注意:以下翻译的准确性尚未经过验证。这是使用 AIP ↗ 从原始英文文本进行的机器翻译。
使用Pipeline Builder创建媒体集批处理管道
在本教程中,我们将使用Pipeline Builder创建一个简单的管道,通过媒体集从PDF中提取文本。
在这个示例中,我们使用Palantir发布的公开可用文档的PDF。
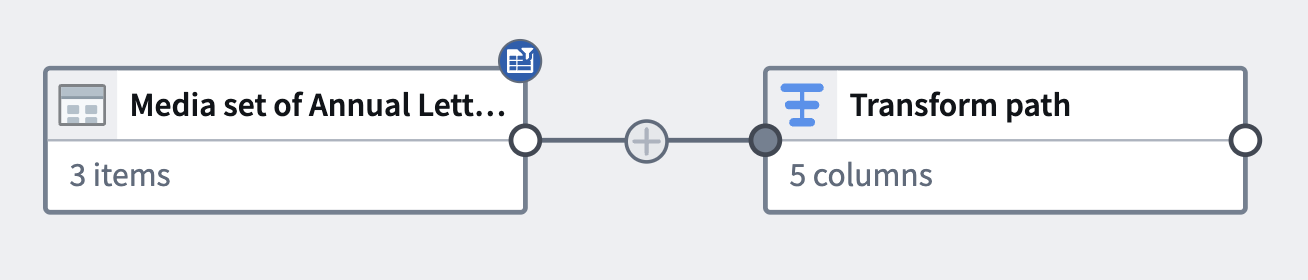
在本教程结束时,您将拥有如下所示的管道:

该管道将生成一个新的Object输出,其中包含提取的PDF文本,可用于进一步的探索。
第1部分:初始设置
首先,我们需要创建一个新的管道。
-
登录到Foundry后,从左侧导航栏访问Pipeline Builder。如果Pipeline Builder不在应用列表中,选择查看全部,在构建和监控管道部分下找到Pipeline Builder。
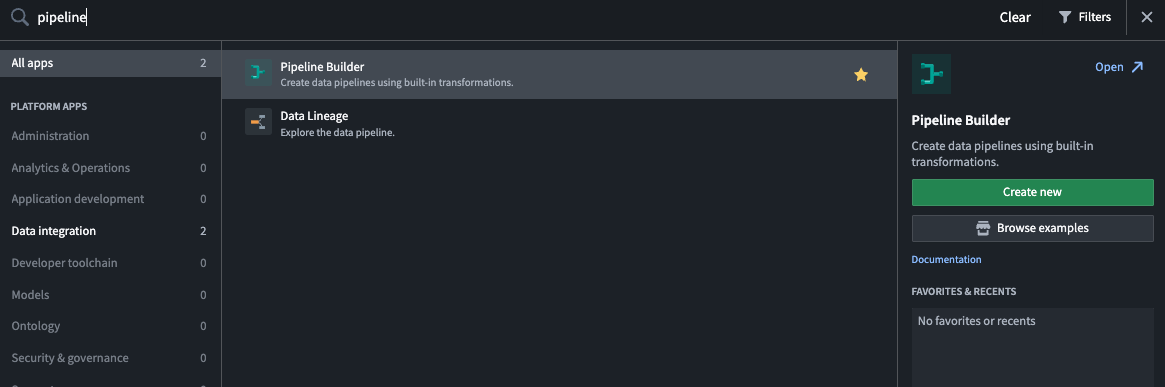
-
接下来,在Pipeline Builder主页的右上角,通过选择新建管道来创建新管道。然后选择批处理管道。
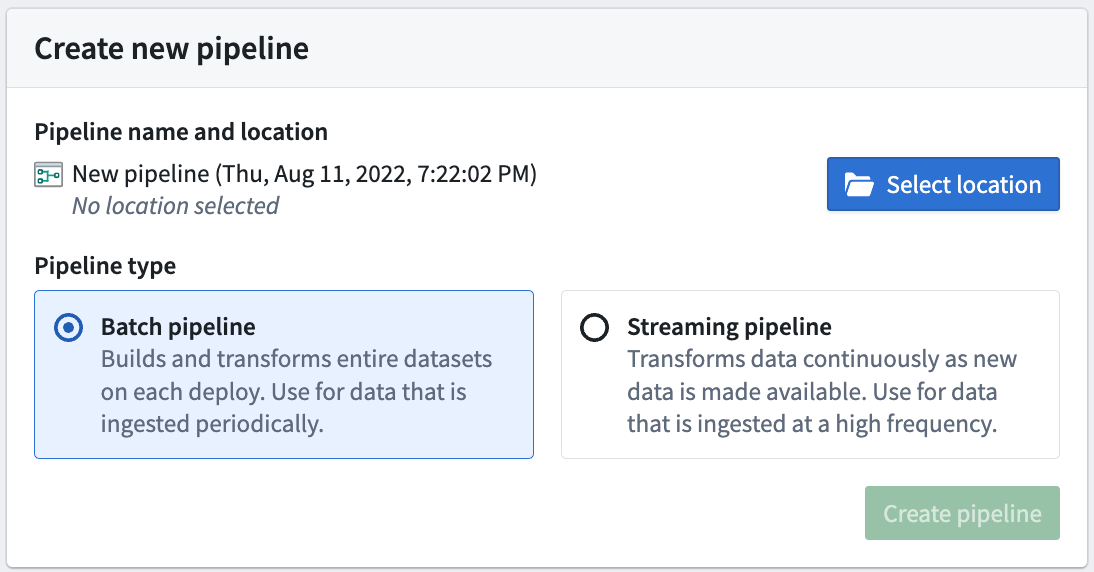
创建流式管道的功能并不是在所有Foundry环境中都可用。如果您的应用案例需要它,请联系您的Palantir代表以获取更多信息。
-
选择一个位置保存您的管道。请注意,管道不能保存在个人文件夹中。
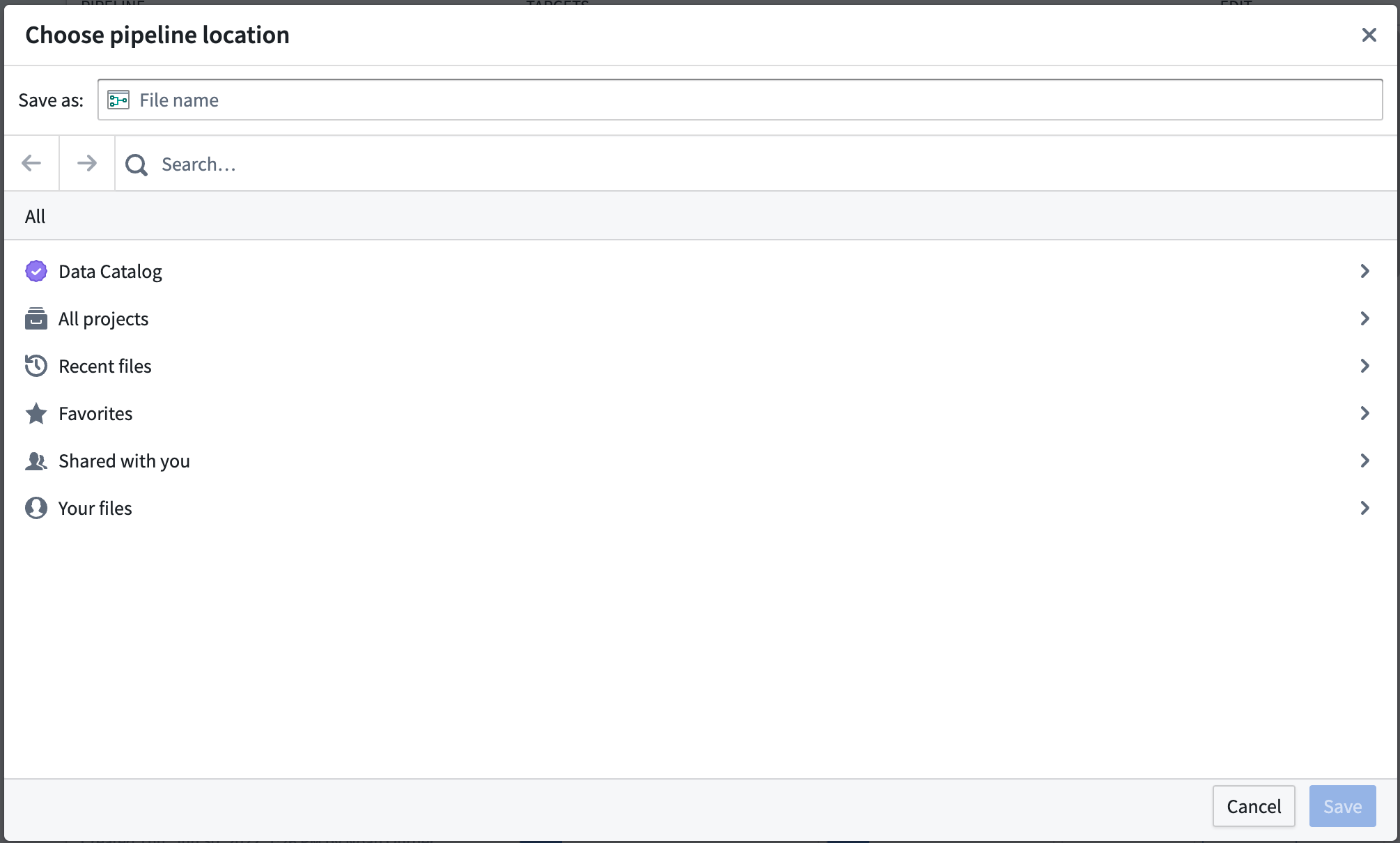
-
选择创建管道。
第2部分:添加媒体集
现在我们可以将数据集添加到我们的管道工作流中。在本教程中,我们将使用来自Palantir的公开可用文档的PDF。
-
从Pipeline Builder页面,在主页上选择添加Foundry数据。

您还可以选择顶部面板上的添加数据操作。

或者,您可以拖放计算机上的文件以用作您的媒体集。
-
如果您选择了添加数据或添加Foundry数据,您将可以选择您想要的媒体集。

-
选择所有媒体集后,选择添加数据。
-
导入媒体集后,您将能够看到带有缩略图预览的媒体集。

第3部分:媒体集变换
添加原始媒体集后,我们可以进行一些基本的变换。在此工作流中,我们将从这些PDF文件中提取文本。
从PDF中提取文本
首先,我们将变换年度信件媒体集媒体集。选择媒体集中媒体项的媒体引用。
获取媒体引用
-
在您的图中选择
年度信件媒体集节点。 -
选择变换。

-
搜索并选择将媒体集转换为表行变换以打开面板。

-
选择是否
包含时间戳和按路径去重。
-
选择应用以将变换添加到您的管道中。
-
您的输出应如下所示:

示例媒体引用:
{"mimeType":"application/pdf","reference":{"type":"mediaSetItem","mediaSetItem":{"mediaSetRid":"ri.mio.main.media-set.xxx","mediaItemRid":"ri.mio.main.media-item.xxx"}}}示例媒体项RID:
ri.mio.main.media-item.xxx-xxx-xxx-xxx-xxxx
提取文本
-
使用媒体引用后,您现在可以选择一个新的面板,该面板利用媒体引用。搜索并选择文本提取变换。

-
选择提取方法(
原始文本(PDF解析)或OCR),媒体引用列,OCR输出格式(如果选择了OCR),以及语言/脚本。
-
选择应用以将变换添加到您的管道中。
-
当您将鼠标悬停在提取的文本上时,您的输出应如下所示:

您现在可以在提取的文本列上运行可用的字符串变换。
-
选择右上角的返回图表以返回到您的管道图表。
(非必填)语义搜索工作流
如果需要,您可以继续使用提取的文本进行语义搜索工作流。
第4部分:添加输出
现在我们已完成从PDF中提取文本并可能运行额外的字符串变换,我们可以添加一个输出。在本教程中,我们将添加一个Object输出。
-
在完成变换的
Transforms节点中,选择添加输出。
-
选择新对象类型。

-
命名您的对象类型并通过选择请选择一个Ontology来设置Ontology。

-
选择编辑并编辑任何列映射。确保为主键选择有效的列。

第5部分:搭建管道
-
要搭建您的管道,请确保选择保存,然后选择部署 > 部署管道。
-
您应该在
部署管道侧边栏选项下看到初始化部署。
-
选择查看部署历史以跟踪您的部署进度。您应该被引导到管道中的
历史选项卡,在那里您可以查看部署的状态和历史:

(非必填)第6部分:Ontology之北
一旦部署完成并且您的对象已初始化,您应该能够直接在您的对象输出上进行操作。选择创建Workshop模块以生成一个带有管道输出的Workshop模块。

通过这最后一步,我们生成了管道输出并生成了一个Workshop模块。