注意:以下翻译的准确性尚未经过验证。这是使用 AIP ↗ 从原始英文文本进行的机器翻译。
变换 Excel 解析器
在 Foundry 中,有多种方式可以从包含 Microsoft Excel 文件的无模式数据集中提取表格数据,包括管道搭建器、使用开源库如 openpyxl ↗ 的基于 Python 文件的变换和使用开源库如 Apache POI ↗ 的基于 Java 文件的变换。
除了这些选项外,Palantir 提供了一个名为 transforms-excel-parser 的库,它封装了 Apache POI 的合理默认行为,使其可以在 transforms-java 存储库中轻松使用,且无需复杂配置。
该库提供的一些有用功能和行为的示例包括:
- 处理包含部分重叠但不一致模式的输入数据集,从表头推断模式。
- 从多个工作表(或同一工作表中的不同表格)中提取数据,并将结果写入多个输出数据集中,同时只需将文件读取到内存中一次。
- 提供一个流畅的API,以定义从非表格化、“表单样式”工作表中提取字段(数据位于标签上方、下方或相邻)的操作。
- 设置适当的全局参数,解决常见的 Apache POI 问题,如错误的“压缩炸弹”检测或因超过“最大字节数组大小”而失败。
- 通过
ParseResult类上的errorDataframe()方法支持快速失败和安全失败行为,可以在运行时检查以失败任务,或者将其写入单独的输出并异步检查。 - 为增量管道提供适当的配置选项和实用函数,以处理常见边缘情况,如增量批次间不一致的模式。
设置
1. 确认 transforms-excel-parser-bundle 的可用性并将其添加为支持存储库
在存储库的 Maven 库面板中搜索 transforms-excel-parser。

选择最新版本。
这将显示一个对话框,用于将 transforms-excel-parser-bundle 作为额外的支持存储库导入。选择“添加库”。
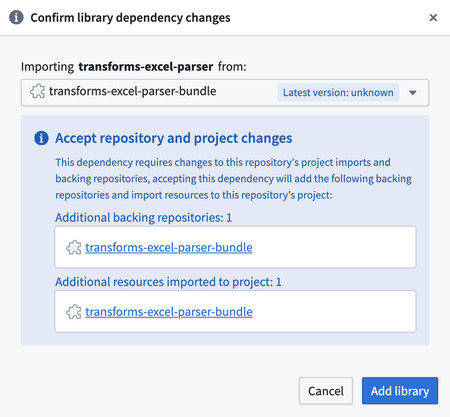
您可能会看到 eddie-spark-module-bundle 和/或 ri.eddie.artifacts.repository.bundles 除了 transforms-excel-parser-bundle 之外的下拉选项。
名称中带有 eddie 的支持存储库专为 管道搭建器 应用程序专用,因此它们不是合适的选择,使用它们可能会导致未来的问题。
如果您没有看到 transforms-excel-parser-bundle 作为选项,请联系您的 Palantir 代表进行安装。
2. 添加依赖到 build.gradle
将最新可用版本添加到您的 transforms-java/build.gradle 文件中,如下所示。
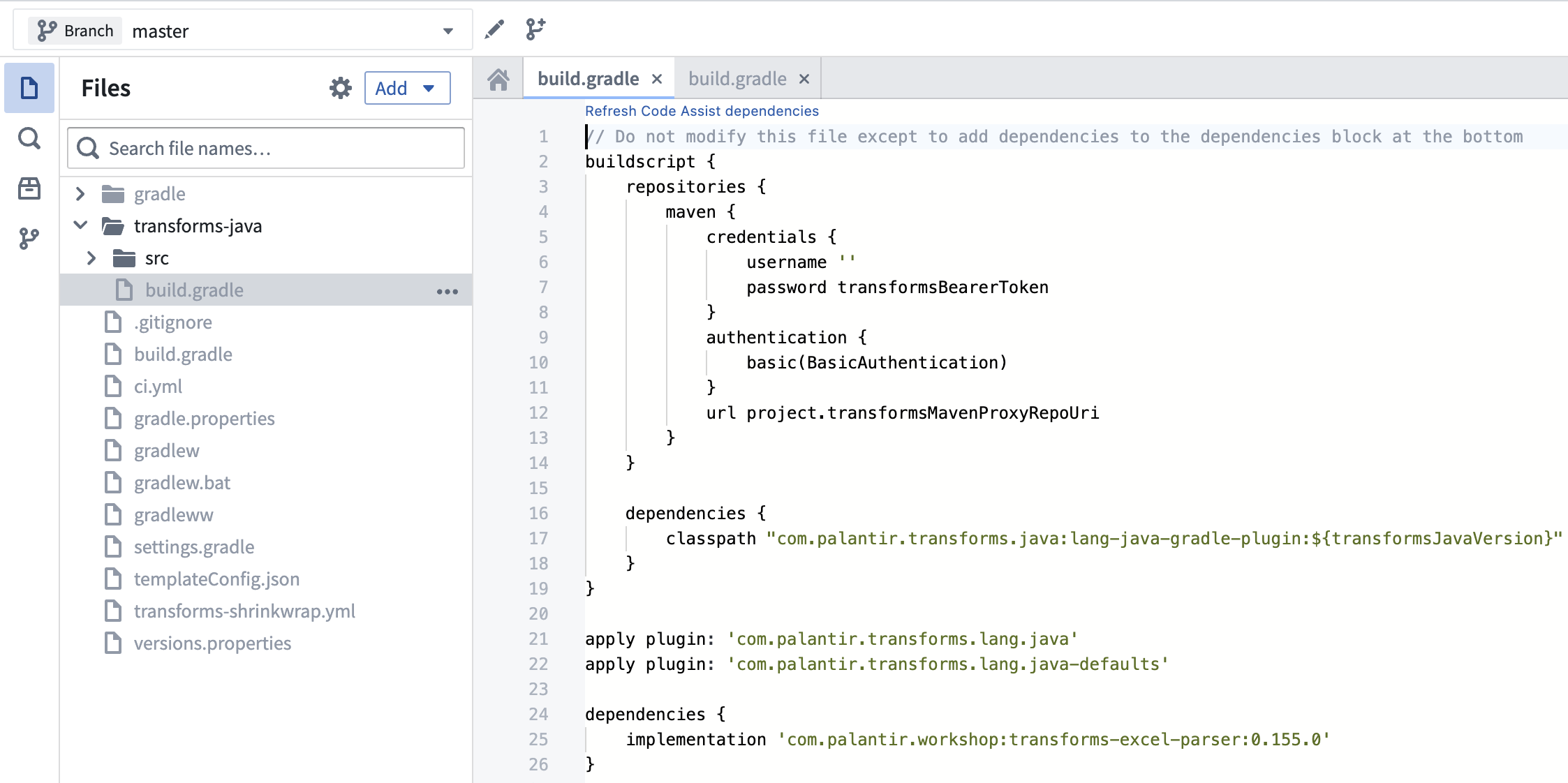
transforms-java/build.gradle 是一个隐藏文件,因此您需要切换 显示隐藏文件 设置才能看到它。
API 文档
有关详细的 API 文档,下载 javadoc 存档,解压缩并在网络浏览器中查看包含的 HTML 文件。
阅读 javadoc 时,最好的起始位置是 com/palantir/transforms/excel/package-summary.html。
已知问题和注意事项
支持的文件类型
当前支持以下文件格式:
- xls
- xlt
- xltm
- xltx
- xlsx
- xlsm
请注意,xlsb 文件当前不受支持。
代码助手预览不稳定
运行代码助手预览时,您可能会发现一个问题,即工作区启动后的首次运行成功,而第二次运行失败,并出现类似如下的出错:
// 该异常信息表示在Java程序中发生了类转换异常。
// java.lang.ClassCastException: 表示程序试图将一个对象强制转换为它不支持的类。
// 错误信息指出 com.palantir.transforms.excel.KeyedParsedRecord 类在两个不同的模块加载器中被加载,
// 这些模块加载器分别是 java.net.URLClassLoader @5a5d825a 和 java.net.URLClassLoader @53dafc50。
// 由于这两个类加载器不相同,导致了类型不匹配的情况,尽管类名相同,但它们在JVM中被认为是不同的类。
// 解决方案通常包括确保类只在一个类加载器中加载,或者检查类路径配置以避免重复加载。
此问题仅限于代码助手预览功能,并不会在搭建时导致问题。 刷新您的浏览器窗口应允许您再次预览,而无需执行完整的代码助手工作区重建。
内存需求
Apache POI 库以其高内存消耗而闻名,这意味着即使是相对较小的 Excel 文件在打开时也会导致相当大的内存占用。因此,默认的变换 Spark 配置通常提供的内存不足以容纳内存中的 Object。内存不足可能导致以下问题:
- 变换任务失败,并出现类似
Spark module '{module_rid}' died while job '{job_rid}' was using it的出错。 - 变换任务长时间停滞,既未成功也未失败。
判断任务是否停滞的一个粗略指南是处理单个文件是否需要超过 10 分钟,因为在内存充足的情况下,一个非常大的 Excel 文件可能需要大约 8 分钟处理。请注意,一个 Spark 任务可以处理多个输入文件,因此应用此规则时并不总是简单直接。
无论内存不足的症状是任务失败还是任务停滞,建议通过切换到每个任务提供更多内存的 Spark 配置文件 组合来解决问题,例如 EXECUTOR_MEMORY_LARGE 和 EXECUTOR_CORES_EXTRA_SMALL。
使用示例
简单的表格 Excel 文件
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49package myproject.datasets; import com.palantir.transforms.excel.ParseResult; import com.palantir.transforms.excel.Parser; import com.palantir.transforms.excel.TransformsExcelParser; import com.palantir.transforms.excel.table.SimpleHeaderExtractor; import com.palantir.transforms.excel.table.TableParser; import com.palantir.transforms.lang.java.api.Compute; import com.palantir.transforms.lang.java.api.FoundryInput; import com.palantir.transforms.lang.java.api.FoundryOutput; import com.palantir.transforms.lang.java.api.Input; import com.palantir.transforms.lang.java.api.Output; import java.util.Optional; import org.apache.spark.sql.Dataset; import org.apache.spark.sql.Row; public final class SimpleTabularExcel { @Compute public void myComputeFunction( @Input("<input_dataset_rid>") FoundryInput myInput, @Output("<output_dataset_rid>") FoundryOutput myOutput, @Output("<error_output_dataset_rid>") FoundryOutput errorOutput ) { // 创建一个 TableParser,并配置一个 SimpleHeaderExtractor // 在这个例子中,文件的表头在第二行。 // 如果表头在第一行,我们不需要指定 rowsToSkip, // 因为默认值是 0,事实上我们可以直接调用 TableParser.builder().build()。 Parser tableParser = TableParser.builder() .headerExtractor( SimpleHeaderExtractor.builder().rowsToSkip(1).build()) .build(); // 使用 TableParser 创建一个 TransformsExcelParser TransformsExcelParser transformsParser = TransformsExcelParser.of(tableParser); // 解析输入数据 ParseResult result = transformsParser.parse(myInput.asFiles().getFileSystem().filesAsDataset()); // 获取解析后的数据,如果输入没有行或者发生错误,可能为空 Optional<Dataset<Row>> maybeDf = result.singleResult(); // 如果解析后的数据不为空,将其写入输出数据集 maybeDf.ifPresent(df -> myOutput.getDataFrameWriter(df).write()); // 将错误信息写入错误输出数据集 errorOutput.getDataFrameWriter(result.errorDataframe()).write(); }
此代码实现了一个 Java 类 SimpleTabularExcel,用于解析 Excel 文件并将结果写入指定的数据集。代码中使用了 Palantir 的库进行 Excel 文件解析,并且使用了 Apache Spark 的 Dataset 来处理数据。解析过程中,如果文件没有数据或解析出错,会将错误信息写入错误输出数据集。
具有复杂多行标题的表格 Excel 文件
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49package myproject.datasets; import com.palantir.transforms.excel.ParseResult; import com.palantir.transforms.excel.Parser; import com.palantir.transforms.excel.TransformsExcelParser; import com.palantir.transforms.excel.table.MultilayerMergedHeaderExtractor; import com.palantir.transforms.excel.table.TableParser; import com.palantir.transforms.lang.java.api.Compute; import com.palantir.transforms.lang.java.api.FoundryInput; import com.palantir.transforms.lang.java.api.FoundryOutput; import com.palantir.transforms.lang.java.api.Input; import com.palantir.transforms.lang.java.api.Output; import java.util.Optional; import org.apache.spark.sql.Dataset; import org.apache.spark.sql.Row; public final class ComplexHeaderExcel { @Compute public void myComputeFunction( @Input("<input_dataset_rid>") FoundryInput myInput, @Output("<output_dataset_rid>") FoundryOutput myOutput, @Output("<error_output_dataset_rid>") FoundryOutput errorOutput ) { // 创建一个带有MultilayerMergedHeaderExtractor的TableParser Parser tableParser = TableParser.builder() .headerExtractor(MultilayerMergedHeaderExtractor.builder() .topLeftCellName("A1") .bottomRightCellName("D2") .build()) .build(); // 使用TableParser创建一个TransformsExcelParser TransformsExcelParser transformsParser = TransformsExcelParser.of(tableParser); // 解析输入 ParseResult result = transformsParser.parse(myInput.asFiles().getFileSystem().filesAsDataset()); // 获取解析后的数据,如果输入中没有行或发生错误,可能为空 Optional<Dataset<Row>> maybeDf = result.singleResult(); // 如果解析后的数据不为空,将其写入输出数据集 maybeDf.ifPresent(df -> myOutput.getDataFrameWriter(df).write()); // 将错误信息写入错误输出 errorOutput.getDataFrameWriter(result.errorDataframe()).write(); } }
这里的代码是一个Java类,用于处理Excel文件的复杂表头。代码使用Palantir Foundry的API读取Excel文件,解析其内容,并将结果写入输出数据集。同时,还将任何解析错误写入错误输出。主要步骤包括创建一个TableParser来处理多层合并表头,使用该解析器解析输入数据,检查解析结果是否为空,并分别处理正常数据和错误数据。
包含表单的Excel文件
在此示例中,我们注册了多个FormParser实例,但也可以注册FormParser和TableParser实例的组合,这在包含表格元素的复杂表单中是一种常见模式(可以在同一工作表内或跨工作表)。
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71package myproject.datasets; import com.palantir.transforms.excel.TransformsExcelParser; import com.palantir.transforms.excel.ParseResult; import com.palantir.transforms.excel.Parser; import com.palantir.transforms.excel.form.FieldSpec; import com.palantir.transforms.excel.form.FormParser; import com.palantir.transforms.excel.form.Location; import com.palantir.transforms.excel.form.cellvalue.AdjacentCellAssertion; import com.palantir.transforms.excel.form.cellvalue.CellValue; import com.palantir.transforms.excel.functions.RegexSubstringMatchingSheetSelector; import com.palantir.transforms.lang.java.api.Compute; import com.palantir.transforms.lang.java.api.FoundryInput; import com.palantir.transforms.lang.java.api.FoundryOutput; import com.palantir.transforms.lang.java.api.Input; import com.palantir.transforms.lang.java.api.Output; public final class FormStyleExcel { private static final String FORM_A_KEY = "FORM_A"; private static final String FORM_B_KEY = "FORM_B"; @Compute public void myComputeFunction( @Input("<input_dataset_rid") FoundryInput myInput, @Output("<form_a_output_dataset_rid>") FoundryOutput formAOutput, @Output("<form_b_output_dataset_rid>") FoundryOutput formBOutput, @Output("<error_output_dataset_rid>") FoundryOutput errorOutput) { // Form A 解析器配置 Parser formAParser = FormParser.builder() .sheetSelector(new RegexSubstringMatchingSheetSelector("Form_A")) // 使用正则表达式选择表单A的工作表 .addFieldSpecs(createFieldSpec("form_a_field_1", "B1")) // 添加字段规范 .addFieldSpecs(createFieldSpec("form_a_field_2", "B2")) .build(); // Form B 解析器配置 Parser formBParser = FormParser.builder() .sheetSelector(new RegexSubstringMatchingSheetSelector("Form_B")) // 使用正则表达式选择表单B的工作表 .addFieldSpecs(createFieldSpec("form_b_field_1", "B1")) // 添加字段规范 .addFieldSpecs(createFieldSpec("form_b_field_2", "B2")) .build(); // 创建包含Form A和Form B解析器的TransformsExcelParser TransformsExcelParser transformsParser = TransformsExcelParser.builder() .putKeyToParser(FORM_A_KEY, formAParser) // 将Form A解析器与键关联 .putKeyToParser(FORM_B_KEY, formBParser) // 将Form B解析器与键关联 .build(); // 解析输入 ParseResult result = transformsParser.parse(myInput.asFiles().getFileSystem().filesAsDataset()); // 将解析的数据写入输出数据集 result.dataframeForKey(FORM_A_KEY) .ifPresent(df -> formAOutput.getDataFrameWriter(df).write()); // 如果存在则写入Form A的数据 result.dataframeForKey(FORM_B_KEY) .ifPresent(df -> formBOutput.getDataFrameWriter(df).write()); // 如果存在则写入Form B的数据 // 将错误信息写入错误输出 errorOutput.getDataFrameWriter(result.errorDataframe()).write(); } // 辅助方法,用于简洁地创建带有适当断言的FieldSpec private static FieldSpec createFieldSpec(String fieldName, String cellLocation) { return FieldSpec.of( fieldName, CellValue.builder() .addAssertions(AdjacentCellAssertion.left(1, fieldName)) // 添加相邻单元格断言 .location(Location.of(cellLocation)) // 设置单元格位置 .build()); } }
多输出的增量处理
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57package myproject.datasets; import com.palantir.transforms.excel.ParseResult; import com.palantir.transforms.excel.Parser; import com.palantir.transforms.excel.TransformsExcelParser; import com.palantir.transforms.excel.functions.RegexSubstringMatchingSheetSelector; import com.palantir.transforms.excel.table.CaseNormalizationOption; import com.palantir.transforms.excel.table.SimpleHeaderExtractor; import com.palantir.transforms.excel.table.TableParser; import com.palantir.transforms.excel.utils.IncrementalUtils; import com.palantir.transforms.lang.java.api.*; public final class IncrementalTransform { @Compute public void myComputeFunction( @Input("<input_dataset_rid>") FoundryInput myInput, @Output("<sheet_1_output_dataset_rid>") FoundryOutput sheet1Output, @Output("<sheet_2_output_dataset_rid>") FoundryOutput sheet2Output) { // 定义解析器 // 指定CONVERT_TO_LOWERCASE或CONVERT_TO_UPPERCASE对于CaseNormalizationOption特别重要, // 以避免在增量处理过程中由于输入文件在不同增量批次之间大小写不一致而导致的细微问题。 Parser sheet1Parser = TableParser.builder() .headerExtractor(SimpleHeaderExtractor.builder() .caseNormalizationOption(CaseNormalizationOption.CONVERT_TO_LOWERCASE).build()) .sheetSelector(new RegexSubstringMatchingSheetSelector("Sheet1")).build(); Parser sheet2Parser = TableParser.builder() .headerExtractor(SimpleHeaderExtractor.builder() .caseNormalizationOption(CaseNormalizationOption.CONVERT_TO_LOWERCASE).build()) .sheetSelector(new RegexSubstringMatchingSheetSelector("Sheet2")).build(); TransformsExcelParser transformsParser = TransformsExcelParser.builder().putKeyToParser("Sheet1", sheet1Parser) .putKeyToParser("Sheet2", sheet2Parser).build(); // 解析数据 FoundryFiles foundryFiles = myInput.asFiles(); ParseResult result = transformsParser.parse(foundryFiles.getFileSystem(ReadRange.UNPROCESSED).filesAsDataset()); // 检查错误并快速失败 // 特别是在增量处理中,通常最好快速失败,而不是将错误数据帧写入单独的输出并异步检查。 // 如果快速失败不是一个选项,并且您采用“将错误数据帧写入单独输出”的方法, // 请注意,您需要①重新上传输入数据集中解析错误的文件,或②通过手动虚拟交易强制触发该转换的快照构建 // 在其中一个输出数据集上,以便重新处理解析错误的文件。 if (result.errorDataframe().count() > 1) { throw new RuntimeException("Errors: " + result.errorDataframe().collectAsList().toString()); } // 将解析的数据通过APPEND事务增量写入输出,如果不可能则使用合并替换的SNAPSHOT事务 // 以下实现假设在给定增量批次文件中一部分解析器没有找到数据是正常且预期的。 // 如果不是这种情况,您可能希望在数据帧子集缺失且输入中有非零数量未处理文件时引发异常。 // 缺失结果不一定意味着错误数据帧中会有错误(例如,SheetSelector返回一个空的sheet集合不被认为是错误)。 FilesModificationType filesModificationType = foundryFiles.modificationType(); result.dataframeForKey("Sheet1").ifPresent( dataframe -> IncrementalUtils.writeAppendingIfPossible(filesModificationType, dataframe, sheet1Output)); result.dataframeForKey("Sheet2").ifPresent( dataframe -> IncrementalUtils.writeAppendingIfPossible(filesModificationType, dataframe, sheet2Output)); } }