注意:以下翻译的准确性尚未经过验证。这是使用 AIP ↗ 从原始英文文本进行的机器翻译。
分块
本页概述如何在语义搜索工作流中整合基本的分块策略。在此上下文中,分块是指将较大的文本块拆分为较小的文本块。这是有利的,因为嵌入模型对文本具有最大输入长度,且较小的文本块在搜索过程中将更具语义区分性。分块通常用于解析大型文档,如PDF。
主要目标是将长文本拆分为较小的“块”,每个块都与原始对象关联的Ontology对象相关联。
分块示例
作为起始点,我们将展示如何在不使用代码的情况下在Pipeline Builder中实现基本的分块策略。对于更高级的策略,我们建议将代码仓库作为管道的一部分。
为了说明,我们将使用一个简单的两行数据集,包含两列,object_id和object_text。为了便于理解,下面的object_text示例故意简短。
| object_id | object_text |
|---|---|
| abc | gold ring lost |
| xyz | fast cars zoom |
我们首先使用Chunk String面板,该面板引入一个额外的列,其中包含将object_text分段为较小部分的数组。面板支持多种分块方法,如重叠和分隔符,以确保每个语义概念保持连贯和独特。
下面的Chunk String面板截图显示了一个简单的策略,您可以根据自己的应用案例进行修改。以下配置将尝试返回大小约为256字符的块。有效地,面板根据最高优先级分隔符拆分文本,直到每个块等于或小于块大小。如果没有更多最高优先级分隔符可以拆分且某些块仍然过大,则移动到下一个分隔符,直到所有块等于或小于块大小或没有更多分隔符可用。最后,面板将确保每个识别出的块,其后面的块具有覆盖前一个块最后20个字符的重叠。

| object_id | object_text | chunks |
|---|---|---|
| abc | gold ring lost | [gold,ring,lost] |
| xyz | fast cars zoom | [fast,cars,zoom] |
接下来,我们希望数组中的每个元素都有其自己的行。我们将使用Explode Array with Position面板将数据集变换为一个包含六行的数据集。每行中的新列(如下所示)是一个结构(映射),包含两个键值对,数组中的位置和数组中的元素。

| object_id | object_text | chunks | chunks_with_position |
|---|---|---|---|
| abc | gold ring lost | [gold,ring,lost] | {position:0, element} |
| abc | gold ring lost | [gold,ring,lost] | {position:1, element} |
| abc | gold ring lost | [gold,ring,lost] | {position:2, element} |
| xyz | fast cars zoom | [fast,cars,zoom] | {position:0, element} |
| xyz | fast cars zoom | [fast,cars,zoom] | {position:1, element} |
| xyz | fast cars zoom | [fast,cars,zoom] | {position:2, element} |
从这里,我们将位置和元素提取到它们自己的列中。


| object_id | object_text | chunks | chunks_with_position | position | chunk |
|---|---|---|---|---|---|
| abc | gold ring lost | [gold,ring,lost] | {position:0, element} | 0 | gold |
| abc | gold ring lost | [gold,ring,lost] | {position:1, element} | 1 | ring |
| abc | gold ring lost | [gold,ring,lost] | {position:2, element} | 2 | lost |
| xyz | fast cars zoom | [fast,cars,zoom] | {position:0, element} | 0 | fast |
| xyz | fast cars zoom | [fast,cars,zoom] | {position:1, element} | 1 | cars |
| xyz | fast cars zoom | [fast,cars,zoom] | {position:2, element} | 2 | zoom |
为了为每个块创建一个唯一标识符,我们将块在其数组中的位置转换为字符串,然后将其与原始对象ID连接。我们还将删除不必要的列。
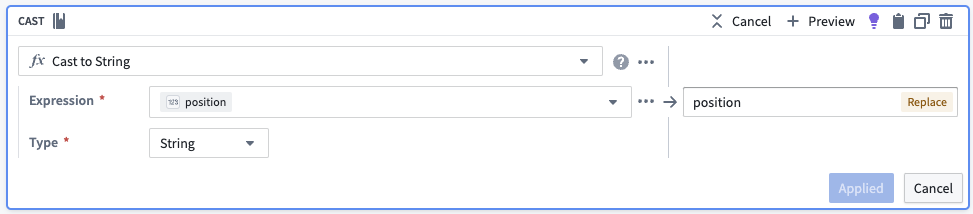
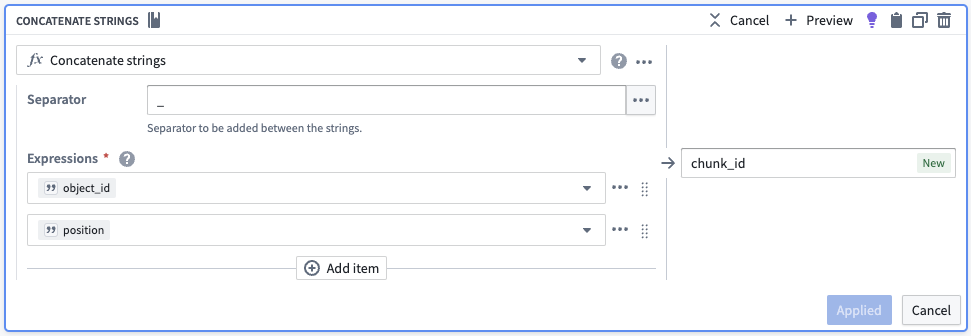

| object_id | chunk | chunk_id |
|---|---|---|
| abc | gold | abc_0 |
| abc | ring | abc_1 |
| abc | lost | abc_2 |
| xyz | fast | xyz_0 |
| xyz | cars | xyz_1 |
| xyz | zoom | xyz_2 |
现在,我们有六行代表六个不同的块,每个块都有object_id(用于链接)、新的chunk_id作为新的主键,以及chunk用于如语义搜索工作流中描述的嵌入。这导致如下表:
| object_id | chunk | chunk_id | embedding |
|---|---|---|---|
| abc | gold | abc_0 | [-0.7,...,0.4] |
| abc | ring | abc_1 | [0.6,...,-0.2] |
| abc | lost | abc_2 | [-0.8,...,0.9] |
| xyz | fast | xyz_0 | [0.3,...,-0.5] |
| xyz | cars | xyz_1 | [-0.1,...,0.8] |
| xyz | zoom | xyz_2 | [0.2,...,-0.3] |