注意:以下翻译的准确性尚未经过验证。这是使用 AIP ↗ 从原始英文文本进行的机器翻译。
实时部署计算使用情况
Foundry 机器学习实时部署是一个持久的、可扩展的模型发布部署,可以通过 API 端点进行交互。实时部署持续保留专用计算资源,以确保部署能够快速响应传入流量。因此,托管实时部署在部署活动期间会使用 Foundry 的计算秒数。请注意,这仅适用于模型支持的部署:JavaScript 函数支持的部署不在本文档的覆盖范围内。
运行时,Foundry 机器学习实时计算使用量归因于建模目标本身,并在包含建模目标的项目级别进行汇总。要深入了解 Foundry 中计算秒的定义以及用于计算使用量的公式来源,请查看使用类型文档。
计算秒的测量
Foundry 机器学习实时在 Foundry 的基于 pod 的计算集群上托管其基础设施,使用专用的“副本”运行。每个副本被指派一组计算资源,以 vCPU 和 GiB RAM 为单位进行测量。每个副本本地托管模型,并使用其计算资源来处理传入请求。
Foundry 机器学习实时部署在其活动期间使用计算秒数,无论接收到的请求数量如何。部署一旦启动即被视为“活动”,并持续到通过图形界面或 API 将其关闭为止。如果与实时部署关联的建模目标被发送到 Compass 回收站,实时部署也将被关闭。
实时部署将使用的计算秒数取决于三个主要因素:
- 每个副本的 vCPU 数量
- 对于实时部署,vCPU 以 millicore 为单位进行测量,每个 millicore 是 vCPU 的 1/1000
- 每个副本的 GiB RAM
- 每个副本的 GPU 数量
- 副本的数量
- 部署中的每个副本将具有相同数量的 vCPU 和 GiB RAM
在支付 Foundry 使用费用时,默认使用费率如下:
| vCPU / GPU | 使用费率 |
|---|---|
| vCPU | 0.2 |
| T4 GPU | 1.2 |
| A10G GPU | 1.5 |
| V100 GPU | 3 |
这些是实时模型在 Foundry 的并行计算框架下根据其计算配置文件使用计算的费率。如果您与 Palantir 签订了企业合同,请在进行计算使用量计算之前联系您的 Palantir 代表。
以下公式用于计算 vCPU 计算秒数:
live_deployment_vcpu_compute_seconds = max(vCPUs_per_replica, GiB_RAM_per_replica / 7.5) * num_replicas * live_model_vcpu_usage_rate * time_active_in_seconds
# live_deployment_vcpu_compute_seconds 计算公式:
# 1. 计算每个副本所需的 vCPU 数量(vCPUs_per_replica)和每 7.5 GiB RAM 所需的 vCPU 数量(GiB_RAM_per_replica / 7.5)中的较大值。
# 2. 将上述结果乘以副本数量(num_replicas)。
# 3. 将乘积结果乘以模型使用 vCPU 的速率(live_model_vcpu_usage_rate)。
# 4. 最后乘以模型活动的时间(time_active_in_seconds)。
以下公式测量GPU计算秒数:
Copied!1 2 3 4 5 6# 计算实时部署所用的GPU计算秒数 # GPUs_per_replica: 每个副本使用的GPU数量 # num_replicas: 副本数量 # live_model_gpu_usage_rate: 实时模型的GPU使用率 # time_active_in_seconds: 模型活动的时间(以秒为单位) live_deployment_gpu_compute_seconds = GPUs_per_replica * num_replicas * live_model_gpu_usage_rate * time_active_in_seconds
调查建模目标的使用情况
平台上的所有计算秒使用情况都可以在资源管理应用中查看。
部署的计算使用情况附加于其来源的Foundry建模目标。请注意,对于任何给定的目标,可以有多个实时部署处于活动状态。建模目标的实时部署可以在部署部分找到。请参见下面的截图示例。
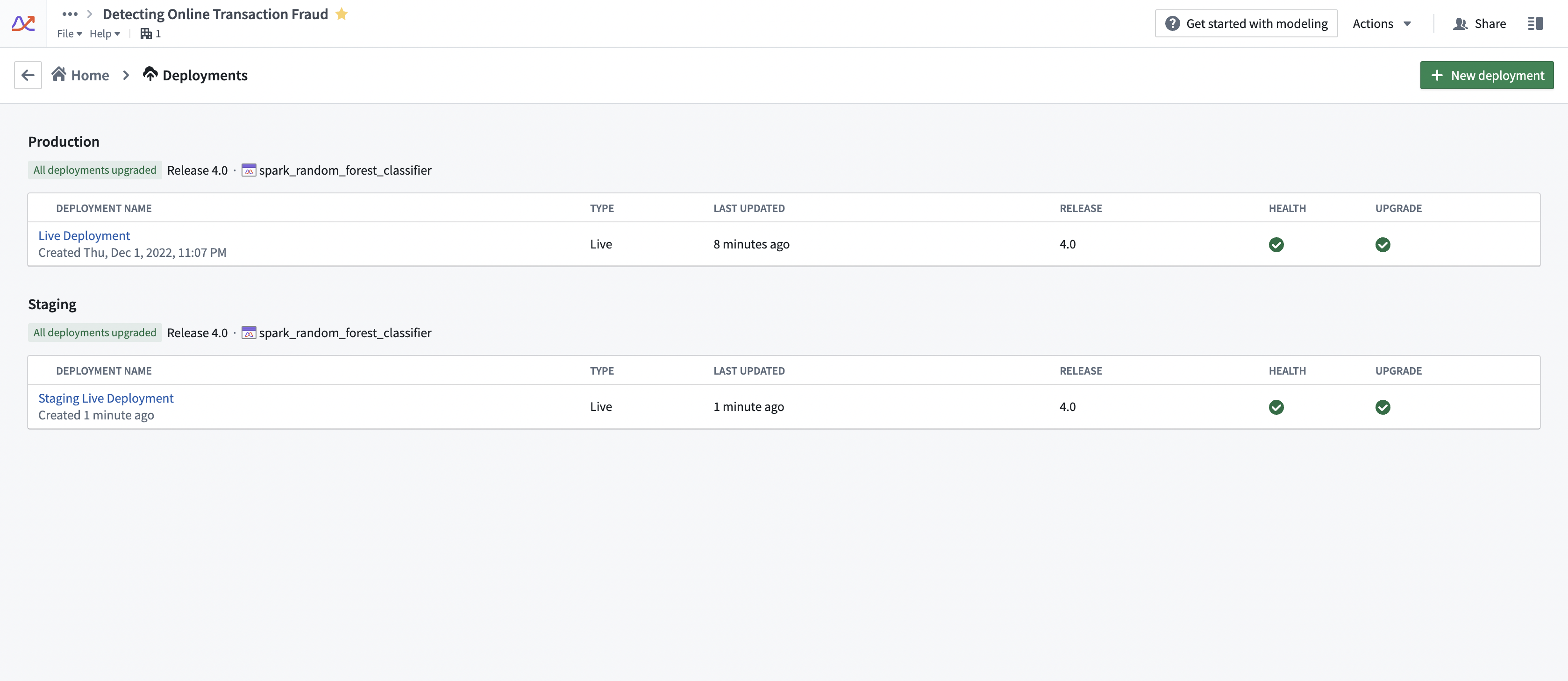
使用量增加或减少的驱动因素
实时部署在活动时使用计算秒。可以通过一些策略来控制部署的总体使用量。
- 确保部署针对您预期的请求负载进行正确调整。部署应针对预期的同时请求峰值进行调整。如果部署资源不足,则会开始对请求返回失败响应。然而,资源过剩的部署可能会使用比必要更多的计算秒。
- Palantir建议实时部署管理员对实时部署端点进行压力测试,以确定在将模型部署到运营关键环境之前的正确资源配置。
- 实时部署将运行,直到它们被明确停止或取消。重要的是监控实时部署的使用情况,以确保部署在不需要时没有错误地继续运行。这在分阶段部署中很常见。
- 在不更改其配置文件的情况下增加/减少部署上的API负载不会影响其计算使用情况。实时部署将根据其资源允许的情况下服务尽可能多的请求,而不会更改其使用的计算秒数量。
管理使用情况
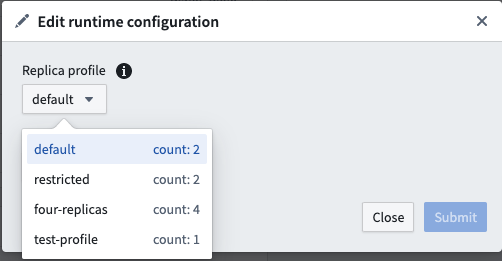
实时部署的资源使用情况由其配置文件定义。配置文件可以在实时部署创建时设置。配置文件可以在部署活动时更改。部署将自动接收更新后的配置文件且无停机时间。
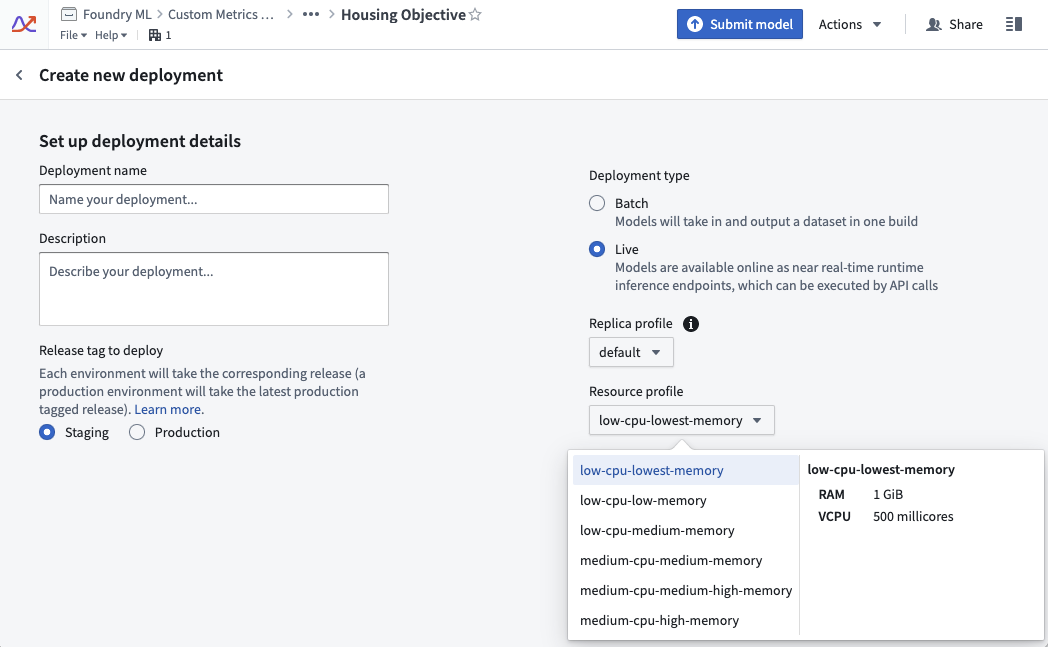
使用示例
示例1:vCPU计算
对于具有默认副本配置文件为两个副本、活动时间为20秒且使用“低CPU-最低内存”配置文件的实时部署。
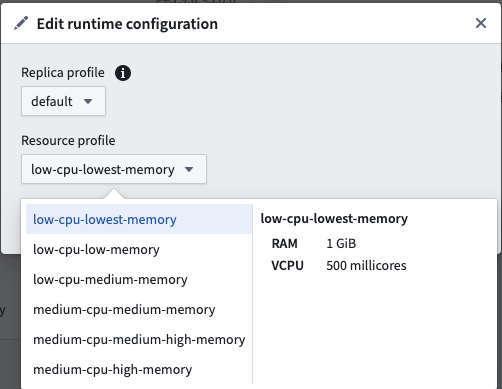
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16resource_config: num_replicas: 2 # 副本数量 vcpu_per_replica: 0.5 vCPU # 每个副本分配的虚拟CPU数 GiB_RAM_per_replica: 1 GiB # 每个副本分配的内存大小(GiB) seconds_active: 20 seconds # 活跃时间(秒) live_model_vcpu_usage_rate: 0.2 # 模型活跃时虚拟CPU的使用率 # 计算消耗的计算秒数 compute seconds = max(vcpu_per_replica, GiB_RAM_per_replica / 7.5) * num_replicas * live_model_vcpu_usage_rate * time_active_in_seconds = max(0.5vCPU, 1GiB / 7.5) * 2replicas * 0.2 * 20sec = 0.5 * 2 * 0.2 * 20 = 4 compute-seconds # 说明: # 计算公式中,首先计算每个副本需要的资源量,选取 vCPU 和内存(按 7.5 GiB/vCPU 转换)的较大值。 # 然后乘以副本数量、虚拟CPU使用率和活跃时间,得到最终的计算秒数。
示例2:GPU计算
以下示例显示了一个实时部署的使用率。该实时部署具有一个默认副本配置文件,其中包含两个副本,并在具有GPU V100配置文件的情况下活跃20秒。
Copied!1 2 3 4 5 6 7 8 9 10resource_config: num_replicas: 2 # 副本数量 gpu_per_replica: 1 V100 GPU # 每个副本使用的GPU数量 seconds_active: 20 seconds # 活动时间(秒) live_model_gpu_usage_rate: 3 # 活动模型的GPU使用率 compute seconds = gpu_per_replica * num_replicas * live_model_gpu_usage_rate * time_active_in_seconds = 1 * 2replicas * 3 * 20sec = 1 * 2 * 3 * 20 = 120 compute-seconds # 计算秒数
在这个计算中,我们首先定义了一些配置参数,例如副本数量、每个副本使用的GPU数量、活动时间和活动模型的GPU使用率。然后,计算总的计算时间(compute-seconds),这是通过将这些参数相乘得到的。