注意:以下翻译的准确性尚未经过验证。这是使用 AIP ↗ 从原始英文文本进行的机器翻译。
读取和写入数据系统
查询编辑器允许您查询数据源。根据数据源的类型,您可以在查询编辑器中编写不同的查询。以下提供了如何编写不同类型查询的概述和示例、在每种查询中使用Handlebars时的安全考虑,以及查询部分和条件查询的介绍。
查询安全概述
Foundry查询使用Foundry同步器,它在所有同步表上强制执行只读权限;此外,对单个表的访问遵循Foundry中数据集级别授予的访问权限。
对于Foundry之外的数据源,在查询中使用Handlebars会引发安全问题,因为恶意用户可能会通过用有害代码替换模板内容来进行注入攻击。因此,这些查询需要针对Handlebars使用的额外安全规则——这些规则在下面的SQL查询和HTTP JSON查询部分中进行了详细描述。
此外,任何引用用户变量的模板(例如{{user.firstName}})都是从服务器获取其值,而不是接受在登录时传递给浏览器的值。
一个SQL安全出错的示例:

一个HTTP JSON安全出错的示例:
Foundry查询
Foundry同步器
使用Foundry同步器是在Slate中查询Foundry数据的推荐方式。此设置在Foundry内提供一个Postgres实例,允许您编写常规SQL查询以从Foundry数据集中检索数据,前提是这些数据集已通过Foundry同步器作为SQL表提供。
请注意,您不需要使用任何SQL安全助手。
Foundry同步器可以通过元数据视图进行控制,如Foundry同步器文档的同步UI部分所述,或者直接在Slate中通过添加数据集并在Slate的数据集选项卡中与Foundry同步器进行交互来控制。当Foundry数据源被添加到Slate时,数据集选项卡会自动启用。要操作UI,请在Slate中添加一个数据集并查看同步到Postgres部分。

点击应用并同步按钮。

同步完成后,数据集选项卡内的Postgres面板将显示一个示例SQL查询,以便粘贴到Slate查询选项卡中。限制是为了防止意外查询超过所需的数据;您可以在Slate中的实际查询中删除它。有关如何通过UI与Foundry同步器进行交互的更多详细信息,请参阅同步UI文档,例如创建索引和自定义表名的操作。
Phonograph查询
在查询支持对象类型的Phonograph表时,考虑使用对象集来筛选、聚合和排序对象。
Phonograph是一种与同步到Phonograph服务的Foundry数据进行交互的数据源类型,该服务提供了一个支持ElasticSearch的API,用于查询和写入Foundry数据集的更改。
请参阅从Slate向Foundry数据输出,以获取有关在Slate中使用此服务的详细教程。
SQL查询
安全考虑
所有SQL查询中的Handlebars模板(使用Foundry数据源的除外)必须由SQL安全助手或Handlebars内置助手 ↗包围。您可以在SQL助手中找到如何以及何时使用每个SQL安全助手的完整详细信息。
有五个助手,分别是schema、table、column、alias和param。
schema,table:schema和table助手的工作方式非常相似。给定一个名称和一个允许的名称列表,助手会检查该名称是否存在于允许的名称列表中以及相应的信息架构表中。例如,table助手检查表名称是否存在于允许的名称列表中,以及在information_schema.tables或数据库中的相应架构表中。指定允许的名称列表可防止查询访问不应该访问的任何架构/表。您不能模板化允许的名称,因为这会破坏验证的目的。
Copied!1SELECT column1 FROM {{schema someSchemaName 'allowedSchemaName1' 'allowedSchemaName2'}}.{{table someTableName 'allowedTableName1'}};
Copied!1 2 3 4-- 这段SQL代码使用的是一种模板格式,可能用于动态SQL生成。 -- {{schema someSchemaName 'allowedSchemaName1' 'allowedSchemaName2'}} 表示一个动态的schema名称,其中允许的schema包括 'allowedSchemaName1' 和 'allowedSchemaName2'。 -- {{table someTableName 'allowedTableName1'}} 表示一个动态的表名称,其中允许的表名是 'allowedTableName1'。 -- SELECT column1 意味着从指定的schema和表中选择 column1 字段的数据。
column:column助手检查名称是否存在于information_schema.columns或数据库中的对应模式表中。
Copied!1SELECT {{column someColumnName}} FROM table1;
这个 SQL 语句用于从 table1 中选择列 someColumnName。其中 {{column someColumnName}} 使用了一种参数化语法,可能用于模板引擎或 ORM 框架中,以在运行时动态替换 someColumnName 的实际列名。
alias: 当您想要为别名的模式、表或列名称创建模板时,可以使用alias助手。因为别名不在信息模式中,您必须使用alias助手在Slate中注册它;否则,该名称无法被验证。您只能将alias助手用于常量字符串,而不能用于引用,即{{alias 'someConstantString'}}是允许的,而{{alias someReference}}是不允许的。为其创建模板会使在schema、table或column中验证它的目的失效,因为它们可能引用相同的事物。
Copied!1 2 3 4 5 6 7 8 9SELECT column1 as {{alias 'aliasedColumnName'}} -- 将 column1 重命名为 aliasedColumnName FROM table1 ORDER BY {{column someColumnName}} -- 这里的 someColumnName 应该是一个有效的列名 -- 注意: -- 在 ORDER BY 子句中,使用 {{column someColumnName}} 可能会导致错误, -- 因为 someColumnName 被引用为非数据库中实际存在的列名。 -- 需要确保 someColumnName 是表 table1 中的一个有效列。
param:param助手将模板替换为‘?’,以便稍后可以使用preparedStatement设置值。PreparedStatement是防止SQL注入的最安全方法之一。请注意,所有来自前端的值都是数字或字符串,因此要在查询中使用除数字或字符串之外的类型值,必须将该值转换为该类型。
Copied!1 2 3SELECT column1 FROM table1 WHERE column1 > {{param value1}} AND dateColumn1 < {{param value2}}::date
Copied!1 2 3-- 这段SQL查询从table1中选择column1列,其中column1的值大于参数value1, -- 并且dateColumn1的日期小于参数value2的日期。 -- {{param value1}} 和 {{param value2}} 是参数占位符,通常用在SQL模板中。
我应该何时使用哪个助手?
- 当您想要为模式/表/列名称创建模板时,应使用相应的
schema、table或column助手。 - 当您想要为别名表/列创建模板时,应该使用
alias助手注册别名。 - 当您想要为参数值创建模板,即在WHERE子句中的比较值时,应该使用
param助手。
编写SQL查询
当查询SQL数据源时,编辑器接受任何SQL命令。通常,您会运行SELECT语句。例如:
Copied!1 2SELECT name,diameter,period FROM allNamed; -- 选择 name(名称), diameter(直径), period(周期)从表 allNamed 中
Slate 将生成的行解析为JSON,为每一列创建一个键,以便可以通过handlebars访问它们。
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14{ "name": [ "Undina", // 天体名称:Undina "Hekate" // 天体名称:Hekate ], "diameter": [ 126.42, // 直径:126.42(单位可能是千米) 88.66 // 直径:88.66(单位可能是千米) ], "period": [ 5.68801089633658, // 公转周期:5.68801089633658(单位可能是年) 5.42957878301233 // 公转周期:5.42957878301233(单位可能是年) ] }
您可以使用SQL 的内置函数 ↗执行数据变换,例如基本的字符串和数学运算。
HTTP JSON 查询
安全性考虑
所有 HTTP JSON 查询必须符合以下要求:
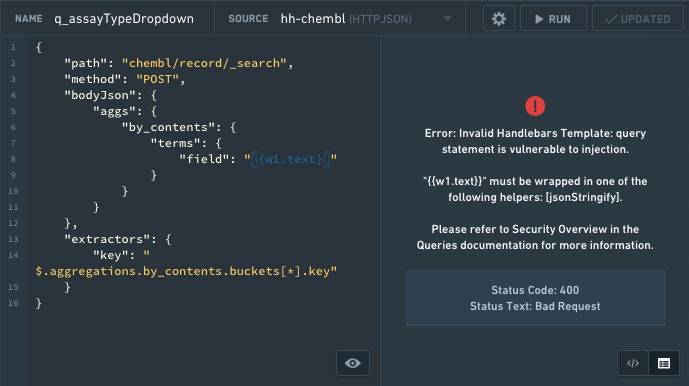
- 所有 Handlebars 模板必须被包裹在一个 jsonStringify 助手中。
jsonStringify助手确保模板的值无法逃离其当前范围。例如,它不能关闭块并向请求添加额外的属性。
使用它来模板化属性的一个示例:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13{ "path": "path/to/api", // API请求路径 "method": "POST", // 使用POST方法 "bodyJson": { "filter": {{jsonStringify w1.text}} // 将w1.text对象转换为JSON字符串并作为请求体的一部分 }, "extractors": { "result": "$" // 提取API响应的根对象 }, "headers": { "Custom_Header": "my custom header value" // 自定义请求头 } }
一个示例是将其用作属性的一部分:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13{ "path": "path/to/api", // API的路径 "method": "POST", // 使用POST方法 "bodyJson": { "filter": {{#jsonStringify}}some text plus {{w1.text}}{{/jsonStringify}} // 发送的JSON主体,包含一个动态字符串 }, "extractors": { "result": "$" // 从响应中提取结果 }, "headers": { "Custom_Header": "my custom header value" // 自定义请求头 } }
..在路径中是不允许的。这确保查询路径不会索引到任何父级范围,并且不会访问不应访问的信息。
编写HTTP JSON查询
HTTP JSON数据源的查询是一个包含以下属性的对象:path,method,bodyJson,extractors。
path: 数据源的URL路径queryParams: (非必填) 请求时附加到URL的键值对映射(例如,“query”: “something” 将附加 ?query=something 到path)。注意,当此映射不为空时,不应在path中指定查询参数。method: 用于发出请求的HTTP方法。支持的方法有GET、POST、DELETE和PUT。bodyJson: (非必填) 作为数据发送到API端点的JSON(例如,如何格式化和聚合数据)。如果数据源端点不需要JSON,则此字段不是必需的。extractors: 查询返回的结果。使用 JSONPath ↗ 确定要提取的内容。例如,要查看整个结果,请使用"result": "$"。有关编写JSONPath的帮助,请参阅以下 测试工具 ↗。有关JSONPath的更多信息,请参阅 JSONPath示例 ↗。headers: (非必填) 请求中要设置的头的映射。如果存在,认证头将被添加到此列表的顶部。
例如:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20{"path": "astronomy/_comets", // API路径,用于获取彗星数据 "queryParams": { "limit": 5, // 查询参数:限制返回结果的数量为5 "text": "searchabc" // 查询参数:搜索文本为searchabc }, "method": "GET", // HTTP方法:GET请求 "bodyJson": { "fields" : ["name", "type", "date"], // 请求体:需要返回的字段列表 "query": { "type": "dust" // 查询条件:彗星类型为“dust” } }, "extractors": { "name": "$.results[*].fields.name" // 数据提取:从JSON路径提取每个结果的名称 }, "headers": { "Custom_Header": "my custom header value" // 自定义HTTP头部 } }
Elasticsearch
以下是使用Elasticsearch的示例。
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23{ "path": "geologist/_search", // 定义搜索路径 "method": "POST", // 使用POST方法发送请求 "bodyJson": { "query": { "prefix": { // 前缀查询 "request": "/daily/api/permalinks/" // 查找以"/daily/api/permalinks/"开头的请求 } }, "aggs": { // 聚合查询 "views": { "terms": { "field": "auth", // 按照"auth"字段分组 "size": 0 // 返回所有分组 } } } }, "extractors": { "Users": "$.aggregations.views.buckets[*].key", // 从聚合结果中提取用户信息 "Views": "$.aggregations.views.buckets[*].doc_count" // 从聚合结果中提取视图计数 } }
有关Elasticsearch的更多信息,请参见查询DSL文档 ↗。
服务API
SERVICEAPI 数据源类型专用于将公共API提供给Slate开发人员使用的Foundry服务。可用的服务可能会因Foundry实例而异,但通常包括搭建服务、Compass或目录服务。
对于每个添加的服务API,API的文档将会行内显示。特定的有效负载类型示例通常可以在request输入旁边的_显示详细信息_切换中找到。这些端点的安全性与普通的HTTPJSON数据源类型查询不同,因此您_不需要_对{{jsonstringify}}进行handlebar输入处理。
如果您希望为您的应用程序开发Foundry集成,请联系您的Palantir代表。
查询部分
查询部分允许您编写可在文档中的多个查询中重复使用的查询代码。要创建部分,请单击查询编辑器面板中的 + 新建部分 按钮。
您可以通过编写{{>partialName}}将部分插入到查询中。例如,假设您有一个名为columnFilter的部分,其内容为WHERE column={{param w8.selectedValue}}。您可以创建另一个查询,代码为SELECT * from table {{>columnFilter}}。这将呈现为查询SELECT * from table WHERE column={{param w8.selectedValue}}。
您还可以向部分传递参数,语法为{{>partialName arg1=value1 arg2=value2 arg3=value3}}。在部分的上下文中,参数的值将替换为您在特定查询中提供的值。值可以是静态值(如字符串或数字),或Handlebars引用(如w8.selectedValue)。在上面的示例中,如果您有两个完全相同的查询,但筛选条件是两个不同的选定值,您可以将columnFilter重新定义为WHERE column={{param columnValue}},并将查询更改为SELECT * from table {{>columnFilter columnValue=w8.selectedValue}},这将呈现为SELECT * from table WHERE column={{param w8.selectedValue}},与之前一样。
您还可以嵌套部分,允许在代码重用中实现代码重用。
部分是Handlebars的一个概念,而Slate实现使用Handlebars语法。请参阅Handlebars部分文档 ↗以了解更多信息。
条件查询
查询设置面板允许您控制查询运行的条件。运行查询有两个条件选项,您可以选择所有依赖项不为空,这意味着查询中的每个handlebars引用都必须不为null才能运行,或者您可以选择仅在此返回true时运行:,这将允许您指定一个handlebars条件。此条件可以是对函数、微件属性的引用,或任何您希望控制查询运行逻辑的内容。查询仅在此handlebars引用评估为true时运行,否则查询将不会运行。

示例1:所有依赖项不为空
以下查询需要至少一个值来自w_visits_bar.selection.data才能运行。

如果没有值存在,请求将因语法错误而在Postgres上失败。
添加条件仅在所有依赖项不为空时运行将防止已知的错误请求被发送到Postgres,否则会消耗连接和资源。

示例2:仅在此返回true时运行
以下查询获取用于填充选项卡容器中的微件的数据。假设微件在页面加载时不可见,但依赖于一组页面级筛选。在这种情况下,您可能会考虑为查询添加一个条件,仅在微件可见时运行。这可以通过在查询设置中使用仅在此返回true时运行选项来实现。


教程:让数据可用于Slate
您应尽可能仅使用Slate的平台选项卡中的对象集构建器加载数据。对象集构建器允许您轻松查询Ontology,并将数据以类似于下面示例的表格格式返回。下面解释的Postgres工作流程保留作为传统用法的参考。
在按照以下步骤同步您的新数据之前,请通过左侧边栏中的项目和文件下的项目视图查看Foundry培训和资源项目是否可用。
如果项目可用,请按照以下步骤操作,将Foundry参考项目的Ontology项目:航空文件夹中的flights和airports数据集添加到新应用程序中。在剩余的教程步骤中,使用flights数据集而不是last-mile-flights。
Foundry参考项目中的flights和airports数据集应已配置同步;如果使用这些数据集,您可以跳过下面的相关说明部分。
如果您没有使用Foundry参考项目中现有的flights和airports数据集,您必须将您上传到Foundry的last-mile-flights和airports数据集提供给Slate使用。打开数据集面板并选择**+添加**以打开Foundry资源选择器。

通过选择所有文件 > 入门数据导航到last-mile-flights数据集,或者在资源选择器中使用搜索框。一旦找到数据集,选择选择last-mile-flights选项开始导入配置。

要查看配置选项,请选择同步到Postgres旁边的箭头。

Postgres中的默认表名称将包括文件路径和混合大小写的数据集名称。为了处理特殊字符/、大写字母和空格,Postgres将把表名视为引用标识符。这意味着每当在查询中引用表时,您必须使用双引号,否则Postgres将抛出语法错误。我们建议在设置中包含一个使用蛇形命名法的小写字母和_的Postgresql表名称,以避免需要使用双引号。
由于数据访问模式尚未定义并且last-mile-flights数据集相对较小,我们不会在表上创建任何索引。您可以随时后期添加这些索引。选择应用并同步以开始同步。您可以使用检查状态按钮来监控同步。

同步完成后,您应该会看到一个在Slate中使用的示例查询,看起来类似于以下内容,尽管附加到您的数据集名称的编号会有所不同:
Copied!1 2SELECT * FROM "foundry_sync"."Getting Started Data/last-mile-flights-master-9406" LIMIT 10 -- 从表“foundry_sync”下的“Getting Started Data/last-mile-flights-master-9406”中选择所有列,限制返回结果为前10行
在搭建应用程序时复制查询以便日后使用。现在,将airports数据集同步到Slate。
创建查询
首先,创建一个SQL查询以从我们同步的数据集中提取所需数据。
选择 Queries 以打开编辑器。
您应该会看到一个 Queries 列表,一个 Partials 列表,以及一个编辑器。由于尚未创建查询,这些列表将为空。 选择 + New query。编辑器现在应显示工具栏、文本编辑器和查询结果预览面板。
在 Name 文本框中,输入 q_allFlights 作为查询名称。从 Source 下拉菜单中选择类型为FOUNDRY的数据源,以指向Slate到我们的数据库。请注意,此数据源可能被称为foundry-sync、foundry-postgate、foundry或类似名称,但始终在数据源名称的右侧显示FOUNDRY类型。
我们建议将查询命名为以q_这样的查询标识符开头,以便于识别。这种最佳实践在构建更大、更复杂的应用程序时尤其有用。
对于此查询,我们希望从数据库中的last-mile-flights表中提取几行数据。为此,我们可以在编辑器中使用之前复制的示例查询:
我们在下面使用的查询示例将使用“变量”作为特定表名的代替。例如,您会看到"foundry_sync"."{{v_flightTable}}",而不是"foundry_sync"."Getting started data/last-mile-flights-master-9406"。
可以通过选择测试,或在Windows上使用Ctrl+Enter或在macOS上使用Cmd+Enter来测试查询是否有效。这会将查询结果填入预览面板。
如果出现出错,请确保您已在Slate中提供last-mile-flights,并且您使用了正确的路径。
选择更新查询以保存查询。

可以通过选择 < / > 来查看原始JSON响应结构中的结果。
由于我们的数据集中有很多列,请优化查询以仅提取几个感兴趣的列:
Copied!1 2 3 4 5 6 7 8 9 10 11 12SELECT flight_id, -- 航班ID carrier_code, -- 航空公司代码 tail_num, -- 飞机尾号 origin, -- 出发地 dest, -- 目的地 dep_ts_utc, -- 出发时间(UTC) arr_ts_utc, -- 到达时间(UTC) distance, -- 距离 actual_elapsed_time -- 实际经过时间 FROM "foundry_sync"."{{v_flightTable}}" -- 从变量指定的航班表中选择数据 LIMIT 10 -- 限制结果为10条记录