注意:以下翻译的准确性尚未经过验证。这是使用 AIP ↗ 从原始英文文本进行的机器翻译。
在 Pipeline Builder 中使用 LLM 节点
在 Pipeline Builder 中使用 LLM 节点提供了一种方便的方法,以大规模执行大语言模型(LLMs)在您的数据上。将该节点集成到 Pipeline Builder 中,允许您在各种数据变换之间无缝地加入 LLM 处理逻辑,无需编写代码即可简化 LLM 的集成。
使用 LLM 节点包括预先设计的提示模板。这些模板为初学者提供了一个使用 LLMs 的起点,利用了经验丰富的提示工程师的专业知识。您还可以在输入数据集的几行上进行试运行,以在对整个数据集运行模型之前迭代您的提示。此预览功能在几秒钟内计算完成,加快了反馈循环并增强了整体开发过程。
要使用此功能,用户必须由平台管理员授予自定义工作流的 AIP 功能权限。
选择数据集
要将 LLM 应用于数据集,请在您的工作区中选择一个数据集节点,然后选择 Use LLM。

选择提示
以下是可用提示模板的不同示例。要创建您自己的提示,请选择 Empty prompt。

分类
当您想将数据分类到不同类别时,应该使用分类提示。
下面的示例展示了如何为我们的分类餐厅评论为三类(服务、食物和气氛)的目标填写提示。

Multiplicity 字段允许您选择输出列是否包含一个类别、多个类别或确切数量的类别。在我们的示例中,我们希望包含评论可能属于的所有类别,因此我们选择 One or more categories 选项。
在 Context 字段中,输入您的数据描述。在我们的示例中,我们输入 Restaurant Review。
在 Categories 字段中,输入您希望将数据指派到的不同类别。在我们的示例中,我们指定了三个类别:Food、Service 和 Atmosphere,因为我们希望将餐厅评论分类到这三个类别中的任意一个。
在 Column to classify 字段中,选择包含您要分类的数据的列。在我们的示例中,我们选择 review 列,因为那是包含餐厅评论的列。
总结
您可以使用总结模板将数据总结为指定长度。
在此模板中,您可以指定总结的长度。您可以选择单词、句子或段落的数量,并在 Summarization size 字段中指定大小。
在我们的示例中,我们希望有一个餐厅评论的一句话总结,因此我们指定 1 作为总结大小,并从下拉菜单中选择 Sentences。

翻译
要将数据翻译成不同的语言,请使用翻译提示。在 Language 字段中指定您要将数据翻译成的语言。在下面的示例中,我们希望将餐厅评论翻译成西班牙语,因此我们在 Language 字段中指定 Spanish。

情感分析
当您希望根据数据的正面或负面情感为其分配一个数字评分时,请使用情感分析提示。
在此模板中,您可以配置输出评分的范围。在下面的示例中,我们希望一个从零到五的数字,其中五表示评论最为正面,零表示最为负面。

实体提取
当您希望从数据中提取特定元素时,请使用实体提取提示。在我们的示例中,我们希望提取餐厅评论中的所有 food、service 和 times visited 元素。
特别是,我们希望在 String Array 中提取所有食物元素,服务质量作为 String,以及一个 Integer 表示该人访问餐厅的次数。
要获得这些结果,我们更新 Entities to extract 字段。在 Entity name 下输入 food、service 和 number visited,并具有以下属性:
- 对于
food,在 Type 中指定Array并选择String作为该数组的类型。 - 对于
service,选择String作为类型 - 对于
number visited,选择Integer。
现在,LLM 输出已配置为符合我们在此示例中指定的类型。

您还可以在提示页面的 Output type 下调整提取实体的类型。

空提示
如果没有任何提示模板适合您的应用案例,您可以选择 Empty prompt 创建自己的提示。

视觉
目前,Pipeline Builder 的 GPT-4o 模型支持需要视觉能力的提示。这意味着模型可以接收图像,分析它们,并根据视觉输入回答问题。
要使用此视觉功能,请在空提示模板的 Provide input data 部分中输入媒体引用列,并选择 GPT-4o 作为模型。

目前,视觉提示不支持媒体集作为直接输入。使用 Convert Media Set to Table Rows 变换以获取您可以输入到 Use LLM 节点的 mediaReference 列。
非必填配置
输出类型
在提示页面,您可以指定 LLM 输出应符合的期望输出类型。选择屏幕底部附近的 Output type 选项,然后从下拉菜单中选择首选类型。

包含错误
同样在提示页面,您可以配置输出以显示 LLM 错误以及输出值。此配置将更改您的输出类型为一个包含原始输出类型和错误字符串的结构。要包含 LLM 错误,请勾选 Include errors 旁边的框。

要将输出更改回原始输出而不包含错误,请取消勾选 Include errors 框。
跳过已处理的行计算
这是一个新功能,可能尚未在所有注册中可用。
为节省计算成本和时间,您可以通过切换 Skip recomputing rows 来跳过已处理的行计算。

当启用 Skip recomputing rows 时,将基于输入提示中传递的列和参数值来比较行。具有相同列和参数值的匹配行将在未来部署中获得缓存的输出值而无需重新处理。
如果对提示进行更改需要重新计算所有行,可以清除缓存。在 LLM 视图上会出现一个警告横幅。

要清除缓存,请选择红色垃圾桶图标。如果缓存被清除,所有行将在下一次部署中重新处理。

如果更改了输出类型,缓存将自动清除。当这种情况发生时,会出现一个警告横幅。如果这是一个错误,您可以在横幅中选择 撤销更改。

任何缓存状态的更改将在合并分支时显示在 更改 页面上。

如果具有多个下游输出的 use LLM 节点启用了 Skip recomputing rows,则必须将这些输出放在同一任务组中。否则,当尝试部署时,您将收到以下错误:

创建一个新的任务组 在默认任务组之外以修复此错误。
[高级] 显示模型配置
对于每个提示,您可以配置用于该 Use LLM 节点的模型:
- Model Type:GPT 实例的模型类型,例如
3.5或4。Use LLM 节点还支持开源模型,如 Mistral AI 的 Mixtral 8x7b。 - Temperature:较高的温度值将使输出更随机,而较低的值将使其更集中和确定。
- Max Tokens:这将限制输出中的词元数量。您可以将词元视为语言模型用于理解和处理书面语言的小文本块。
- Stop Sequence:如果 LLM 生成命中任何停止序列值,将停止生成。您最多可以配置四个停止序列。

试运行
在每个 Use LLM 面板的底部,您可以选择使用示例测试您的特定 LLM。选择 Trial run 选项卡并在左侧输入您要测试的值。然后选择 Run。

要测试更多示例,您可以选择 Add trial run。
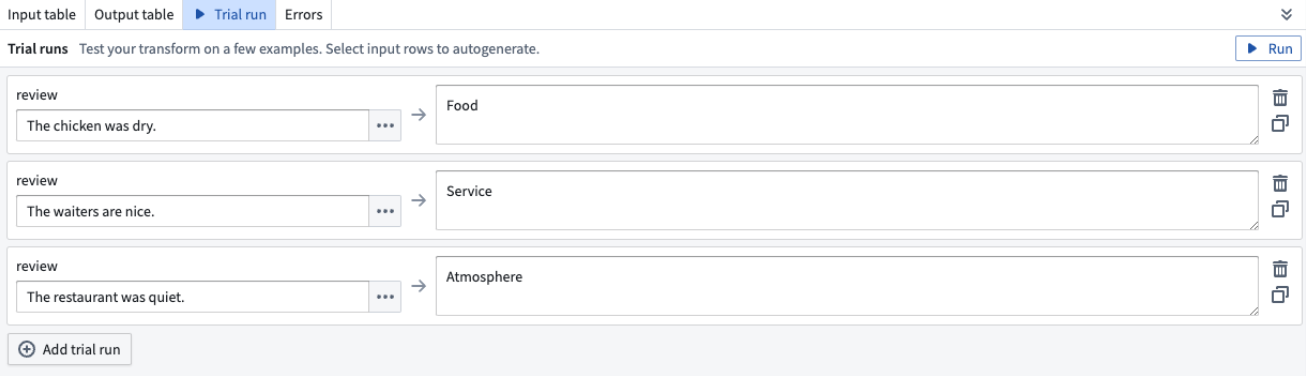
要直接从您的输入数据中添加示例,请导航到 Input table 选项卡并选择要在试运行中使用的行。选择 Use rows for trial run,然后您将自动返回 Trial run tab,已选择的行将填充为试运行。

预览和创建
如果您使用五个模板之一,您可以在创建提示之前通过选择 Preview 选项卡预览 LLM 提示说明。您将只能查看但不能编辑 Preview 选项卡中的说明。如果您想编辑模板,请返回 Configure 选项卡。

您应该选择 Create prompt 以编辑新输出列的名称并在 Output column 中预览结果。
一旦选择 Create prompt,您将无法返回到该特定面板的模板。

要更改输出列名称,请编辑 Output column 部分。要查看应用于输出表预览的更改,请选择 Applied。要预览输出表,请选择 Output table 选项卡。此预览将仅显示前 50 行。

最后,当您完成配置 Use LLM 节点时,请选择右上角的 Apply。这允许您为 LLM 面板的输出添加变换逻辑,并在主 Pipeline Builder 工作区中选择 LLM 面板时查看前 50 行的预览。