注意:以下翻译的准确性尚未经过验证。这是使用 AIP ↗ 从原始英文文本进行的机器翻译。
非必填数据持久化
对于工作簿中的每个变换,用户可以选择是否将结果保存为数据集。
选择是否保存为数据集
默认情况下,新变换不会被保存为数据集。要保存它们,请在逻辑窗格中使用切换按钮。

这些截图使用的是来自纽约市出租车和豪华轿车委员会 ↗的开源数据。
要一次更改多个变换的持久性,请使用左侧的批量编辑器。

如果您选择将变换从未保存更改为已保存,它将重新链接到其之前保存的数据集。如果不存在之前保存的数据集,将创建一个新的数据集。
已保存的变换以水平蓝色条表示。
执行模型
运行一个节点时,该节点上游所有未持久化节点的逻辑也将运行。在下图中,运行已保存变换C时,未保存变换A的逻辑也将被执行。

如果更改未保存变换A中的代码但未运行它,然后运行已保存变换C,已保存变换C的结果将反映出逻辑的更改。
在运行未保存变换D时,将从Foundry数据集中读取已保存变换C,并执行未保存变换B的逻辑。

假设我们切换已保存变换C,使其不再保存为数据集。在运行未保存变换D时,将执行所有三个上游变换的逻辑。

在这种情况下,当运行这一系列变换时——如果我的最终目标是查看未保存变换D的结果,则无需预览3个上游未保存的变换。通过运行未保存变换D,将使用所有四个变换中的最新逻辑和导入数据集的最新事务。
常见问题
什么时候应该将变换保存为数据集?
如果一个变换计算量很大,并且在许多其他变换的上游使用,您可能需要将其保存为数据集,以防止性能下降。
如果您希望在工作簿外使用变换的结果(例如,在另一个Code Workbook或Contour分析中),则应将变换的结果保存为数据集。
如果一个变换以非确定性方式计算一个函数(例如,使用row_number函数或调用当前时间的函数),您应将数据集持久化到Foundry。这将保证下游变换将使用写入数据集的确切结果。
如果您的工作簿包含长链的未持久化节点,建议定期通过持久化一个中间节点来检查您的工作簿。
什么时候应该预览一个节点?
通常情况下,应在创建一系列变换时使用预览功能,以验证其正确性并预览其结果。一旦一系列变换被编纂,就很少有理由使用预览功能。
为什么我的未保存变换没有出现在数据沿袭中?
Code Workbook中的未保存变换是逻辑块,而不是项目中的资源。当您探索数据沿袭时,数据集将显示它们执行的所有代码。这包括上游未保存变换的代码。
例如,这个工作簿包含一个未保存变换和一个已保存变换。
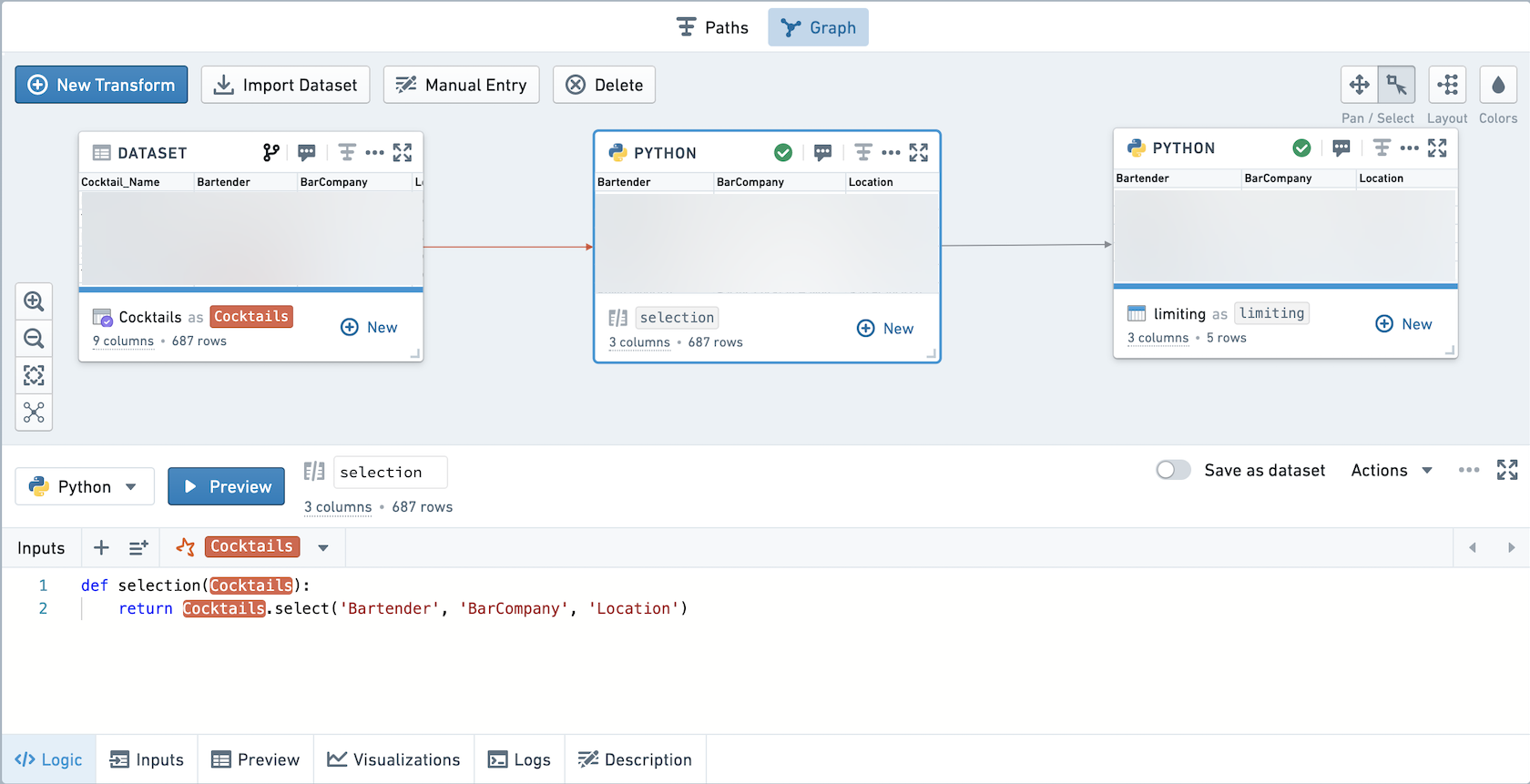
如果您点击探索数据沿袭,它将显示如下。请注意,selection变换的代码被添加到limiting变换的代码之前。

非必填数据持久化对性能和资源使用的影响是什么?
Code Workbook最初使用的执行模型是将每个变换保存为Foundry数据集。当前执行模型允许用户选择是否将变换保存为数据集,这对性能和资源使用有影响。
定期搭建
假设您在之前的执行模型中运行了一个定期搭建。在新的执行模型中,如果所有变换仍然持久化,性能将保持与之前相同。
如果您确定某些中间变换不需要保存为Foundry数据集,并选择取消持久化它们,管道速度将有显著的性能提升。这是因为这些节点的中间结果不再需要写入Foundry,并且在某些情况下可以帮助Spark查询计划器进一步优化下游计算。
互动使用
在互动情况下,旧的执行模型中会计算预览结果和写入结果。通过非必填持久化,未持久化的节点仅计算预览,而持久化的节点仅计算写入。因此,不会有重复工作,并且运行一个相同的工作簿将比以前的执行模型使用更少的资源。
非必填持久化对互动情况下性能的影响更为微妙。对于具有非常大计算量的变换的工作流(例如,大型合并),您可能希望持久化该合并以避免每次运行下游变换时重新计算大型合并。
在所有情况下,当您决定取消持久化一个变换时,通过不写入Foundry可以节省存储空间。