注意:以下翻译的准确性尚未经过验证。这是使用 AIP ↗ 从原始英文文本进行的机器翻译。
使用表达式面板
除了直方图和图表等可视化工具外,Contour 还提供了一个表达式面板,让您使用 Contour 丰富的表达式语言从数据中派生新列、执行复杂的筛选或执行复杂的聚合。Contour 的表达式语言是一种自定义语言,结合了 SparkSQL 的多种函数。
- 使用表达式编辑器时,使用 ? 图标快速参考表达式语言。
- 输入时,建议的函数会在下拉菜单中出现。单击或使用 Enter 键选择一个函数。
列名是区分大小写的。此外,选择列时,可以使用或不使用双引号来书写列名。例如,year("birthdate_col") 等同于 year(birthdate_col)。为了保持一致,本文档中的列名写作带有双引号。
添加表达式面板
您可以从工具栏中将表达式面板添加到您的 Contour 分析中,如本概述中所示:
此示例使用存储在 Foundry 参考项目中的美国交通统计局的开源数据。
配置表达式面板
表达式面板有两种模式:保存的表达式库和编辑器。
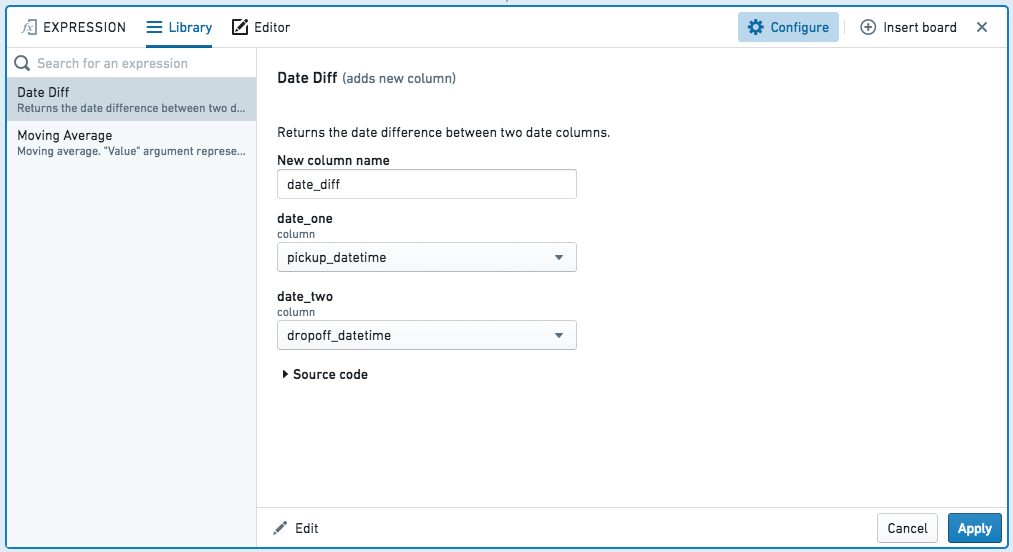
库
库允许您重用自己或他人编写的表达式,并带有参数:
编辑器
在编辑器中,您可以编写四种类别的表达式:
- 添加新列
- 替换列
- 筛选
- 聚合
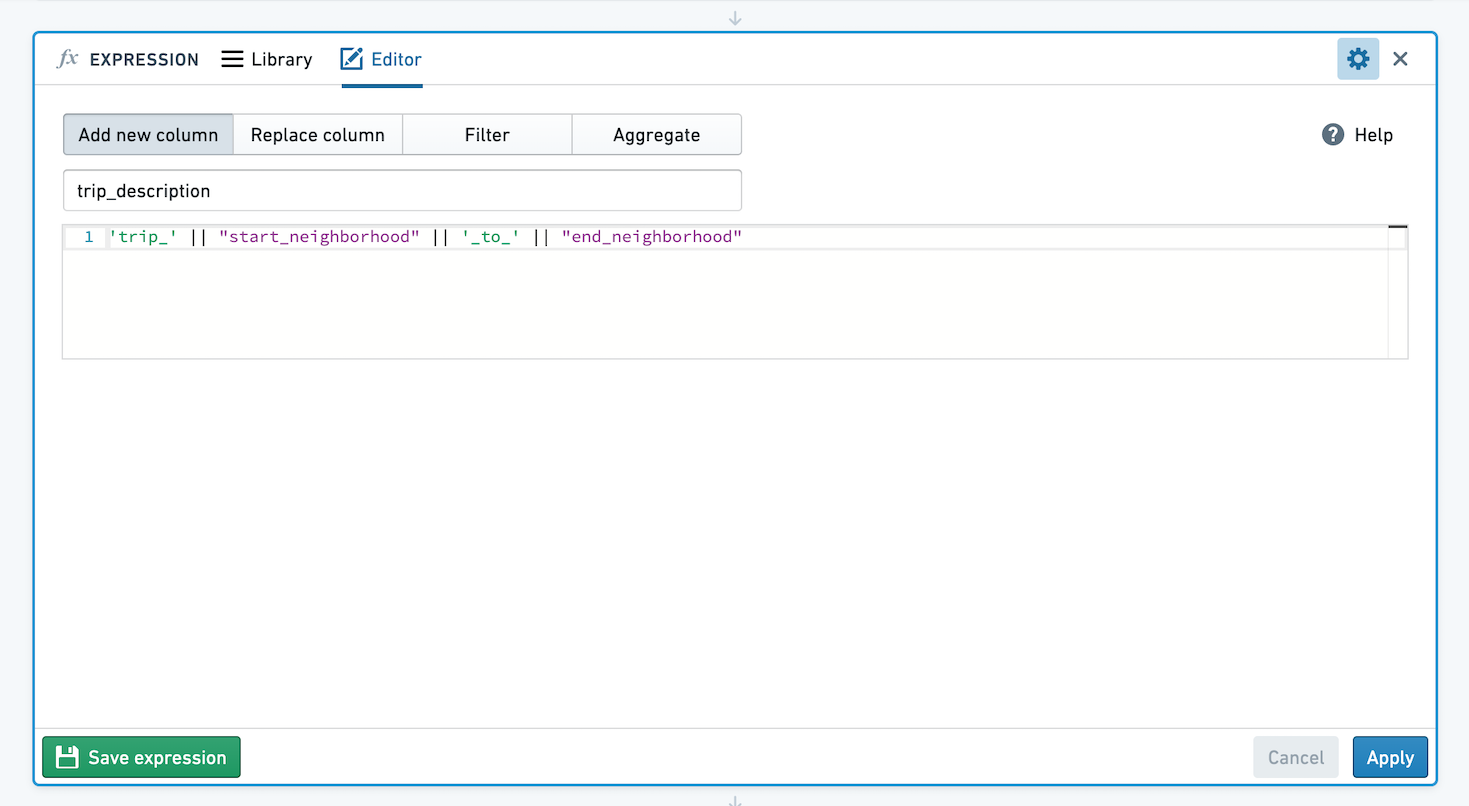
添加新列
输入新列的名称,以及构建它的表达式。例如,通过使用 year("birthdate_col") 从生日中提取年份来创建新列,或通过连接其他列的值来创建包含出租车行程描述字符串的列:
替换列
选择您要替换的列,以及用于替换的表达式。
使用表达式筛选数据
通过输入一个求值为布尔值的表达式来定义筛选条件。您的数据将被筛选为表达式求值为 true 的所有行。例如,使用 year("birthdate_col") == 1981 筛选只包含1981年出生的人的数据,或筛选出租车行程表以仅包含车费超过50美元的行程:
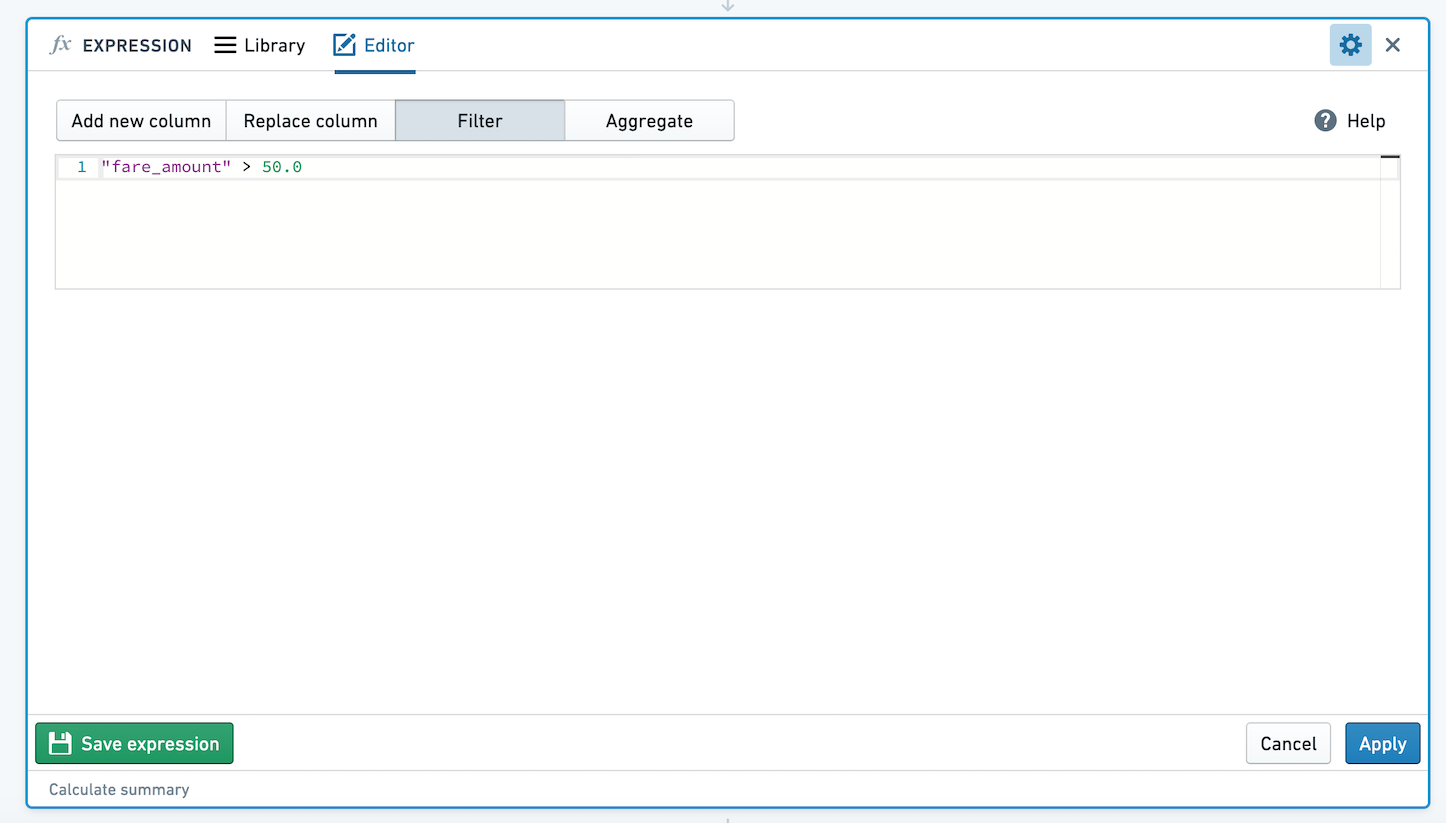
由于 SparkSQL 的限制,您不能在筛选表达式中使用窗口函数 (OVER 语法)。您可以使用它们来创建新列,如后面所示。
以下部分包含您可以在 Contour 中使用的筛选表达式示例。
常见示例
将列与静态值进行比较
# 判断出租车费用是否小于25.0
"taxi_fare" < 25.0
Copied!1 2# 比较字符串 "birth_date" 是否等于日期字符串 '1776-07-04' "birth_date" == '1776-07-04'
在表达式面板编辑器中,null = null 产生 true。这与 SparkSQL 不同,SparkSQL 中 null = null 解析为 null。
使用不等于运算符进行筛选
筛选出所有 league_id 不等于 ‘NHL’ 的行:
Copied!1league_id != 'NHL' # 判断变量 league_id 是否不等于字符串 'NHL'
比较两列
Copied!1 2 3 4"age" < "average_age" # 这里的代码比较两个字符串 "age" 和 "average_age" 的字典序。 # 在Python中,字符串比较是基于ASCII值的。 # 因此,这行代码会返回 True,因为 "age" 在字典序中小于 "average_age"。
筛选小费百分比(小费除以车费)大于或等于 average_tip_percentage 的行:
Copied!1("tip" / "fare") >= "average_tip_percentage" # 计算小费与车费的比率,判断是否大于等于平均小费百分比
删除包含空值的行
筛选出所有category不为空的行:
Copied!1 2# 检查"category"字段是否不为空 not isnull("category")
使用特殊字符拆分列
通过|拆分categories列。由于|是一个特殊字符的示例,需要对其进行转义以将其视为文字。
Copied!1SPLIT("categories", '\|')
这个代码片段使用了一个 SPLIT 函数来对字符串进行分割。具体来说,它将以竖线符号 | 作为分隔符来拆分字符串 "categories"。注意在正则表达式中,竖线符号 | 是一个特殊字符,所以在这里需要用反斜杠 \ 进行转义。
使用 LIKE 搜索模式
使用 SQL LIKE 运算符 ↗ 搜索列值中的模式。
匹配所有以 A 结尾的国家名称:
Copied!1"country_name" LIKE '%a'
该SQL语句用于查找country_name列中以字母'a'结尾的所有记录。
筛选多个条件
使用AND或OR组合两个或更多筛选表达式:
Copied!1 2# 判断起始区和终止区是否都是'Queens' ("start_borough" == 'Queens') AND ("end_borough" == 'Queens')
Copied!1 2"department" is 'sales' OR "department" is 'r&d' -- 这段代码用于检查“department”字段是否为“sales”或“r&d”。
查找最小值或最大值所在行
在数据分析中,一个常见任务是查找某个分区中某列的最小值或最大值所在的行。例如,您可能有一个包含患者记录的数据集,并希望找到每位患者最早访问办公室的日期。您可以使用两个表达式来找到这些行。
您必须先派生一个新列,然后使用该列进行筛选,而不是在筛选表达式中完成所有操作。这是因为由于SparkSQL的限制,无法在筛选表达式中使用窗口函数。
首先,派生一个新列以查找分区的最小值或最大值。在以下示例中,我们确定每辆出租车(由车徽号码标识)最近的一次乘车,创建一个新列most_recent_ride:
Copied!1max("pickup_datetime") OVER (PARTITION BY "medallion")
该 SQL 语句的作用是计算每个 "medallion" 分组中 "pickup_datetime" 的最大值。
PARTITION BY "medallion":将数据按照 "medallion" 列进行分组。OVER:指定窗口函数的范围。max("pickup_datetime"):对于每个分组,计算 "pickup_datetime" 的最大值。
如需复习窗口函数 (OVER) 的使用,请参阅高级表达式:窗口函数。
然后添加一个筛选表达式,将每行的接送日期值与其分区的最大值进行比较:
Copied!1 2# 比较字符串 "pickup_datetime" 和 "most_recent_ride" 是否相等 "pickup_datetime" == "most_recent_ride"
使用表达式聚合数据
此模式允许您使用group by表达式和聚合表达式来聚合数据。您可以有零个、一个或多个group by表达式,并且可以有一个或多个聚合表达式。每个group by和聚合表达式必须被命名,生成的表格将具有新的架构,每个表达式都有一列。
例如,给定以下表达式,通过起始邻域聚合平均出租车行程距离:
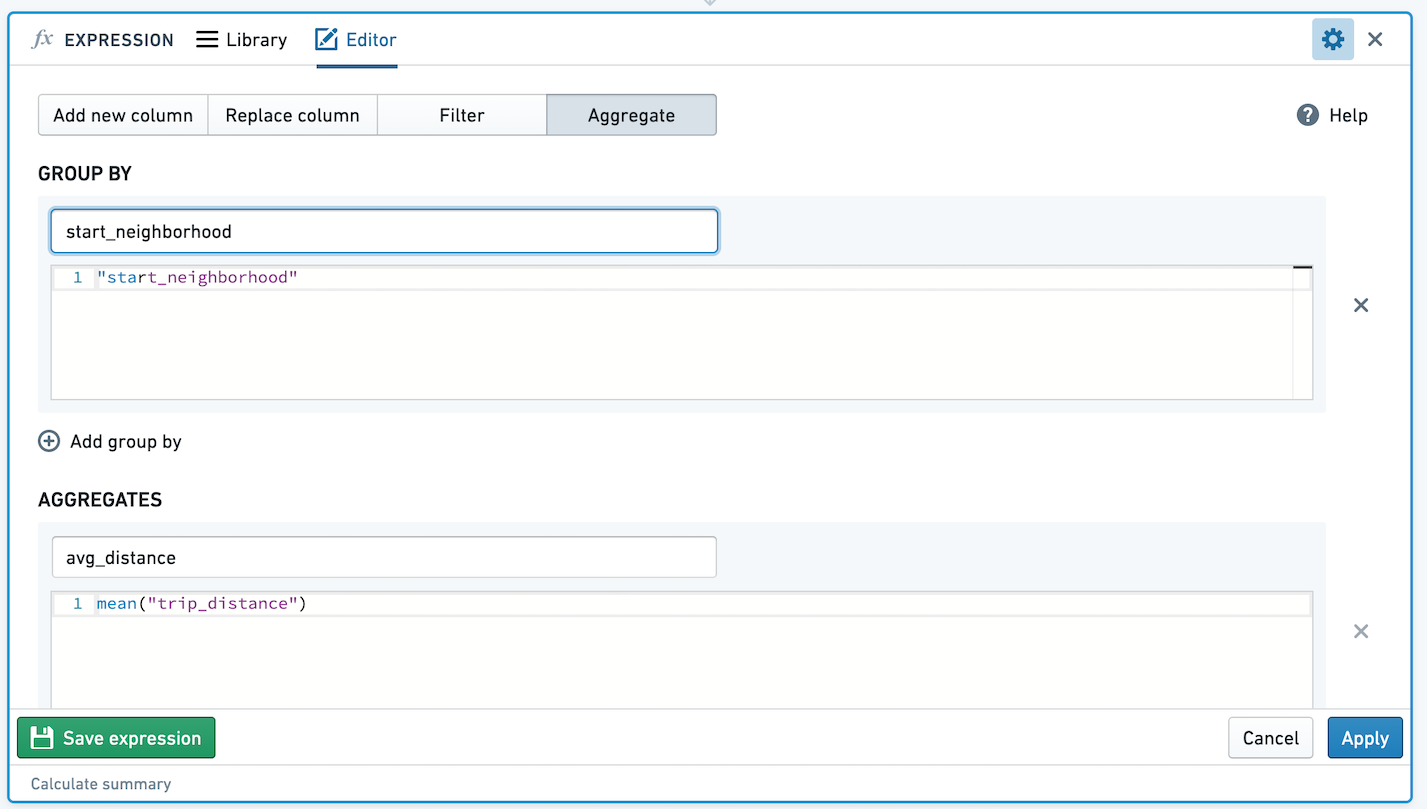
生成的表格将如下所示:
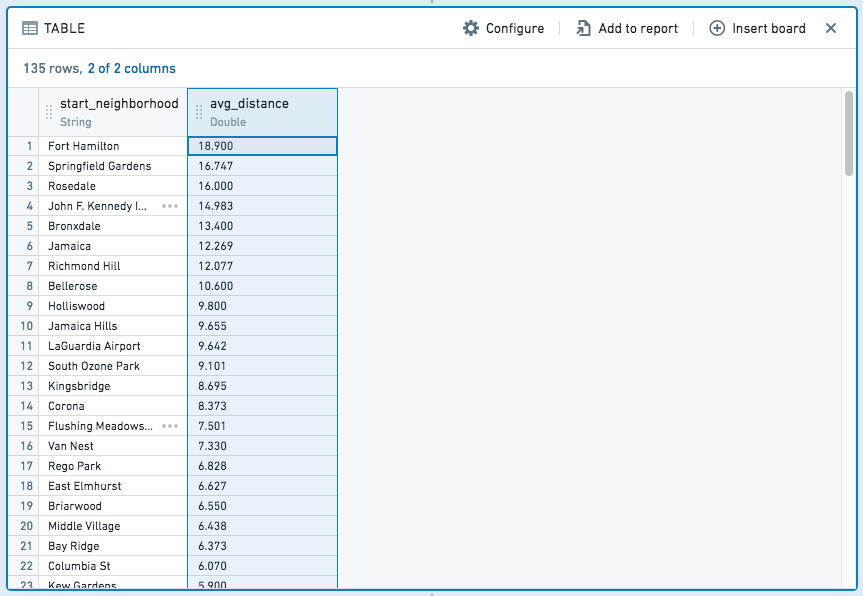
与添加列和筛选表达式不同,聚合表达式生成一个全新的表,包括每个聚合和group by分区的列。
例如,给定如下的假设数据集:
| id | name | sport | birthday | number_of_gold_medals |
|---|---|---|---|---|
| 1 | Jane | Swimming | 6/29/1985 | 6 |
| 2 | John | Gymnastics | 2/19/1971 | 3 |
| 3 | Mike | Swimming | 3/23/1971 | 7 |
| 4 | Michelle | Gymnastics | 9/12/1971 | 5 |
如果您想知道获得的金牌总数,您可以使用:
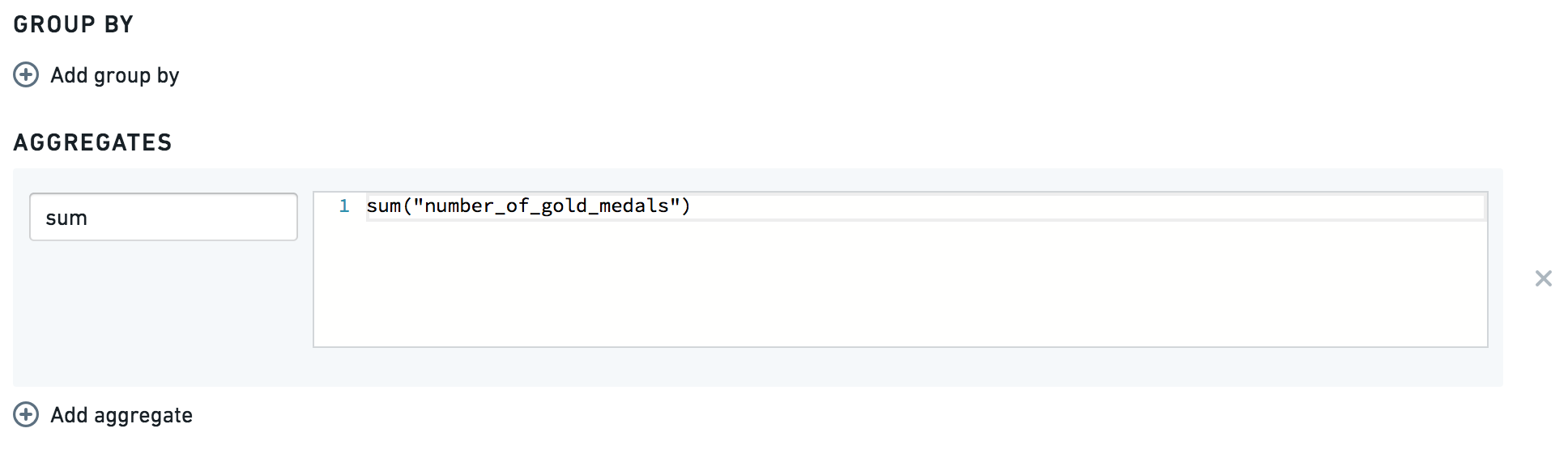
这将为您提供以下表格:
| sum |
|---|
| 21 |
如果您想知道按出生年份和运动项目获得的金牌总数和平均数,您可以使用:
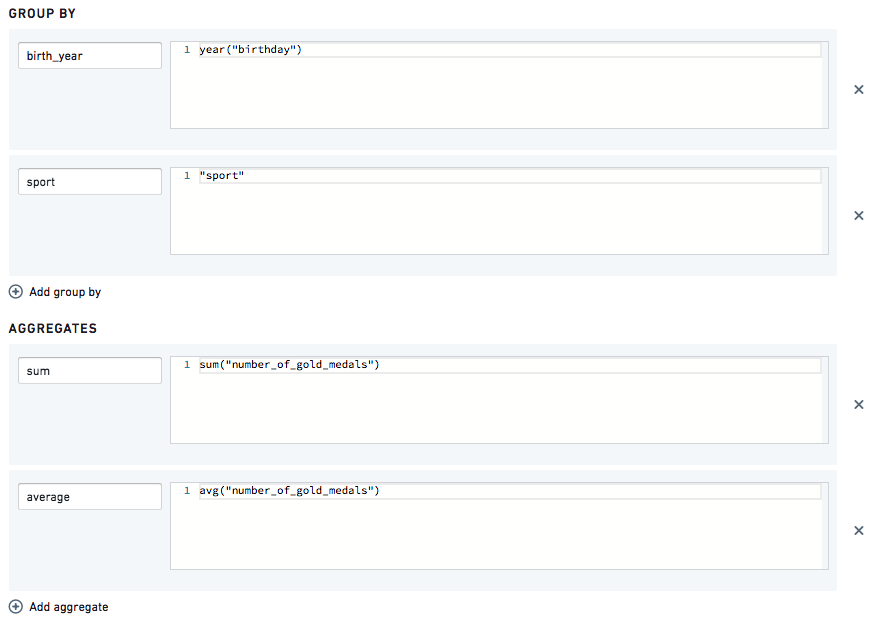
这将为您提供:
| birth_year | sport | sum | average |
|---|---|---|---|
| 1971 | Swimming | 7 | 7 |
| 1971 | Gymnastics | 8 | 4 |
| 1985 | Swimming | 6 | 6 |
如果您希望对聚合生成的新表进行分析,可以切换到聚合数据。
保存的表达式
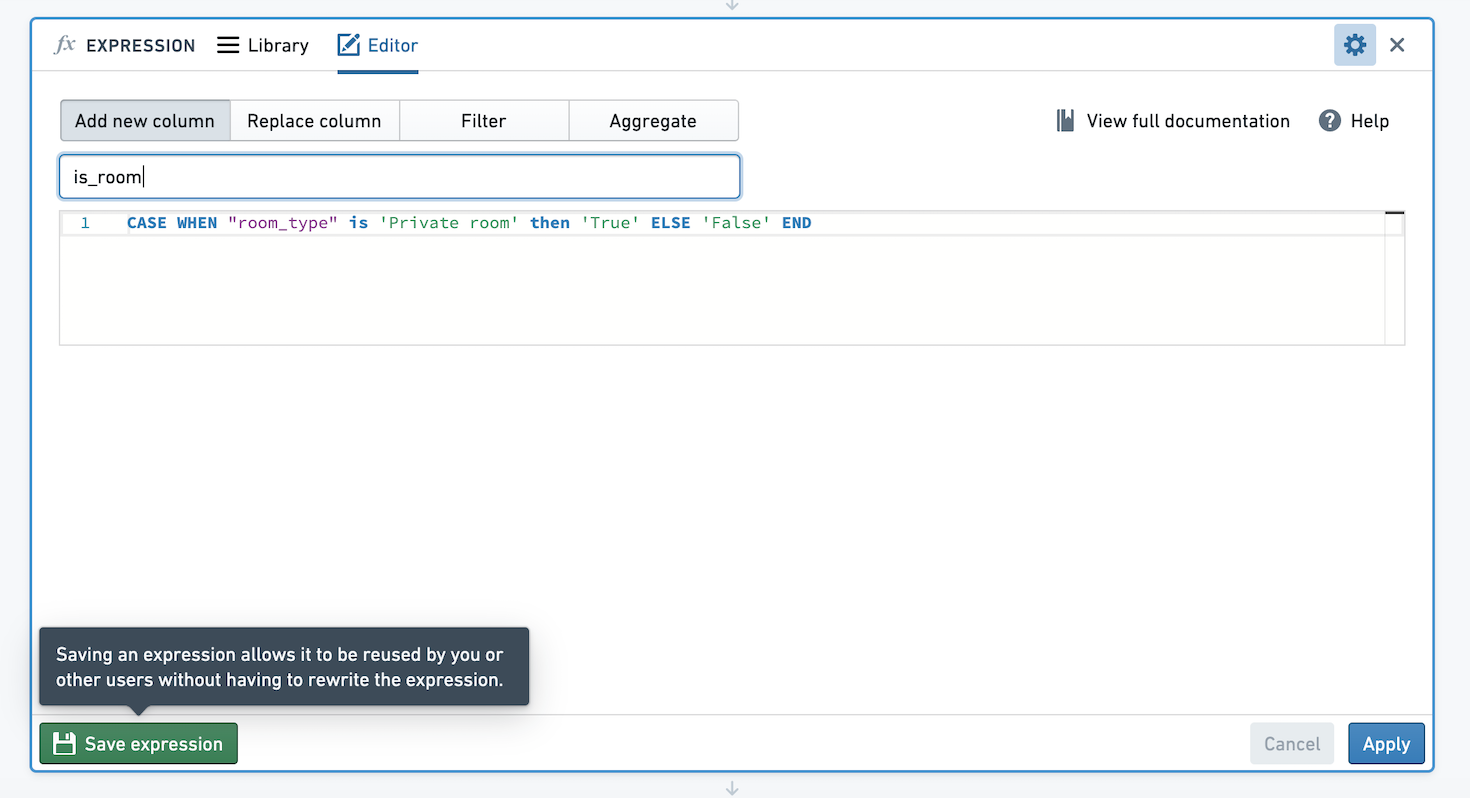
在Contour中,您可以保存表达式,以便轻松重用分析和路径中的逻辑,并与他人共享逻辑。假设我们创建了一个表达式,创建一个新列,如果列room_type的值是Private room则值为True,否则为False。我们希望保存此表达式,以便他人可以使用此逻辑。
点击表达式面板左下角的保存表达式。
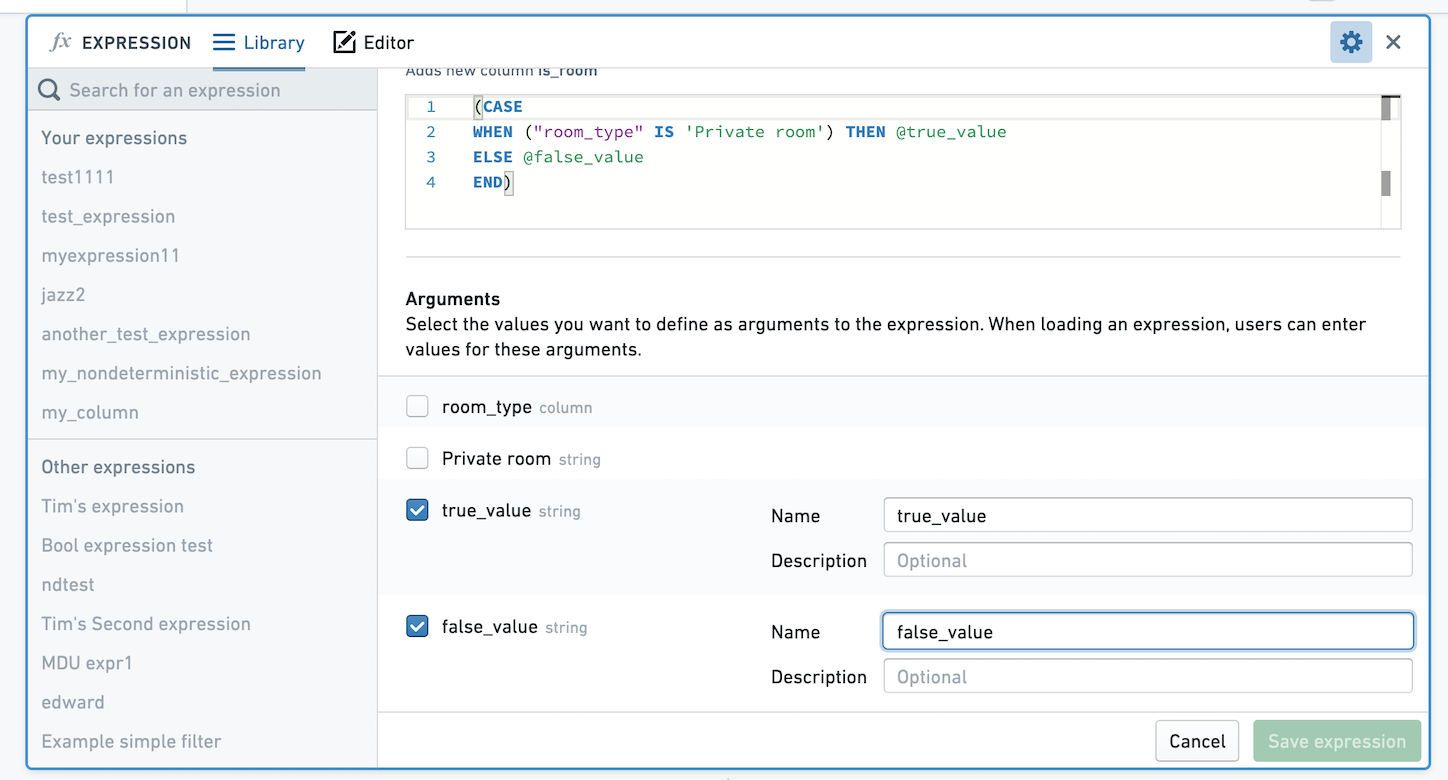
您可以选择保存没有参数的表达式,或者选择要定义为表达式参数的值。如果您保存没有参数的表达式,则在应用时表达式的逻辑将保持您定义时的样子。如果您选择定义参数,用户将能够选择不同的参数值。在下图中,我们将True和False的值参数化。
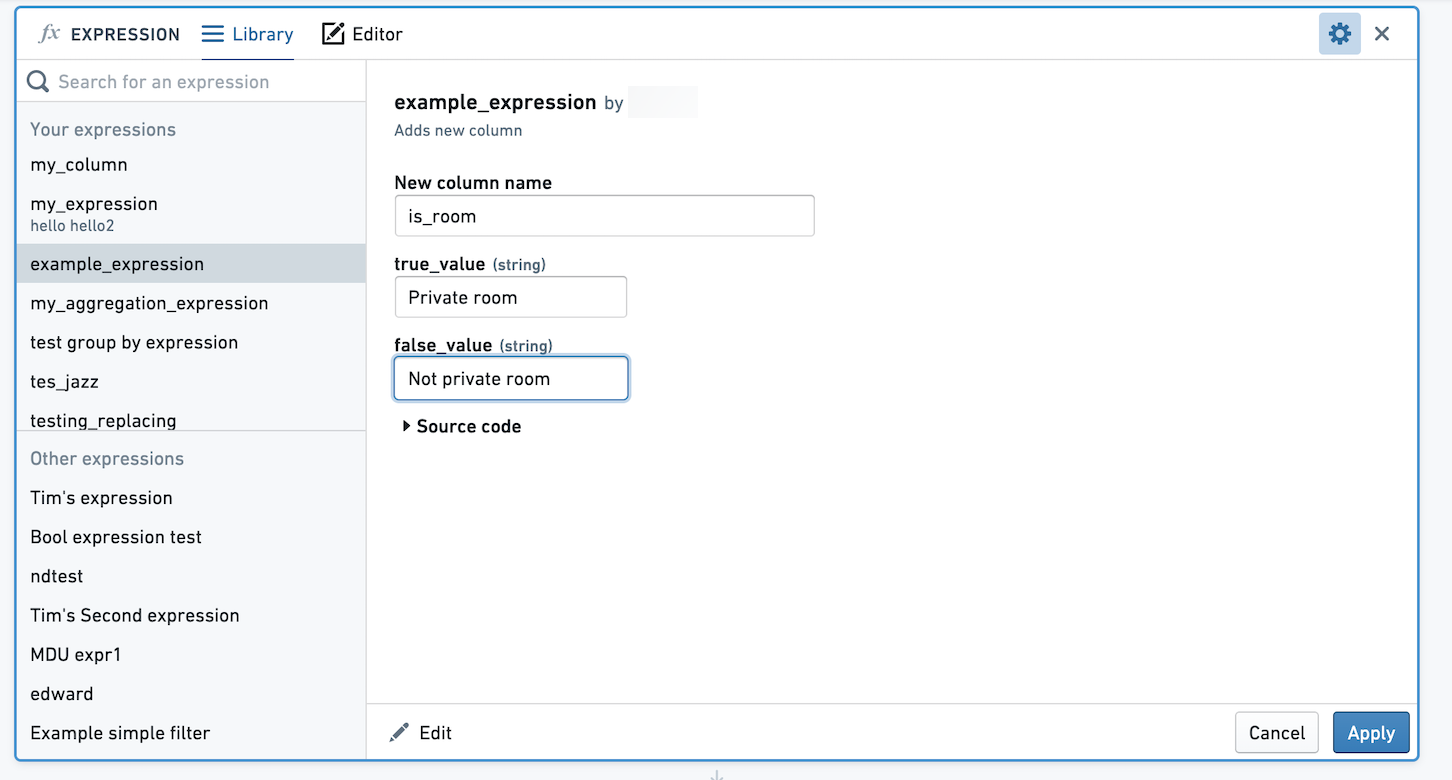
当您或其他用户选择应用此表达式时,系统会提示您选择true_value和false_value的值。在这里,这些值映射到Private room和Not private room。
保存的聚合表达式
聚合表达式用于基于零个或多个group by聚合数据。如果您保存一个没有group by的聚合表达式,表达式的用户将能够选择任意数量的列进行group by。
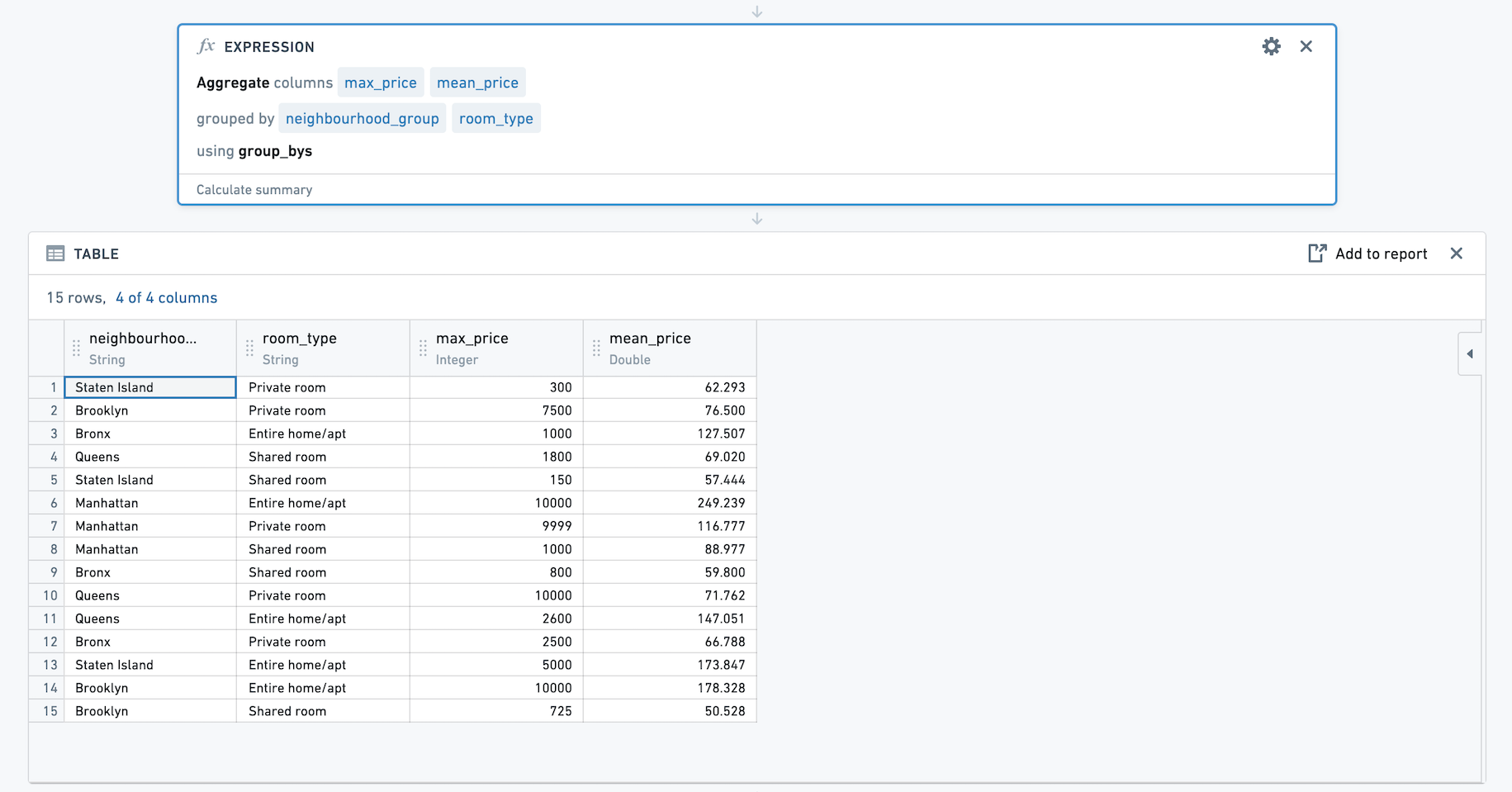
例如,下面我们有一个没有group by的聚合表达式和两个聚合,使用来自Inside Airbnb ↗的开源数据。这些聚合计算price的平均值和最大值。让我们保存这个聚合表达式。
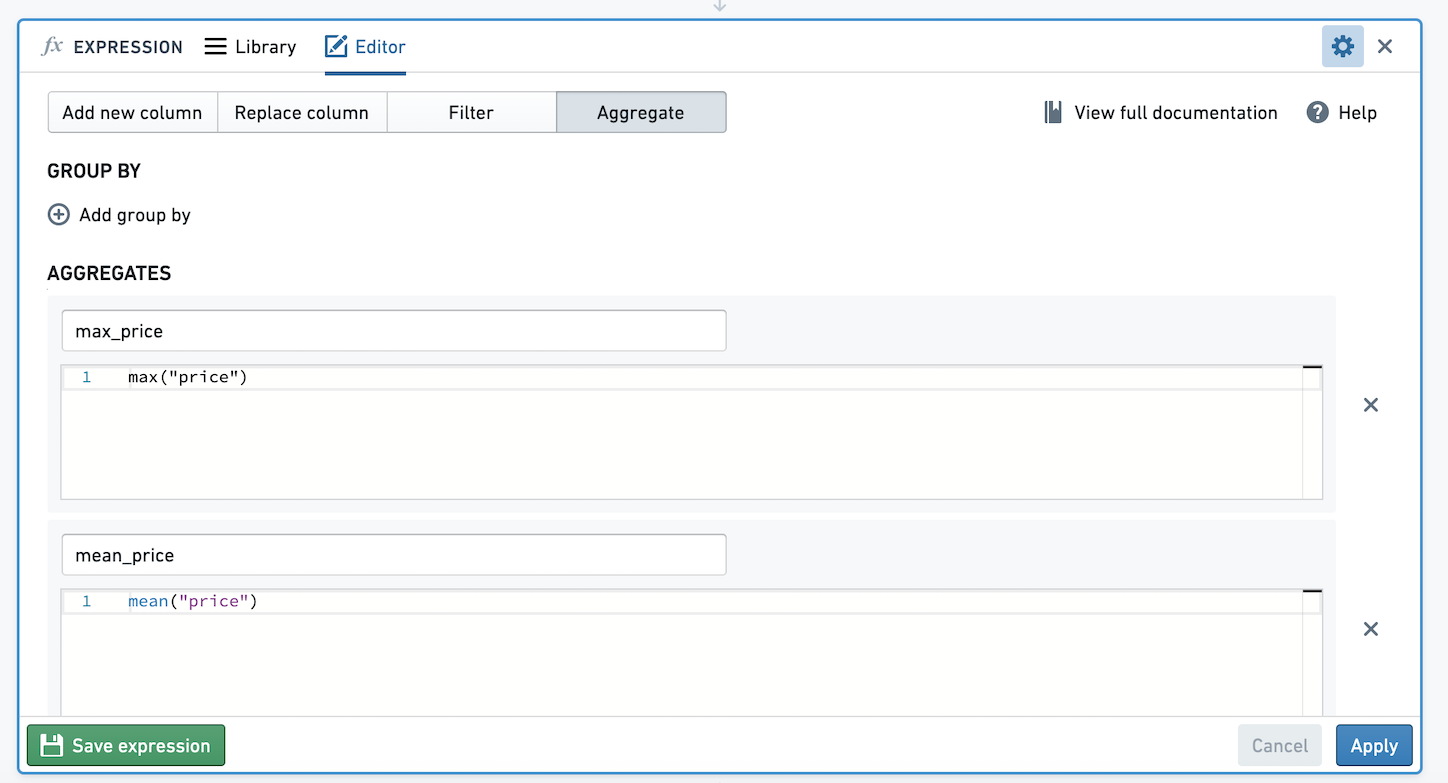
使用此表达式时,我们会看到一个列选择器。我们可以选择按多列进行group by。在这里,我们将计算每个neighbourhood_group和room_type组合的price的平均值和最大值。
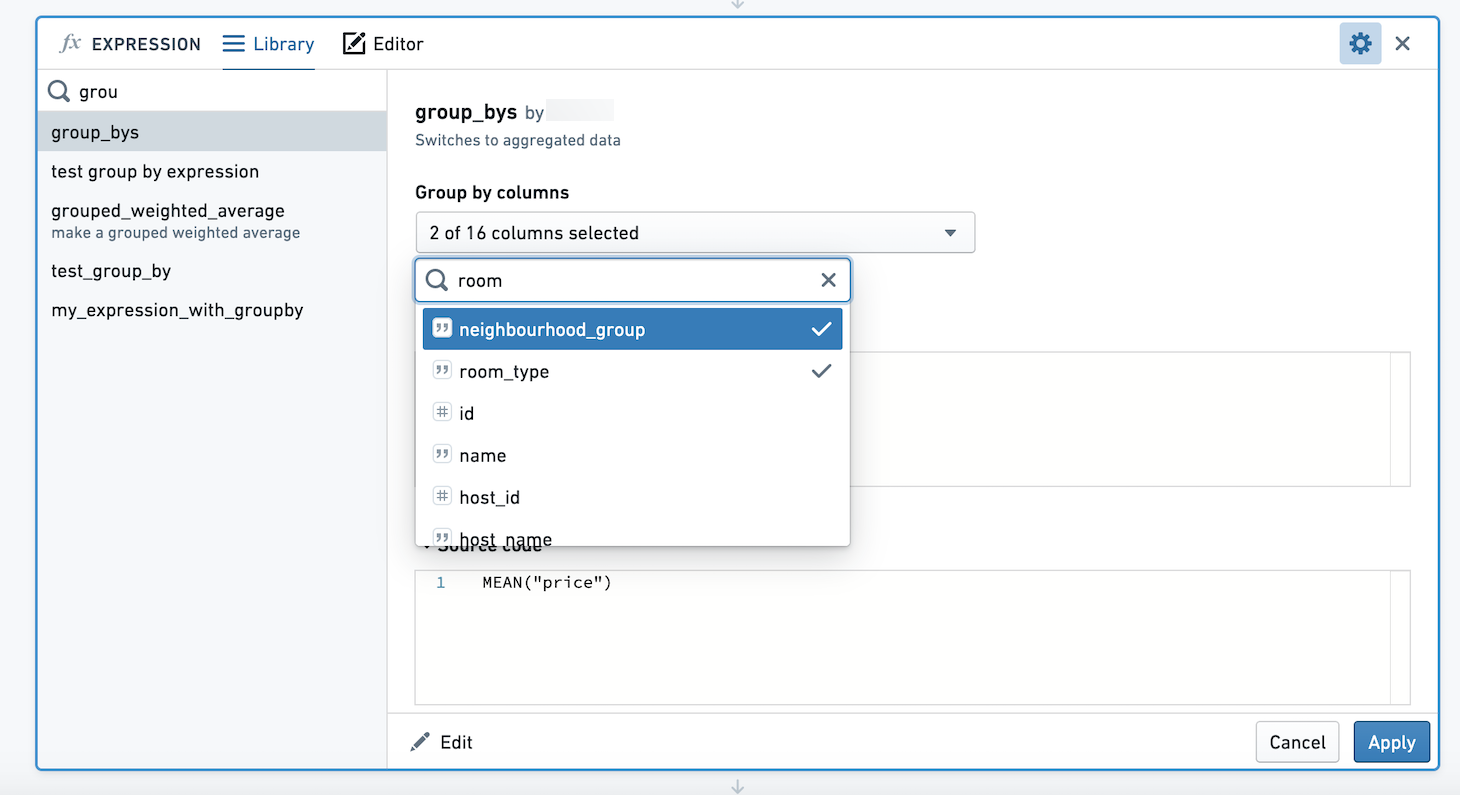
生成的数据集有四列,neighbourhood_group,room_type,max_price和mean_price。