注意:以下翻译的准确性尚未经过验证。这是使用 AIP ↗ 从原始英文文本进行的机器翻译。
API:查询模型或建模目标的实时部署
在直接模型部署和建模目标中,您可以创建实时部署并通过HTTP端点托管您的模型。可以通过实时部署的查询选项卡,使用模型上的函数在生产中使用模型,或直接使用实时部署API来测试托管模型。
要直接查询托管模型,请从以下端点选项中选择:
- 多I/O端点: 为复杂的托管模型和输入类型设计的更灵活的端点。
- 单I/O端点: 为较不复杂的托管模型设计的简化端点。
单I/O端点已弃用,仅在建模目标部署中支持。
多I/O端点
多I/O端点是一个灵活的端点,支持一个或多个输入和一个或多个输出。
多I/O端点不支持基于数据集的模型。
- URL:
<ENVIRONMENT_URL>/foundry-ml-live/api/inference/transform/ri.foundry-ml-live.<LIVE_DEPLOYMENT_RID>/v2<ENVIRONMENT_URL>:有关更多信息,请参阅下面部分。
- HTTP方法:
POST - 认证类型: Bearer词元
- 必需的HTTP标头:
Content-Type:必须为"application/json"。Authorization:必须为"Bearer <BEARER_TOKEN>",其中<BEARER_TOKEN>是您的认证词元。
- 请求体: 一个包含要发送给模型的信息的JSON对象。其预期结构取决于已部署模型的API。
- 响应: 成功的响应将返回状态代码
200和一个由模型返回的推理响应的JSON对象。此对象的结构将反映当前部署模型的API。
示例:使用多I/O端点查询实时部署
对于以下示例,我们将使用一个具有单输入和输出的简单API模型。
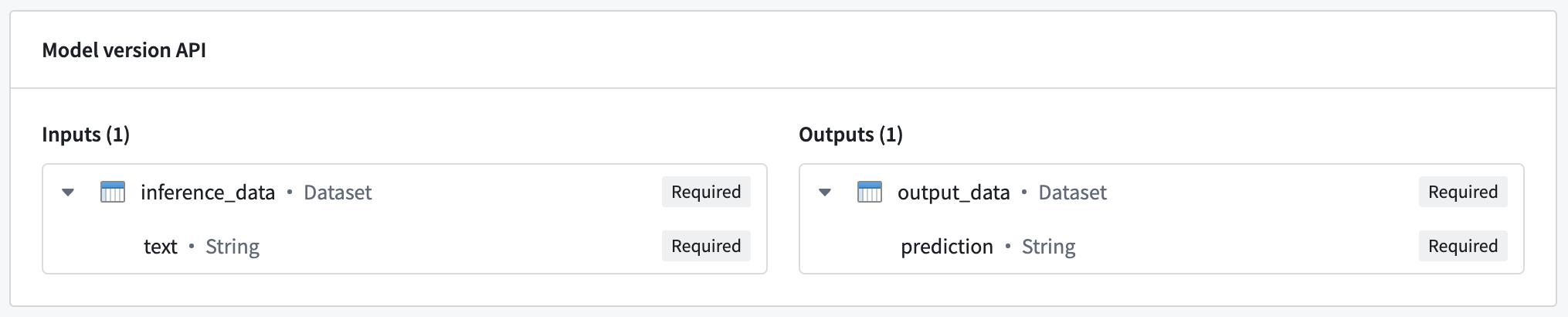
此示例中的托管模型期望一个名为inference_data的单一输入,这是一个包含text列的数据集。在这种情况下,预期的请求格式如下:
Copied!1 2 3 4 5 6{ "inference_data": [{ "text": "<Text goes here>" // 在这里插入文本 }] }
Copied!1 2 3 4 5{ "output_data": [{ "prediction": "<Model prediction here>" // 模型预测结果 }] }
Copied!1curl --http2 -H "Content-Type: application/json" -H "Authorization: <BEARER_TOKEN>" -d '{ "inference_data": [ { "text": "Hello, how are you?" } ] }' --request POST <ENVIRONMENT_URL>/foundry-ml-live/api/inference/transform/ri.foundry-ml-live.<LIVE_DEPLOYMENT_RID>
此命令使用 curl 工具发送一个 HTTP/2 POST 请求至指定的机器学习服务接口。
-H "Content-Type: application/json": 设置请求头,表明发送的数据格式为 JSON。-H "Authorization: <BEARER_TOKEN>": 设置授权头,其中<BEARER_TOKEN>需要替换为实际的访问令牌,用于认证请求的身份。-d '{ "inference_data": [ { "text": "Hello, how are you?" } ] }': 发送的数据体,包含一个 JSON 对象,inference_data字段内包含待推理的文本数据。--request POST: 指定使用 POST 方法发送请求。<ENVIRONMENT_URL>/foundry-ml-live/api/inference/transform/ri.foundry-ml-live.<LIVE_DEPLOYMENT_RID>: 请求的目标 URL,其中<ENVIRONMENT_URL>和<LIVE_DEPLOYMENT_RID>需要替换为实际的环境 URL 和部署 ID。
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17import requests # 定义请求的URL,其中包含环境URL和实时部署的资源ID url = '<ENVIRONMENT_URL>/foundry-ml-live/api/inference/transform/ri.foundry-ml-live.<LIVE_DEPLOYMENT_RID>/v2' # 构建推理请求数据,其中包含待处理文本 inference_request = { 'inference_data': [ { 'text': 'Hello, how are you?' } ] } # 发送POST请求,包含推理请求数据和必要的请求头信息 response = requests.post(url, json = inference_request, headers = { 'Content-Type': 'application/json', 'Authorization': 'Bearer <BEARER_TOKEN>' }) # 检查响应状态码,如果请求成功则打印模型结果,否则打印错误信息 if response.ok: modelResult = response.json() print(modelResult) else: print("An error occurred")
此代码使用Python的requests库向机器学习服务发送HTTP POST请求,用于进行文本推理。请求中的数据和认证信息需要根据实际情况进行替换。
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28// 构建请求 const inferenceRequest = { "inference_data": [{ "text": "Hello, how are you?" // 推理数据,包含要处理的文本 }] }; // 发送请求 const response = await fetch( "<ENVIRONMENT_URL>/foundry-ml-live/api/inference/transform/ri.foundry-ml-live.<RID>/v2", // 替换 <ENVIRONMENT_URL> 和 <RID> 为实际的环境URL和资源ID { method: "POST", // 使用 POST 方法发送请求 headers: { "Content-Type": "application/json", // 请求头,表示发送的数据类型为 JSON Authorization: "Bearer <BEARER_TOKEN>", // 授权头,替换 <BEARER_TOKEN> 为实际的 Bearer 令牌 }, body: JSON.stringify(inferenceRequest), // 请求体,包含序列化后的推理请求数据 } ); if (!response.ok) { throw Error(`${response.status}: ${response.statusText}`); // 如果响应状态不是 OK,抛出错误 } const result = await response.json(); // 解析响应数据为 JSON 格式 console.log(result); // 输出结果到控制台
示例:多输入输出模型
多输入输出模型可以接收多个输入并返回多个输出。下图显示了一个具有多个输入和输出的模型示例:
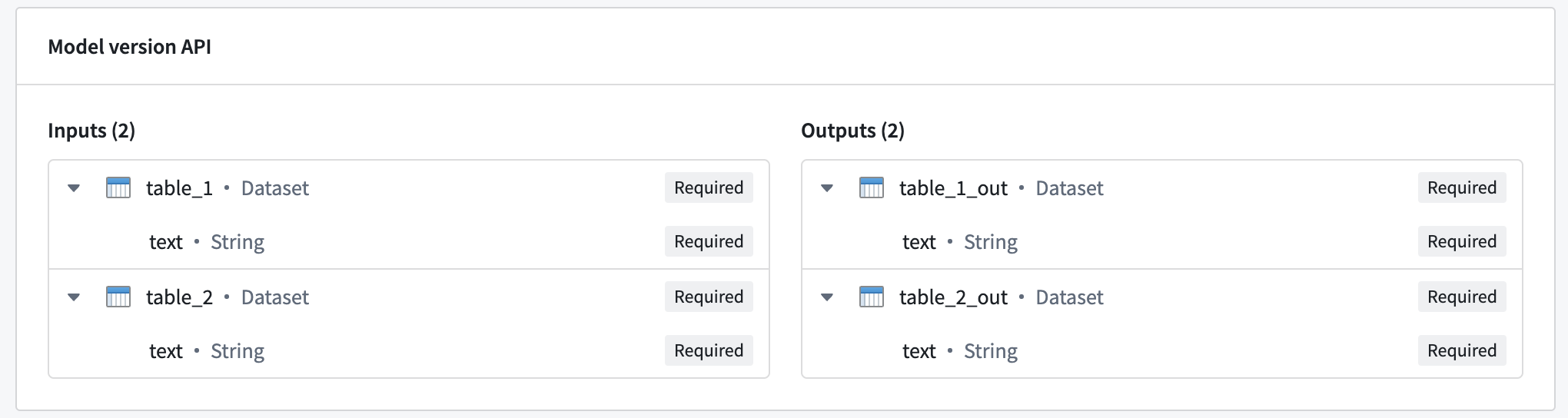
要查询多输入输出模型,请使用与前面示例中相同的请求格式,其中inference_request包含每个输入的命名字段:
Copied!1 2 3 4{ "table_1": [{ "text": "Text for table one" }], // 表格一的文本 "table_2": [{ "text": "Text for table two" }] // 表格二的文本 }
模型还将响应一个包含每个输出命名字段的Object:
Copied!1 2 3 4{ "table_1_out": [{ "text": "Result for table one" }], // 表格一的结果 "table_2_out": [{ "text": "Result for table two" }], // 表格二的结果 }
单一I/O端点
单一I/O端点不支持多I/O模型。
所有使用foundry_ml打包的模型都应使用单一I/O端点。
- URL:
<ENVIRONMENT_URL>/foundry-ml-live/api/inference/transform/ri.foundry-ml-live.<LIVE_DEPLOYMENT_RID> <ENVIRONMENT_URL>: 更多信息请参见下面部分。- HTTP方法:
POST - 认证类型: Bearer词元
- 必需的HTTP头:
Content-Type: 必须为"application/json"。Authorization: 必须为"Bearer <BEARER_TOKEN>",其中<BEARER_TOKEN>是您的认证词元。
- 请求体: 包含以下字段的JSON Object:
requestData: 包含要发送到模型的信息的数组。此数组的预期形状取决于已部署模型的API。requestParams: 包含要发送到模型的请求参数的Object。仅用于使用foundry_ml打包的模型,此Object的预期形状也取决于已部署模型的API。
- 响应: 成功响应将返回状态码
200以及包含以下字段的JSON Object:modelUuid: 标识模型的字符串。responseData: Object数组,其中每个Object表示模型的推理响应。这些Object的形状取决于已部署模型的API。
示例: 使用单一I/O端点查询实时部署
对于以下示例,我们将使用一个具有简单API的单一输入和输出的模型。
此示例中托管的模型期望一个名为inference_data的单一输入,它是包含text列的数据集。在这种情况下,预期的请求格式如下:
Copied!1 2 3 4{ "requestData": [{ "text": "<Text goes here>" }], // 在此处填写文本 "requestParams": {}, // 请求的参数,可以根据需要添加 }
模型以名为 output_data 的数据集进行响应,其中包含一个 prediction 列。这对应于以下响应:
Copied!1 2 3 4 5 6{ "modelUuid": "000-000-000", // 模型的唯一标识符 "responseData": [{ "prediction": "<Model prediction here>" // 模型预测的结果 }] }
示例:curl
Copied!1curl --http2 -H "Content-Type: application/json" -H "Authorization: <BEARER_TOKEN>" -d '{"requestData":[ { "text": "Hello, how are you?" } ], "requestParams":{}}' --request POST <ENVIRONMENT_URL>/foundry-ml-live/api/inference/transform/ri.foundry-ml-live.<RID>
Copied!1 2 3 4 5 6# 这段代码使用了 `curl` 工具来发送一个 HTTP/2 POST 请求。 # - `-H "Content-Type: application/json"`:设置请求头,指定发送的数据格式为 JSON。 # - `-H "Authorization: <BEARER_TOKEN>"`:添加授权头,使用 Bearer Token 进行身份验证。 # - `-d '{"requestData":[ { "text": "Hello, how are you?" } ], "requestParams":{}}'`:请求体包含一个 JSON 对象,`requestData` 是一个数组,包含需要处理的文本,`requestParams` 是请求的参数,这里是空的。 # - `--request POST`:指定请求方法为 POST。 # - `<ENVIRONMENT_URL>/foundry-ml-live/api/inference/transform/ri.foundry-ml-live.<RID>`:请求的 URL,这里的 `<ENVIRONMENT_URL>` 和 `<RID>` 需要替换为实际的环境 URL 和资源 ID。
示例:Python
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19import requests url = '<ENVIRONMENT_URL>/foundry-ml-live/api/inference/transform/ri.foundry-ml-live.<RID>' # 构建推理请求 inference_request = { 'requestData': [{ 'text': 'Hello, how are you?' }], # 请求数据 'requestParams': {}, # 请求参数 } # 发送POST请求到推理API端点 response = requests.post(url, json = inference_request, headers = { 'Content-Type': 'application/json', 'Authorization': 'Bearer <BEARER_TOKEN>' }) # 检查响应状态 if response.ok: modelResult = response.json()['responseData'] # 获取响应数据 print(modelResult) # 打印模型结果 else: print("An error occurred") # 打印错误信息
示例:JavaScript(使用 Node.js 18)
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28// 构建请求对象 const inferenceRequest = { requestData: [{ text: "Hello, how are you?" }], // 请求数据,包含需要处理的文本 requestParams: {}, // 请求参数,可以添加其他参数 }; // 发送请求 const response = await fetch( "<ENVIRONMENT_URL>/foundry-ml-live/api/inference/transform/ri.foundry-ml-live.<RID>", // API 端点 URL { method: "POST", // 使用 POST 方法 headers: { "Content-Type": "application/json", // 请求头,指定内容类型为 JSON Authorization: "Bearer <BEARER_TOKEN>", // 授权头,使用 Bearer Token 进行身份验证 }, body: JSON.stringify(inferenceRequest), // 请求体,序列化后的请求对象 } ); // 检查响应状态 if (!response.ok) { throw Error(`${response.status}: ${response.statusText}`); // 如果响应不正常,抛出错误 } const result = await response.json(); // 解析响应数据为 JSON console.log(result.responseData); // 输出响应数据
环境 URL
在上面显示的示例中,<ENVIRONMENT_URL>占位符代表您的环境的URL。要检索您的环境URL,请从部署沙箱的查询选项卡中复制curl请求并提取URL。

错误处理
最常见的HTTP错误代码详述如下:
- 400: 通常由模型推理过程中发生的异常引起。
- 422: 由格式不正确的请求引起。确认请求中的JSON有效并符合模型API。
- 429: 由于请求过多引起。请重试并使用退避算法。速率限制取决于您的环境。
- 500: 由内部服务器或部署错误引起。当部署不健康并自动尝试重新启动时,可能会发生这种情况。可能需要人工干预。
- 503: 服务不可用。请重试并使用退避算法。可能需要人工干预。