注意:以下翻译的准确性尚未经过验证。这是使用 AIP ↗ 从原始英文文本进行的机器翻译。
概览
Pipeline Builder 为在 Foundry 中变换数据提供了一个灵活、强大且易于使用的界面。在现有工具(例如 Spark 或 SQL)中编写数据变换对于非编码人员和有经验的软件开发人员来说都是具有挑战性且容易出错的。此外,现有工具通常与一个特定的执行引擎耦合,并需要使用代码库来表达数据变换。
Pipeline Builder 使用一个通用模型来描述数据变换。这个后端是用于编写变换的工具与执行这些变换之间的中间层。
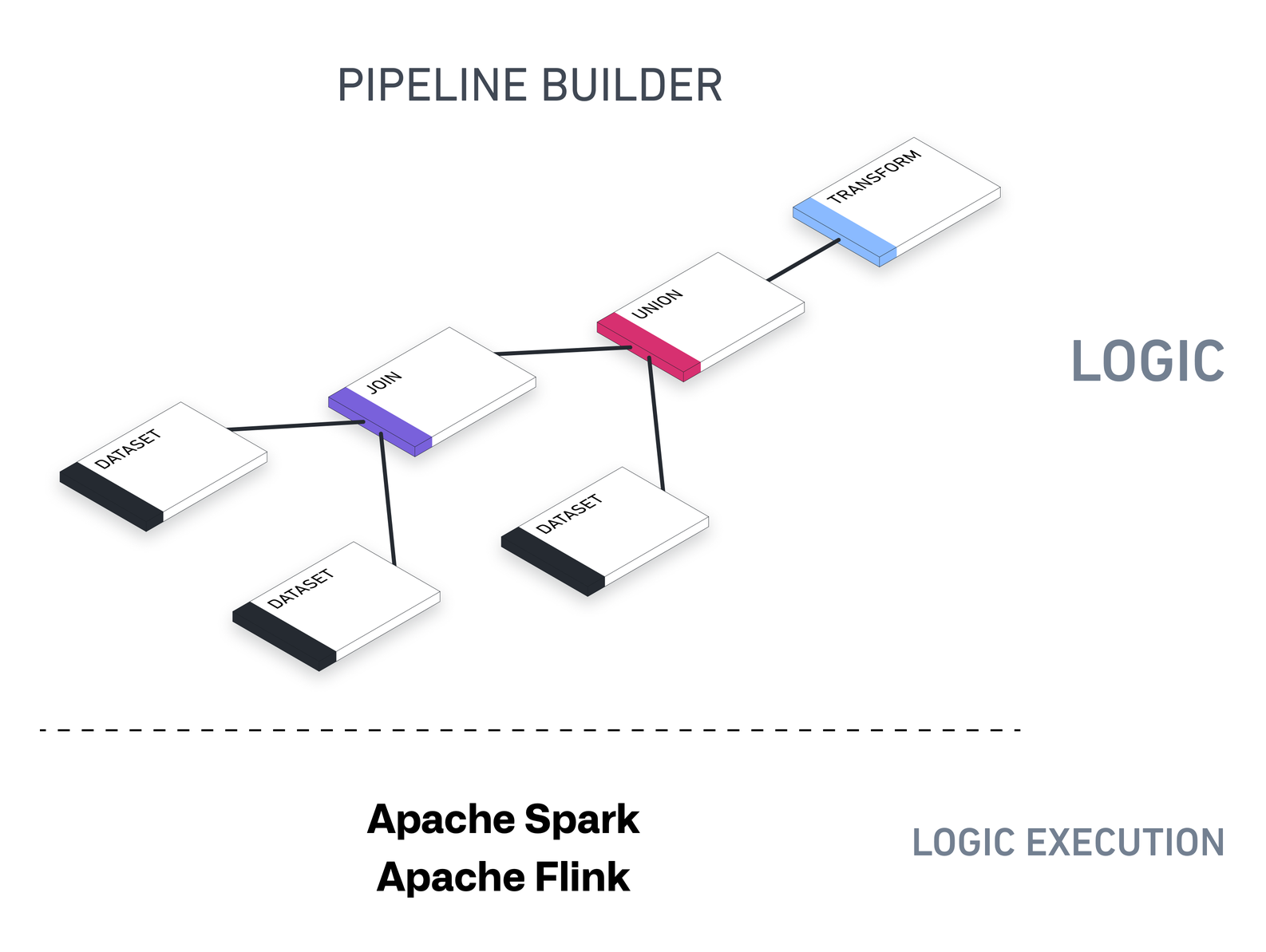
Pipeline Builder 的底层架构旨在支持各种输出——数据集、本体对象、流、时间序列以及导出到外部系统。您可以运行用于数据集、对象类型、链接类型的批处理管道,或与流数据集对应的流式管道。
在 Pipeline Builder 中使用变换
在 Pipeline Builder 中,您可以使用两种类型的数据变换:表达式和变换。表达式以表中的列为输入并输出单列(例如 Split string),而变换以整个表为输入并返回整个表(例如,Pivot 或 Filter)。
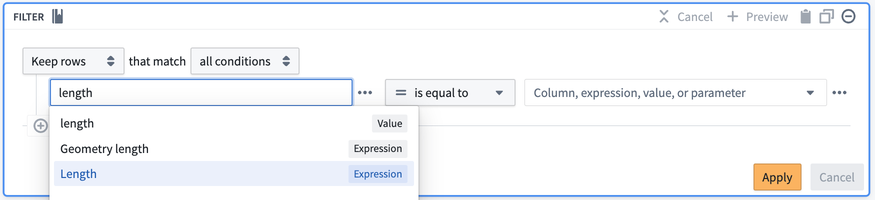
我们在相同的配置界面中将表达式和变换分组在一起。例如,您可以在表达式如 Cast 和 Concatenate strings 旁边找到 Drop columns 变换。这允许您在同一路径中同时使用表达式和变换,并在一个配置表单中将表达式嵌入到变换中,如下所示,通过将 Length 表达式插入到下面的 Filter 变换中。
其他数据结构化变换,即 合并 和 Union,有其自己的配置窗格,并在 Pipeline Builder 界面中用独特的图标标记。

为简单起见,我们通常将所有类型的数据变换称为变换。
合并
合并会结合两个至少有一个匹配列的数据集。根据您配置的合并类型,您的合并输出可以结合匹配的行并排除不匹配的行。
Union
Union 将两个数据集结合以包含所有行。
Union 变换要求所有输入具有相同的模式。如果输入模式不完全匹配,Union 将显示一条错误消息,并列出缺失的列。
用户定义的函数
如果您无法使用现有的变换选项操作您的数据,或者有复杂的逻辑需要在多个管道中重用,您可以创建用户定义的函数(UDF)。用户定义的函数允许您在 Pipeline Builder 中运行可以版本化和升级的自定义代码。
注意: 我们建议使用 Python 函数以获得最佳体验。如果您需要访问特定的 Java 库,也可以使用 Java UDFs。
用户定义的函数应仅在必要时使用。我们建议在可能的情况下使用 Pipeline Builder 中优化的变换面板。
后续步骤
了解如何添加变换到您的管道工作流程中。