注意:以下翻译的准确性尚未经过验证。这是使用 AIP ↗ 从原始英文文本进行的机器翻译。
计算模块使用和定价
计算模块功能处于测试版,可能并未在所有注册中可用。如果您的注册中有计算模块,请导航至计算模块应用程序以获取最新文档。
计算模块功能使您能够部署交互式容器。要了解它们的计算使用情况,您需要知道这些部署可以水平自动扩展和缩减,甚至可能在没有请求的情况下由于预测自动扩展而进行扩展。您可能会在点击搭建并部署运行时随时消耗使用量。
任何运行时消耗的计算使用量将归因于计算模块本身。计算使用量在您有一个“副本”起始或运行时消耗,而在您没有副本起始或运行时不消耗。消耗多少使用量取决于副本数量及其随时间的资源使用情况。
为了最好地理解您的使用情况,您应该知道一个计算模块可以有多个副本,每个副本可以有多个容器。
定价
计算模块使用情况以 Foundry 计算秒为单位进行跟踪(参见使用类型)。只要一个副本正在起始或处于活动状态,就会测量计算秒。计算秒使用的判断有几个因素:
- 每个副本的 vCPU 数量
- 每个副本的 RAM GiB 数量
- 每个副本的 GPU 数量
- 副本数量
- 任何给定时间的副本数量是动态的,但它们都有相同的资源配置
在为 Foundry 使用付费时,默认使用费率如下:
| vCPU / GPU | 使用费率 |
|---|---|
| vCPU | 0.2 |
| T4 GPU | 1.2 |
| V100 GPU | 3 |
| A10G GPU | 1.5 |
如果您与 Palantir 签订了企业合同,在进行计算使用量计算之前,请联系您的 Palantir 代表。
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13# 计算虚拟CPU使用秒数 vcpu_compute_seconds = max(vCPUs_per_replica, GiB_RAM_per_replica / 7.5) * num_replicas * vcpu_usage_rate * time_active_in_seconds # vCPUs_per_replica: 每个副本的虚拟CPU数量 # GiB_RAM_per_replica: 每个副本的内存(以GiB为单位) # num_replicas: 副本的数量 # vcpu_usage_rate: 虚拟CPU的使用率 # time_active_in_seconds: 活跃时间(以秒为单位) # 公式说明: # 1. 计算每个副本的虚拟CPU需求,取虚拟CPU数量和内存需求(以每7.5 GiB内存等效一个vCPU)中的较大值。 # 2. 乘以副本数量,得到总的虚拟CPU需求。 # 3. 乘以虚拟CPU的使用率和活跃时间,得到总的虚拟CPU使用秒数。
以下公式计算GPU计算秒数:
Copied!1 2 3 4 5 6 7# 计算 GPU 使用的总秒数 # GPUs_per_replica: 每个副本使用的 GPU 数量 # num_replicas: 副本的数量 # gpu_usage_rate: GPU 使用率 # time_active_in_seconds: 活动时间(秒) gpu_compute_seconds = GPUs_per_replica * num_replicas * gpu_usage_rate * time_active_in_seconds
计算模块的扩展配置
您可以直接在我们的配置页面上配置允许的副本数量的最小值和最大值。
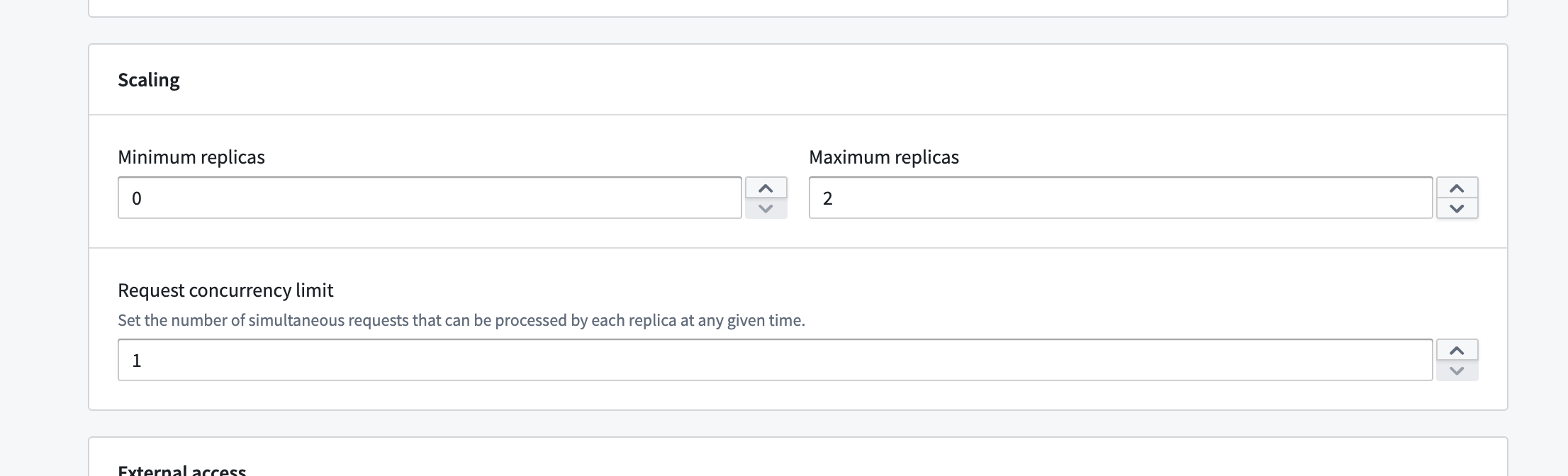
此范围允许您对自动水平扩展有一定的控制。基本上,我们可以在您配置的范围内随时扩展到任意数量的副本。您还可以设置每个副本的并发限制,这将对扩展产生影响。较低的并发限制可能会在相同负载下导致更积极的水平扩展。
如果您将最小副本数设置为非零值,即使您未主动使用您的部署,您也将消耗计算使用量。如果将最小值设置为零,并且在一段时间内没有请求发送到您的部署,我们可以缩减到零,在这种情况下您将不会消耗使用量。然而,我们会在首次部署时立即从零扩展,并在我们预测可能有负载时立即扩展。
计算模块具有预测扩展功能,我们会跟踪您的部署的历史查询负载,并尝试预先扩展以满足预测的需求。如果我们的预测不准确,我们将使用它来优化我们的下次预测,并且我们将相对快速地缩减。此系统会遵循您配置的最大副本数量,因此您应随着时间的推移监控您的部署扩展并相应调整您的扩展设置。
计算模块的资源配置
计算模块接口使您能够为每个副本基于每个容器配置资源。CPU、内存和GPU资源请求和限制都可以为每个副本配置。
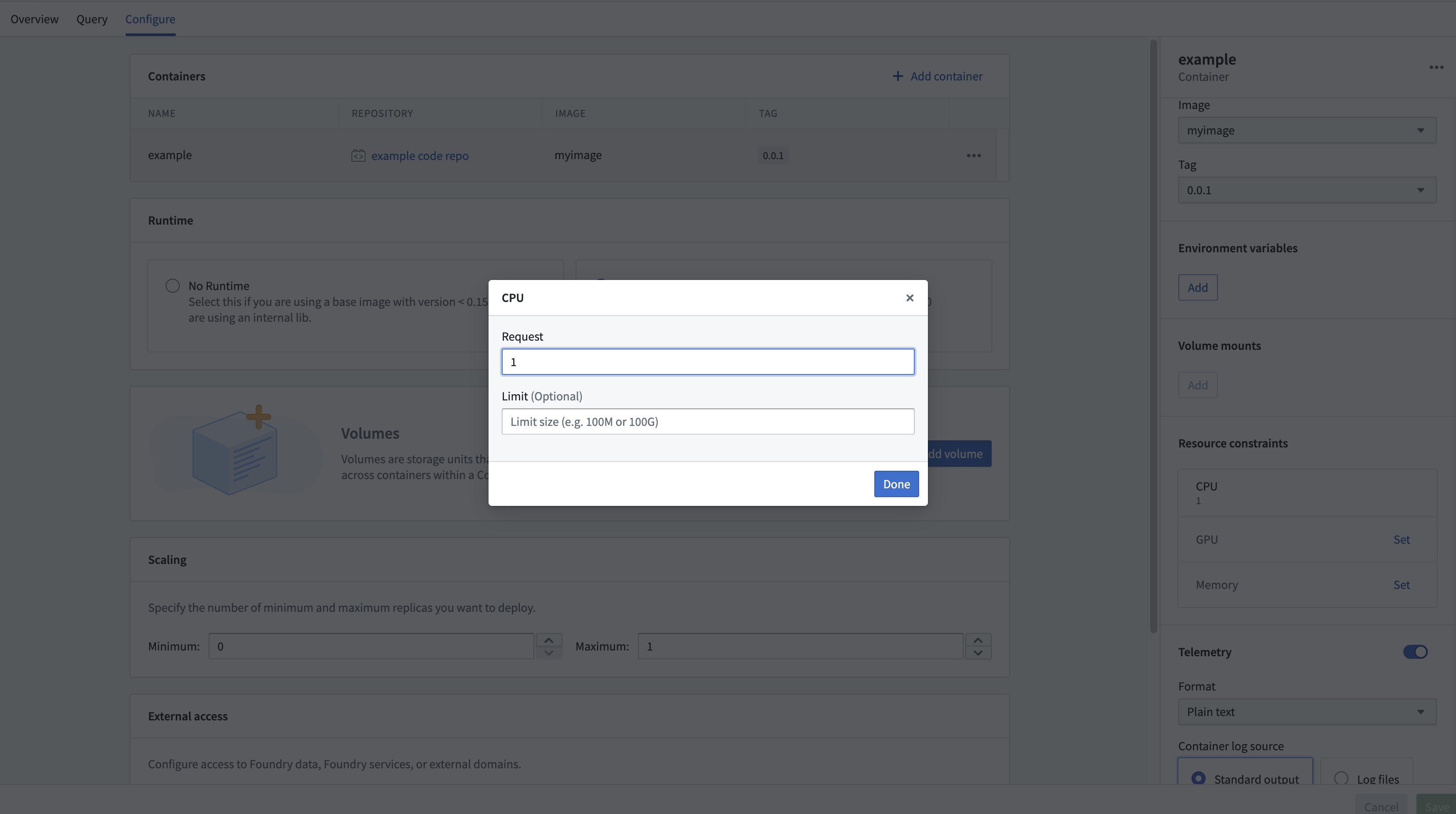
设置这些资源是非必填的;如果没有配置,副本将默认为1个vCPU、4 GB内存和无GPU。每个副本将请求配置的资源量,并在设置限制时遵循限制。这意味着如果您使用默认资源(1个vCPU和4 GB内存且无限制),并且您有四个副本,您可能会消耗4个vCPU和16 GB内存(尽管根据请求负载,您可能会消耗更多或更少)。