注意:以下翻译的准确性尚未经过验证。这是使用 AIP ↗ 从原始英文文本进行的机器翻译。
用于Foundry数据集的S3兼容API
用于Foundry数据集的S3兼容API允许您像与S3存储桶交互一样与Foundry数据集交互。了解通过API访问数据集时的行为,并查看设置指南和示例。
概述
Foundry公开了一部分Amazon Simple Storage Service (S3) API ↗,允许您使用能够与S3存储服务通信的客户端与Foundry数据集交互。示例包括AWS CLI、AWS SDKs、Hadoop S3文件系统和Cyberduck。
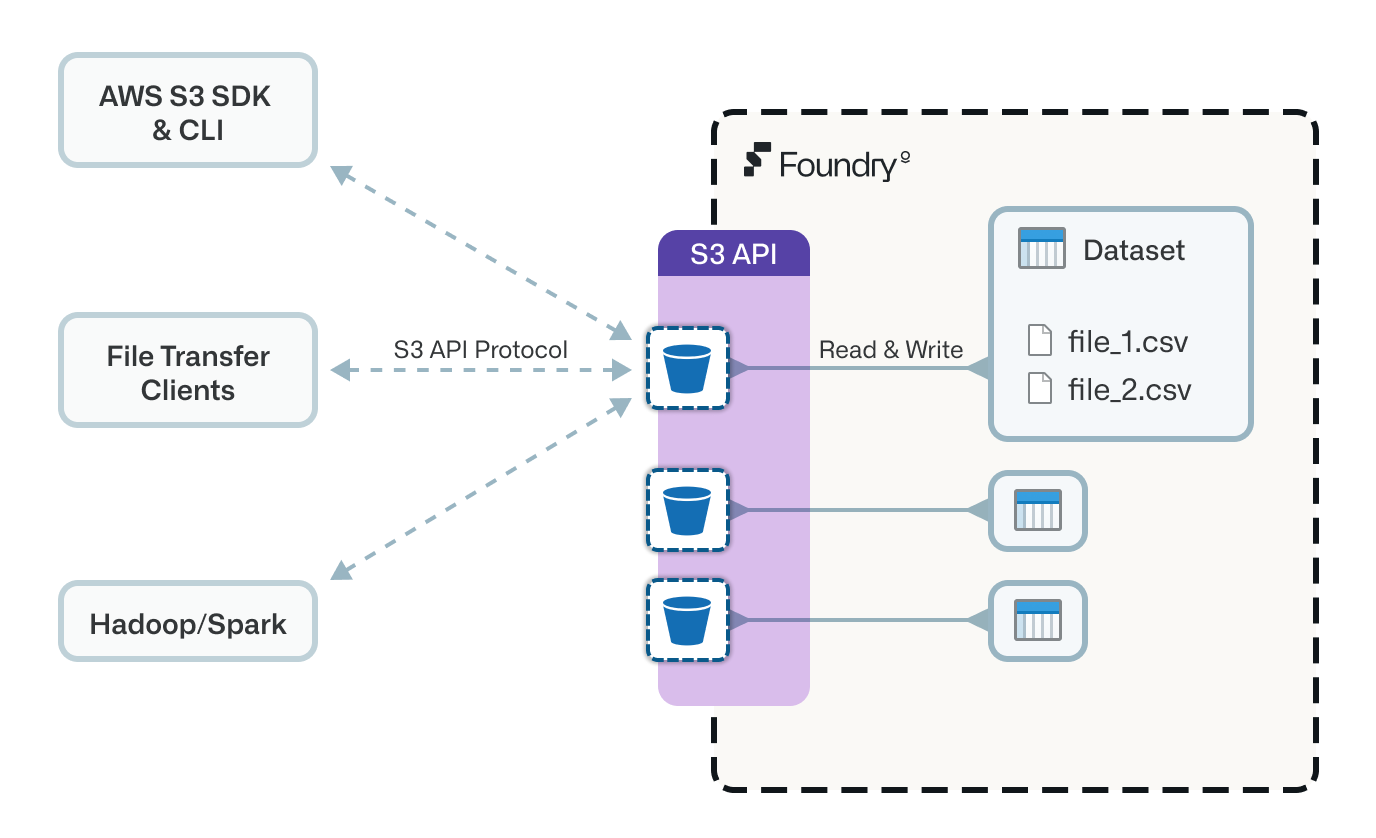
S3 API未完全实现,因为并非所有S3概念都能自然地映射到Foundry中的概念。例如,目前不支持创建和删除存储桶(代表Foundry数据集);数据集应在使用API之前在Foundry中创建。然而,支持大多数文件读/写/删除工作流,包括分段上传。查看支持的操作以了解支持的S3操作列表。
概念
本节概述了S3概念如何映射到Foundry数据集概念。
S3存储桶对应于Foundry数据集
S3存储桶对应于Foundry数据集,存储桶名称是Foundry数据集的唯一标识符(例如,ri.foundry.main.dataset.bafb7e96-84f1-4d23-a4a5-40b17c6912e7)。
S3对象键对应于Foundry数据集中文件的逻辑路径(例如,top-level-file.csv或subfolder/nested-file.csv)。
分支
API支持访问具有字母数字名称(仅包含a-z、A-Z或0-9)的数据集分支。要指定分支,通过在存储桶名称后附加分支名称并用句点分隔来修改存储桶名称:<dataset-rid>.<branch-name>。如果未指定分支,则使用默认分支。
例如,要访问RID为ri.foundry.main.dataset.bafb7e96-84f1-4d23-a4a5-40b17c6912e7的数据集的mybranch分支,请使用存储桶名称ri.foundry.main.dataset.bafb7e96-84f1-4d23-a4a5-40b17c6912e7.mybranch。
API不支持分支创建;指定的分支必须已存在于数据集中。
事务
API支持以类似于分支的方式访问数据集事务。这允许用户访问数据集的历史版本。例如,要访问RID为ri.foundry.main.dataset.bafb7e96-84f1-4d23-a4a5-40b17c6912e7的数据集的ri.foundry.main.transaction.0cdfe8c9-f595-4859-a194-7daecff9d6fe事务,请使用存储桶名称ri.foundry.main.dataset.bafb7e96-84f1-4d23-a4a5-40b17c6912e7.ri.foundry.main.transaction.0cdfe8c9-f595-4859-a194-7daecff9d6fe。
只能以这种方式访问已提交的事务。因此,存储桶将是只读的;使用包含事务标识符的存储桶名称时,无法放置或删除对象。
事务管理
S3没有事务的概念,所以Foundry数据集事务会自动处理,具有以下行为:
- 当用户写入或删除文件时,事务会延迟打开。
- API支持并发写入多个文件_或_并发删除多个文件。文件将在同一个开放事务中修改,写入使用
UPDATE事务,删除使用DELETE事务。 - API不支持并发写入_和_删除,因为这需要同时激活
UPDATE和DELETE事务。 - 在写入或删除后的短时间内不活动后,事务会自动提交。这允许您在同一事务中上传多个文件,避免出现含有很少文件的多个事务。为了避免事务无限期保持打开状态,例如如果文件持续上传以至于没有不活动期,一旦没有活动的上传,事务将在一定时间后提交。如果文件并行连续上传,则事务将在所有上传完成后保持打开状态。
- 如果在事务打开期间的不活动期内收到读取请求,
UPDATE和DELETE事务将在可能的情况下立即提交。这旨在保留S3通常预期的写后读语义。但是,如果在开放事务中仍有活动写请求时尝试读取,则读取将从最新提交的视图进行。为了确保在所有写入或删除完成后事务提交,您可以在任何新的写入或删除请求之前发出后续读取请求。
鉴于上述行为,不保证写后读语义。然而,尽一切努力在可能的情况下提供它们。
身份验证
通过API的连接使用访问密钥ID和秘密访问密钥凭证进行身份验证。
静态凭证
静态凭证类似于标准AWS访问密钥ID和秘密访问密钥凭证。静态凭证是长期有效的,在Foundry情况下,与在Foundry控制面板中注册的第三方应用程序的服务用户相关联。
当使用静态访问密钥ID和秘密访问密钥通过S3兼容API连接到数据集时,访问级别由授予第三方应用程序的服务用户的访问权限确定。静态凭证还必须至少限制到一个项目。生成新凭证集时指定项目限制。
有关使用/io/s3/api/v2/credentialsAPI端点生成这些凭证的指南,请参阅下面的设置指南。
临时凭证
我们建议在任何需要长期凭证或将访问权限绑定到服务用户的工作流程中使用静态凭证。如果您更喜欢以常规Foundry用户身份验证API,我们支持交换用户身份验证词元以获取临时S3凭证。此词元也可以通过OAuth2授权之一获取,适用于第三方应用程序。
使用标准的AssumeRoleWithWebIdentity ↗安全词元服务(STS)API获取临时凭证。我们只需要WebIdentityToken请求参数存在并配置为上述常规Foundry词元。返回的临时凭证将具有与提供的词元相同的范围。可以提供DurationSeconds参数来指定凭证的生命周期。凭证的最长有效期为一小时,并且永远不会超过用于获取临时凭证的Foundry词元的生命周期。
STS API可以通过https://<FOUNDRY_URL>/io/s3访问。如果您希望以编程方式获取STS凭证,则应在标准STS客户端或凭证提供程序的端点配置中配置此URL。例如:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14import boto3 endpoint = "https://<FOUNDRY_URL>/io/s3" session = boto3.session.Session() client = session.client(service_name='sts', endpoint_url=endpoint) # RoleArn 和 RoleSessionName 是 boto3 中必需的参数,即使未被使用 # assume_role_with_web_identity 方法用于通过 Web 身份验证获取临时的 AWS 凭证 credentials = client.assume_role_with_web_identity( RoleArn="xxxxxxxxxxxxxxxxxxxx", RoleSessionName="xxxxx", WebIdentityToken=token # Web 身份验证令牌 )["Credentials"]
或者,您可以使用cURL或等效工具直接访问API,如下面的示例所示。<TOKEN>应替换为有效的Foundry词元。
Copied!1 2curl -X POST \ https://<FOUNDRY_URL>/io/s3?Action=AssumeRoleWithWebIdentity&WebIdentityToken=<TOKEN>
您将在 XML 响应中收到会话凭证,如下所示。这些凭证应被安全存储。
Copied!1 2 3 4 5 6 7 8 9 10 11 12<?xml version='1.0' encoding='UTF-8'?> <AssumeRoleWithWebIdentityResponse xmlns="https://sts.amazonaws.com/doc/2011-06-15/"> <AssumeRoleWithWebIdentityResult> <Credentials> <AccessKeyId>PLTRLZZJE0...</AccessKeyId> <!-- 访问密钥 ID --> <SecretAccessKey>2j3hKX4EDP...</SecretAccessKey> <!-- 秘密访问密钥 --> <SessionToken>eyJwbG50ci...</SessionToken> <!-- 会话令牌 --> <Expiration>2023-08-30T10:55:08.841403951Z</Expiration> <!-- 凭证过期时间 --> </Credentials> </AssumeRoleWithWebIdentityResult> </AssumeRoleWithWebIdentityResponse>
此 XML 文件示例用于从 AWS 安全令牌服务(STS)中获取临时安全凭证。这些凭证包括访问密钥 ID、秘密访问密钥和会话令牌,它们通常用于在一定时间内访问 AWS 资源。Expiration 元素显示凭证的到期时间。
一旦您拥有临时凭证,请导航到下面设置指南的第四步,以获取配置S3客户端的指导。您无需遵循任何有关第三方应用程序的步骤。在配置S3客户端时,您必须提供会话词元、访问密钥ID和秘密访问密钥。
通过S3兼容API读取或写入数据,用户需要s3-proxy:datasets-read和s3-proxy:datasets-write权限,这些权限默认分别授予Viewer和Editor角色。当使用静态凭证时,对应第三方应用的服务用户需要被授予相关角色。当使用临时凭证时,获取凭证的用户需要相关角色。
路径风格URL访问
API仅支持路径风格 ↗桶访问。您的桶URL将采用格式https://<FOUNDRY_URL>/io/s3/<bucket-name>/<key-name>。
在Foundry术语中,这意味着https://<FOUNDRY_URL>/io/s3/<dataset-rid>/<logical-filepath>。
当前不支持虚拟主机风格的桶访问(其中桶名包含在URL的子域中)。
预签名URL
预签名URL支持putObject操作。
设置指南
按照以下步骤设置从您的S3客户端到API的连接。
步骤1:在Foundry中注册第三方应用程序
要获取S3兼容API的凭证,您首先需要获取在Foundry的控制面板中创建的第三方应用程序的客户端ID和秘密:
- 在Foundry中打开控制面板。
- 在侧边栏中选择第三方应用程序。
- 选择新建应用程序,然后使用以下参数完成设置向导:
- 客户端类型:选择机密客户端。
- 授权许可类型:启用客户端凭证许可。
- 在摘要页面的右下角选择注册应用程序。
- 在完成屏幕上,记录下客户端ID,因为这将在后续步骤中需要。然后选择启用应用程序使用并使用切换开关启用它。
查看概念:认证以了解项目限制的要求和行为,以及生成凭证的范围。
步骤2:授予第三方应用程序的服务用户权限
当您在上一步中创建第三方应用程序时,Foundry会自动创建一个服务用户。要通过S3 API访问数据集,此服务用户必须在相关项目和权限标记上具有足够的权限。
为服务用户设置权限:
- 找到服务用户的名称和ID。您可以在应用程序的“管理应用程序”页面上,在授权许可类型 > 客户端凭证许可 > 服务用户下找到这些详细信息。
- 授予服务用户权限,可以直接将用户添加到项目和权限标记中,或将用户添加到已被授予这些权限的组中。
步骤3:生成S3访问密钥ID和秘密访问密钥
要生成凭证,您需要在控制面板上具有“用户体验管理员”角色。
运行下面的终端命令(使用curl或Powershell),以接收访问密钥ID和秘密访问密钥。用您用户帐户的有效词元替换<TOKEN>,用在上一步中生成的第三方应用程序的客户端ID替换<CLIENT_ID>。此外,您必须用凭证有访问权限的项目的RID替换<PROJECT_RID>。projectRestrictions值可以包含多个项目,如果需要,可以列出更多的项目RID。
选项1:curl
Copied!1 2 3 4 5curl -X POST \ -H "Authorization: Bearer <TOKEN>" \ # 使用Bearer令牌进行身份验证 -H "Content-type: application/json" \ # 设置内容类型为JSON格式 --data '{"clientId":"<CLIENT_ID>","projectRestrictions":["<PROJECT_RID>"]}' \ # 提交请求数据,包括客户端ID和项目限制 https://<FOUNDRY_URL>/io/s3/api/v2/credentials # 请求的URL,用于获取S3 API v2的凭证
选项 2:Powershell (Windows)
Copied!1 2 3 4 5 6 7 8 9 10 11 12$headers = @{ "Authorization" = "Bearer <TOKEN>" # 使用Bearer令牌进行授权 "Content-type" = "application/json" # 设置内容类型为JSON } $body = @{ "clientId" = "<CLIENT_ID>" # 客户端ID "projectRestrictions" = @("<PROJECT_RID>") # 项目限制,使用项目ID } | ConvertTo-Json # 将PowerShell对象转换为JSON格式 # 发送POST请求以获取凭证 Invoke-WebRequest -Uri "https://<FOUNDRY_URL>/io/s3/api/v2/credentials" -Method POST -Headers $headers -Body $body
安全地存储在此请求响应中收到的访问密钥和秘密密钥。您必须使用这些凭证配置客户端,而不是第三方应用程序的客户端ID和秘密。
指定组织
默认情况下,/v2/credentials 端点假设正在进行身份验证的用户正在为其自身组织中的第三方应用程序生成凭证。如果第三方应用程序存在于不同的组织中,请在URL中将组织ID指定为查询参数:https://<FOUNDRY_URL>/io/s3/api/v2/credentials?organizationRid=<ORGANIZATION_ID>。
撤销凭证
如果您需要撤销访问密钥和秘密访问密钥,请调用以下端点并将 <ACCESS_KEY_ID> 替换为您希望撤销的访问密钥ID:
Copied!1 2 3curl -X DELETE \ -H "Authorization: Bearer <TOKEN>" \ https://<FOUNDRY_URL>/io/s3/api/v2/credentials/<ACCESS_KEY_ID>
此命令使用 curl 发送一个 HTTP DELETE 请求,主要用于删除特定的访问凭证。以下是具体说明:
-X DELETE:指定 HTTP 方法为 DELETE,用于删除资源。-H "Authorization: Bearer <TOKEN>":添加 HTTP 头部,使用 Bearer 令牌进行身份验证,确保请求的安全性。https://<FOUNDRY_URL>/io/s3/api/v2/credentials/<ACCESS_KEY_ID>:请求的 URL,其中<FOUNDRY_URL>是服务的基础 URL,<ACCESS_KEY_ID>是要删除的访问凭证的唯一标识符。
步骤4:配置S3客户端
要配置S3客户端,您必须设置以下配置参数。有关如何在常见S3客户端中配置这些参数的详细信息,请参阅下方的示例。
| 名称 | 值 | 描述 |
|---|---|---|
| 主机名 / 终端节点 | https://<FOUNDRY_URL>/io/s3 | 客户端应连接的主机名(而不是AWS中托管的原生S3桶的s3.amazonaws.com)。 |
| 区域 | foundry | 区域必须设置为foundry,因为它是V4签名验证 ↗过程的一部分。如果客户端只能使用标准AWS区域,则使用us-east-1。 |
| 凭证 | 访问密钥ID和密钥,以及非必填的会话词元 | 如上所述生成的静态或临时凭证。 |
| 路径样式访问 | true | 该API仅支持路径样式 ↗桶访问,而不是虚拟主机样式桶访问。 |
| 桶名称(非必填) | ri.foundry.main.dataset.<uuid> | 每个Foundry数据集都可以作为一个单独的S3桶访问,桶名称为数据集的RID。 |
支持的操作
支持以下S3操作 ↗:
- AbortMultipartUpload ↗
- CompleteMultipartUpload ↗
- CopyObject ↗
- CreateMultipartUpload ↗
- DeleteObject ↗
- DeleteObjects ↗
- GetObject ↗
- HeadBucket ↗
- HeadObject ↗
- ListMultipartUploads ↗
- ListObjects ↗
- ListObjectsV2 ↗
- ListParts ↗
- PutObject ↗
- UploadPart ↗
客户端设置示例
如上所述,您必须确保客户端/SDK/连接器配置为使用路径样式桶访问。如果客户端不支持路径样式桶访问,目前与此API不兼容。例如,在S3A Hadoop客户端 ↗中,可以使用fs.s3a.path.style.access标志进行配置。
如果您使用临时凭证,请务必同时配置AWS会话访问词元。请参阅相关的AWS客户端文档了解详情。例如,对于AWS CLI ↗,您应该设置AWS_SESSION_TOKEN环境变量。
AWS CLI
一旦您有了访问密钥ID和密钥,就可以配置AWS CLI ↗。运行以下命令,输入访问密钥ID、密钥和区域。
Copied!1 2 3 4 5 6 7 8 9 10 11# 配置AWS命令行界面(CLI)的示例,使用名为"foundry"的配置文件。 $ aws configure --profile foundry # 输入AWS访问密钥ID AWS Access Key ID [None]: <ACCESS_KEY_ID> # 输入AWS秘密访问密钥 AWS Secret Access Key [None]: <SECRET_ACCESS_KEY> # 设置默认区域名称,这里填写为"foundry" Default region name [None]: foundry # 设置默认输出格式,这里为空,表示使用默认值 Default output format [None]:
这段代码用于配置AWS CLI工具的凭证和默认设置,以便通过"foundry"配置文件与AWS服务进行交互。
您现在应该能够为foundry配置文件运行命令。例如:
Copied!1aws --profile foundry --endpoint-url https://<FOUNDRY_URL>/io/s3 s3 ls s3://<DATASET_RID>
这个命令使用 AWS CLI 列出指定数据集 RID 的 S3 存储桶内容。 以下是命令中各个部分的说明:
aws --profile foundry: 使用名为foundry的 AWS 配置文件。--endpoint-url https://<FOUNDRY_URL>/io/s3: 指定 S3 服务的自定义端点 URL。s3 ls s3://<DATASET_RID>: 列出 S3 存储桶中指定数据集 RID 下的对象。 根据 最近发布的版本 ↗ 的AWS CLI,现在可以将endpoint-url配置为profile配置的一部分。如下所示,在~/.aws/config中配置的一个foundry配置文件示例。当配置具有endpoint_url属性的配置文件时,使用aws命令时不再需要包含--endpoint-url参数。只需要--profile即可。
Copied!1 2 3[profile foundry] region = foundry # 指定区域名称为foundry endpoint_url = https://<FOUNDRY_URL>/io/s3 # 指定S3服务的端点URL
要在 AWS CLI 中使用 临时凭证,请参阅 AWS 文档 ↗,该文档解释了如何配置 CLI 以为您进行 AWS STS AssumeRoleWithWebIdentity 调用。下面展示了一个在 ~/.aws/config 中配置的 foundry 配置文件示例。使用此配置时,您无需在环境变量(AWS_ACCESS_KEY_ID、AWS_SECRET_ACCESS_KEY、AWS_SESSION_TOKEN)或 ~/.aws/credentials 中配置凭证。
Copied!1 2 3 4 5[profile foundry] region = foundry # 区域设置为 foundry endpoint_url = https://<FOUNDRY_URL>/io/s3 # 端点 URL,替换 <FOUNDRY_URL> 为实际的 URL web_identity_token_file = ~/.foundry/web-identity.token # Web 身份令牌文件路径 role_arn=xxxxxxxxxxxxxxxxxxxx # 角色 ARN,替换为实际的 ARN
上述示例假定在 ~/.foundry/web-identity.token 文件中存储了一个有效的 Foundry 词元。只有在确保该文件安全且没有泄漏风险的情况下,我们才推荐这种方法。role_arn 属性虽然不被用于在,但仍必须提供,并且由于 AWS CLI 的验证要求,长度至少为20个字符。我们在示例中使用 xxxxxxxxxxxxxxxxxxxx 作为占位符。要使用此配置,您必须在 ~/.aws/config 中配置 endpoint_url,而不是使用 --endpoint-url,如上所述。
AWS SDK 以 Python (Boto3)
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22import boto3 import pandas as pd # 创建一个S3客户端 s3 = boto3.client( 's3', aws_access_key_id="<ACCESS_KEY_ID>", # 替换为您的AWS访问密钥ID aws_secret_access_key="<SECRET_ACCESS_KEY>", # 替换为您的AWS秘密访问密钥 # session_token="<SESSION_TOKEN>", 仅当使用临时凭证时需要 endpoint_url="https://<FOUNDRY_URL>/io/s3", # 设置Foundry的S3端点URL region_name="foundry" # 指定区域名称为Foundry ) bucket = 'ri.foundry.main.dataset.<uuid>' # 指定S3桶名称 key = 'iris.csv' # 指定文件的S3键 # 从S3获取对象 obj = s3.get_object(Bucket=bucket, Key=key) # 使用pandas读取CSV文件 df = pd.read_csv(obj['Body']) # 打印数据帧内容 print(df)
查看 Boto3 文档的 S3 部分 ↗,以获取有关使用 Boto3 连接到 S3 兼容源的更多信息。
Spark
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23from pyspark.sql import SparkSession hostname = "https://<FOUNDRY_URL>/io/s3" access_key_id = "<ACCESS_KEY_ID>" secret_access_key = "<SECRET_ACCESS_KEY>" # 确保数据集的RID可以被解析为一个有效的主机名 dataset_rid = "ri.foundry.main.dataset.<uuid>".replace('.', '-') spark_session = ( SparkSession.builder .config("fs.s3a.access.key", access_key_id) # 配置S3访问密钥ID .config("fs.s3a.secret.key", secret_access_key) # 配置S3密钥 # .config("fs.s3a.session.token", session_token) 仅在使用临时凭证时需要 .config("fs.s3a.endpoint", hostname) # 配置S3终端点URL .config("fs.s3a.endpoint.region", "foundry") # 配置S3终端点区域 .config("fs.s3a.path.style.access", "true") # 配置S3路径风格访问 .getOrCreate() ) # 读取Parquet格式的数据集 df = spark_session.read.parquet(f"s3a://{dataset_rid}/*") df.show() # 显示数据集的内容
查看 Spark 文档 ↗ 以获取更多关于将 Spark 与 S3 结合使用的信息。
使用带有包含'.'的桶名称的 Hadoop AWS 客户端存在已知问题。您可能会遇到类似 "bucket is null/empty" 的错误消息。如果出现这种情况,数据集 RID 无法解析为有效的主机名。作为一种变通方法,您可以将数据集 RID 中的 '.' 替换为 '-'。
Cyberduck
-
下载以下配置文件:Foundry S3.cyberduckprofile ↗
-
双击配置文件以在 Cyberduck 中打开并注册该配置文件。
-
在 Cyberduck 为您创建的默认书签上设置以下连接属性:
- Server:
https://<FOUNDRY_URL> - Access Key ID:
<ACCESS_KEY_ID> - Secret Access Key:
<SECRET_ACCESS_KEY> - Path: (在 More Options 下)
ri.foundry.main.dataset.<uuid>
- Server:
-
关闭书签设置窗口。
-
双击书签以打开连接。
查看 Cyberduck 文档 ↗ 以获取更多关于连接到 S3 兼容源的信息。
Google 存储传输服务
Google Cloud 的 存储传输服务 ↗ 可以将 Foundry 视为 S3 兼容源 ↗。您可以通过以下步骤将数据从 Foundry 数据集传输到 Cloud Storage 桶中。
-
按照 Google Cloud 的说明 ↗ 设置代理池和传输代理。
-
创建一个传输任务,并选择 S3-compatible object storage 作为 Source type。然后选择您在步骤 (1) 中创建的代理池,并确保设置以下配置:
- Bucket:
ri.foundry.main.dataset.<uuid>。 - Endpoint:
https://<FOUNDRY_URL>/io/s3 - Signing region:
foundry - Signing process: Signature Version 4 (SigV4)
- Addressing-style: Path-style requests
- Network protocol:
HTTPS - Listing API version:
ListObjectsV2完成设置以配置 Cloud Storage 桶的目标、计划和传输任务的设置。
- Bucket:
Apache NiFi
您可以使用 Apache NiFi 在 Foundry 数据集中读取和写入文件。以下示例展示如何配置 PutS3Object 处理器类型以进行写入:
- Object Key: 数据集中的逻辑文件路径,格式为
path/to/file.csv - Bucket: 数据集 RID,例如
ri.foundry.main.dataset.<uuid> - Access Key ID:
<ACCESS_KEY_ID> - Secret Access Key:
<SECRET_ACCESS_KEY> - Region: "US East (N. Virginia)" 对应
us-east-1 - Use Path Style Access:
true - Endpoint Override URL:
https://<FOUNDRY_URL>/io/s3
请参考 Apache NiFi 文档 ↗ 以获取更多关于 PutS3Object 处理器和其他支持 S3 兼容源的处理器的信息。
Airbyte
Airbyte ↗ 对 S3 目标的支持可用于将文件写入 Foundry 数据集。设置以下目标设置:
- Destination type: S3
- S3 Key ID:
<ACCESS_KEY_ID> - S3 Access Key:
<SECRET_ACCESS_KEY> - S3 Bucket Name:
ri.foundry.main.dataset.<uuid> - S3 Bucket Path: 任意有效的子目录路径。Airbyte 将文件写入 Foundry 数据集内的该子目录中。
- S3 Bucket Region:
us-east-1 - Output Format: 所有 Airbyte 的输出格式都与 Foundry 数据集兼容。
- Endpoint:
https://<FOUNDRY_URL>/io/s3
请参考 Airbyte 的文档 S3 目标 ↗ 以获取更多信息和配置选项。
DuckDB
DuckDB ↗ 对 S3 的支持可用于查询 Foundry 数据集。您可以使用 DuckDB 的密钥管理凭证,并使用 s3:// 前缀的 URL 查询数据集。
Copied!1 2 3 4 5 6 7 8 9 10 11CREATE SECRET foundry_secret ( TYPE S3, -- 指定类型为 S3 KEY_ID '<ACCESS_KEY_ID>', -- 访问密钥 ID SECRET '<SECRET_ACCESS_KEY>', -- 访问密钥 REGION 'foundry', -- 区域设置为 foundry ENDPOINT '<FOUNDRY_URL>/io/s3', -- S3 服务的终端 URL URL_STYLE 'path' -- URL 风格为路径 ); CREATE TABLE new_tbl AS SELECT * FROM 's3://ri.foundry.main.dataset.<uuid>/spark/*.parquet'; -- 从指定的 S3 路径中选择所有 parquet 文件并创建新表 new_tbl
请参考DuckDB 文档 ↗了解更多信息。
在上述密钥配置中,ENDPOINT 配置参数不应包含 https:// 方案。URL 方案由 USE_SSL 参数自动处理,默认为 true。
Polars
Polars ↗ 对 S3 的支持可以被用于在查询 Foundry 数据集。
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21import polars as pl # 配置 Foundry 的 S3 存储 URL hostname = "https://<FOUNDRY_URL>/io/s3" # 配置 AWS 访问密钥 ID access_key_id = "<ACCESS_KEY_ID>" # 配置 AWS 秘密访问密钥 secret_access_key = "<SECRET_ACCESS_KEY>" # 配置数据集的 RID(资源标识符) dataset_rid = "ri.foundry.main.dataset.<uuid>" # 配置存储选项 storage_options = { "aws_access_key_id": access_key_id, "aws_secret_access_key": secret_access_key, "aws_region": "foundry", "endpoint_url": hostname } # 使用 polars 库扫描 Parquet 文件,并加载为 DataFrame df = pl.scan_parquet(f"s3://{dataset_rid}/spark/*.parquet", storage_options=storage_options)
有关更多信息,请参阅 Polars 文档 ↗。