注意:以下翻译的准确性尚未经过验证。这是使用 AIP ↗ 从原始英文文本进行的机器翻译。
概览
数据连接支持将 Foundry 中的数据集和流导出到外部系统。这在多种情况下非常有用:
- 在 Foundry 中使用数据管道清理和变换后的数据可以同步到数据仓库或数据湖等系统中。这种模式在"Palantir Foundry 如何推动您的数据平台" ↗中有更详细的描述。
- 使用批量部署创建的机器学习模型的推断结果可以导出到其他系统,以在整个组织内实现机器学习项目的运营化。
- 从终端用户在Ontology中捕获的操作数据可以写入其他系统,以便在 Foundry 之外进行分析。
数据连接导出尚未支持所有源类型。请查看源类型概览文档中列出的各个源页面以检查可用性。如果导出功能可用,每个源页面将列出文件导出、流式导出、表导出或传统导出任务支持。例如,Amazon S3源类型支持文件导出,而BigQuery源需要导出任务。
尚未支持文件、流式或表导出功能的一些源可能支持传统导出任务配置。对于实现更新导出功能的源类型,不再推荐使用导出任务。
为源启用导出
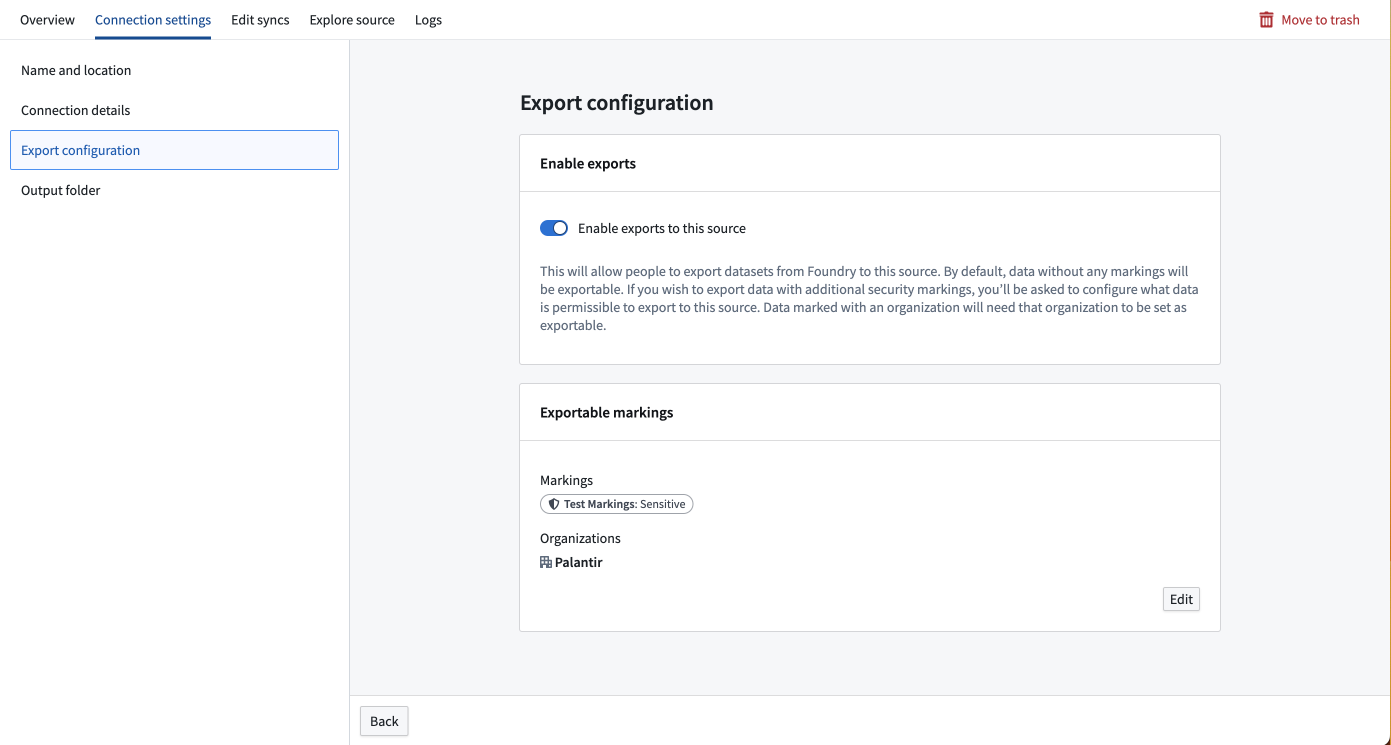
要导出数据,您必须在要导出的源的连接设置部分中启用导出。支持导出的源类型将在屏幕左侧显示一个导出配置选项卡。具有信息安全官角色的 Foundry 用户应导航到此选项卡并切换开启启用导出到此源的选项。
信息安全官是 Foundry 中的默认角色;用户可以在控制面板的注册权限下被授予信息安全官角色。
启用导出后,您必须提供可以导出到此源的一组权限标记。如果在导出配置中未添加权限标记和组织,则具有这些权限标记或组织的数据将无法导出到此源。要添加可导出的权限标记,用户必须同时是信息安全官并拥有希望允许导出到此源的权限标记或组织的取消标记权限。
例如,您可能在Palantir组织中有一个具有敏感权限标记的数据集。要导出此数据集,您必须将敏感权限标记和Palantir组织都添加到此源的可导出权限标记集合中。
在数据连接源配置中输入的凭据必须对外部系统中的表具有写入权限。例如,S3需要"s3:PutObject"权限。如果目标路径尚不存在,其他文件导出可能需要特定权限来创建目录。表导出在使用截断导出模式时可能需要额外的权限。
请查看源类型概览文档中列出的各个源页面,以获取源特定的注意事项。
创建新导出
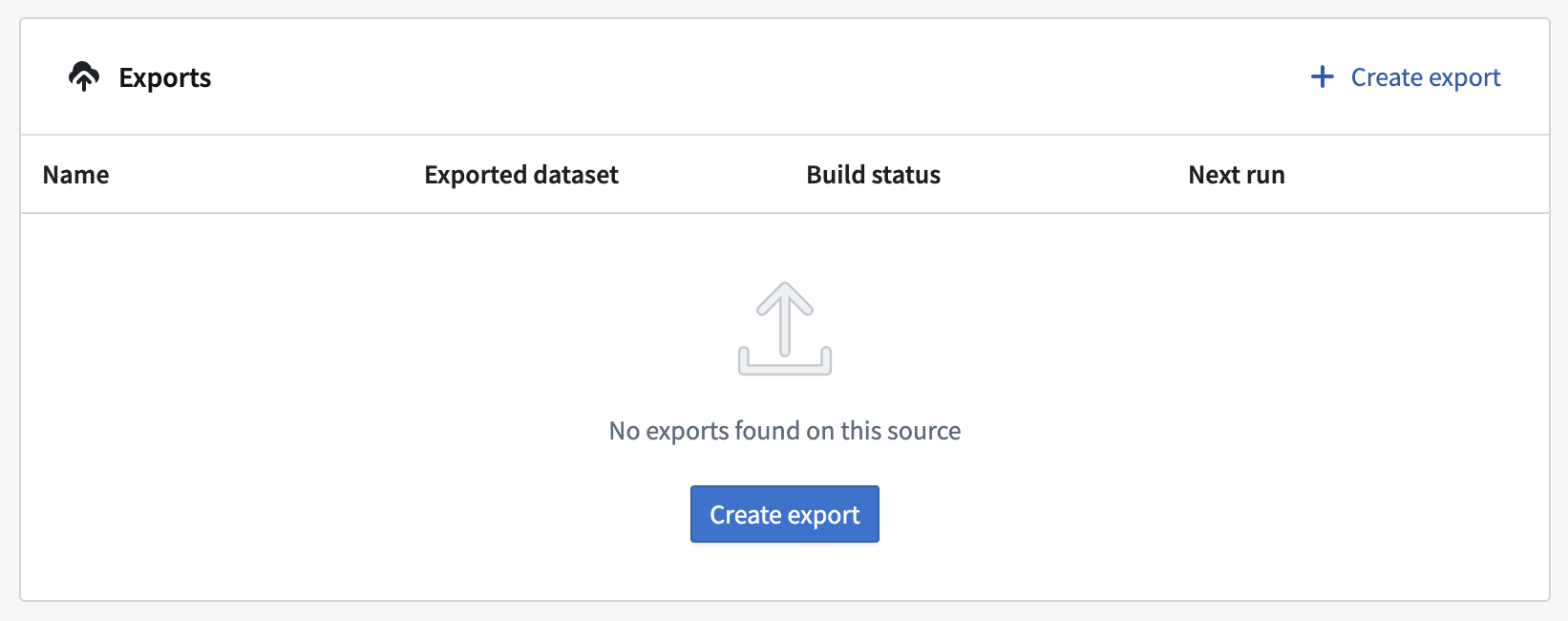
要创建导出,首先导航到要导出的源的概览页面。
如果这是您为给定源设置的第一个导出,您将看到一个空表格和一个创建导出的按钮。
选择创建导出,然后选择要导出的数据集或流,以及任何源特定的导出配置选项。这些选项因源连接器而异,具体说明在我们文档中的相应源类型页面中。如果导出数据集上存在多个分支,只有主分支上的数据会被导出。
下面的示例展示了S3连接器的导出配置界面:
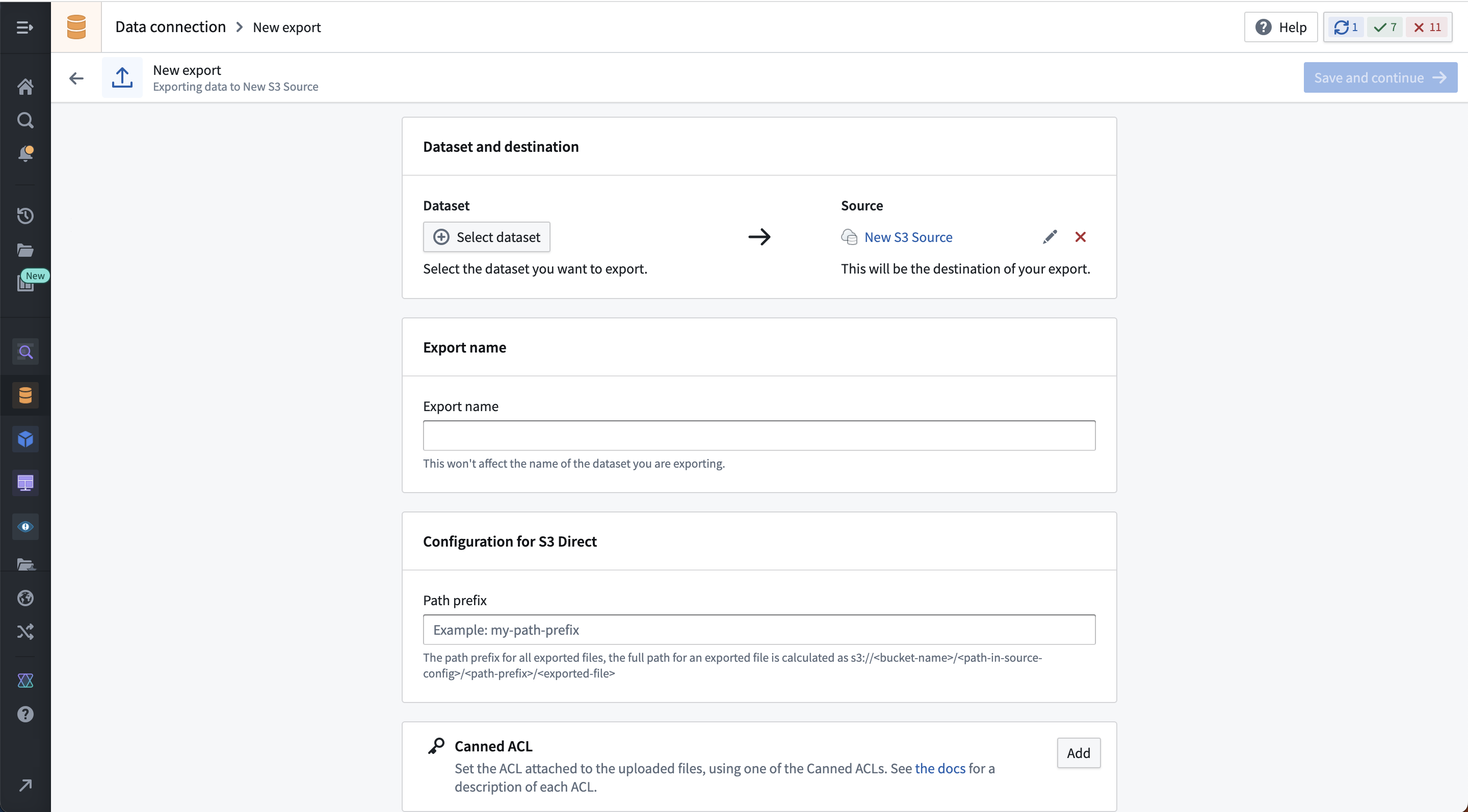
保存导出后,您将进入导出管理页面,在这里您可以进行以下操作:
- 手动运行导出。
- 为导出设置计划。
- 查看导出历史。
- 修改配置选项。
流式导出使用开始/停止按钮而不是运行按钮。如果在流式导出上配置了计划,它的行为将类似于其他流上的计划;如果流在计划触发时被停止,它将自动重新启动。如果流在计划触发时未被停止,它将继续运行。
某些源导出选项在初始设置后可能不可编辑。如果必须更改不可变选项,则必须删除并重新创建导出。
导出类型
导出的行为将取决于目标系统可以接受的数据类型。
| 导出类型 | 概述 |
|---|---|
| 文件导出 | 用于导出到没有架构的系统。数据集中的原始文件按计划复制并写入目标系统。 |
| 流式导出 | 用于持续导出到支持事件流的系统。来自 Foundry 流的记录被持续推送到目标系统。 |
| 表导出 | 用于导出到具有架构的系统。根据所选的导出模式,数据集的行按计划插入到目标系统。 |
文件导出
支持文件导出的系统示例是 S3。
文件导出将所选 Foundry 数据集中的文件写入配置的目的地。默认情况下,只有自上游数据集中上次成功导出的事务以来修改的文件才会被写入。这意味着,如果文件在给定事务中未更新,则在任何下游导出的下次计划或手动运行时,它将不会被重新导出。
如果必须重新导出整个数据集,请在相同源上设置新的导出或确保您的上游变换覆盖必须导出的所有文件。
默认情况下,如果目的地中已存在文件,导出任务将用导出的数据覆盖该文件。此行为可能因源类型而异。为避免意外覆盖存储在目标系统中的数据,我们建议创建一个专用子文件夹来存放从 Foundry 导出的数据。
流式导出
支持流式导出的目标示例是 Kafka。
导出到流式目的地将在 Foundry 中运行导出任务期间将记录流式传输到目的地。如果任务被停止并重新启动,它将从停止的地方继续流式传输记录。
流式导出重播行为
在配置到流式目的地的导出时,必须指定流在 Foundry 中重播时的期望行为。通常,在对处理逻辑进行重大更改后,流会被重播。在这种情况下,必须使用以下方式之一重新处理以前处理的记录:
-
**导出重播记录:**当流重播时,重新导出所有记录。请注意,任何先前导出的记录将再次导出,并且外部系统必须配置为处理重复项。
-
**不导出重播记录:**暂停导出,直到重播偏移与导出任务中的最新偏移匹配。由于偏移在重播流中不保证匹配,此选项通常会导致一些记录丢失而无法导出。
使用直接连接运行时,尚不支持导出到流式目的地。您必须使用代理代理或代理工作者运行时来执行流式导出。
表导出
截至 2024 年 6 月,表导出已普遍可用,但可能不适用于所有源类型。可用时,表导出优于导出任务。要检查源类型是否支持表导出,请访问数据连接中的新源页面并查找表导出标签,或访问相关源类型的文档页面。
表导出允许导出到包含已知架构的表格数据的系统,其中外部目标架构与您希望导出的 Foundry 数据集的架构匹配。表导出将执行系统特定的INSERT语句或等效的 API 调用,根据所选表导出模式将行写入目标表,如下所述。
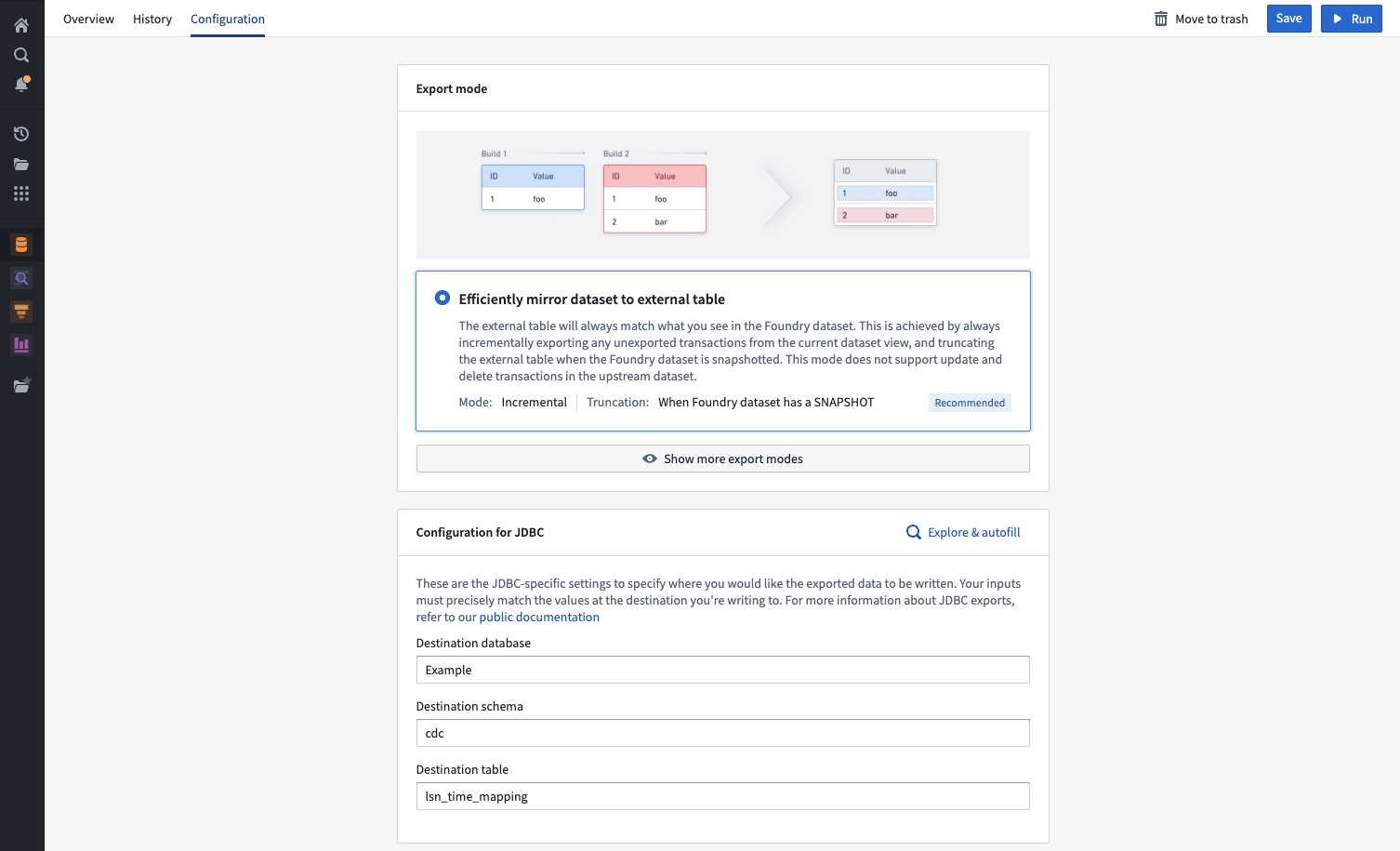
表导出模式
选择的导出模式指定在表导出期间如何导出数据。所有表导出都可用以下导出模式,并且在数据连接中的导出设置页面上也有解释。
| 表导出模式 | 描述 |
|---|---|
| 高效地镜像数据集到外部表(推荐) | 外部表将始终与您在 Foundry 数据集中看到的内容匹配。 这是通过始终增量导出当前数据集视图中的任何未导出事务并在正在导出的 Foundry 数据集中有 SNAPSHOT事务时截断外部表来实现的。此模式不支持正在导出数据集中的 UPDATE和DELETE事务。 |
| 无截断的完整数据集 | 始终导出 Foundry 数据集整个视图的快照,而不首先截断外部表。 注意:此选项几乎总是会导致外部表中的重复。此选项在外部系统在每次运行后消耗并移除行或您希望重新导出已导出的行时很有用。 |
| 带截断的完整数据集 | 此选项将截断(删除)目标表,然后导出完整当前数据集视图的快照。 这将导致外部表始终镜像 Foundry 数据集,但效率低于增量选项“高效地镜像到外部表”。 如果在导出之间对外部表进行了编辑并且您希望始终覆盖它们,此选项可能有用。 |
| 增量导出 | 仅导出当前视图中的未导出事务,而不截断目标表。 此模式不支持正在导出数据集中的 UPDATE和DELETE事务。此选项仅使用APPEND事务镜像数据集,以避免再次导出相同的数据。如果上游数据集中有SNAPSHOT事务,此模式可能会在目标表中产生重复记录。 |
| 带截断的增量导出 | 此选项截断(删除)目标表,然后仅导出当前视图中尚未导出的事务。 当将目标表视为消息队列时,此模式很有用(例如,当另一个任务从表中提取行并将其写入其他地方时)。 注意:此模式不支持上游数据集中的 UPDATE和DELETE事务。 |
增量导出且在非APPEND时出错 | 仅导出当前视图中的未导出事务,如果有SNAPSHOT、UPDATE或DELETE事务(在第一次运行后)则出错。此选项只要包含 APPEND事务,就会镜像 Foundry 数据集。它可以防止在 Foundry 数据集中出现快照的情况下可能重新导出所有数据,并保证不会将重复数据导出到目标表。 |
导出模式不适用于传统导出任务。
表导出中的 SQL 方言
表导出目前支持自定义 JDBC 源类型。尽管 Foundry 为特定系统(如 Oracle)提供专用连接器,但只有通过自定义 JDBC 连接建立连接时,表导出源功能才会出现为选项。
您必须确认 Palantir 用于导出数据的 INSERT 语句语法与您的系统将接受的 SQL 方言兼容。下面,您可以找到 Palantir 用于导出到自定义 JDBC 源的 INSERT 语句示例。这些语句目前无法自定义。如果您的系统不接受运行导出时使用的语句,您可以依靠基于代码的连接选项写入您的系统。
您还必须确保数据库中使用的类型与下面列出的支持类型兼容。
支持类型列表
支持的 JDBC 源类型包括:
DECIMALBIGINTBINARYBOOLEANSMALLINTDATEDOUBLEFLOATINTEGERVARCHARTIMESTAMP
不支持的 JDBC 源类型列表
不支持的 JDBC 源类型包括:
ARRAYMAPSTRUCT- 其他上面未列为支持的类型(如不常见的类型如
GEOGRAPHY)
如果您的数据集包含不支持类型(如ARRAY、MAP或STRUCT)的列,则导出将失败。
表导出将触发的 INSERT 语句示例
下面的示例提供了表导出使用的语法的更多信息。如果您的源系统不支持此格式的 INSERT 语句,则 INSERT 语句将在运行时失败。
假设在我们的源系统中存在一个target_table,其架构与 Foundry 中相应的数据集相同。外部源和 Foundry 之间的列名和数据类型必须匹配。以下是 Foundry 中数据集的模拟示例:
| column1 | column2 | column3 |
|---|---|---|
| value1 | value2 | value3 |
| value4 | value5 | value6 |
| value7 | value8 | value9 |
单行的INSERT语句遵循以下通用格式:
Copied!1 2INSERT INTO target_table (column1, column2, column3) VALUES ('value1', 'value2', 'value3'); -- 向目标表(target_table)中插入一行数据,指定列为column1, column2, column3,分别对应的值为'value1', 'value2', 'value3'。
根据源类型,插入语句将应用于一行或多行数据。例如,Snowflake支持批量插入,因此允许一次写入多行。
Copied!1 2 3 4 5 6-- 将多行数据插入到目标表 target_table 中 INSERT INTO target_table (column1, column2, column3) VALUES ('value1', 'value2', 'value3'), ('value4', 'value5', 'value6'), ('value7', 'value8', 'value9');
相比之下,像 Apache Hive 这样的源对批量插入的支持有限,将通过三个后续的插入语句进行导出。
Copied!1 2 3 4-- 将数据插入到目标表 target_table 中 INSERT INTO target_table (column1, column2, column3) VALUES ('value1', 'value2', 'value3'); -- 插入第一行数据 INSERT INTO target_table (column1, column2, column3) VALUES ('value4', 'value5', 'value6'); -- 插入第二行数据 INSERT INTO target_table (column1, column2, column3) VALUES ('value7', 'value8', 'value9'); -- 插入第三行数据
示例 TRUNCATE TABLE 语句
像 Full dataset with truncation 这样的导出选项将首先在外部源截断目标表,然后运行插入语句。实现此操作的实际代码如下例所示:
Copied!1 2 3 4 5-- 清空表格数据 TRUNCATE TABLE table_name; -- 将数据插入目标表 INSERT INTO target_table (column1, column2, column3) VALUES ('value1', 'value2', 'value3');
下一步
如果需要更具体的方言,我们推荐使用 Foundry 的基于代码的连接选项,例如外部变换。
表导出的特殊注意事项
- 从 Foundry 导出的数据集必须与外部源一一匹配,包括精确的列名称(区分大小写)和数据类型。例如,将类型为
LONG的COLUMN_ABC导出到目标地,其中COLUMN_ABC的类型为STRING,将在运行时失败。 - 设置表导出时,请确保
DATABASE、SCHEMA和TABLE字段已填写(如果您的源要求)。缺少任何这些字段将导致导出在运行时失败。同样,包含不必要的字段也可能导致失败。为了最高的可靠性,请使用探查源和自动填充来选择您源中的目标。 - 使用代理运行时进行表导出时,代理必须在 Linux 主机上运行。不支持在 Windows 代理上运行表导出。
- 导出到表格目标的数据集的底层文件必须是 Parquet 格式。CSV 和其他支持架构的文件类型将无法导出。
- 目标表必须已存在于源系统中;Foundry 不会自动创建。
- 使用执行截断的导出模式时,Foundry 源配置中输入的凭据必须具有在外部系统中截断表的权限。
Array、Map和Struct类型不支持导出。如果您要导出的数据集包含类型为Array、Map或Struct的列,导出将失败。
调度导出
应定期调度导出,将最近的数据导出到外部目标。流导出不需要调度,因为它们只需启动或停止。
要调度导出,请导航到导出的 概览 页面。然后,选择 添加调度 以在数据沿袭中打开导出。从那里,在屏幕右侧选择 创建新调度 并像为其他任何任务一样配置。了解更多关于可用的调度选项。
查看触发特定导出的任何调度,如下所示,在该导出的 概览 页面上查看:
导出历史
与同步类似,导出作为任务在 Foundry 的构建系统中运行。导出的 历史 视图显示了与之关联的任务的历史。每个任务都可以通过在 任务详情 部分的右上方选择 查看构建报告 来打开和查看。
对于流导出,导出历史还将显示流导出任务当前是否正在运行或已停止。
变换导出数据
一般来说,导出不支持作为导出任务一部分执行的任何数据变换。这意味着您选择导出的数据集或流应该已经是您所需的格式,包括筛选、重命名或重新分区的文件以及任何其他数据变换。
Pipeline Builder 和 Code Repositories 是 Foundry 用于构建数据变换管道的工具;这两个应用程序应该提供完整的工具来准备您的数据以供导出,包括任务可扩展性、监控、版本控制以及编写任意逻辑的灵活性。
可以在导出到 Kafka 时允许 Base64 解码流记录。有关 Kafka 导出的更多信息,请查看完整的 Kafka 连接器文档。
导出与导出任务
表导出旨在完全替代现已日落的导出任务,根据发布的产品生命周期,这些任务最终将被弃用。虽然导出任务提供的许多功能在新的导出选项中可用,但在功能和配置上存在一些差异。
从导出任务迁移到表导出
从导出任务到新导出选项的迁移必须手动执行。使用下文记录的选项配置您的导出;一旦新的导出过程按预期工作,手动删除之前使用的导出任务。
如果导出任务中可用的功能在新的导出中没有等效选项,建议的迁移是切换到使用外部变换。外部变换为执行与外部系统交互的自定义逻辑提供了灵活的替代方案,并且旨在在源功能的 UI 配置选项无法覆盖所需功能时使用。
导出与导出任务的功能比较
| 导出任务选项 | 新导出中支持? | 详情 |
|---|---|---|
parallelize: <boolean> | 取决于源类型 | 这可能与每个源相关,支持将在特定源的导出设置中记录(如果可用) |
preSql: <sql statements> | 不支持 | 如果您的应用案例需要此功能,请使用外部变换。 |
stagingSql: <sql statements> | 不支持 | 如果您的应用案例需要此功能,请使用外部变换。 |
afterSql: <sql statements> | 不支持 | 如果您的应用案例需要此功能,请使用外部变换。 |
manualTransactionManagement: <boolean> | 不支持 | 如果您的应用案例需要此功能,请使用外部变换。 |
transactionIsolation: READ_COMMITTED | 不可配置 | 这可能作为源配置选项可用,并将在执行导出时应用。查看源特定文档以了解此配置选项是否可用。 |
datasetRid: <dataset rid> | 支持 | 您希望导出的数据集或流 |
branchId: <branch-id> | 不可配置 | 数据始终从 master 分支导出。 |
table:database: mydb # 非必填schema: public # 非必填table: mytable | 支持 | 这些选项是特定于JDBC源的表导出。 |
writeDirectly: <boolean> | 不可配置 | 新导出始终使用等同于 writeDirectly: true 的选项。 |
copyMode: <insert|directCopy> | 不可配置 | 新导出始终使用等同于 copyMode: insert 的选项。 |
batchSize: <integer> | 取决于源类型 | 批量大小支持JDBC源上的导出,但可能不支持其他源类型。 |
writeMode: <ErrorIfExists|Append|Overwrite|AppendIfPossible>incrementalType: <snapshot|incremental> | 支持 | 这些选项共同类似于上文记录的表导出模式。并非所有组合对导出任务都有效,这些组合已被规范化为表导出的六种模式。 |
exporterThreads: <integer> | 不支持 | 如果您需要对导出线程进行精细控制,请使用外部变换。 |
quoteIdentifiers: <boolean> | 不支持 | 该选项仅在目标系统中创建表时相关,而新导出不支持此操作。表必须在配置导出之前存在。 |
exportTransactionIsolation: READ_UNCOMMITTED | 不可配置 | 与 transactionIsolation: READ_COMMITTED 类似,事务隔离将从源配置中获取(如果可用并已配置)。 |