注意:以下翻译的准确性尚未经过验证。这是使用 AIP ↗ 从原始英文文本进行的机器翻译。
使用 Foundry Streaming 进行计算
Foundry Streaming 是一种高吞吐量、低延迟的计算形式,它持续监听新的传入消息,应用用户定义的逻辑,并将其推送到管道的下一阶段。
Foundry 流依赖于分布式并行工作者架构,每个并行工作者都有其专用于特定流任务的资源。流的资源需求随着活动流的最大吞吐量以及其处理的消息总数而扩展。
如何衡量计算
流计算使用分为两种类型:
-
实时处理计算: 在实时数据上运行用户定义的变换的过程。这种源类型称为“流”。
-
存档计算: 将数据从流层移动到 Foundry 的存储层的过程。存档计算是一个批处理过程,将显示为“变换”。
注意,在支付 Foundry 使用费用时,默认的 streaming_usage_rate 为 0.5。这是用户定义的变换在实时数据上运行的速率。如果您与 Palantir 有企业合同,请在继续进行计算使用量计算之前联系您的 Palantir 代表。
Foundry 中流的实时处理计算通过其在挂钟时间内使用的计算秒数来衡量。因此,在流任务中使用更多计算资源(例如 vCPUs、内存、并行化)将增加任务的成本。任务运行时间越长,使用的计算量越多。由于流被设计为持续运行以连续处理数据,因此流将继续使用计算,直到被用户结束。
流是静态分配的;在流运行时,它们每挂钟秒使用恒定数量的计算秒数。流通常被调整以满足峰值需求,这意味着来自流的计算使用量不受可变数据量的影响。即使没有数据通过流,流也会使用计算秒数。
流使用可以计算为单个任务管理器和多个任务管理器使用的总秒数之和。注意,每个并行工作者将具有相同的计算资源。
任务管理器计算秒数计算方式如下:
max(num_vCPU, gib_ram / 7.5) * streaming_usage_rate * stream_duration_seconds
任务管理器计算秒数计算方式如下:
max(num_vCPU, gib_ram / 7.5) * streaming_usage_rate * stream_duration_seconds * (num_parallel_task_managers + 1)compute_seconds = 任务管理器计算秒数 + 任务管理器计算秒数
了解用于计算计算使用量的值,包括内存与核心比率。
存档任务是与每个流一起运行的批处理任务。存档任务定期从流的热存储层读取数据并将其移动到 Foundry 存储中以实现稳健的持久性和历史跟踪。由于存档任务不像流本身那样有低延迟要求,它们按计划运行,仅在有数据需要存档时使用计算。
存档任务使用基于单一 Spark 驱动程序,可以通过以下公式计算:
compute_seconds = max(num_vcpu, gib_ram / 7.5) * num_seconds- 存档任务很小。存档器始终以 1 vCPU 和 4 GiB RAM 的最小配置文件运行。
调查 Foundry Streaming 使用情况
要查看流的总使用情况,首先导航到资源管理应用程序。然后,在 按资源使用 部分找到您的流并选择 详细信息 以查看按单个数据集的使用情况。
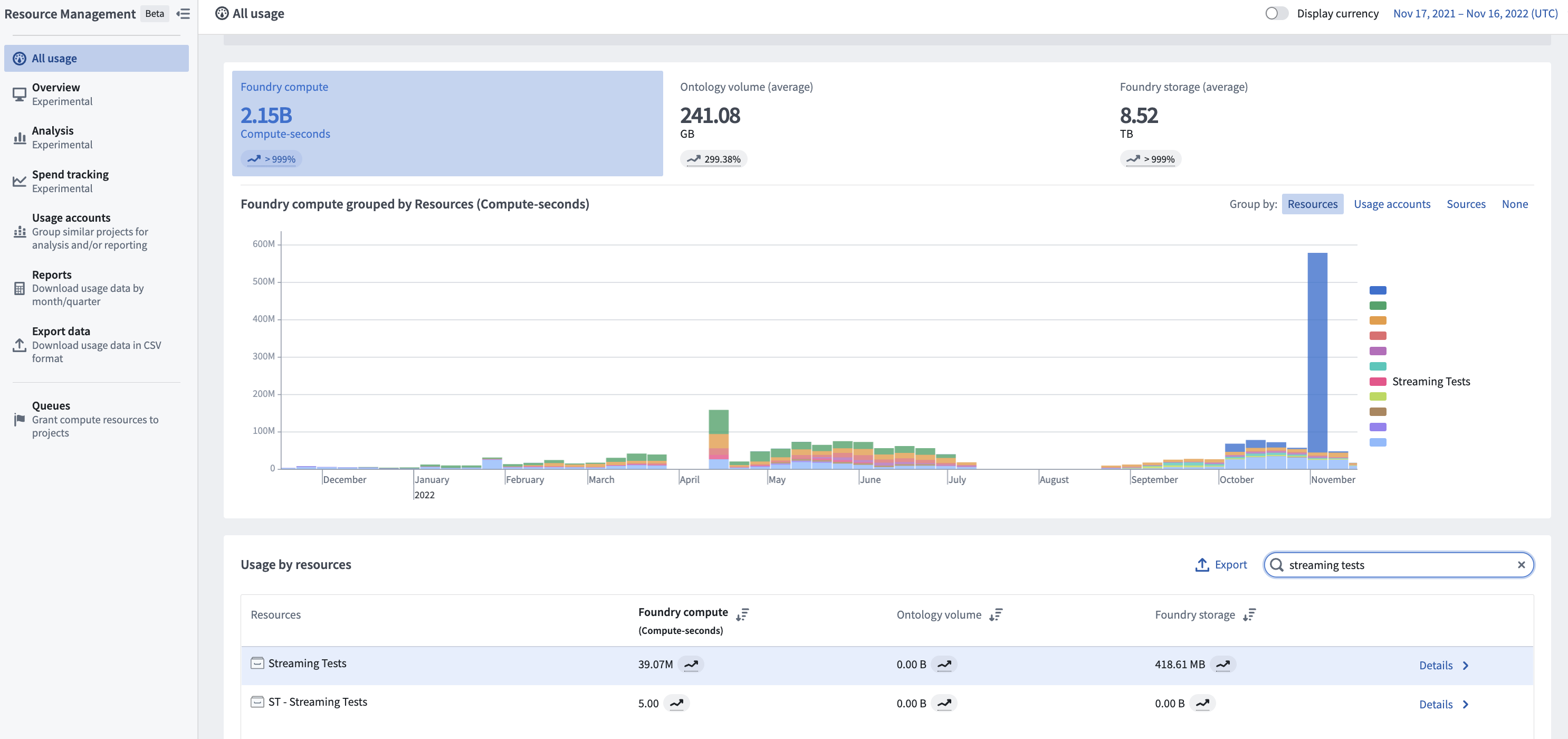
流的成本归因于流产生的检查点数据集。此数据集作为该流处理的永久使用记录。此数据集上的流使用属于资源管理应用程序中的“流”类别。
每次流运行时,它将连续运行,直到被用户停止。当用户停止流时,该运行将出现在数据集的 历史 选项卡下。您可以调查每个单独流的配置文件以了解历史流运行的性能和计算使用情况。
每次运行历史存档时,它会在搭建应用程序中发布其计算指标。使用搭建应用程序调查每次运行的存档的资源分配。
了解使用驱动因素
流使用的主要驱动因素是流本身的计算资源占用。在这种情况下,计算资源包括每个任务管理器的 vCPUs 数量、每个分区的 GiB RAM 以及流中的分区数量。这些资源在流的配置文件中设置,并在流的持续时间内保持不变。
- 流资源应分配以满足传入流的峰值吞吐量。如果传入消息的量对于计算资源来说过高,以至于无法有效服务,流将会落后。
- 要更改流使用的资源,您必须更改资源配置文件并重启流。
- 存档任务的计算使用量随着通过流的数据量而扩展。存档任务读取自上次存档以来的所有数据。如果没有数据被流动,则存档任务将使用零计算。存档任务在流活动时每 10 分钟运行一次。
使用 Foundry Streaming 管理使用
理解何时选择流和何时选择批处理用于特定工作流是很重要的。流设计用于需要秒级延迟和持续计算的工作流。如果数据可以每几分钟运行一次,请考虑一个小的微批处理任务,其可以以降低的计算秒成本和显著更高的数据延迟推送与流相同数量的数据。
- 流的大小显著影响每次运行使用的总计算秒数。流应配置足够的资源以处理该流预期的最大同时负载。
- 选择流的大小以确保峰值负载可以被服务,同时确保没有过度配置是很重要的。这需要仔细配置每个任务(vCPUs 和内存)的大小以及流的任务管理器总数。
- 流将运行直到它们被停止。仔细监控流计算的来源,以确保流仅在需要时运行。
计算使用量
以下示例展示了如何计算一个假设流的计算使用量,该流运行 10 分钟。注意,大多数生产流是持续运行的。
流配置文件
- 任务管理器 vCPUs: 0.5
- 任务管理器 gib_ram: 1
- 任务管理器 vCPUs: 0.5
- 任务管理器 gib_ram: 2g
- 并行度: 2
- gib_ram: 4
- 流持续时间: 10 分钟 (600 秒)
- streaming_usage_rate: 0.5
计算
- 任务管理器计算秒数 = max(vCPUs, gib_ram / 7.5 gib_ram) * streaming_usage_rate * 600s = max(0.5, 0.133) * 0.5 * 600s = 150 计算秒数
- 或者,每秒 0.25 计算秒数或每小时 900 计算秒数
- 任务管理器计算秒数 = max(vCPUs, gib_ram / 7.5 gib_ram) * (并行度 + 1) * streaming_usage_rate * 600s = max(0.5, 0.267) * 3 * 0.5 * 600s = 450 计算秒数
- 或者,每秒 0.75 计算秒数或每小时 2700 计算秒数
此流运行 10 分钟的总计算使用量为 150 任务管理器计算秒数和 450 任务管理器计算秒数。了解更多关于影响 Foundry 计算使用量的因素。