注意:以下翻译的准确性尚未经过验证。这是使用 AIP ↗ 从原始英文文本进行的机器翻译。
公告
提醒: 注册 Foundry 通讯以直接在您的收件箱中接收平台上新产品、功能和改进的摘要。有关如何订阅的更多信息,请参阅 Foundry 通讯和产品反馈渠道公告。
在 我们的开发者论坛 ↗ 分享您对这些公告的想法。
介绍 community.palantir.com,我们的官方 Palantir 开发者社区
发布日期:2024-06-25
我们自豪地介绍 Palantir 开发者社区,这是一个专门为 Foundry 和 AIP 用户及合作伙伴之间交换想法和专业知识而设的协作空间。在这个社区中,Palantir 开发者、应用程序构建者和高级用户可以相互连接以提问和回答问题、提供产品反馈并随时了解最新产品计划和开发者活动。
Palantir 开发者社区,Palantir 平台的开发者和高级用户的家园。
要开始,请导航到 community.palantir.com 创建一个免费帐户并加入对话。
注意:Palantir 开发者社区是公开的。请避免发布机密或敏感数据,并在 Palantir 开发者社区中发帖时遵守您组织的相关政策。参与是自愿的,回复不保证。与 Palantir 签订支持合同的客户应通过标准支持渠道提交需要回复的请求、非公开查询、错误报告或功能请求。
现在可用的 JDBC 系统表格导出
发布日期:2024-06-25
现在可以使用数据连接中的表格导出将数据集导出到外部 JDBC 系统。表格导出为通过直观界面配置表格数据导出引入了一种新的用户体验,丰富的导出模式选择,并能够探索目标系统以配置导出。表格导出将与通过直接连接和代理运行时配置的自定义 JDBC 系统一起使用。
导出模式
表格导出支持六种不同的导出模式,以满足您的独特需求:
- 高效镜像数据集到外部表(推荐): 外部表将始终与您在 Foundry 数据集中看到的内容匹配。
- 完整数据集不截断: 始终导出 Foundry 数据集的整个视图的快照,而不先截断外部表。
- 完整数据集截断: 截断(删除)目标表,然后导出完整当前数据集视图的快照。
- 增量导出: 仅导出当前视图中未导出的事务,而不截断目标表。
- 增量导出并截断: 截断(删除)目标表,然后仅导出当前视图中以前未导出的事务。
- 增量导出并在不为
APPEND时出错: 仅导出当前视图中未导出的事务,如果存在SNAPSHOT、UPDATE或DELETE事务则失败(首次运行后)。
在我们的文档中了解有关每种导出模式的详细信息。
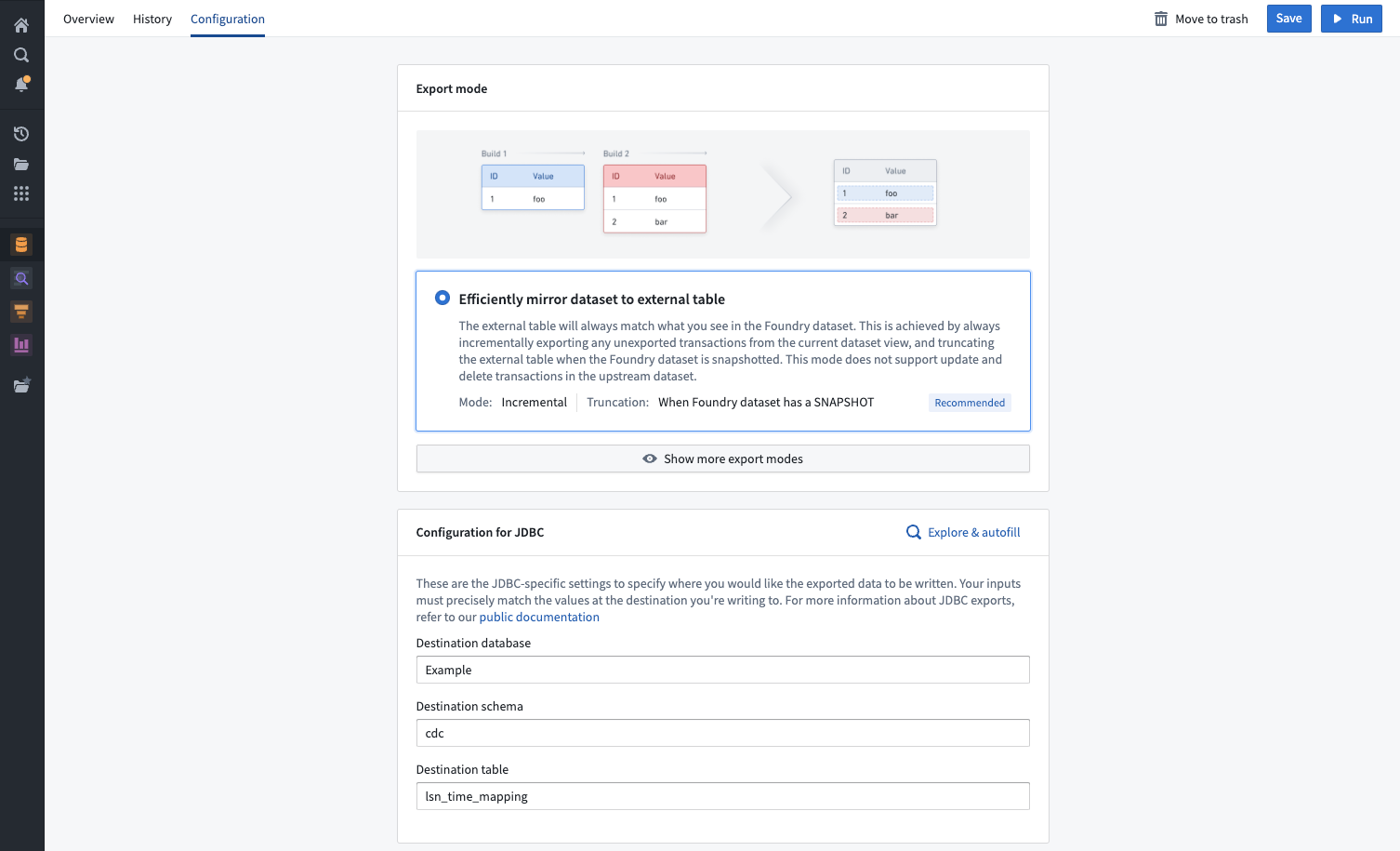
数据连接中的导出模式选择示例。
探索目标系统
要导出数据集,其架构_必须_与目标系统上的表的架构匹配。为帮助您配置正确的表,提供了一个源浏览器来导航目标源上的所有架构和表。
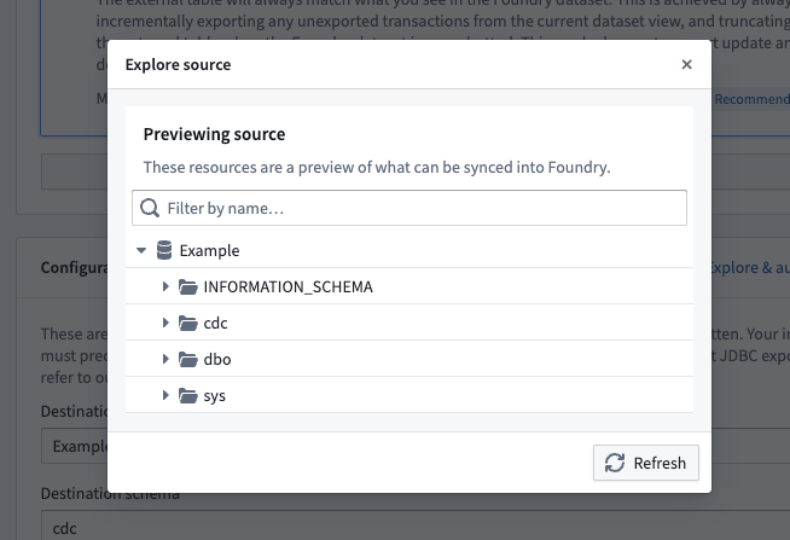
源探索对话框示例。
从导出任务迁移
表格导出的添加旨在取代现在已停用的导出任务以导出表格数据,鼓励每个导出任务的用户迁移到表格导出。了解有关数据连接导出和导出任务之间的区别的更多信息,并了解如何迁移您的工作流程。
开发路线图上的下一个是什么?
目前,表格导出仅适用于自定义 JDBC 源。我们计划在不久的将来扩展对更多连接器类型的支持。
使用 Pipeline Builder 中的词元计数估算计算使用量
发布日期:2024-06-25
现在,词元计数指标可用于使用 OpenAI 模型的 Pipeline Builder 预览和试运行。此功能在部署管道之前提供了更多对计算使用情况的可见性,使用户能够更好地控制计算使用量和成本。
Use LLM 节点预览和下游变换现在在使用 OpenAI 模型时具有总估计词元计数。试运行还会显示运行行数的总估计词元计数。
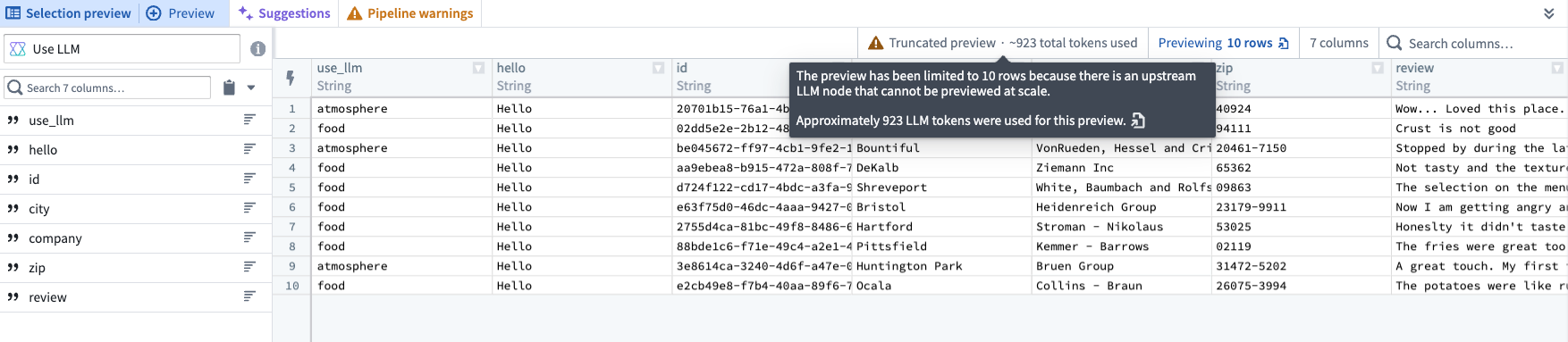
在 Use LLM 节点预览中近似词元计数。
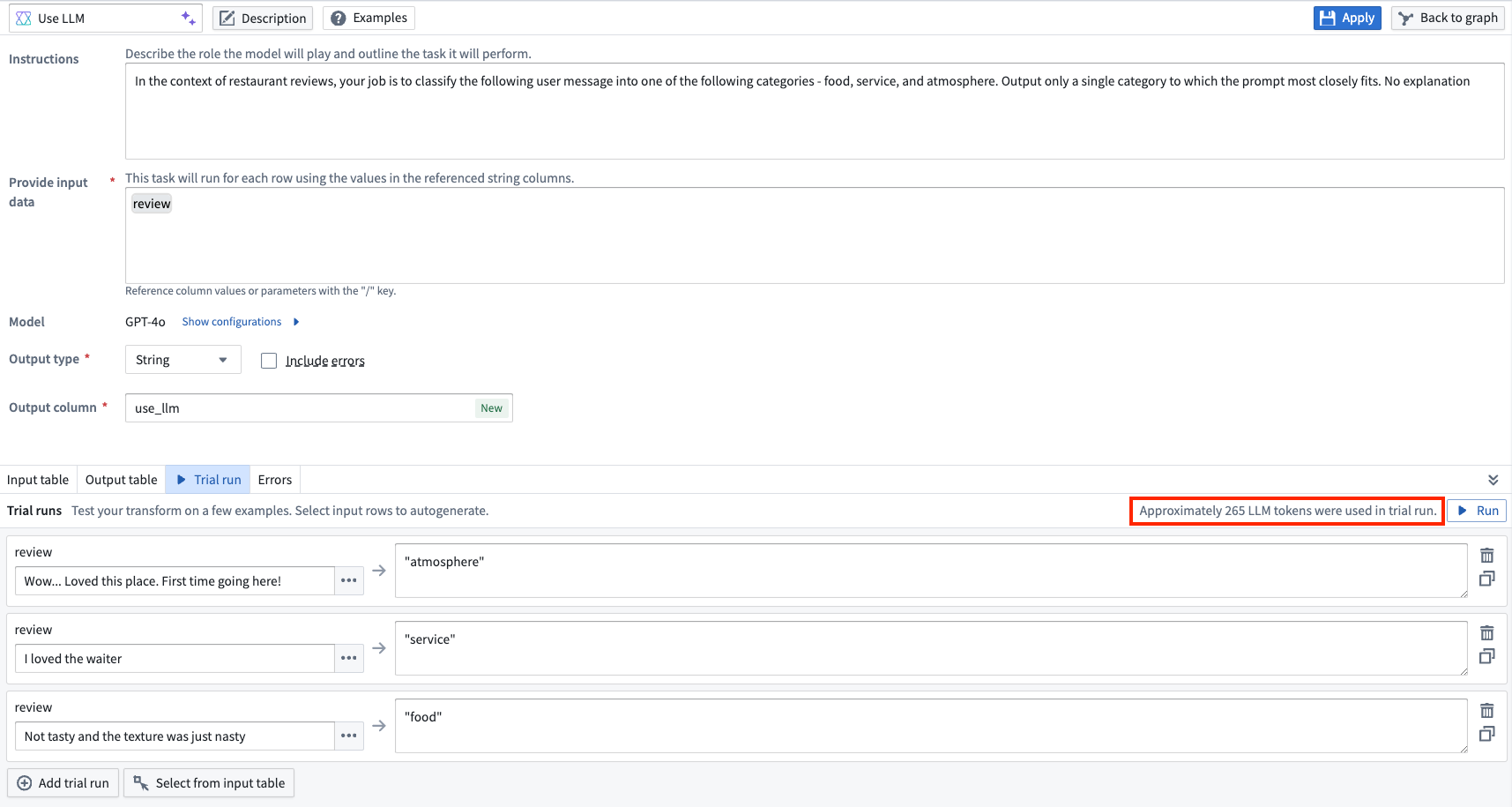
在试运行中显示的近似词元计数。
请注意,词元计数不提供给缓存结果,因为没有使用额外的词元。
了解有关 Pipeline Builder 预览和试运行的更多信息。
在 Ontology Manager 中引入可自定义的默认位置
发布日期:2024-06-25
Ontology Manager 现在使您更容易恢复工作,或在启动时导航到对您最重要的 Object 类型。
定制您的默认位置体验
新的 Discover 页面可以自定义以分组显示关键关注的 Object 类型,使您可以快速访问您的收藏和最近查看的 Object 类型。
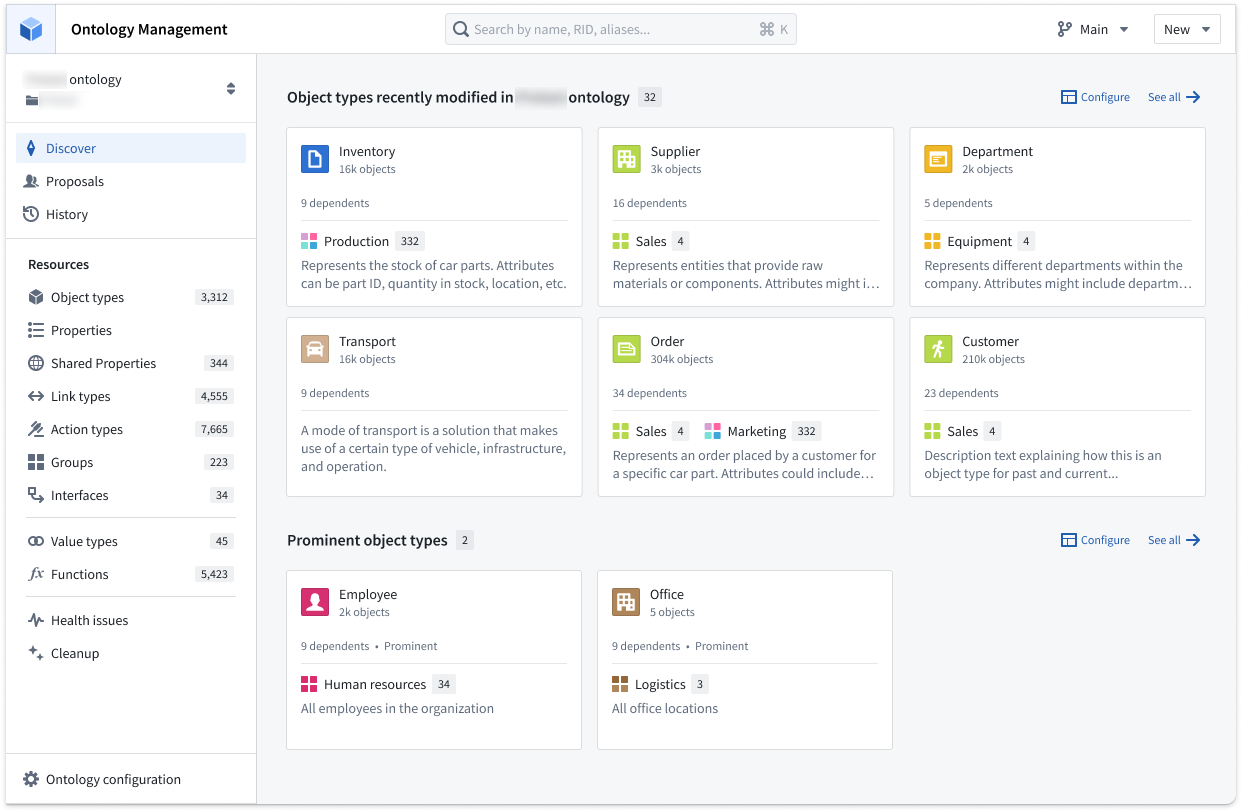
从 Discover 查看您最近查看的 Object 类型、收藏的 Object 类型或收藏的组。
根据您的喜好自定义部分
选择可用的部分,并通过 Configure 选项在您的可自定义主页上对它们进行排序。使用 Add section 选项从收藏组、Object 类型或最近查看中选择,或选择特定类型组。
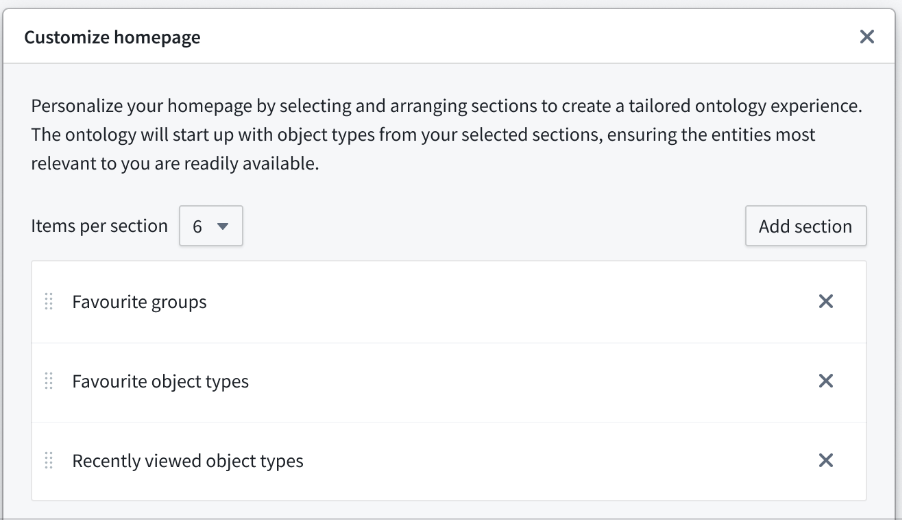
使用 Customize homepage 窗口添加部分并对其进行排名。
为帮助减少 Ontology 加载时间并让您快速恢复工作流程,您选择的部分中的 Object 类型将首先加载。
一目了然的 Object 类型
Discover 页面包括一个新的 Object 类型紧凑预览,帮助您更好地理解资源的使用方式。此视图针对可读性进行了优化,通过显示 Object 计数、依赖者数量、可见性和组成员资格。
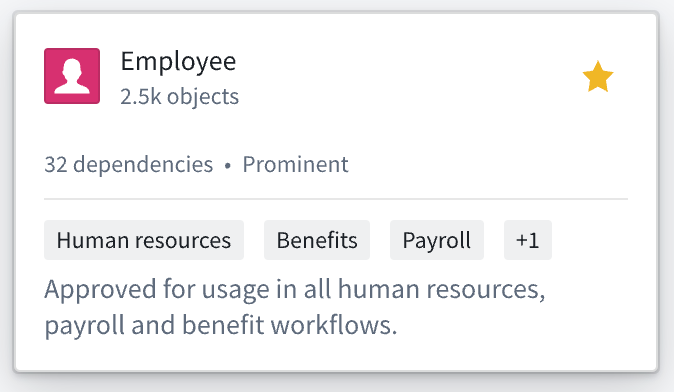
Employee Object 类型的紧凑预览。
Foundry Connector 2.0 for SAP Applications v2.31.0 (SP31) 现已推出
发布日期:2024-06-20
用于连接 Foundry 到 SAP 系统的 Foundry Connector 2.0 for SAP Applications 附加组件 的版本 2.31.0 (SP31) 现已可以从 Palantir 平台下载。
此最新版本具有错误修复和小改进,包括:
- 提高了 SAP Landscape Transformation Replication Server (SLT) 元数据检索的性能。
- 扩展了在字符上拆分
STXL行格式的功能。 - 增强了利用 CDPOS 的增量同步增量解决方案。
我们建议与您组织的 SAP 基础团队共享此通知。
有关下载最新附加组件版本的更多信息,请参阅文档中的 下载 Palantir Foundry Connector 2.0 for SAP Applications 附加组件。
介绍用于 Ontology SDK 的 Build with AIP
发布日期:2024-06-20
一个新的 Build with AIP 包现已可用于 Ontology 软件开发工具包 (OSDK)。Ontology SDK 允许您直接从开发环境访问 Ontology 的全部功能,并将 Palantir 视为开发自定义应用程序的后端。使用 Build with AIP 包,您可以按照平台内的教程在开发者控制台中创建您自己的 "To Do" 应用程序,该应用程序自定义为您组织的 Ontology 资源,允许您连接 Object 类型、操作类型、链接等具体到您关心的应用案例。使用 Build with AIP 包为构建者提供了从 Ontology 无缝读取和写入的能力,减少了在其他 Foundry 应用程序中导航以更新或加载数据的需求。
这个全面的平台内指南将教您从在 React 或 Jupyter® 中设置开发环境,到部署最终产品的所有内容。例如,您可以构建一个由数据和 Ontology 操作类型支持的 React 应用程序,或使用 Jupyter® 对您独特的 Ontology 数据进行分析。
要在 Ontology SDK 中开始使用 Build with AIP 包,首先在您的平台应用程序中搜索 Build with AIP 门户。然后搜索 "OSDK" 以找到 Getting Started with Ontology SDK (OSDK) 包。选择安装它,然后指定一个保存位置。
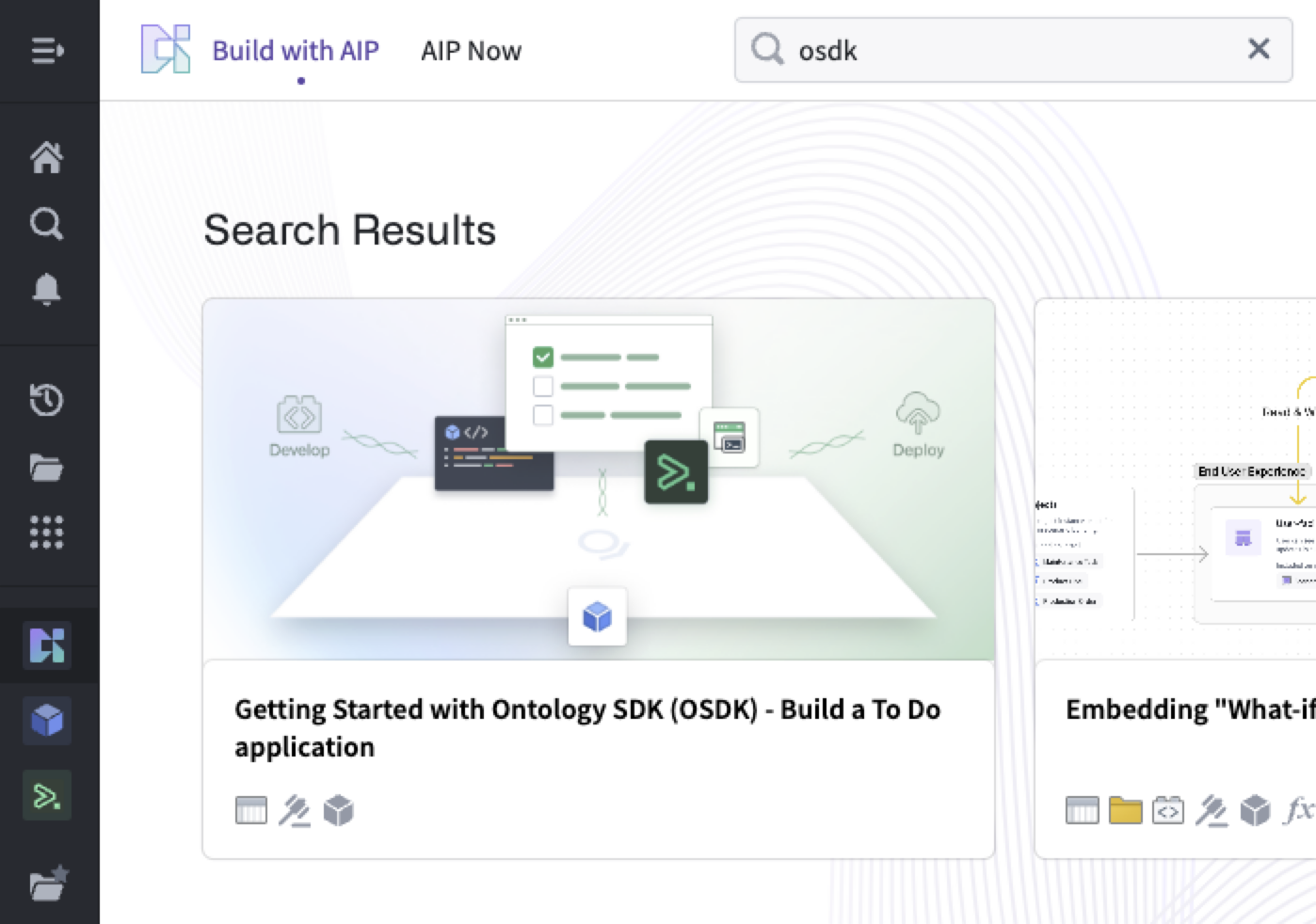
在 Build with AIP 中搜索 "OSDK"。
安装完成后,选择 Open Example 以遵循指南。
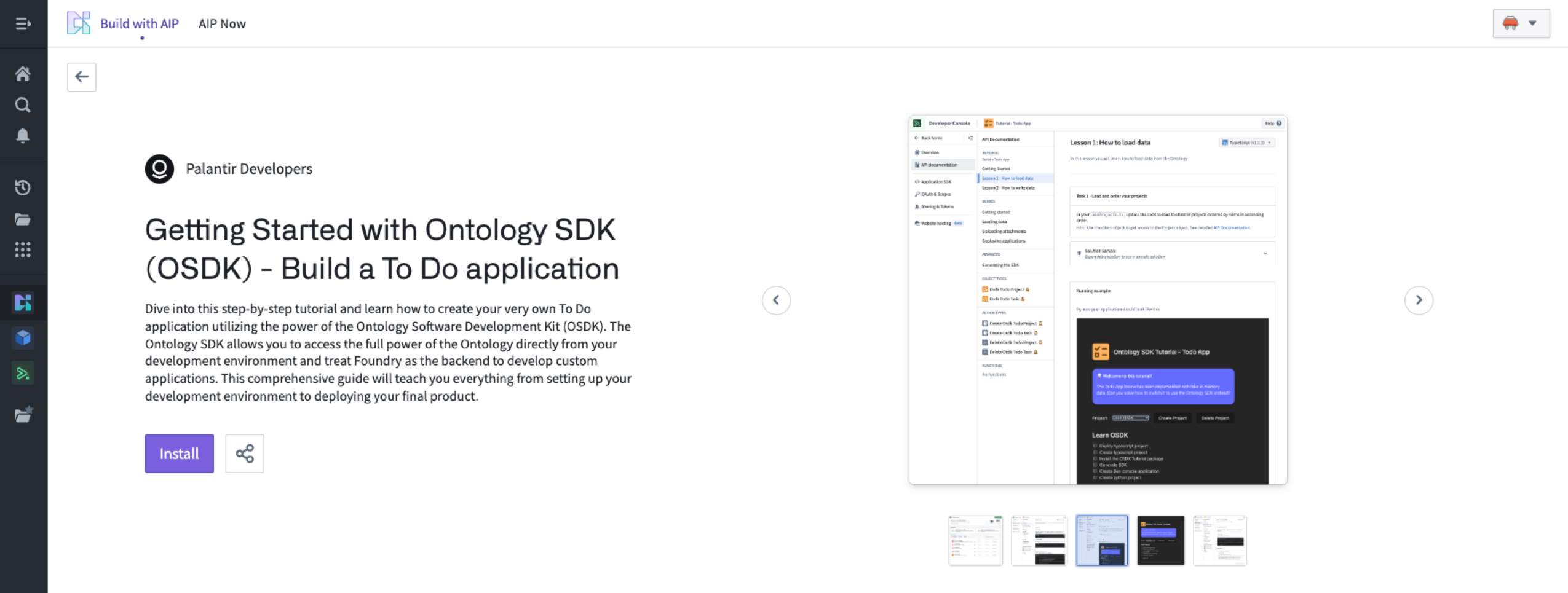
安装示例待办事项应用程序。
您尝试过这个功能吗?
在 我们的开发者论坛 分享您的想法。
开发路线图上的下一个是什么?
我们正在努力发布更多的 Build with AIP 包,包括演示如何使用 LLMs 和利用 AIP Logic 从您的 Ontology SDK 应用程序的包。
Jupyter®、JupyterLab® 和 Jupyter® 徽标是 NumFOCUS 的商标或注册商标。
所有引用的第三方商标(包括徽标和图标)仍然是其各自所有者的财产。不暗示任何关联或认可。
AIP Assist 现在可以将用户引导到 Palantir 开发者社区论坛
发布日期:2024-06-20
从 7 月 7 日这一周开始,当无法提供合适答案时,AIP Assist 将开始将用户查询重定向到 Community.palantir.com,我们的 Palantir 开发者社区。
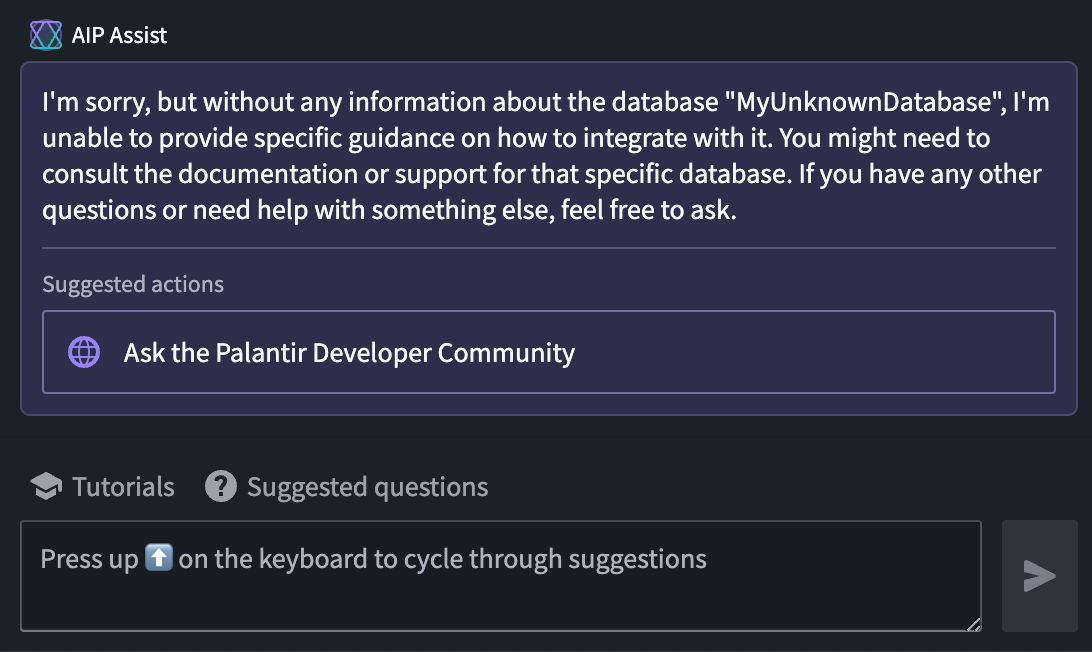
用户交互示例,建议向 Palantir 开发者社区提问。
为提供更多的用户体验控制,注册管理员可以通过导航到 Control Panel > AIP Assist > Suggested actions 来禁用此功能,从今天开始。
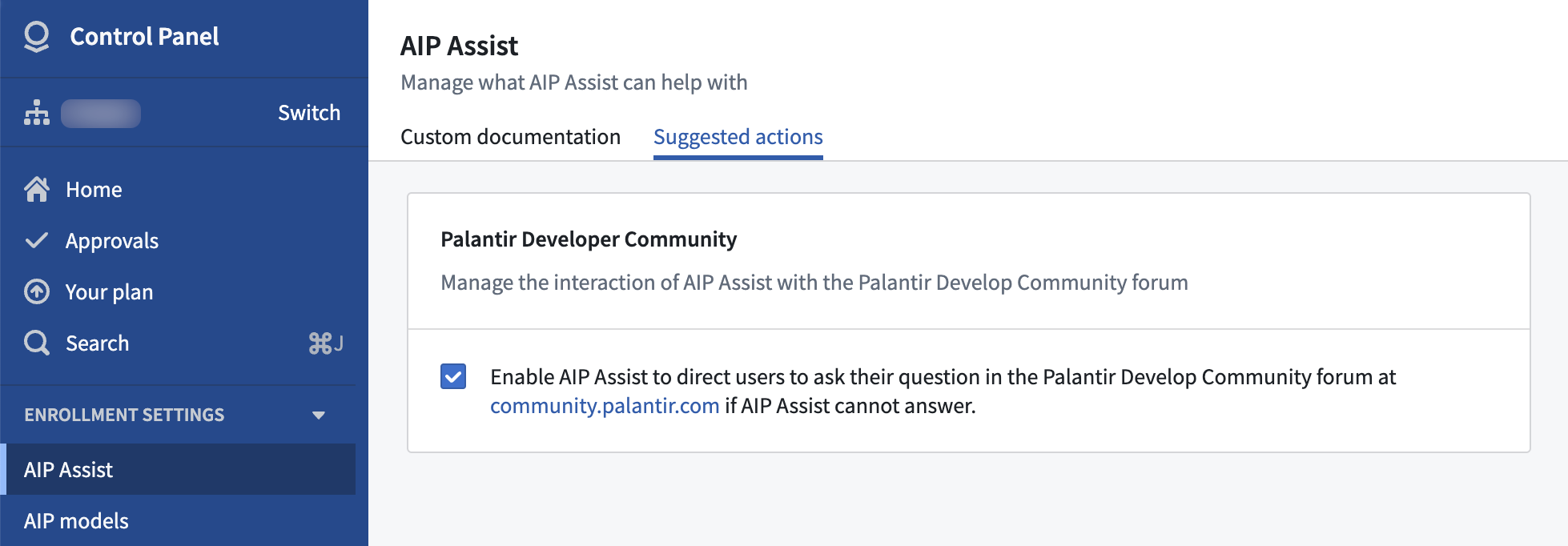
在 AIP Assist 中启用或禁用重定向到 community.palantir.com。
了解有关在 AIP Assist 文档中启用和禁用该功能的信息。
数据连接中现有超过150个新数据源
发布日期:2024-06-20
数据连接应用程序中现有的数据源连接现在包括超过 150 种新支持的数据源类型。这些新数据源允许组织使用 Palantir 提供的 JDBC 驱动程序访问更多位置的数据。新数据源类型包括 DynamoDB、Dataverse、CosmosDB、LDAP 等许多其他数据源。
更新的数据连接默认位置页面显示新连接器。
这些新数据源已在 Palantir 的开发生命周期的实验阶段发布,并标记为此类。每个数据源将独立遵循开发生命周期的各个阶段,因为使用和支持不断扩大。
具有行内文档的示例源配置。
了解有关使用 Palantir 提供的驱动程序的连接,并在我们的文档中探索新可用数据源的列表。
所有引用的第三方商标(包括徽标和图标)仍然是其各自所有者的财产。不暗示任何关联或认可。
Pipeline Builder 中更快的预览
发布日期:2024-06-17
由于缓存增强,Pipeline Builder 预览现在显著加快。内部测试显示计算时间从 40 秒减少到 1 秒,加快了资源密集型预览 40 倍。此功能现已在所有注册中普遍可用。
由缓存改进推动的更快预览
缓存改进现在允许 Pipeline Builder 中的节点使用已预览的上游节点的缓存或"存储"结果。这使得下游节点可以跳过重新计算并快速显示您的数据预览。
Pipeline Builder 的改进缓存功能包括:
- 减少冗余计算: Pipeline Builder 中的预览现在仅在预览缓存节点的下游时计算额外的节点。
- 高效缓存: 计算昂贵的节点(如合并和
use LLM)现在主动缓存,使下游节点避免重复和耗时的计算。
用户将受益于快速的预览和减少的处理成本,节省时间和资源,尤其是在昂贵节点的下游工作时。闪电图标将出现在使用缓存上游预览结果的预览上,如下所示:

改进的节点缓存
在此更改之前,如果您在没有任何逻辑更改的情况下预览一个节点两次,它会缓存第一次预览的结果并在第二次预览中重用它们。如果您然后预览一个下游节点,它将无法访问其他缓存节点结果。上游节点需要从头开始重新计算。
现在,Pipeline Builder 中的所有节点预览都可以利用缓存结果,因此只需计算额外的下游节点。
以下示例数据集:

如果您预览 C,节点 Dataset → A → B → C 被计算。在此更改之前,如果您随后预览 D:
- 节点
Dataset → A → B → C被重新计算,外加D。
在此更改之后,如果您在 C 之后预览 D:
- 仅计算节点
C → D,因为节点D现在可以使用节点C的缓存结果。
请注意,所有节点预览最多计算 500 行。不会从此功能中受益的操作包括更改行计数的操作、合并、聚合或逻辑更改。
了解有关 Pipeline Builder 预览的更多信息。
现在支持 Llama 3 的 70B Instruct 和 8B Instruct LLMs
发布日期:2024-06-17
Llama 3 的 70B Instruct 和 8B Instruct LLMs 现在普遍可用,并且可以在所有商业注册中启用。这些来自 Meta 的新旗舰模型的性能与行业中的其他顶级模型相当。如果您的注册与 Palantir 的协议不涵盖这些模型的使用,注册管理员必须首先通过 AIP 设置控制面板扩展接受附加合同附录,才能启用这些模型。
该模型应适用于所有 AIP 功能,如 Functions、Transforms、Logic 和 Pipeline Builder。
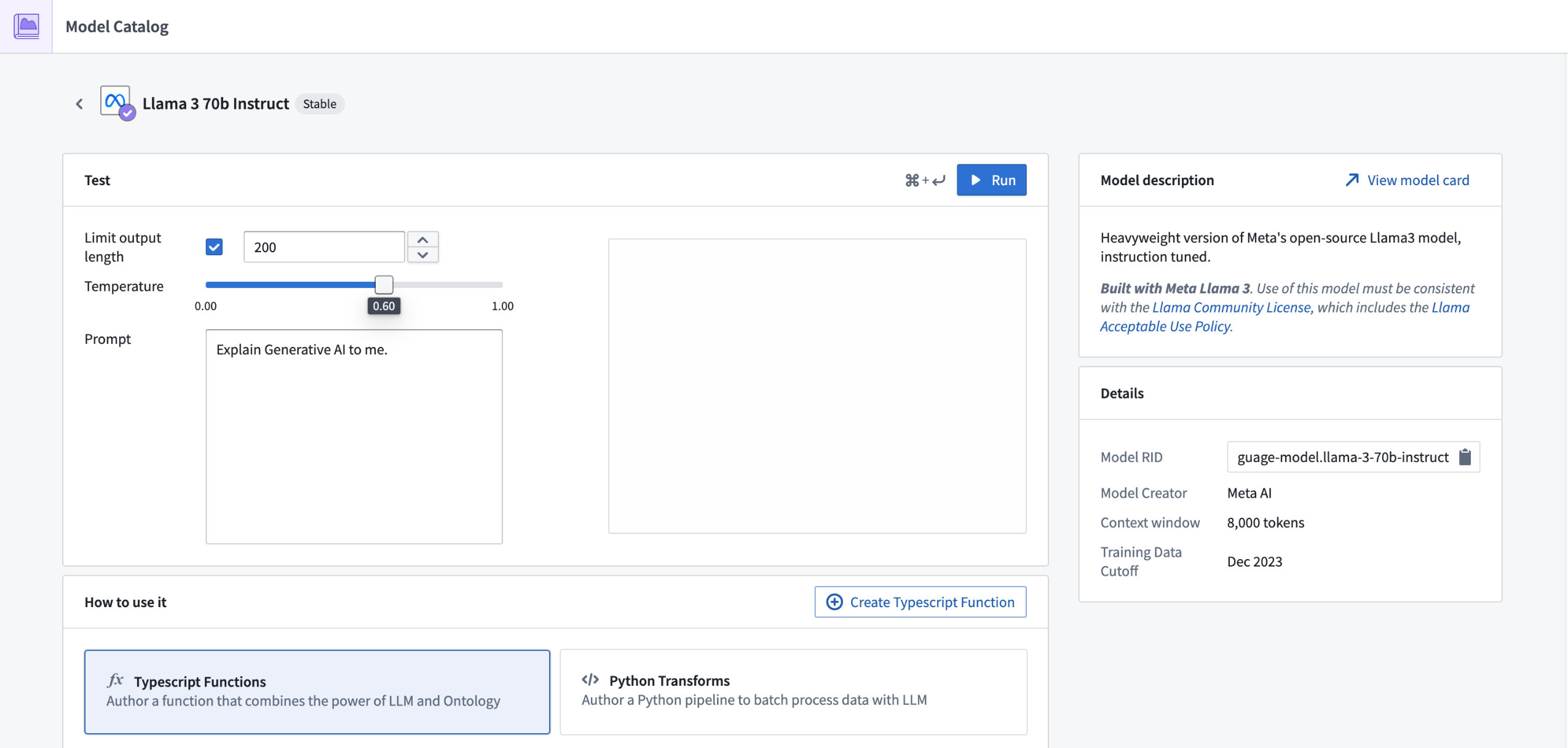
查看在 Palantir 中支持的 LLMs 列表。
现在支持 GPT-4o LLM
发布日期:2024-06-17
通过 Azure OpenAI 的 GPT-4o 现已普遍可用于所有不受地理限制的注册,或地理限制在美国或欧盟的注册。
要使用 GPT-4o,您需要通过 AIP 设置控制面板扩展启用 Azure OpenAI 模型。
GPT-4o 旨在成为 OpenAI 提供的新旗舰模型。建议使用 GPT-4 的现有工作流程使用 GPT-4o,因为它比 Azure OpenAI 提供的现有模型更便宜、更快,容量更大,并支持多模态输入,如图像和文本。
支持区域的扩展正在开发中。
通过 AWS Bedrock 现在支持 Claude 3 Sonnet LLM
发布日期:2024-06-17
通过 AWS Bedrock 的 Claude 3 Sonnet 现已普遍可用于所有非地理限制的注册,以及在美国、欧盟和澳大利亚的地理限制注册。这个来自 Anthropic 的新旗舰模型的性能与行业内的其他顶级模型相当,并支持多模态工作流程,包括视觉。如果您的注册协议不涵盖 Claude 3 Sonnet 的使用,注册管理员必须首先通过 AIP 设置控制面板扩展接受附加合同附录,才能启用该 LLM。
该模型应适用于所有 AIP 功能,如 Functions、Transforms、Logic 和 Pipeline Builder。
对其他地区地理限制注册的支持正在积极开发中。
为 Pipeline Builder、Workshop 和其他应用引入 Python 函数 [Beta]
发布日期:2024-06-13
Python 函数 现在支持在 Pipeline Builder、Workshop 和其他基于 Ontology 的应用程序中使用。Python 是一种熟悉的、易于学习的和有良好文档的语言 ↗,拥有从数据科学到图像处理的一系列库,现在您可以在 Palantir 平台中加以利用。
由于 Palantir 平台中的用户定义 Python 函数有意在应用程序中重复使用,您可以轻松地在 Pipeline Builder 中预计算值,或在用户添加输入时在 Workshop 模块中实时计算它们。同样的函数也可以在其他基于 Ontology 的应用程序中使用,以增强组织的决策过程。
在平台中使用用户定义的 Python 函数可以获得以下好处:
-
利用外部库: Python 拥有大量可以使开发更简单、更快速和更高性能的库。
-
快速迭代: 在开发时在代码库中预览您的代码以监控您的结果。
在 Pipeline Builder 中使用 Python 函数
Pipeline Builder 中的 Python 函数为您的管道提供效率和灵活性:
-
轻松发布: 当您对更改满意时,只需标记并发布您的代码即可在 Pipeline Builder 中使用。
-
提高执行时间: 通过将批处理大小设置在 100 到 1000 之间,指定要并行处理的行数来减少构建时间。
通过在图的右上角选择 Reusables 将自定义函数添加到您的 Pipeline Builder 管道中。然后,选择 User-defined functions > + Import UDF。在这里,您可以选择要添加到管道中的 Python 函数。您的函数将接收一行,使用您的逻辑变换它,并为所有批处理和流处理管道输出一行。
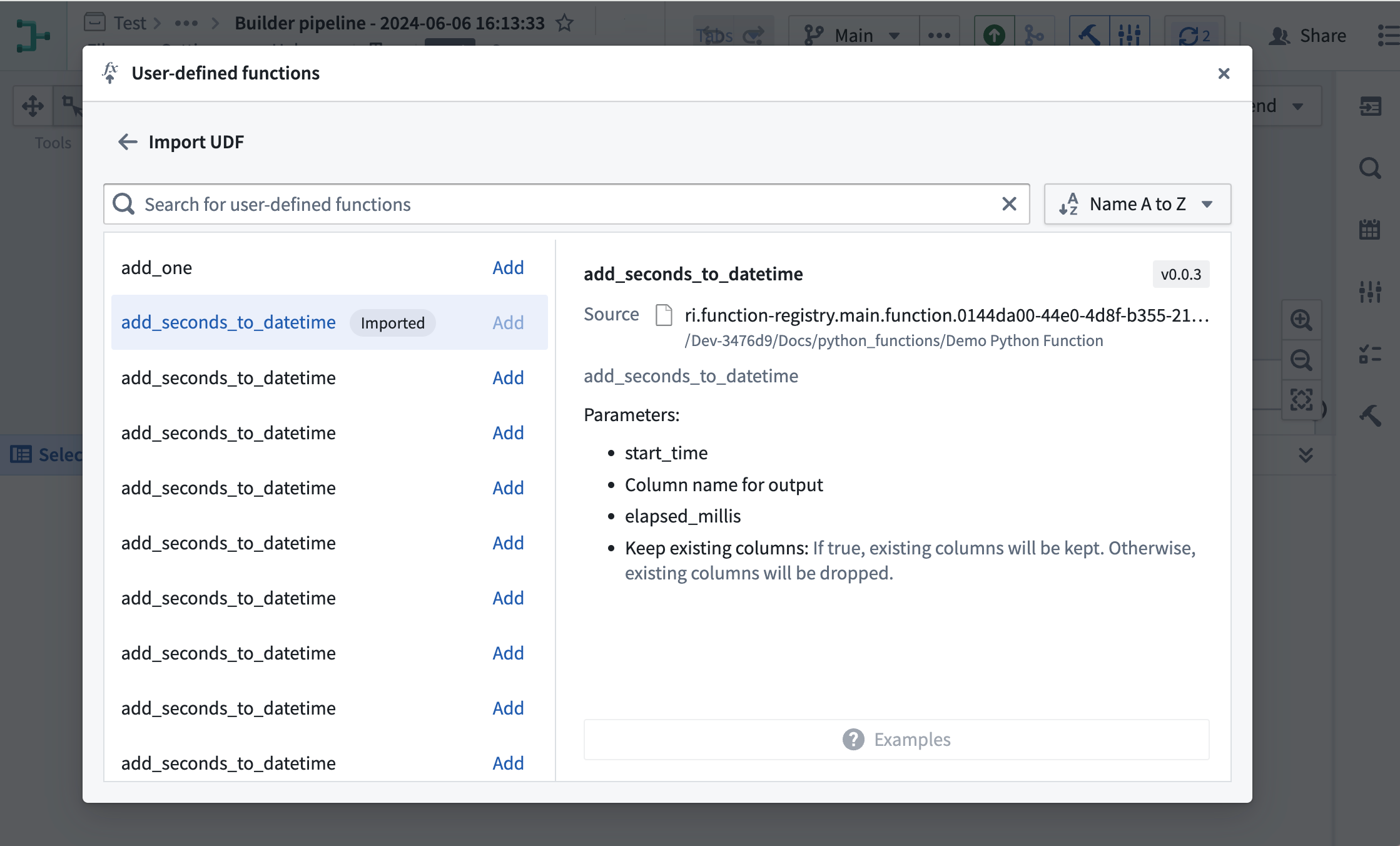
将 Python 函数导入 Pipeline Builder。
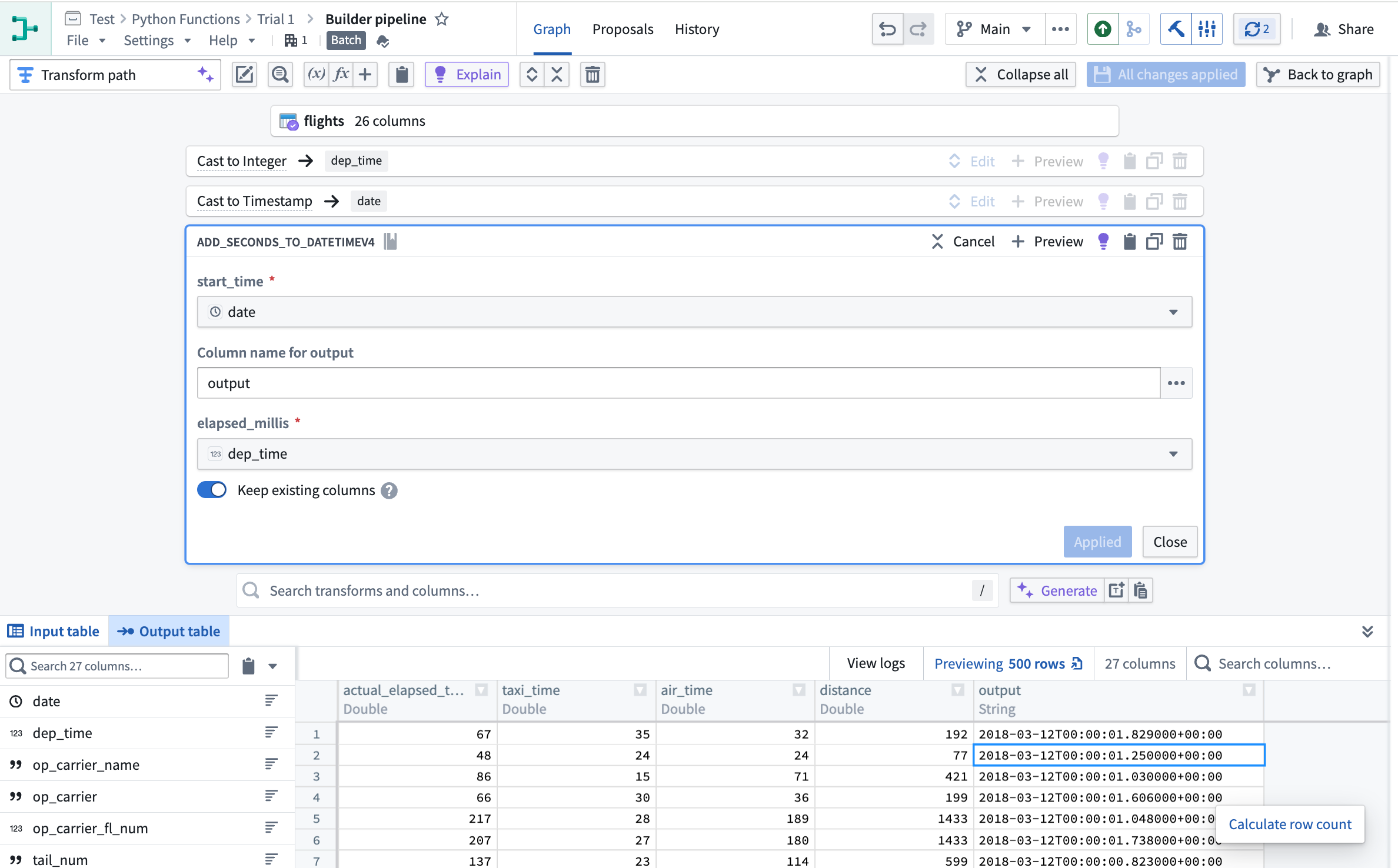
将 Python 函数添加到 Pipeline Builder 管道中。
在 Workshop 和基于 Ontology 的应用程序中使用 Python 函数
在 Workshop 中,您的函数将被"部署",允许其动态适应传入请求的数量。在高使用率期间,您的部署函数将动态扩展以支持新的用户输入。
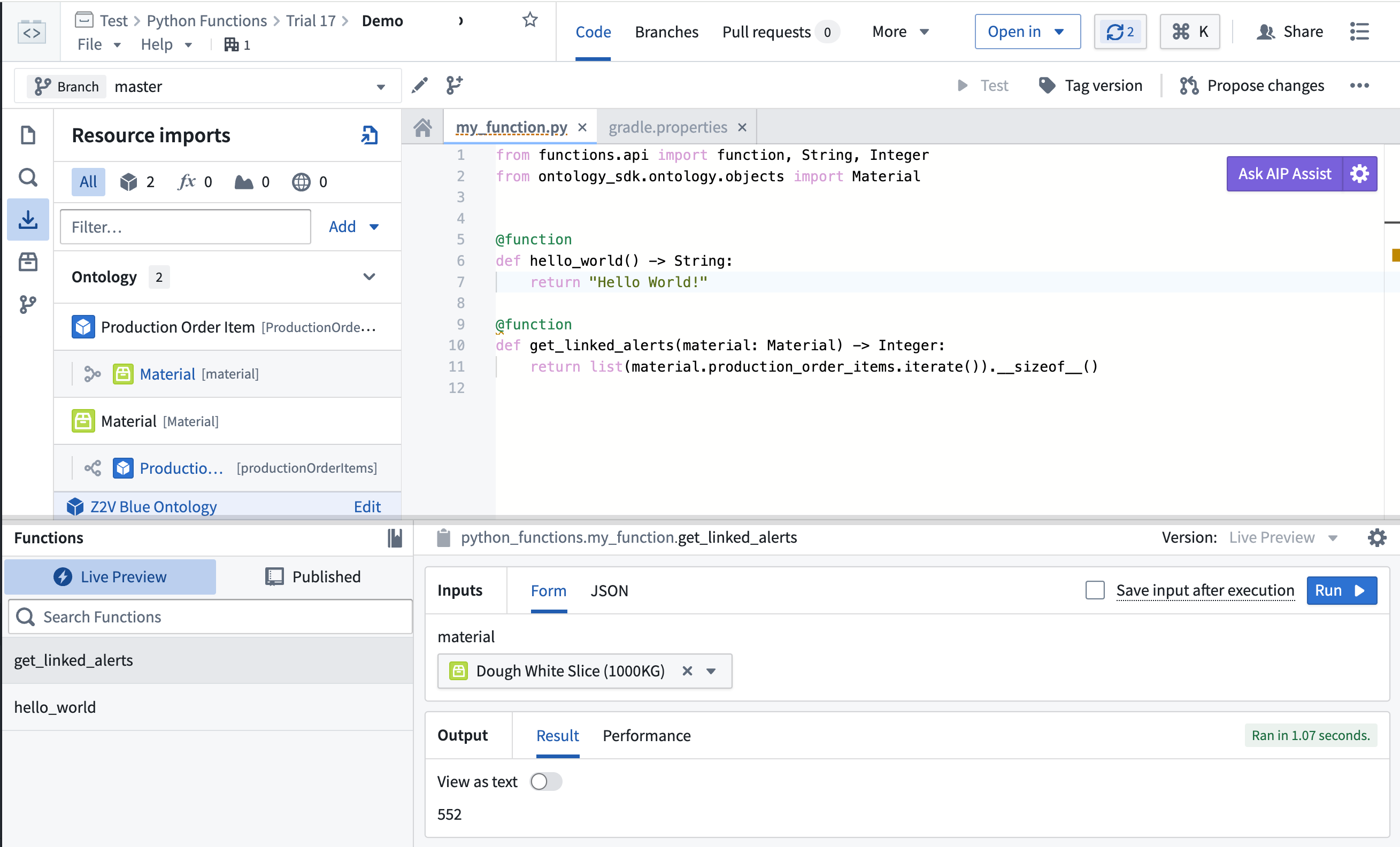
在代码库中预览您的函数。
在 Workshop 模块中部署的函数。
通过我们的文档了解更多关于 Python 函数的信息,并编写您的第一个用户定义 Python 函数。
开发路线图上的下一个是什么?
-
更便宜、更快的后端: 我们正在积极致力于提高 Workshop 和其他应用程序中使用的 Python 函数的后端性能,以匹配 TypeScript 函数的高水平性能。
-
弥合 TypeScript 和 Python 函数之间的差距: 我们继续努力为 Python 函数提供与 TypeScript 函数相同级别的支持。目前,我们的最高优先级是通过 Python 函数提供对 Ontology 编辑的支持。
-
市场兼容性: Python 函数将很快在 市场 中可用,方便您与其他用户轻松分享您的函数。
代码库现在支持 Python 3.11
发布日期:2024-06-10
代码库 现在支持 Python 3.11 ↗ 用于所有注册。根据 Python 文档 ↗,Python 3.11 提供了显著的性能增强,如 "比 Python 3.10 快 10-60%"。
要访问这些优势,您必须升级您的代码库。我们强烈建议保持您的代码库最新,以利用最新的性能改进和关键的安全补丁。
Python 3.11 支持提升性能、TOML 解析和增强的类型支持
用户现在可以在 Python 环境中使用此版本,无论是在预览期间还是在 Python 变换运行时。
Python 3.11 的亮点包括:
- 显著的性能提升
- 支持解析 TOML ↗
- 改进的异常信息和类型支持
要使用 Python 3.11,用户必须升级代码库,并可以将 Python 环境 设置为使用 Python 的推荐版本或明确选择 Python 3.11 版本。
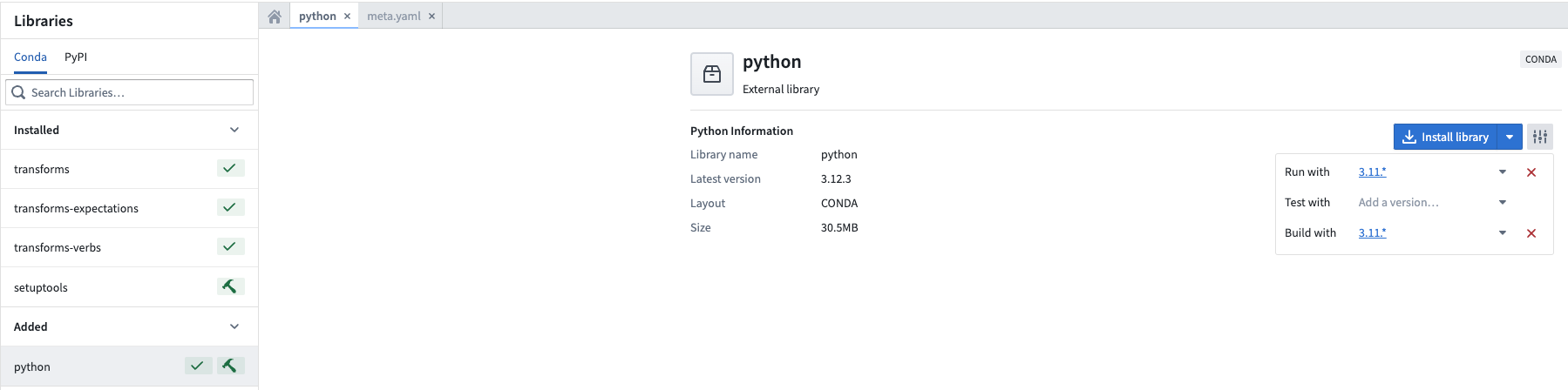
将 Python 环境设置为所需版本。
在代码库中引入用于 Python 包管理的 Hawk
发布日期:2024-06-10
我们很高兴地宣布 Hawk,一个用于 Python 环境的新包管理器。Hawk 将于 2024 年 6 月中旬在 Foundry 注册的代码库中可用。它取代了在 2023 年 9 月经历重大中断更改的 Mamba ↗,成为代码库中默认的 Python 包管理器。
Hawk 提供增强的性能和可维护性,确保更高效和可靠的 Python 环境管理体验。Hawk 的初步测试显示,与 Mamba 相比,在解析和安装新包时,检查执行时间提升了约 25%。此外,Hawk 建立在积极维护的库之上,确保核心基础设施保持最新和安全。
新的 Python 代码库将自动开始使用 Hawk。对于现有代码库,您可以通过选择 ... 然后选择 Upgrade 来升级代码库。
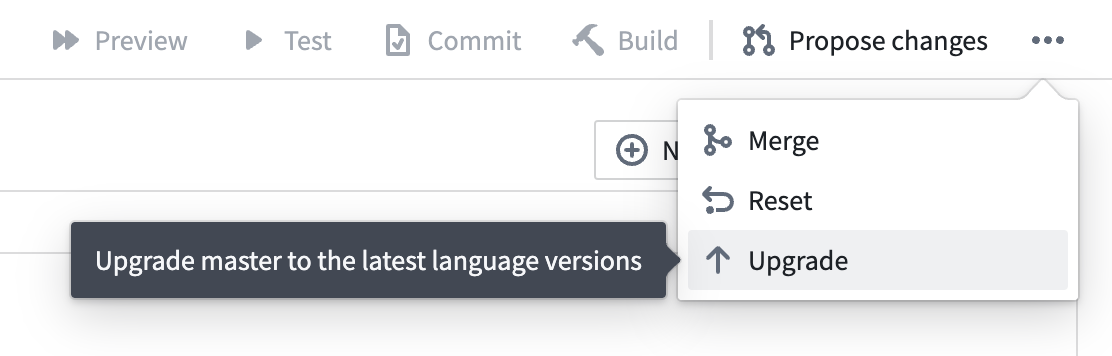
将您的 Python 代码库升级到新的 Hawk 环境管理系统。
在使用 Hawk 的 Python 代码库中,您可以在 Checks 选项卡中查看日志行,指示某些任务由 Hawk 而不是 Mamba 执行。例如,您可以查看日志行 Executing task 'runVersions' with 'HAWK'。
Hawk 建立在开源库 Rattler ↗ 之上。
在 Slate 中引入 OSDK [Beta]
发布日期:2024-06-05
Ontology 软件开发工具包 (OSDK) 允许您直接从开发环境访问 Ontology 的全部功能。在所有注册中,OSDK 现在在 Slate 中可用,您可以通过在 Slate 中编写函数来变换 Ontology 数据与 Ontology 进行交互。
使用 OSDK,Slate 和 Ontology 之间的集成更为紧密。例如,构建者可以从专用接口访问 Object 类型、链接类型和操作,其中 OSDK 包可以在 Ontology 更改时生成和更新。
通过构建能够轻松遍历 Object 类型的应用程序,并使用操作为您组织最重要的工作流程提供丰富和定制的应用程序,全面与代码中的 Ontology 丰富性互动。
Slate 允许在 Platform 选项卡中使用 Foundry Functions 以及使用非 Ontology 数据源,为应用程序构建者提供高度灵活的环境。
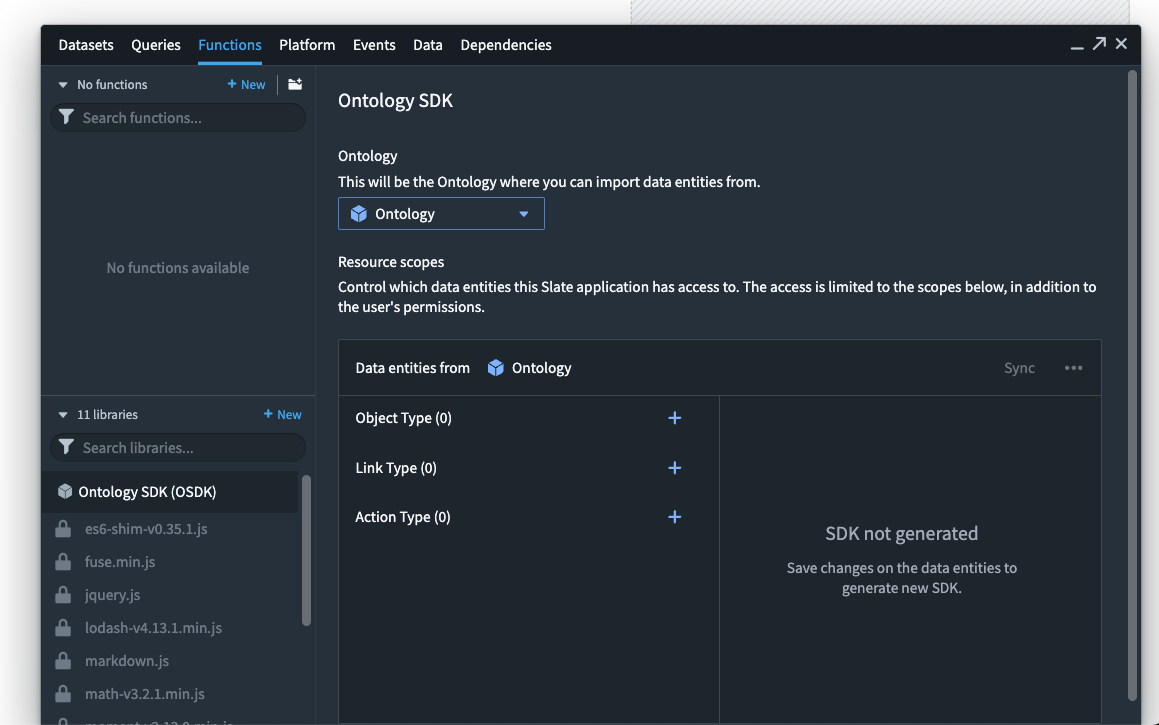
应用程序构建者现在可以在 Slate 中使用 OSDK 功能来启用与 Ontology 交互的产品。
了解有关在 Slate 中使用 Ontology SDK (OSDK) 的更多信息。
其他亮点
管理 | 控制面板
空间现在在控制面板中管理 | 为了整合和简化 Foundry 中的管理设置,空间(以前称为命名空间)现在在控制面板下的注册设置中进行管理。
虽然 Spaces 选项卡对每个人都可见,但管理单个空间所需的权限保持不变。要进行配置,必须满足访问要求并_获得相关空间的角色_。有关更多详细信息,请查看我们的空间文档。
分析 | 笔记本
从笔记本模板创建增强的文档 | 笔记本应用程序现在包括一项增强功能,允许用户从最新版本的已发布笔记本模板中立即生成文档。此新功能可以方便地从应用程序的主页或直接通过应用程序标题中的文件菜单访问。
分析 | Quiver
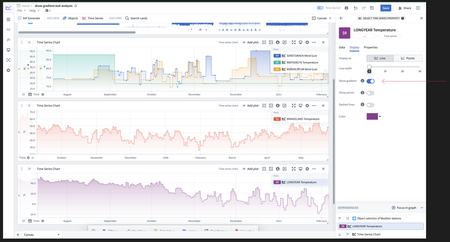
用于时间序列洞察的精细渐变显示 | Quiver 现在具有一种渐变显示选项,用于配置时间序列图表的颜色填充。这提高了当图形在同一图表中重叠时的可读性,并帮助识别随时间的相对变化幅度。
应用构建 | Slate
Slate 中增强的侧边栏体验 | Slate 中重新设计的侧边栏引入了一个更具凝聚力的用户界面。此更新将应用程序设计、数据管理、逻辑操作和调试的基本工具集中在一个可访问的面板中,增强了用户体验,并为新用户提供了更顺畅的入门。
Slate 文档版本历史中的增强 JSON 导出 | 版本对话框现在支持导出任何选定版本的 Slate 文档的 JSON。此增强功能确保编辑可以轻松访问和导出任何现有版本的文档 JSON。
应用构建 | Workshop
新的排序选项 | Object 列表微件现在支持多属性排序以及基于函数支持的属性进行排序。
Workshop 中虚拟化的 Object 列表 | Object 列表微件现在利用虚拟化技术显著提升性能,尤其是在包含大量元素的列表中。
Workshop 中增强的微件配置 | Workshop 操作微件现在支持带有支持同时创建多行新数据或上传行电子表格以填充输入表的配置的表格数据输入。此功能解锁需要高容量手动数据输入的工作流程。
增强的分支到主模块比较 | 变更日志面板现在支持在分支内工作时选择最新的主版本进行比较,简化了模块差异化过程。此更新对参与分支工作流程的用户尤其有利。
数据集成 | 数据连接
数据连接中的增强 Webhook 访问 | 用户现在可以直接查看和管理与源相关联的 webhook,方法是导航到该源。先前可用的列出所有 webhook 的页面已被弃用。
Ontology | Ontology管理
在Ontology管理器上传中的优化主键处理 | 针对操作的表格输入模式的增强功能现在确保在文件上传期间对主键的处理更加直观。有效的主键会自动与其各自的Object相关联,用于Object引用表单参数。无法解析的主键将被立即突出显示,以便在上传界面中直接编辑。此更新简化了通过CSV上传填充表格操作时的数据校正过程。
Ontology | Vertex
在Vertex图层中优化的图标个性化 | Vertex为图层引入了优化的图标个性化功能,使用户能够根据Object属性定制图标或从扩展的静态图标选择中进行选择。此改进为图表表示中的节点可视化提供了定制化方法,以满足不同工作流的多样化需求。
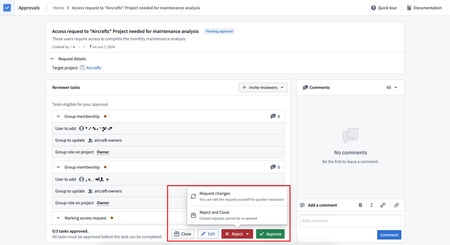
安全性 | 审批
改进的审批操作和状态 | 审批中的访问请求已得到简化;可用操作现在显示在请求级别,而不是任务级别。审批人现在可以对多个任务应用操作。这改善了所有可用操作的发现性和解释性,并简化了请求处理。新的访问请求状态如待审批、已关闭、需要操作和已完成已被引入,以更好地传达请求的状态。
改进的审批收件箱搜索 | 现在,审批收件箱允许用户根据包含的项目、用户或组来筛选请求,除了现有的筛选器。这些新筛选器仅适用于访问请求,通过使访问请求审核更加高效,显著改善了用户体验。之前显示在表头的筛选器现在位于左侧边栏。