注意:以下翻译的准确性尚未经过验证。这是使用 AIP ↗ 从原始英文文本进行的机器翻译。
1. 教程 - 在 Foundry 中设置机器学习项目
在本教程的这一步中,您将在 Foundry 中创建一个机器学习项目。这是必需的步骤,将涵盖:
1.1 如何构建用于机器学习的 Foundry 项目结构
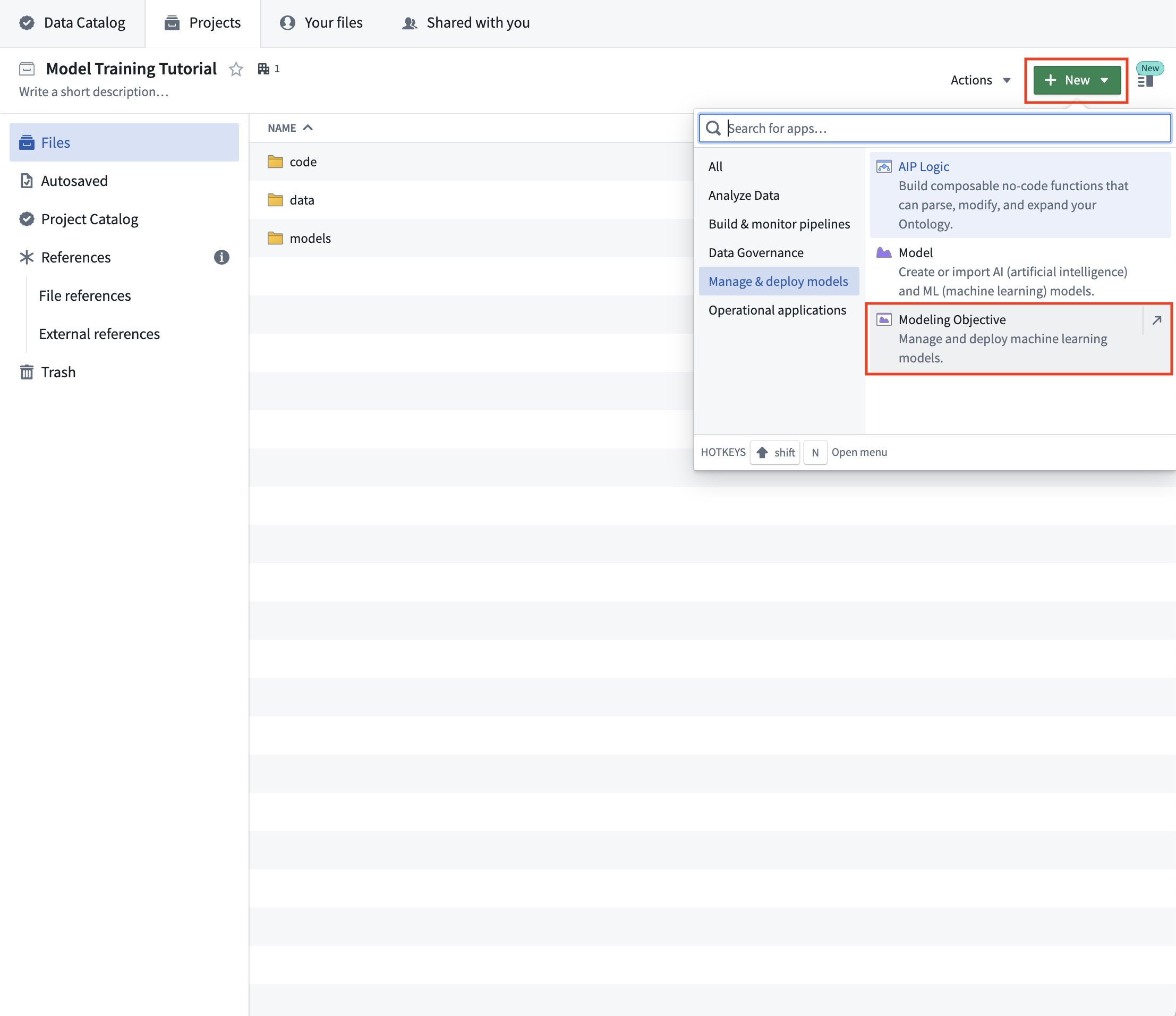
Foundry 项目是用于存储相关工作的文件夹结构。我们建议为每个机器学习项目创建一个独立的 Foundry 项目。该项目应包括:
- 一个用于存储此项目中使用的数据集的
data文件夹, - 一个用于存储此项目中的模型的
models文件夹, - 一个用于存储此项目中使用的模型训练逻辑的
code文件夹,以及, - 一个用于管理和部署生产模型的建模目标。
如果您没有创建新项目的权限,可以在现有项目中创建一个新文件夹作为您的机器学习项目的根目录。
操作: 为本教程创建一个新的 Foundry 项目并创建上述文件夹 - 查看如何创建。如果您无法创建新的 Foundry 项目,请在现有项目中创建一个空文件夹以模拟新项目的根目录。
操作: 在您的 Foundry 项目中,选择 +新建 > 建模目标。建模目标的命名应与您尝试解决的机器学习问题相关。在本例中,将目标命名为“房价预测目标”。
完成的项目结构
1.2 如何管理机器学习的数据
在本教程中,我们将搭建一个机器学习模型来估计美国人口普查区域的房价中位数。
我们将获取特征数据(关于美国人口普查区域的历史详细信息)和标签(该人口普查区域在那时的房价中位数)以揭示特征和标签之间的关系,然后将该关系保存为 Foundry 中的可重用模型。未来,当我们拥有最新特征数据(关于某个人口普查区域的详细信息)但没有最新标签(房价中位数)时,我们可以将模型应用于该人口普查区域的特征数据,以估算该人口普查区域的房价。这种类型的机器学习项目称为监督机器学习,是最常见的机器学习项目类型。
在 Foundry 中,一个监督机器学习项目应具有两个数据集:
- 一个 标注数据集,可用于模型训练和测试,以及,
- 一个 未标注数据集,包含最新特征但没有标签。我们将在此数据集上应用模型以生成推断(我们标签的预测)。
这些数据集通常来自生产源的数据连接或您的Ontology。但是,对于本教程,我们将上传 CSV 文件来模拟这些生产源。
操作: 下载 标注的美国住房数据源 并将其上传到 data 文件夹中,命名为 housing_features_and_labels。下载 未标注的美国人口普查数据源 并上传到 data 文件夹中,命名为 housing_inference_data。您可以通过将 CSV 文件拖入文件夹结构中来将其上传到 Foundry - 对于本教程,上传为结构化数据集。
完成的数据文件夹

1.3 如何管理机器学习模型
在 Foundry 中训练的模型链接到用于训练它们的数据、代码和开发环境。这很有用,因为它提供了一个关于所有模型如何生成的治理记录,以及记录和分享历史实验的详细信息。
机器学习模型可以在 Foundry 的代码库应用程序中进行训练。
代码库
代码库应用程序是一个用于编写数据管道和机器学习逻辑的基于网络的开发环境。Foundry 提供了一个用于机器学习的模板库,称为 Model Training 模板。
代码库支持 Git 以进行本地代码迭代,但需要提交的代码才能在 Foundry 内运行搭建。代码库应用程序最适合用于编写生产和可重复的数据管道和机器学习逻辑。
集成现有模型
如果您已经有一个想在 Foundry 中使用的模型,您可以通过以下方式集成该现有模型:
Foundry 还提供了一些可以通过建模目标应用程序导入的开源语言模型。
本教程步骤中无需执行操作。
1.4 如何管理机器学习项目
在 Foundry 中,机器学习项目通过建模目标应用程序进行管理。建模目标通过以下方式提供管理机器学习项目的最佳实践:
- 围绕特定问题定位机器学习项目
- 创建系统化模型评估的标准
- 在生产使用前启用模型的多方审查
- 维护所有用于生产的模型的历史记录
- 将模型开发与批处理管道或实时托管推理的部署集成
在本教程中,建模目标是预测人口普查区域的房价中位数。
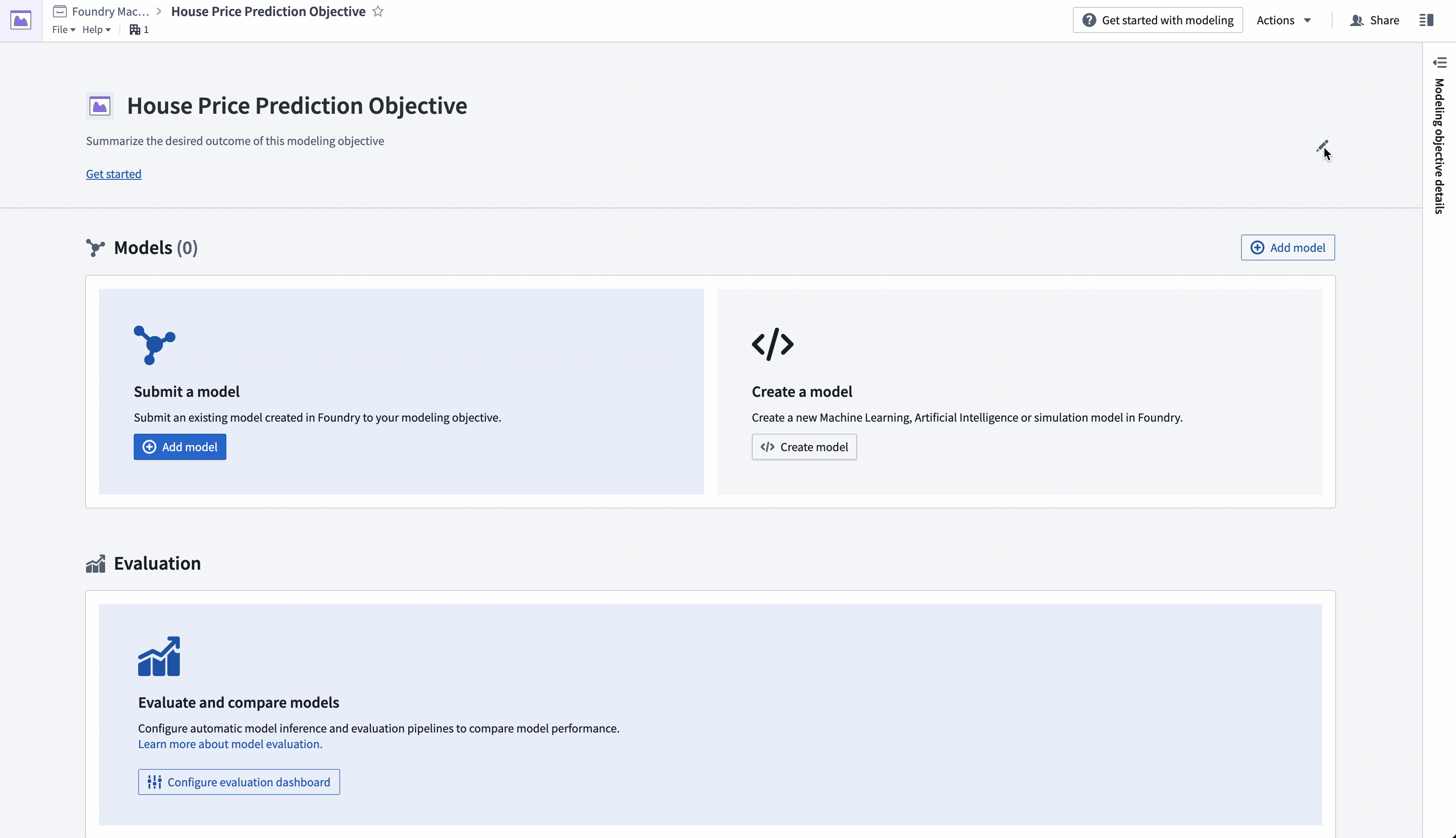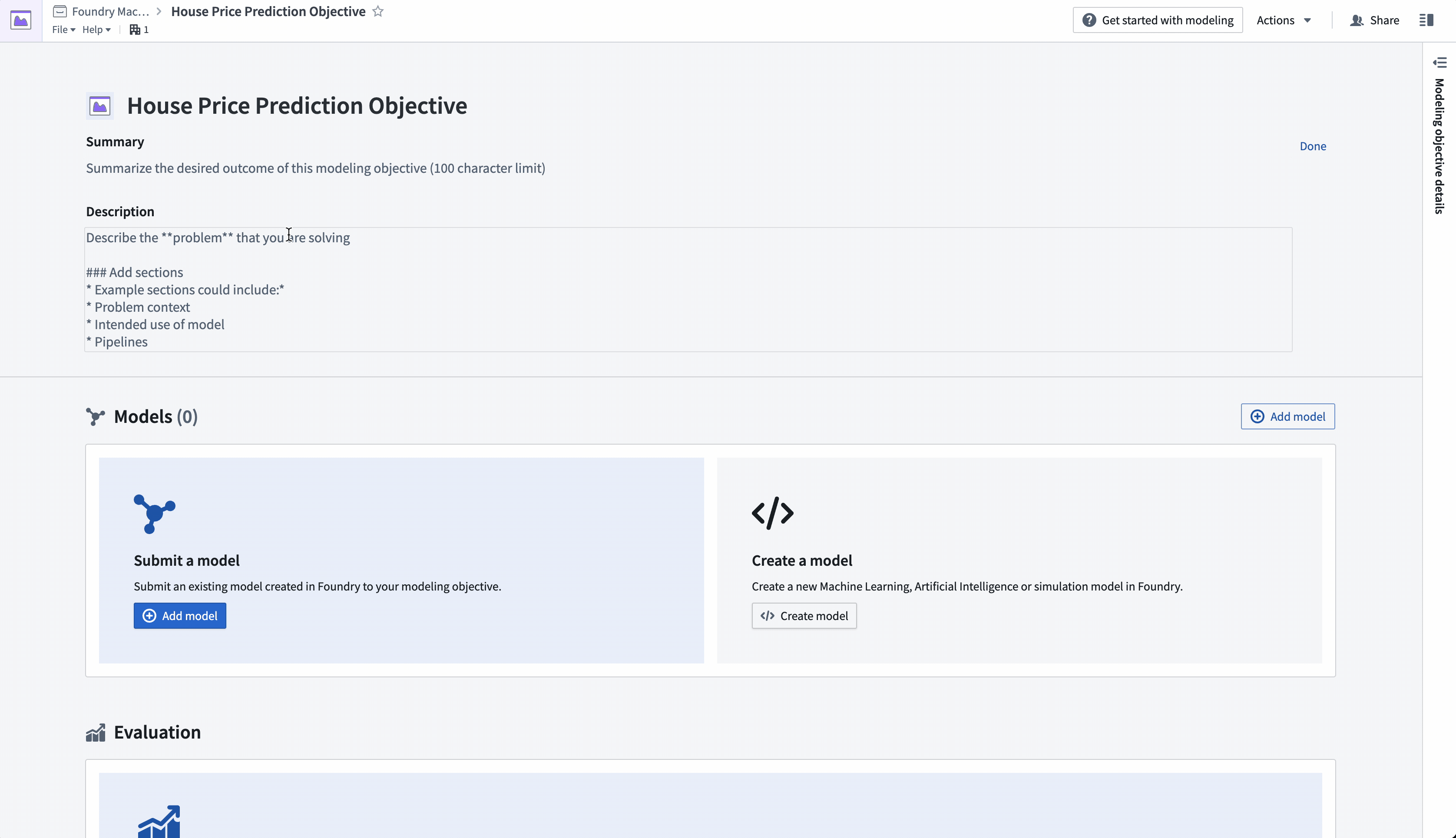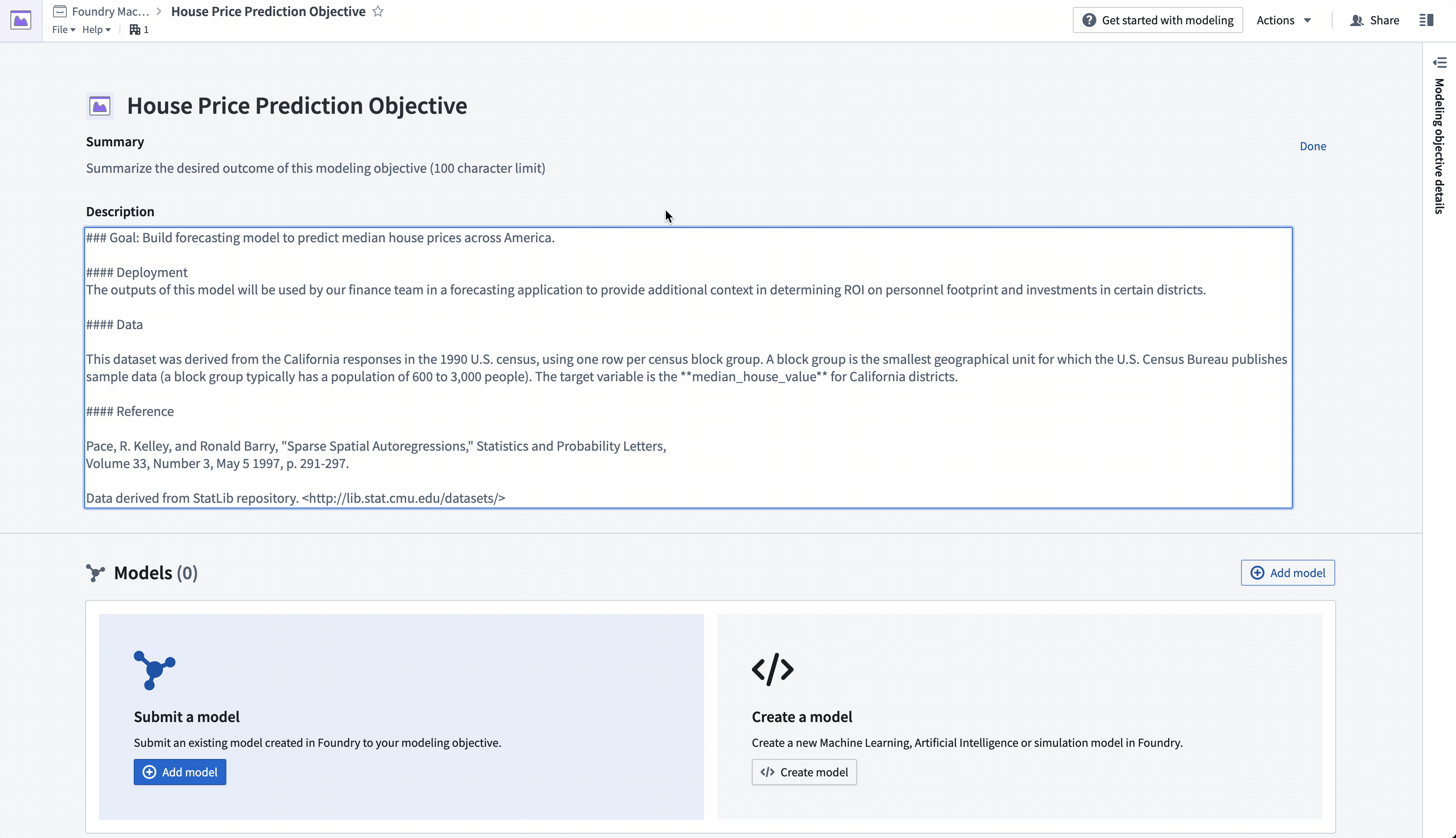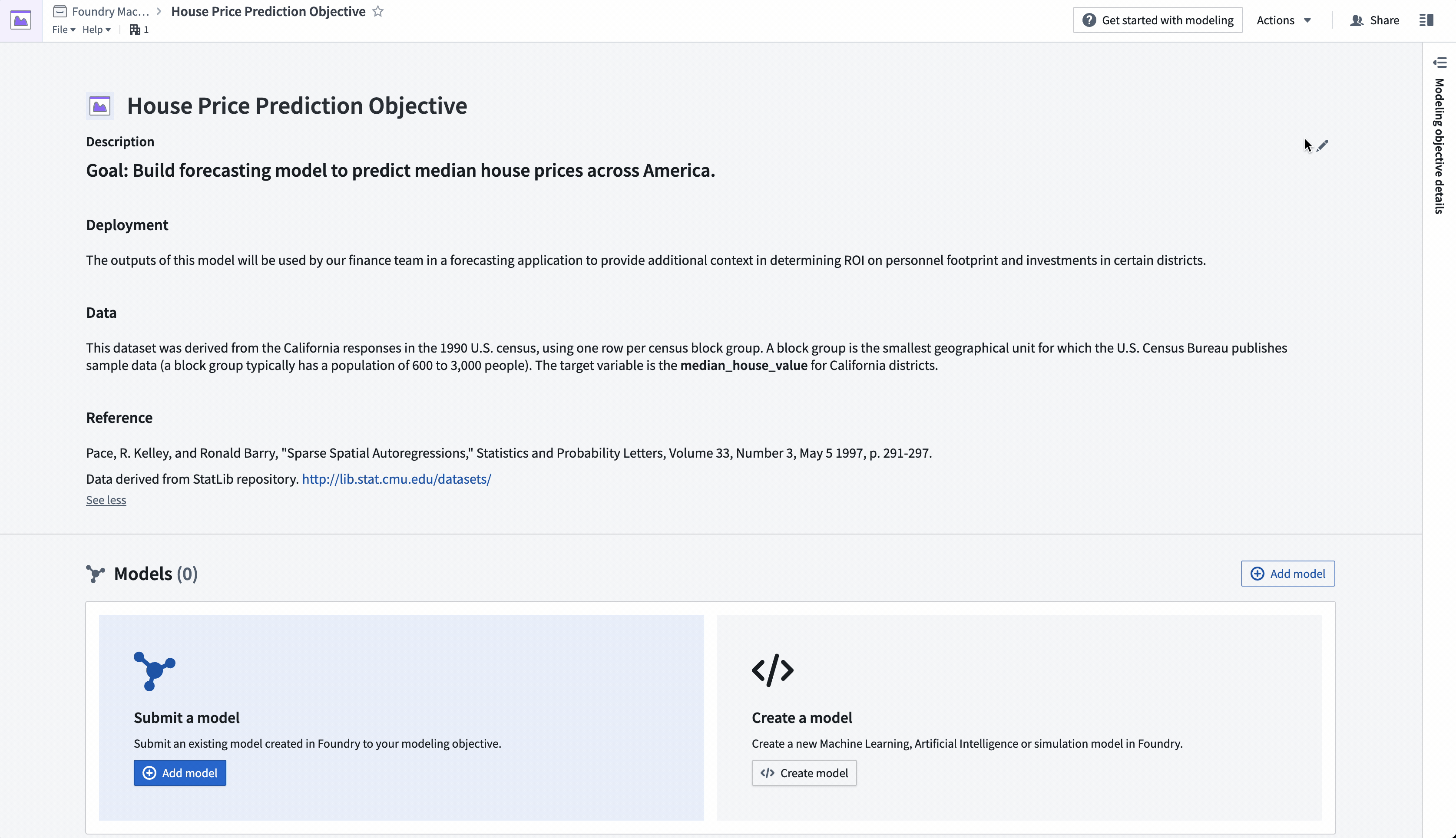
操作: 导航到之前创建的“房价预测目标”建模目标。在建模目标的标题部分添加项目上下文以描述问题给其他团队。选择标题右侧的笔图标进入编辑模式,并为您的目标添加摘要和描述。描述字段支持 Markdown。以下是建议内容的示例:
#### 目标:构建预测模型以预测全美各地的房价中位数。
#### 数据
该数据集取自1990年美国人口普查中的加利福尼亚州的响应数据,每行代表一个普查块组。普查块组是美国人口普查局发布样本数据的最小地理单位(一个普查块组通常有600到3000人)。
目标变量是加利福尼亚州各地区的 **median_house_value**(房价中位数)。
#### 参考文献
Pace, R. Kelley, 和 Ronald Barry, "Sparse Spatial Autoregressions," 《统计与概率通讯》,
第33卷, 第3期, 1997年5月5日, 第291-297页。
数据来源于StatLib存储库。<http://lib.stat.cmu.edu/datasets/>
下一步
现在我们已经构建了机器学习项目的结构,我们将进入模型训练。在本教程中,您的下一步是选择在Jupyter®笔记本中训练模型或在代码仓库中训练模型。Jupyter®笔记本推荐用于快速和迭代的模型开发,而代码仓库推荐用于生产级数据和模型管道。