注意:以下翻译的准确性尚未经过验证。这是使用 AIP ↗ 从原始英文文本进行的机器翻译。
训练和交互模型
模型交互仅支持在 JupyterLab® 代码工作区中进行。
代码工作区允许您训练和发布模型,并导入它们以与先前发布的模型交互。
代码工作区要求您为工作区中引用的每个 Foundry 模型资产创建一个模型别名。模型别名充当特定模型的引用,允许您与模型交互以发布新版本或下载已保存的模型文件。
在模型选项卡中注册模型时,代码工作区会在工作区的/home/user/repo/.foundry文件夹中的隐藏文件中创建所选模型别名与 Foundry 模型唯一标识符之间的映射。
要了解如何从 Jupyter® 笔记本发布模型,请查看模型集成文档。
将模型添加到工作区
模型可以在模型侧边栏面板中创建或导入到工作区。
要创建新模型,请打开模型侧边栏面板并选择添加 > 创建新模型。这将引导您完成创建新模型、注册别名,并提供发布模型的代码片段。这还将生成一个骨架模型适配器Python 文件,必须实现此文件以将模型发布回 Foundry。
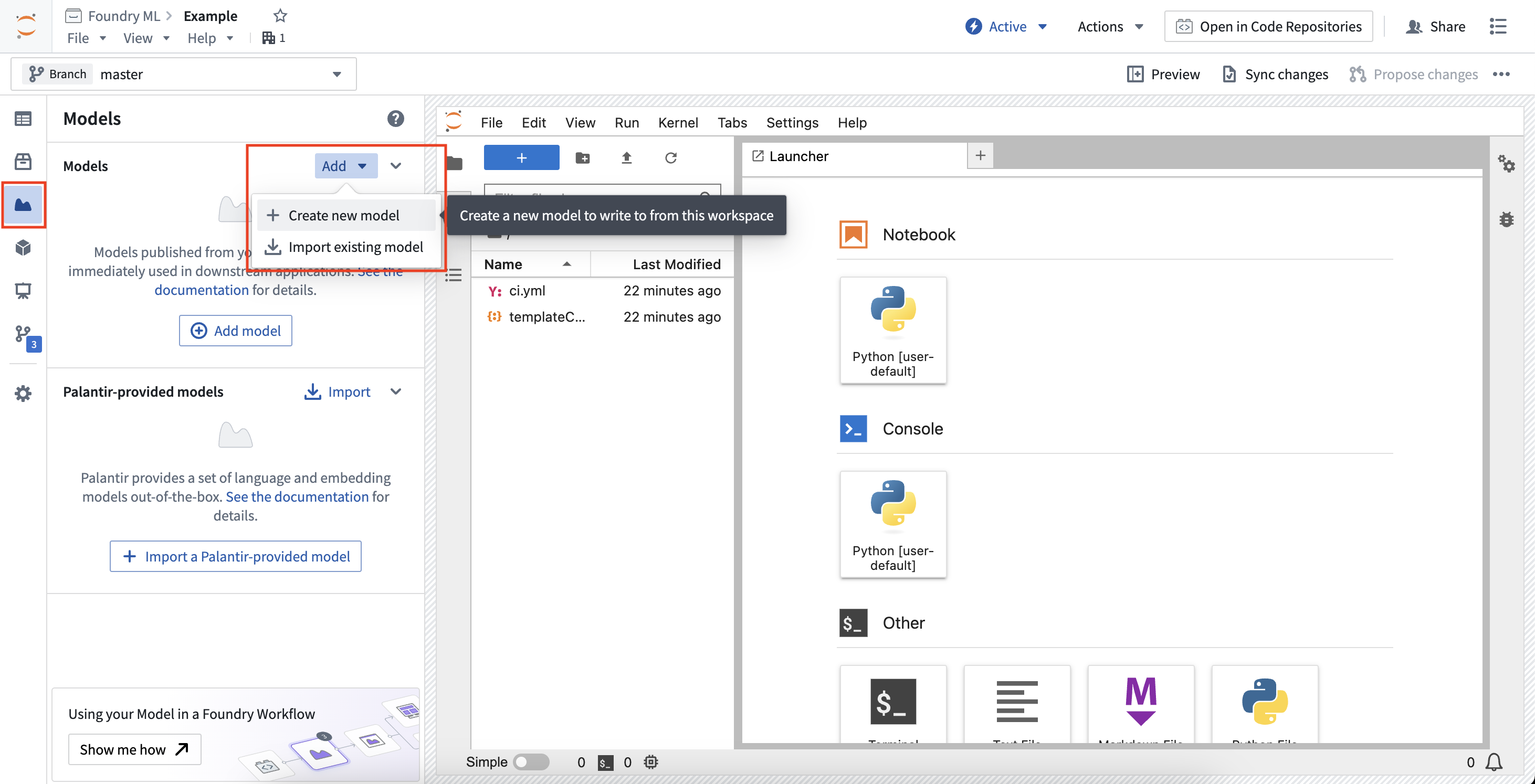
要导入现有模型,请打开模型侧边栏面板并选择添加 > 导入现有模型。这将引导您完成导入模型和注册别名,并提供下载已保存模型状态文件的代码片段。
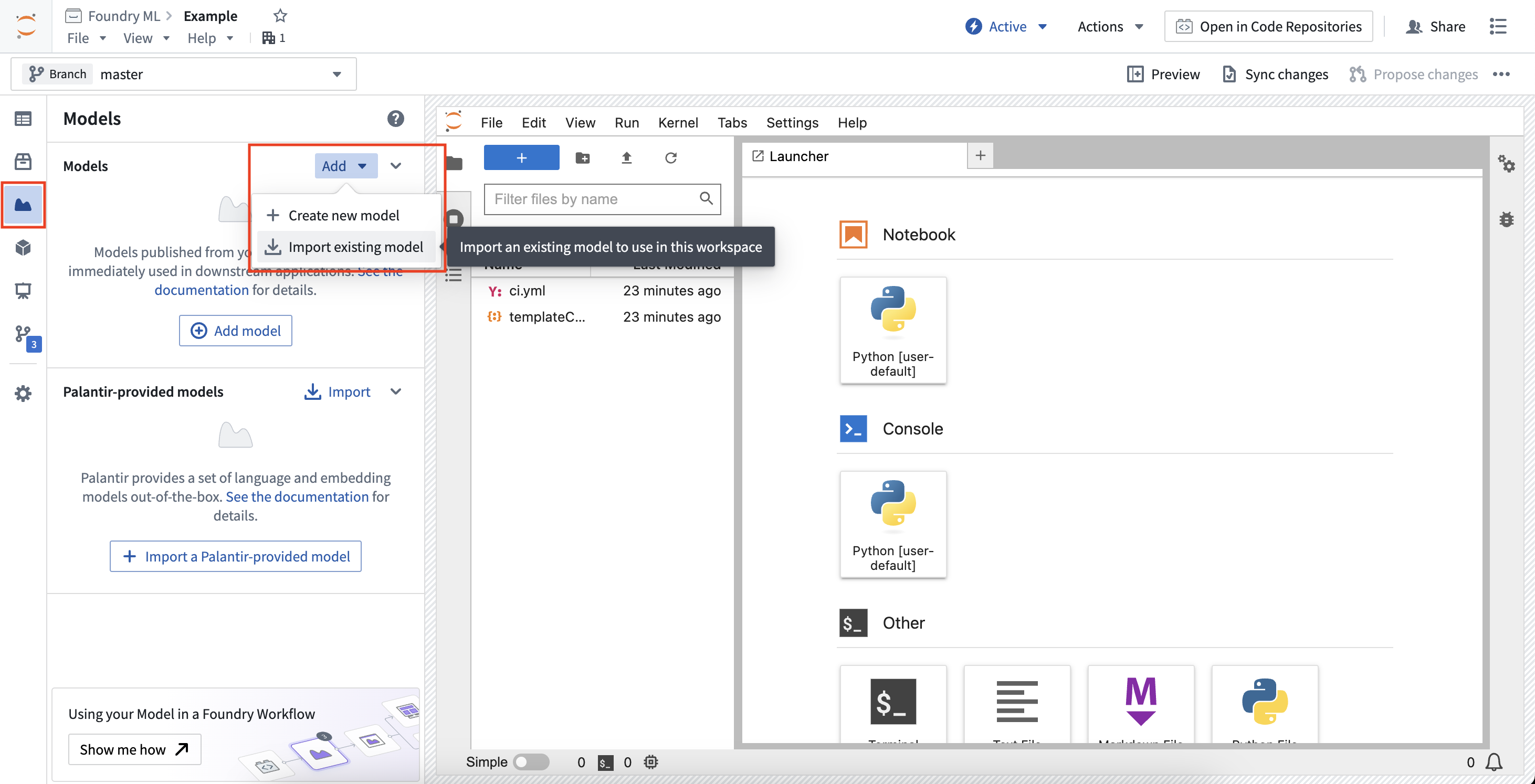
导入的模型从给定的模型版本加载序列化的模型状态。代码工作区提供不同的控件来选择在导入模型时使用哪个模型版本,允许您选择当前工作区分支上的最新版本、提供的分支上的最新版本或指定的模型版本。
可用代码片段
模型侧边栏面板提供可复制粘贴到笔记本中的常见工作流代码片段。所有代码片段都会指导您安装palantir_models和palantir_models_serializers,它们是 Palantir 提供的用于开发和交互模型的库。
侧边栏中的每个模型卡片都会创建特定于该模型的唯一代码片段。选择模型卡片将展开卡片,并显示一个选择器以选择显示特定任务的代码片段。
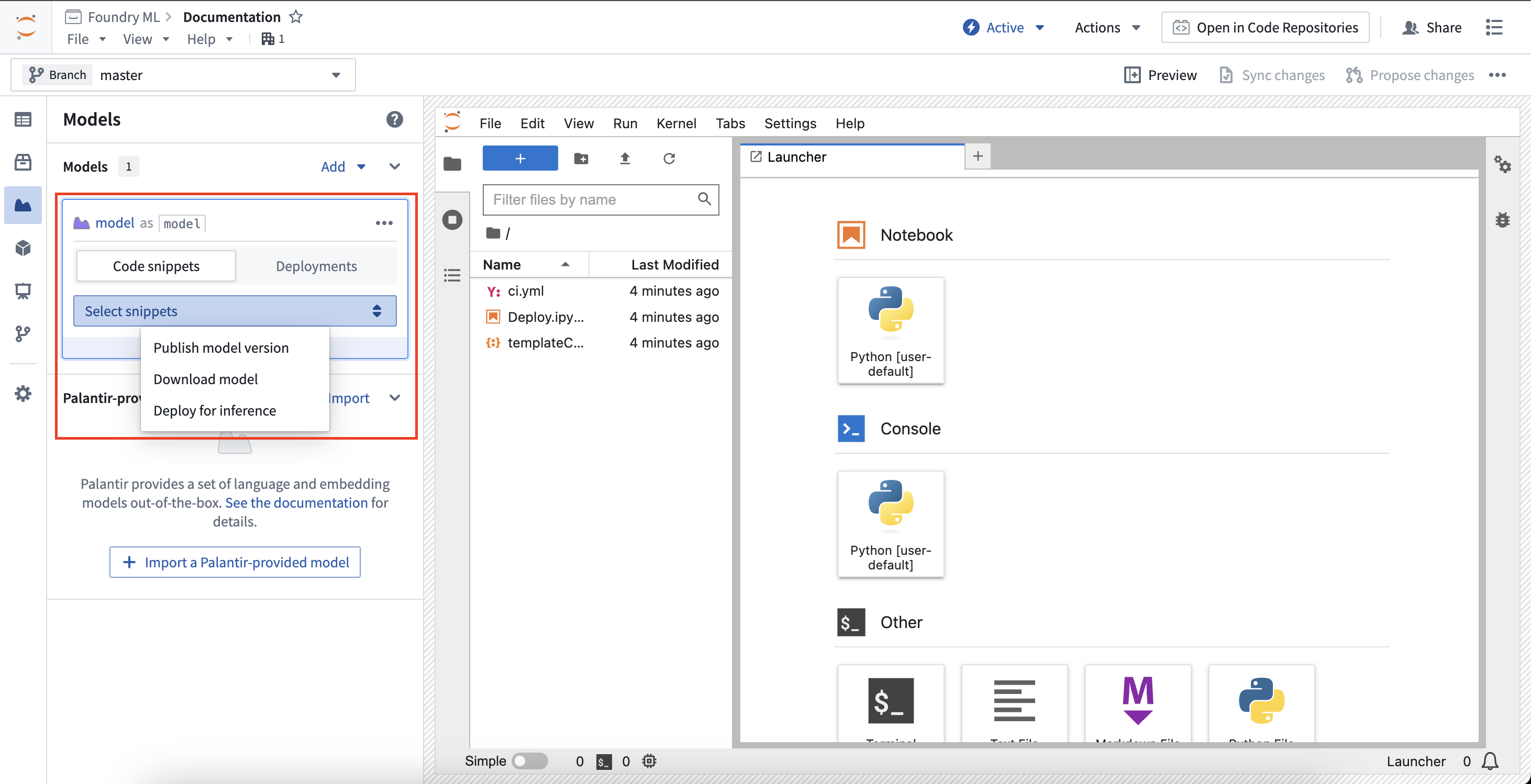
发布模型版本
要发布模型版本,您必须首先开发模型适配器。对于在代码工作区内创建的模型,将为您创建一个骨架适配器,以在与模型别名相同的 Python 文件中实现。模型卡片将提供有关开发您的模型适配器和将模型发布回 Foundry的详细说明。
下面的代码片段是用于别名为linear_regression_model的模型的。假设已在linear_regression_model_adapter.py中编写了模型适配器,模型发布代码应如下所示:
Copied!1 2 3 4 5 6 7 8 9 10 11from palantir_models.code_workspaces import ModelOutput # Model adapter api 已在 linear_regression_model_adapter.py 中定义 from linear_regression_model_adapter import LinearRegressionModelAdapter # sklearn_model 是在另一个单元格中训练的模型 linear_regression_model_adapter = LinearRegressionModelAdapter(sklearn_model) # 创建 ModelOutput 实例并发布适配器模型 model_output = ModelOutput("linear_regression_model") model_output.publish(linear_regression_model_adapter)
下载模型
要下载以前已发布的模型版本,将代码片段选择器更改为 下载模型。这将提供解决模型版本的控件,用于控制下载模型文件时使用的模型版本。
- 当前分支上的最新版本: 选择的模型版本将是当前工作区分支上的最新版本。
- 分支上的最新版本: 选择的模型版本将是所选分支上的最新版本。
- 特定模型版本: 选择的模型版本将固定为给定的模型版本RID。
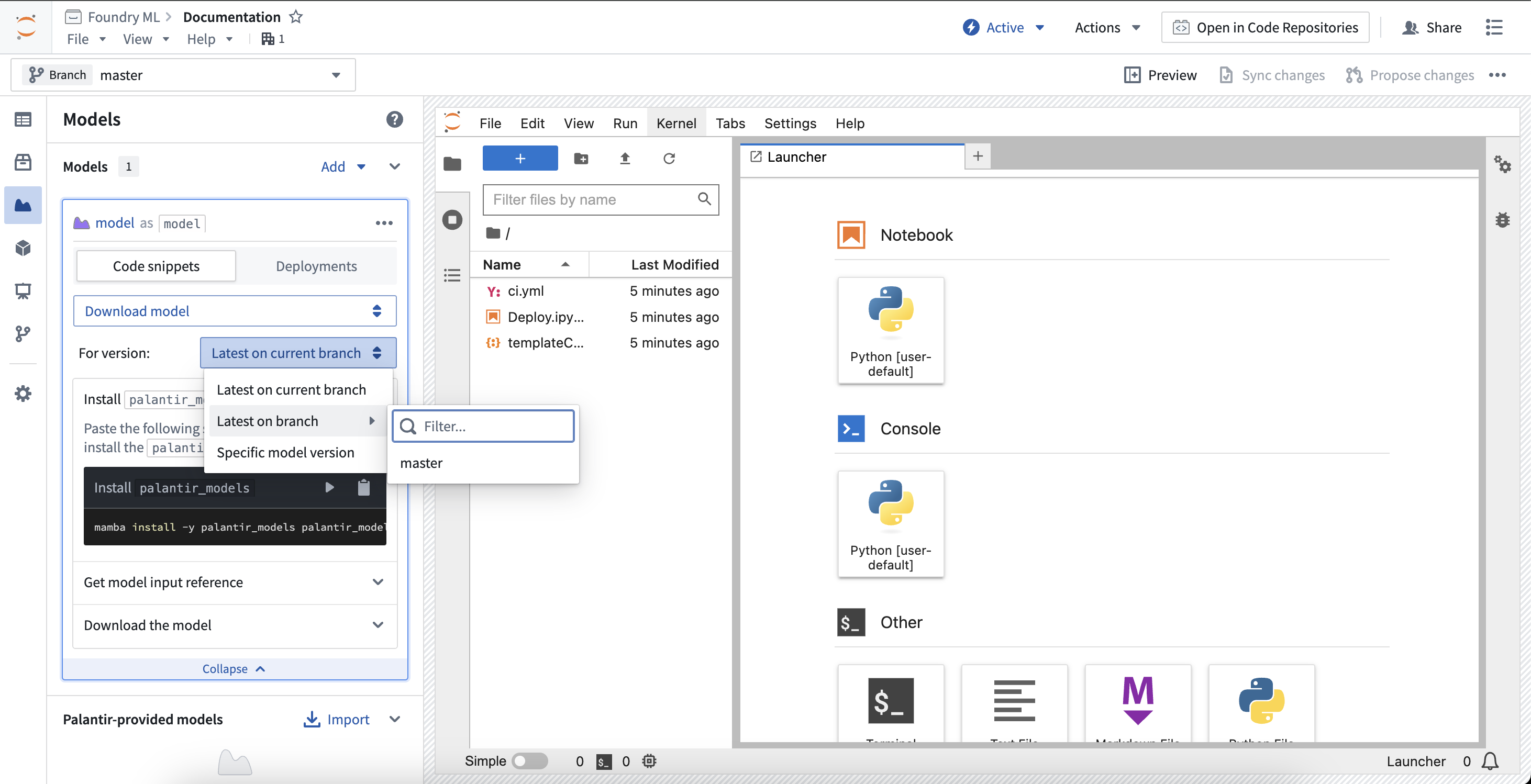
代码片段将自动更新以支持所选的模型版本解决控件。查看下面的ModelInput类文档以了解更多信息。
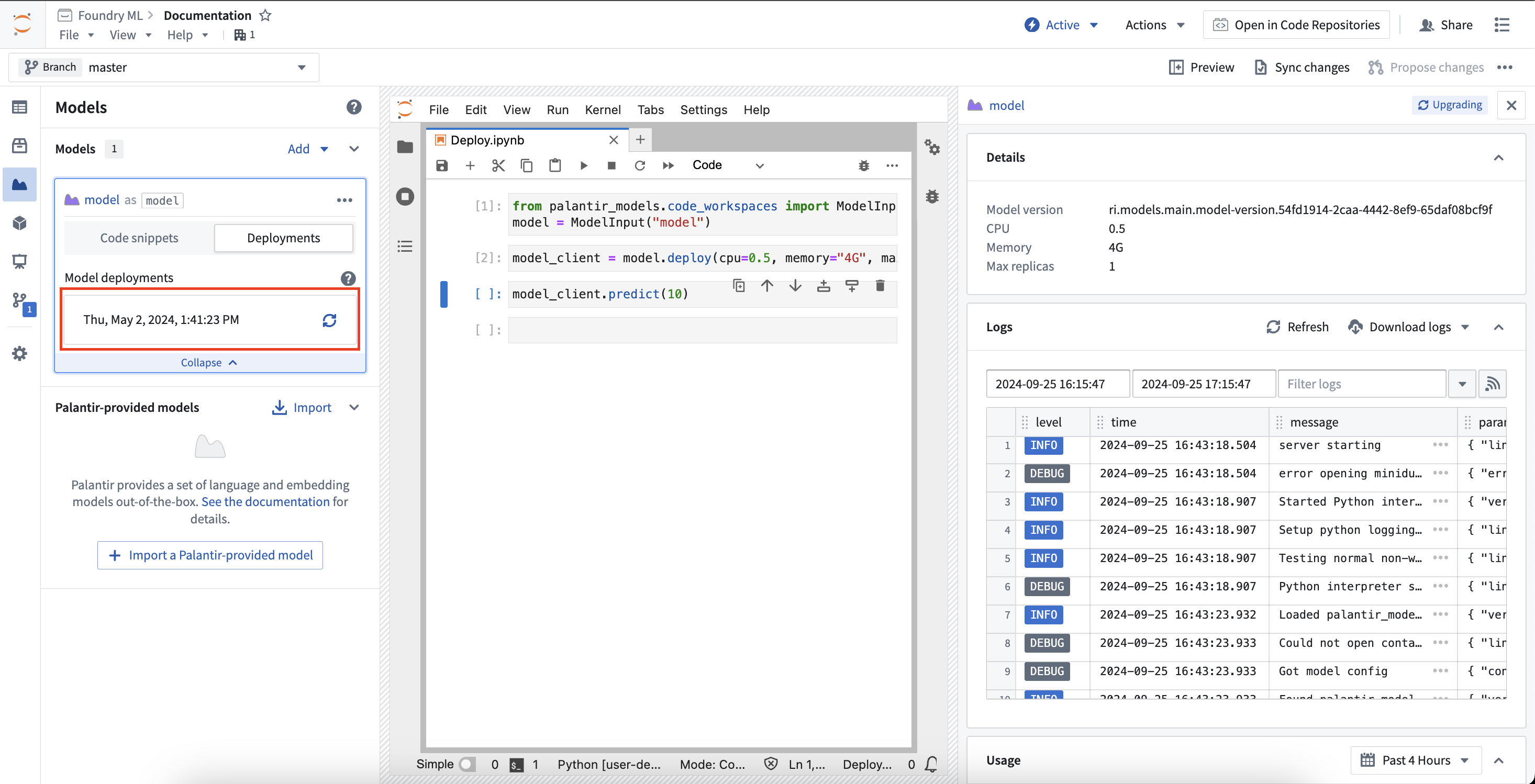
部署模型以进行推理
模型可以在Code Workspaces中部署以进行推理。这些部署是按模型版本共享的,这意味着一个给定的模型版本最多可以有一个关联的部署,并且这些部署与现有的模型目标实时部署和模型部署完全分开。部署可以通过代码完全配置,并且具有一个默认的扩展策略,即在20分钟内无使用后关闭部署。
要加载给定模型版本的部署,使用选择代码片段下拉菜单,并将选项更改为部署以进行推理。这将加载用于部署模型的代码片段,并显示与选择模型版本的下载文件选项相同的选择器。代码片段将逐步引导完成模型的部署并对其进行推理。
要在Code Workspaces中监控部署,展开您正在处理的模型的卡片并选择部署。在部署选项卡中,将提供已部署模型版本的列表。选择一个模型版本将会在右侧展开一个新面板,其中包含有关部署的信息,例如使用的资源、日志等。
请参阅下面的ModelInput类文档以了解更多信息。
开发模型适配器
模型适配器用于指导Foundry如何在平台上保存、加载和执行模型。在发布模型时,必须使用模型适配器包装模型。
在Code Workspaces中,模型适配器必须在单独的.py文件中定义。当一个新模型被添加到工作区时,会根据给定的别名生成一个文件。例如,如果别名是my_model,则会生成一个名为my_model_adapter.py的文件,其中包含一个名为MyModelAdapter的骨架模型适配器类。
模型面板中提供的代码片段是在假设别名、文件名和类名匹配的情况下生成的。如果文件被移动或适配器类被重命名,您可能需要对生成的代码片段进行手动编辑。
模型输出类
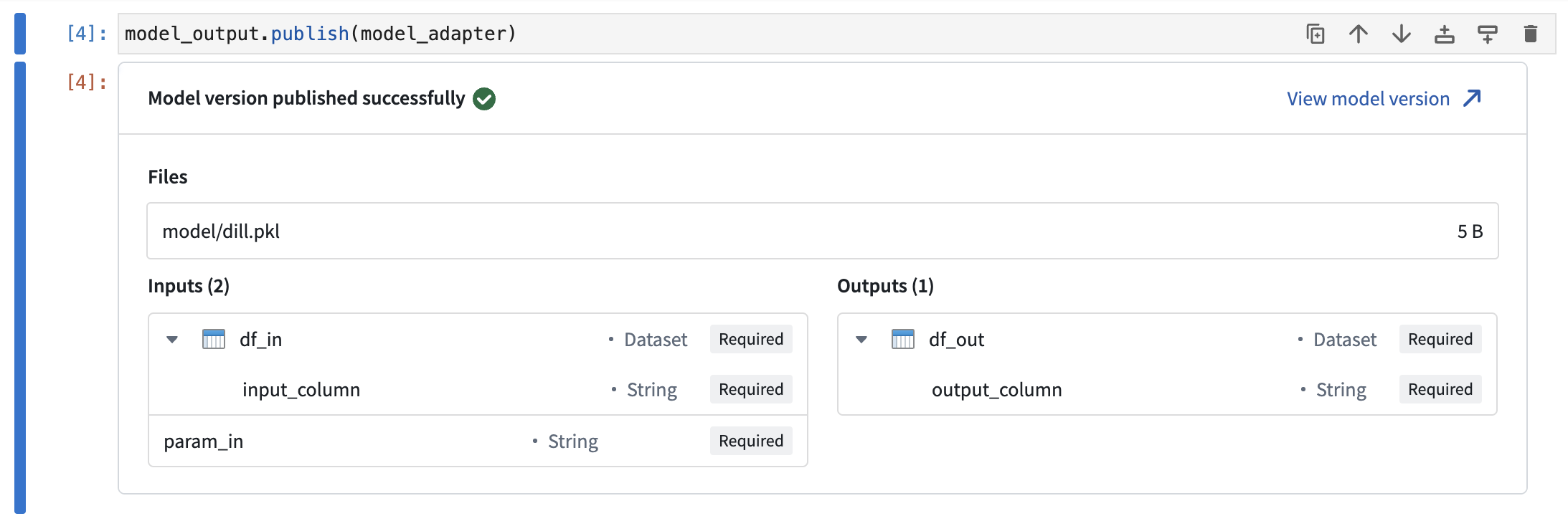
从palantir_models.code_workspaces导入的ModelOutput类为您的Foundry模型提供了一个可写的引用。要发布您的模型,您必须将模型包装在一个模型适配器中,并通过publish方法传递给引用。
调用publish方法将模型保存为一个新模型版本。如果model_output.publish方法调用是任何Jupyter® notebook单元中的最后一行,将显示一个预览窗口,确认模型已成功发布。
模型输入类
从palantir_models.code_workspaces导入的ModelInput类为您的Foundry模型提供了一个轻量级的可读引用,这允许读取已发布模型的序列化状态并在本地部署模型以进行推理。下面的代码展示了如何获取别名为my_model的模型的可读引用,并获取test分支上的最新模型版本的示例:
Copied!1 2 3from palantir_models.code_workspaces import ModelInput # 创建一个 ModelInput 实例,别名为 "my_alias",分支为 "test" my_model_input = ModelInput("my_alias", branch="test")
下载模型
ModelInput允许下载在模型发布时存储的序列化模型权重。
Copied!1 2 3 4 5 6from palantir_models.code_workspaces import ModelInput # 获取最新的模型版本 my_model_input = ModelInput("my_alias") # 下载文件 my_model_input.download_files()
这将返回一个路径,指向下载文件的临时目录。
初始化模型适配器
对于涉及模型微调/重新发布的工作流,通常能够下载模型文件并将其加载到适配器中是很有用的。如果工作区有用于发布模型的适配器的本地副本,或者适配器来自共享适配器包,并且您已将其添加为工作区中的依赖项,则可以加载适配器,并像在其他地方一样使用适配器。
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13# 在这个例子中,适配器位于本地的 Python 文件 `my_adapter_file.py` 中 from my_adapter_file import MyAdapter from palantir_models.code_workspaces import ModelInput # 创建一个 ModelInput 实例,传入别名和模型版本 my_model_input = ModelInput("my_alias", model_version="ri.models.main.model-version...") # 初始化适配器 initialized_adapter = my_model_input.initialize_adapter(MyAdapter) # 现在初始化的适配器可以通过 `ModelOutput` 重新发布,或者你可以访问存储在适配器中的 Python 对象 # 例如,如果有一个变量 `pipeline` 保存了一个 Huggingface pipeline。注意,这段代码会根据你的适配器定义而有所不同。 pipeline = initialized_adapter.pipeline
部署模型以进行推理
模型也可以在代码工作区内部署以进行推理。这些部署是按模型版本共享的,因此多个同时使用相同模型版本的会话将向同一部署发送请求。
要与模型部署进行交互,您必须为该模型获取一个部署客户端。
Copied!1 2 3 4 5 6 7from palantir_models.code_workspaces import ModelInput # 创建一个模型输入实例,使用别名 "my_alias" my_model_input = ModelInput("my_alias") # 部署客户端,指定使用的CPU为2,内存为8G,最大副本数为1 deployment_client = my_model_input.deploy(cpu=2, memory="8G", max_replicas=1)
部署客户端有多种方法可用于控制部署。
Copied!1 2 3 4 5 6 7 8 9 10 11# 等待模型准备就绪 client.wait_for_readiness() # 调整部署的规模 client.scale(cpu=4) # 运行推理 client.predict(...) # 手动关闭(部署将在20分钟无使用后自动关闭) client.disable()
变换
生成模型输出的Jupyter®笔记本也可以用于从Code Workspaces创建的变换中。请按照以下步骤为模型输出注册一个变换:
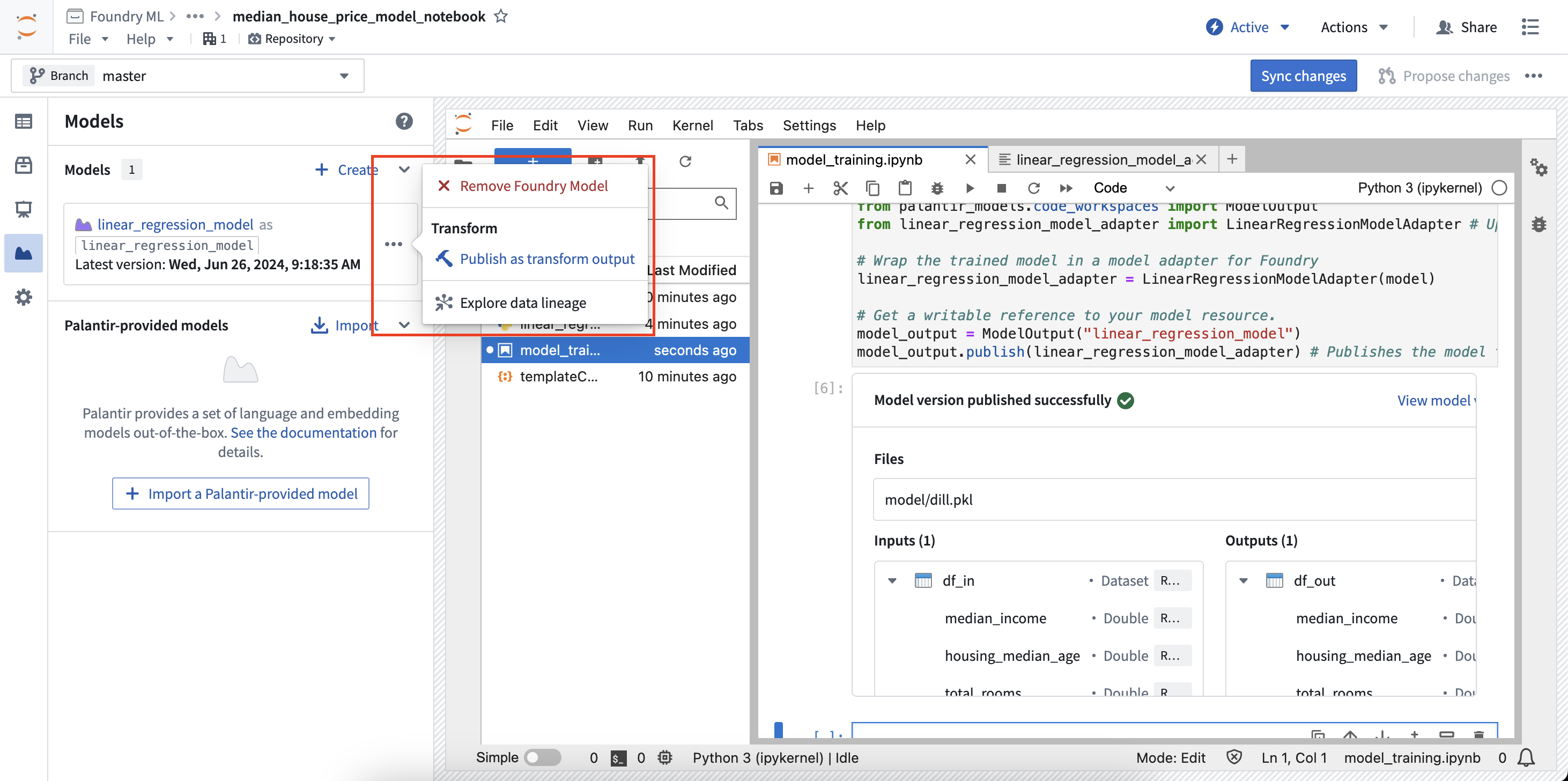
- 在模型面板中,找到您想要从变换中输出的模型卡片,然后在菜单中选择发布为变换输出。
- 在创建变换面板中,您可以配置要执行的文件以及变换所需的输入和输出。在下面的示例中,训练数据用作输入,而测试数据集和模型用作输出。
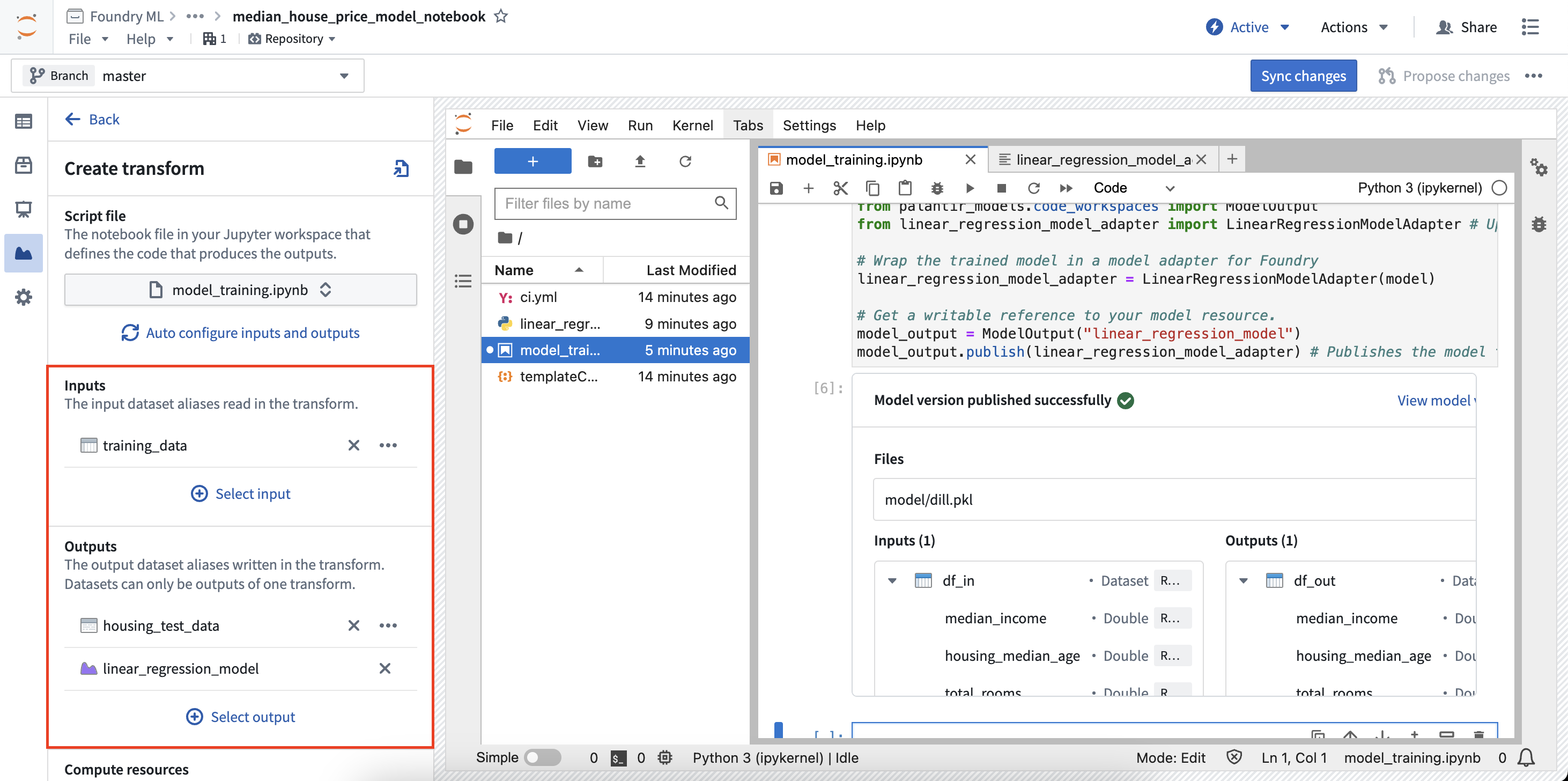
- 一旦配置了输入和输出,选择配置页面底部的同步并运行以保存您当前的代码更改并创建变换。变换将开始运行,任务的状态将与相关的数据集和模型一起显示在模型面板中。
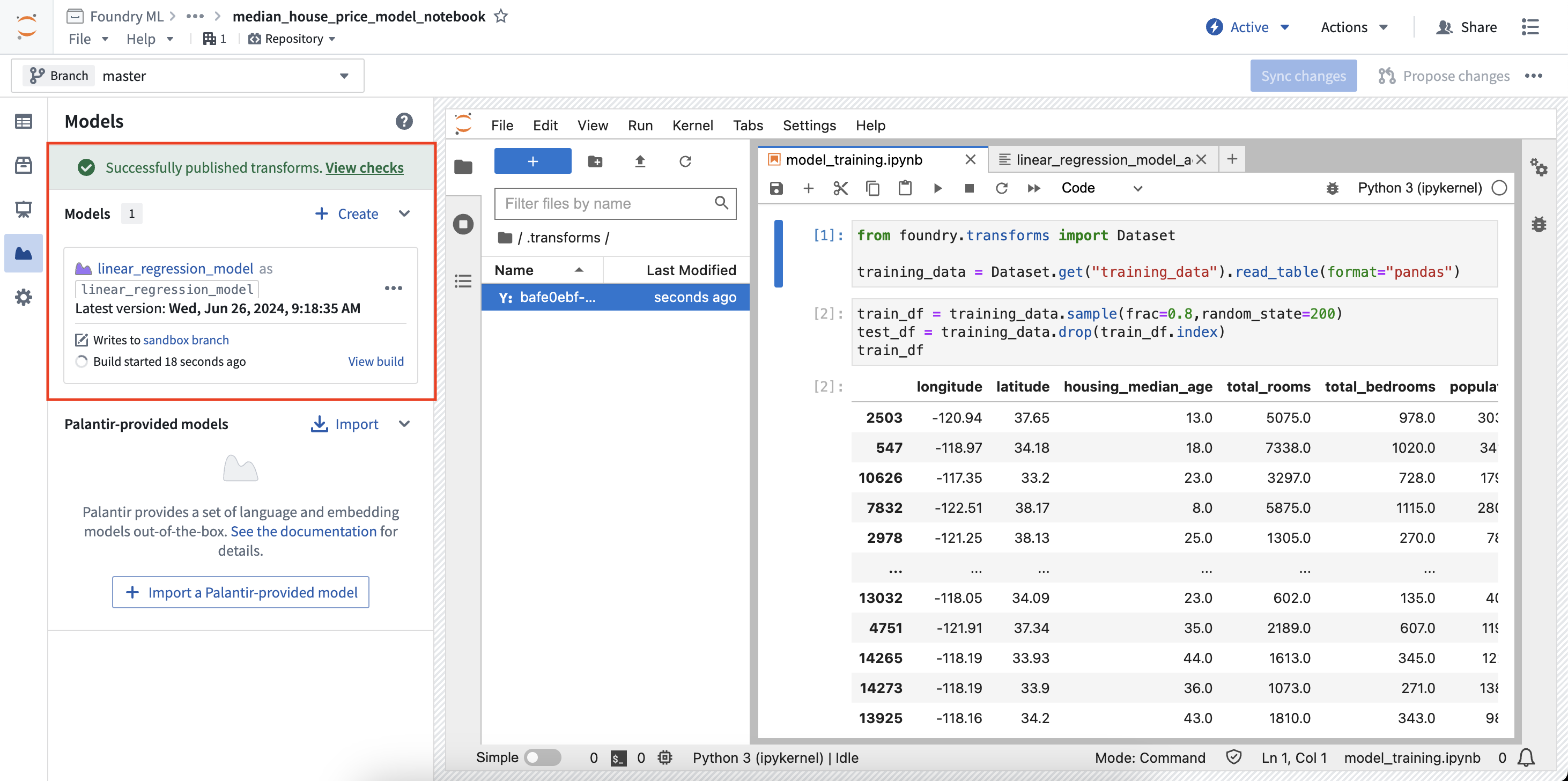
然后您可以选择查看搭建以查看正在运行的变换任务。如果您对笔记本代码进行了更改并希望重新搭建模型,请在模型卡片中选择重建以重新运行搭建。通过变换创建的模型和数据集可以像平台其他地方创建的变换一样进行调度。了解更多关于调度变换的信息。
Jupyter®、JupyterLab®和Jupyter®标志是NumFOCUS的商标或注册商标。
所有引用的第三方商标(包括标志和图标)仍为其各自所有者的财产。不暗示任何隶属关系或认可。