注意:以下翻译的准确性尚未经过验证。这是使用 AIP ↗ 从原始英文文本进行的机器翻译。
SQL预览
使用SQL预览功能可以对结构化数据集进行快速分析。SQL预览包含一个SQL“便笺”,您可以在其中运行只读SQL查询,包括以下功能:
- 数据集模式/列名的自动补全
- 以反引号“
”搜索其他数据集以执行高效的JOIN`查询 - 使用编辑器友好的功能,如键盘快捷键来运行高亮查询
- 输出执行SQL查询结果的预览表
- 调整列和底部面板的大小以适应您的偏好
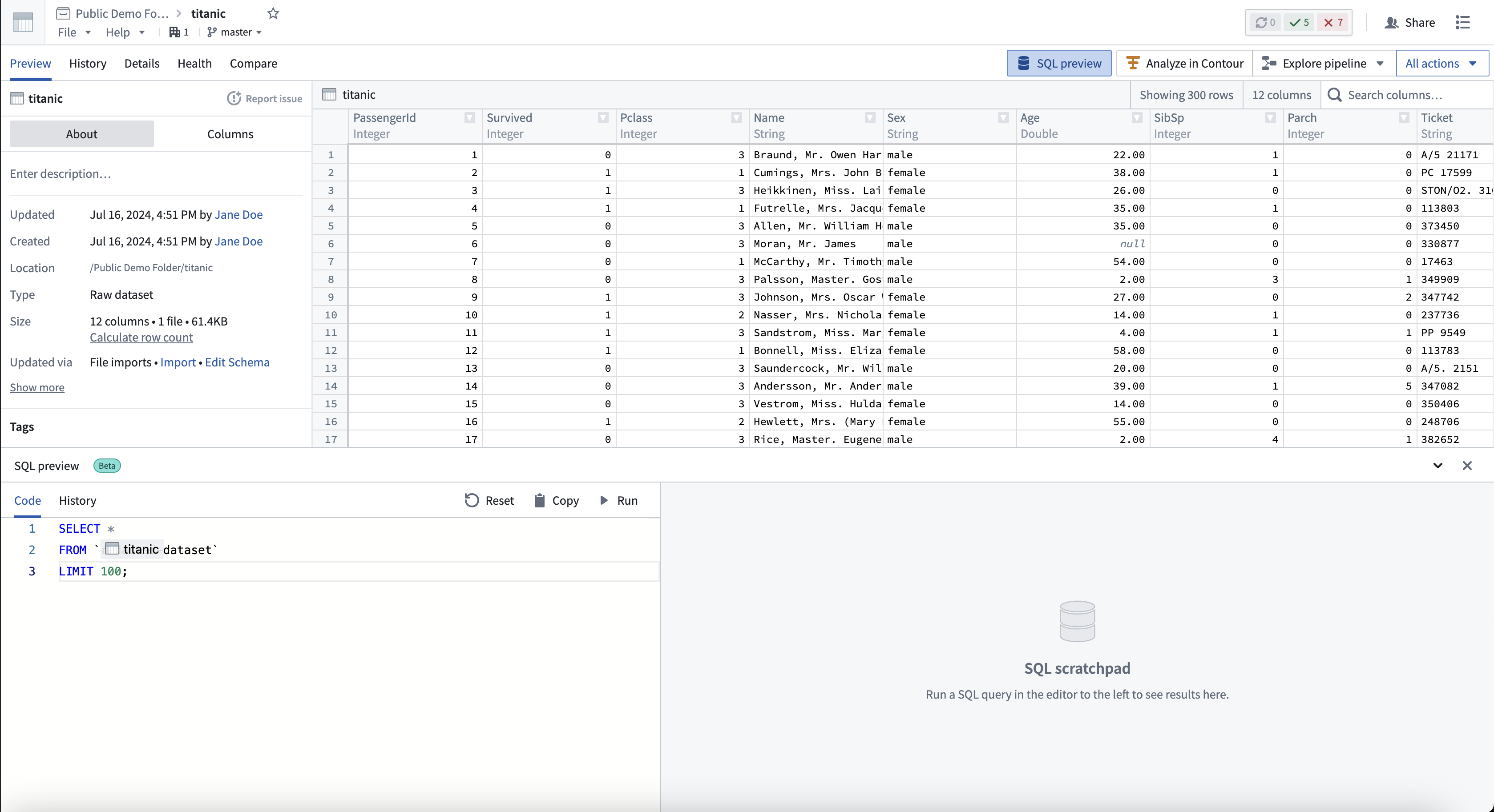
分析您的SQL数据
按照以下步骤使用SQL预览功能。
- 导航到任何表格数据集。
- 从屏幕左下角选择SQL预览以打开可调节的预览面板。
- 在代码选项卡中,对数据集编写任何只读查询(包括合并)。
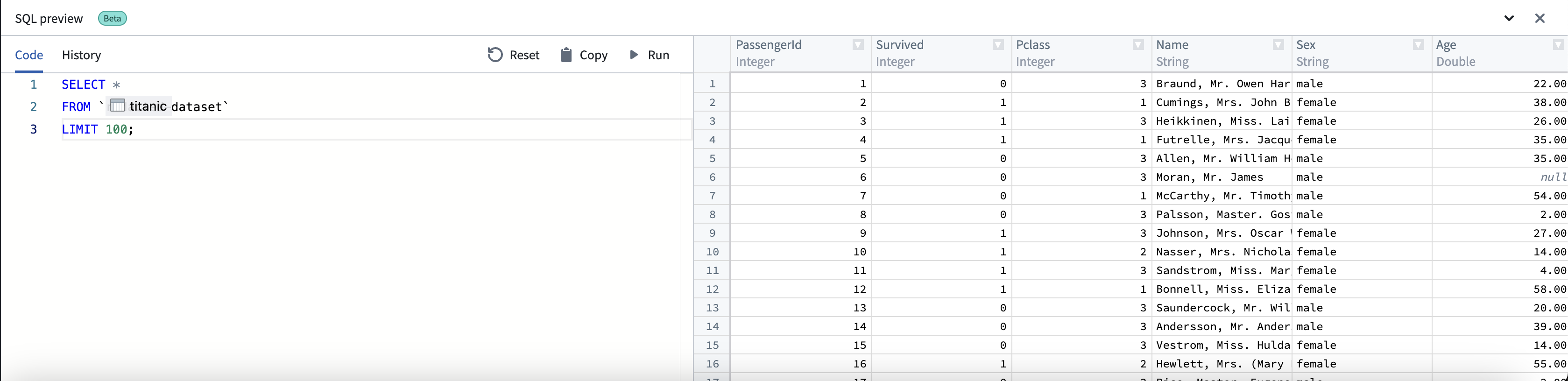
-
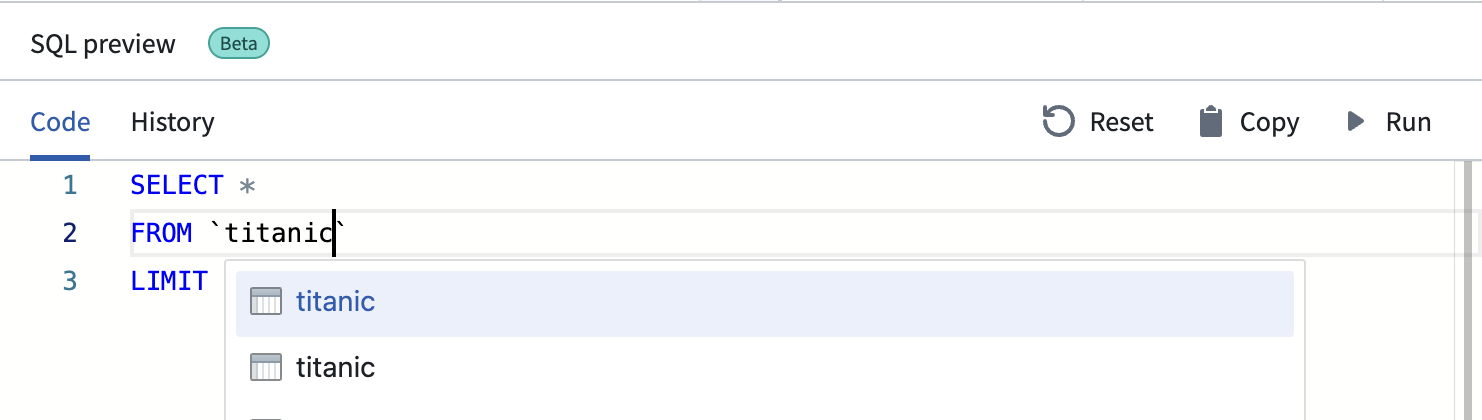
您可以通过在反引号“`”中输入数据集名称来搜索合并的数据集。将出现一个符合该名称的数据集下拉列表。
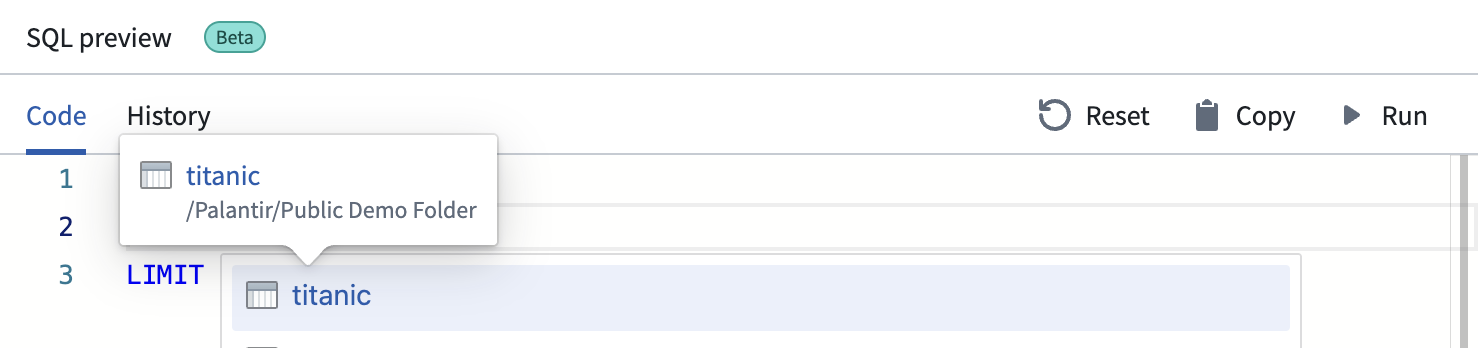
-
将鼠标悬停在下拉列表中的任何数据集上会显示完整的资源名称和文件路径。
- 使用编辑器上方的运行按钮或
Cmd + Enter(macOS)或Ctrl + Enter(Windows)键命令运行每个查询。一次只允许运行一个查询。如果您有多个查询,请高亮一个查询以运行。
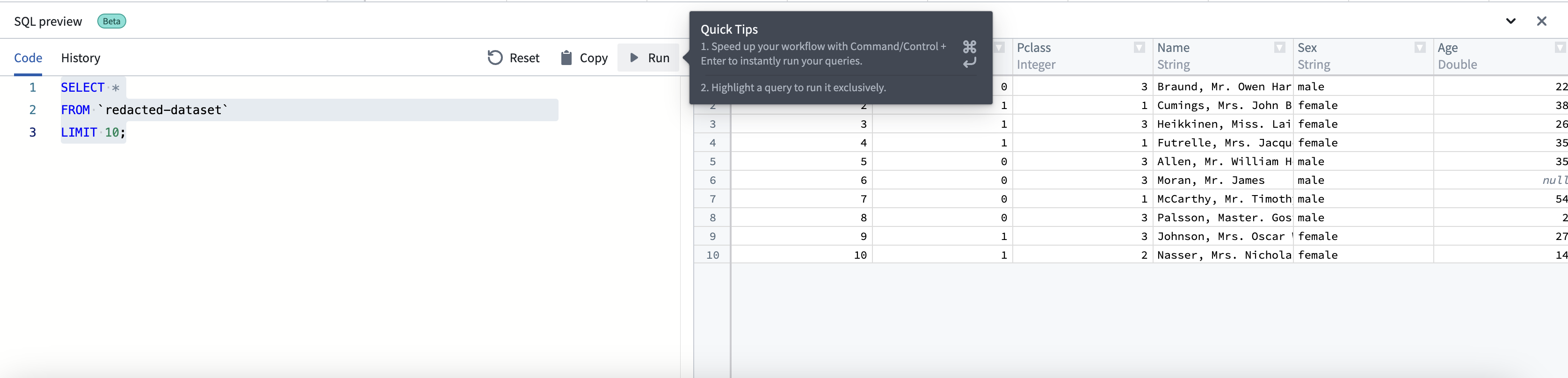
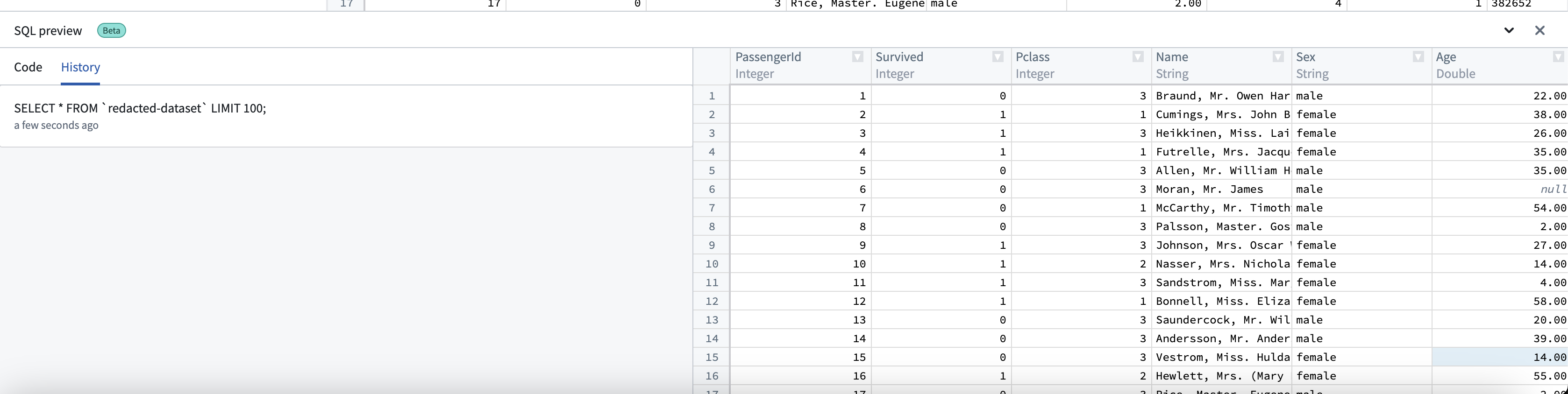
- 所有运行的查询将自动保存在历史记录选项卡中。
兼容性
SQL引擎支持Spark SQL方言。在Spark SQL中,诸如表名之类的标识符应该使用反引号(`)而不是单引号或双引号来引用。
例如:
Copied!1 2SELECT column_name FROM `table_name`; -- 从`table_name`中选择column_name列的数据
有关Spark SQL方言及其语法的更多信息,请参阅官方Spark SQL文档 ↗。
查询执行细节和限制
- 每个查询在整个数据集上运行,并使用与Contour相同的计算后端。
- 每个查询将返回最多1,000行的样本。