注意:以下翻译的准确性尚未经过验证。这是使用 AIP ↗ 从原始英文文本进行的机器翻译。
调试失败的管道
快速调试和解决管道问题的能力是管道维护工作的重要组成部分。这确保了支持重要组织工作流的生产管道保持可靠和有意义。
本页面提供了一个框架,您可以以此为基础制定标准操作程序(SOP),当您在值班轮换期间作为管道维护员收到健康检查失败通知时使用。
先决知识
本页面假设您熟悉各种Foundry工具和工作流。相关部分将提供链接:
还假设您的管道维护团队记录了一个事件日志或其他文档,用于记录管道中反复出现的问题。这是一个最佳实践,如果当前没有这样的文档,应当实施。
调试框架概述
始终按照以下三个问题的顺序进行询问:
- 缓解措施: 我能否尽快缓解这个问题?一些示例包括:
- 重建调度。我们建议重建调度而不是单个数据集或失败的任务,因为这将出现在您的调度历史记录中。调度历史记录允许您跟踪管道的历史,而不是单个数据集的历史。
- 如果排队过多,寻找并取消重叠或密集的调度。
- 如果手动上传出错,将事务恢复到已知的稳定版本。
- 分类: 问题属于哪一类?
- 我们分类问题的原因是为了帮助识别根本原因,并确定解决方案是否需要其他团队的参与。
- 有关如何思考问题类别并识别它们的更多详细信息,请参见下文。
- 更广泛的影响: 这个问题是否可能影响平台的其他部分?
阅读您的管道文档!也许这个问题以前已经解决过。或者在缓解过程中可能有警告。例如,某些搭建可能非常昂贵,并可能影响在高峰使用时间段内的环境性能。这类细节应该为您的整个团队记录良好。
问题类别分类
在尝试缓解问题后,作为管道维护员,您需要深入了解和解决根本原因。分类问题在调试过程中有帮助,因为它帮助我们识别根本原因,最重要的是,帮助您快速识别是否可以自行修复问题,或者是否需要联系其他团队。
问题分为三类:
- 上游问题: 与其他人管理的基础设施或制品相关
- Foundry之外: 上游数据源的问题
- Foundry之内: 由管道上游的数据集/项目引起的问题
- 平台问题: 由Foundry平台服务未按预期工作引起的问题。
- 更改: 在您负责监控的管道范围内 发生的任何更改。这是最常见的问题类别,通常由用户更改引起。一些示例包括:
- 代码更改
- 调度更改
- 管道中的数据量增加
按问题类别解决问题的步骤:
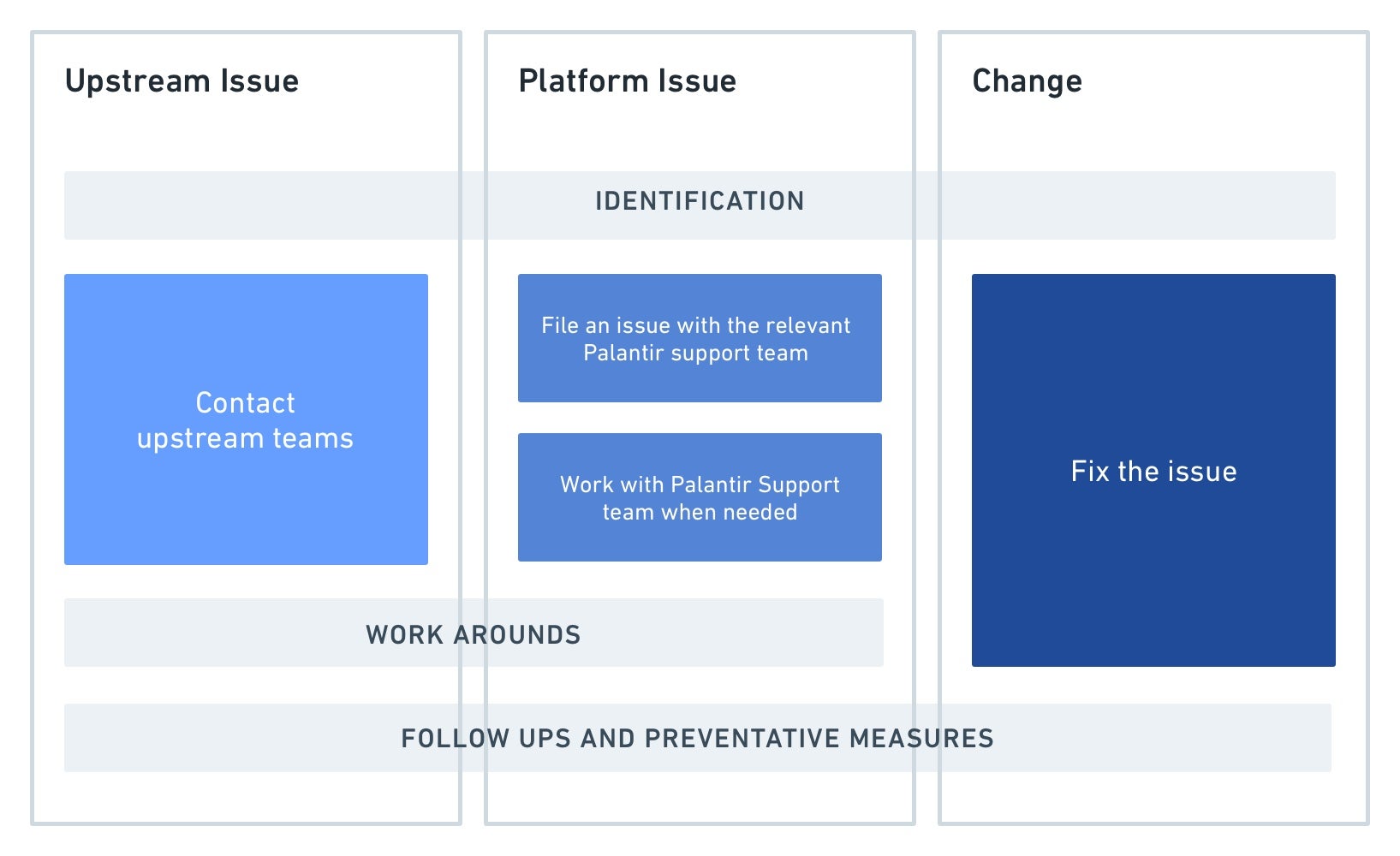
详细来说,上述步骤是:
-
识别: 在执行上述步骤时,重要的是非常精确地识别出什么是出错的。回答以下问题:
- 问题何时开始?
- 在管道的哪一步出现了失败?
- 哪些健康检查出错?
- 管道中是否有东西更改了导致这种错误状态?
这使您能够在需要时有效地与其他团队沟通上游问题和平台问题,并减少解决时间。它还提高了在平台上的调试技能。
-
操作:
- 上游问题: 一旦确认问题确实是由延迟、缺失或不正确的数据引起的,来自您管道上游的项目或数据源,请联系负责上游数据的团队。
- 提示: 在开始监控之前记录上游团队的联系方式是有帮助的。这使值班人员可以轻松联系他们。
- 平台问题: 如果您已识别出Foundry的意外行为,并排除了管道中的任何用户更改,请联系您的Palantir代表。向他们提供尽可能多的关于问题的具体信息,包括观察到的任何更改的详细信息。请参见下文以获取一些识别这些问题的提示。
- 更改: 在识别出监控的管道中有变化后,您通常可以采取措施修复它。在某些情况下,可能需要联系进行更改的人以获取更多信息。请参见下一节以帮助识别管道中的更改。
- 上游问题: 一旦确认问题确实是由延迟、缺失或不正确的数据引起的,来自您管道上游的项目或数据源,请联系负责上游数据的团队。
-
[非必填] 下游用户通信: 上图中未提到的一步是,当问题已被分类并进一步找到根本原因时,可能适合通知管道的下游消费者。这取决于问题的影响、范围、持续时间和管道的应用案例。
-
变通方案: 如果来自其他团队或用户的修复需要一些时间,可能有必要实施中期变通方案,以确保管道的健康部分继续为下游消费者运行。具体的临时修复取决于问题和用户的需求。示例包括:
- 通过从调度中移除出错的数据集或管道分支来隔离问题。
- 如果这是问题的根本原因,可以固定另一个Python库版本。这可以通过在meta.yml中指定库名称旁边的明确版本号来完成。
识别管道中的更改
作为管道维护员,最常见的问题是由于您监控的管道中某些更改的意外后果引起的。这也是作为管道维护员,您最具控制力的类别,您可以直接修复问题而无需依赖其他团队。
更详细地说,采取的步骤是:
-
尽可能精确地查找出管道中问题的来源。例如,尝试识别调度、数据集、事务、代码更改等。
-
将正常的先前运行与当前出错状态进行比较,以识别哪些更改了。 拥有一份问题清单可能会很有帮助。下面是一个示例问题清单,以及一些可能帮助您找到答案的工具示例:
- 比平时慢?这是由排队引起的还是构建实际上需要更长时间来计算?
- 文件/数据大小的更改?
- 代码更改?架构更改?
- 调度更改?
- 正在进行的平台事件?
工具
如果您不熟悉Foundry中用于回答上述问题的工具,下面的列表提供了调查期间使用的最常见模式示例。该列表未涵盖所有可能性,而是作为起始指南:
我的任务/搭建是否比平时慢?
-
搭建应用用于比较给定数据集的任务。在搭建概览的右上方的进度详情切换将允许您查看搭建的进度,按排队时间与计算时间进行区分。
- 如果失败的任务是作为调度的一部分进行的,则在搭建详情页面的左下角将显示一个调度卡片。您可以通过点击表示先前搭建的一个点来打开调度的先前运行。

- 如果失败的任务是作为调度的一部分进行的,则在搭建详情页面的左下角将显示一个调度卡片。您可以通过点击表示先前搭建的一个点来打开调度的先前运行。
-
调度指标允许您查看调度的历史运行以及比较运行的指标和图表
我的数据集大小有变化吗?我的变换是否运行了更多数据?
-
数据集预览:任何Foundry数据集的历史和比较标签提供了数据集历史的概览,并能够与数据集的先前事务进行比较,以获得变更概览。

-
Contour提供了历史视图来比较使用摘要面板的行数,如果您有一个表示数据添加/创建日期的列,您可以创建图表来比较添加日期与行数。
-
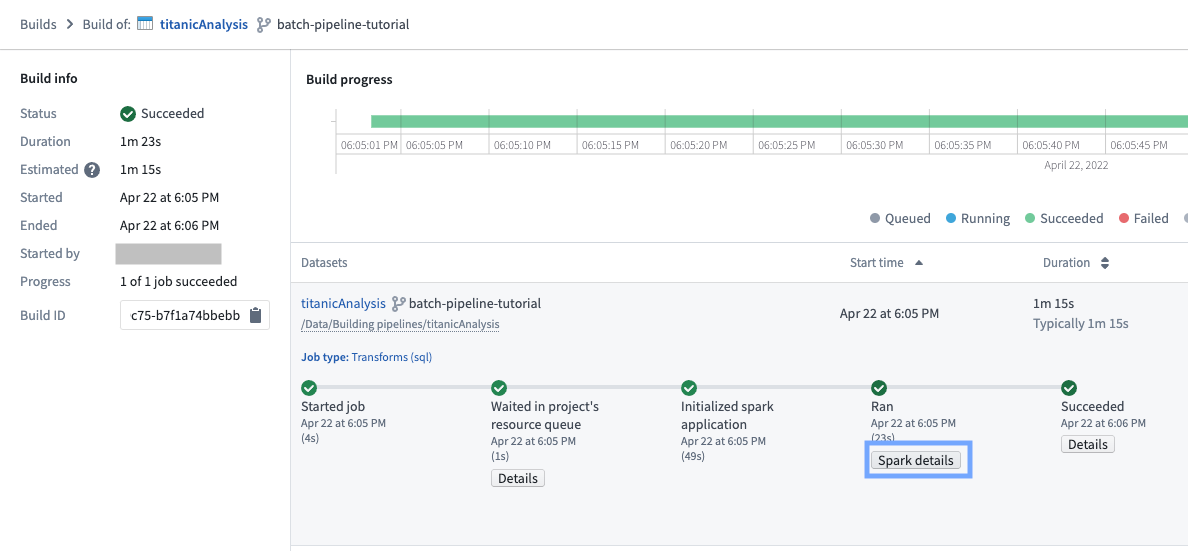
Spark详情:通过点击任何任务上的Spark详情按钮(见下图),您将能够看到一些信息,例如
任务数量指标,帮助指示管道中是否有更多数据。
我的管道中的代码更改了吗?
- 数据集预览的比较标签允许您在比较数据集的历史事务时查看直接变换文件的代码更改。
- 在代码库中,代码标签中的文件更改(提交历史)助手允许您查看代码更改。
- 数据沿袭工具允许您快速查看管道中的架构概览。侧面板属性和直方图特别有用,可以跟踪管道中哪些数据集包含特定列。
我的调度被更改了吗?
- 平台各个部分的调度卡片将允许您查看调度上次更改的时间。
- 调度的版本标签上的调度指标页面将允许您准确识别调度配置中进行了哪些更改。
识别平台问题
如果您不确定基于所看到的症状问题是什么,检查其他任务、搭建或相关平台组件中的类似症状可能是一个有用的调查路径。
特别是,您应该寻找这些问题的答案:
- 是否可重现?
- 此问题是否持续发生?
- 是否遵循模式?例如,它是否每周一上午9点在周末之后失败?
- 范围是什么?
- 如果您的任务缓慢或失败,您是否在其他变换任务中看到此情况?或者仅在其他Python任务中?
使用搭建应用过滤平台上的任务历史可以帮助您回答上述问题。
快速调试和解决管道问题的能力是管道维护员工作的重要组成部分。这确保了支持重要组织工作流的生产管道保持可靠和有意义。如果您发现自己遵循本页面所述的指南,仍然无法识别手头的问题,请联系您的Palantir代表。