshop模块中更容易支持语义搜索。此前,Workshop构建者需要编写自定义typescript函数以允许在具有向量嵌入属性的对象上进行语义搜索。现在,Workshop的对象集定义面板允许在前端通过几次点击配置语义搜索筛选。


Ontology | Vertex
发布日期:2024-02-06
Vertex用户界面改进 | 对Vertex主页、设计选择和时间轴进行了多项用户界面增强。用户将体验更精致的界面,具有更清晰的对象类型用户界面、改进的设计选择视觉效果和减少时间轴中的闪烁。
Ontology | Ontology管理
发布日期:2024-02-06
Ontology管理器中的属性类型增强验证 | Ontology管理器现在包括增强的验证功能,以防止在恢复到对象存储V1时保存无效的属性类型,以确保在迁移属性类型时的数据完整性和一致性。
分析 | Contour
发布日期:2024-02-06
顶级值自定义看板 | 引入顶级值自定义看板,允许用户筛选和显示基于指定数量或百分比的列的顶级或底部值。这个新看板提供了一种动态的方法来分析数据并创建有用的报告。
Ontology | Vertex
发布日期:2024-02-06
在Vertex中复制注释 | 用户现在可以在Vertex中复制一个或多个选定的注释,使创建样式相似的注释更容易。
Ontology | Ontology管理
发布日期:2024-02-06
前20个Ontology管理器错误的自定义错误消息 | Ontology管理器现在为用户在保存对其Ontology的更改时遇到的前20个最常见错误提供自定义错误提示消息。此增强通过提供更清晰和更具体的错误消息来改善用户体验。
Ontology | Ontology管理
发布日期:2024-02-06
更新MDO导出的输入数据源 | 用户现在可以更新Ontology管理器中多数据源对象(MDO)导出类型的输入数据源。这在更改由多个数据源支持的对象类型的输入数据集时提供了更大的灵活性。
Ontology | Vertex
发布日期:2024-02-06
Vertex的自定义标签名称 | 用户现在可以在Vertex中定义自定义标签名称,提供更多的灵活性和个性化。此更新允许用户通过使用对他们更有意义的标签来更好地组织和管理他们的数据。
分析 | Contour
发布日期:2024-02-06
在分析子菜单中扩展数据集访问 | 用户现在可以在所有资源选择器下拉菜单中的分析子菜单中访问数据集,从而提高在合并和联合看板上工作的便利性和效率。
应用构建 | Workshop
发布日期:2024-02-06
Workshop: 编辑历史微件现已可用 | 在Workshop中引入编辑历史微件,允许用户查看对对象属性所做的编辑。构建者可以配置可查看属性的集合以及编辑显示的顺序。此微件仅兼容使用对象存储V1的对象类型,V2支持将在今年晚些时候提供。


数据集成 | 代码存储库
发布日期:2024-02-06
增强的TypeScript单元测试调试器 | 引入TypeScript函数的增强调试功能,允许您在调试模式下运行您的单元测试。设置代码中的断点并逐步执行过程,以更好地理解幕后的一切是如何工作的。
Ontology | Ontology管理
发布日期:2024-02-06
在Ontology管理器中改进的显示名称排序 | Ontology管理器现在通过组合大写和小写结果来更直观地排序显示名称。以前,以大写字母开头的实体与以小写字母开头的实体分开排序。新的排序行为将以任何字母开头的实体分组在一起。
模型集成 | 建模
发布日期:2024-02-06
作为函数的实时部署 | 用户现在可以发布实时部署作为函数,并访问新的部署表以便更好地组织和管理。
应用构建 | Foundry开发者控制台
发布日期:2024-02-06
开发者控制台中的新权限页面 | 开发者控制台现在有一个专用的权限页面,您可以在其中管理应用程序的共享、网站的共享和应用程序发现。OAuth客户端角色授权也将被移至此页面。