注意:以下翻译的准确性尚未经过验证。这是使用 AIP ↗ 从原始英文文本进行的机器翻译。
HyperAuto V2 架构
本页面描述了 HyperAuto V2 的架构。有关 HyperAuto V1 架构的描述,请访问 HyperAuto V1 概述。
HyperAuto V2 围绕数据集成工作流的三个主要组件进行编排和自动化——数据同步、构建器管道和Ontology,以便自动从支持的源生成可直接使用的输出。
HyperAuto 利用数据源的元数据,实时查询源以推断同步应该如何搭建,应用什么变换逻辑,以及如何设计适当的 Ontology。
HyperAuto 管道指的是由单个 HyperAuto 实例管理的所有资源,从同步到 Object。每个管道都以用户提供的源表列表为输入,将其同步到 Foundry(如果需要)并将其转换为有价值的、可直接使用的输出数据集和(非必填)Ontology Object。用户可以为每个源创建多个 HyperAuto 管道,以满足其个人需求。
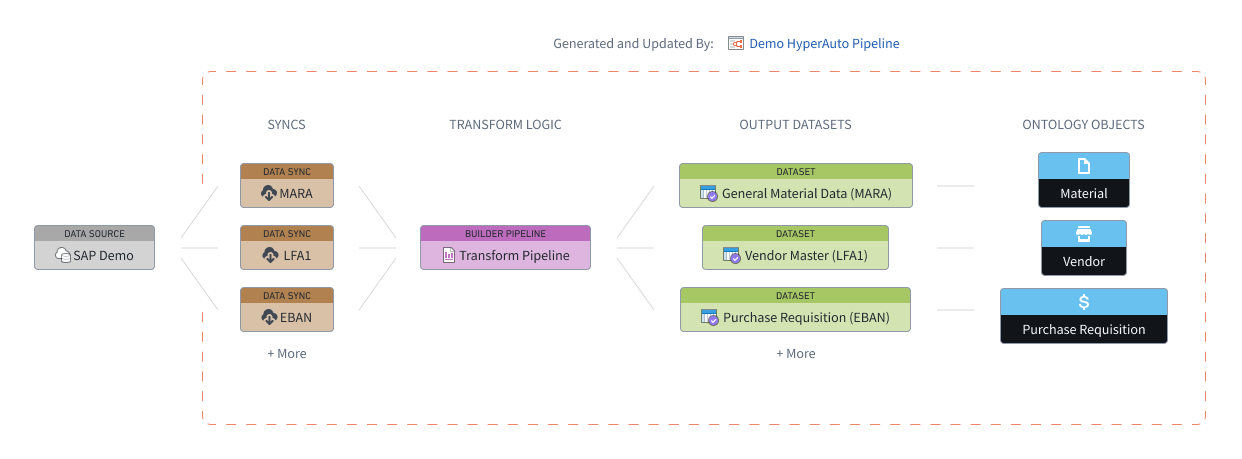
数据同步
当不存在与源的直接连接时,HyperAuto 也支持使用静态文件,在这种情况下,本节不适用。请参阅基于文件夹的 SAP 文档以了解更多信息。
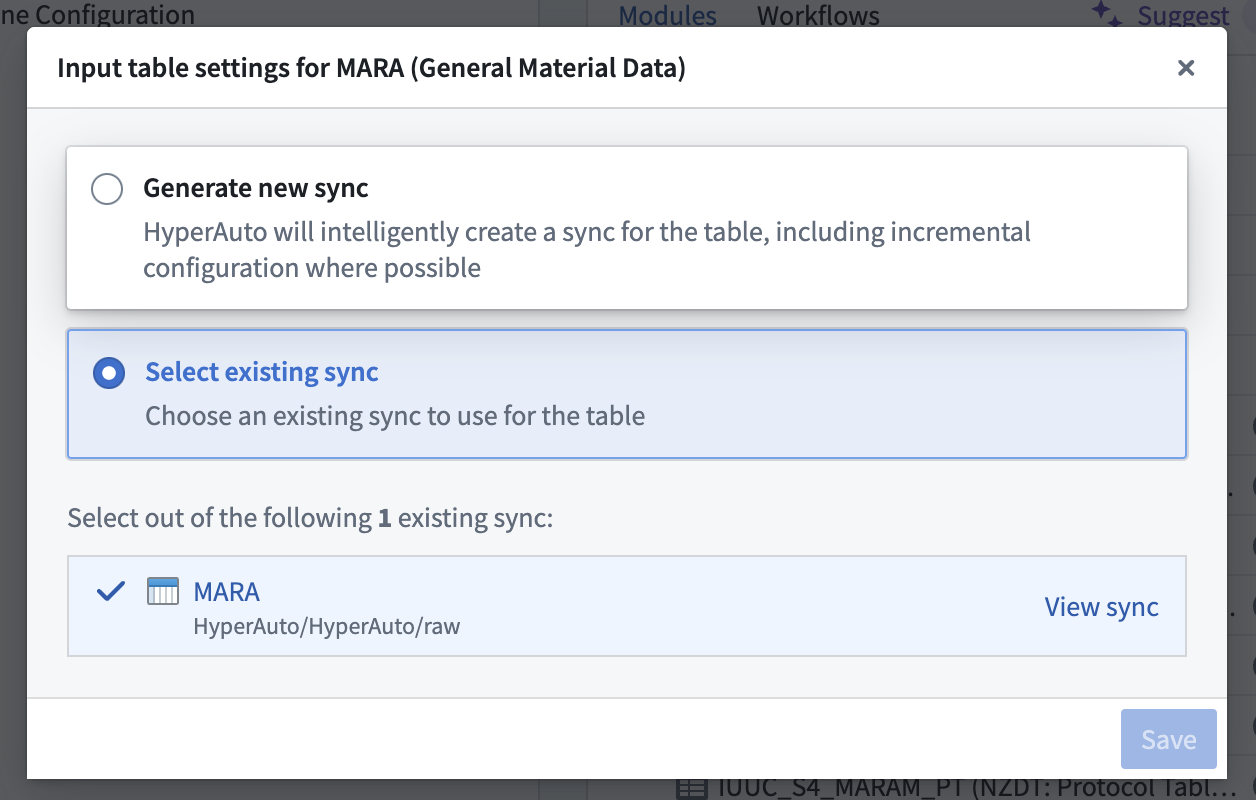
HyperAuto 提供对源上所有可见表的访问权限。如果用户选择的源表未映射到现有数据同步,则将自动生成新的数据同步。
如果所选源表已经存在一个或多个数据同步,则默认会选择最新的同步。您可以在输入配置页面上通过悬停在配置输入表按钮上来更改该选择。在那里,可以选择使用不同的现有同步或选择创建新的同步。
根据数据规模,如果 HyperAuto 创建了新的数据同步,生成可能需要更长时间。这是因为在 HyperAuto 的其他流程(如构建器管道生成)之前,数据同步需要进行初始运行。
数据变换(管道构建器)
HyperAuto 管道内的数据变换允许将难以使用的源数据转换为经过清理、丰富的输出,可以立即用于分析和应用搭建。
HyperAuto 管道由自动生成的构建器管道提供支持,这是 Foundry 内进行数据变换的主要方法。
HyperAuto 根据源类型和用户的偏好动态生成有见地的变换逻辑。用户可以通过从 HyperAuto 管道概述页面选择查看管道来查看此构建器管道。对该管道的编辑通过提案更改 HyperAuto 配置来进行。
HyperAuto 中可用的变换功能类型如下:
- **清理:**源系统通常导出带有常见“清洁”问题的数据,例如数据类型不正确、空/空值处理不当或字符串值中不需要的空白。HyperAuto 提供有见地的变换选项来修复这些问题(以及更多)。
- **重命名:**通过使用源的元数据,HyperAuto 可以将输出表和列重命名为描述性和自解释性,而不是坚持使用通常不可读的模式。
- **合并:**源系统通常将相关信息(如元数据)存储在单独的表中,例如在符合“规范”数据模型时。HyperAuto 使用其对源数据模型的理解来合并这些表,提供非规范化的丰富输出数据集,便于分析并为 Ontology 提供强大的基础。
- **筛选:**不需要的行(如重复项)可以由 HyperAuto 自动筛选掉,例如去重更改数据捕获输入。
支持批处理和实时流媒体管道模式,请参阅配置选项以了解更多详细信息。

Ontology
HyperAuto 可以使用源的数据模型根据生成的输出数据集动态生成Ontology,包括定义对象之间的语义链接。
启用此设置可以让您从新的(支持的)源到完全定义的 Ontology 只需几分钟,无需人工干预。
如果您对该功能感兴趣,请联系您的 Palantir 代表。
资源管理
HyperAuto 管道设计为完全控制其创建的任何资源,使用户能够持续获得系统的好处和升级,包括性能升级和错误修复。 这些管道的设计也使得很容易对已经生成的资源进行微调,例如在管道中添加新的变换步骤或输入。
对基础资源(例如同步或构建器管道)的任何编辑必须通过 HyperAuto 应用程序进行管理,以避免更改冲突。
如果需要,删除 HyperAuto 管道资源将移除其对相应构建器管道的所有权,允许正常直接编辑构建器管道。