注意:以下翻译的准确性尚未经过验证。这是使用 AIP ↗ 从原始英文文本进行的机器翻译。
旧版 REST API 插件 (magritte-rest-v2)
此处记录的使用自定义 magritte-rest-v2 源类型的旧版 REST API 选项仅供历史参考。此功能不再进行主动开发,除非涉及本地系统的极少情况,否则不应使用。
- 对于同步和以{filetype}格式导出到互联网可访问的源,请使用外部变换。
- 对于包括互联网可访问和本地端点的 webhooks,请使用REST API 源。
- 如果没有可用的源连接器以同步和以{filetype}格式导出到本地系统,可以继续使用旧版 REST API 插件。
magritte-rest-v2 自定义源类型允许从一系列 API 调用中与外部系统进行交互,主要应用于通过代理运行时连接到本地 REST API。
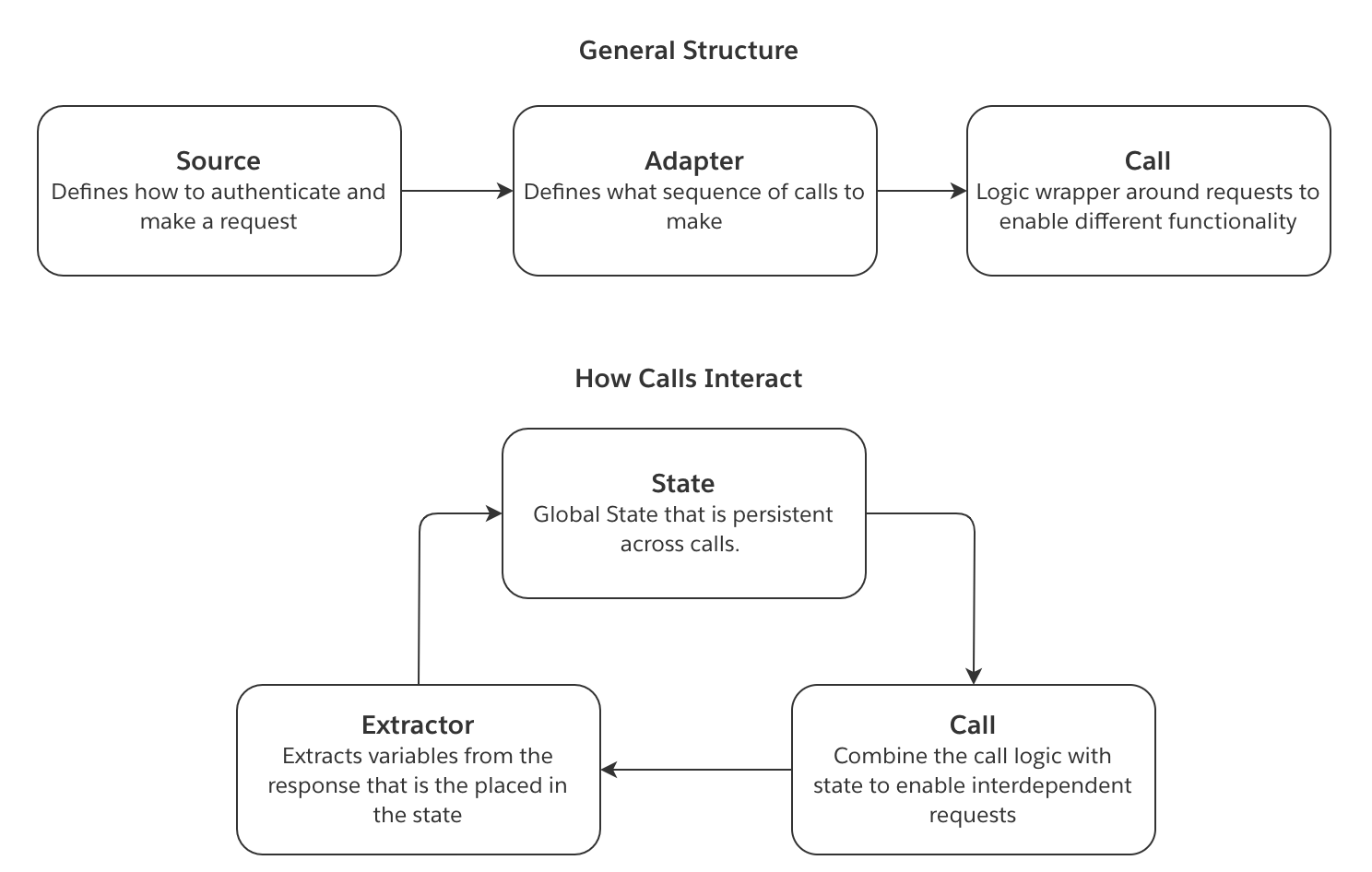
架构
以下概念说明了使用 magritte-rest-v2 源时的信息流动。
- 源定义如何建立连接。这包括请求应如何进行身份验证。
- 同步由一系列调用组成。每个调用定义应进行何种请求,并实现围绕该请求的任何所需逻辑。调用可以是简单的单个 GET 请求,也可以是复杂的请求循环用于分页。
- 提取器定义如何解析对身份验证调用和同步调用的响应。对于同步调用,它可以将响应中的字段保存到状态中。
- 生成的状态传递给下一个调用。此
状态中的变量可以注入到后续调用中。这允许相互依赖的请求。
下图说明了上述概念如何交互:
创建自定义 magritte-rest-v2 源
要创建 magritte-rest-v2 源,请从数据连接应用程序的源选项卡中选择新建源。然后,选择添加自定义源选项。magritte-rest-v2 插件主要通过 YAML 编辑器进行配置。
以下示例提供了不同身份验证类型配置所需的 YAML 代码片段:
本文档还提供了关于以下主题的额外指导:
身份验证
Headers
Copied!1 2 3 4 5 6 7type: magritte-rest-v2 sourceMap: my_api: type: magritte-rest headers: Authorization: 'Bearer {{token}}' # 使用Bearer令牌进行身份验证 url: "https://some-api.com/" # API的基础URL
以上代码是一个YAML配置文件片段,用于定义API的连接设置。type指定了API的版本类型,而sourceMap定义了具体的API连接参数。headers部分包含了用于身份验证的Bearer令牌,url定义了API的基础URL。
用户名和密码
也称为 Basic 认证。
Copied!1 2 3 4 5 6type: magritte-rest-v2 sourceMap: my_api: type: magritte-rest usernamePassword: '{{username}}:{{password}}' # 使用模板变量来插入用户名和密码 url: "https://some-api.com/" # API的基础URL地址
这段代码是在YAML中配置一个REST API的连接信息。type字段指定了使用的API类型。在sourceMap下,有一个名为my_api的API配置,其中usernamePassword使用模板变量来动态插入用户名和密码,url字段则是API的基础URL地址。
正文
Copied!1 2 3 4 5 6 7 8type: magritte-rest-v2 sourceMap: my_api: type: magritte-rest-auth-call-source url: "https://some-api.com/" # API的URL地址 requestMimeType: application/json # 请求的MIME类型为JSON body: '{"username": "{{username}}", "password": "{{password}}"}' # 请求体使用模板字符串,包含用户名和密码 authCalls: [] # 认证调用列表,目前为空
URL 参数
Copied!1 2 3 4 5 6 7 8 9type: magritte-rest-v2 sourceMap: my_api: type: magritte-rest-auth-call-source url: "https://some-api.com/" parameters: username: "{{username}}" # 使用模板语法从外部注入用户名 password: "{{password}}" # 使用模板语法从外部注入密码 authCalls: [] # 目前没有定义的认证调用
以上代码是一个配置文件片段,定义了一个类型为 magritte-rest-v2 的 REST API 资源。sourceMap 中的 my_api 是一个 API 调用源,使用了 magritte-rest-auth-call-source 类型。通过 URL 和参数指定了 API 的基本信息,其中用户名和密码是通过模板语法动态注入的。authCalls 当前为空,意味着没有额外的认证调用。
调用
以下配置可被用于在将URL编码的表单主体提交到/auth端点,以便在同步中使用返回的词元。如果您的端点具有表单类型,则应仅使用formBody;否则使用body。
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18type: magritte-rest-v2 sourceMap: my_api: type: magritte-rest-auth-call-source url: "https://some-api.com/" headers: Authorization: 'Bearer {%token%}' # 使用Bearer令牌进行认证 authCalls: - type: magritte-rest-call path: /auth method: POST formBody: username: '{{username}}' # 使用模板语法填充用户名 password: '{{password}}' # 使用模板语法填充密码 extractor: - type: magritte-rest-json-extractor assign: token: /token # 从JSON响应中提取令牌并赋值给token变量
此配置文件定义了一个REST API调用的认证流程。通过指定/auth路径和POST方法,发送用户名和密码以获取访问令牌,该令牌随后用于API请求的认证。
如果返回的词元经常在同步完成之前过期,请使用 authExpiration 参数指定在 authCalls 下的调用应重试的频率。将 authExpiration 的值设置为不超过 /auth 端点返回的词元的有效期。
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19type: magritte-rest-v2 sourceMap: my_api: type: magritte-rest-auth-call-source url: "https://some-api.com/" authExpiration: 30m # 认证有效期为30分钟 headers: Authorization: 'Bearer {%token%}' # 使用Bearer Token进行认证 authCalls: - type: magritte-rest-call path: /auth # 认证接口路径 method: POST # 使用POST方法进行请求 formBody: username: '{{username}}' # 用户名参数 password: '{{password}}' # 密码参数 extractor: - type: magritte-rest-json-extractor assign: token: /token # 从JSON响应中提取token并赋值
当您的API使用诸如订阅密钥等安全头以便成功登录时,您需要在authCalls下添加一个额外的头部部分。这个第二个头部部分专门用于认证调用,并且与第一个头部部分完全分开;所有其他API调用(除了认证调用)都使用第一个头部部分。如果这些头部部分配置不正确,可能会导致401认证失败。下面给出了一个示例。
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23type: magritte-rest-v2 sourceMap: my_api: type: magritte-rest-auth-call-source url: "https://some-api.com/" headers: X-service-identifier: SWN Authorization: 'Bearer {%token%}' # 使用令牌进行授权 Ocp-Apim-Subscription-Key: '{{subscriptionKey}}' # 订阅密钥 authCalls: - type: magritte-rest-call path: /auth # 授权路径 method: POST # HTTP方法为POST headers: X-service-identifier: SWN Ocp-Apim-Subscription-Key: '{{subscriptionKey}}' body: username: '{{username}}' # 用户名 password: '{{password}}' # 密码 extractor: - type: magritte-rest-json-extractor assign: token: /token # 从响应中提取令牌
这个YAML配置文件定义了一个REST API调用的结构,其中包含授权步骤。它使用了magritte-rest-v2类型来指定API的版本,并通过authCalls定义了一个用于获取授权令牌的调用路径。
调用另一个域
这使得可以在一个域上进行身份验证,以便在另一个域上使用词元:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22type: magritte-rest-v2 sourceMap: auth_api: type: magritte-rest url: "https://auth.api.com" # 认证API的URL data_api: type: magritte-rest-auth-call-source url: "https://data-api.com/" # 数据API的URL headers: Authorization: 'Bearer {%token%}' # 使用Bearer令牌进行认证 authCalls: - type: magritte-rest-call source: auth_api # 认证调用使用的来源 path: /auth # 认证API的路径 method: POST # 使用POST方法进行认证 formBody: username: '{{username}}' # 认证所需的用户名 password: '{{password}}' # 认证所需的密码 extractor: - type: magritte-rest-json-extractor assign: token: /token # 从响应中提取令牌并赋值给'token'变量
这段代码配置了一个使用REST API的认证和数据请求流程。首先,通过向auth_api发送用户名和密码获取认证令牌,然后使用该令牌访问data_api。
客户端证书
数据源支持提供用于身份验证的Java KeyStore (JKS)文件:
Copied!1 2 3 4 5 6 7type: magritte-rest-v2 sourceMap: my_api: type: magritte-rest url: "https://some-api.com/" # 接口的URL地址 keystorePath: "/my/keystore/keystore.jks" # 密钥库文件的路径 keystorePassword: "{{password}}" # 密钥库的密码(使用模板变量)
NTLM
以下 curl 命令:curl -v http://example.com/do.asmx --ntlm -u DOMAIN\\username:password 可以翻译为:
Copied!1 2 3 4 5 6type: magritte-rest-ntlm-source url: http://example.com user: "{{username}}" # 用户名 password: "{{password}}" # 密码 domain: DOMAIN (optional) # 域(可选) workstation: (optional) the name of your machine as given by $(hostname) # 工作站名(可选),由命令 $(hostname) 提供
代理
Copied!1 2 3 4 5 6type: magritte-rest-v2 sourceMap: my_api: type: magritte-rest url: http://example.com proxy: 'http://my-proxy:8888/' # 你也可以传递一个 IP 地址
这个 YAML 配置文件的作用是定义一个名为 my_api 的 REST API 源映射。它使用了 magritte-rest-v2 类型,其中 my_api 的具体类型是 magritte-rest。API 的基础 URL 是 http://example.com,并且配置了一个代理服务器,代理地址为 http://my-proxy:8888/。你可以选择使用一个 IP 地址来代替代理 URL。
您还可以在配置中传入代理凭证:
Copied!1 2 3 4 5 6 7 8 9type: magritte-rest-v2 sourceMap: my_api: type: magritte-rest url: http://example.com proxy: url: 'http://my-proxy:8888/' # 你也可以传递一个IP地址 username: 'my-proxy-username' # 代理服务器的用户名 password: 'my-proxy-password' # 代理服务器的密码
这段YAML配置用于设置一个REST API的代理,使用了magritte-rest-v2类型。在sourceMap中定义了API的基本信息和代理服务器的配置,包括代理服务器的URL、用户名和密码。
服务器证书问题
如果您看到类似 javax.net.ssl.SSLHandshakeException 的出错信息,您可能需要根据本指南将服务器的证书添加到代理的信任库中。
仅用于调试目的,您也可以禁用证书检查,这相当于运行带有不安全 -k 标志的 curl(curl -k https://some-domain):
Copied!1 2 3 4 5 6type: magritte-rest-v2 sourceMap: my_api: type: magritte-rest # 定义API类型 url: https://example.com # API的URL地址 insecure: true # 是否启用不安全的连接(例如,跳过SSL验证)
TLS版本
默认情况下,插件将仅通过现代TLS版本(TLSv1.2和TLSv1.3)进行连接。
要使用旧版本,请在配置中指定TLS版本:
Copied!1 2 3 4 5 6type: magritte-rest-v2 sourceMap: my_api: type: magritte-rest url: https://example.com # API的URL地址 tlsVersion: 'TLSv1.1' # 使用的TLS版本
此代码片段定义了一个名为 magritte-rest-v2 的类型,使用一个 sourceMap 映射来配置API连接,其中包括API的URL和TLS版本的信息。
支持的版本:TLSv1.3、TLSv1.2、TLSv1.1、TLSv1、SSLv3。
创建同步
要创建同步,请在 magritte-rest-v2 来源的顶部点击“创建同步”按钮。基本视图将引导您通过创建一个或多个调用来获取数据。高级视图将使您能够直接编辑 YAML 配置。您可以在页面右上角切换这些视图。
同步至少需要一个调用。在基本视图中,您可以通过点击“按顺序执行调用”标题下的“添加”按钮来创建新的调用。
然后您可以指定调用是否应通过选择“单次调用”来执行一次,或根据循环、时间范围、日期范围、列表或分页结果来多次执行。
每个调用都需要一个路径,该路径将在查询时附加到来源 URL。例如,如果来源的 URL 是 https://my-ap-source.com,使用路径 /api/v1/get-documents 将导致调用查询 https://my-ap-source.com/api/v1/get-documents。
本节提供了一系列解决常见场景的 YAML 配置:
本文档还提供了关于这些主题的其他指导:
常见场景
基于日期时间的 API
假设一个 API 为每个日期在 /daily_data?date=2020-01-01 提供 CSV 报告。在此示例中,我们希望在这些报告可用时获取它们。为此,我们可以安排一个每日同步,以记住已同步报告的最后日期,从而自动获取直到今天为止未同步日期的报告:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26type: rest-source-adapter2 outputFileType: csv incrementalStateVars: incremental_date_to_query: '2020-01-01' # 增量查询的初始日期 initialStateVars: yesterday: type: magritte-rest-datetime-expression offset: '-P1D' # 设置为前一天 timezone: UTC formatString: 'yyyy-MM-dd' # 日期格式 restCalls: - type: magritte-increasing-date-param-call checkConditionFirst: true # 首先检查条件 paramToIncrease: date_to_query # 需要递增的参数 increaseBy: P1D # 递增一天 initValue: '{%incremental_date_to_query%}' # 初始化值 stopValue: '{%yesterday%}' # 停止值 format: 'yyyy-MM-dd' # 日期格式 method: GET # HTTP 请求方法 path: '/daily_data' # API 路径 parameters: date: '{%date_to_query%}' # 查询参数中的日期 extractor: - type: magritte-rest-string-extractor fromStateVar: 'date_to_query' var: 'incremental_date_to_query' # 更新增量查询日期
此 YAML 配置用于从 REST API 中获取数据,并通过递增日期参数来实现增量数据获取。它将数据导出为 CSV 格式,初始查询日期为 2020-01-01,并会每天递增,直到前一天为止。 您可能会发现将上述配置与等效的Python片段进行比较很有帮助。请记住,如果您的API可以通过互联网访问,您可以直接使用外部Python变换。
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26import requests from datetime import datetime, timedelta incremental_state = load_incremental_state() if incremental_state is None: # 初始化增量状态,如果为空则设置查询开始日期为2020-01-01 incremental_state = {'incremental_date_to_query': '2020-01-01'} # 获取昨天的日期 yesterday = datetime.utcnow() - timedelta(days=1) # 从增量状态中获取需要查询的日期 date_to_query = incremental_state['incremental_date_to_query'] date_to_query = datetime.strptime(date_to_query, '%Y-%m-%d') # 循环查询数据,直到昨天的日期 while yesterday >= date_to_query: response = requests.get(source.url + '/daily_data', params={ 'date': date_to_query.strftime('%Y-%m-%d') # 以YYYY-MM-DD格式设置查询参数 }) upload(response) # 上传获取的数据 date_to_query += timedelta(days=1) # 日期递增一天 incremental_date_to_query = date_to_query # 更新增量查询日期 # 保存更新后的增量状态 save_incremental_state({'incremental_date_to_query': incremental_date_to_query})
基于页面的API
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19type: rest-source-adapter2 outputFileType: json restCalls: - type: magritte-paging-inc-param-call paramToIncrease: page # 需要增加的参数为 page initValue: 0 # 初始值为 0 increaseBy: 1 # 每次增加 1 method: GET # 使用 GET 方法进行请求 path: '/data' # 请求的路径为 /data parameters: page: '{%page%}' # 将当前页数插入到请求参数中 entries_per_page: 1000 # 每页条目数为 1000 extractor: - type: magritte-rest-json-extractor assign: page_items: '/items' # 从 JSON 响应中提取 items 并赋值给 page_items condition: type: magritte-rest-non-empty-condition var: page_items # 条件为 page_items 非空
此代码片段配置了一个 REST 数据源适配器,使用分页参数调用 API 并提取数据,直到 page_items 为空为止。 如果您是开发人员,您可能会发现通过将上述配置与等效的python代码片段进行比较,更容易理解:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14import requests page = 0 while True: response = requests.get(source.url + '/data', params={ 'page': page, 'entries_per_page': 1000 }) upload(response) page += 1 page_items = response.json().get('items') if not page_items: # 如果没有更多的项目,结束循环 break
这段代码是一个简单的分页数据获取和上传的过程:
- 使用
requests.get从指定的 URL 获取数据。 - 每次请求时,通过
params参数指定请求的页码page和每页的数据条数entries_per_page。 - 调用
upload(response)函数上传获取到的数据。 - 增加页码
page并解析响应内容中的items。 - 如果
items为空,则退出循环,表示没有更多数据可获取。
基于偏移的API
以下是一个ElasticSearch基本搜索API示例:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21type: rest-source-adapter2 outputFileType: json restCalls: - type: magritte-paging-inc-param-call paramToIncrease: offset initValue: 0 increaseBy: 100 method: POST path: '/_search' body: |- { "from": {%offset%}, # 从当前偏移量开始请求数据 "size": 100 # 每次请求100条数据 } extractor: - type: magritte-rest-json-extractor assign: hits: '/hits' # 提取JSON响应中的'hits'字段 condition: type: magritte-rest-non-empty-condition var: hits # 检查'hits'字段是否非空,以决定是否继续请求
此配置文件用于配置一个REST数据源适配器,其执行分页请求。它通过增量更新偏移量参数offset来实现分页,每次请求100条数据,并使用magritte-rest-json-extractor提取响应中的数据。如果提取到的hits字段为空,则停止请求。
下一页基于链接的API
下一页词元通常也称为游标、延续或分页词元。
以下是一个ElasticSearch搜索和滚动API示例:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28type: rest-source-adapter2 outputFileType: json restCalls: - type: magritte-rest-call method: GET path: /my-es-index/_search?scroll=1m parameters: scroll: 1m extractor: - type: json assign: scroll_id: /_scroll_id # 提取并分配滚动ID,用于后续滚动请求 - type: magritte-do-while-call method: GET checkConditionFirst: true path: /_search/scroll parameters: scroll: 1m scroll_id: '{%scroll_id%}' # 使用前一次请求提取的滚动ID extractor: - type: json assign: scroll_id: /_scroll_id # 更新滚动ID hits: /hits # 提取搜索结果 timeBetweenCalls: 0s # 每次请求之间的时间间隔 condition: type: magritte-rest-non-empty-condition var: hits # 检查搜索结果是否为空,以决定是否继续滚动
此段代码定义了一组REST API调用,其中包含初始搜索请求和后续的滚动请求。通过滚动机制,可以处理大数据量的搜索结果。每次请求会提取scroll_id用于下次请求,并检查hits是否为空以决定是否继续请求。
这是一个示例的AWS nextToken 分页API:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31type: rest-source-adapter2 outputFileType: json restCalls: - type: magritte-rest-call method: POST path: /findings/list extractor: - type: json assign: nextToken: /nextToken # 从返回的JSON中提取nextToken allowNull: false # 不允许值为null allowMissingField: true # 允许字段缺失 requestMimeType: application/json body: '{}' # 请求体为空的JSON - type: magritte-do-while-call method: POST checkConditionFirst: true # 首先检查条件是否满足 path: /findings/list extractor: - type: json assign: findings: /findings # 从返回的JSON中提取findings nextToken: /nextToken # 从返回的JSON中提取nextToken allowNull: false # 不允许值为null allowMissingField: true # 允许字段缺失 condition: type: magritte-rest-available-condition var: nextToken # 使用nextToken作为条件变量 timeBetweenCalls: 0s # 调用之间的时间间隔为0秒 requestMimeType: appliation/json # MIME类型为application/json body: '{"nextToken":"{%nextToken%}"}' # 请求体包含nextToken的JSON
此YAML配置文件描述了一个REST源适配器,用于从REST API中提取数据。主要包括两个REST调用,第一个调用简单地获取nextToken,第二个调用在条件满足的情况下循环获取findings和nextToken。
触发并下载报告
以下sync适用于需要三个相互依赖步骤的API。
- 将主体发布到返回包含ID的响应的端点。
- 此ID需要在下一个端点中被用于在获取报告。然而,报告并不是立即准备好的,因此响应中包含一个名为
status的字段,用于定义报告是否完成。 - 一旦报告完成,我们可以从第三个端点获取报告。
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35type: rest-source-adapter2 outputFileType: json restCalls: - type: magritte-rest-call path: '/findRelevantId' # 发送请求到 /findRelevantId 路径 method: POST # 使用 POST 方法 requestMimeType: application/json # 请求的 MIME 类型为 application/json extractor: - type: json assign: id: /id # 从返回的 JSON 中提取 id 字段 body: > body # 请求体内容 saveResponse: false # 不保存响应 - type: magritte-do-while-call path: '/reportReady' # 发送请求到 /reportReady 路径 method: GET # 使用 GET 方法 parameters: id: '{%id%}' # 使用之前提取的 id 作为参数 extractor: - type: magritte-rest-json-extractor assign: status: /status # 从返回的 JSON 中提取 status 字段 condition: type: "magritte-rest-regex-condition" var: status matches: "(processing|queued)" # 条件:status 字段匹配 "processing" 或 "queued" timeBetweenCalls: 8s # 每次请求之间的间隔为 8 秒 saveResponse: false # 不保存响应 - type: magritte-rest-call path: '/getReport/{%id%}' # 使用提取的 id 发送请求到 /getReport/{%id%} 路径 method: GET # 使用 GET 方法 requestMimeType: application/json # 请求的 MIME 类型为 application/json
此 YAML 配置文件定义了一系列 REST API 调用过程,主要包括三个步骤:首先通过 POST 请求获取相关 ID,然后不断通过 GET 请求检查报告是否准备好,最后通过 GET 请求获取报告。每个步骤都指定了请求的路径、方法、MIME 类型以及如何从响应中提取所需信息。
提取器定义了在状态中保存哪些字段。请注意,这些变量在所有后续的REST调用中均可用。要注入保存的变量,请用{%%}包围变量名。第二个do-while调用实现了一个循环,该循环发送请求直到状态变量不再排队或处理中。
某些API没有status端点,而是需要轮询getReport端点,在报告准备好之前提供空响应。以下配置展示了如何处理这种情况:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15type: rest-source-adapter2 outputFileType: json restCalls: - type: magritte-do-while-call path: '/getReport/{%id%}' # REST API请求路径,其中{id}是路径参数 method: GET # HTTP方法为GET extractor: - type: magritte-rest-string-extractor var: response # 从响应中提取字符串并存储在变量response中 condition: type: magritte-rest-not-condition # 条件类型为非条件 condition: type: magritte-rest-non-empty-condition # 非空条件检查 var: response # 检查变量response是否非空 timeBetweenCalls: 8s # 两次调用之间的时间间隔为8秒
或者如果getReport端点在报告准备好之前返回204状态码,它可以处理为:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14type: rest-source-adapter2 outputFileType: json restCalls: - type: magritte-do-while-call path: '/getReport/{%id%}' # REST API的路径,其中{%id%}是一个占位符,将在实际调用时替换为具体的ID method: GET # HTTP请求方法为GET extractor: - type: magritte-rest-http-status-code-extractor assign: responseCode # 提取HTTP状态码并分配给变量responseCode condition: type: magritte-rest-regex-condition var: responseCode # 使用提取的responseCode变量 matches: 204 # 检查responseCode是否匹配204 timeBetweenCalls: 8s # 两次调用之间的时间间隔为8秒
该配置文件定义了一个REST源适配器,输出文件类型为JSON。它包含一个do-while类型的REST调用,该调用将重复执行,直到HTTP响应状态码不再是204为止。在每次调用之间,有8秒的时间间隔。
增量同步
此插件支持增量同步。为此,通过指定 incrementalStateVars 从 state 中选择您要保存为同步的增量 state 的变量:
Copied!1 2 3type: rest-source-adapter2 incrementalStateVars: var_name: initial_value # 如果未找到增量元数据,则使用的初始值
Copied!1 2 3type: rest-source-adapter2 incrementalStateVars: lastModifiedDate: 20190101 # 最后修改日期,格式为YYYYMMDD
保存的增量state将被用于在运行同步时作为初始state。
更详细的例子:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23type: rest-source-adapter2 outputFileType: json incrementalStateVars: lastModifiedTime: 'Some initial start time' # 初始的最后修改时间 initialStateVars: # 获取当前时间 currentTime: type: magritte-rest-datetime-expression timezone: 'Some timezone, e.g. Europe/Paris' # 时区,例如欧洲/巴黎 formatString: 'Some format string https://docs.oracle.com/javase/8/docs/api/ \ java/time/format/DateTimeFormatter.html' # 时间格式字符串,参考Java文档 restCalls: - type: magritte-rest-call path: /my/values method: GET parameters: from: '{%lastModifiedTime%}' # 请求参数,从最后修改时间开始 until: '{%currentTime%}' # 请求参数,直到当前时间 extractor: # 更新最后修改时间为当前时间 - type: magritte-rest-string-extractor var: lastModifiedTime fromStateVar: currentTime
此配置文件定义了一个REST源适配器,输出文件类型为JSON。它使用了增量状态变量和初始状态变量来管理时间戳,用于REST API调用中的时间参数更新。lastModifiedTime用于记录最后一次修改时间,而currentTime通过获取当前时间来动态更新这两个时间参数。
详细文档
如果添加多个API来源,在每个REST调用中必须通过source属性指定要使用的来源。
同步
同步配置包含以下字段。
Copied!1 2 3 4 5 6 7 8 9 10type: rest-source-adapter2 restCalls: [calls] # 请参阅下面的 Calls 文档 initialStateVars: {variableName}: {variableValue} # 初始状态变量 incrementalStateVars: {variableName}: {variableValue} # 增量状态变量 outputFileType: json # 对于 oneFilePerResponse,这是必需的 cacheToDisk: defaults to True # 默认为 True,表示缓存到磁盘 oneFilePerResponse: defaults to True; when set to True "outputFileType" is required # 默认为 True,当设置为 True 时,"outputFileType" 是必需的
上述代码是一个 YAML 配置文件的示例,通常用于定义 REST 接口的数据源适配器。
要设置输出文件类型为 outputFileType,oneFilePerResponse 必须为 true,否则响应将被保存为数据集中的行。请参阅下文 存储响应 以获取基于响应类型的推荐选项。
存储响应
推荐用于二进制响应或响应总大小 > 100MB:
Copied!1 2 3 4 5cacheToDisk: true outputFileType: [any file format, e.g. txt, json, jpg] # 指定输出文件的格式,支持任意文件格式,例如 txt, json, jpg oneFilePerResponse: true # 默认值,不需要特别指定 # 每个响应生成一个文件
对于非二进制响应,单个响应大小最多为几MB,总响应大小低于100MB,我们建议如下:
Copied!1 2cacheToDisk: false # 不将缓存存储到磁盘 oneFilePerResponse: false # 每个响应不生成单独的文件
对于响应无法存储在磁盘上但总同步时间较短(少于3分钟)的同步,我们建议如下:
Copied!1 2 3cacheToDisk: false # 是否将缓存存储到磁盘,false 表示不存储 oneFilePerResponse: true # 每个响应生成一个文件 outputFileType: [any file format, e.g. txt, json, jpg] # 输出文件类型,可以是任何文件格式,如 txt、json、jpg
调用
核心调用字段
所有调用都继承自基础RestCall对象,其中包含以下字段:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28type: Rest call type path: Endpoint method: GET | POST | PUT | PATCH # 以下都是可选项 source: The API source to use for this call. # 当有多个API来源时,这个是必需的。 parameters: Map of parameters to pass with request # 默认是空的映射 saveResponse: Should the response be saved in foundry # 默认是True,表示是否将响应保存在foundry中 body: Body to post formBody: # 使用x-www-form-urlencoded格式发送POST请求时的参数映射。 # 可选项,仅在访问x-www-form-urlencoded端点时使用,而不是body。 param1: value1 requestMimeType: application/json headers: Request headers, these append to the source headers, but replace matching headers # validResponseCodes: 可选项,设置不终止API调用的HTTP响应代码集合。 # 如果未设置,默认的有效HTTP响应代码是200, 201和204。 validResponseCodes: - 200 - 201 - 204 # retries: 默认为0。请求可能因取消、连接问题或超时而失败。 # 允许为此调用的每个请求设置所需的重试次数。 retries: 0 extractor: A list of extractor object, see Extractors # 文件名模板,例如 'data_{%page%}', # 否则文件名将是 '[sourceName][path][parameters]' filename: '<dont override if not necessary>' addTimestampToFilename: 默认是true,表示是否在文件名中附加时间戳
继承调用可以在上述字段的基础上添加额外的字段。
REST 调用
Copied!1 2 3type: magritte-rest-call # 这是一个YAML配置片段,定义了一个类型为 magritte-rest-call 的操作。 # 该类型通常用于描述REST API调用的相关配置。
执行单个请求。使用与核心调用相同的YAML设置。
增量分页调用
在满足某些条件时执行具有增加参数的相同请求。通常用于分页。请注意,如果在路径或parameters:部分中包含正在增加的参数,其值应为{%paramToIncrease%}。
Copied!1 2 3 4 5 6 7 8 9 10 11type: magritte-paging-inc-param-call paramToIncrease: state key to param to increase. # 状态键,用于标识需要增加的参数。 checkConditionFirst: when set to "true", equivalent to a while loop. When "false" (default) equivalent to do-while loop. # 如果设置为 "true",等同于 while 循环;如果为 "false"(默认),等同于 do-while 循环。 initValue: Initial value of increasing parameter. # 增加参数的初始值。 increaseBy: How much to increase the parameter by in each iteration. # 每次迭代中参数增加的量。 onEach: List of calls to run in each iteration. Optional and used to do nested calls. # 每次迭代中运行的调用列表。可选,用于执行嵌套调用。 condition: Condition object that keeps requests going. As long as the condition is true, a new request is created. The condition is checked only after the first request, so this acts similarly to a do-while loop. # 条件对象,用于保持请求进行。只要条件为真,就会创建一个新请求。条件仅在首次请求后检查,因此这类似于 do-while 循环。 maxIterationsAllowed: How many iterations to run before throwing an error. # 在抛出错误之前允许运行的最大迭代次数。 timeBetweenCalls: (optional) time to wait between requests # (可选)请求之间的等待时间。
增量日期调用
执行相同请求,并不断增加日期参数,直到满足某个条件。被用于在迭代日期。这使用LocalDate和Period类型,因此最小的增量是一天。这仅适用于仅日期匹配。如果您需要更细粒度的增量,请参阅magritte-increasing-time-param-call。
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16type: magritte-increasing-date-param-call # 参数名为state key to param to increase的参数将被增加 paramToIncrease: state key to param to increase. # 当设置为"true"时,相当于一个while循环。当设置为"false"(默认值)时,相当于do-while循环。 checkConditionFirst: when set to "true", equivalent to a while loop. When "false" (default) equivalent to do-while loop. # 增加参数的初始值 initValue: Initial value of increasing parameter. # 每次迭代时,参数增加的量,可以解析为java.time.Period increaseBy: How much to increase the parameter by in each iteration, parseable as a java.time.Period # 将使用的最后一个日期,如果适用,包括此值。 stopValue: The last date which will be used, including this value if applicable. # 每次调用中DateTime参数的格式,与initValue和stopValue相同(使用java.time.format.DateTimeFormatter) format: The format (java.time.format.DateTimeFormatter) for the DateTime parameter in each call, the same as initValue and stopValue. # (可选)请求之间等待的时间 timeBetweenCalls: (optional) time to wait between requests
增量时间调用
执行相同的请求,并不断增加DateTime参数,直到满足某个条件。被用于在遍历DateTime。 注意,这使用OffsetDateTime和Duration类型,与magritte-incrementing-date-param-call不同。OffsetDateTime不会考虑夏令时的任何更改。确保这不会导致API处理DateTime时出现意外的间隙。
Copied!1 2 3 4 5 6 7 8 9 10type: magritte-increasing-time-param-call paramToIncrease: state key to param to increase. # 需要增加的参数的状态键。 checkConditionFirst: when set to "true", equivalent to a while loop. When "false" (default) equivalent to do-while loop. # 当设置为 "true" 时,相当于一个 while 循环。默认 "false" 相当于 do-while 循环。 initValue: Initial value of increasing parameter. # 增加参数的初始值。 increaseBy: How much to increase the parameter by in each iteration, parseable as a java.time.Duration # 每次迭代中增加参数的量,可以解析为 java.time.Duration。 stopValue: The last DateTime which will be used, including this value if applicable. # 最后使用的 DateTime 值,如果适用,也包括这个值。 format: The format (java.time.format.DateTimeFormatter) for the DateTime parameter in each call, the same as initValue and stopValue. # 每次调用中 DateTime 参数的格式,与 initValue 和 stopValue 相同。 timeBetweenCalls: (optional) time to wait between requests # (可选)请求之间等待的时间。
Do while
执行请求,直到不再满足指定条件。除了核心调用字段外,还应提供两个字段。
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13type: magritte-do-while-call timeBetweenCalls: time to wait between requests # 决定请求之间的等待时间 checkConditionFirst: when set to "true", equivalent to a while loop. When "false" (default) equivalent to do-while loop. # 当设置为 "true" 时,相当于一个 while 循环。当为 "false"(默认)时,相当于 do-while 循环。 condition: Condition object that keeps requests going. As long as the condition is true, a new request is created. # 控制请求是否继续的条件对象。只要条件为真,就会创建一个新请求。 maxIterationsAllowed: How many iterations to run before throwing an error. Defaults to 50. # 在抛出错误之前允许的最大迭代次数。默认值为50。
可以非必填地提供初始state以初始化第一次调用。
例如:
Copied!1 2initialState: nextPage: "" # 初始状态中,nextPage 为空字符串
在初始state和增量state冲突的情况下,增量state将覆盖初始State。
可迭代状态调用
对state元素中每个可迭代元素执行请求。
Copied!1 2 3 4 5 6 7 8 9 10 11type: magritte-iterable-state-call timeBetweenCalls: 5s # 限制每次调用之间的时间间隔 iterableField: The state key to iterate over. This variable must be iterable. # 要迭代的状态键。此变量必须是可迭代的。 iteratorExtractor: List of extractors to run on each element in the iterable. # 在可迭代对象的每个元素上运行的提取器列表。 onEach: List of calls to run in each iteration. Optional and used to do nested calls. # 每次迭代中运行的调用列表。可选项,用于执行嵌套调用。 maxIterationsAllowed: How many iterations to run before throwing an error. Defaults to 50. # 在抛出错误之前允许的最大迭代次数。默认为50。 parallelism: Integer number of threads to use for the sync. Assumptions/limitations include no side effect in request, no guarantee as to order that calls are made or their responses update state, no time between calls. This field is optional and defaults to 1. # 用于同步的线程数。假设/限制包括请求中没有副作用, 不保证调用的顺序或其响应更新状态,以及调用之间没有时间间隔。 此字段为可选项,默认为1。
提取器
提取器定义了如何将变量从响应或state变量保存到状态中。您可以在URL、URL参数或请求体中以{%var_name_1%}的形式引用state中的变量。
提取器的默认行为是从响应中提取值。非必填地,您可以添加fromStateVar配置以从状态中提取。这允许连续运行不同的提取器,例如:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15type: rest-source-adapter2 # 指定适配器类型为 REST 源适配器 outputFileType: csv # 输出文件类型为 CSV restCalls: - type: magritte-rest-call # 指定 REST 调用的类型 path: /my/path/index.html # 请求路径 source: mysource # 数据源 method: GET # HTTP 请求方法 extractor: - type: magritte-rest-json-extractor # JSON 提取器类型 assign: full_name: /my/field/full_name # 提取 JSON 字段并赋值给 full_name - type: magritte-rest-regexp-extractor # 正则表达式提取器类型 fromStateVar: full_name # 从 full_name 状态变量中提取数据 assign: names: '\w+' # 使用正则表达式匹配单词字符并赋值给 names
所有提取器都内置了一个条件检查,可被用于在:
Copied!1condition: 检查输入状态是否满足给定条件。如果不满足,则不运行提取器。
JSON 提取器
所有 JSON 提取器使用 Jackson JsonNode ↗ 并遵循相同的表示法。
字段引用快速指南:
给定 JSON {"id":1}:
- 使用
"/id"将返回1 - 使用
"/"将返回{"id":1}
给定一个列表,例如 [1,2,3] 或 [{"id":1},{"id":2}]:
- 使用
""将返回列表。
可以使用通配符引用列表中所有项目的子索引或字段。例如:
给定一个包含嵌套列表的字段,如 { "result": [[1], [2, 3, 4]] }:
- 使用
"/result/*/0"将返回[1,2]。
给定一个包含对象列表的字段,如 { "result": [{ "foo": 1}, {"foo": 2}]}:
- 使用
"/result/*/foo"将返回[1,2]。
指派 JSON 提取器
一个简单地将响应中的字段放入状态中的提取器。YAML 设置是要保存的变量的映射。左侧字符串是状态中变量的名称,右侧字符串是变量的路径。
JSON 提取器支持通配符 - 给定 JSON [{"id":1}, {"id":2}],使用 /*/id 将返回 [1,2],而使用 ""(空字符串)将返回完整列表。
Copied!1 2 3 4type: json assign: var_name_1: /field-name1 # 将JSON路径/field-name1的值赋给变量var_name_1 var_name_2: /field_name2 # 将JSON路径/field_name2的值赋给变量var_name_2
默认情况下,如果提取的字段具有空值或不存在,则调用将失败。
为了防止在这些情况下调用失败,可以使用以下标志:
allowMissingField当字段不存在或字段具有空值时不出错。allowNull当存在的字段具有空值时不出错。allowUnescapedControlChars当JSON响应包含未转义的控制字符(如\n)时不出错。
Copied!1 2 3 4 5type: json allowMissingField: true # 允许缺失字段 assign: var_name_1: /field-name1 # 将JSON路径/field-name1的值分配给变量var_name_1 var_name_2: /field_name2 # 将JSON路径/field_name2的值分配给变量var_name_2
添加JSON提取器
Copied!1 2 3 4 5 6 7type: magritte-rest-append-json-extractor appendFrom: /field in response that contains an array to append from # 从响应中包含要追加的数组的字段 appendFromItem: /field per array element to extract # Optional # 可选:每个数组元素中要提取的字段 appendTo: variable name in state to append elements to. # 在状态中要追加元素的变量名称
如果响应看起来像:
Copied!1 2 3 4 5 6{ "things": [ {"name": "dummy", "id": "1"}, // 这是一个对象,其中 "name" 是对象名称,"id" 是对象的唯一标识符 {"name": "dummy2", "id": "2"} // 同样,这个对象包含名称和唯一标识符 ] }
then the YAML:
Copied!1 2 3 4type: magritte-rest-append-json-extractor appendFrom: /things # 从 /things 路径提取数据 appendFromItem: /id # 从提取的数据中选择 /id 项 appendTo: var # 将选定项附加到变量 var
将导致 [1,2] 被附加到 var。
或者,可以使用:
Copied!1 2 3type: magritte-rest-append-json-extractor appendFrom: /things # 从 /things 路径获取数据 appendTo: var # 将获取的数据追加到变量 var
这将导致向state变量附加[{"name": "dummy", "id": "1"}, {"name": "dummy", "id": "2"}]。
最大JSON提取器
Copied!1 2 3 4 5type: magritte-rest-max-json-extractor list: /field in response that contains an array to max over. # 响应中包含要取最大值的数组的字段 item: /field per array element to extract # 每个数组元素中要提取的字段 var: state variable to save the max value to. # 用于保存最大值的状态变量 previousVal: state variable to get the current max value from# Optional # 可选的,用于获取当前最大值的状态变量
Copied!1 2 3 4 5 6{ "things": [ {"name": "dummy", "value": "1"}, // 定义一个名为 "dummy" 的对象,值为 "1" {"name": "dummy2", "value": "2"} // 定义另一个名为 "dummy2" 的对象,值为 "2" ] }
Copied!1 2 3 4type: magritte-rest-max-json-extractor list: /things # 指定要处理的JSON对象列表路径 item: /id # 要从每个对象中提取的字段路径 var: max_value # 用于存储提取的最大值的变量名称
该YAML文件配置用于提取JSON对象列表中某个字段的最大值。list指定JSON对象列表路径,item指定要提取的字段路径,var指定存储最大值的变量名称。
将会导致将2保存到max_value。
或者,假设我们已经在max_value中有值5,那么:
Copied!1 2 3 4 5type: magritte-rest-max-json-extractor list: /things # JSON 数组的路径 item: /id # 从每个元素中提取的字段 var: max_value # 存储计算的最大值 previousVal: max_value # 之前计算的最大值,用于比较和更新
将max_value保持为5。
流式JSON最后一行提取器
用于流式JSON (NDJSON)格式的提取器,其中响应在每一行包含一个JSON文件。通常此格式被用于返回数据集,因此每一行都应具有相同格式的JSON。
该提取器支持从NDJSON文件的最后一行的路径中提取变量。
Copied!1 2 3 4type: magritte-rest-last-streaming-json-extractor nodePath: /id # 如果json看起来像{'value':'somevalue', 'id':1},这将提取1 varName: id # 用于保存值的状态变量名称 saveNulls: false # 是否将null值保存到变量中或跳过(默认:false)
上述YAML配置用于定义一个JSON提取器,专门从给定的JSON结构中提取信息。以下是各参数的详细说明:
type: 指定提取器的类型。nodePath: 定义要提取的JSON路径。在这个例子中,提取的是JSON中的id字段。varName: 提取的值将被保存到状态变量中,此参数指定该变量的名称。saveNulls: 决定是否将null值保存到变量中。设置为false时,null值将被跳过。
流式JSON追加提取器
提取器支持从NDJSON文件的每一行中提取一个变量到数组中,并提取最后遇到的变量。一旦提取器遇到null(无论是缺行、缺键还是键下的null值),它将停止循环。
Copied!1 2 3 4 5type: magritte-rest-last-streaming-json-extractor nodePath: /id # 如果 JSON 结构类似于 {'value':'somevalue', 'id':1},这将提取其中的 1 arrayVarName: ids # 在状态中保存数组的变量名称 optional<lastVarName>: lastId # 在状态中保存数组最后一个值的变量名称(可选) optional<limit>: 10 # 限制解析的行数,可以与 lastVarName 一起使用,并结合 iterableStateCall 以限制每次提取运行的调用次数
这段代码配置了一个 JSON 提取器,用于从 REST API 响应中提取数据。通过 nodePath 指定 JSON 路径以提取特定值,并将结果存储到变量中。可选参数 lastVarName 和 limit 用于进一步控制提取操作。
XML提取器
指派XML提取器
一个提取器,将响应中的字段简单地放入状态中。YAML设置是要保存的变量映射。左边的字符串是状态中变量的名称,右边的字符串是使用xpath表示法的变量路径。
Copied!1 2 3 4type: magritte-rest-xml-extractor assign: var_name_1: /top_level_tag/second_level_tag/text() # 提取 XML 中 second_level_tag 标签的文本内容并赋值给 var_name_1 var_name_2: /top_level_tag/text() # 提取 XML 中 top_level_tag 标签的文本内容并赋值给 var_name_2
HTML提取器
通过CSS选择器从HTML中提取内容(支持的选择器语法 ↗)。可以指定要提取的属性;如果留空,将返回选定元素的文本。如果first为true,提取器将尝试以字符串或数字的形式返回第一个元素。此提取器也可用于格式不正确的XML。
Copied!1 2 3 4 5type: magritte-rest-html-extractor var: 'links' selector: "a[href$='pdf']" # 选择器,用于选择所有以'pdf'结尾的链接 attribute: href # 可选属性,提取链接的href属性 first: false # 可选项,默认为false,表示提取所有符合条件的元素而不仅仅是第一个
提供的示例将所有以 .pdf 结尾的锚标签超媒体引用保存为 links 变量中的字符串数组。
字符串提取器
字符串提取器
提取一个字符串,并返回一个新state,并将此字符串指派给定义的变量。
Copied!1 2type: magritte-rest-string-extractor var: 'variable_name' # 变量名
该YAML配置片段定义了一种类型为 magritte-rest-string-extractor 的对象,并且包含一个变量 var,其值为 'variable_name'。
子字符串提取器
从state中的变量提取子字符串,并将其保存到另一个状态。
Copied!1 2 3 4 5 6type: magritte-rest-substr-extractor start: 2 # 起始索引,从字符串的第二个字符开始 length: 5 # 可选参数,子字符串的长度(包括起始索引)。 # 如果未设置,子字符串将是起始索引之后的整个字符串。 assign: var_to_save_substring_to # var: state_variable_to_substring - 已弃用,使用 fromStateVar 代替!
正则表达式提取器
一个从字符串中提取一个或多个正则表达式的提取器。YAML设置是要保存的变量映射。左侧字符串是State中变量的名称,右侧字符串是要匹配的正则表达式。
Copied!1 2 3 4type: magritte-rest-regexp-extractor assign: var_name_1: (1(.*)3|a(.*)c) # 正则表达式,用于匹配以1开头3结尾,或以a开头c结尾的字符串 var_name_2: (NotInString) # 正则表达式,用于匹配字符串"NotInString"
如果输入中的字符串是:
abcHelloWorld123
该字符串是一个简单的字母和数字组合,没有代码需要解释。 响应将如下所示:
Copied!1 2 3 4{ "var_name_1": ["abc", "123"], // var_name_1 是一个数组,包含字符串 "abc" 和 "123" "var_name_2": [] // var_name_2 是一个空数组 }
以下是一个完整示例,展示如何从HTML中提取CSV链接,然后获取CSV:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22type: rest-source-adapter2 outputFileType: csv restCalls: - type: magritte-rest-call path: /my/path/index.html source: mysource method: GET extractor: - type: magritte-rest-regexp-extractor assign: file_paths: '(?<=https://www\.mysite\.com)(.*filename.*csv)(?=\")' # 使用正则表达式提取文件路径 saveResponse: false - type: magritte-iterable-state-call source: mysource timeBetweenCalls: 1s # 每次请求之间的时间间隔为1秒 iterableField: file_paths method: GET path: '{%path%}' # 使用迭代器变量生成路径 saveResponse: true iteratorExtractor: - type: magritte-rest-string-extractor var: 'path' # 定义迭代器变量路径
这段YAML代码配置了一个REST源适配器流程,主要分为两个REST调用。第一个调用从指定路径的HTML中使用正则表达式提取CSV文件路径,而第二个调用则迭代这些提取的文件路径进行GET请求,并保存响应。
正则表达式替换提取器
一个在字符串中替换一个正则表达式的提取器,类似于PySpark函数pyspark.sql.functions.regexp_replace:
Copied!1 2 3 4type: magritte-rest-regexp-replace-extractor var: result # `state`变量,将创建或用结果字符串覆盖 pattern: "[a]" # 要查找的正则表达式 replacement: "A" # 用于替换正则表达式匹配项的新字符串
数组操作
追加或扩展数组
追加数组提取器接收一个state变量并将其推送到数组的末尾。此提取器在收集路径以传递给可迭代的state调用时非常有用。
Copied!1 2 3type: magritte-rest-append-array-extractor appendTo: target # 如果目标未初始化,提取器将初始化一个空数组。 fromStateVar: args # 接受单个参数(追加)或集合(扩展)
以下是完整示例:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30type: rest-source-adapter2 restCalls: - type: magritte-paging-inc-param-call method: GET path: category paramToIncrease: page # 每次请求时用于分页的参数 initValue: 0 # 初始化分页参数的值 increaseBy: 100 # 每次增加的分页参数值 parameters: start_element: '{%page%}' # 使用分页参数来替换路径中的占位符 num_elements: 100 # 每页请求的元素数量 extractor: - type: magritte-rest-json-extractor assign: res: /response/categories # 从响应中提取类别数据并赋给变量res - type: magritte-rest-append-array-extractor fromStateVar: res # 从状态变量res中提取数据 appendTo: categories # 将提取的数据追加到categories数组中 until: type: magritte-rest-non-empty-condition var: res # 当res变量为空时停止分页 - type: magritte-iterable-state-call method: GET path: 'category/{%category%}' timeBetweenCalls: 5s # 每次请求之间的等待时间 iterableField: categories # 迭代的字段 iteratorExtractor: - type: magritte-rest-string-extractor var: category # 提取迭代元素并赋给category变量 outputFileType: json # 输出文件类型为JSON
This YAML configuration is used for a REST source adapter, which makes HTTP GET requests to retrieve categories in a paginated manner and iterates over the categories for further processing.
其他提取器
HTTP状态码提取器
从响应中提取HTTP状态码。
Copied!1 2type: magritte-rest-http-status-code-extractor assign: 'variable_name'
该代码是一个YAML格式的配置片段,配置类型为magritte-rest-http-status-code-extractor。以下是配置的说明:
type: 指定配置的类型,这里是magritte-rest-http-status-code-extractor,意味着这是一个用于提取HTTP状态码的配置。assign: 指定提取到的HTTP状态码将被赋值给哪个变量,此处为'variable_name'。
Set-Cookie响应头提取器
从响应中的Set-Cookie头提取cookie。
Copied!1 2 3type: magritte-rest-set-cookie-header-extractor assign: var_name_1: cookie_name_in_set_cookie_header # 从Set-Cookie头中提取的cookie名称
数组元素提取器
从给定数组中提取一个元素。
Copied!1 2 3 4type: magritte-rest-array-element-extractor fromStateVar: Array var to extract an element from. # 从数组中提取元素的数组变量。 index: The index of the element in the input array to extract. # 要提取的输入数组中元素的索引。 toStateVar: Name of the variable to extract the element to. # 提取的元素将存储到的变量名称。
给定的索引参数可以是负数,以从数组末尾开始,例如 -1 提取最后一个元素。
类型转换提取器
一种提取器,它接收一个变量,使用一些预定义的转换逻辑转换变量的类型,并将结果保存到目标变量。
Copied!1 2 3 4type: magritte-rest-typecast-extractor fromStateVar: Input variable to the extractor. # 提取器的输入变量 toStateVar: Output variable of the extractor. # 提取器的输出变量 toType: Type of the output variable after casting. # 转换后的输出变量类型
toType参数必须是'java.lang.'包中的有效Java类型。
有效类型的示例包括'String'、'Integer',但也包括完整的'java.lang'包和名称:'java.lang.Double'。
为了使类型转换正常工作,必须有一个预定义的方法将输入变量的类型转换为输出类型。 这意味着插件中必须有代码以变换变量从而转换为配置的类型。
注意:将一个包含2个字符串a和b的java.util.Arrays转换为字符串将得到[a, b],而将一个包含2个字符串a和b的com.fasterxml.jackson.databind.node.ArrayNode转换为字符串将得到["a","b"],因为这是JSON数组的字符串表示形式。
条件
这些条件的工作方式类似于ElasticSearch条件。当前支持的条件有:
正则表达式
Copied!1 2 3type: magritte-rest-regex-condition var: a state variable key # 状态变量的键 matches: a valid regular expression # 一个有效的正则表达式
示例:
Copied!1 2 3type: "magritte-rest-regex-condition" var: my_state_variable matches: '^\d+$' # 正则表达式:匹配一个或多个数字字符
可用条件
检查给定变量是否可用(是否被指派了非空值)。
Copied!1 2type: magritte-rest-available-condition var: a state variable key # 状态变量键
这段代码片段是一个 YAML 格式的配置文件示例,其中:
type指定了配置的类型为magritte-rest-available-condition,这可能是一个特定系统或框架中的条件类型。var是一个状态变量的键,可能用于在系统中引用或检查某个状态变量的值。
Copied!1 2type: magritte-rest-available-condition var: my_state_variable # 我的状态变量
非空条件
检查给定变量是否可用且不为空。
Copied!1 2type: magritte-rest-non-empty-condition var: a state variable key # 一个状态变量的键
以上代码是一个YAML格式的片段,用于描述某种类型的条件。在这里:
type: 指定条件的类型为magritte-rest-non-empty-condition,可能是在某个框架或系统中定义的特定条件类型。var: 表示一个状态变量的键,这个键用于在系统中存取或检查某个状态变量的值。
Copied!1 2 3 4 5type: magritte-rest-non-empty-condition var: my_array_state_variable # 该YAML片段定义了一种类型为“magritte-rest-non-empty-condition”的配置。 # 变量“my_array_state_variable”用于存储数组的状态。 # 这个配置通常用于检查REST API中数组变量是否非空。
非条件
对给定的子条件取反。
Copied!1 2type: magritte-rest-not-condition condition: 需要取反的条件。
Copied!1 2 3 4type: magritte-rest-not-condition condition: type: magritte-rest-available-condition var: my_state_variable # 这是状态变量的名称,可以根据具体需求进行更改
这段YAML配置用于定义条件逻辑,其中 magritte-rest-not-condition 表示一个否定条件,其内部包含一个 magritte-rest-available-condition 类型的条件,该条件依赖于一个名为 my_state_variable 的状态变量。
And 条件
要求所有给定的子条件都为true。
Copied!1 2type: magritte-rest-and-condition conditions: A list of conditions to AND over. # 一个需要进行逻辑与操作的条件列表。
Copied!1 2 3 4 5 6type: magritte-rest-and-condition conditions: - type: magritte-rest-available-condition var: my_state_variable # 确保 my_state_variable 是可用的 - type: magritte-rest-non-empty-condition var: my_array-state_variable # 确保 my_array-state_variable 非空
这里的代码使用 YAML 格式定义了一种复合条件,名为 magritte-rest-and-condition,包括两个子条件:
magritte-rest-available-condition:检查变量my_state_variable是否可用。magritte-rest-non-empty-condition:检查变量my_array-state_variable是否为非空数组。
二元条件
Copied!1 2 3 4 5type: magritte-rest-binary-condition toCompare: left: `state` key to compare on the left side of condition # `state`键用于条件左侧的比较 right: `state` key to compare on the right side of condition # `state`键用于条件右侧的比较 op: One of the following "=", "<", ">", "<=", ">=" # 运算符可以是以下之一 "=", "<", ">", "<=", ">="
这段YAML描述了一种二元条件类型,用于比较两个state键的值,并通过指定的运算符(如等于、小于等等)进行比较。
Copied!1 2 3 4 5type: magritte-rest-binary-condition toCompare: left: a_state_variable # 左侧变量,参与比较的状态变量 right: another_state_variable # 右侧变量,参与比较的另一个状态变量 op: < # 比较运算符,此处为“小于”操作符
表达式
表达式可被用于在Magritte REST同步期间随时计算某些值。与提取器不同,表达式的结果不依赖于同步的state。
DateTime表达式
一个用于提供特定日期和/或时间的表达式。起始于获取当前日期/时间并添加给定的偏移量。
其他state变量的参数(例如,应该放在顶级initialStateVars:块中):
Copied!1 2 3 4 5type: magritte-rest-datetime-expression offset: 可选。用于添加或减去当前日期/时间的时间量。可以为负数。 timezone: 可选。用于计算日期/时间的时区。默认为UTC。 formatString: 可选。计算后的日期和时间的输出格式。 默认为带有偏移量的ISO 8601日期时间格式。
以上是一个配置文件的片段,定义了日期时间表达式的类型及其可选参数说明。 有关有效偏移量,请参阅Java 8 Duration 文档 ↗。
有关有效时区,请参阅Java 8 ZoneId 文档 ↗。
有关有效输出格式字符串,请参阅Java 8 DateTimeFormatter ↗。
字面值表达式
一个将提供字面值的表达式。
字面值的类型将自动推断,可以通过查看字面值表达式的日志找到。当前支持的类型包括字符串、数字和列表。
Copied!1 2type: magritte-rest-literal-expression literalValue: Required. # 必填项。
Copied!1 2type: magritte-rest-literal-expression literalValue: 270 # 这是一个简单的字面量表达式,值为270
列出示例:
Copied!1 2type: magritte-rest-literal-expression literalValue: ["it's", "a", "kind", "of", "magic"] # 字面值数组,包含字符串元素
在 Foundry 中处理 JSON
在导入 JSON 数据时:
Copied!1 2 3 4 5 6 7 8 9 10{ "response": { "size": 1000, // 响应内容的大小 "items": [ { "item id": 1, "status": { "modifiedAt": "2020-02-11" }, "com.palantir.metadata": { ... } }, // 项目ID为1,最后修改时间为2020-02-11 { "item id": 2, "status": { "modifiedAt": "2020-02-12" }, "com.palantir.metadata": { ... } }, // 项目ID为2,最后修改时间为2020-02-12 { "item id": 3, "status": { "modifiedAt": "2020-02-13" }, "com.palantir.metadata": { ... } } // 项目ID为3,最后修改时间为2020-02-13 ] } }
使用 magritte-rest-v2 插件,每个JSON响应将作为一个单独的文件保存在数据集中。
为了便于处理这些数据,请在原始数据集上放置一个模式:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22{ "fieldSchemaList": [ { "type": "STRING", // 字段类型为字符串 "name": "row", // 字段名称为"row" "nullable": null, // 可为空属性未定义 "userDefinedTypeClass": null, // 用户自定义类型类未定义 "customMetadata": {}, // 自定义元数据为空 "arraySubtype": null, // 数组子类型未定义 "precision": null, // 精度未定义 "scale": null, // 标度未定义 "mapKeyType": null, // 映射键类型未定义 "mapValueType": null, // 映射值类型未定义 "subSchemas": null // 子模式未定义 } ], "dataFrameReaderClass": "com.palantir.foundry.spark.input.DataSourceDataFrameReader", // 用于读取数据框的类 "customMetadata": { "format": "text", // 数据格式为文本 "options": {} // 选项为空 } }
要清理此数据集并将每个item作为数据集中的单独行,并将item字段作为列,请创建一个Python变换库。
将以下代码片段添加到新的utils/read_json.py文件中:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78from pyspark.sql import functions as F import json import re def flattenSchema(df, dontFlattenCols=[], jsonCols=[]): """ 展平DataFrame的schema,将嵌套结构展平成扁平结构。 参数: df: 输入的DataFrame dontFlattenCols: 不需要展平的列名列表 jsonCols: 需要作为JSON处理的列名列表 """ new_cols = [] for col in df.schema: _flattenSchema(col, [], new_cols, dontFlattenCols + jsonCols, jsonCols) print(new_cols) return df.select(new_cols) def _flattenSchema(field, path, cols, dontFlattenCols, jsonCols): """ 递归地展平每个字段。 参数: field: 当前字段 path: 当前字段的路径 cols: 新生成的列列表 dontFlattenCols: 不需要展平的列名列表 jsonCols: 需要作为JSON处理的列名列表 """ curentPath = path + [field.name] currentPathStr = '.'.join(curentPath) if field.dataType.typeName() == 'struct' and currentPathStr not in dontFlattenCols: for field2 in field.dataType.fields: _flattenSchema(field2, curentPath, cols, dontFlattenCols, jsonCols) else: fullPath = '.'.join(['`{0}`'.format(col) for col in curentPath]) newName = '_'.join(curentPath) sanitized = re.sub('[ ,;{}()\n\t\\.]', '_', newName) # 将特殊字符替换为下划线 if currentPathStr in jsonCols: cols.append(F.to_json(fullPath).alias(sanitized)) # 转换为JSON格式 else: cols.append(F.col(fullPath).alias(sanitized)) def parse_json(df, node_path, spark): """ 解析DataFrame中的JSON字段,将其转为DataFrame。 参数: df: 输入的DataFrame node_path: JSON路径 spark: SparkSession对象 """ rdd = df.dataframe().rdd.flatMap(get_json_rows(node_path)) df = spark.read.json(rdd) return df def get_json_rows(node_path): """ 从JSON中提取指定路径的节点。 参数: node_path: JSON路径 返回: 从指定路径提取的JSON对象的列表 """ def _get_json_object(row): parsed_json = json.loads(row[0]) node = parsed_json for segment in node_path: node = node[segment] return [json.dumps(x) for x in node] return _get_json_object
然后,您可以使用如下代码创建一个Python变换:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14from transforms.api import transform, Input, Output from utils import read_json @transform( output=Output("/output"), json_raw=Input("/raw/json_files"), ) def my_compute_function(json_raw, output, ctx): # 解析JSON文件,提取出'response'和'items'字段,转换为Spark DataFrame df = read_json.parse_json(json_raw, ['response', 'items'], ctx.spark_session) # 扁平化DataFrame中的复杂JSON字段,特别是'com.palantir.metadata' df = read_json.flattenSchema(df, jsonCols=['com.palantir.metadata']) # 将处理后的DataFrame写入输出 output.write_dataframe(df)
它将创建一个数据集:
item_id | status_modifiedAt | com_palantir_metadata
1 | "2020-02-11" | "{ ... }" // 元数据字段,可能包含其他信息
2 | "2020-02-12" | "{ ... }"
3 | "2020-02-13" | "{ ... }"
这段代码表示一个简单的表结构,包含三个字段:
item_id:项目的唯一标识符。status_modifiedAt:状态最后修改的日期。com_palantir_metadata:可能包含其他相关信息的元数据字段。