注意:以下翻译的准确性尚未经过验证。这是使用 AIP ↗ 从原始英文文本进行的机器翻译。
设置流式同步
同步 是从源读取特定数据并将其摄入Foundry的任务。例如,如果您有一个包含多个表的关系数据库源,您可以配置同步以将特定表摄入Foundry。
流式同步类似于非流式(即批处理或增量)同步,但存在一些差异。主要区别在于批处理或增量同步会定期运行,而流式同步会持续运行,以尽可能低的延迟将数据拉入Foundry。
下面,我们将讨论创建同步所需的步骤:
- 定义要同步的数据。
- 在Foundry中定义一个位置以发送数据。
- 配置流式同步。
- 运行流式同步。
在本教程中,我们将使用一个Kafka源来设置同步。
第1部分:定义数据
首先,决定您想同步到Foundry的数据。在Data Connection中选择您的流式源,然后选择右上角的可用操作:
- 浏览和创建同步: 如果您的源类型支持源浏览,此选项将出现,允许您在创建同步时浏览数据源。
- 创建同步: 如果您的源类型不支持源浏览,则会出现此选项。

浏览和创建同步
如果您的源类型支持源浏览,您将进入Data Connection中的浏览源页面,该页面显示可同步的数据。浏览视图界面取决于您使用的源类型。例如,Kafka源浏览允许您查看Kafka代理上的主题 ↗并预览这些主题中包含的数据。
在Kafka浏览视图中,您可以在页面左侧的列表中查看现有主题。
选择一个主题将让您预览该主题的数据样本。
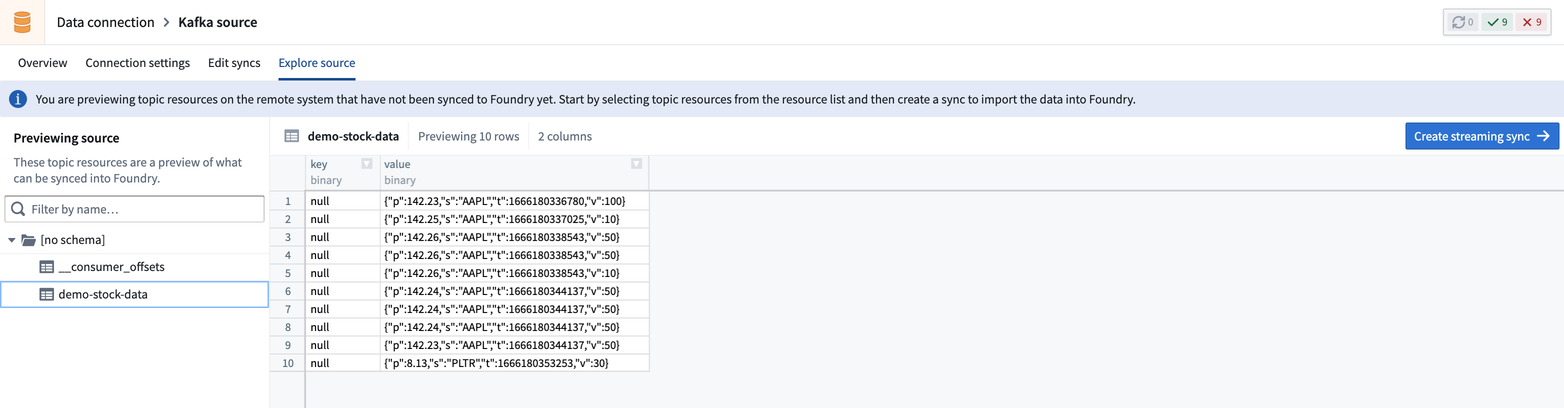
第2部分:定义同步位置
接下来,您需要决定将同步的数据集保存到Foundry中的位置。数据集的位置将决定谁有权限访问生成的数据集,这基于项目级别权限。
我们建议将同步的数据集保存到其源所在的项目旁边,使它们具有相同的权限;匹配的数据集和源权限在创建数据管道时非常有用。了解更多关于数据管道推荐的项目结构。
选择同步位置后,点击右上角的创建流式同步。
第3部分:配置流式同步
现在,您将进入Data Connection中的同步创建页面,您可以在此为您的同步定义源特定和核心流式配置。
- 源特定: 位于配置页面顶部,这些选项取决于您的源类型,并配置传递给您正在连接的特定源的参数。
- 核心流式: 位于源特定配置下方,这些选项对所有流式同步通用。核心配置包括吞吐量、模式和同步目标。
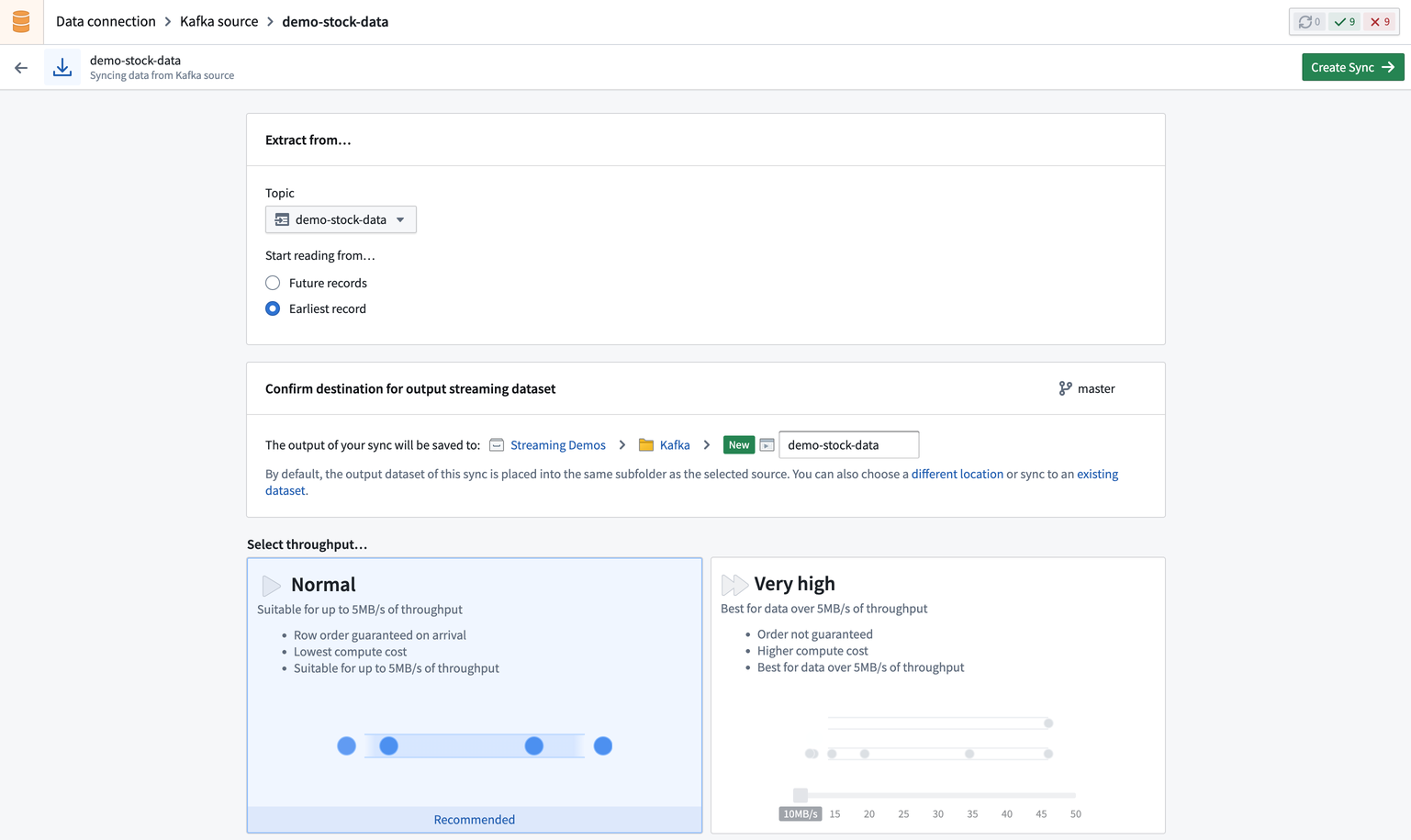
接下来,选择您流的吞吐量。吞吐量决定将创建的分区数量。选择较多的分区数量可以实现更高的吞吐量。选择正常吞吐量将允许该流达到5 MB/s。
然后指定输入数据的模式,默认情况下从源推断,但如有必要可以覆盖。
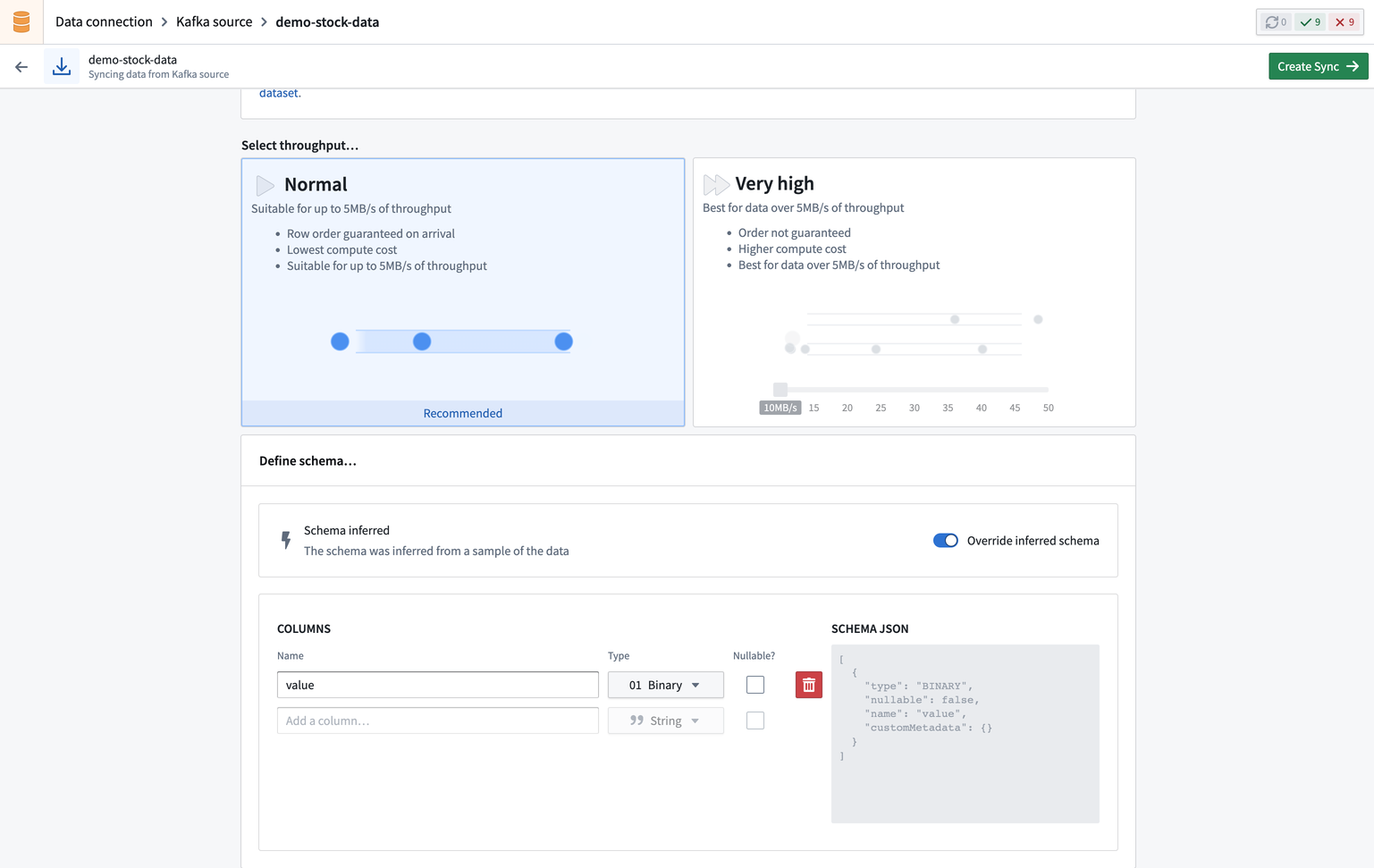
配置同步后,选择右上角的创建同步。
现在您的同步已创建,您将进入概览选项卡。
第4部分:运行同步
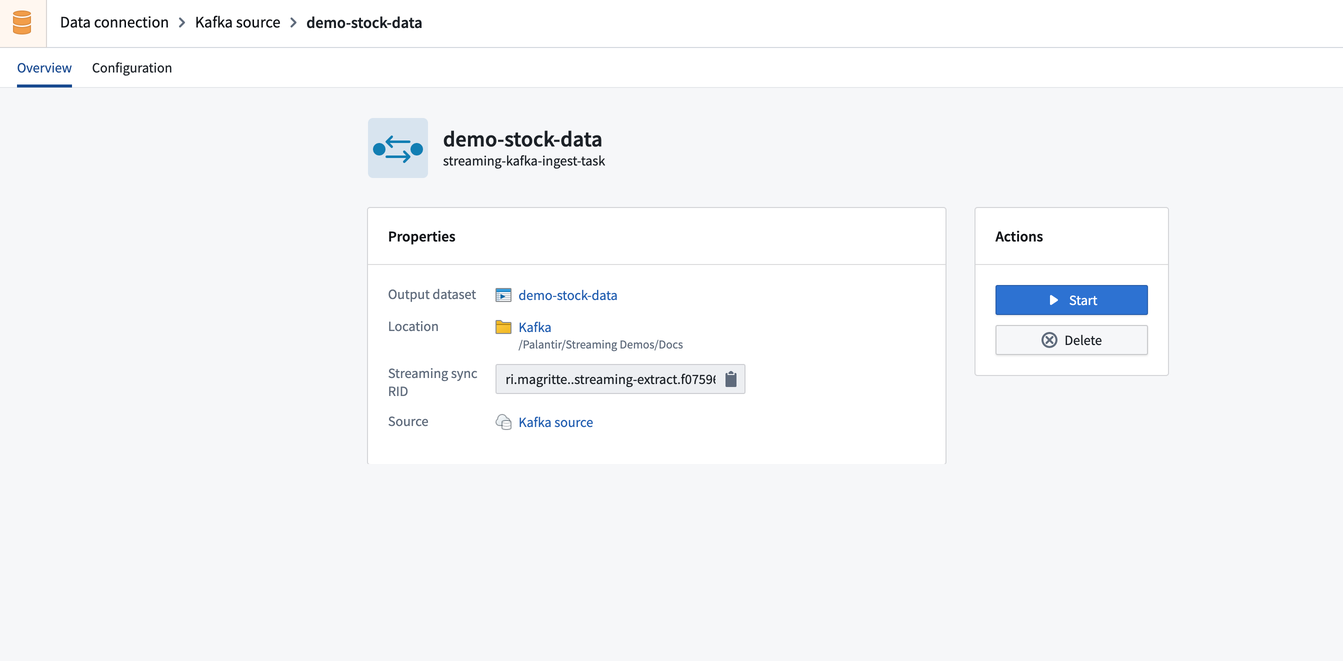
现在,您可以运行同步。选择概览选项卡以查看新同步的摘要,包括输出数据集、位置和可用操作。
点击开始以开始将外部流的数据同步到Foundry。
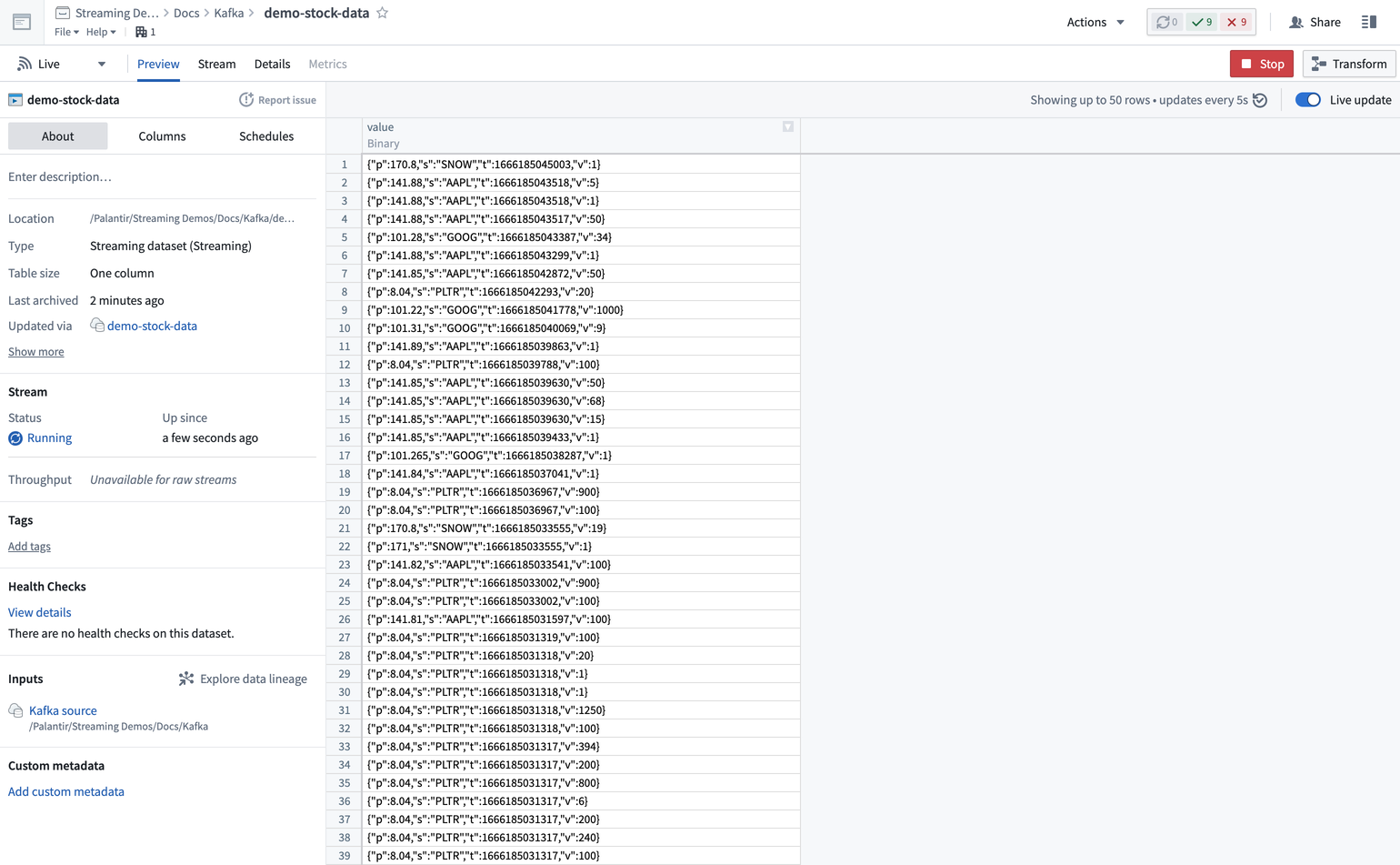
要查看流数据,请导航到您在创建同步时配置的流以查看流预览页面。您应该可以看到记录从Kafka主题流入流中。
后续步骤
现在您已成功运行同步,学习如何调试失败的流,通过基于推送的摄取将数据推入流,或将您的流集成到Ontology。