注意:以下翻译的准确性尚未经过验证。这是使用 AIP ↗ 从原始英文文本进行的机器翻译。
合并数据集
Contour 提供了几种不同的面板以进行合并。本指南将教您 (1) 如何使用每个面板来合并数据集,(2) 每个面板的 SQL 等价性,以及 (3) 性能考量。
合并面板
合并面板允许您将当前工作数据集与另一个数据集合并,并将匹配的结果合并到您的数据中。以下是概述:
示例
假设您有一个包含客户购买信息的表格。
| customer_id | item_id | purchase_date | price |
|---|---|---|---|
| 101 | 999 | 1/1/2000 | 50 |
| 121 | 997 | 1/1/2000 | 35 |
| … |
您可能还有第二个表格,其中包含库存中所有商品的信息:
| item_id | item | weight_kg |
|---|---|---|
| 999 | Toaster oven | 1 |
| 997 | Frying pan | 0.5 |
| … |
您可以使用合并面板来丰富您的起始数据集(transactions),以获得有关每件购买商品的信息。
如果您的数据集中有同名的列,Contour 会提示您为列名添加前缀。在这种情况下,两个数据集都有一列叫做 item_id。我们将对来自传入数据集的列应用前缀“inv” (以 inventory)。
如果您不想将重复的 item_id 列添加到结果合并的数据集中,可以从传入数据集中取消选择该列。
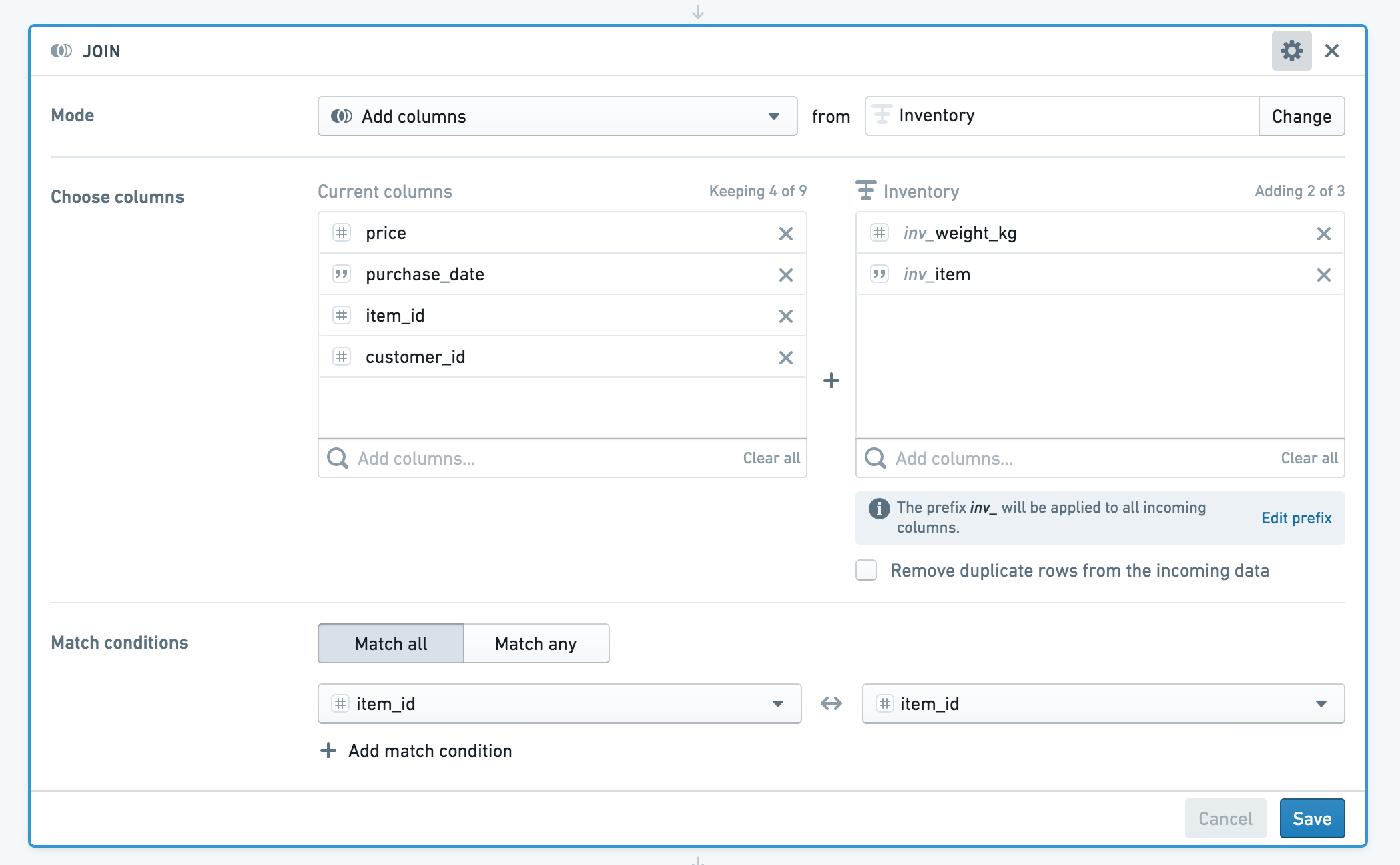
您的丰富数据集将如下所示:
| customer_id | item_id | purchase_date | price | inv_item | inv_weight_kg |
|---|---|---|---|---|---|
| 121 | 997 | 1/1/2000 | 35 | Frying pan | 0.5 |
| 101 | 999 | 1/1/2000 | 50 | Toaster oven | 1 |
| … |
合并面板的配置
选择要执行的合并类型:左合并(添加列)、内合并(交集)、右合并(切换到数据集)或全合并(合并所有数据,尽可能匹配行)。
选择要从其他数据集中添加到当前工作集的列。默认情况下,将返回第一个数据集的所有列。
然后从每个集合中选择一个或多个键。如果使用多个合并键,您可以选择 匹配任意 或 匹配所有 条件。
请注意,对于全合并,将从两个数据集中返回所有行;这意味着对于任一数据集的合并列可能会显示空值,因为不会合并两列。
并集面板
使用并集面板以根据另一集合更改当前数据集。您可以从其他数据集中追加数据(添加行),筛选数据集以仅保留存在于另一个数据集中的数据(保留行),或根据存在于另一个数据集中的数据删除数据(删除行)。您可以选择根据数据集中列的位置或列名称进行匹配。
我们将使用这三张表格来举例:
people
| first_name | last_name |
|---|---|
| Casey | Linden |
| Jess | Sage |
| Lee | Rose |
| Taylor | Oak |
candidates
| first_name | surname |
|---|---|
| Jess | Sage |
| Lee | Rose |
| Jamie | Wood |
candidates_backward
| last_name | first_name |
|---|---|
| Sage | Jess |
| Rose | Lee |
| Wood | Jamie |
我们有一个人的表格,并希望将其与两个候选人表格进行比较。两个表格与people表格的模式不同。以下部分展示了根据您在表格上执行的比较(集合数学),结果集合的变化。
示例:添加行
从people表格开始,如果我们按名称从candidates_backward表格中添加行,结果集合如下所示:
| first_name | last_name |
|---|---|
| Casey | Linden |
| Jess | Sage |
| Lee | Rose |
| Taylor | Oak |
| Jess | Sage |
| Lee | Rose |
| Jamie | Wood |
从people表格开始,如果我们按位置从candidates_backward表格中添加行,结果集合将是将people表格中的名字添加到candidates_backward表格的姓氏中,反之亦然。这可能不是期望的。结果集合如下所示:
| first_name | last_name |
|---|---|
| Casey | Linden |
| Jess | Sage |
| Lee | Rose |
| Taylor | Oak |
| Sage | Jess |
| Rose | Lee |
| Wood | Jamie |
您可能希望按位置将candidates表格的行添加到people表格中,因为列名不匹配,但名字和姓氏列的位置匹配。注意列名是从起始集合中取的:
| first_name | last_name |
|---|---|
| Casey | Linden |
| Jess | Sage |
| Lee | Rose |
| Taylor | Oak |
| Jess | Sage |
| Lee | Rose |
| Jamie | Wood |
示例:保留行
从people表格开始,如果我们配置并集面板以按位置****保留出现在candidates表格中的行,结果集合如下所示:
| first_name | last_name |
|---|---|
| Jess | Sage |
| Lee | Rose |
从people表格开始,如果我们配置并集面板以按名称****保留出现在candidates_backward表格中的行,结果集合如下所示:
| first_name | last_name |
|---|---|
| Jess | Sage |
| Lee | Rose |
示例:删除行
从people表格开始,如果我们按位置删除出现在candidates表格中的行,结果集合如下所示:
| first_name | last_name |
|---|---|
| Casey | Linden |
| Taylor | Oak |
从people表格开始,如果我们按名称删除出现在candidates_backward表格中的行,结果集合如下所示:
| first_name | last_name |
|---|---|
| Casey | Linden |
| Taylor | Oak |
如果我们改为从people表格开始,并按位置删除出现在candidates_backward表格中的行,结果集合如下。注意该表与people表格相同,因为在按位置匹配时没有行出现在candidates_backward表格中。
| first_name | last_name |
|---|---|
| Casey | Linden |
| Jess | Sage |
| Lee | Rose |
| Taylor | Oak |
并集面板的配置
选择保留行、添加行或删除行,然后选择您要比较的集合。
对于保留行和删除行,您可以选择出现在或匹配。
- 使用出现在时,您可以选择按位置或名称匹配。
- 使用匹配时,您必须指定要合并的列(每个集合中的一列)。
执行并集时,两个数据集必须具有相同数量的列。因此,在使用并集面板时,如果模式可能发生更改,则需小心。例如,透视表的下游并集面板在切换到透视数据后,可能会由于模式更改而导致列数的意外变化。
SQL 等价性
对于熟悉 SQL 的用户,理解 Contour 合并操作的 SQL 等价性可能会有所帮助。 下表显示了哪些面板支持哪些 SQL 合并类型:
合并
合并操作在 SQL 中等同于以下内容:
Copied!1 2 3 4 5 6 7 8SELECT [DISTINCT] <Column1, Column2, ...> -- 选择语句,DISTINCT用于去重,<>中填入要选择的列 FROM CurrentTable -- 指定主表 <INNER JOIN | LEFT OUTER JOIN | RIGHT OUTER JOIN | FULL OUTER JOIN > OtherTable -- 指定连接类型和要连接的其他表 ON <join condition 1>([AND | OR] <join condition 2> [AND | OR] <join condition 3> ...) -- 指定连接条件,多个条件可以用AND或OR连接
合并
保留匹配行 相当于 SQL 中的左半合并:
Copied!1 2 3SELECT L.* FROM L INNER JOIN (SELECT DISTINCT <join column> FROM R) AS R_KEY ON L.<join column> = R_KEY.<join column>
这个SQL查询的目的是从表 L 中选择所有列,其中 L 的 <join column> 值在表 R 的 <join column> 中是唯一的。具体来说,它首先在子查询中从表 R 中选择 <join column> 的唯一值,然后通过内连接将这些唯一值与表 L 中的对应列进行匹配。
以下是代码的关键点:
SELECT DISTINCT <join column> FROM R:从表R中选择<join column>列的唯一值。AS R_KEY:为子查询结果命名为R_KEY。INNER JOIN:通过内连接将表L和子查询结果R_KEY进行匹配。ON L.<join column> = R_KEY.<join column>:指定连接条件,要求L表中的<join column>与子查询结果R_KEY中的<join column>相等。
**删除匹配的行** 等同于 SQL 左外连接,其中连接键不匹配:
```sql
SELECT L.*
FROM L LEFT OUTER JOIN R
ON L.<join column> = R.<join column>
-- 使用左外连接,从表 L 中选择所有数据,并根据指定的连接列与表 R 进行匹配
WHERE R.<join column> is null
-- 过滤出在表 R 中没有匹配项的记录,即只保留表 L 中独有的记录
数据类型
检查您的结果集以确保数据类型符合预期。
当使用合并面板时,请注意您列的数据类型。兼容的列类型将被转换。举个具体的例子,让我们使用两个数据集。
dataset1
| ID (int) | Name (字符串) |
|---|---|
| 555 | Alice |
| 666 | Bob |
dataset2
| ID (long) | Name (字符串) |
|---|---|
| 555 | Alice |
| 999 | Chloe |
起始于dataset1,如果我们按位置添加行从dataset2,结果集如下所示:
| ID (long) | Name (字符串) |
|---|---|
| 555 | Alice |
| 666 | Bob |
| 555 | Alice |
| 999 | Chloe |
起始于dataset1,如果我们保留在dataset2中出现的行按位置,结果集如下所示:
| ID (long) | Name (字符串) |
|---|---|
| 555 | Alice |
请注意,即使起始集包含的列ID是int类型,在结果集中它是long类型。保留在dataset2中出现的行使用spark中的Intersect 函数。
起始于dataset1,如果我们移除在dataset2中出现的行按位置,结果集如下所示:
| ID (long) | Name (字符串) |
|---|---|
| 666 | Bob |
再次注意,尽管起始集包含的列ID是int类型,在结果集中它是long类型。移除在dataset2中出现的行使用spark中的Except 函数。
性能考虑
- 在为合并两个表选择键时,应尽可能使用唯一ID(如主键)。我们强烈建议不要使用外键合并——这样做会导致Spark崩溃。
- 在复杂合并或表达式后,您应该使用保存为数据集功能,以“保存”您的工作再继续。这将使下游查询更高效,因为合并已持久化到磁盘。
检查结果
合并数据集后,查看合并集的表以检查结果是否符合预期是个好主意。在操作功能区中选择表以添加一个表面板,并滚动查看您的新合并集。