注意:以下翻译的准确性尚未经过验证。这是使用 AIP ↗ 从原始英文文本进行的机器翻译。
Contour中的非确定性
非确定性窗口函数
当在窗口函数中使用ROW_NUMBER、FIRST、LAST、LEAD、LAG、NTILE、ARRAY_AGG或ARRAY_AGG_DISTINCT时,要注意非确定性。假设我们以列A进行分区,并以列B进行排序。如果对于同一列A的值,有多行具有相同的列B值,那么这些窗口函数的结果可能是非确定性的,即在相同输入数据和逻辑下可能产生不同的结果。
在表达式看板中使用这些表达式时,系统会提示您确保窗口函数中的ORDER BY子句是确定性的。
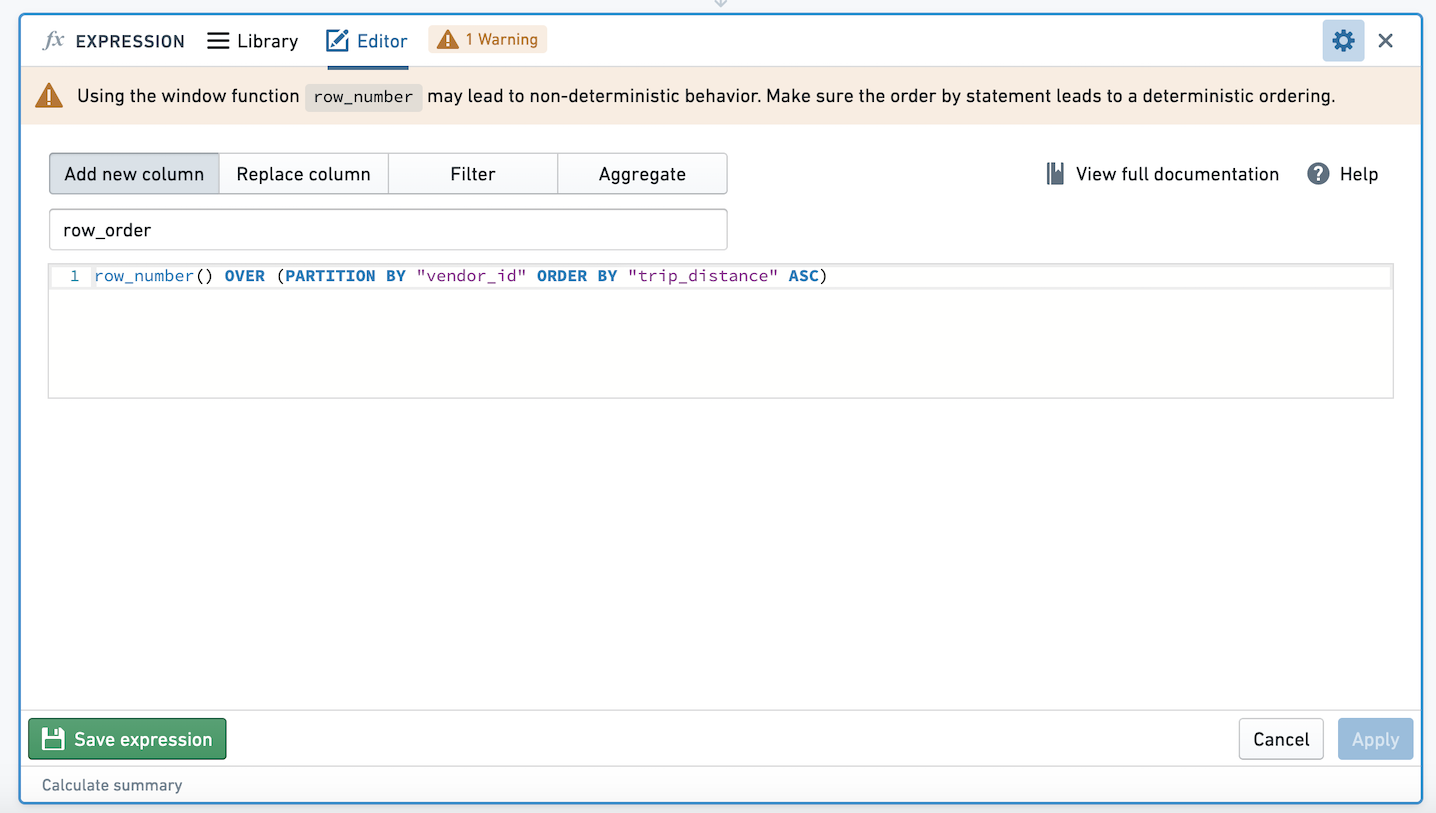
让我们通过一个数据示例来说明:
| name | class | grade |
|---|---|---|
| Aaron | Math | 95 |
| Burt | Math | 95 |
| Chrissy | Math | 80 |
| Angelica | Science | 77 |
| Burt | Science | 81 |
| Charlie | Science | 66 |
我们想要按成绩对每个班级的学生进行排名,因此我们添加了一个新列rank,表达式为ROW_NUMBER() OVER (PARTITION BY "class" ORDER BY "grade" DESC)。
我们得到以下结果:
| name | class | grade | rank |
|---|---|---|---|
| Aaron | Math | 95 | 1 |
| Burt | Math | 95 | 2 |
| Chrissy | Math | 80 | 3 |
| Angelica | Science | 77 | 2 |
| Burt | Science | 81 | 1 |
| Charlie | Science | 66 | 3 |
但有时,我们得到这个结果:
| name | class | grade | rank |
|---|---|---|---|
| Aaron | Math | 95 | 2 |
| Burt | Math | 95 | 1 |
| Chrissy | Math | 80 | 3 |
| Angelica | Science | 77 | 2 |
| Burt | Science | 81 | 1 |
| Charlie | Science | 66 | 3 |
由于Aaron和Burt在数学中的成绩相同,rank列是非确定性的。为了使该列确定性,我们可以在表达式的ORDER BY子句中添加“name”列:ROW_NUMBER() OVER (PARTITION BY "class" ORDER BY "grade" DESC, "name" ASC)。通过这个表达式,我们使用name列来打破任何具有相同成绩的行之间的平局,因此我们将始终得到以下结果:
| name | class | grade | rank |
|---|---|---|---|
| Aaron | Math | 95 | 1 |
| Burt | Math | 95 | 2 |
| Chrissy | Math | 80 | 3 |
| Angelica | Science | 77 | 2 |
| Burt | Science | 81 | 1 |
| Charlie | Science | 66 | 3 |
其他非确定性函数
除了上述窗口函数,CURRENT_DATE、CURRENT_TIMESTAMP、CURRENT_UNIX_TIMESTAMP和MONOTONICALLY_INCREASING_ID也是非确定性的。
对于CURRENT_DATE、CURRENT_TIMESTAMP和CURRENT_UNIX_TIMESTAMP,这些值只会在路径更新时计算。例如,如果您在第1天创建了一个包含CURRENT_DATE的新列,并在第2天回到分析中,新列仍将反映昨天的日期。
双精度列上的聚合
由于Spark计算的分布式特性,算术运算中操作数的顺序是非确定性的(即,1+2与2+1)。这种非确定性顺序可能导致在使用输入类型double时,聚合产生非确定性输出。这意味着,即使输入相同,双精度的聚合在不同计算中可能会有所不同;这些差异非常小,例如0.000001。
例如,取一个双精度列的mean或variance将导致一个非确定性列。在非确定性列上执行操作(例如筛选)的结果也将是非确定性的。
在您的分析中取一个双精度列的mean、sum、stddev、variance、corr或sum_distinct将创建一个非确定性列。
让我们看一个示例:
假设您有一个双精度列pickup_latitude。在数据透视表中,我们取双精度列pickup_latitude的平均值。如果您切换到透视数据,我们现在创建了一个非确定性列。
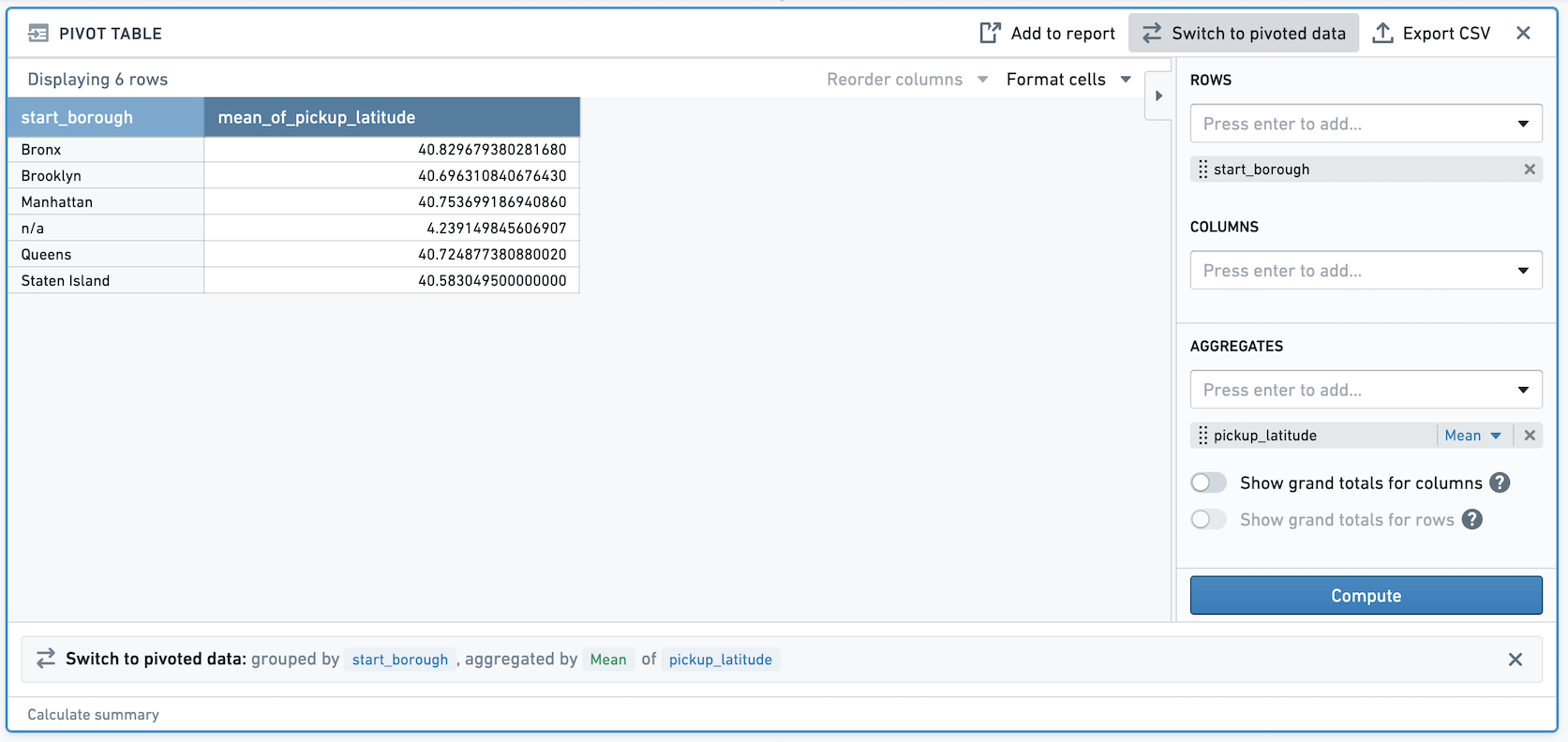
如果您然后筛选新创建的列,该筛选的结果将是非确定性的。例如,在上面的截图中,Staten Island的平均pickup_latitude是40.5830495。如果我们筛选到该值,我们看到一行保留。
然而,如果我们重新计算这个路径,可能该行在筛选后将不再出现,因为平均值的变化非常小。我们建议避免在非确定性列上使用精确筛选(例如筛选到mean = 40.5830495)。我们还建议避免使用非确定性列作为合并键。
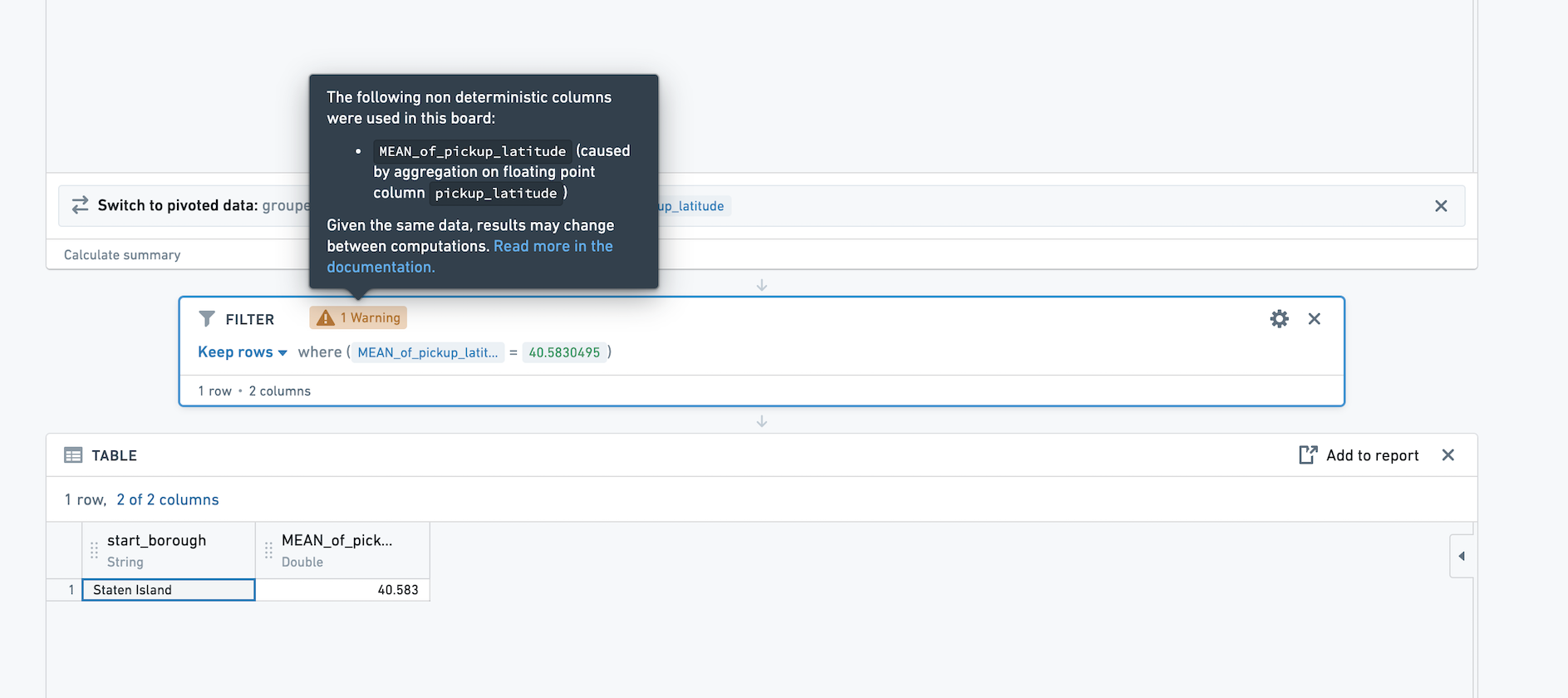
在Contour中对非确定性列执行操作(例如,对该列进行筛选)时,看板上会出现警告。警告指出哪个聚合是非确定性列的来源。
诊断非确定性
分析非确定性的一个标志是不一致的行数。例如,假设您在分析中插入了一个汇总看板,然后执行了一系列不更改行数的变换,然后添加了另一个汇总看板。如果两个汇总看板的行数不匹配,您应该调查路径上是否存在非确定性操作。注意用户界面中使用非确定性函数或双精度聚合时的警告信号。