注意:以下翻译的准确性尚未经过验证。这是使用 AIP ↗ 从原始英文文本进行的机器翻译。
预览变换
在代码库中使用预览工具以有限的输入数据集样本运行代码,以快速预览输出。预览生成一个样本输出,而不提交更改、运行检查或在 Foundry 中实现任何数据集。预览可以加速开发周期,消除触发搭建以测试代码更改的需求。
运行预览
可以从代码库中的两个地方触发预览。
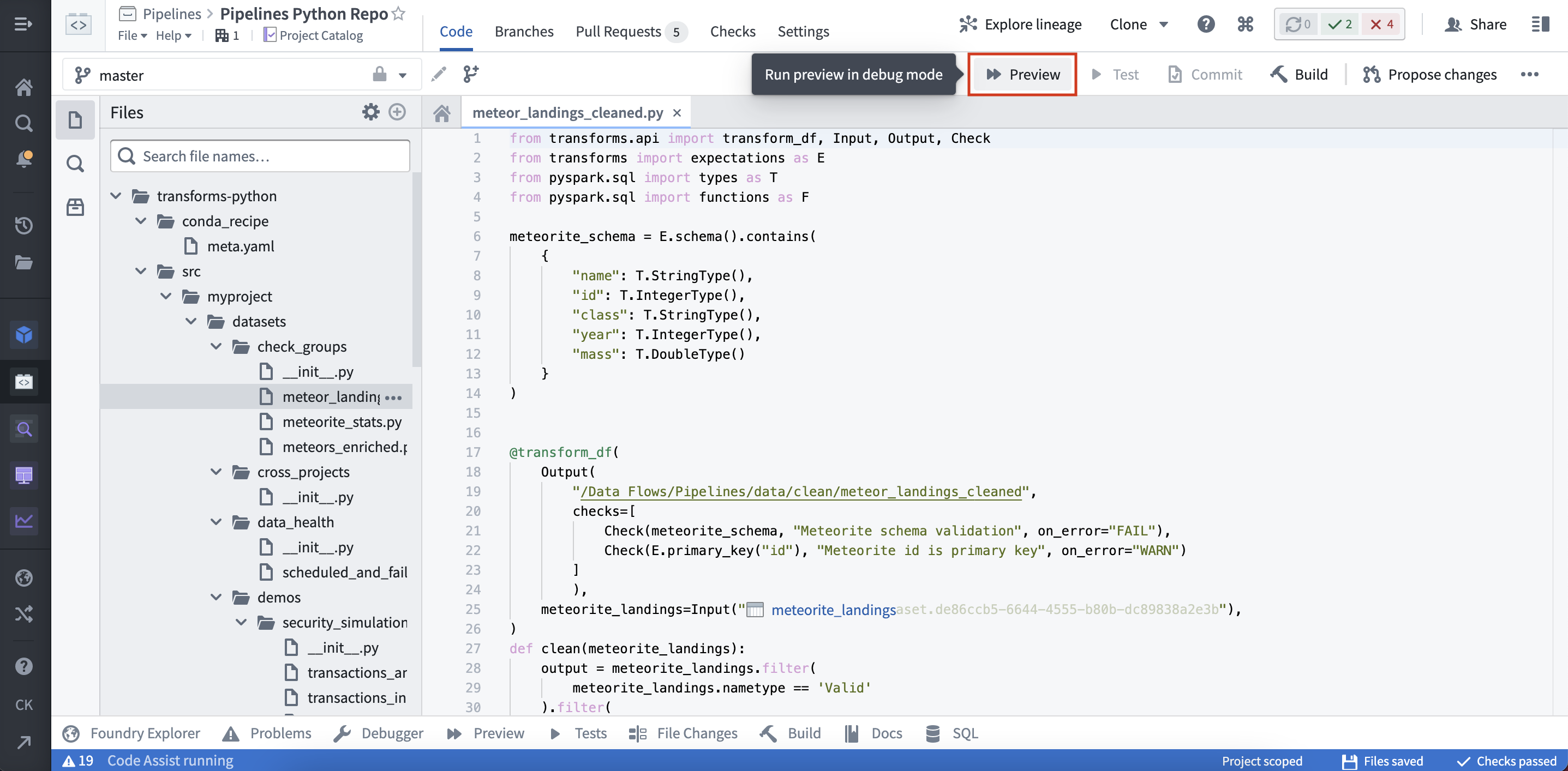
(1) 在代码编辑器选项面板中选择预览:
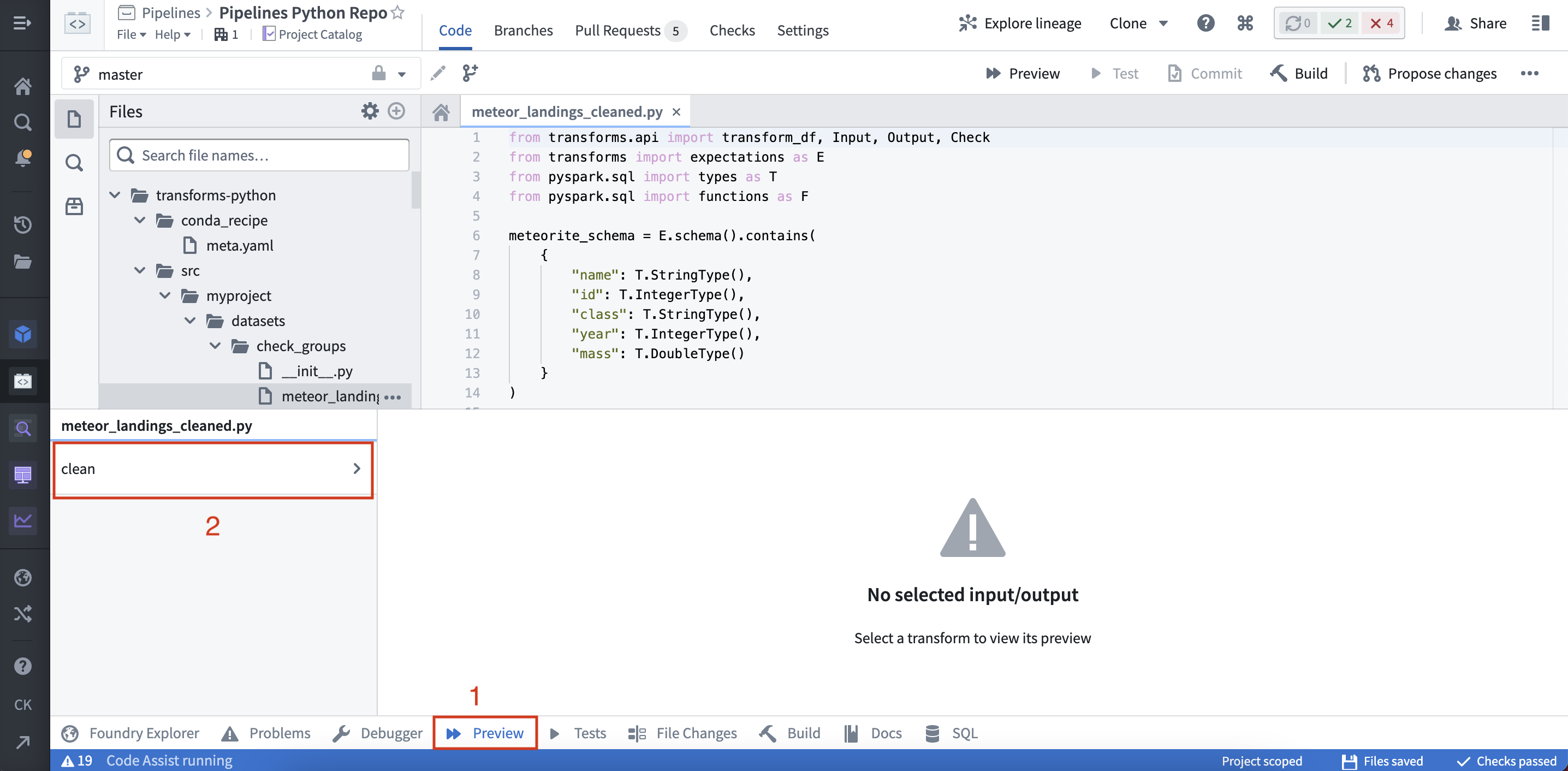
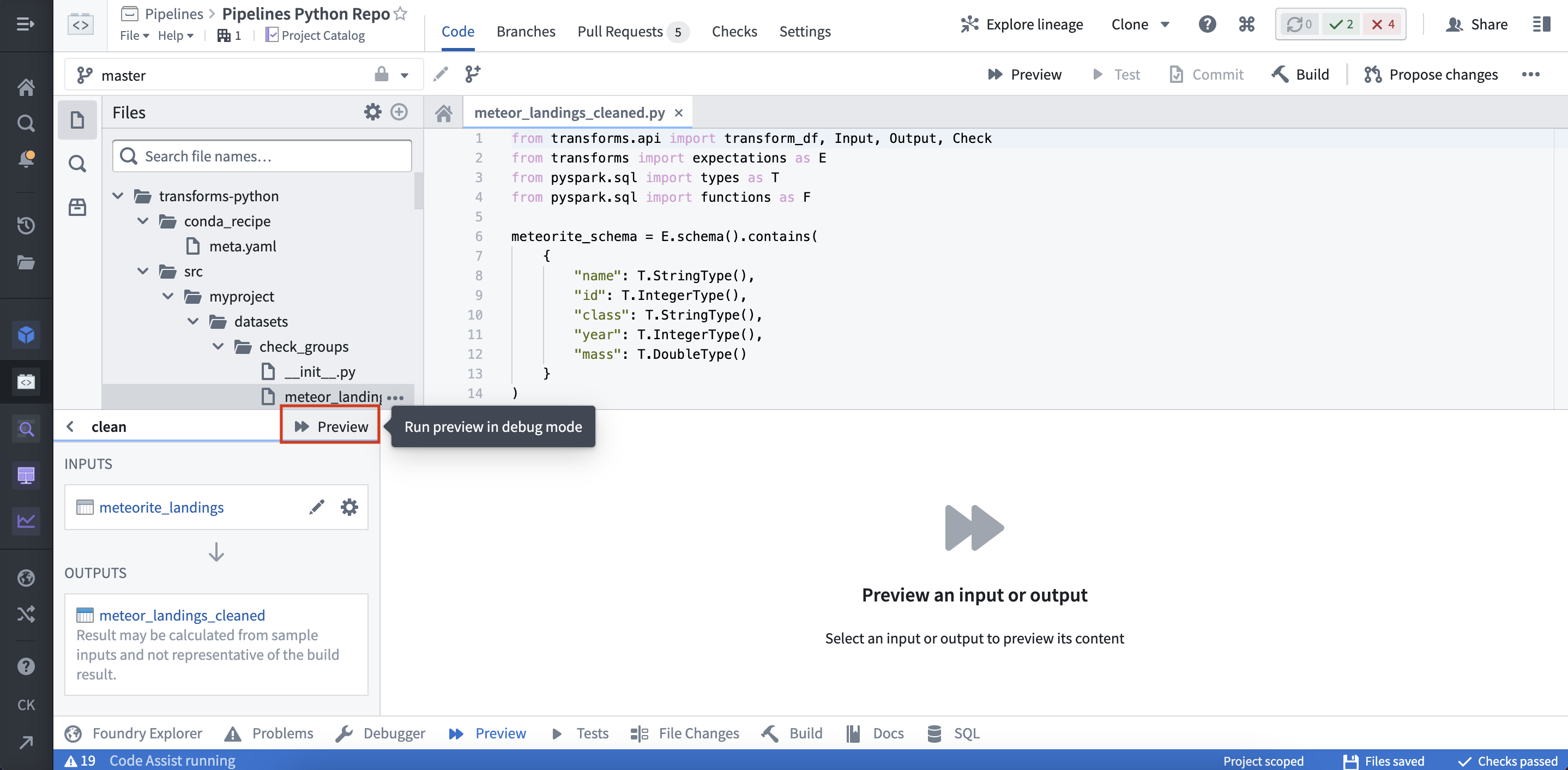
(2) 在助手面板中选择预览:
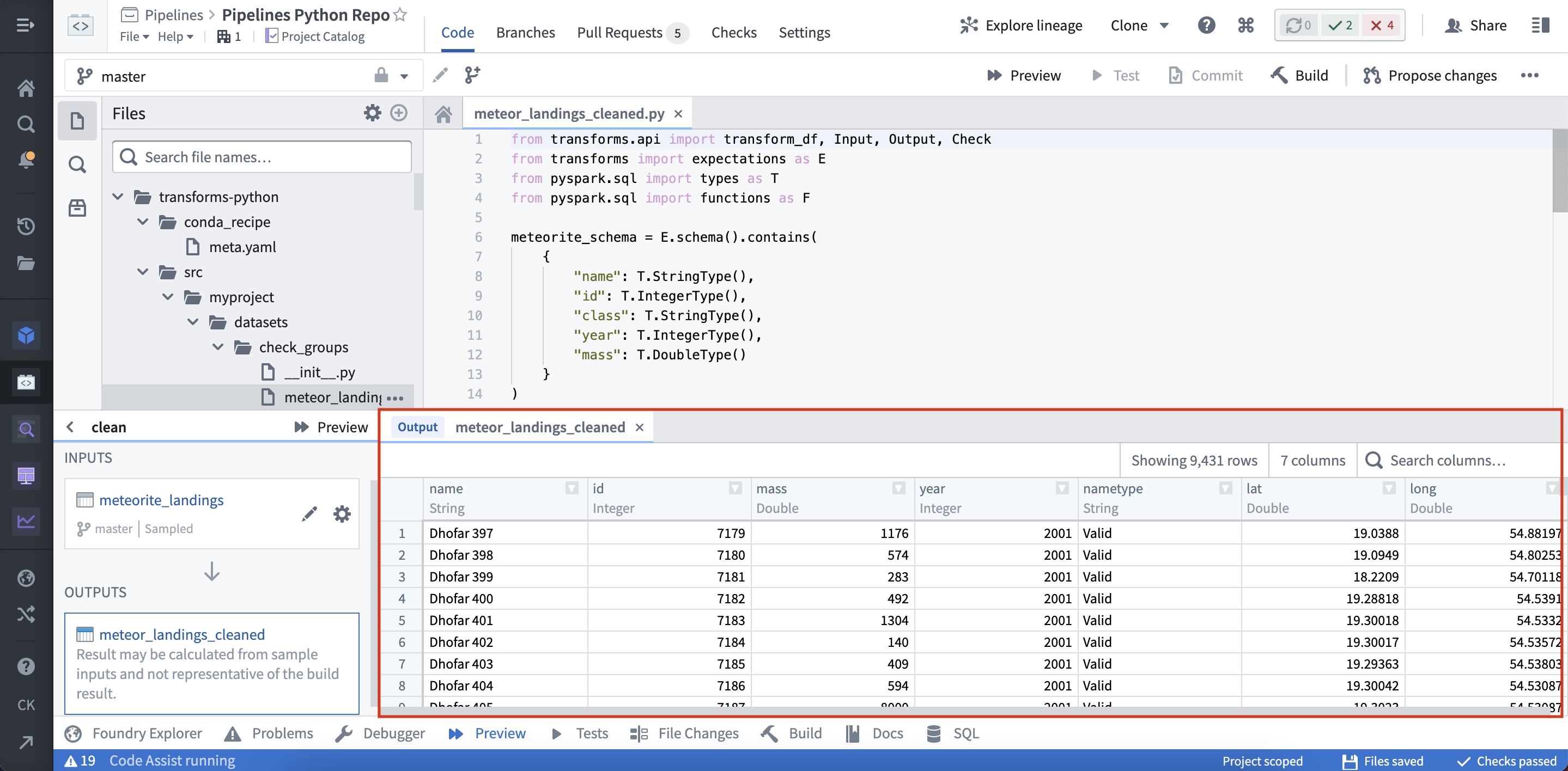
一旦预览执行完毕,输出将显示:
使用文件配置预览
预览可用于包含非结构化文件的数据集。在首次对包含文件的数据集运行预览时,必须配置将在样本中使用的文件。
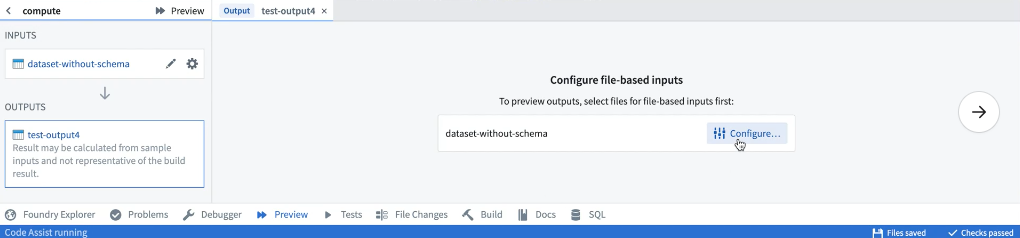

选定样本文件后,可以通过从输入列表中选择相关输入来重新配置它们。保存配置后,预览将在选定的文件样本上执行代码。再次运行预览时,无需重新配置输入文件。一旦预览执行完毕,您可以以行或文件的形式查看样本输出。如果您有必要的权限,还可以选择下载输出文件。
使用模型配置预览
模型资产
无需额外配置,预览支持模型资产,这些资产可以是在 Foundry 中训练的、由预训练文件支持的、或是导入的语言模型。

数据集支持的模型
配置预览以与数据集支持的模型一起工作的过程与使用文件配置预览相同。请确保选择所有必要的建模特定文件,以确保预览能够成功执行。有关在代码库中开发模型的更多信息,请参阅训练模型资产。
预览在变换生成器中创建的变换
在变换生成器中创建的变换共享函数的名称;为了更容易选择预览的预期变换,更改生成的变换的__name__属性以生成有意义的名称。例如:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22from transforms.api import transform_df, Output def generate_transforms(): transforms = [] for output_dataset_name in ["One", "Two", "Three"]: @transform_df( Output(f"/output/path/{output_dataset_name}")) def my_transform(ctx, output_dataset_name=output_dataset_name): # 默认情况下,生成的转换将被命名为 `my_transform (1)`, `my_transform (2)`... cols = ['id', 'value'] # 定义数据框的列名 vals = [ (0, f'{output_dataset_name}'), (1, f'{output_dataset_name}'), (2, f'{output_dataset_name}') ] # 定义数据框的值,每个值都是一个元组 (id, value) df = ctx.spark_session.createDataFrame(vals, cols) # 使用 Spark 创建数据框 return df transforms.append(my_transform) transforms[-1].__name__ = f'{output_dataset_name}_{transforms[-1].__name__}' # 重写转换的名称 return transforms TRANSFORMS = generate_transforms()
该代码定义了一个函数 generate_transforms(),该函数会为每个指定的输出数据集名称创建一个转换函数 my_transform,并将其添加到 transforms 列表中。每个转换函数会生成一个包含三行数据的 Spark 数据框,其中的 value 列根据输出数据集名称动态设置。转换函数的名称也会被动态重命名,以包含输出数据集名称。