注意:以下翻译的准确性尚未经过验证。这是使用 AIP ↗ 从原始英文文本进行的机器翻译。
在Pipeline Builder中创建唯一ID
在Pipeline Builder中,唯一ID有助于数据的跟踪、处理和分析,确保每条记录都可以被单独识别和正确处理。因此,通常需要为记录创建唯一标识符(ID)。本节解释了为什么使用单调递增ID不是最佳方法,以及为什么生成唯一ID的首选方法是字符串列的连接和SHA256哈希。
使用字符串列的连接和SHA256哈希
生成唯一ID的最佳方法是将输入数据中的字符串列连接起来,然后对连接的字符串创建SHA256哈希。
要在Pipeline Builder中使用此方法生成唯一ID,请在Pipeline Builder变换路径中按照以下步骤操作:
- 确定可以唯一标识数据集中每条记录的字符串列。
- 将选定的字符串列连接起来,形成每条记录的单个字符串。
- 使用“Hash sha256”计算连接字符串的SHA256哈希。生成的256位哈希可以表示为64字符的十六进制字符串,这将作为每条记录的唯一ID。

这种方法有几个优点:
- 一致性:相同的输入数据将始终生成相同的唯一ID,确保数据管道不同运行之间的一致性。这使得跟踪记录、识别重复项和执行数据对账变得更容易。值得注意的是,如果这些ID被用作Object的主键,您不希望这些主键因为重新搭建管道而更改。此外,请考虑是否有人在数据下游的任何时候可能依赖于ID的稳定性。
- 分布式生成:由于唯一ID是从数据本身派生的,多个进程可以同时生成唯一ID,而无需同步或集中协调。这提高了分布式数据处理环境中的可扩展性和性能。
通过使用字符串列的连接和SHA256哈希,您可以生成可扩展、安全和一致的唯一ID,使其成为数据管道应用程序的理想选择。
单调递增ID的缺点
虽然Pipeline Builder不支持单调递增ID,但它们常常被熟悉Spark的数据工程师使用。单调递增ID按顺序生成,如1, 2, 3,依此类推。虽然这种方法本身具有简单性,但它有几个缺点:
- 搭建之间的一致性问题:在Spark中使用单调递增ID时,生成的ID可能会在相同应用程序的不同运行之间发生变化。这是因为Spark将任务分配给其执行者的方式可能会有所不同,导致不同的ID分配顺序。因此,这种不一致性可能使得重现结果、比较不同运行或执行增量更新变得困难,从而使其成为ID列的一个不可靠选择。如果用作Ontology Object的主键,这将迫使每次搭建时进行全重新索引。
- 依赖状态:生成单调递增ID需要在行之间维护状态。
这些缺点表明,使用单调递增ID不是生成数据管道应用程序中唯一标识符的最佳方法。相反,如前一节所述,我们建议使用字符串列的连接和SHA256哈希。
如果没有可供哈希的一组唯一列
请注意,这在搭建或预览之间将不一致。如果不能确定一组唯一列,此方法应作为绝对最后的选择。
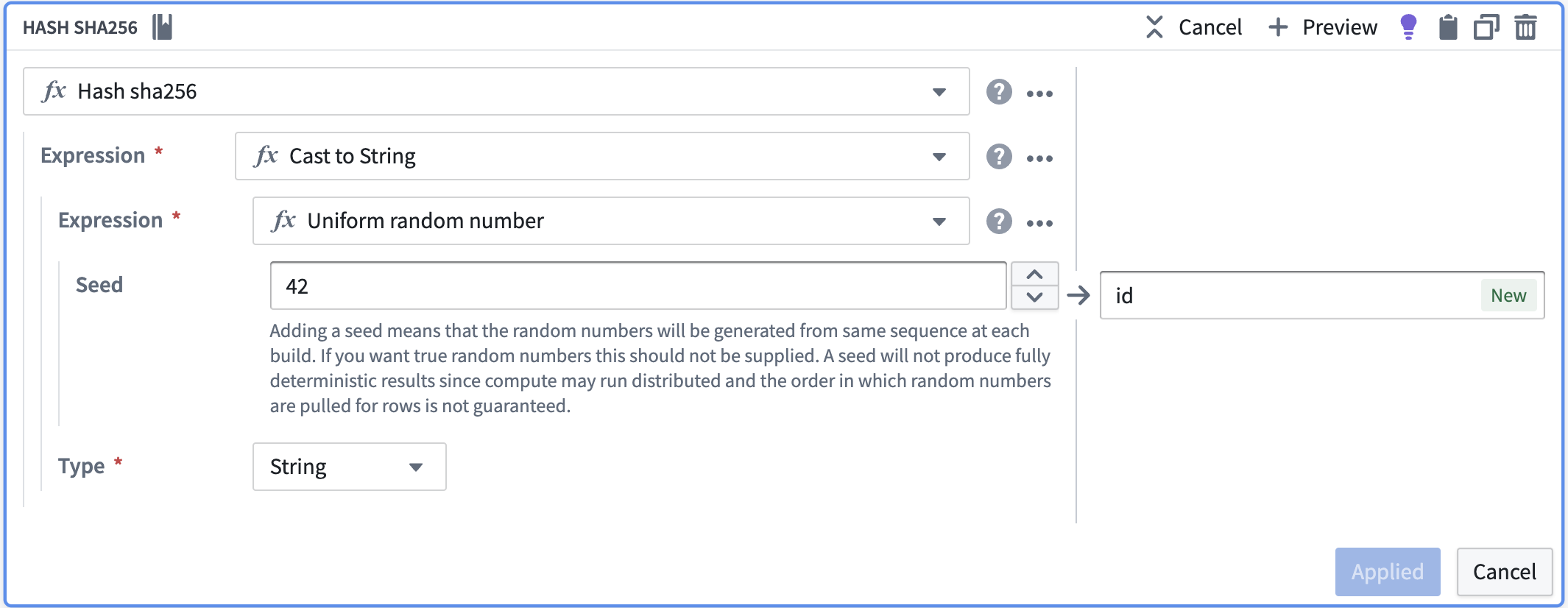
如果您没有一组定义数据中唯一行的列,您可以使用随机数的哈希来创建ID。要以这种方式创建ID,请在Pipeline Builder变换路径中按照以下步骤操作:
- 使用“Uniform random number”创建一个随机数。
- 将列转换为字符串。
- 使用“Hash sha256”对该列进行哈希。