注意:以下翻译的准确性尚未经过验证。这是使用 AIP ↗ 从原始英文文本进行的机器翻译。
创建新的流式同步
设置源
SAP流式摄取仅支持通过SAP SLT复制服务器连接到SAP系统。
如果尚不存在,请创建一个新的SAP源,明确设置连接类型为SLT,并包括用于识别源系统的上下文。按照标准步骤创建新的源,并使用以下形式的自定义YAML:
Copied!1 2 3 4 5 6 7type: magritte-sap-source url: https://<host>:<port>/sap/palantir # SAP系统的URL地址,需替换<host>和<port> usernamePassword: <username>:{{password}} # 使用用户名和密码进行身份验证 connectionType: type: slt # 连接类型为SLT(SAP Landscape Transformation) slt: context: <context> # 需要指定SLT上下文,替换<context>
以上代码片段是一个YAML配置文件,用于配置与SAP系统的连接,特别是通过SAP的SLT(Landscape Transformation)进行数据同步或集成。请确保替换占位符(如<host>、<port>、<username>、{{password}}、<context>)为实际的值。
上下文是RFC连接的唯一标识符,如SLT配置指南中所讨论。
负载考虑
每个流式同步会在SLT复制服务器中创建并订阅其自身的操作增量队列(ODQ)。
流式摄取的工作原理如下:
- Foundry将定期轮询队列;轮询间隔默认为1秒,可以在创建流式同步时修改。
- 如果队列上没有记录,则不会发出进一步的请求。
- 如果队列上的记录少于或等于50,000条(默认页面大小),这些记录将被同步消费。
- 如果队列上的记录多于50,000条,记录消费将分页进行。
在负载测试中,我们观察到,当SLT复制服务器中可用的对话工作进程数量至少与活跃的流式同步数量相等时,能够实现最低的流延迟。当可用的对话工作进程少于活跃的流式同步时,延迟可能会增加,因为流式同步会竞争一个可用的进程来处理轮询请求。
创建流式同步
-
打开SAP源。您应该在概览页面上看到现有流式同步的表格;可能需要向下滚动页面以查看。在此表格顶部选择**+ 创建流式同步**。

-
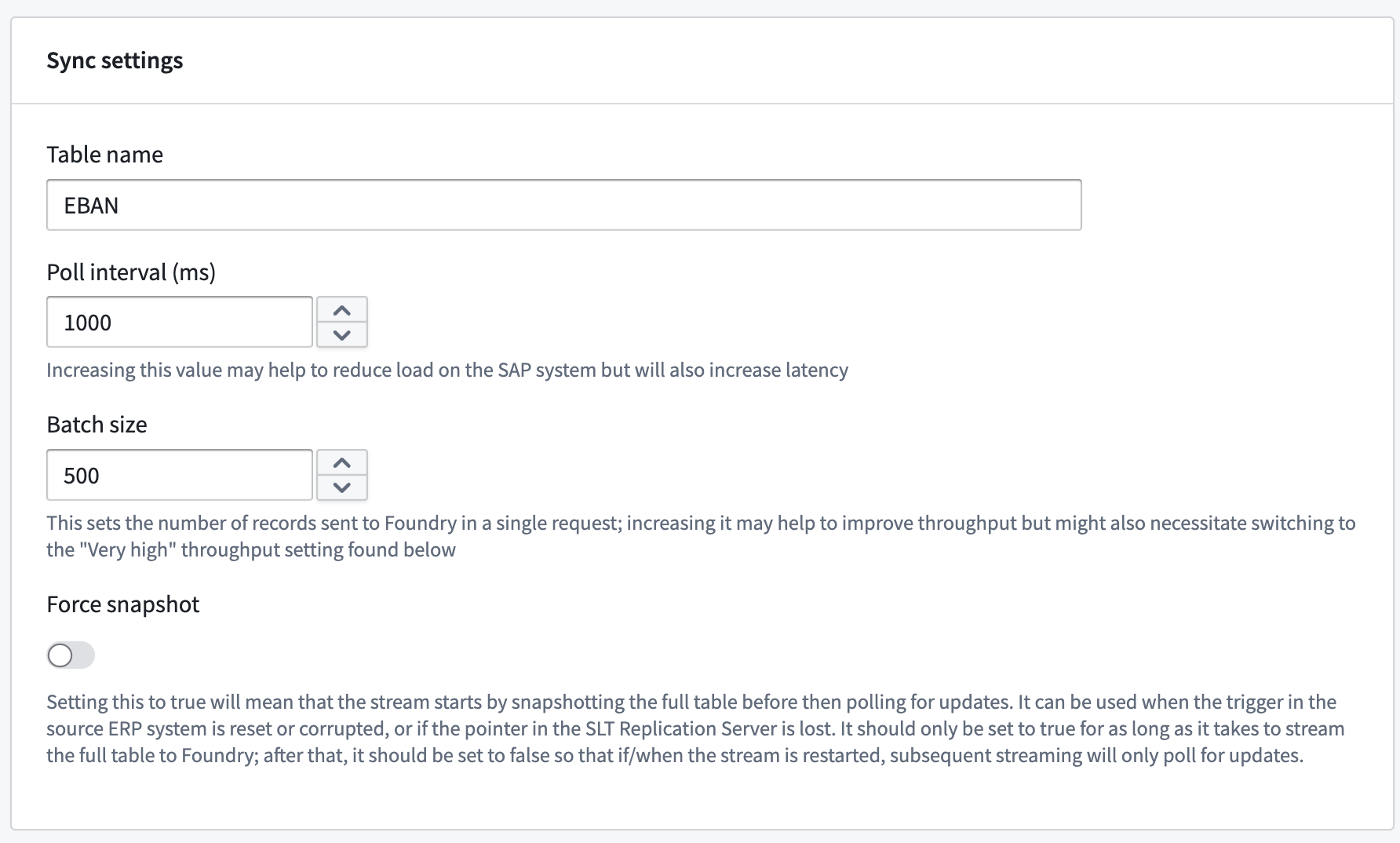
在第一部分中,输入要流式传输的SAP表的名称。
- 在第二部分中,为输出流式数据集选择一个位置。
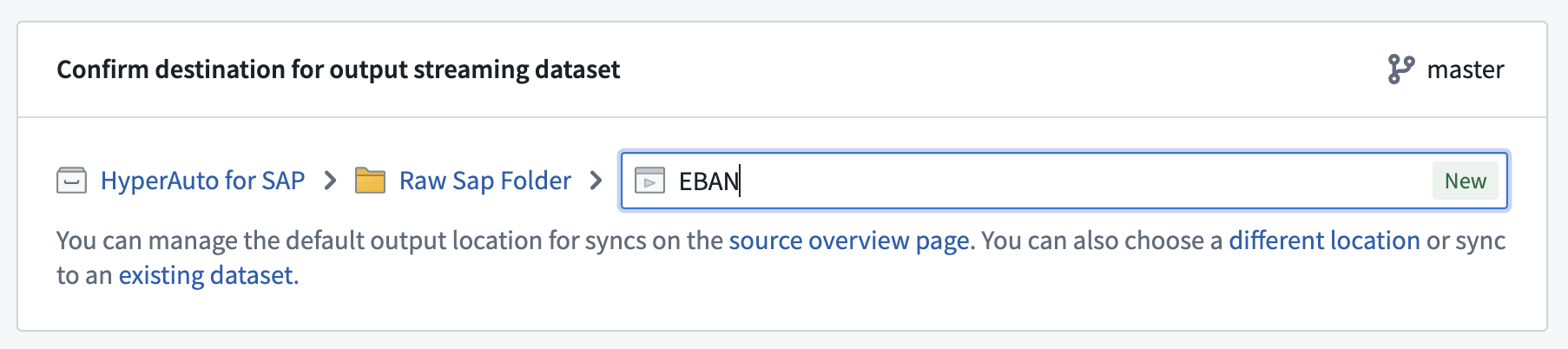
在继续下一步之前,确保屏幕底部的预览窗格已加载。流式数据集的模式来自此预览,如果预览尚未完成加载,则会不正确。在某些情况下,预览可能仅显示模式而不显示数据;这就足够了。
- 在屏幕右上角选择创建流式同步。您可以选择立即运行流或在创建后手动启动。
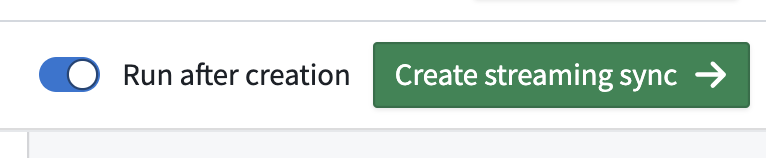
为了确保在数据连接代理或SAP系统停机时流能够自动重启,请在流式数据集上设置一个计划,时间触发器为1分钟。
吞吐量和分区键
将吞吐量设置从正常切换到非常高可能有助于提高性能。然而,这将增加使用的分区数量。当使用多个分区时,需要设置分区键以保证来自SAP的唯一记录之间的顺序。这些键应构成SAP表的主键。