注意:以下翻译的准确性尚未经过验证。这是使用 AIP ↗ 从原始英文文本进行的机器翻译。
面板描述
在 Contour 中的探索和分析是通过一系列的面板来进行的。一些面板创建图表或执行计算,而另一些则用于通过筛选、删除列等来操作您的数据集。
使用此摘要表中的链接在本页面的不同面板类型之间导航。
| 面板 | 描述 | 可视化 | 筛选行 | 聚合 | 操作列 | 删除重复项 |
|---|---|---|---|---|---|---|
| 总结 | 报告表的行数。 | 是 | 否 | 否 | 否 | 否 |
| 筛选 | 通过数值、文本或日期时间值筛选数据集。 | 否 | 是 | 否 | 否 | 是 |
| 表达式 | 使用表达式语言派生新列或执行复杂筛选。 | 否 | 是 | 否 | 是 | 否 |
| 表格 | 查看原始数据的一部分,探索模式并计算数据覆盖指标。 | 是 | 否 | 否 | 否 | 否 |
| 直方图 | 创建数据的直方图并筛选到特定组。 | 是 | 是 | 是 | 是,通过 Pivot 选项 | 否 |
| 分布 | 创建数据的分布图。 | 是 | 是 | 否 | 否 | 否 |
| 时间序列 | 创建 x 轴为日期/时间的图表并筛选到特定组。 | 是 | 是 | 否 | 否 | 否 |
| 编辑列 | 合并、复制、删除、重命名或拆分列。 | 否 | 否 | 否 | 是 | 否 |
| 数据变换 | 模糊数据,查找并替换值,或解析日期。 | 否 | 否 | 否 | 是 | 否 |
| 图表 | 创建可自定义的多层图表。 | 是 | 是 | 是 | 否 | 否 |
| 网格 | 创建两个分类列的矩阵。单元格可以被筛选,并显示为热图。 | 是 | 是 | 否 | 否 | 否 |
| 热图 | 查看基于坐标数据的热图。 | 是 | 是 | 否 | 否 | 否 |
| 透视表 | 为一个或多个指标创建透视表。 | 是 | 是 | 是 | 是,通过 Pivot 选项 | 否 |
| 列编辑器 | 派生新列或移除不必要的列。 | 否 | 否 | 否 | 是 | 是 |
| 多列编辑器 | 重命名、删除、重新排序列,或删除数据中的重复行。 | 否 | 否 | 否 | 否 | 否 |
| 丰富 | 使用另一个数据集丰富数据,并返回两个数据集的列。 | 否 | 否 | 否 | 是 | 是 |
| 链接 | 合并到另一个数据集,并返回该数据集的匹配记录。 | 否 | 否 | 否 | 是 | 是 |
| 集合数学 | 根据外部数据集保留、添加或删除行。 | 否 | 是 | 否 | 否 | 否 |
| 合并 | 执行策划的合并。 | 否 | 是 | 否 | 否 | 否 |
| 导出 | 以CSV或XLS格式导出最终筛选的观测集。 | 否 | 否 | 否 | 否 | 否 |
| 重新排序列 | 重新排序表中的列。 | 否 | 否 | 否 | 否 | 否 |
| 宏 | 将模板化变换应用于路径。 | 否 | 否 | 否 | 否 | 否 |
| 排序 | 基于一个或多个列对数据行进行排序。 | 否 | 否 | 否 | 否 | 否 |
| 计算 | 显示多个聚合计算。 | 是 | 否 | 是 | 否 | 否 |
| 逆透视 | 通过将一些列转为行来重塑数据。 | 否 | 否 | 否 | 是 | 否 |
总结
总结面板显示在路径中当前位置的表格中的行和列的数量。
如果您完全没有筛选数据,那么这就是起始集的行数。如果您应用了筛选(例如,通过添加直方图并选择某些条),这就是筛选后剩余的行数。
筛选
筛选面板的目的是在数据集上应用可自定义的筛选。虽然您也可以在其他面板(分布、直方图)中应用筛选,但筛选面板允许在一个地方搭建涉及多个变量的更复杂的筛选。
在筛选面板中使用列表类似于 SQL 中的 WHERE IN (x,y,z) 子句。Contour 可以处理筛选面板中成千上万项的列表。然而,庞大的列表会拖累浏览器,过大的列表可能会导致浏览器出错。在这些情况下,列表应作为单独的集合导入到 Contour,并通过链接或集合数学面板来实现筛选。了解如何使用链接或集合数学面板。
配置
点击 添加筛选,选择要筛选的列,然后从下拉菜单中选择筛选类型。根据您选择的列,Contour 会选择合适的筛选类别(例如,数值列选择数字)。
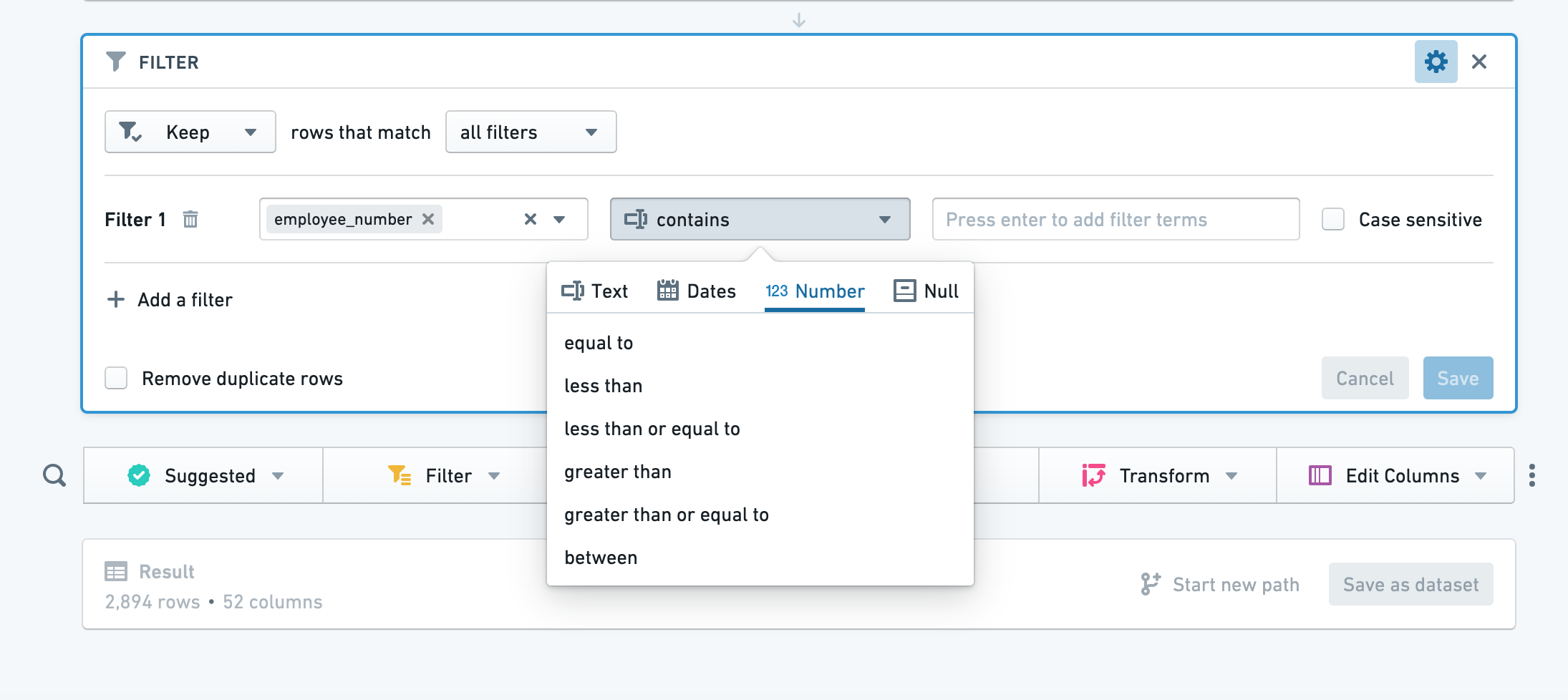
在某些文本筛选中,您可以使用通配符:* 可替换为多个字符,而 ? 可替换为单个字符。
在 "匹配"(正则表达式)文本筛选中,您可以直接输入正则表达式(不需要引号或字符串指示符)。
要添加另一个筛选,只需再次点击 添加筛选。您可以选择匹配 所有筛选 或 任意筛选。要删除筛选,点击筛选旁边的回收站按钮。 点击 保存 应用您的筛选。
文本筛选详情
当前文本筛选提供以下选项:
- 包含: 返回包含任何搜索词的行。搜索词应仅包含文本。例如,术语“hello”会匹配包含“hihellohi”的行。
- 包含(带通配符): 返回包含任何搜索词的行。搜索词可以包含
?表示单字符通配符,或 * 表示多字符通配符。例如,术语h?l*o会匹配“hi hello hi”或“hi halqqqqqo hi”。 - 等于: 返回等于任何搜索词的行。搜索词应仅包含文本。例如,术语
hello会匹配“hello”,但不匹配“hi hello hi”。 - 等于(带通配符): 返回等于任何搜索词的行。搜索词可以包含 ? 表示单字符通配符,或 * 表示多字符通配符。例如,术语
h?l*o会匹配“hello”或“halqqqqqo”。 - 匹配: 返回匹配任何术语的行,其中术语是正则表达式。此选项使用 Java Pattern ↗ 评估正则表达式。
表达式
除了直方图和图表等可视化工具外,Contour 还提供了一个表达式面板,允许您使用 Contour 丰富的表达式语言从数据中派生新列,执行复杂筛选或执行复杂聚合。
- 在使用表达式编辑器时,点击 ? 图标以快速参考表达式语言。
- 在输入时,建议的函数会在下拉列表中出现。点击或使用 Enter 键选择您想要的函数。
列名是区分大小写的。此外,在选择列时,您可以选择使用或不使用双引号来书写列名。例如,year("birthdate_col") 等价于 year(birthdate_col)。为了一致性,本文件中的列名均以双引号书写。
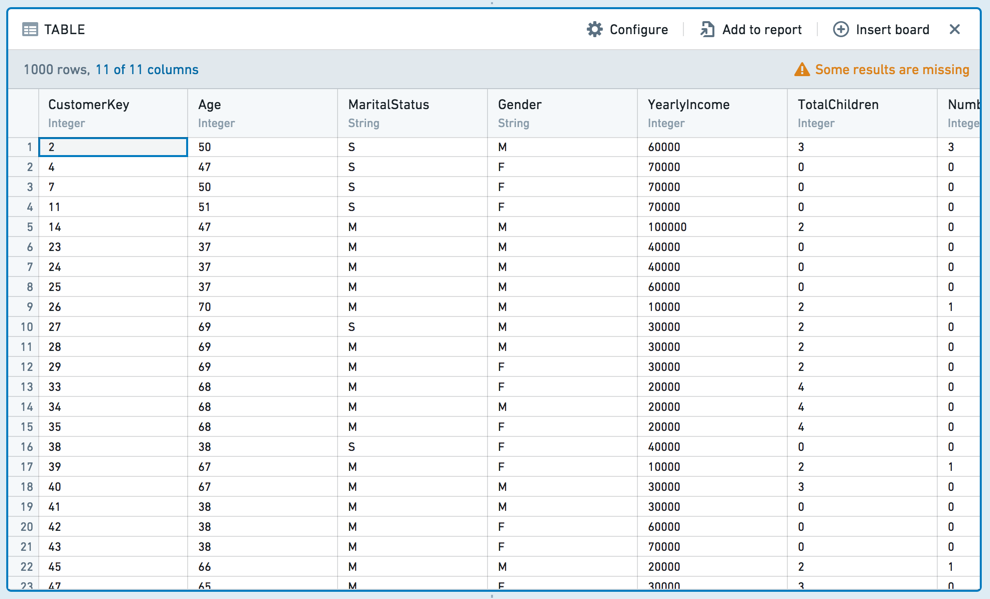
表格
表格面板以表格格式显示您的数据集快照。请注意,数据集中仅显示前 limit(默认:1,000)行。此限制存在以防止浏览器性能问题,通常不可配置。
表格面板对于快速检查数据是否符合预期非常有用。您可以与表格交互:拖放列以重新排序它们,或从每列的下拉菜单中选择。这些表格的格式更改不会更改底层数据(如果您仅查看部分列,所有列仍存在于底层数据中)。
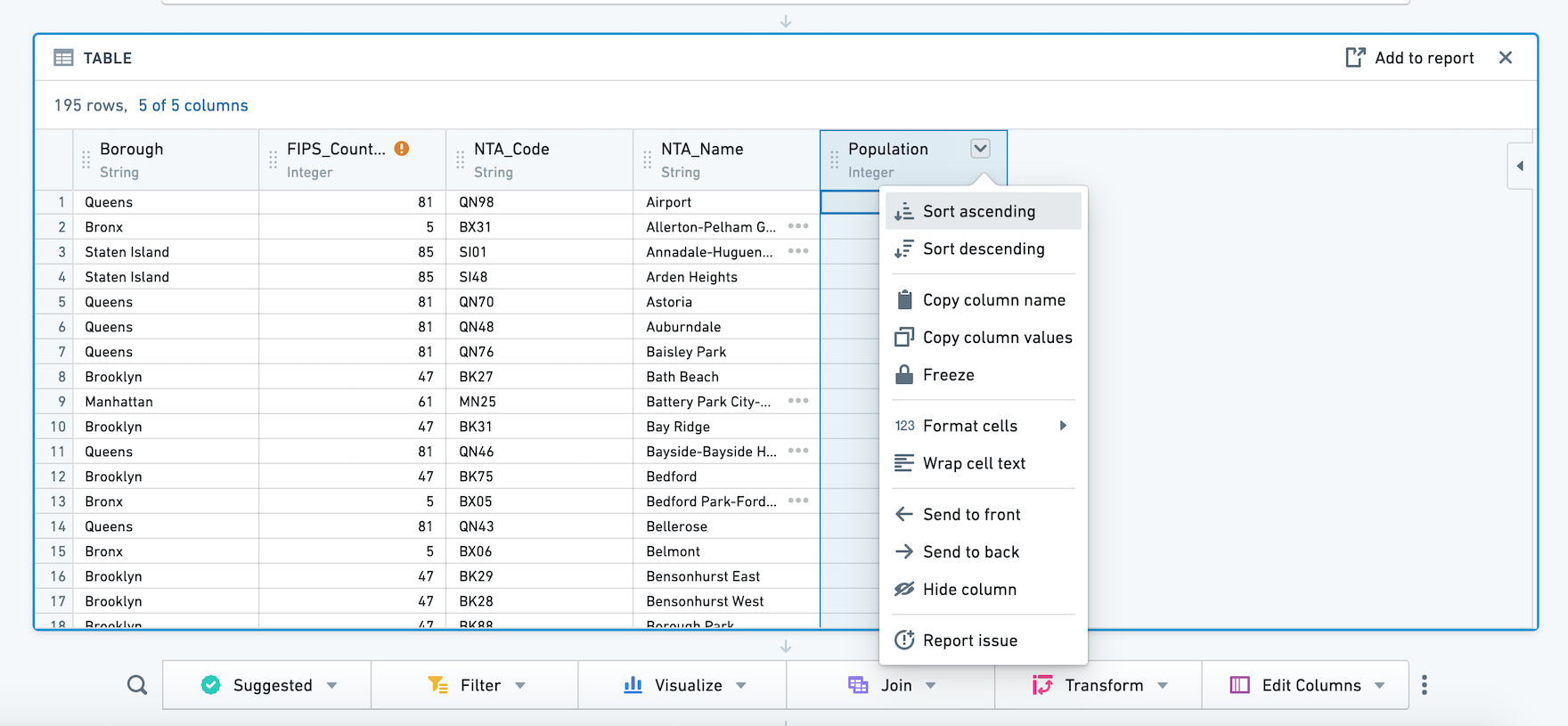
要一次移动多个列,请按住 Shift 键选择列。 您还可以使用 配置 面板一次修改多个列。
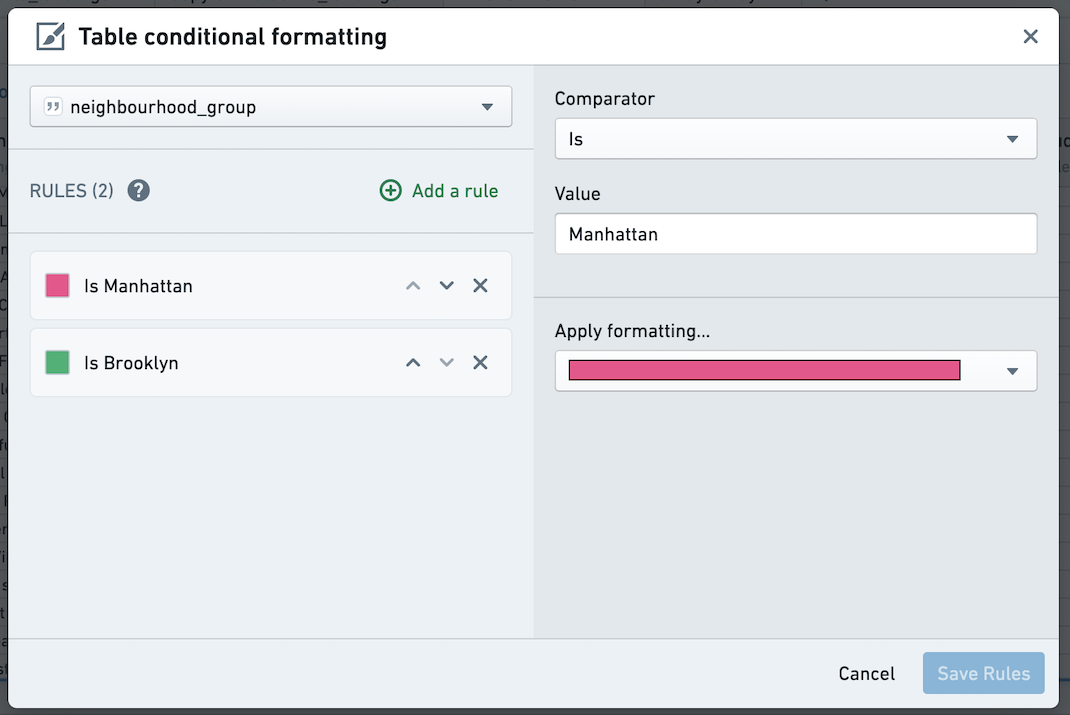
条件格式
您可以通过点击列下拉菜单向表格面板添加条件格式。
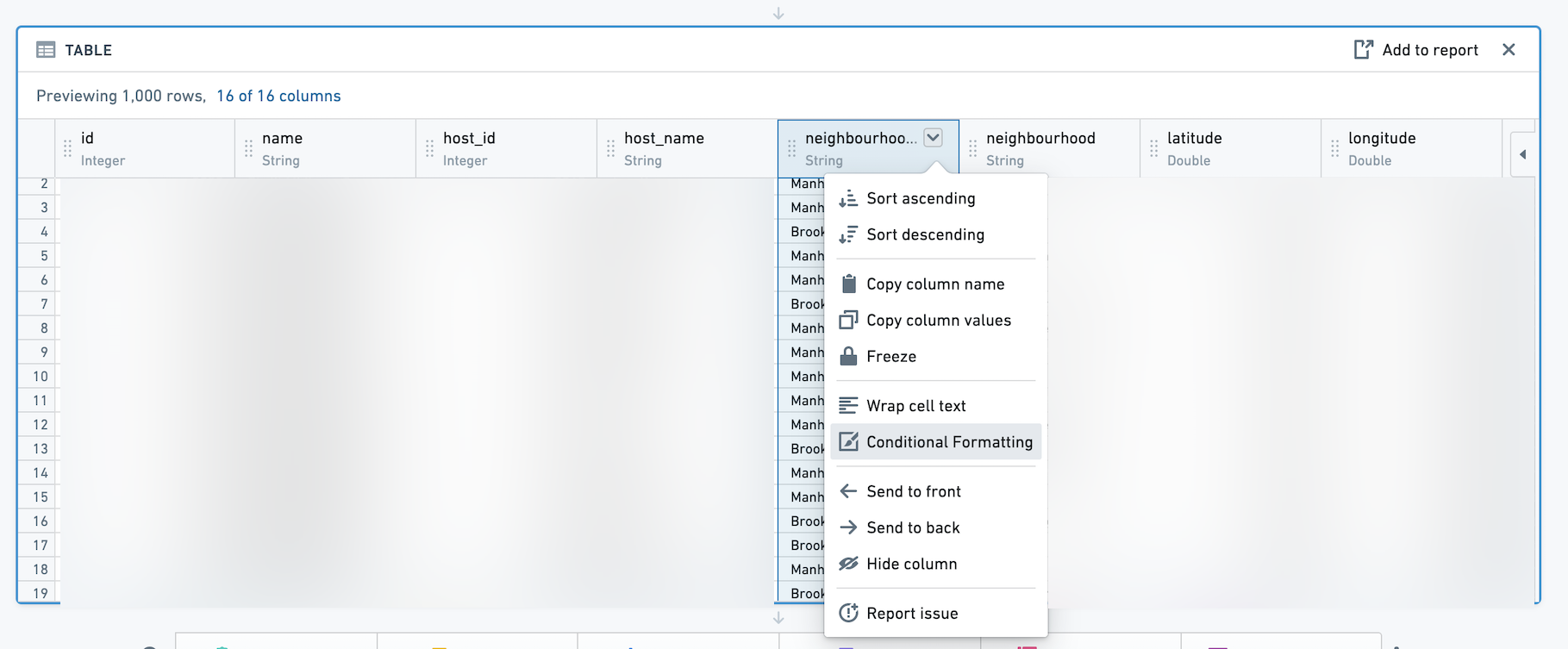
然后,使用对话框为给定列添加规则。条件格式化的单元格将以所选颜色显示文本和背景。日期列不支持规则。
表格面板 vs. 表格视图
您可以在路径中的任何一点添加表格面板,以快速预览数据,或者可以从路径视图切换到 表格视图。
表格视图使表格(而不是面板)成为焦点,因此您可以看到添加每个面板时数据的变化。这在编写表达式时特别有帮助。
您可以通过点击右上角的 表格 切换到表格视图。再次点击按钮或点击 隐藏表格 返回路径视图。
表格视图不支持条件格式。
直方图
直方图面板汇总给定列中的不同值,并将结果显示为条形图。
例如,下面的直方图计算出根据纽约哪个社区开始的出租车行程的平均长度。
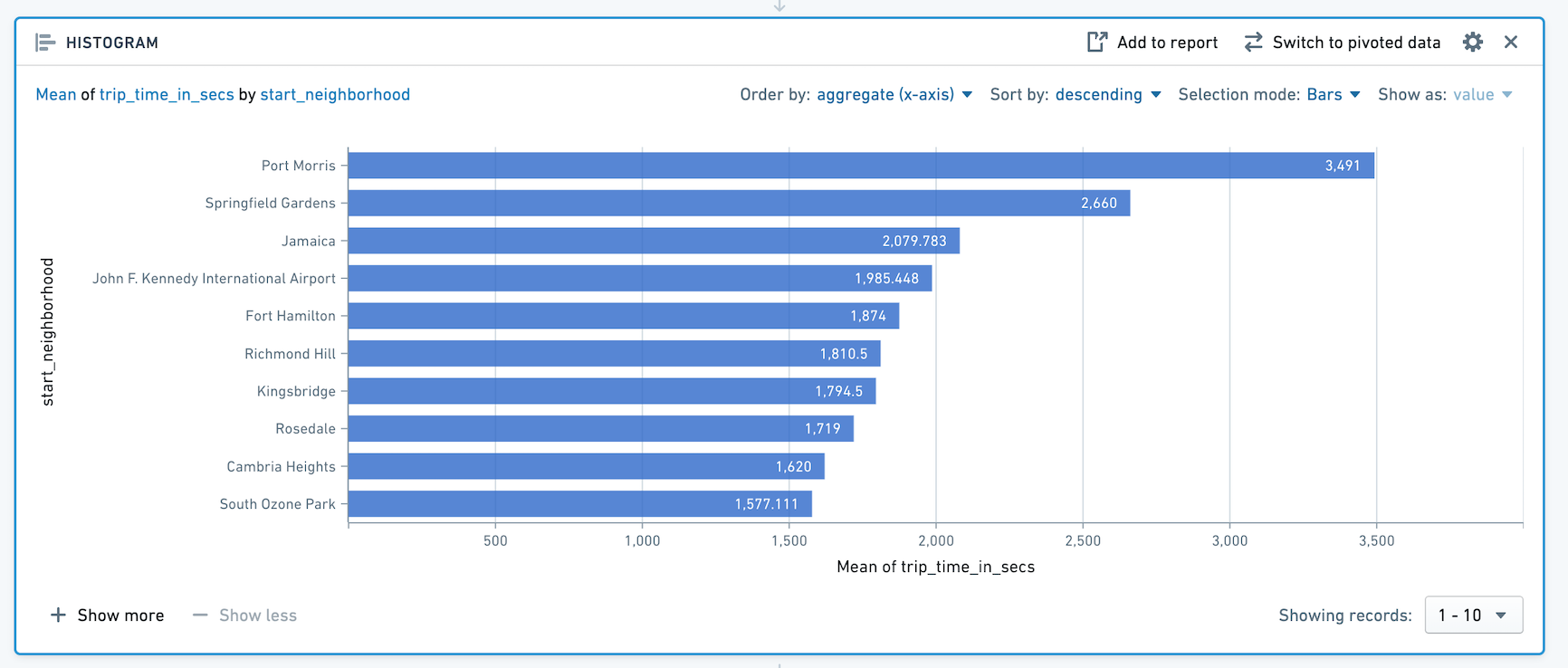
请注意,仅显示前十个条形。要显示更多条形,请点击 + 显示更多。您一次最多可以显示 50 个值。如果值超过 50 个,请使用下拉菜单导航到范围的其他部分。
SQL 等效
直方图面板是 SQL GROUP BY 子句的可视化。
上述示例直方图等价于以下 SQL 查询:
Copied!1 2 3 4 5 6SELECT start_neighborhood, mean(trip_time_in_secs) -- 选择起始社区和平均旅行时间(以秒为单位) FROM <table name> -- 从指定的表中 GROUP BY start_neighborhood -- 按起始社区进行分组
配置
- Y轴
- 选择一个列以对数据进行分组。数据将根据此列的离散值进行分组,然后计算聚合。
- X轴
- 选择一个要计算的聚合,如果聚合不是 Count,请选择要应用的列。
- 聚合
- 可用的聚合指标有:Count(记录数量)、Unique Count、Min、Max、Sum、Mean、Approx. median、Standard Deviation 和 Variance。
- 除了 Count,您必须指定聚合应用于哪个列。对于 Unique Count,您可以选择任何列。
- Min、Max、Sum、Mean、Approx. Median、Standard Deviation 和 Variance 仅适用于数值列。
- 聚合针对选为 Y轴的列中的每个不同值进行计算。
- 可用的聚合指标有:Count(记录数量)、Unique Count、Min、Max、Sum、Mean、Approx. median、Standard Deviation 和 Variance。
Approx. Median 聚合是近似值。Contour 调用 percentile_approx ↗ 函数,百分比值为 0.5,默认精度。
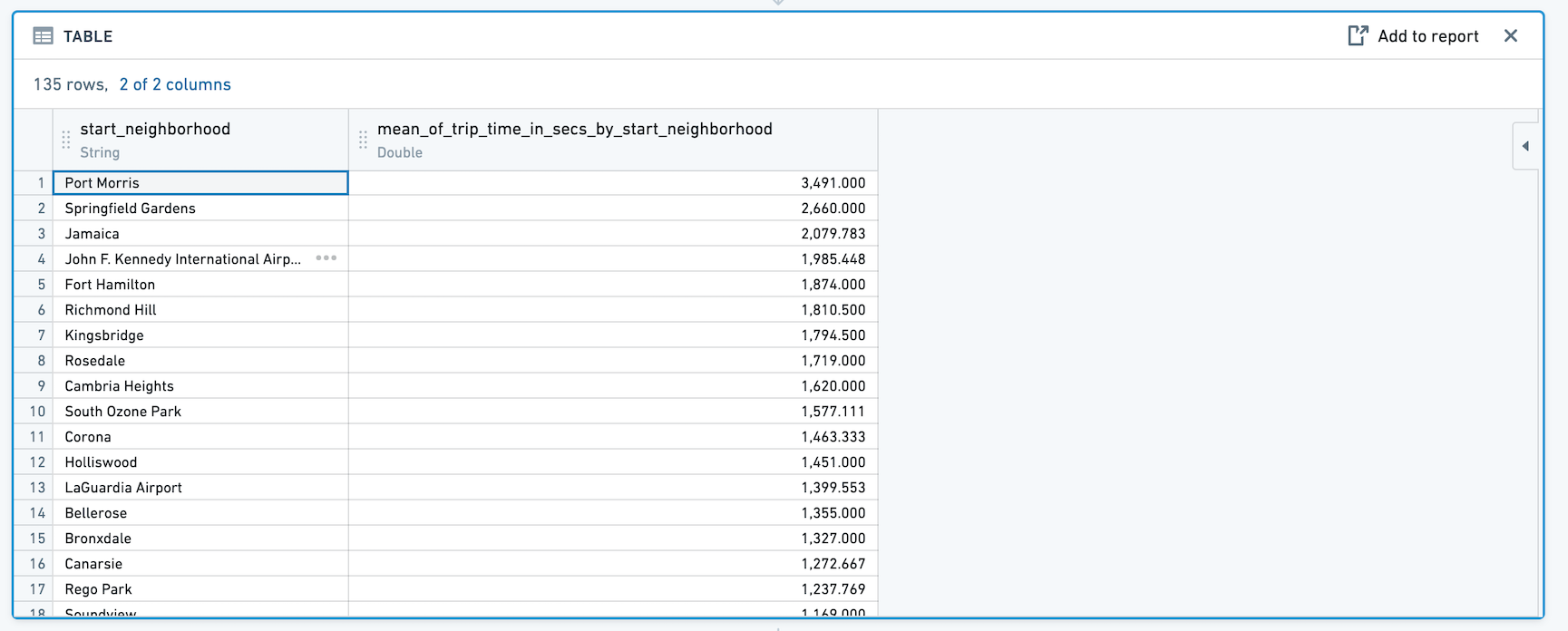
切换到透视数据
当您点击 切换到透视数据 时,您在直方图后添加的任何面板将使用表中计算的聚合数据,而不是原始数据集。
新数据集将包括您在原始直方图配置中选择的 Y轴列,以及一个用于聚合的列。例如:
排序
直方图默认按聚合降序排序。对于非常大的直方图,排序在聚合的1,000个最高值上执行。
您可以使用下拉菜单更改为按Y轴列值排序,或更改排序方向。
筛选
在直方图上选择数据以筛选未来面板的数据集。
选择模式:
- 选择 条 以通过您选择为 Y轴的列的一个或多个不同值进行筛选。
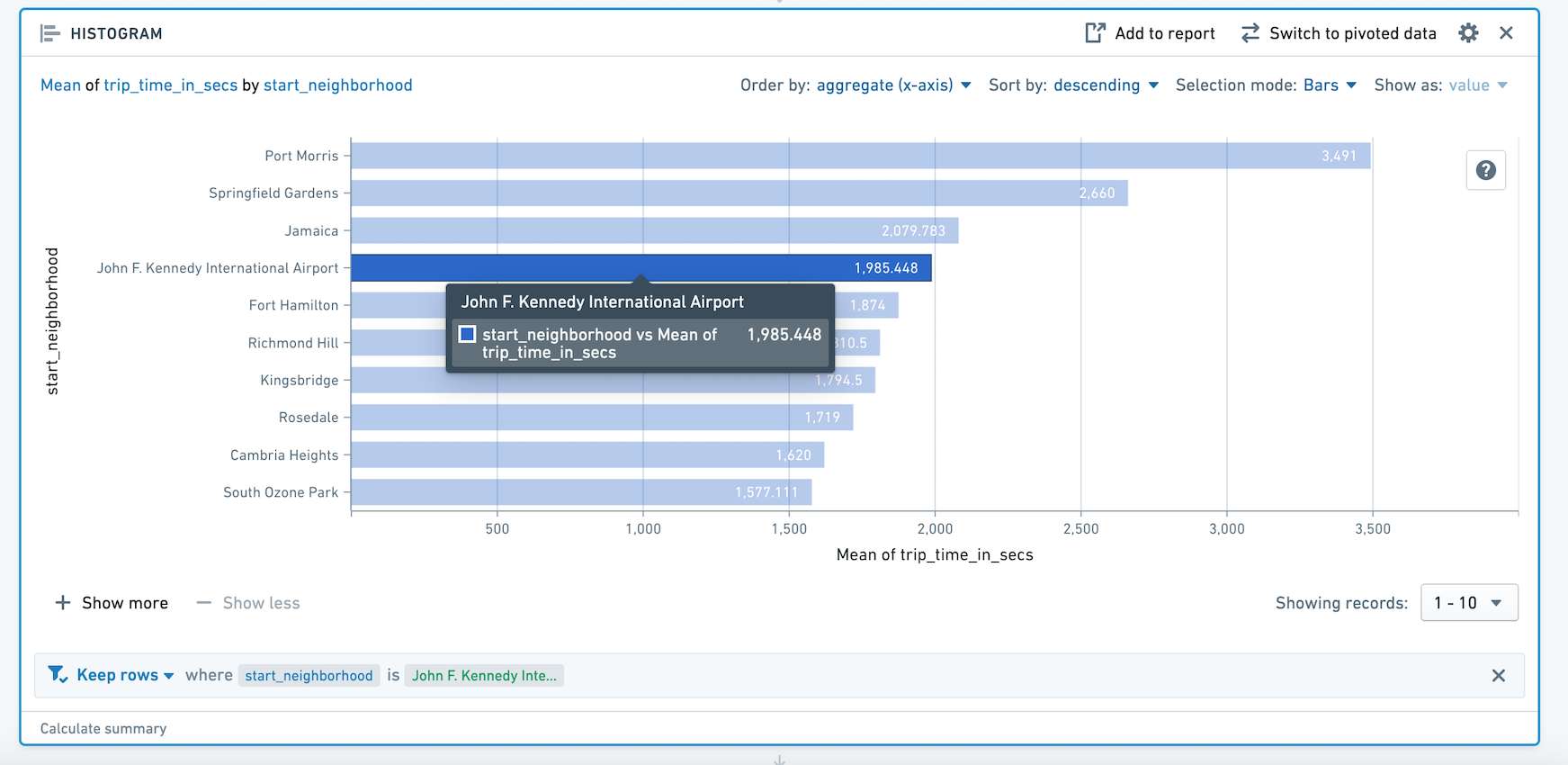
- 选择 范围 以通过聚合值进行筛选。例如,您可以使用范围选择仅选择具有高于某个阈值的类别。
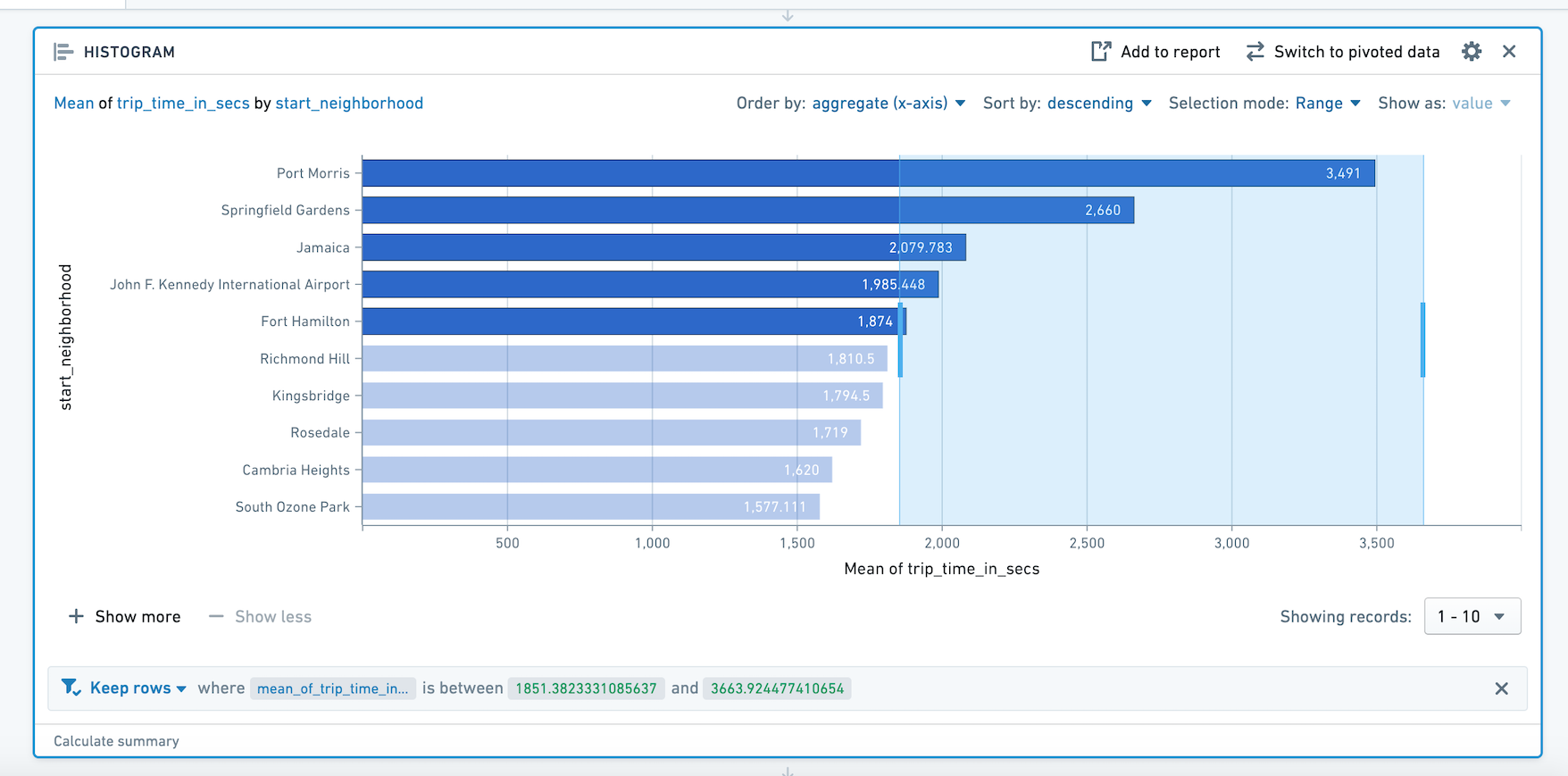
然后选择 保留 以仅筛选到所选值,或 删除 以仅保留未选择的值。

分布
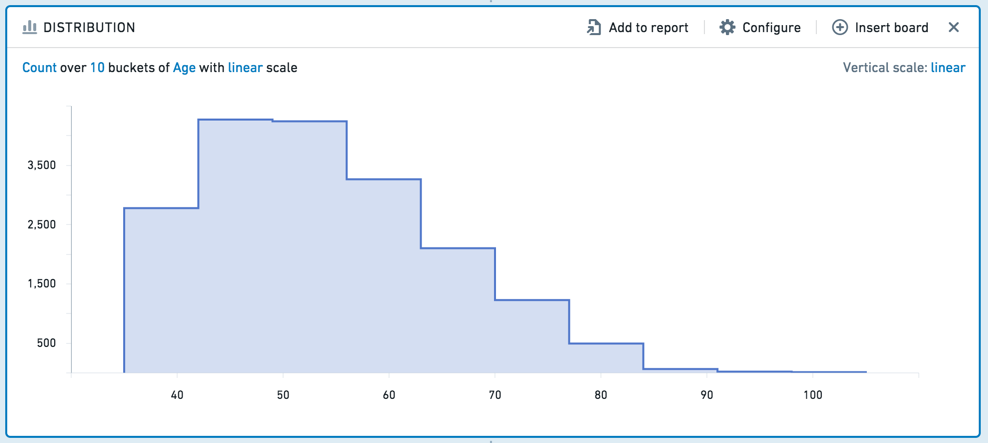
分布面板显示聚合指标的数值变量的分布。
分布面板类似于直方图,但它基于值的范围显示聚合数据,而不是特定值。例如,以下分布显示了客户年龄的数据。年龄被分为十个范围(或“桶”)。
SQL 等效
在计算分布面板时,我们首先找到X轴的最小值和最大值,并创建一个函数来计算桶。分布的SQL等效性大致等于以下内容:
Copied!1 2 3SELECT X_AXIS_BUCKET_FUNCTION([x-axis-column]), <AGGREGATE_METRIC>([aggregate-column]) FROM <PARENT_BOARD> GROUP BY X_AXIS_BUCKET_FUNCTION([x-axis-column])
Copied!1 2 3-- 选择 X_AXIS_BUCKET_FUNCTION 对 x 轴列进行分桶,然后选择一个聚合度量函数对聚合列进行计算 -- 从 PARENT_BOARD 表中获取数据 -- 按照 X_AXIS_BUCKET_FUNCTION 对 x 轴列进行分组
配置
- X轴
- 选择一个数值列。该列中的值将分组为等宽范围(换句话说,您的数据被平均分为十个、100个或1000个“桶”),然后应用聚合。您还可以配置此轴的比例(线性或对数)。
- Y轴
- 选择一个聚合指标以计算每个范围。
- 可用的聚合指标有:计数(记录数)、唯一计数、最小值、最大值、总和、平均值、近似中位数、标准差和方差。除了计数,您必须指定聚合应用的列。
- 您也可以配置Y轴的比例(线性或对数)。
- 选择一个聚合指标以计算每个范围。
近似中位数聚合是近似值。Contour调用了percentile_approx ↗函数,百分比值为0.5,并使用默认精度。
筛选
要选择一个范围进行筛选,请在图表上单击并拖动所需的区间。
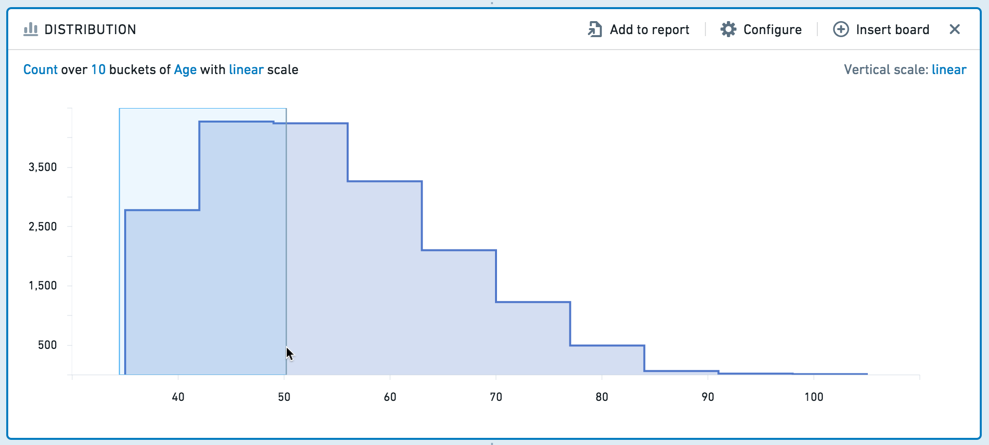
然后,您可以在可编辑的面板页脚中更精细地调整区间。
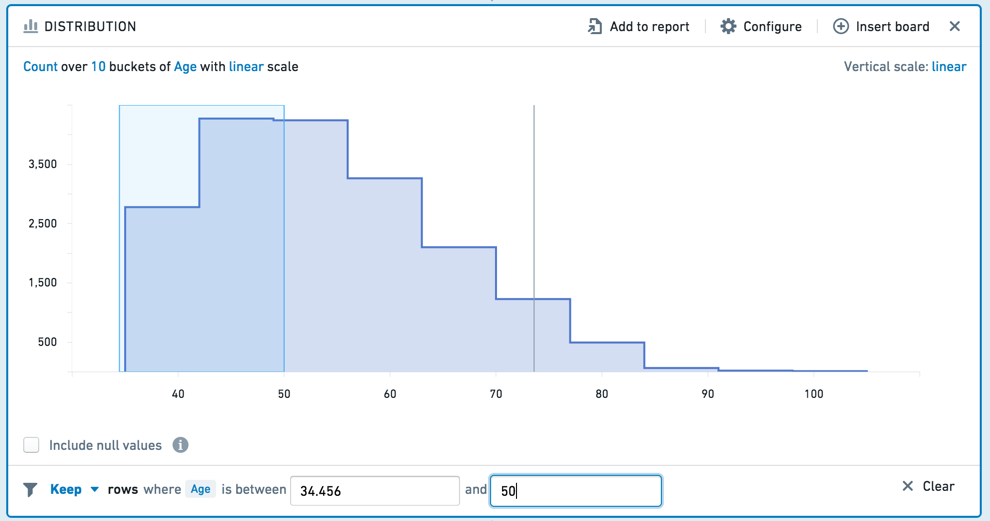
您可以选择保留选定区间内的值,或移除这些值,仅保留未选择的值。要清除选择,请单击清除按钮(x)。
时间序列
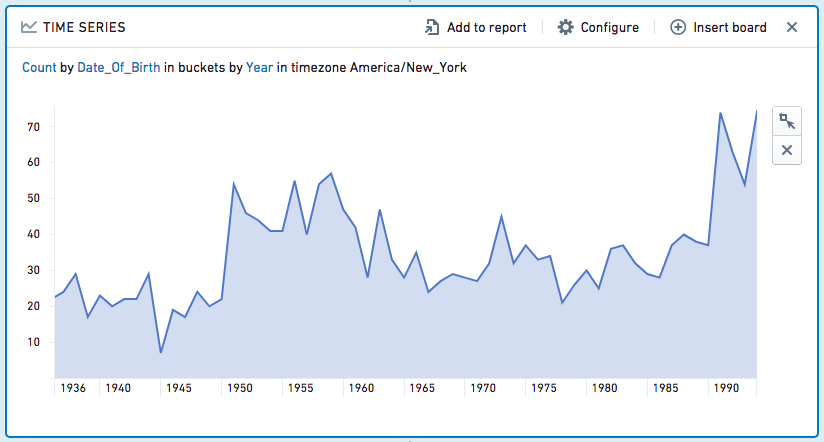
时间序列面板允许您按时间间隔对数据进行分组,并计算该数据上的聚合指标。
例如,给定一个包含客户个人信息的数据集,以下时间序列面板计算每年出生的人数。
您还可以进一步指定一个列用作系列。对于上述示例,您可以选择使用性别作为系列。然后,时间序列面板将分为每个系列列值的一条线:在这种情况下,F(女性)或M(男性)。
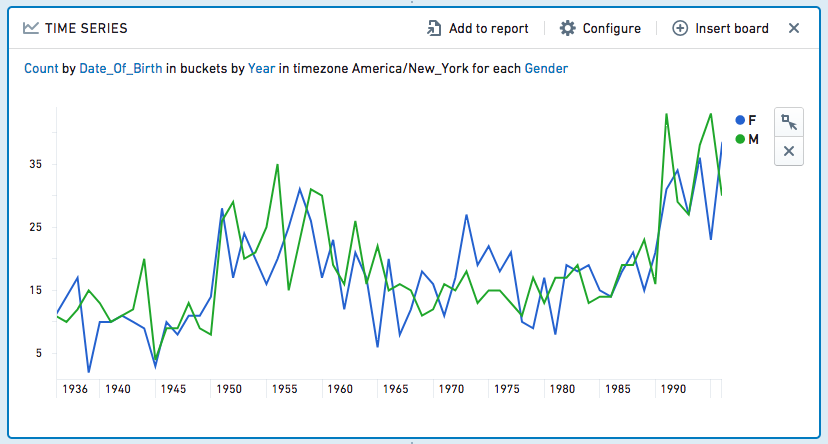
请注意,时间序列在整个数据集上执行其聚合,并在显示时将输出减少到前1000个值。
配置
- X轴
- 选择一个DateTime列以按时间分组数据。然后选择一个时间单位——数据将按该长度的间隔分组。可用的单位有:秒、分钟、小时、天、周、月和年。
- 聚合
- 定义要应用于每个时间间隔的聚合。
- 可用的聚合指标有:计数(记录数)、唯一计数、最小值、最大值、总和、平均值、标准差和方差。
- 除了计数,您必须指定聚合应用的列。对于唯一计数,您可以选择任何列。
- 最小值、最大值、总和、平均值、近似中位数、标准差和方差仅适用于数值列。
- 系列
- 选择一个列以将数据划分为系列。对于列中的每个离散值,将有一个系列(在图表中表示为一条线)。
近似中位数聚合是近似值。Contour调用了percentile_approx ↗函数,百分比值为0.5,并使用默认精度。
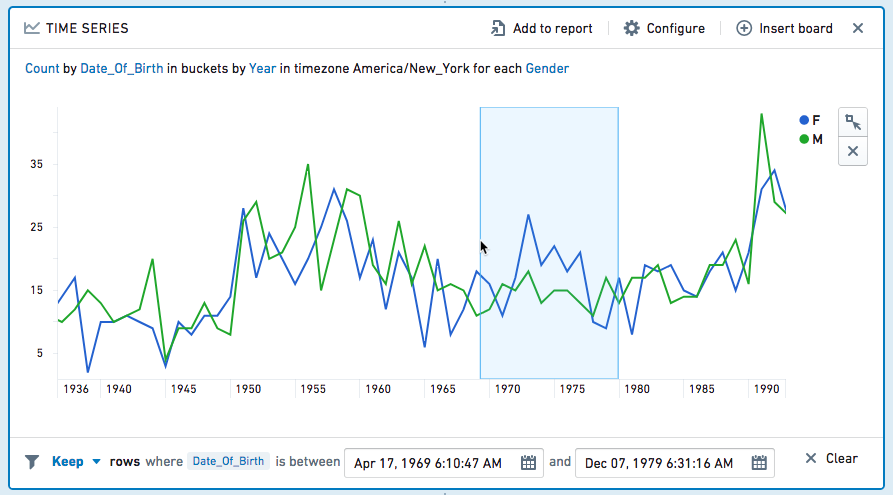
筛选
您可以在时间序列上选择一个日期范围,以筛选未来面板的数据集。点击![]() ,然后单击并拖动所需的区间。(您可以在可编辑的面板页脚中更精细地调整区间。)要清除选择,请单击
,然后单击并拖动所需的区间。(您可以在可编辑的面板页脚中更精细地调整区间。)要清除选择,请单击![]() 图标。
图标。
从下拉菜单中选择保留以筛选仅选择的值,或选择移除以仅保留未选择的值。
编辑列
您可以使用以下面板在Contour中编辑列:
- 合并两个或多个列。
- 复制一列(例如,在不影响原始数据的情况下尝试该列上的操作)。
- 移除表中的一列。
- 重命名一列。
- 拆分一列,使用一些分隔字符。
变换数据
您可以使用以下面板变换列中的数据:
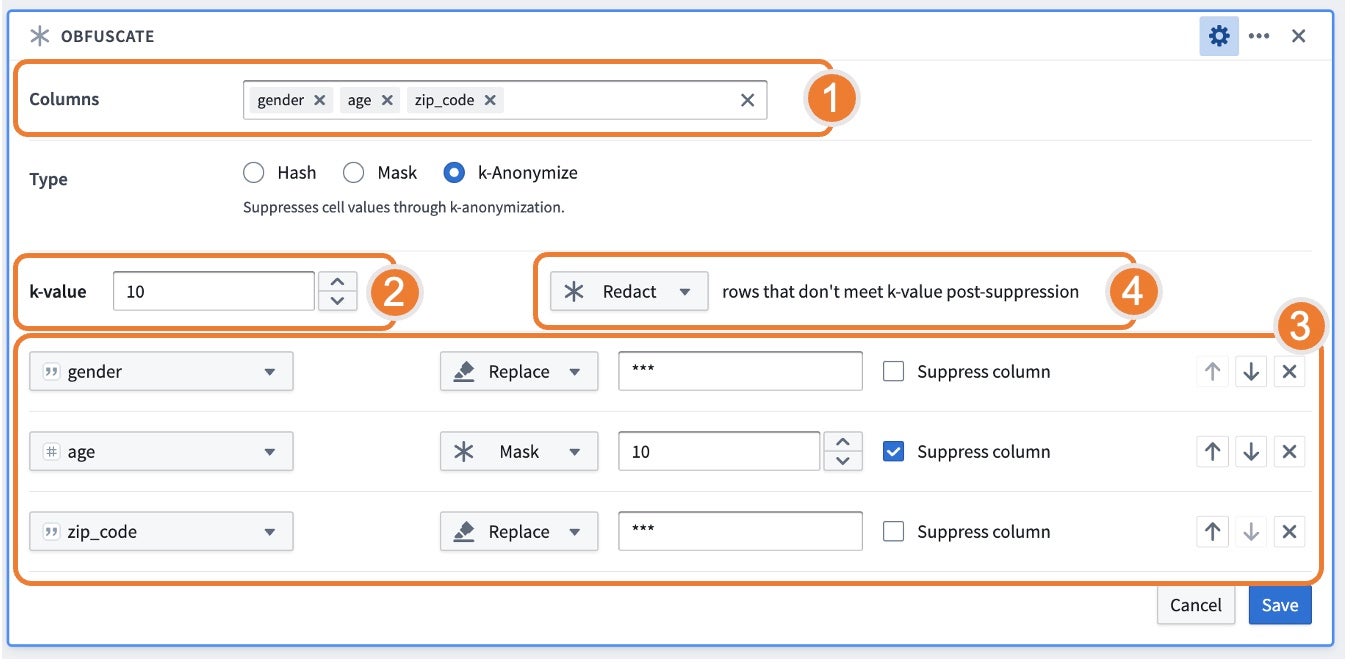
混淆
- 哈希单元格值(例如,隐藏敏感数据如姓名)。列中的每个值都被替换为该值的哈希表示,使用SHA-1 ↗哈希函数。
SHA-1哈希可以被解密,且不被认为是完全安全的。因此,它不应被用于数据合规目的。
- 掩码值中的某些字符数(例如,掩码电话号码中除最后2位以外的所有字符)。
- K匿名化数据列作为一种隐私技术,旨在对数据集应用一个阈值(
k),确保至少有k个实例具有相同的敏感信息,从而降低重新识别的风险(即使没有任何个人可识别信息)。此过程通过“抑制”可能有助于重新识别数据的特定字段来完成。
适用于您的应用案例的k值由上下文决定。组织通常根据分析的上下文和重新识别的统计风险来制定其设置k值的策略。一些示例策略包括国家教育统计中心↗和美国卫生与公众服务部↗。至少,k值应始终大于1且小于数据集中的总行数。
使用k匿名化函数,面板需要请求k匿名化的列、k值目标、抑制策略以及对不符合k值后抑制的行的处理。
-
列:表示“准标识符”或可以与外部数据链接以唯一识别个人的属性。
-
k值:表示阈值
k,即至少有k个实例具有相同的敏感信息。 -
策略:表示数据应如何抑制以及以何种顺序。您可以设置给定的操作顺序以达到指定的k值。对于列出的每一列,您可以选择不同的策略来应用于数据以符合k值:
- 桶:用一个范围替换整数;仅在选择数值类型列时可用。
- 掩码:用*替换最后n个字符。
- 替换:用字符串替换整个值。默认行为建议使用
***作为替换值,但可以替换为用户提供的值。 - 勾选了抑制列标志的列将对所有值应用策略,无论是否符合k值。此行为对于诸如年龄分桶之类的情况特别相关,因为在所有值中拥有一致的分桶策略是有用的。
-
不符合k值后抑制的行:如果某些行不符合k值阈值且无法抑制以满足大于
k的计数,则提供以下选项:- 保留:保留行以免数据丢失。请注意,如果保留这些行,数据集将不会k匿名化;这通常是审查k匿名化结果的有用步骤。
- 丢弃:移除所有不符合k值的行。选择丢弃时,请确保计算混淆前后的行数以了解丢弃的行数。
- 编辑:用
***混淆表中的所有值。如果您希望保留相同的行数,此选项特别相关。
-
查找和替换列中的文本,或查找空或null单元格。此面板支持属性为字符串或数值类型。
-
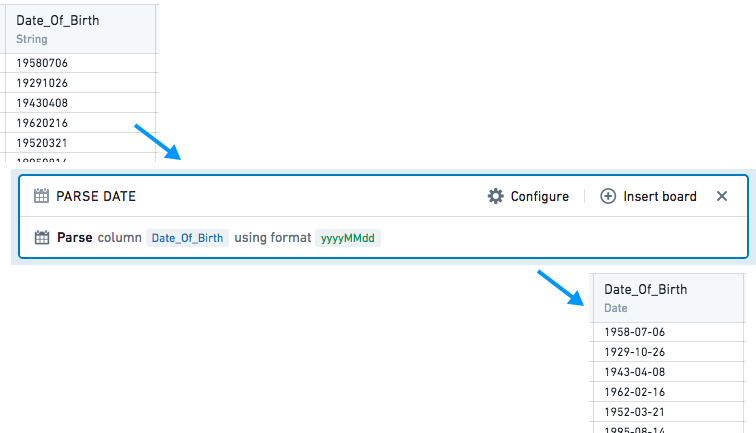
解析日期从字符串中。
图表
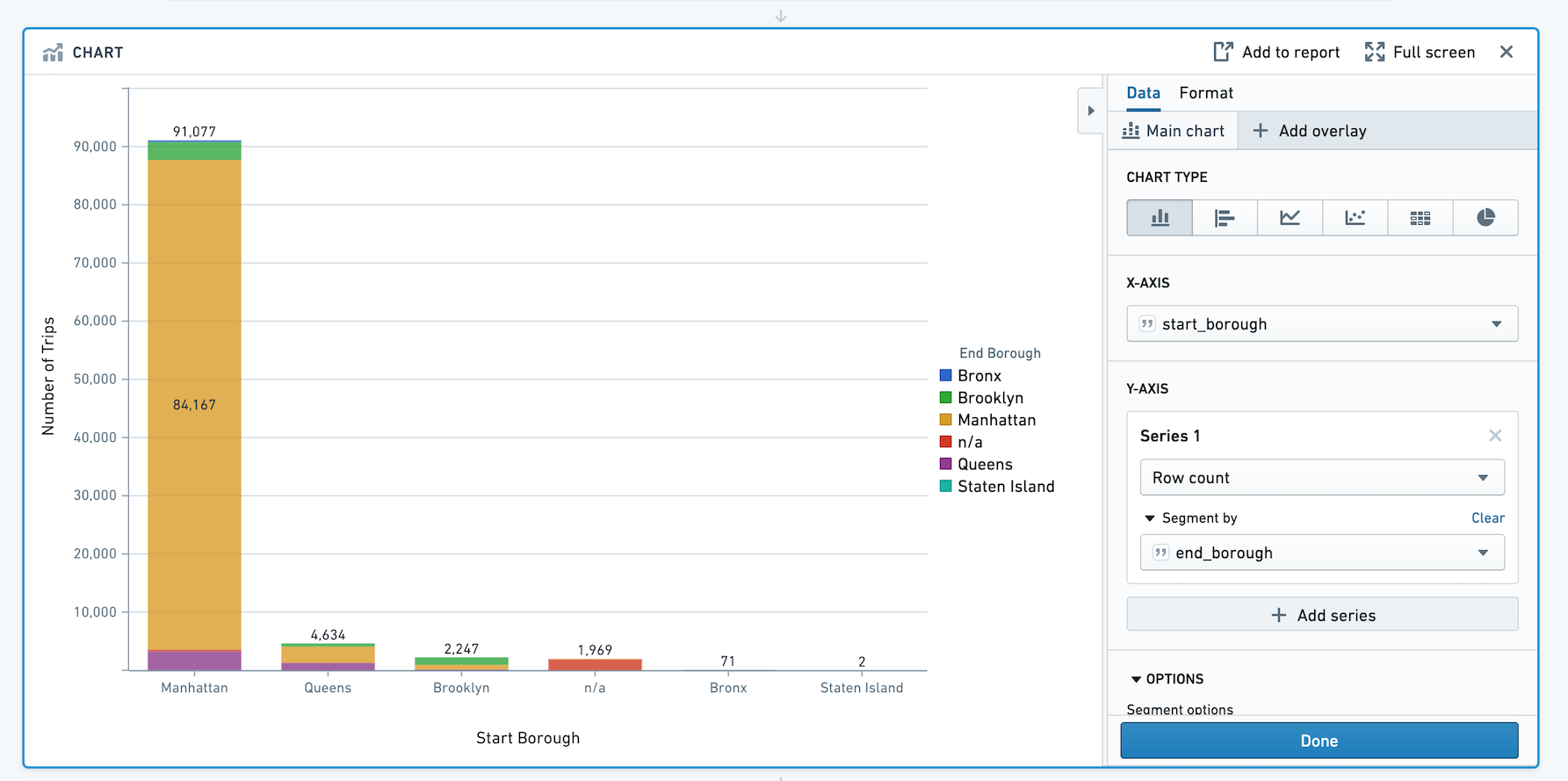
Contour图表面板允许您搭建自定义图表以分析您的数据。
配置
选择主图层的图表类型,然后配置x轴和y轴。当前图表面板提供以下类型的图表:
条形图
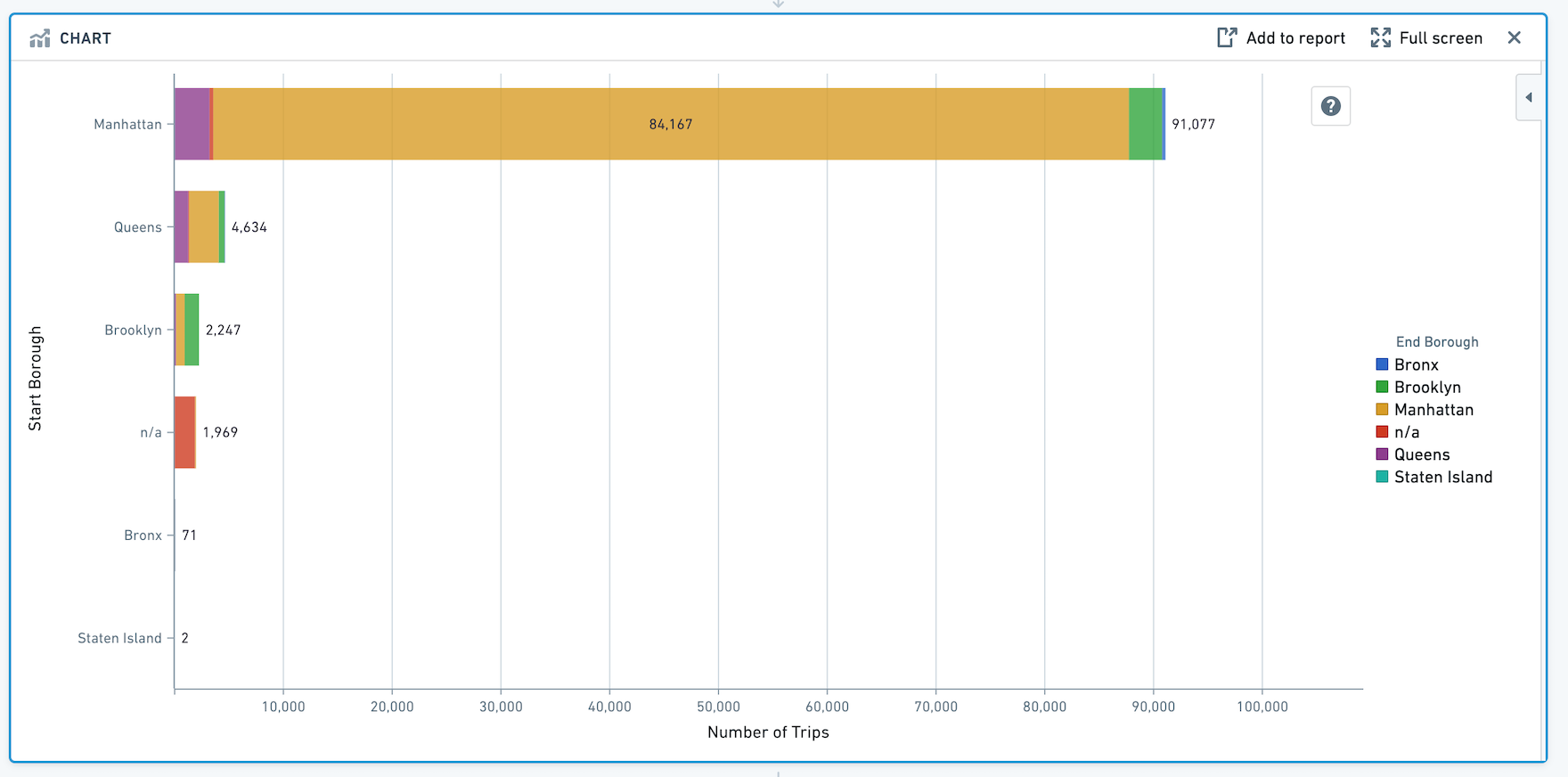
水平条形图
折线图
散点图
热网格
饼图
按段
对于除热网格和饼图以外的图表类型,您还可以选择将数据分段为系列。
排序
展开选项部分以更改图表数据的排序方式。 您可以按主图层中的值对图表数据进行排序:
- X值
- Y值
- 自定义列值。此排序值可以是数据集中的任何列(即使是未在图表上绘制的列)。
以下示例按一个国家在奥运会上获得的金牌数量对条形图进行排序:
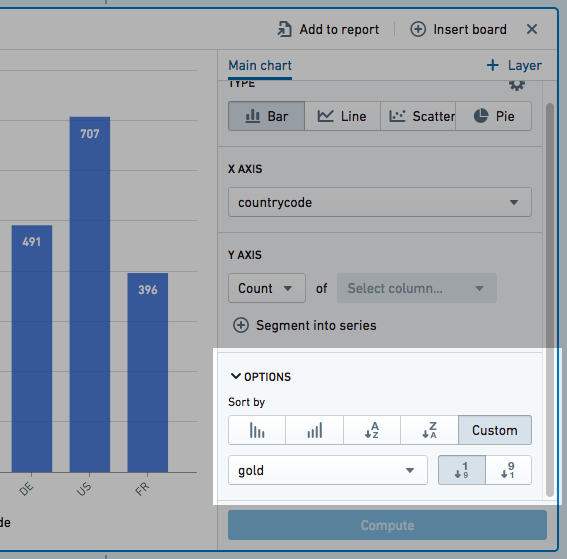
数据可以按升序或降序排序。覆盖图值不能用于排序图表数据。
格式化
使用格式化选项卡配置图表。您可以更改X轴和Y轴标题、轴的格式、图例位置、系列排序和系列颜色。
添加覆盖
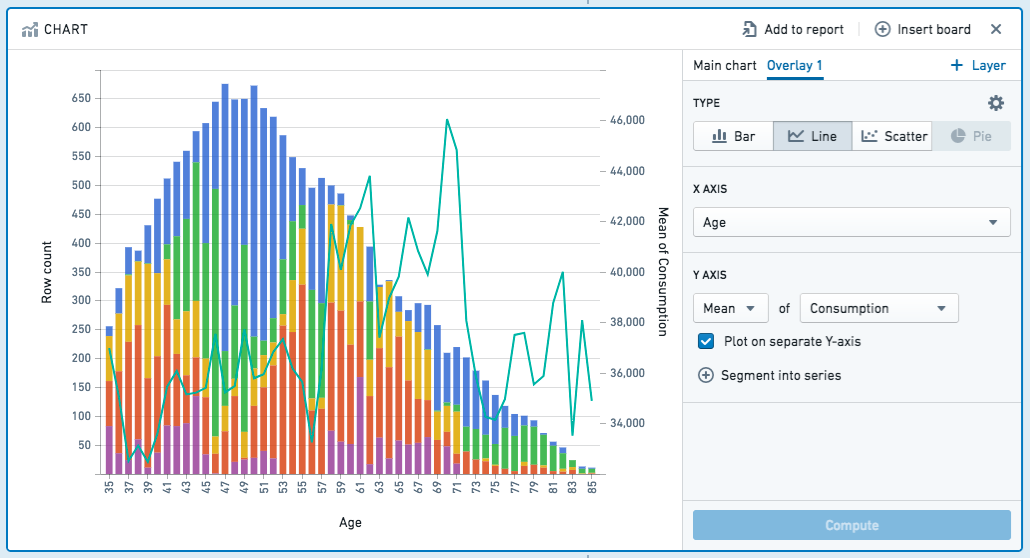
您可以通过单击**+ 添加覆盖**来添加覆盖图。例如,您可能希望在条形图上叠加一个折线图。
当您添加覆盖时,您可以选择图表是使用当前路径中的数据还是使用不同的数据集。
从不同数据集中绘制数据不会将该数据集与工作集合并。要合并数据集,您应该使用合并面板。
请注意,只有主图层是数据路径的一部分。其他图层仅用于演示目的。换句话说,在覆盖图层上选择或以其他方式操作数据不会影响路径下游的数据。
如果各个图层的值无关或数据范围或绘图比例显著不同,则可以在单独的y轴上绘制图层。
桶选择
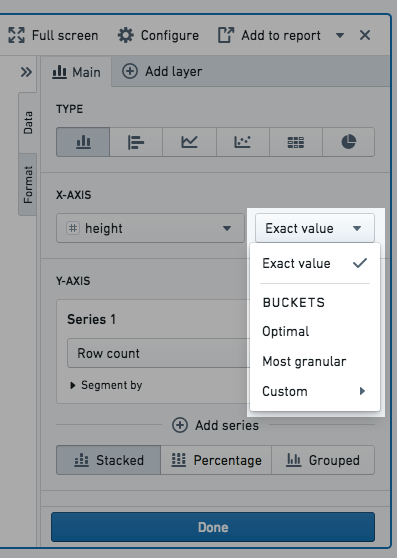
在配置按组列(例如在x轴上)和按段列时,您可以选择如何对数据点进行分桶。只有数值、日期或时间列可以进行分桶。例如,如果您创建一个条形图并选择日期列作为x轴的按组列并选择桶类型年,则生成的图表将每年有一个条形。可用的桶类型如下所列。
数值列桶类型:
- **精确值:**数据不进行分桶,显示精确值。
- **最佳:**桶的数量等于基础数据范围中点的平方根。数据范围是列的最大值和最小值之间的差。
- **最细粒度:**图表使用在结果限制内可以容纳的最大桶数。尽可能使用精确值。
- **自定义:**可以手动选择桶的数量。请注意,桶的数量不能大于结果限制。
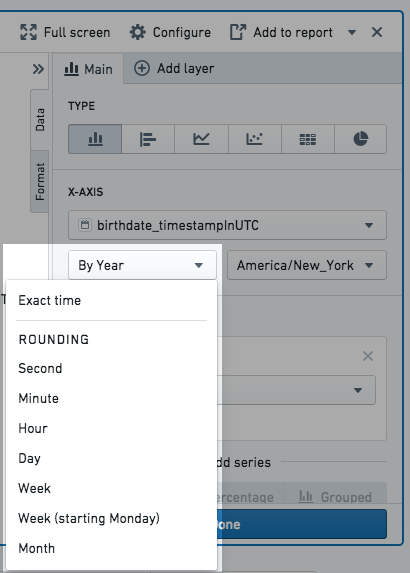
日期和时间列桶类型:
- **精确时间:**数据不进行分桶,显示精确值。
- 舍入:数据按最近的秒、分钟、小时、天、周、月或年进行分桶,具体取决于选择。例如,如果按年分桶,则日期为2018年6月15日的数据点被分入2018桶。
- 序数:数据按序数日期分桶。例如,如果选择星期几,数据将分桶为七个桶,每个星期一天一个桶。
如果桶选择不符合结果限制,将应用最细粒度的选项以确保数据不丢失。请阅读结果限制了解更多信息。
结果限制
Contour限制在浏览器上显示的数据点数量。实际上,Contour无法显示比屏幕上的像素更多的数据点。为了生成准确的图表而不丢失任何数据,图表面板将重新分桶图表配置为在结果限制内可容纳的最细粒度桶选择。
结果限制由您的Palantir管理员设置,默认为1000点。重新分桶将适用于数值、日期或时间列。
为了说明重新分桶,考虑以下示例:
- 在包含出生日期的数据集上创建了一个图表面板。
- 面板被配置为条形图,x轴设置为出生日期列。例如,计算具有相同出生日期的人的数量。
- 出生日期列指定日期精确到秒,因此选择了秒桶类型。
- 在此数据集中,唯一出生日期每秒的数量超过了结果限制。
- 因此,在计算时,图表面板会自动按小时而不是按秒分桶数据,因为小时是适合该特定数据集结果限制的最细粒度桶大小。
筛选
在图表上选择数据以筛选未来面板的数据集。使用Ctrl+点击或Cmd+点击进行多选。
您可以在图表上平移和缩放以更轻松地查看数据。将鼠标悬停在图表上的条形或点上还会显示一个工具提示,突出显示您正在查看的内容。
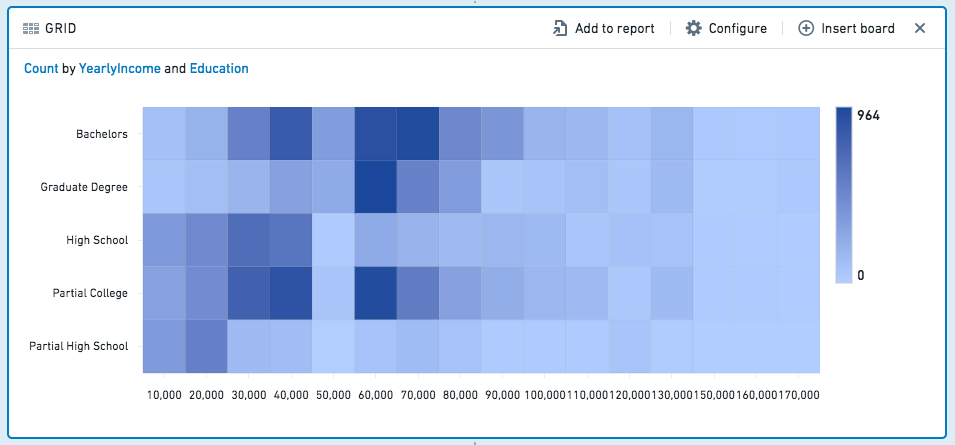
网格
网格面板类似于直方图,但网格面板按两个列而不是一个列汇总数据,显示结果的热网格图。(对于超过两列的数据,您可以使用数据透视表)。例如,以下网格比较了教育水平与年收入:
SQL等效
网格面板是聚合查询的可视化,类似于直方图和数据透视表面板。 网格大致等同于以下SQL查询:
Copied!1 2 3SELECT [x-axis-column], [y-axis-column], <AGGREGATE_METRIC>([aggregate-column]) FROM <PARENT_BOARD> GROUP BY [x-axis-column], [y-axis-column]
Copied!1 2 3 4-- 这个SQL查询从<PARENT_BOARD>表中选择数据。 -- 它按[x-axis-column]和[y-axis-column]列进行分组。 -- 对[aggregate-column]列应用<AGGREGATE_METRIC>聚合函数。 -- 例如,<AGGREGATE_METRIC>可以是SUM、AVG等。
配置
- X轴和Y轴
- 选择两列 - 这些列中的每个唯一值组合将在网格中形成一个单元格。
- 聚合
- 选择一个聚合指标以计算网格中每个单元格的值。聚合结果将决定单元格的颜色。
- 可用的聚合指标包括:计数(记录数)、唯一计数、最小值、最大值、总和、平均值、近似中位数、标准偏差和方差。
- 除了计数,您必须指定聚合应用于哪一列。对于唯一计数,您可以选择任何列。
- 最小值、最大值、总和、平均值、近似中位数、标准偏差和方差仅适用于数值列。
近似中位数聚合是近似的。Contour 调用了percentile_approx ↗函数,百分比值为0.5,默认精度。
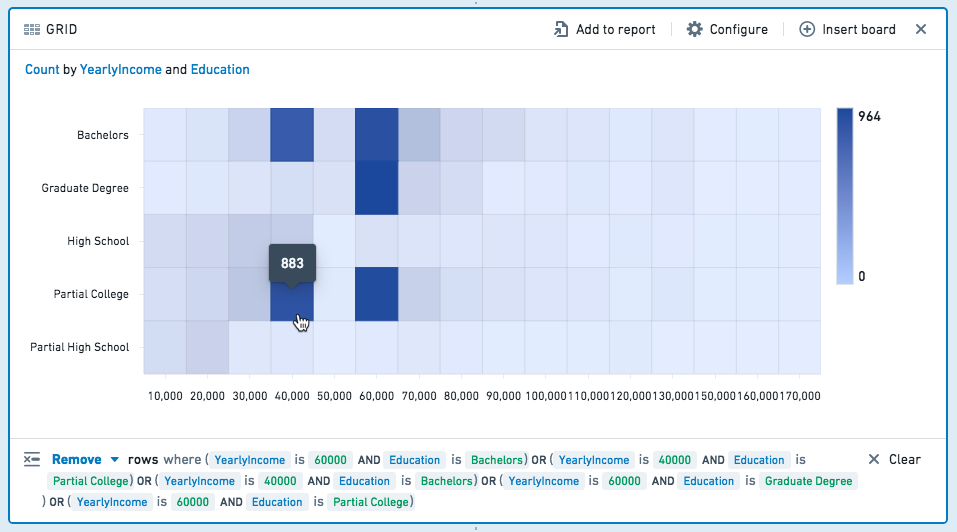
筛选
选择网格上的一个或多个单元格,以筛选未来看板的数据集。再次点击一个单元格以取消选择。
选择保留以筛选为仅选择的值,或者选择移除以仅保留未选择的值。
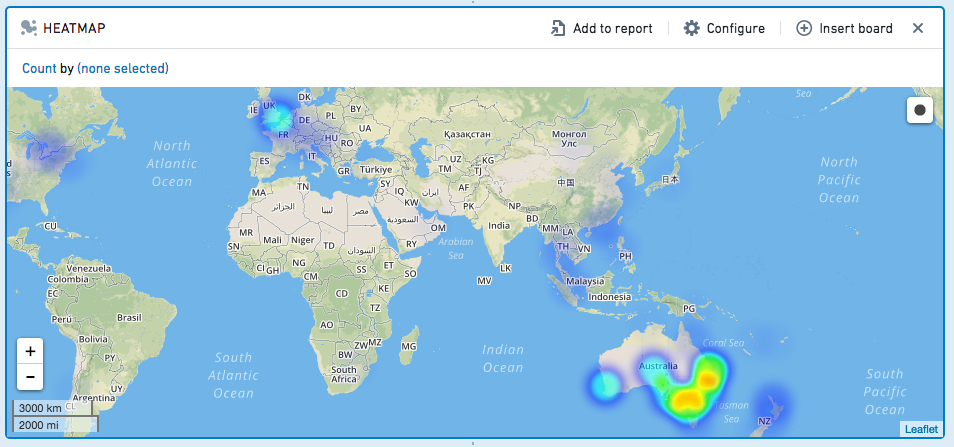
热力图
热力图面板在地图上显示地理编码数据,并使用颜色编码来表示值。
配置
- 指定哪些列包含纬度/经度数据。
- 非必填,指定一个地理哈希列。
- 然后,选择一个要计算的聚合指标。
- 可用的聚合指标包括:计数(记录数)、唯一计数、最小值、最大值、总和、平均值、近似中位数、标准偏差和方差。
- 除了计数,您必须指定聚合应用于哪一列。对于唯一计数,您可以选择任何列。
- 最小值、最大值、总和、平均值、近似中位数、标准偏差和方差仅适用于数值列。
- 可用的聚合指标包括:计数(记录数)、唯一计数、最小值、最大值、总和、平均值、近似中位数、标准偏差和方差。
近似中位数聚合是近似的。Contour 调用了percentile_approx ↗函数,百分比值为0.5,默认精度。
筛选
您可以在热力图上绘制一个半径,以选择包含该半径内地理数据的所有行。
点击![]() ,然后点击并拖动以在地图上绘制一个圆。
,然后点击并拖动以在地图上绘制一个圆。
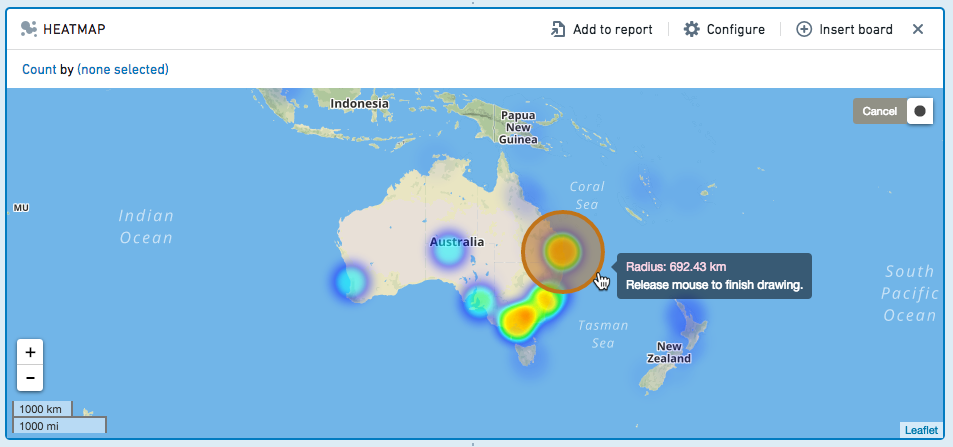
选择保留选定半径内的值,或移除这些值,仅保留未选择的值。
要清除选择并删除筛选器,请在地图上的圆外单击。
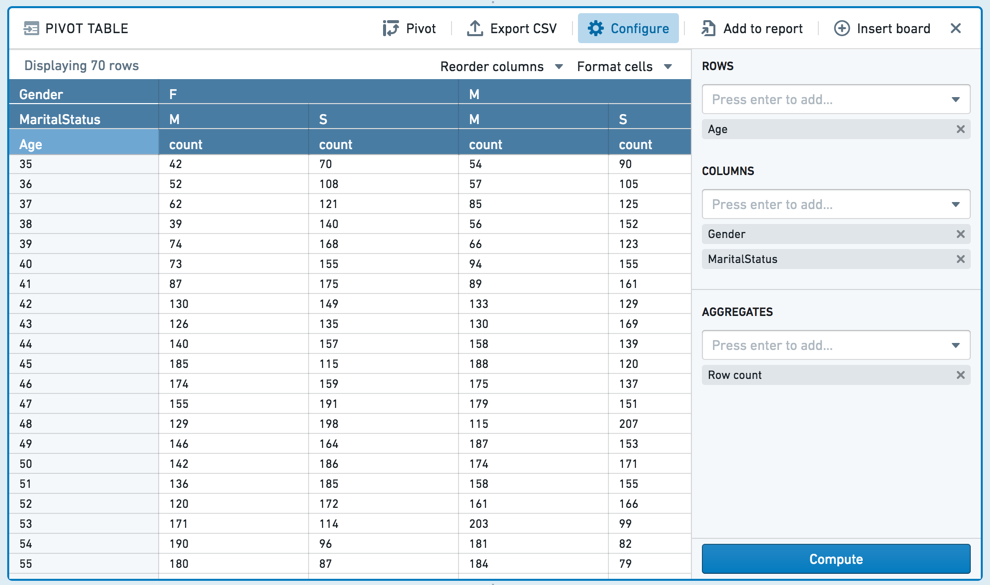
透视表
透视表面板允许您快速计算数据在多个维度上的多个聚合值。这种计算的结果是抽样的,因此表中显示的内容可能不完整。下面将更详细地描述这种抽样。
给定一个包含客户人口信息的数据集,以下透视表计算按年龄划分的已婚女性、已婚男性、单身女性或单身男性的客户数量。
关于抽样的重要说明
为了防止前端和后端性能缓慢,计算的行数是有限的。在大多数环境中,限制为1,000行,通常不可配置。
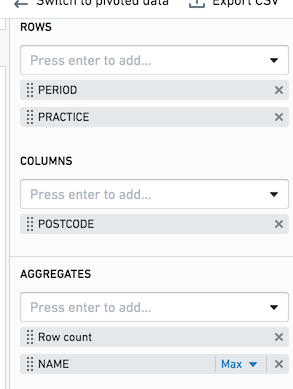
假设如上图所示,您有透视表行聚合PERIOD和PRACTICE,以及列聚合POSTCODE。对于每个组合,您想获得行数和列NAME的最大值。如果您的环境中限制为默认值1,000,您将只计算1,000完整行。每行都保证是完整的,但某些行可能不存在。
当您在透视表中对列进行排序时,排序是在预览上进行的,而不是整个数据集。要对整个数据集进行排序,请使用排序看板。参见排序以获取更多信息。
为了与透视数据的整体进行交互,请在面板上使用切换到透视数据选项,这将使您的Contour分析转换为透视表面板下方所有面板的完全计算透视数据。或者,您可以尝试通过在透视表上游进一步筛选数据来避免单元格限制。
配置
当指定列聚合时,列中的值必须大小写不敏感地唯一。例如,如果列“Borough”包含值“Brooklyn”和“brooklyn”,并且您指定“Borough”作为列聚合,则透视表计算将失败。考虑将所有值转换为一致的大小写以避免此问题。
- 列
- 选择一个或多个列进行聚合 - 原始数据集中所选列的每个值组合将在透视表中形成一列。
- 行
- 从原始数据集中选择一个或多个列以定义透视表中的行 - 原始数据集中所选列的每个值组合将在透视表中形成一行。
- 聚合
- 可用的聚合指标包括:计数(记录数)、唯一计数、最小值、最大值、总和、平均值、近似中位数、标准偏差和方差。
- 除了计数,您必须指定聚合应用于哪一列。对于唯一计数,您可以选择任何列。
- 最小值、最大值、总和、平均值、近似中位数、标准偏差和方差仅适用于数值列。
- 可用的聚合指标包括:计数(记录数)、唯一计数、最小值、最大值、总和、平均值、近似中位数、标准偏差和方差。
近似中位数聚合是近似的。Contour 调用了percentile_approx ↗函数,百分比值为0.5,默认精度。
您可以在列、行和聚合之间拖放。
您可以在单个透视表中指定多个聚合。每个聚合将为您选择的行和列的每个组合计算。
总计也可以计算行、列或两者。总计是通过对整个数据集进行聚合来计算的(换句话说,唯一计数的总计是数据集中唯一计数的总数,平均值的总计是整个数据集的平均值)。
透视(切换到聚合数据)
当您点击透视(切换到聚合数据)时,您在直方图之后添加的任何面板都将使用表中计算的聚合数据,而不是原始数据集。
新数据集将包括您在原始直方图配置中选择的Y轴列,以及一个用于聚合的列。例如:
列编辑器
列编辑器面板允许您轻松从数据集中移除列并派生新列。后续面板将使用您选择保留的列集。
添加新列
您可以对数据集中现有列执行二元运算以创建新的派生列,或将字符串列解析为数字或日期格式的列。
SQL 等效
派生列相当于在SQL或Spark中使用运算符。例如,以下派生一个列用于人均收入:
Copied!1 2 3 4 5SELECT [Household Members], -- 家庭成员数量 [Marital Status], -- 婚姻状况 [Income Column] / [Household Members] AS [Income per person] -- 每个人的收入,计算公式为总收入除以家庭成员数量 FROM [Table Name] -- 数据表名称
现有列
要移除列,选择 显示现有列 并选择您想要移除的任何列名。您可以通过再次选择来重新添加列。如果您想删除多列,还可以选择 全部移除,然后选择您想要保留的任何列。
移除重复行
您可以使用列编辑面板中的 移除重复行 选项来移除重复行。

SQL 等效
通过列编辑面板移除列相当于在 SQL 中选择列名。例如,给定一个包含 5 列(A-E)的表,以下代码移除了列 D 和 E:
Copied!1 2 3SELECT columnA, columnB, columnC FROM <tableName> -- 从指定的表中选择列 columnA, columnB 和 columnC
多列编辑器
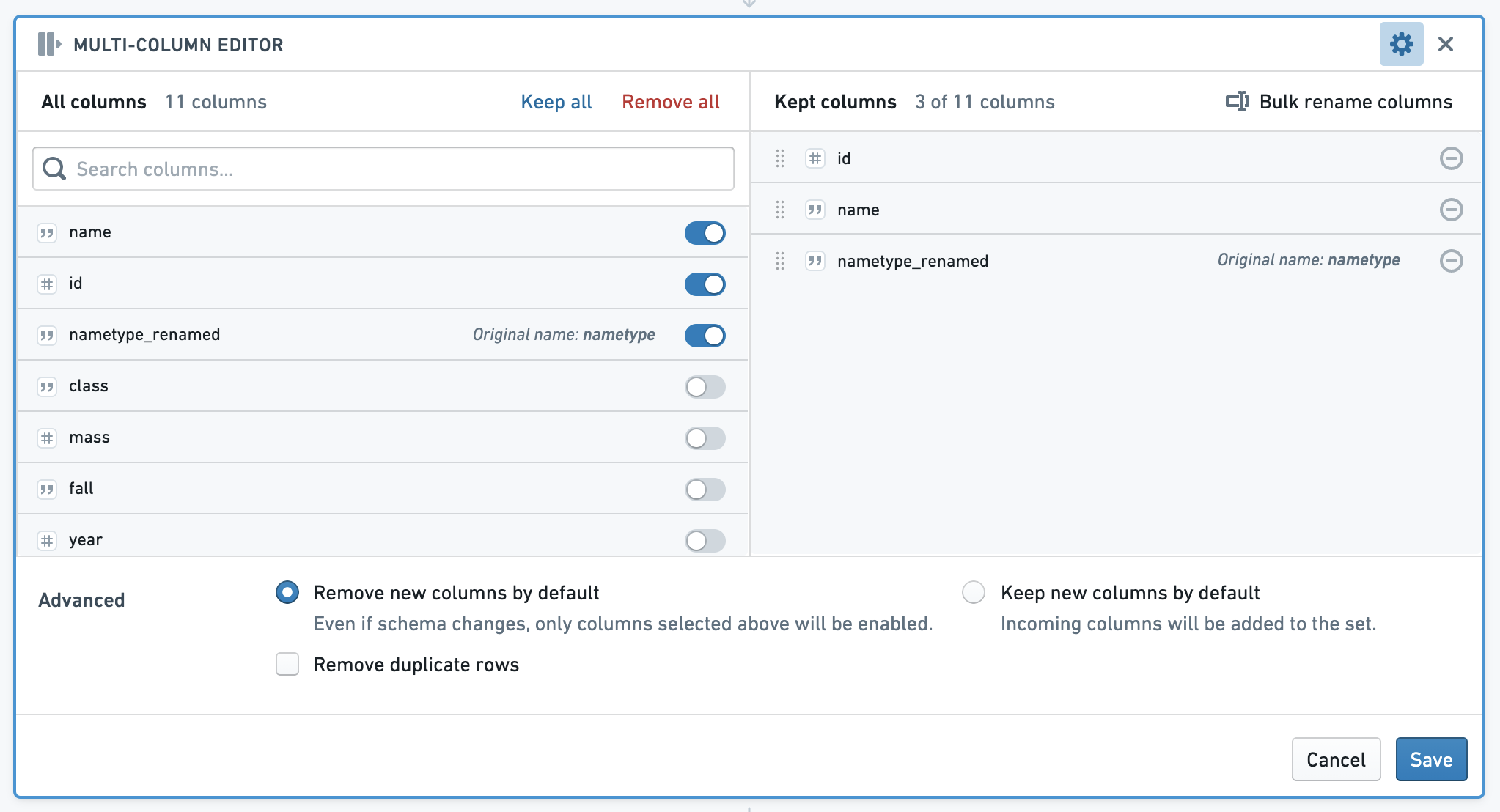
多列编辑器面板允许您重新排序、重命名和移除数据中的列,并删除重复的行。后续面板将使用您选择保留的列集。
面板的左侧显示所有列,右侧显示保留列。在保留列部分,您可以选择重命名或重新排序保留列,或使用批量重命名功能。
SQL等价
重新排序、重命名和移除列相当于在SQL中选择列名。例如,给定一个有5列的表,A-E,以下代码移除了列D和E,并将A重命名为A_1:
Copied!1 2SELECT columnA as columnA_1, columnB, columnC FROM <tableName>
Copied!1 2 3 4 5-- 在这段SQL代码中: -- SELECT 语句用于从数据库表中选择数据。 -- columnA as columnA_1:将 columnA 列的结果命名为 columnA_1。这是列的别名。 -- columnB, columnC:选择的其他列。 -- FROM <tableName>:指定要从中选择数据的表名。
丰富
丰富面板允许您将当前工作数据集与另一个数据集合并,并将匹配结果合并到您的数据中。
链接
链接面板允许您合并到另一个数据集并返回该数据集的匹配记录。这与集合数学仅保留操作不同,因为它仅返回来自链接(右)表的列。
集合数学
集合数学面板允许您根据另一个集合更改当前数据集。您可以筛选数据集以仅保留存在于另一个数据集中的数据(仅保留);从另一个数据集中添加数据(添加);或根据另一个数据集的结果移除数据(移除)。
合并
合并面板为您提供由您的Palantir管理员策划的推荐合并模板。如果您希望添加或修改推荐的合并,请联系您的管理员。
导出
导出面板允许您将您的分析集下载为CSV或XLS文件。
从下拉菜单中选择csv或xls,然后点击导出。在面板完成其在服务器上的操作后,您可以选择自定义文件名。然后点击下载 <#> 条记录来下载文件。


重新排序列
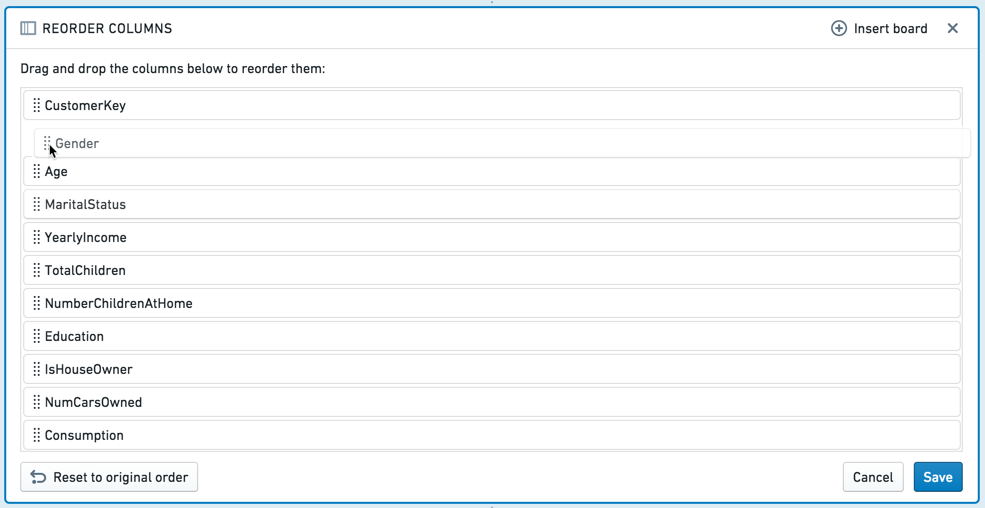
重新排序列面板允许您通过拖放方式将表中的列重新排列。
宏
宏面板允许您将先前创建的宏应用到您的路径。
排序
排序面板允许您对数据集中所有数据进行排序。请注意,此排序仅限于分析,并不会持久化到保存的数据集中。排序可能会因下游聚合(例如合并或删除重复行)而丢失,因此建议在排序之前进行此类聚合。
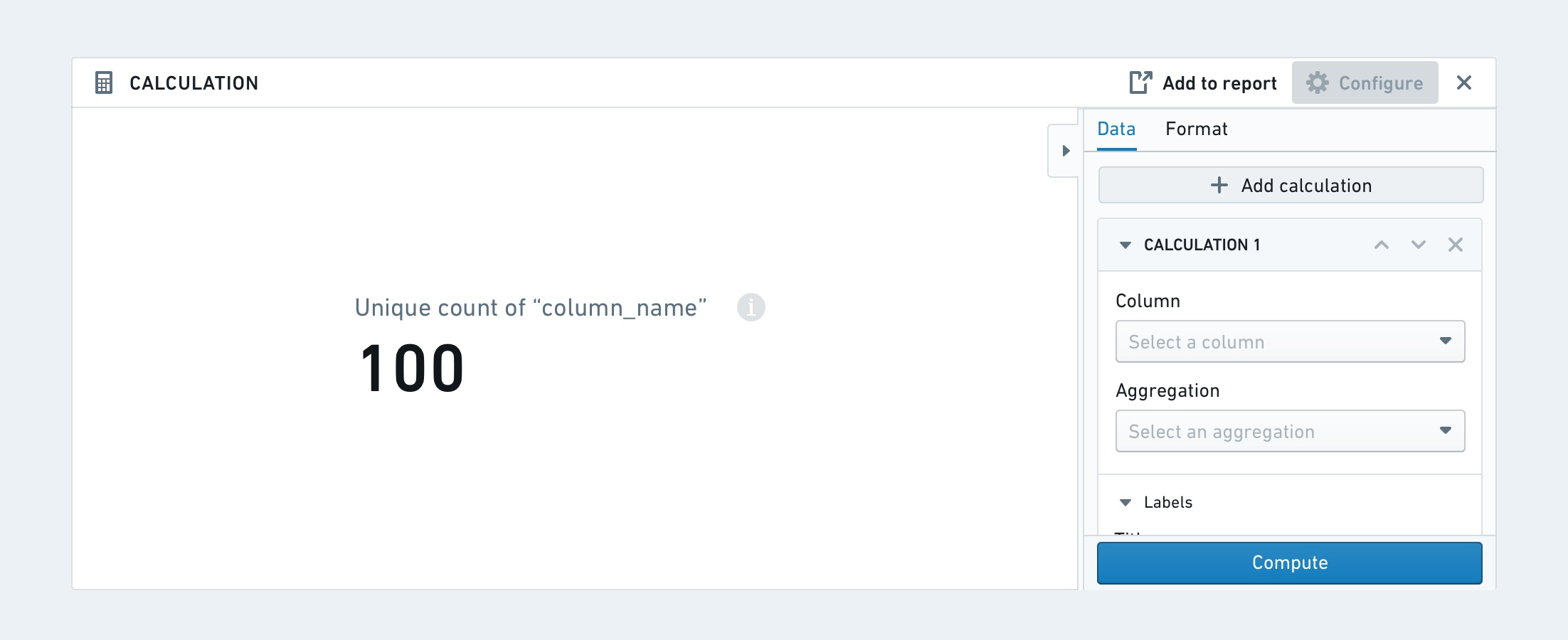
计算
计算面板允许您以卡片或列表的形式显示多个聚合计算在您的数据上。可用的聚合指标包括:唯一计数、最小值、最大值、总和、平均值、中位数、标准差和方差。
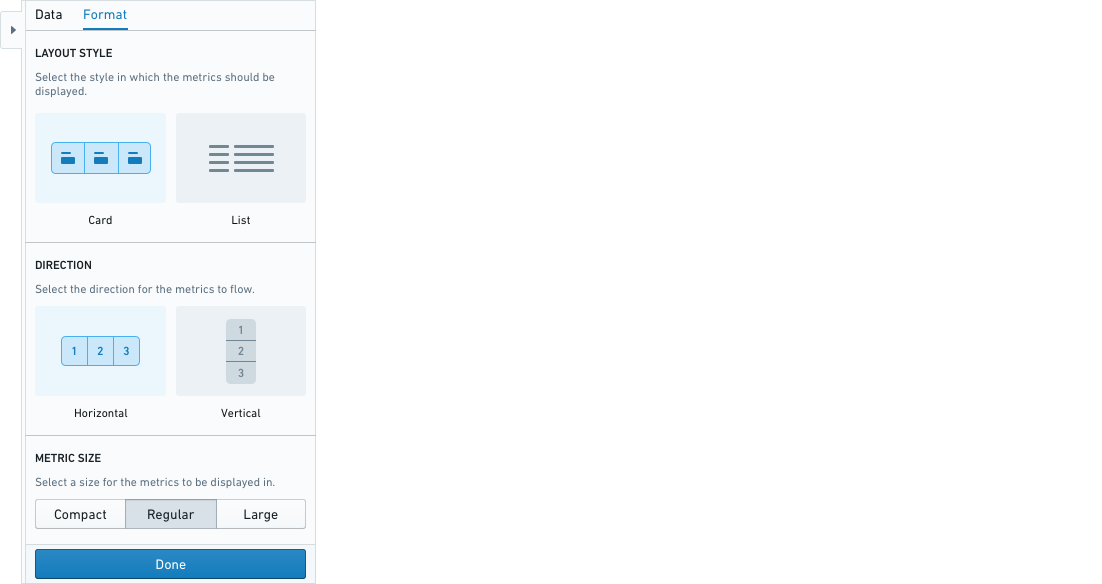
计算面板可以格式化为卡片或列表。
卡片格式具有额外的格式选项,包括横向或纵向方向和指标大小。
最后,每个计算可以基于一组指定的规则(条件)进行条件格式化。这意味着字体颜色和背景颜色可以根据条件是否满足而改变。
取消透视
取消透视面板允许您通过将某些列转换为行来重塑您的数据。您选择的列将被重新格式化为两个新列:一个标题列(包含原始列名)和一个值列(包含原始数据值)。