注意:以下翻译的准确性尚未经过验证。这是使用 AIP ↗ 从原始英文文本进行的机器翻译。
3. 教程 - 在建模目标应用中评估模型
在开始本教程之前,您应该已经完成了建模项目设置并在Jupyter®笔记本或代码库中训练了一个模型;此时,您应该在您的建模目标中至少有一个模型。
在本教程的这个步骤中,我们将评估我们的模型性能并在建模目标中发布该模型。此步骤是推荐的,但不会影响本教程的后续步骤,您可以稍后返回执行。内容包括:
3.1 什么是建模目标?
建模目标可以被视为潜在生产模型版本的目录。向目标提交模型会将模型添加到该目录中,并使其可以在特定建模问题或目标的上下文中进行评估和审查。每个模型提交,无论最终是否投入生产,都会帮助跟踪建模项目的进展,并维护项目空间周围的实验和学习历史。
本教程的这一步骤没有必需的操作。
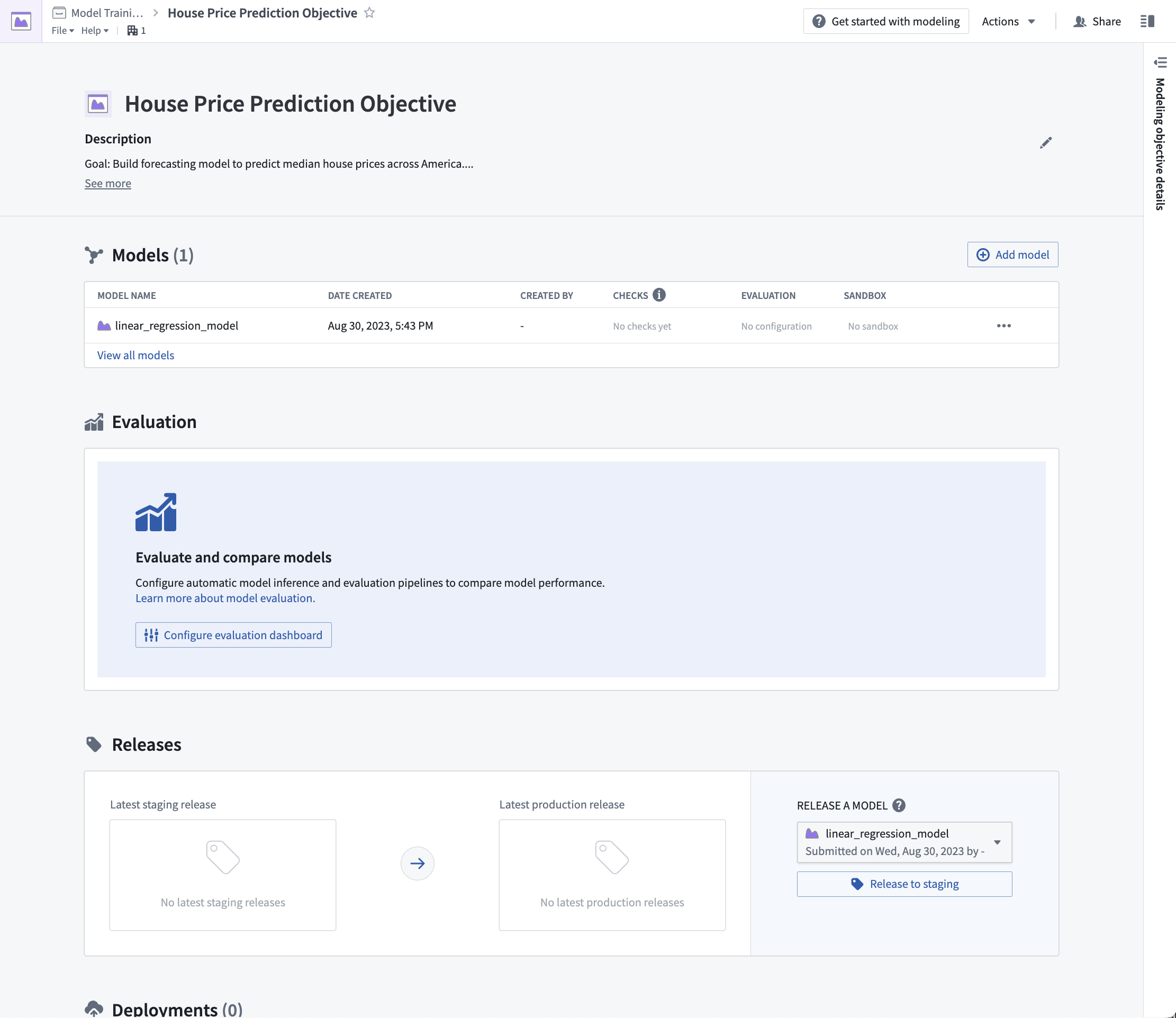
3.2 如何配置自动模型评估
现在我们在我们的建模目标中有一个模型候选,我们可以通过在此建模目标中生成模型性能指标来评估该模型的表现。性能指标是理解模型表现如何以及模型行为原因的重要工具。
由于本教程的目标是估计一个数字(美国人口普查区的平均房价),我们的建模问题可以归类为回归建模问题。对于回归建模问题,通常会查看评估指标,例如平均绝对误差、均方根误差。这些指标以及其他指标包含在Foundry的默认回归评估器中,因此,我们将使用该库来评估我们的模型提交的性能。
操作: 从建模目标中,选择配置评估仪表盘。


配置模型评估
自动模型评估是一种确保模型以标准化方式进行评估的有用方法。标准化确保了一致的模型比较,并允许您自信地选择哪个模型最适合用于生产。
如果启用了评估管道管理;Foundry将自动为每个模型提交和评估数据集的组合生成一个推理数据集。推理数据集是针对评估数据集运行推理(生成预测)的结果。评估数据集由用户定义为模型的标准测试集,并需要特征(用于生成预测)和标签(用于将模型推理与真实标签进行比较)。
操作: 要配置管道管理,请选择编辑,然后选择以下两个选项:生成推理和指标管道和在模型提交时自动运行推理和指标。然后,保存以确认您的管道管理设置。

操作: 要配置评估数据集,选择添加评估数据集,然后选择您在模型训练教程中创建的**housing_test_data数据集作为您的评估数据集。选择您的data文件夹作为推理目标和指标目标。通过选择选择数据集和文件夹**确认您的选择。

配置评估库
评估库是一个可参数化的Foundry库,可用于获取推理数据集并生成将被添加到建模目标中评估仪表盘的评估指标。Foundry带有默认的回归和二元分类评估库,但也可以为您的特定建模问题创建自定义评估库。
要评估添加到此建模目标的所有模型,所有模型提交必须一致地产生它们的评估分数。在此建模目标中,我们期望所有模型生成一个名为prediction且为float类型的推理列。
操作: 选择选择评估库,然后选择回归默认库。将inference_field配置为类型为float的prediction,将actual_field(我们试图估计的属性)配置为median_house_value并保持histogram_bins为空。保存以保存评估库配置。

配置评估子集
设置评估子集是模型评估中的一个非必填步骤,允许您独立为评估数据的特定部分生成指标。这些指标可以在评估仪表盘中单独进行分析。
您可能希望启用评估子集的情况:
- 您希望了解数据中模型表现优于其他部分的部分。这可以指示该模型应在生产中使用的界限。
- 您希望了解模型表现不佳的区域,以便您可以集中未来的开发工作。
- 您希望确保您的模型在评估数据中对受保护群体没有偏见。
在这种情况下,我们将检查模型在平均房龄小于5年或大于30年时的表现。
操作: 选择添加评估子集,然后选择housing_median_age字段。由于这是一个数值字段,我们可以定义要使用的定量分桶策略。在此示例中,我们将使用范围切断,桶为5和30。操作: 保存子集配置。

此子集配置将在每个评估数据集上评估四个不同的数据集。
Overall:这是整个评估数据集。housing_median_age (<5):评估数据集筛选为housing_median_age小于5的部分。housing_median_age (>= 5, < 30):评估数据集筛选为housing_median_age大于或等于5但小于30的部分。housing_median_age (>= 30):评估数据集筛选为housing_median_age大于或等于30的部分。
这将允许我们确定模型在housing_median_age不同的记录上的行为是否一致。
操作: 选择页面右上角的保存配置以保存并返回到评估仪表盘。从现在开始,您提交到此目标的任何模型都将自动生成并搭建推理和指标数据集,以便您评估您的模型。

3.3 如何搭建指标管道
配置指标管道后,每次您向此建模目标提交模型时,都会创建和启动一个推理数据集和指标数据集。如果配置为这样做,Foundry还将自动运行这些数据集并将指标添加到您的建模目标中的评估仪表盘。
在这种情况下,由于我们已经将模型添加到此目标中,我们需要手动启动这些数据集的搭建。
操作: 在评估仪表盘的右上角选择搭建评估,然后选择housing_test_data作为评估仪表盘和linear_regression_model作为要评估的模型。然后,搭建以开始推理和指标搭建。
您的评估管道可能需要几分钟才能创建;您可能需要等待直到搭建操作变为可用。

一旦您的搭建开始,您可以通过查看评估仪表盘右上角的最近搭建下拉菜单来查看这些搭建的进度。
根据您的Foundry实例的负载,运行评估管道可能需要几分钟。

3.4 如何在评估仪表盘中评估模型
在继续本教程之前,您的评估仪表盘应该已经成功完成了您之前创建的推理和指标数据集的搭建。指标完成后,您将能够查看和比较您添加到此建模目标中的所有模型的指标。这为您的建模项目的性能创建了一个集中的来源。
在回归评估库中,我们生成了一系列可在评估仪表盘中查看的指标。这些指标使我们了解我们的模型在预测标签(人口普查区的中位数房价)方面在未见过的测试数据上的准确程度。
确定使用哪些指标和什么是足够的性能将因项目而异。这个过程通常需要与利益相关者讨论,但对于我们的虚构示例,我们将认为该模型的表现足够好。在这种情况下,82639.10的均方根误差意味着,平均而言,模型预测与我们未见过的测试数据中的标签相差82639.10美元。
操作: 刷新页面,在左侧栏的数据集选择器中选择**housing_test_dataset数据集**,然后从模型选择器中选择linear_regression_model。

评估仪表盘还向我们展示了我们之前定义的子集的模型性能。我们的评估仪表盘中的标签反映了我们可以查看指标的可用子集组。在这种情况下,我们可以看到我们的模型在中位数房龄在5到30岁之间时表现最佳。
操作: 在评估仪表盘的顶部选择housing_median_age标签。

下一步
现在我们已经评估了我们的机器学习模型,我们可以将此模型集成到生产应用中。查看如何将模型投入生产的教程。