注意:以下翻译的准确性尚未经过验证。这是使用 AIP ↗ 从原始英文文本进行的机器翻译。
外部变换
外部变换允许直接引用出口策略、凭据值和出口控制权限标记。新的基于源的外部变换主要通过导入包含这些设置的数据连接源,将其作为单一资源来工作。
基于源的外部变换的主要优势包括支持以下功能:
- 连接到无法从互联网访问的系统。
- 旋转/更新凭据而无需代码更改。
- 在多个存储库之间共享连接配置。
- 针对选定源类型的开箱即用Python客户端。
- 改进和简化的治理工作流程,用于启用和管理外部变换存储库。
- 在数据沿袭中可视化连接到外部源的外部变换。
查看我们的文档以获取有关使用基于源的外部变换的更多信息。
您可以在代码存储库中使用Python变换直接在代码中连接到外部系统。例如,当您需要复杂的逻辑来与外部系统交互或想要使用第三方提供的软件开发工具包(SDK)时,这可能会很有用。我们建议使用外部变换通过REST API执行计划的同步和导出。
在继续之前,请确保创建一个Python变换代码存储库并按照以下说明进行配置。
连接到外部系统的变换只能在代码存储库中的预览助手中预览,前提是它们不使用Foundry输入。
允许代码存储库设置外部连接
本节介绍使用外部变换所需的配置。
外部变换仅可用于在SECURE模式下运行的存储库。其他安全模式仅可通过与您的Palantir代表联系获得。
启用外部系统交互
在您刚刚创建的代码存储库中,具有信息安全官角色的Foundry用户应导航到存储库设置选项卡,然后导航到存储库 > 外部系统以切换打开允许从此存储库访问外部系统的选项。
信息安全官是Foundry中的默认角色;用户可以在控制面板的注册权限下被授予信息安全官角色。

启用数据集输入
具有信息安全官角色的Foundry用户可以选择允许在外部变换中使用输入。
当数据集用作可以与外部系统通信的变换的输入时,该数据集中的任何数据都有可能离开Foundry。具有信息安全官角色的Foundry用户应为任何应允许作为此存储库中外部变换输入的数据选择一组安全权限标记和组织权限标记。
例如,您可能有一个在Palantir组织中具有敏感权限标记的数据集。要在外部变换中使用此数据集,信息安全官必须在代码存储库设置的步骤三配置Foundry输入与外部系统的使用中添加敏感权限标记和Palantir组织。
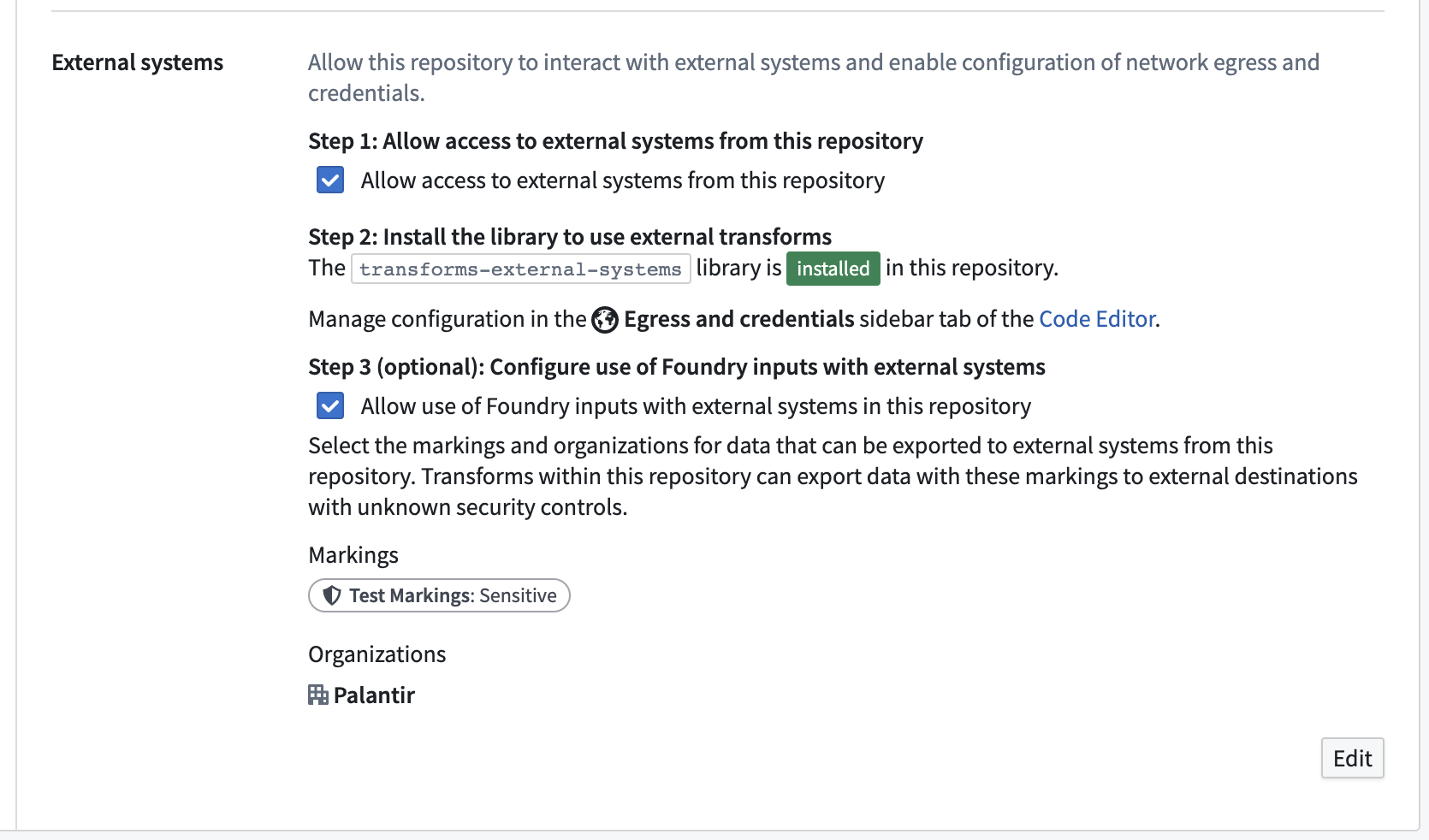
添加transforms-external-systems库
一旦为代码存储库启用了外部系统交互,您必须从代码界面左侧的库侧边栏选项卡添加transforms-external-systems库。

配置出口和凭据
添加库后,您可以访问代码界面左侧的新出口和凭据选项卡。
在此选项卡中,您可以设置代码中调用的任何端点所需的网络出口策略,并为存储库添加凭据(如果需要)。请注意,并非所有端点都需要凭据。

使用网络出口策略和凭据
添加出口策略
Foundry要求用户编写的代码发起的所有连接在访问外部目的地时都必须绑定到网络出口策略。网络出口策略允许从用户编写的代码发起的允许连接到达Foundry之外的目的地。
如果您的注册启用了自助出口,您可以在控制面板中创建和管理出口策略。如果您的连接需要添加新的网络路径,请联系您的信息安全官或Palantir代表了解您的出口策略详细信息。
如果您的Foundry实例未启用自助出口,请联系您的Palantir代表以内部启用端点并配置策略。
在使用外部变换的出口策略(无论是全局还是非全局)之前,您必须从代码存储库中的出口和凭据面板的出口选项卡中导入它们。出口选项卡公开了您有权限访问的所有策略,并将它们分类为三类:
- 已导入: 当前代码存储库中可供您的变换使用的网络出口策略。
- 可导入: 需要向网络出口策略添加项目引用。
- 需要访问请求: 您对策略有
只读权限但没有导入者权限。
在此选项卡中,搜索所需的网络出口策略。如果策略标记为可导入,请选择它并选择将出口策略导入到项目。
如果所需的网络出口策略标记为需要访问请求,具有信息安全官角色的Foundry用户应在控制面板的网络出口页面上授予您导入者角色。要授予导入者角色,信息安全官应首先选择所需的网络策略,然后选择操作 > 管理共享将您添加为策略的导入者。
添加凭据
如果您的外部系统需要授权凭据(用户名和密码)才能获得访问权限,您可以使用出口和凭据侧边栏中的凭据选项卡添加一组凭据,并在代码中使用它们。
如果源端点有白名单过程,您必须将Foundry IP地址列入白名单。请联系您的Palantir代表获取所需的IP地址。
传递证书
如果您的外部系统需要传递SSL/TLS证书,您可以将证书存储在凭据中,然后在外部变换逻辑中使用该凭据。
编写外部变换逻辑
您现在可以编写一个Python数据变换到外部系统。我们建议在编写外部变换之前查看有关如何编写Python数据变换的基本说明。
从transforms.external.systems包中导入所需的use_external_systems装饰器以及EgressPolicy和Credential(如果需要)输入。从transforms-api中导入变换装饰器和Output。如果您的外部源不需要凭据,您无需在逻辑中添加Credential输入。
您必须使用use_external_systems装饰器才能成功编写外部变换逻辑。
以下示例展示了如何使用这两个装饰器:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14from transforms.api import transform, Output from transforms.external.systems import use_external_systems, EgressPolicy, Credential # 使用外部系统装饰器,指定出口策略和凭据 @use_external_systems( egress=EgressPolicy('<policy RID>'), # 出口策略的资源标识符 creds=Credential('<credential RID>') # 凭据的资源标识符 ) @transform( output=Output('/path/to/output/dataset') # 指定输出数据集的路径 ) def compute(egress, creds, ...): # 计算逻辑的实现部分 # ...
然后,您可以设置一个简单的变换以连接到API:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23from transforms.api import transform, Output from transforms.external.systems import EgressPolicy, use_external_systems, Credential import requests @use_external_systems( egress=EgressPolicy('<policy RID>'), # 使用外部系统的出口策略 creds=Credential('<credential RID>') # 使用外部系统的凭证 ) @transform( output=Output('/path/to/output/dataset') # 指定输出数据集的路径 ) def compute(egress, output, creds): # 从凭证中获取用户名和密码 username = creds.get('username') password = creds.get('password') # 使用基本身份验证从指定的API URL获取响应 response = requests.get('https://<API URL>', auth=(username, password), timeout=10).text # 将响应内容写入文件系统中的response.json文件 with output.filesystem().open('response.json', 'w') as f: f.write(response)
您还可以在单个变换中指定多个出口策略或凭据,如下例所示。
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15from transforms.api import transform, Output from transforms.external.systems import use_external_systems, EgressPolicy, Credential @use_external_systems( egress1=EgressPolicy('<first policy RID>'), # 使用第一个出口策略的 RID egress2=EgressPolicy('<second policy RID>'), # 使用第二个出口策略的 RID creds1=Credential('<first credential RID>'), # 使用第一个凭证的 RID creds2=Credential('<second credential RID>') # 使用第二个凭证的 RID ) @transform( output=Output('/path/to/output/dataset') # 输出数据集的路径 ) def compute(egress1, egress2, creds1, creds2, ...): # 这里进行数据处理或转换的逻辑 # ...
添加 Foundry 数据集输入
在某些情况下,编写处理 Foundry 输入数据的外部变换可能会很有用。例如,您可能希望查询一个 API 以为表格数据集中的每一行收集额外的元数据。或者,您可能需要将 Foundry 数据镜像到外部软件系统中。
这种情况被视为出口控制的工作流程,因为它打开了将安全的 Foundry 数据导出到另一个安全性未知且数据来源中断的系统的可能性。变换开发人员有责任评估出口工作流程的安全性,并确保从 Foundry 离开的数据在外部系统中得到正确的保护。Foundry 提供治理控制,以确保开发人员可以清晰地编码安全意图,信息安全官员可以审核与外部系统交互的工作流程的范围和意图。
要选择加入出口控制,请在您的外部变换中应用 ExportControl。ExportControl 接受一个用于导出的安全权限标记和组织 ID 列表。如果上游数据被标记了额外的安全权限标记,变换任务将保证失败。要在代码库中扩展支持导出的权限标记集,信息安全官员必须调整代码库设置。导航到 设置 > 代码库 标签。然后,在 外部系统 部分,选择在步骤 3 中允许在此代码库中使用 Foundry 输入与外部系统。
安全权限标记和组织都作为权限标记实现,应在出口控制配置中一起列出。有关缺少权限标记的错误消息可能指的是安全权限标记或组织。
例如,您可以使用一个导出外部变换来下载 Foundry 数据集中指定的图像 URL:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30from transforms.api import transform, Input, Output from transforms.external.systems import use_external_systems, ExportControl, EgressPolicy from pyspark.sql.functions import udf import shutil import requests from pyspark.sql.functions import col @use_external_systems( export_control=ExportControl(markings=['<marking ID>']), egress=EgressPolicy(<policy RID>), ) @transform( images_output=Output('/path/to/output/dataset'), image_urls=Input('/path/to/input/dataset'), ) def compute(export_control, egress, images_output, image_urls): # 定义一个用户自定义函数(UDF)用于下载图片 @udf def download(name, url): # 从给定的URL下载图片 response = requests.get(url, stream=True) # 使用文件系统打开输出路径下的文件,模式为写二进制 with images_output.filesystem().open(f'{name}.jpg', mode='wb') as out_file: # 将请求响应的内容复制到输出文件中 shutil.copyfileobj(response.raw, out_file) return True # 将URL数据集中的每一行应用download函数,并收集结果 image_urls.dataframe().withColumn('downloaded', download(col('Name'), col('Url'))).collect()
代码解释
- 导入必要的模块:导入了必要的模块和函数,包括
transform、Input、Output等,用于数据转换和管理。 - 定义注解:使用
@use_external_systems注解定义导出控制和出口策略,确保数据导出符合安全和合规要求。 - 定义转换函数:
@transform定义了一个转换函数compute,指定了输入和输出的数据集路径。 - 用户自定义函数:在
compute函数中,定义了一个UDFdownload用于从URL下载图片并保存到指定路径。 - 数据处理:通过
withColumn方法向数据框添加一个新列,存储下载操作的结果,并使用collect()方法执行操作。
添加 Foundry 媒体集输出(测试版)
媒体集输出处于开发的测试阶段,可能无法在您的注册中使用。
在使用外部变换来摄取图像、音频或PDF等媒体文件时,您可能希望将文件写入媒体集。要将媒体项写入现有媒体集,请以编程方式将项放入指定的媒体集输出中:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28from transforms.api import transform from transforms.mediasets import MediaSetOutput from transforms.external.systems import use_external_systems import requests import tempfile # 使用装饰器标记该函数将使用外部系统 @use_external_systems() # 使用transform装饰器,指定输出媒体集的路径 @transform( media_set_output=MediaSetOutput('/path/to/output/media/set') ) def compute(media_set_output): # 向指定的API URL发送GET请求 response = requests.get('https://<API URL>') # 定义要保存的文件名 fname = 'my_image.png' # 创建一个临时文件 with tempfile.NamedTemporaryFile() as tmp: # 将响应内容写入临时文件 tmp.write(response.content) tmp.flush() # 确保数据写入到磁盘 # 以二进制方式读取临时文件 with open(tmp.name, 'rb') as tmp_read: # 将读取的内容作为媒体项存入指定的媒体集输出路径 media_set_output.put_media_item(tmp_read, path=fname)
更多方式连接到外部系统
与API服务交互
如果外部系统中存在API服务,您可以通过编程方式访问和使用这些API服务。例如,您可以使用外部变换中的Mapbox Static Images API ↗将地图图像输出到Foundry数据集中:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29from transforms.external.systems import EgressPolicy, use_external_systems, Credential from transforms.api import transform, Output from mapbox import Static @use_external_systems( egress=EgressPolicy('<policy RID>'), mapbox_creds=Credential('<credential RID>') ) @transform( output=Output('/Users/username/datasets/example_mapbox'), ) def compute(output, egress, mapbox_creds): # 从凭证中获取 Mapbox 访问令牌 mapbox_access_token = mapbox_creds.get('mapbox-token') # 创建 Mapbox 静态客户端 client = Static(access_token=mapbox_access_token) # 获取伦敦地区的卫星地图图像 london = client.image('mapbox.satellite', lat=51.5072, lon=0.0, z=12) # 将响应码写入日志文件 with output.filesystem().open('london.log', 'w') as f: f.write(f'response code: {london.status_code}') # 将图像内容写入文件 with open('london.png', 'wb') as f: f.flush() with output.filesystem().open('london.png', 'wb') as f: f.write(london.content)
这里的代码使用 Mapbox API 获取伦敦地区的卫星地图图像,并将其保存到指定输出路径。代码中使用了外部系统的凭证来获取访问令牌,并且还记录了获取地图图像的响应状态码。
与数据集文件交互
您可以通过编程方式打开、流式传输和与文件交互,就像使用常规变换一样。了解更多关于读取和写入非结构化文件。
增量处理
您可以像使用常规变换一样增量运行外部变换。
在外部增量变换中,经常需要在执行之间保持状态。对于常规增量变换,输入文件会被跟踪并与最近处理的事务进行比较。对于外部增量变换,增量状态必须以其他方式显式存储。一个选项是保存一个状态文件,该文件将保存增量变换的最新状态,如下面的示例所示:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63from transforms.api import transform, Input, Output, configure, incremental from pyspark.sql import Row from pyspark.sql import functions as F from pyspark.sql import types as T import logging import time import json log = logging.getLogger(__name__) @incremental() @configure(profile=["KUBERNETES_NO_EXECUTORS"]) @use_external_systems( egress=EgressPolicy('<policy RID>'), creds=Credential('<credential RID>') ) @transform( out=Output("<output_dataset>"), ) def compute(ctx, out, egress, creds): # 获取输出数据集的文件系统,以便读取和写入文件: out_fs = out.filesystem() state_filename = "_state.json" # 以"_"开头将其视为隐藏文件,不在数据集预览中显示。 state = {"last_seen" : 0} # 一些任意的初始状态 # 尝试从输出数据集中获取状态: try: with out_fs.open(state_filename, mode='r') as state_file: data = json.load(state_file) # 验证获取的状态: state = data logging.info(f"state file found, continuing from : {data}") except Exception as e: logging.warn("state file not found, starting over from default state") # 在此处编写逻辑以进行API调用,创建自定义处理,生成数据帧并保存,或直接将文件保存到输出数据集中。 # 例如,以下生成一个数据帧并将其保存到输出数据集中(就像我们通过API调用获取了一些数据): out.write_dataframe(get_dataframe(ctx)) # 更新状态以供下次迭代使用: state["last_seen"] = 1 + state["last_seen"] # 将新的状态保存到输出数据集中: with out_fs.open(state_filename, "w") as state_file: json.dump(state, state_file) # 此函数用于示例目的生成一个数据帧。在生产实现中,这一步不相关: def get_dataframe(ctx): # 定义数据帧的模式: schema = T.StructType([ T.StructField("name", T.StringType(), True), T.StructField("age", T.IntegerType(), True), T.StructField("city", T.StringType(), True) ]) # 创建行的列表: data = [("Alice", 25, "New York"), ("Bob", 30, "San Francisco"), ("Charlie", 35, "London")] # 创建一个PySpark数据帧: df = ctx.spark_session.createDataFrame(data, schema=schema)
在这个代码中,我们定义了一个增量转换函数compute,它通过配置KUBERNETES_NO_EXECUTORS运行,并使用外部系统进行数据处理。函数尝试从输出数据集中读取状态文件,如果不存在则使用默认状态。接下来,程序逻辑可以包含API调用、数据处理等步骤,当前示例通过get_dataframe函数创建了一个示例数据帧并保存。最后,更新并保存状态文件以备下次调用使用。