注意:以下翻译的准确性尚未经过验证。这是使用 AIP ↗ 从原始英文文本进行的机器翻译。
预览管道
预览面板允许您预览管道中单个选定节点的逻辑和列统计信息。选择一个节点并点击 预览 来运行管道。这将打开预览面板,并运行从原始数据集到选定节点的逻辑。
您还可以通过点击图表右下角的图标来扩展预览面板。然后,点击一个节点以预览数据。
要查看统计信息,右键点击一个列并选择 查看统计。
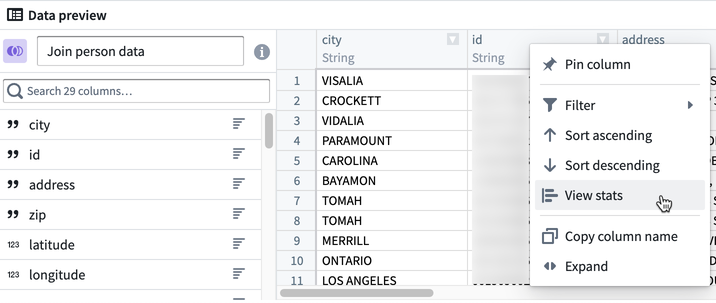
对于字符串列,统计视图包括值和值长度的直方图,以及字符串大小写、空白和空实例的计数。对于数值列,显示值的分布以及基本统计信息,如最小值、最大值、平均值、标准差和不同值的数量。
要查看行数,请在预览面板的右下角选择 计算行数。
预览行数
默认情况下,Pipeline Builder将在预览表中处理最多500行。这种实现可能只需要数据集中500行输入,但许多操作如 筛选、合并 和 删除重复项 可能需要额外的行以生成500行的预览。
为了加快预览,添加输入采样策略以限制用于计算预览的输入行数。输入采样策略仅影响预览,不影响搭建。
行数和统计计算是在采样输入上运行的。这意味着如果使用完整数据集,行数和统计将与完整搭建匹配;然而,如果采样策略设置为仅使用部分输入数据集,行数和统计只会在此采样上计算。
例如,假设我们有一个包含600行的输入数据集:
| id | value |
|---|---|
| 1 | row_1 |
| 2 | row_2 |
| ... | ... |
| 600 | row_600 |
我们的预览将限制为500行。注意,这些不一定是输入的前500行。
| id | value |
|---|---|
| 1 | row_1 |
| 2 | row_2 |
| ... | ... |
| 500 | row_500 |
在设置了小百分比的输入策略后,输入将被限制为一个可以加速预览计算的小样本。假设我们的预览中仅剩六行:
| id | value |
|---|---|
| 1 | row_1 |
| 12 | row_12 |
| 33 | row_33 |
| 62 | row_62 |
| 126 | row_126 |
| 527 | row_527 |
如果我们使用变换来添加一个值为 world 的常量列 hello,预览将显示为我们的六个采样行计算的变换结果:
| id | value | hello |
|---|---|---|
| 1 | row_1 | world |
| 12 | row_12 | world |
| 33 | row_33 | world |
| 62 | row_62 | world |
| 126 | row_126 | world |
| 527 | row_527 | world |
计算行数将返回六行,任何统计信息将仅在这六行上计算。
当我们最终搭建管道时,采样策略将不产生影响,我们的变换将针对全部600行输入计算。