注意:以下翻译的准确性尚未经过验证。这是使用 AIP ↗ 从原始英文文本进行的机器翻译。
推荐的健康检查
本文档提供了设置健康检查以监控管道健康状态的最佳实践。遵循这些指南应能实现稳健且有效的监控,以确保:数据输入、数据搭建和数据输出。
这些最佳实践不会涵盖确保数据集内容的质量、准确性或有效性。这需要对管道有更细致和功能性的了解,以确定在管道内进行正确的验证。
这些指南还应帮助您避免健康检查设置中的常见陷阱:
- 检查过多导致检查量过多而产生噪声
- 错误类型的检查导致无用的警报
- 检查过少导致在有问题时缺乏信号
先决知识
这些指南依赖于对以下内容的理解:
在本文档中,提到的计划的输入、中间和输出指的是已解析的计划,这与数据沿袭应用程序中的计划配置不同。
重要的监控概念
监控单位:已解析的计划
已解析的计划是一种指派角色给计划中涉及的不同数据集的心智模型。有些数据集会参与进来,因为它们可以由计划搭建,这意味着它们是计划的数据集选择的一部分。其他数据集则作为搭建所需的输入参与。根据数据集的角色,推荐不同的健康检查。
数据集在计划中可以有以下角色之一:
- 输出 是计划的最后步骤的数据集。它们由计划搭建,但不被计划中的任何其他数据集使用。
- 中间 是由计划搭建的所有数据集,但不是计划的输出。
- 输入 是不由计划搭建,但被计划使用的数据集。输入构成了计划读取的第一层,例如,数据连接同步和您自己不搭建的派生数据集。
在一个具体的例子中,假设一个计划搭建了以下数据集:
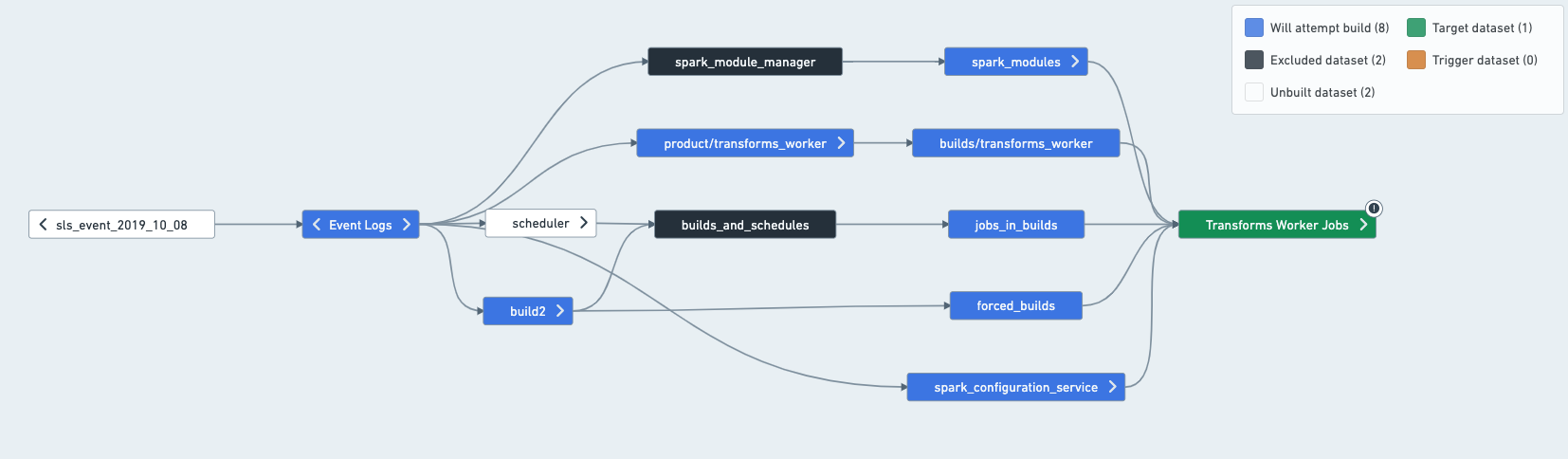
在这种情况下,您可以这样拆分计划:
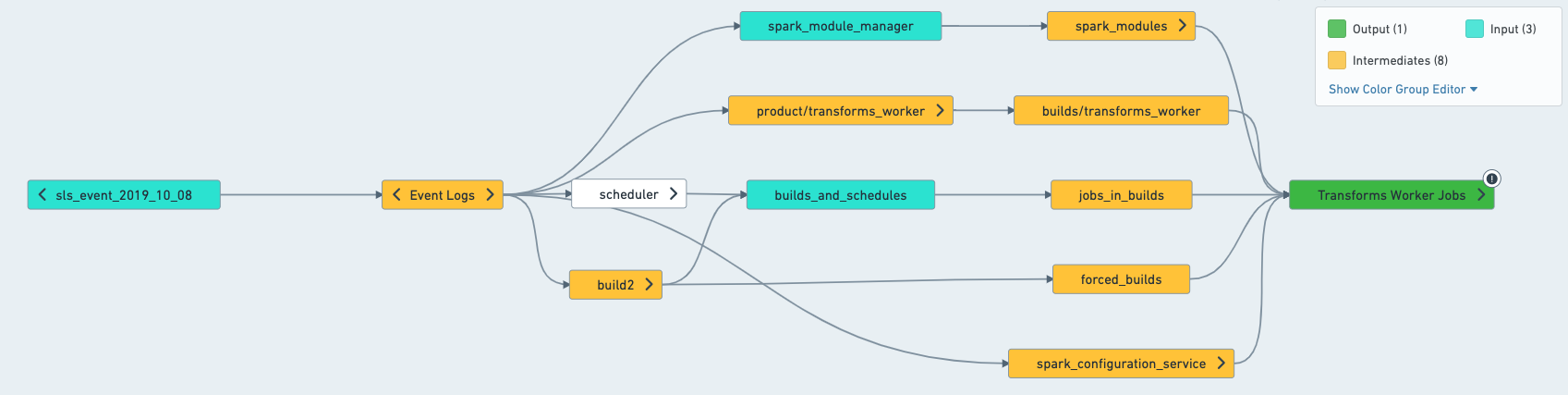
理解实际搭建的内容
要确定一个计划的输入、输出和中间数据集,最简单的方法是打开数据沿袭中的计划。一旦进入数据沿袭,从侧边栏选择计划,这将应用计划着色,帮助您理解计划将尝试搭建的内容。
-
目标和将尝试搭建的内容通常由计划搭建。一个例外是数据连接同步的数据集,只有在计划上设置了“强制搭建”时才会搭建。
-
排除 永远不会由计划搭建。
-
输入(仅连接搭建) 不由计划搭建,除非它们有另一个上游输入。
关于陈旧性的一点简要说明:在实践中,计划很少会搭建这个图中的所有内容,因为某些数据集可能已经是最新的,重新计算它们只会浪费资源。然而,理解解析计划意味着弄清楚计划可以接触到的所有内容仍然很重要。
目标与输出
计划在“目标”上定义,这些通常与“输出”相同。然而,有些情况下目标和输出可能不同:
(1) 数据集可以是“输出”而不是明确定义的“目标”:
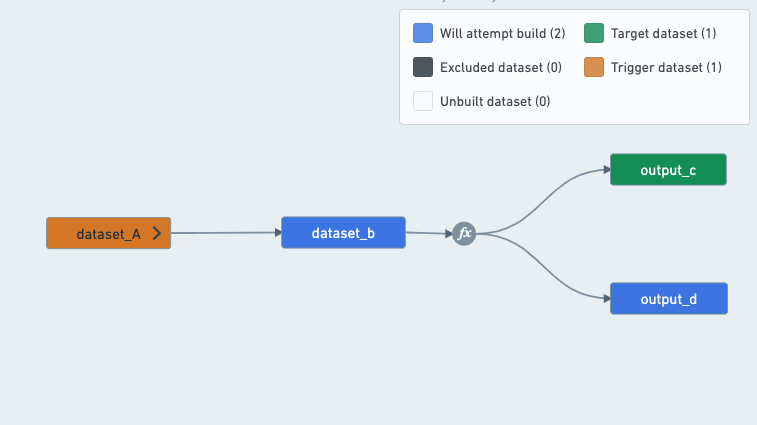
一个搭建output_c的计划将总是需要搭建output_d,因为B、C和D之间的变换是多输出变换。
因此,一个目标为output_c的计划将同时有output_c和output_d作为输出,因为output_d是由计划搭建且不被计划中的任何其他数据集使用的数据集。

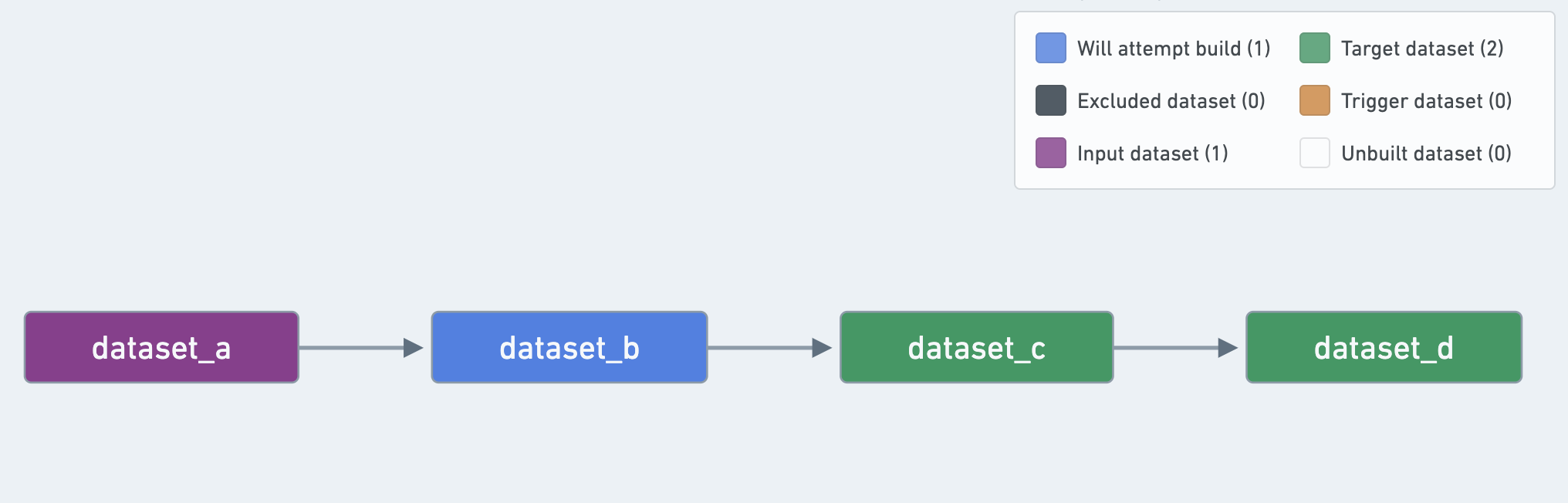
(2) 数据集可以被定义为“目标”但不是“输出”:
即使一个数据集被定义为计划的“目标”,如果它被计划中的其他数据集使用,它被视为“中间”数据集而不是“输出”数据集。
在这个例子中,dataset_c是计划的“目标”,但不被视为“输出”:
健康检查应安装在计划的哪个位置?
以下逐步指南依赖于对任务与搭建状态检查,以及同步与数据新鲜度与上次更新时长检查的理解。如果您不确定这些检查之间的区别,请参阅健康检查类型。
计划为我们提供了管道的合理表示。由于它们是推荐的监控单位,您的监控效果取决于您设置的计划。在开始设置健康检查之前,请确保您的计划遵循这里概述的最佳实践。
输入检查
在您的管道的所有已解析输入上安装检查。如果您的管道失败,能够追踪根本原因非常重要。输入陈旧或架构断裂时有发生——在输入上安装检查将帮助您检测到它们。注意:目前,一个特定类型的检查只能存在于一个特定数据集上。如果您想安装的检查已经存在,只需订阅它。
- 架构检查:如果列被添加或删除,或者您的管道依赖的列名和类型发生意外更改,这将警告您。
- 上次更新时长(TSLU)[非必填]:允许您验证数据是否按时交付给您的管道输入。这可以帮助您在管道未按时搭建时进行根本原因分析。这是一个非必填检查,只有在您确切知道预期的更新频率时才应安装。
- 如果有上游所有者已经监控您的输入数据集,您也应避免应用此检查(您可能甚至没有权限在上游数据集上添加检查)。
- 建议启用“忽略空交易”。
- 任务或搭建状态:非必填,但建议用于数据连接同步或所有权未明确的数据集。推荐使用搭建状态而不是任务状态,因为如果您的输入数据集所属的搭建在上游数据集中失败并被取消/中止,导致单个任务本身未运行,您也会收到警报。
输出检查
在您的管道的所有已解析输出上安装检查(请记住,这些是由计划搭建的,但不被您的计划中的任何其他数据集使用)。
- 搭建状态检查:这将捕捉管道中的所有失败。无需在每个数据集上放置任务状态检查。
- 由于使用搭建状态,我们建议每个计划的输出较少。
- 搭建时长检查:用于捕捉可能的冲突或阻塞您的管道的搭建。此外,还用于检测以下原因导致的问题:
- 异常输入(例如,当某些输入中的键分布发生变化时,连接可能会突然变得更长)。提示:一个失败的任务完成了阶段中的所有任务,除了一个任务,这是键连接偏斜的强烈标志。
- 由代码更改引起的性能下降。
- 上次更新时长检查(TSLU):使用此检查确保您的管道按要求的节奏更新。
- 示例:如果您的管道应每24小时运行一次(例如,每天上午9点,平均搭建时间为1小时),您可以:
- 将“自上次更新以来”的阈值设置为26小时(考虑搭建时间并给出一些余地),并让检查自动更新。
- 将阈值设置为2小时,并让检查按计划运行:在我们的例子中,每天上午11点。提示:检查“自动解决”标志,否则如果搭建完成稍微晚了一点,您的管道将在整个24小时内被视为不健康。
- 示例:如果您的管道应每24小时运行一次(例如,每天上午9点,平均搭建时间为1小时),您可以:
- 架构检查:您的管道输出通常被其他应用程序如Contour、Slate或Object Explorer中的用户消费。这意味着当输出架构断裂时,警告非常重要,因为您可能需要采取措施更新下游应用程序或通知用户。
- 通过在输出数据集上进行搭建状态、搭建时长和TSLU检查,您可以在搭建状态和搭建时长方面提前警告。如果TSLU最终触发,可能出现问题并需要有人调查。
非必填检查
可选地,在重要的中间数据集上安装检查,这些数据集通过其他应用程序直接或通过同步被用户消费:
- 架构检查:类似于输出,如果用户在任何应用程序中消费数据集(无论是通过Contour还是同步),架构更改可能会导致断裂或需要手动跟进步骤。
- 数据新鲜度:使用此检查确保您的数据集内容符合新鲜度要求(如果您有一个合适的时间戳列,可以告诉您行何时添加到源系统的数据集中)。
- 上次更新时长检查:如果您有一个关键数据集(例如一个被许多其他用户使用的中间数据集),它可能由于上游延迟而未能按时更新。希望您通过管道输入检查检测到它,但添加一个TSLU检查是一个有用的补充。
- 如果存在同步:
- 同步状态检查:应安装在正在同步的数据集上(无论是到Foundry应用程序如Slate还是到外部系统)
- 同步新鲜度检查:这在与数据新鲜度和TSLU一起评估时特别有帮助,因为您将能够快速确定问题是a)数据集未能按时更新,b)数据集已更新但源系统未提供新鲜数据,还是c)数据集有新鲜数据但同步未刷新。
总结表
上面解释的最佳实践总结在此表中以便快速参考:
| 搭建状态 | 架构 | 搭建时长 | TSLU | 数据新鲜度 | 同步新鲜度 | 同步状态 | |
|---|---|---|---|---|---|---|---|
| 输入 | ✓ | ✓ (允许添加) | |||||
| 中间 | |||||||
| 输出 | ✓ | ✓ (完全匹配) | ✓ | ✓ | |||
| 面向用户的数据集* | ✓ (完全匹配) | ✓ | |||||
| 已同步的数据集* | ✓ (完全匹配) | ✓ | ✓ | ✓ |
[*] 可以是输入、中间或输出数据集。面向用户的数据集是用户直接在应用程序中消费的数据集,如Contour。