注意:以下翻译的准确性尚未经过验证。这是使用 AIP ↗ 从原始英文文本进行的机器翻译。
交付管道
在Pipeline Builder中完成管道描述并解决模式出错后,您就可以准备交付您的管道。
部署与搭建
部署会更新管道输出的逻辑,而搭建则执行该逻辑以实现逻辑更改。
搭建可能会消耗大量的时间和资源,尤其是当数据规模较大或重新处理整个管道输入时。出于这个原因以及其他原因,您可能选择仅部署而不搭建。选择仅部署可以将搭建的成本推迟到必要时再进行。
交付更改
如果您希望交付第一个端到端管道并包含所有定义的逻辑,请选择顶部工具栏右侧的 Deploy。

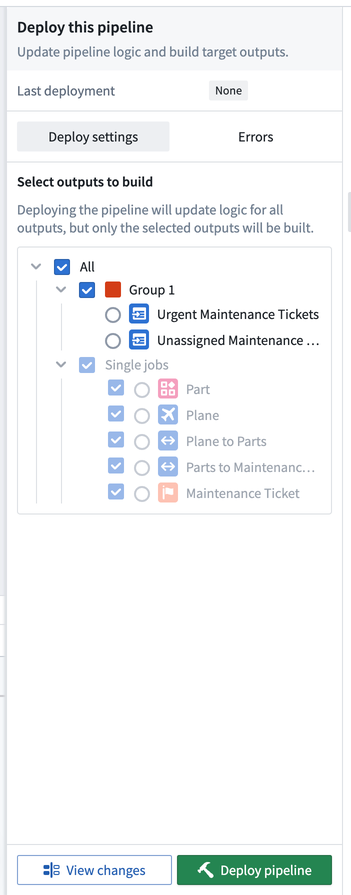
您可以选择在逻辑更改部署后要搭建哪些输出。搭建是按任务组进行的,这意味着您可以非必填地搭建任何给定任务组中的所有输出或未分组的单个输出。Ontology类型的输出必须始终被搭建,这意味着任何包含Ontology类型输出的任务组必须被搭建。
成功启动部署后,图表顶部会出现一个蓝色横幅。选择 View 进入 Build details 视图。

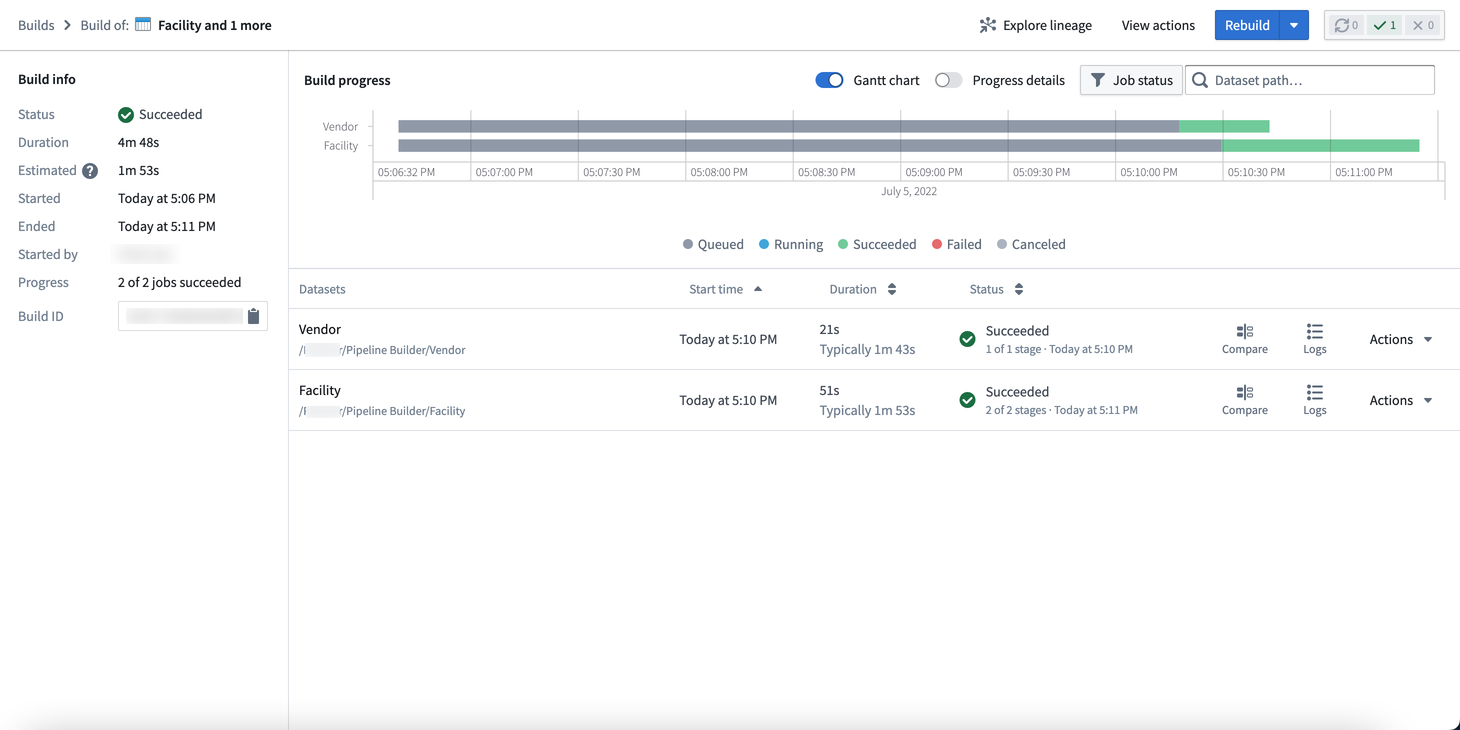
在 Build details 视图中,您可以找到构建信息、进度指标和构建计划的详细信息。
-
Build info: 显示管道的状态、总持续时间和预计持续时间。您还可以查看各种元数据,包括起始和结束时间、启动用户、任务列表中的进度和构建ID。
-
Build progress: 以甘特图形式显示管道构建随时间的详细信息。
-
Build schedule: 显示管道构建计划的名称、频率、状态历史和最后修改日期。
- 了解有关创建构建计划的更多信息。
-
Progress details: 切换查看构建是否正在起始、在项目的资源队列中等待、初始化Spark应用程序、运行或完成。
构建设置
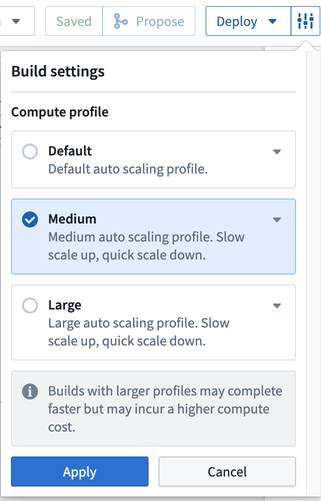
您可以通过点击 Deploy 旁边的设置图标来选择编辑管道的 Build settings。从以下计算设置中进行选择:
- Default: 默认的自动扩展配置文件。使用最少的执行器核心和内存。
- Medium: 提供慢速扩展和快速缩减计算。
- Large: 提供慢速扩展和快速缩减计算。
- 注意:具有较大配置文件的构建可能会更快完成但会产生较高的计算成本。
保存
在Pipeline Builder中,您可以选择保存对管道的更改而不启动部署。这种灵活性允许您编辑工作流程而不将逻辑更改提交到生产。
在对工作流程进行更改后,选择顶部工具栏中的 Save。

如果您先点击 Propose,当前状态将自动保存。
如果仅保存更改而不部署,管道逻辑将不会更新到最新更改。您必须部署管道以捕捉变换逻辑的更改。
从输出节点构建
即使在管道图之外导航时,您也可以选择开始构建管道。例如,您可以通过右键单击输出节点并选择 Open 来打开数据集预览。然后可以通过点击界面右上角的 Build 来启动构建。
管道图之外的构建选项不会使用自上次部署以来的任何更改更新管道逻辑。要更新逻辑并推送到输出,请返回管道图并使用 Deploy。
流式管道的附加选项
如果您正在运行流式管道,将会有其他选项可用。请注意,流式管道仅在某些帐户中可用。欲了解更多信息,请联系您的Palantir代表。
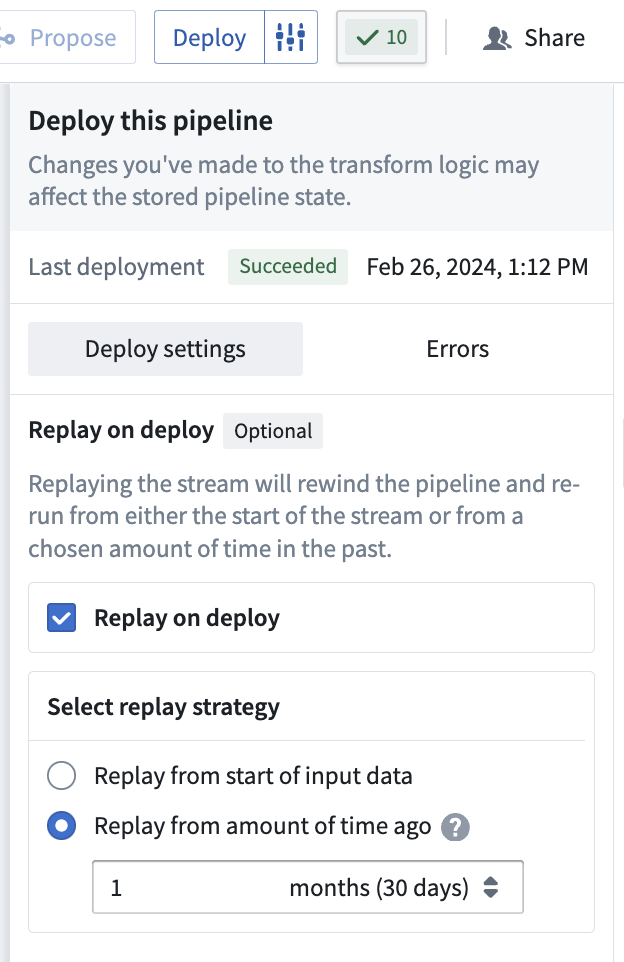
您可以在必要时使用 Replay on deploy 来指示管道从特定的历史时间点开始计算。
在 Deploy 窗口中,选择管道交付中数据处理的起始时间:
- Start of input data: 将处理输入流开始的所有数据。
- From a specified time: 选择希望数据开始处理的时间值。该时间之前的任何数据都将不被处理。例如,要仅包含过去两个月的数据,选择
2 months前。
重播管道可能导致长时间的停机,可能长达数天。当您重播管道时,您的流历史将丢失,所有下游管道消费者都将被要求重播。
有关重播的更多信息,请参阅重大更改文档。
重新部署与重播
流重新部署指的是从先前保存的检查点恢复流任务的过程。当流任务暂停或停止时,数据中会创建一个书签,指示已读取记录的位置。书签,也称为检查点,也会在流运行时定期创建。这可以在流遇到出错时进行恢复。
通过这样做,当流重新启动时,它会从那个特定的检查点恢复处理。在重新部署期间,现有的输出流会被保留,并将新数据附加到它们上。
另一方面,流重播则是生成输出流的新视图。在数据集上建立新视图被视为包含新数据的新流;但是,仍然可以访问先前视图中的数据。各种情况可能需要或为流重播提供优势,包括以下情况:
- 如果您修改了Pipeline Builder管道中的逻辑并需要输出数据遵循更新的逻辑,重播流可以通过从头开始或从指定时间点开始重新启动处理来实现。这确保输出流的数据与更新的变换规则保持一致。
- 如果发生重大更改,将强制执行重播。更多详细信息可以在重大更改文档中找到。
- 如果管道中的输入流已被重播,您也必须重播下游管道以保持输出流中的数据一致性。
请注意,重播管道可能导致延长的停机时间,这可能会根据重播的起始点持续数天。当您重播管道时,输出流中的所有数据都会丢失。如果希望保留先前流中的数据,可以将输出定向到一个新目的地。但是,如果您计划在未来将记录推送到原始输出流,则需要重播管道。
要重新部署流,请按照用于初始部署的相同步骤操作;在Pipeline Builder界面中选择 Deploy。
要重播流,请添加附加设置以从输入数据起始或指定时间进行重播。