注意:以下翻译的准确性尚未经过验证。这是使用 AIP ↗ 从原始英文文本进行的机器翻译。
在 Jupyter® 笔记本中使用 Palantir 提供的语言模型
要使用 Palantir 提供的语言模型,必须首先在您的注册中启用 AIP。
Palantir 提供了一套语言和嵌入模型,可以在 Jupyter® 笔记本中使用。这些模型可以通过 palantir_models 库使用。该库提供了一组类,用于与模型进行交互。
在 Code Workspaces 中设置 Palantir 提供的模型
要向您的笔记本添加语言模型支持,请打开 Code Workspace 左侧的包搜索面板。搜索 palantir_models,然后选择 Latest。这将复制一个安装命令到您的剪贴板,您可以将其粘贴到一个空单元格中并运行。
向您的笔记本添加 Palantir 提供的模型
要向您的笔记本添加语言模型,请打开 Code Workspace 左侧的 Models 面板。如果您尚未导入模型,请点击 Import a Palantir-provided model。如果您已经导入了一个模型,您可以通过选择面板顶部的 + 图标导入其他模型。
然后面板会显示一个可搜索的可用模型列表。模型分为两类:聊天完成模型和嵌入模型。选择所需的模型以将其导入到您的 Code Workspace 中。

不同客户的模型可用性可能会有所不同。欲了解更多信息,请联系您的 Palantir 代表。
导入后,您的模型将出现在 Models 面板中。在 Models 面板中选择模型将显示一个演示该模型基本功能的代码片段。

要开始使用模型,请单击片段以复制代码并粘贴到笔记本中的任意单元格中。
使用语言模型生成完成
在此示例中,我们将使用 OpenAI 模型来回答一个问题。假设您已经导入了一个模型,可以将下面的代码片段复制到任何单元格中继续操作。
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13from language_model_service_api.languagemodelservice_api_completion_v3 import GptChatCompletionRequest from language_model_service_api.languagemodelservice_api import ChatMessage, ChatMessageRole from palantir_models.models import OpenAiGptChatLanguageModel # 获取指定的GPT聊天语言模型实例,此处使用 "gpt_v4" model = OpenAiGptChatLanguageModel.get("gpt_v4") # 创建一个聊天完成请求,用户提问“为什么天空是蓝色的?” response = model.create_chat_completion( GptChatCompletionRequest([ ChatMessage(ChatMessageRole.USER, "why is the sky blue?") ]) )
嵌入
除了生成语言模型之外,Palantir还提供嵌入模型。以下示例展示了如何使用嵌入模型计算一组单词的嵌入,并绘制嵌入以进行可视化。下面的每个代码块都应视为一个独立的单元。
首先,添加此示例所需的依赖项:
Copied!1 2# 使用 mamba 安装 Python 包:palantir_models、matplotlib、numpy 和 scikit-learn !mamba install -y palantir_models matplotlib numpy scikit-learn
这行代码使用 mamba 包管理器安装几个常用的 Python 库:palantir_models(可能是一个与数据分析或机器学习相关的库)、matplotlib(用于数据可视化)、numpy(用于数值计算)以及 scikit-learn(用于机器学习)。-y 选项表示自动确认安装,无需人工干预。
然后确保您在 模型 面板中导入了嵌入模型。在这个例子中,我们将使用 OpenAI 的 text-embedding-ada-002 模型。
为了生成所需的嵌入,我们从模型片段的副本开始,并进行如下修改:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22from language_model_service_api.languagemodelservice_api_embeddings_v3 import GenericEmbeddingsRequest from palantir_models.models import GenericEmbeddingModel # 定义水果列表 fruits = [ "apple", "banana", "orange", "melon", "kiwi", "pear", "grape", "strawberry", "lemon", "lime", "blueberry", "berry", "mango", "watermelon" ] # 定义动物列表 animals = [ "dog", "cat", "cow", "eagle", "mouse", "horse", "squirrel", "lion", "deer", "goose", "chicken", "pig" ] # 将水果和动物列表合并成一个词汇列表 words = fruits + animals # 获取文本嵌入模型 model = GenericEmbeddingModel.get("text-embedding-ada-002") # 创建词汇列表的嵌入表示 embeddings = model.create_embeddings(GenericEmbeddingsRequest(inputs=words)).embeddings
最后,我们可以使用scikit-learn和Matplotlib来可视化我们的嵌入:
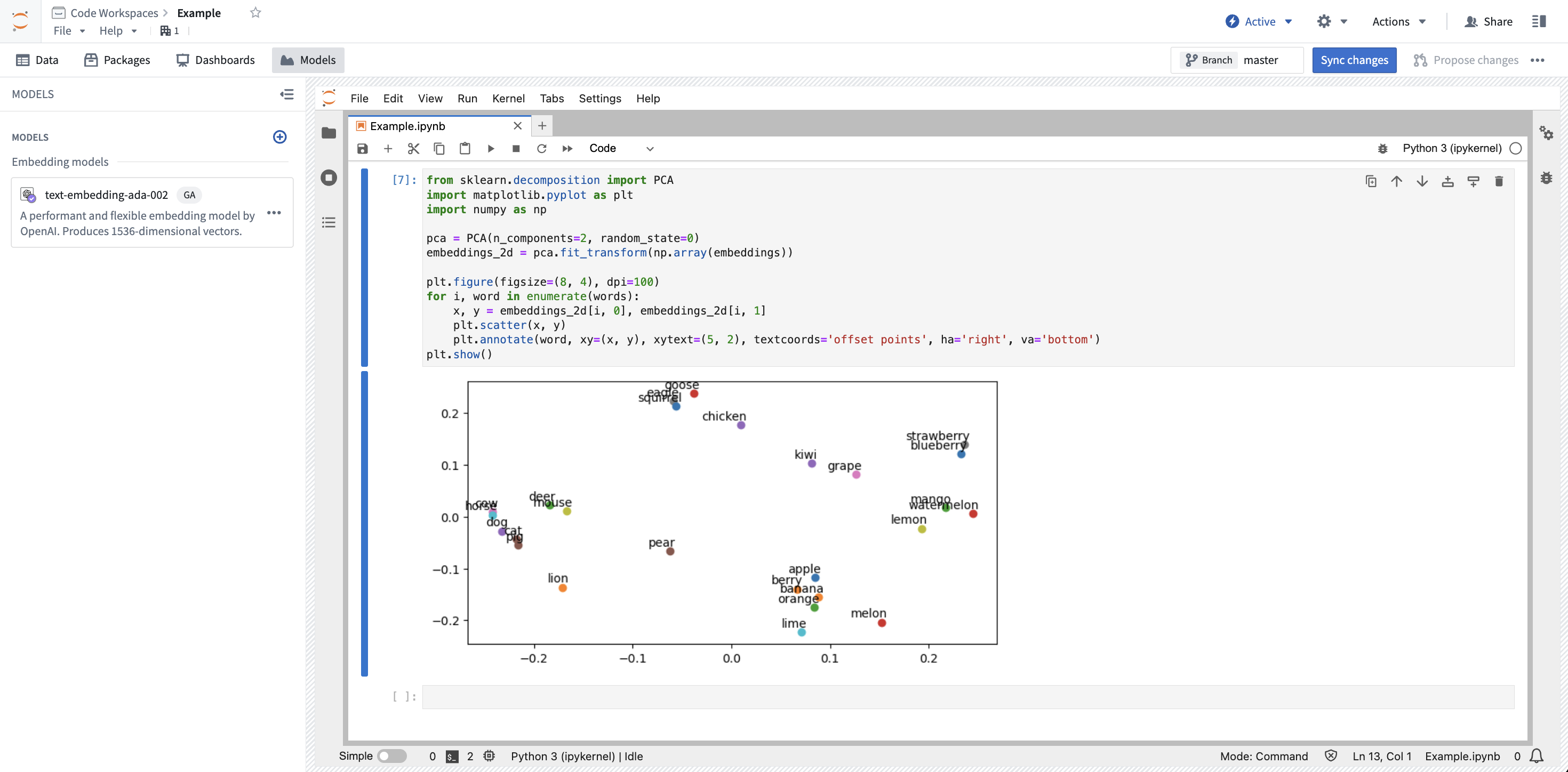
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15from sklearn.decomposition import PCA import matplotlib.pyplot as plt import numpy as np # 使用PCA降维到二维 pca = PCA(n_components=2, random_state=0) embeddings_2d = pca.fit_transform(np.array(embeddings)) # 将高维嵌入降到二维 plt.figure(figsize=(8, 4), dpi=100) for i, word in enumerate(words): x, y = embeddings_2d[i, 0], embeddings_2d[i, 1] plt.scatter(x, y) # 绘制散点 # 添加文本注释,分别在点的右下方偏移一些距离 plt.annotate(word, xy=(x, y), xytext=(5, 2), textcoords='offset points', ha='right', va='bottom') plt.show() # 显示图形
运行笔记本后,您将看到一个嵌入的图表:
Jupyter®、JupyterLab® 和 Jupyter® 徽标是 NumFOCUS 的商标或注册商标。
所有引用的第三方商标(包括徽标和图标)仍归各自所有者所有。 不暗示任何附属关系或认可。