注意:以下翻译的准确性尚未经过验证。这是使用 AIP ↗ 从原始英文文本进行的机器翻译。
安全审计
概述
审计日志是审计员了解 Foundry 用户执行了哪些操作的主要方式。
Foundry 中的审计日志包含足够的信息以推断:
- 谁 执行了某个操作
- 什么 操作
- 何时 发生的操作
- 在哪里 发生的操作
在某些情况下,审计日志会包含有关用户的上下文信息,包括个人身份信息 (PII),如姓名和电子邮件地址。因此,审计日志的内容应被视为敏感信息,仅供具备必要安全资格的人查看。
审计日志通常被导入到一个为安全监控专门构建的系统(“安全信息和事件管理”,或称 SIEM 解决方案)中,由客户拥有。
本指南将解释提取和使用审计日志的过程,分为两个部分:
强烈建议客户通过以下机制捕获和监控自己的审计日志。参阅监控安全审计日志以获取更多指导。
审计交付
根据客户的安全基础设施和 SIEM 要求,审计日志通过多种机制交付以供下游消费。由 Foundry 服务生成的审计日志批次会被编译、压缩并在 24 小时内移动到日志存储桶中(通常是 S3,尽管这取决于环境)。从这里,Foundry 可以通过 Audit Export To Foundry 直接将日志交付给客户消费。
导出审计日志到 Foundry
审计日志可以按组织直接导出到 Foundry 数据集的一部分。在配置设置中,组织管理员选择在 Foundry 文件系统中的何处生成此审计日志数据集。
一旦日志数据进入数据集,客户可以选择通过 Foundry 的 Data Connection 应用程序将审计数据导出到外部 SIEM。
导出权限
要导出审计日志,用户需要在目标组织上具有 audit-export:orchestrate-v2 操作权限。这可以通过控制面板中的 组织管理员 角色在 组织权限 选项卡下授予。参阅组织权限以获取更多详细信息。
导出设置
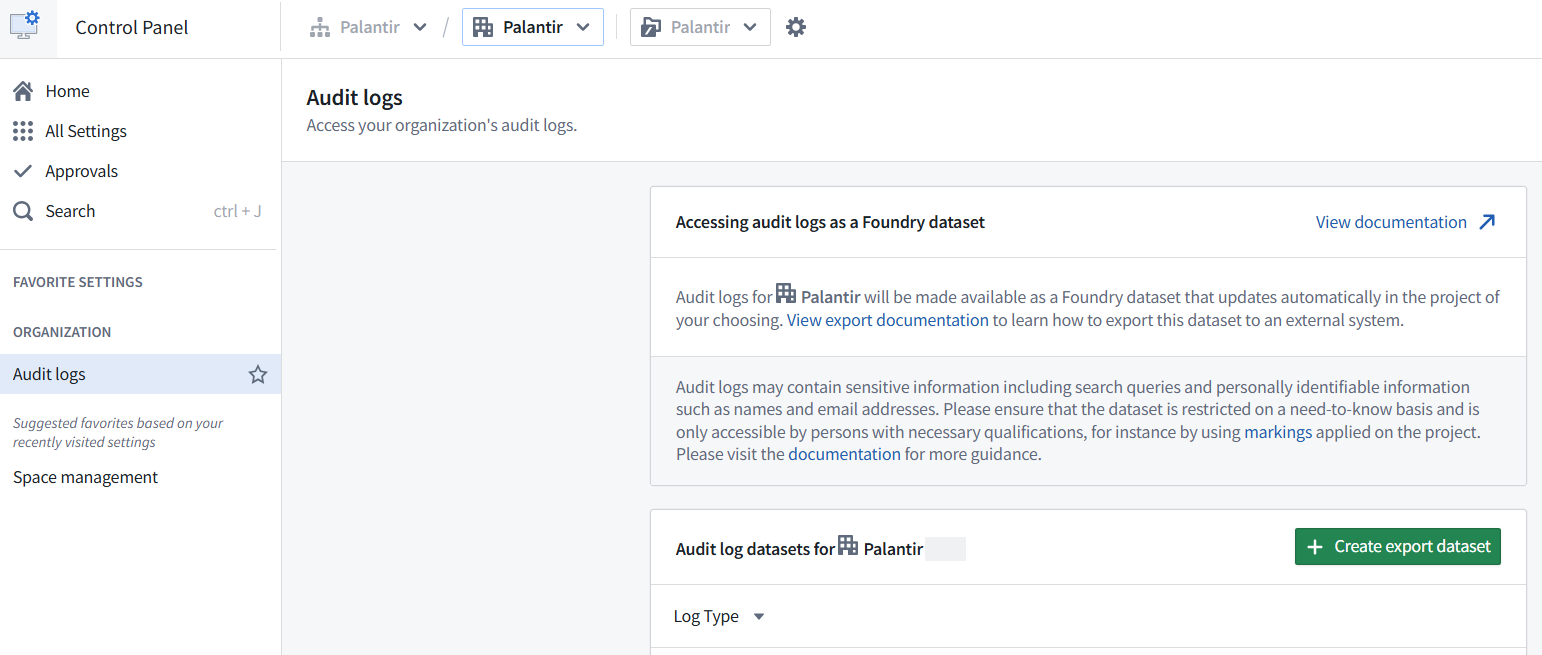
设置导出审计日志到 Foundry:
- 导航到 Foundry 控制面板。
- 在左侧边栏,通过下拉菜单选择相关组织。
- 在左侧边栏下,选择 组织设置 下的 审计日志。
- 选择 创建数据集 以生成审计日志数据集。在 Foundry 中选择此数据集的位置。默认情况下,审计日志数据集将标记为上面选择的组织。参阅组织标记。
- 非必填,配置起始日期筛选,以限制此数据集仅包含在给定日期或之后发生的事件。
- 非必填,配置保留策略,以限制日志在此导出数据集中保存的时间。注意,保留策略基于日志添加到导出数据集的事务时间戳,而不是日志条目本身的时间戳。删除相关事务可能需要在标记为删除后最多七天。以下是两个示例,说明这在实践中如何运作:
- 示例一:
- 起始日期:一年前
- 保留策略:90 天
- 在这种情况下,导出数据集最初将包含过去一年的日志。数据集创建 90 天后,保留策略将生效,只保留过去 90 天添加的日志,而不是数据集中最初的一整年。实际上,这意味着在移除较旧日志后,数据集的大小在 90 天后显著减少。
- 示例二:
- 起始日期:30 天前
- 保留策略:90 天
- 在这种情况下,导出数据集将从过去 30 天的日志开始。随着新日志的添加,数据集将增长,直到它持有最近 90 天数据的滚动窗口。根据保留策略,将移除添加到超过 90 天的事务中的日志。
- 示例一:
注意,对于较大的栈,起始几小时的构建可能会产生空的追加事务。这是预期行为,因为管道正在处理审计日志的积压。
由于审计日志的敏感性,强烈建议将创建的数据集按需限制,并仅由具备必要资格的人访问。使用权限标记来限制您的审计日志数据集,并指定可以查看潜在敏感使用细节(如身份信息或搜索查询)的平台管理员集。
禁用导出
要禁用导出,请将审计日志数据集移至回收站或另一个项目。
移动审计日志数据集将停止该数据集的任何进一步构建。即使数据集随后从回收站恢复或移回原项目,也无法重新启动这些构建。
审计日志更新
在构建时,审计日志数据集遵循一组特定条件来附加新日志(可能会更改):
- 一旦审计日志在日志存储桶中可用,通常在 24 小时内,每两小时运行一次摄取,以将这些日志放入导出数据集上游的隐藏中间数据集中。
- 然后每 10 分钟从中间数据集中将新日志附加到导出数据集中。每次追加最多提取 10 GB 的日志数据。通常仅在首次创建审计日志数据集时需要 10GB 日志数据的追加。
- 当没有新的日志数据可用时,导出数据集的计划暂停一小时,然后恢复。
- 在大多数情况下,一旦审计日志数据集完全更新,任务将每小时继续运行。通常,每三个任务中会有一个将新数据附加到审计日志数据集中;其他任务将被中止,未写入任何额外内容。
- 每次审计日志追加的运行时间与要附加到审计日志数据集的新日志数量直接成比例。
- 控制导出数据集构建的计划由 audit-export 控制,并对用户隐藏。
分析审计日志数据集
审计日志数据集可能包含非常高的数据量,因此我们建议在执行任何聚合或可视化之前,使用 time 列对该数据集进行筛选。对于任何筛选,我们建议使用管道构建器或变换,因为审计数据集可能太大而无法在 Contour 中有效分析而不先进行筛选。
审计架构
Palantir 产品生成的所有日志均为结构化日志。这意味着它们遵循特定的架构,下游系统可以依赖。
Palantir 审计日志目前以 audit.2 schema 交付,也常被称为“审计 V2”。更新的架构 audit.3 或“审计 V3”正在开发中,但尚未普遍可用。
在 audit.2 和 audit.3 架构中,审计日志可能会根据生成它的服务而有所不同。这是因为每个服务都在考虑不同的领域,因此需要描述不同的关注点。这种差异在 audit.2 中更为显著,如下所述。
服务特定信息主要记录在 request_params 和 result_params 字段中。这些字段的内容会根据记录日志的服务和事件而改变。
审计类别
审计日志可以被视为用户在平台上采取的所有操作的精炼记录。这通常是在冗长性和精确性之间的折衷,其中过于冗长的日志可能包含更多信息,但更难以推理。
Palantir 日志包含一个称为 审计类别 的概念,以使日志更易于推理,而不需要特定的服务知识。
使用审计类别,审计日志被描述为可审计事件的联合。审计类别基于一组核心概念,例如 data 与 metaData 与 logic,并分为描述这些概念操作的类别,例如 dataLoad(从系统加载数据)、metaDataCreate(创建描述某些数据的新元数据)和 logicDelete(删除系统中的一些逻辑,其中逻辑描述两个数据之间的变换)。
审计类别也经历了版本变更,从 audit.2 日志中较松散的形式到 audit.3 日志中更严格和丰富的形式。详细信息见下文。
请参阅审计日志类别以获取可用 audit.2 和 audit.3 类别的详细列表。
审计日志归属
审计日志被写入每个环境的单个日志存档。当审计日志通过交付管道处理时,schema 中的 User ID 字段(uid 和 otherUids)会被提取,用户被映射到其对应的组织。
为给定编排协调的审计导出仅限于归属于该组织的审计日志。仅由服务(非人类)用户执行的操作通常不会归属于任何组织,因为这些用户不是组织成员,除了使用 Client Credentials Grants 的第三方应用程序的服务用户,并且仅由注册组织使用,这将生成归属于该组织的审计日志。
Audit.2 日志
audit.2 日志在请求和响应参数的形状上没有跨服务的保证。因此,关于审计日志的推理通常必须在服务逐个基础上进行。
audit.2 日志可能在其中呈现一个审计类别,这对于缩小搜索范围可能很有用。然而,这个类别不包含进一步的信息,也不规定审计日志的其余内容。此外,audit.2 日志不保证包含审计类别。如果存在,类别将包含在 request_params 中的 _category 或 _categories 字段中。
audit.2 日志导出数据集的架构如下所示。
| 字段 | 类型 | 描述 |
|---|---|---|
filename | .log.gz | 日志存档中压缩文件的名称 |
type | string | 指定审计架构版本 - "audit.2" |
time | datetime | RFC3339Nano UTC 日期时间字符串,例如 2023-03-13T23:20:24.180Z |
uid | optional<UserId> | 用户 ID(如果可用);这是最下游的调用者 |
sid | optional<SessionId> | 会话 ID(如果可用) |
token_id | optional<TokenId> | API 词元 ID(如果可用) |
ip | string | 来源 IP 地址的最佳努力标识符 |
trace_id | optional<TraceId> | Zipkin 跟踪 ID(如果可用) |
name | string | 审计事件的名称,例如 PUT_FILE |
result | AuditResult | 事件的结果(成功、失败等) |
request_params | map<string, any> | 方法调用时已知的参数 |
result_params | map<string, any> | 方法内派生的信息,通常是返回值的部分 |
Audit.3 日志
审计 V3 正在开发中,尚未普遍可用。
audit.3 日志建立了更严格的审计类别使用,以减少在推理日志内容时了解特定服务的需求。audit.3 日志的生成考虑了以下保证:
- 每个审计类别明确定义了其适用的值/项目 - 例如,
dataLoad描述了加载的具体资源。 - 每个日志都是严格作为审计类别的联合生成的。这意味着日志不会包含自由格式的数据。
- 审计日志中的某些重要信息被提升到
audit.3架构的顶层。例如,所有命名资源都在顶层出现,以及在请求和响应参数中。
这些保证意味着,对于任何特定日志,可以告诉(1) 生成它的可审计事件是什么以及(2) 它确切包含哪些字段。这些保证是服务无关的。
audit.3 架构如下所示。此信息并非详尽无遗,可能会有所更改:
| 字段 | 类型 | 描述 |
|---|---|---|
environment | optional<string> | 生成此日志的环境。 |
stack | optional<string> | 生成此日志的栈。 |
service | optional<string> | 生成此日志的服务。 |
product | string | 生成此日志的产品。 |
productVersion | string | 生成此日志的产品版本。 |
host | string | 生成此日志的主机。 |
producerType | AuditProducer | 生成此审计日志的方式;例如,从后端(SERVER)或前端(CLIENT)生成。 |
time | datetime | RFC3339Nano UTC 日期时间字符串,例如 2023-03-13T23:20:24.180Z。 |
name | string | 审计事件的名称,例如 PUT_FILE。 |
result | AuditResult | 指示请求是否成功或失败类型;例如,ERROR 或 UNAUTHORIZED。 |
categories | set<string> | 此审计事件生成的所有审计类别。 |
entities | list<any> | 此日志的请求和响应参数中存在的所有实体(例如,资源)。 |
users | set<ContextualizedUser> | 此审计日志中存在的所有用户,具有上下文信息。 ContextualizedUser: 字段:
|
requestFields | map<string, any> | 方法调用时已知的参数。 请求和响应字段中的条目将取决于上面定义的 categories 字段。 |
resultFields | map<string, any> | 方法内派生的信息,通常是返回值的部分。 |
origins | list<string> | 附加到请求的所有地址。此值可以被伪造。 |
sourceOrigin | optional<string> | 网络请求的来源,通过 TCP 栈验证的值。 |
origin | optional<string> | 来源机器的最佳努力标识符。例如,IP 地址、Kubernetes 节点标识符或类似的。这值可以被伪造。 |
orgId | optional<string> | uid 所属的组织(如果可用)。 |
userAgent | optional<string> | 生成此日志的用户的用户代理。 |
uid | optional<UserId> | 用户 ID(如果可用)。这是最下游的调用者。 |
sid | optional<SessionId> | 会话 ID(如果可用)。 |
eventId | uuid | 可审计事件的唯一标识符。可用于将属于同一事件的日志行分组。例如,向消费者流式传输的大型二进制响应的开始和结束时会记录相同的 eventId。 |
logEntryId | uuid | 此审计日志行的唯一标识符,在系统中的任何其他日志行中不重复。注意,某些日志行可能在导入到 Foundry 时被复制,并且可能有多行具有相同的 logEntryId。具有相同 logEntryId 的行是重复的,可以忽略。 |
sequenceId | uuid | 对共享相同 eventId 的事件进行排序的最佳努力字段。 |
traceId | optional<TraceId> | Zipkin 跟踪 ID(如果可用)。 |