注意:以下翻译的准确性尚未经过验证。这是使用 AIP ↗ 从原始英文文本进行的机器翻译。
数据输出至 Phonograph
不推荐使用 Phonograph 数据输出从 Slate 对 Foundry Ontology 进行更改。我们建议使用 操作微件中的操作来应用更新和更改到 Ontology。有关更多信息,请参阅操作类型文档。
本指南适用于无法配置操作以对 Ontology 进行自定义或复杂更改的用户。在继续进行 Phonograph 数据输出之前,请联系您的 Palantir 代表,查看操作是否可以适当地用于您的具体应用案例。
需要三个组件来从 Slate 中捕获用户输入/数据修改并将其保存到 Foundry:
- 源数据集: 这是您希望在 Foundry 中提供编辑的现有数据集。此数据集必须具有主键。
- Phonograph 同步: Phonograph 是一个手动编辑缓存,允许 Slate 捕获用户对源数据集的输入更改。您将数据集同步到 Phonograph(而不是 Postgres),这将使数据集在 Slate 中可用并允许用户编辑。
- 数据输出数据集: 这是您将在 Foundry 中创建的用于存储用户修改版本的源数据集。源数据集将始终保持不变,所有存储在 Phonograph 缓存中的用户编辑将保存到 Foundry 中的数据输出数据集中。
添加源数据集
首先,在 数据集 选项卡中将源数据集添加到您的 Slate 应用程序中。我们将使用 + 添加 按钮添加一个简单的派生数据集,名为 asteroid_notes。这个假想数据集包含小行星名称和一个名为 research_notes 的空白列,用于保存用户输入的小行星信息。
添加数据集后,您将查看数据集的同步设置。我们将配置同步到名为 Phonograph 的手动编辑缓存。
选择一个主键。您的主键选择必须唯一标识单个行。通常,您必须在变换中组合多个列以生成适当的主键,然后进行索引。可以定义一组列作为联合主键;但是,这增加了数据编辑的复杂性。
一旦配置了主键,我们将创建数据输出数据集,该数据集将存储用户在 Foundry 中的编辑。选择“浏览”在 Foundry 中创建一个数据集以保存您的编辑。在弹出窗口中,您将指定数据集的名称以及您希望在 Foundry 中创建数据集的位置。
完成后,您的同步配置应如下所示:

数据输出索引不支持 struct 列类型。这意味着具有 DateTime 列类型的数据集将出错。您可以使用 Contour 或 SQL 或 Python 变换在索引之前将 DateTime 列转换为 Timestamp。
当前无法通过 UI 注销(删除)同步。然而,针对 Slate 的使用,您可以在 "Table Registry - Unregister" 端点添加查询。唯一的参数是表 RID,结果将是表的删除——这不会影响输入或输出数据集。在相关数据集的同步 UI 中,您将看到不再有注册的数据输出同步。这将永久删除表中的所有数据,因此请谨慎使用,并确保您要么删除查询,要么将其设置为手动运行。
查询示例
随着我们的数据被索引到 Phonograph 中,我们现在可以从中读取和写入。最简单的模式如下:
- 使用查询获取所有行或行的子集并将其显示给用户。
- 用户通过应用程序微件交互以添加行、删除行或修改行中的值。
- 每次更改在用户提交时独立写回(例如,用户点击提交按钮)。
- 再次获取所有行以显示更改...
稍后,我们将探索一些选项,以便使用 bulk 端点增加复杂性,并将前端显示状态与后端数据状态分离,以保持应用程序的响应性,但这些都是高级主题。
选择行
要从表中检索所有行,我们需要创建一个新的 Slate 查询。
- 首先在 Slate 应用程序中创建一个新查询。
- 选择 "Phonograph2" 作为此查询的来源。
- 在 "Available Services" 字段中,选择
Table Search Service。 - 使用下面的代码填写此查询的
Search Request字段。您会注意到此请求使用了matchAll块,这将返回所有行。您需要填写表的 RID(在同步配置中可用),以及一个用于排序的列(非必填)。
q_getAllRows 示例
searchRequest
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14{ "tableRids": [ "<your_table_rid>" // 指定需要查询的表的ID ], "filter": { "type": "matchAll", // 过滤器类型为匹配所有记录 "matchAll": {} // 空对象表示没有特定的过滤条件 }, "sort": { "<your_column_to_sort_by>": { // 指定用于排序的列名 "order": "desc" // 排序顺序为降序 } } }
此查询模式允许分页——以减少浏览器的内存负担并提高性能——以及排序(通过添加一个 sort 块)。有关使用服务器端分页函数的更多信息,请参阅表格微件。
pagingToken
"{{w_tableWidget.gridOptions.pagingOptions.currentOffset}}"
// 当前分页偏移量
页面大小
"{{w_phonographResults.gridOptions.pagingOptions.pageSize}}"
这个代码片段没有涉及到计算机科学、数据工程、人工智能或数据科学的具体逻辑,因此不需要添加中文注释。
之前推荐用于检索行的 Get All Rows 端点已弃用。请按照上文所述迁移到 Search 端点,并如下更新 f_getAllRowsFormat 函数:
var rawData= {{getAllRows.result.[0].results.rows}}
变为
var rawData= _.map({{getAllRows.result.[0].hits}}, h => h.row)
q_getRows 示例
除了一次获取所有行之外,您还可以使用 Get Rows 端点提供主键对象列表,以通过其ID检索多行。这是检查当用户输入新值时行是否已存在的简单方法,这对于确定是将更改应用为编辑还是添加事件是必要的(更多内容见下文)。

在微件中显示查询结果
这些获取端点的结果是一个对象数组,其中每个对象代表一行,嵌套的primaryKey对象和columns对象的值代表该行的列:值对。Slate微件(如图表和表格)期望数据以并行数组的形式存在,其中每个数组代表一列,数组索引对应于给定行的值。此辅助函数从Get或Search中获取结果,并返回并行数组以输入表格或其他微件:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24var rawData= _.map({{getAllRows.result.[0].hits}}, h => h.row) // 提取所有行数据 var primaryKeys=Object.keys(rawData[0].primaryKey); // 获取主键列表 var columns=Object.keys(rawData[0].columns); // 获取列名列表 var parsedData={} // 初始化 parsedData 对象,添加主键和列名为属性 for (var pkey of primaryKeys) { parsedData[pkey]=[] } for (var column of columns) { parsedData[column]=[] } // 遍历每一行数据,将主键值和列值分别存入 parsedData 对应属性中 for (var row of rawData) { for (var pkey of primaryKeys) { parsedData[pkey].push(row.primaryKey[pkey]) // 将主键值加入对应列表 } for (var column of columns) { parsedData[column].push(row.columns[column]) // 将列值加入对应列表 } } return parsedData; // 返回解析后的数据
处理空值
数据中的空值不会被索引到Phonograph中。因此,包含空值列的行将不会出现在Phonograph中。在将Phonograph结果转换为行和列时,您可能需要考虑这些缺失值。下面是一个检测所有行中所有列的示例。此示例可以与上面的示例结合使用,以避免第一行中的空值问题。
Copied!1 2 3 4 5 6 7 8 9 10 11// 将queryResult定义为从getAllRows中获取的结果,遍历每个元素e,使用Object.assign合并primaryKey和columns属性到一个新对象中 const queryResult = {{getAllRows.result.[0].hits}}.map(e => (Object.assign({}, ...[e.row.primaryKey, e.row.columns]))); // 获取所有对象的键,并创建一个不重复的列名数组 const columns = [...new Set(...queryResult.map(e => Object.keys(e)))]; // 使用Object.assign将每个列名映射到其对应的值数组中,形成最终的queryResultFilled对象 const queryResultFilled = Object.assign({}, ...columns.map(e => ({[e]: queryResult.map(_e => _e[e])}))); // 返回填充后的查询结果 return queryResultFilled;
用于读取更新的搜索服务与存储服务
搜索服务端点使用关联Phonograph表的搜索索引。该搜索索引不会与存储服务的Post Event端点同步更新,这意味着在更改被写入和更改出现在对Search端点的查询之间会有一些小的延迟。一个简单的模式是使用一个Toast微件来创建一个计时器,例如:
q_postEvent.success->w_successToast.openw_successToast超时配置为5000(5秒)w_successToast.close->q_getAllRows
您可能需要调整Toast的持续时间以确保检索到更改后的行。还要确保在getAllRows查询中添加一个排序块,因为默认排序是按行文档的最后更新时间戳,这意味着编辑过的行将“移动”到所有结果的最后。
或者,为您的应用定义分离数据展示和数据持久化到Phonograph的模式。这可以通过使用状态变量来跟踪当前视图,然后在用户触发时周期性地将数据保存回Phonograph,但不自动重新运行查询以获取所有行。这种模式提供了更好的用户体验(更新即时出现),但需要更复杂的设计。
对Table Storage Service的任何请求,包括通过primaryKey值列表检索行,均保证包括所有编辑,因此可以安全地链接事件,如:q_postEvent.success -> q_getRowByPrimaryKey.run
在这种情况下,通过主键查找检索到的特定行的任何更改均保证包含在结果中。
编辑数据
Table Storage Service上的Post Event端点处理三种类型的事件:rowAdded、rowDeleted和rowModified。
所有三种事件的查询都需要一个包含primaryKey对象和payload对象的tableEditedEventPostRequest,如下所示:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15{ "primaryKey": { "<primary_key_col>": "<primary_key_value>", "<second_primary_key_col>": "<second_value>" // 如果在创建手动编辑索引时指定了多个列,则需要此字段 }, "payload": { "type": "rowModified", // 可能的值为 "rowAdded" 或 "rowDeleted" "rowModified": { // 可能的值为 "rowAdded" 或 "rowDeleted" "columns": { "<col_a>": "<new_value>", // 修改后的新值 "<col_b>": "<new_value2>" // 修改后的新值 } } } }
这个JSON结构用于表示数据库行的变化,支持行的添加、修改和删除。primaryKey部分用于标识唯一的行,payload部分描述了行的操作类型和具体的修改内容。
rowDeleted事件有一个空的rowDeleted对象 - 您无需传递列来删除一行。
通常的最佳实践是使用一个函数来搭建tableEditedEventPostRequest。这些函数可以根据所需的工作流程和实现采取多种不同形式。
示例函数f_createTableEditEvent:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24// 获取用户选择的行 var selectedRow={{q_getAllRows.result.rows.[w_rowsTable.selectedRowsKeys.[0]]}}; // 提取选择行的列数据 var updatedCols=selectedRow.columns; // 更新列数据中的研究笔记 updatedCols.research_notes={{w_notesInput.text}} // 构造一个用于发送表格编辑事件的POST请求对象 var tableEditedEventPostRequest = { "primaryKey":{ "name": selectedRow.primaryKey.name, // 主键名称 }, "payload": { "type": "rowModified", // 事件类型为行修改 "rowModified": { "columns": updatedCols, // 修改后的列数据 } } } // 返回构造的请求对象 return tableEditedEventPostRequest;
在上面的简单函数示例中,所有来自 q_getAllRows 的行都显示在 w_rowsTable 微件中。一个表示行号的列被添加到表中作为选择键,这样通过在 w_rowsTable 中选择一行,我们可以使用选择键在 q_getAllRows 的原始结果中找到该行。选中一行后,我们可以将 w_notesInput 微件中用户输入的值更新到 research_notes 列中。这发生在这一行:updatedCols.research_notes={{w_notesInput.text}})
函数 f_createTableEditEvent 的最后一步是将 updatedCols Object 插入到 tableEditedEventPostRequest 变量中并返回它作为函数的结果。无论您需要多么复杂的操作,这都应该是函数的输出,并且可以直接输入到您的查询中。
一旦函数完成,您可以将函数的输出,即 tableEditedEventPostRequest Object,插入到 updateRow 查询的适当参数字段中(见下图)。
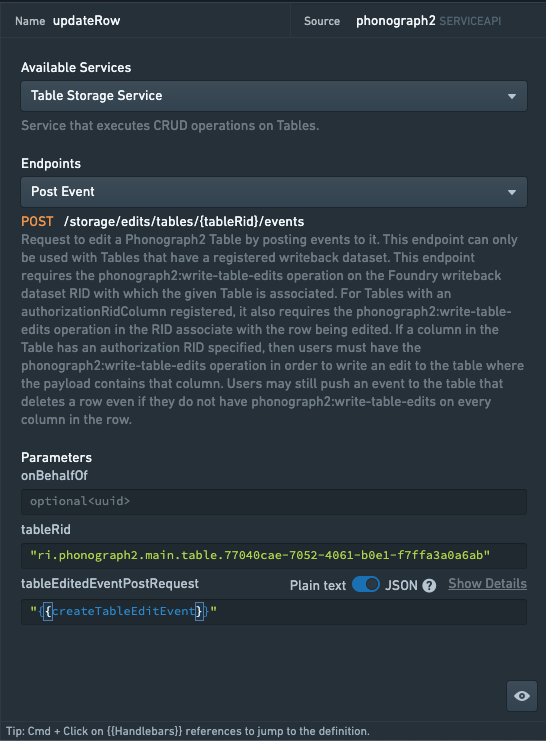
将查询设置为手动运行
现在查询具有适当的参数,我们将定义我们希望查询运行的条件,以便只有在应该对表进行编辑时才进行。
在查询编辑器中查看查询时,使用运行旁边的下拉菜单检查手动运行。这可以防止查询在页面重新加载或其依赖项更改时运行。
我们现在将为查询配置一个触发器,使其在某些用户操作时运行。最简单的方法是添加一个按钮微件,并在 button.clickevent 上触发查询,尽管还有许多其他可能的解决方案。将一个按钮微件添加到 Slate 应用程序,并配置查询在点击时运行。请注意,运行此查询只会更新 Phonograph 缓存(编辑不会立即在 Foundry 的数据输出数据集中看到)。
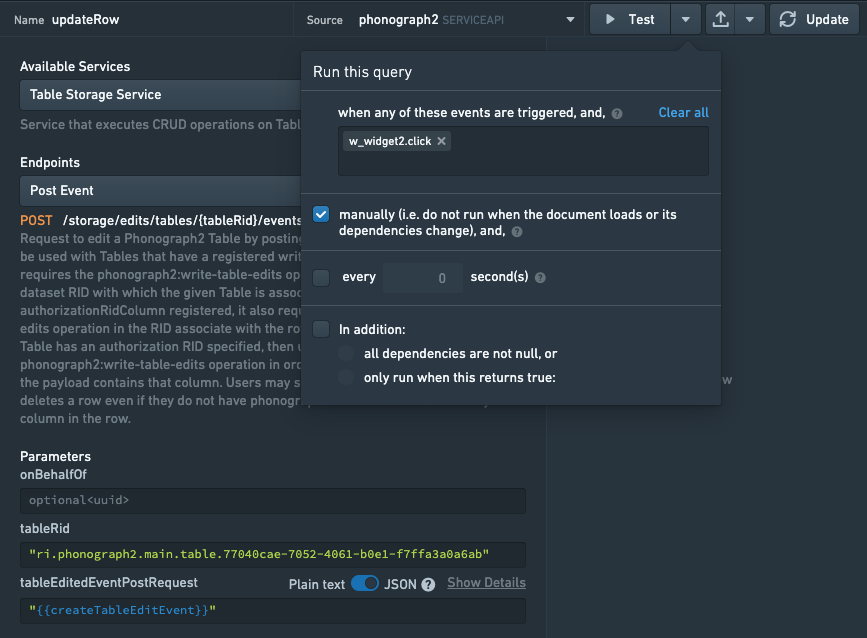
此外,通常的最佳实践是编写一个单独的函数来验证表单输入并生成反馈文本以显示在您的表单旁边。这有助于防止由于用户输入数据导致的数据质量问题。用于执行此操作的函数可能如下所示:
f_validateForm
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21var form = { // 定义一个表单对象 disableSubmit: false, // 提交按钮的禁用状态,初始为false globalMessage: "", // 全局信息,用于显示整体表单的状态或错误信息 fields : { // 表单字段集合 i_widget1: { // 第一个小部件的设置 value: {{i_widget1.text}}, // 从某个外部对象获取的初始值 message: "" // 用于存储该字段的错误或提示信息 }, i_widget2: { // 第二个小部件的设置 value: {{i_widget2.text}}, // 从某个外部对象获取的初始值 message: "" // 错误:缺少冒号(:)和初始值 } // 可以继续添加其他字段设置 } // 注意:缺少逗号(,)导致语法错误 } // 逻辑部分:用于验证字段值,生成每个小部件的提示信息,并确定整体表单的有效状态 // 如果值被认为是无效的,则将disableSubmit设置为true return form; // 返回表单对象
您可以通过将微件的 disable 属性链接到 "{{f_validateForm.disableSubmit}}" 来禁用按钮微件。
添加新行
添加新行的操作与编辑行相同;只需在上面的例子中将 rowAdded 替换为 rowModified。
需要注意的是,尝试添加与现有行具有相同主键的新行将会失败。一个简单的解决方案是触发一个toast微件来简单地提醒用户该行已存在。
一个稍微更友好的选项是在 Get Rows 端点上使用 q_validatePrimaryKey 查询,以用户输入的主键检查该行是否已存在。如果存在,则在 f_createTableEditEvent 中生成一个 rowModified 事件,否则使用 rowAdded。
删除行
要删除一行,只需使用 Post Event 端点提交一个带有要删除行的主键的 rowDeleted 事件。
Copied!1 2 3 4 5 6 7 8 9{ "primaryKey": { "<primary_key_col>": "<primary_key_value>" // 主键列和对应的值,用于标识被删除的行 }, "payload": { "type": "rowDeleted", // 指示操作类型为行删除 "rowDeleted": {} // 包含被删除行的信息,此处为空对象,表示行已被删除 } }
搜索行
表搜索服务在需要通过值而不是通过主键查找行时提供一个搜索端点。语法类似于ElasticSearch搜索语法。您可以在API文档 ↗中找到可用搜索类型的完整规范。
所有搜索返回一个包含嵌套hits对象的对象;如果您将此对象传递到获取行部分的解析函数中,替换rawData变量中的.rows,您可以使用相同的逻辑将结果分解为可以在表微件中显示的并行数组。
所有文本类型的列都由默认的ElasticSearch索引器处理,该索引器在非单词字符上对字符串进行词元化。这可能导致在查找精确匹配时出现意外的搜索行为。要进行精确匹配,您可以使用queryString搜索类型,并使用字符串字面量字符转义搜索词:\"8156-Apron 2 P.2\"
Terms 筛选
terms筛选类型接收一个值数组,并可以跨所有列匹配,或者 - 非必填 - 针对field属性中指定的单个列匹配。请参阅上面关于词元如何被索引的说明。
searchRequest
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16{ "tableRids": [ "{{f_getTableId}}" // 这个字段用来获取表格的ID ], "filter": { "type": "terms", // 过滤器的类型是“terms” "terms": { "field": "first_name", // 过滤的字段是“first_name” "terms": [ "agnese", "ailee", "woodman" // 要过滤的名称列表 ] } } }
queryString 筛选
queryString 筛选类型尝试提供与自然语言搜索等效的搜索。您可以包含 AND 和 OR 操作符,并引用多个词以实现精确匹配:例如 \"multi word exact match\"
searchRequest
Copied!1 2 3 4 5 6 7 8 9 10 11{ "tableRids": [ "{{f_getTableId}}" ], "filter": { "type": "queryString", // 过滤器的类型为查询字符串 "queryString": { "queryString": "jang" // 查询字符串的内容为"jang" } } }
此 JSON 配置用于查询特定表(通过 f_getTableId 函数获取表 ID),并使用查询字符串 "jang" 作为过滤条件。
范围筛选
范围筛选为数值型和日期型列提供比较筛选。支持 gt、gte、lt、lte。
searchRequest
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13{ "tableRids": [ "{{f_getTableId}}" ], "filter": { "type": "range", // 过滤器类型为范围 "range": { "field": "start_date", // 指定过滤的字段为 start_date "lt": "2018-01-01", // 过滤条件为小于 2018-01-01 的日期 "format": "yyyy-MM-dd" // 日期格式为 年-月-日 } } }
GeoBoundingBox 和 GeoDistanceSearch 筛选
如果您在管道中生成了geohashes ↗,那么您可以使用这些筛选进行边界框和半径搜索。
请联系您的 Palantir 团队以获取这些查询的示例。
复杂筛选
所有筛选类型都可以与 AND 和 OR 筛选类型嵌套,以构建更复杂的筛选逻辑。一个常见模式是使用函数生成这些复杂查询,并将函数的输出简单地包含在查询的 searchRequest 参数中。
searchRequest
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23{ "tableRids": {{f_getTableId}}, "filter": { "type": "and", "and": [ { "type": "queryString", "queryString": { "queryString": "pixoboo" // 查询字符串 } }, { "type": "terms", "terms": { "field": "first_name", // 字段名:first_name "terms": [ "harcourt" // 查询的值:harcourt ] } } ] } }
数据输出到 Foundry
我们编写的 updateRow 查询只会更新存储在 Phonograph 中的 asteroid_notes 副本。为了让数据在 Foundry 中显示,我们需要在 Foundry 中的数据集预览页面上点击 "搭建"。

一旦完成,我们可以看到对 research_notes 的编辑出现在 asteroid_notes_edited 中。

高级
批量端点
除了我们上面看到的 Post Event 端点,Table Service 还提供了一个 Post Events for Table 端点,它需要一个 tableEditedEventPostRequest 数组,就像我们之前生成的那些。事件可以是多种类型(rowModified、rowAdded 或 rowDeleted),但是一个给定的 primaryKey 在数组中只能出现 一次,这意味着在一个请求中,您不能对同一个 primaryKey 有例如 rowModified 和 rowDeleted 事件。
Post Events for Table 请求
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24[ // 事件请求1 { "primaryKey": { "primary_key_col": "primary_key_value", // 主键列和对应的值 }, "payload": { "type": "rowModified", // 可以是 "rowAdded"(行添加)或 "rowDeleted"(行删除) "rowModified": { // 当 type 为 "rowModified" 时使用;如果是 "rowAdded" 或 "rowDeleted",则改为相应的键名 "columns": { "col_a": "value", // 列名和对应的值 } } } }, { "primaryKey": { "primary_key_col": "different_primary_key_value", // 另一个主键列值 }, "payload": { "type": "rowDeleted", // 可以是 "rowAdded"(行添加)或 "rowDeleted"(行删除) "rowDeleted": {} // 当 type 为 "rowDeleted" 时使用,内容为空 } }, 等等...
我们将在下文讨论如何使用批量端点和事件框架来搭建更强大的解决方案以处理更改的延迟。
管理延迟
由于手动编辑缓存的底层架构,编辑后不保证立即在主索引中可见,即使调用Post Event成功。目前正在进行工作以使Get All Rows和Get Rows调用同步,因此如果您设置q_getAllRows在q_postEditEvent查询成功后触发,则可保证任何编辑都会出现。然而,如果您依赖于search端点,则需要容忍几秒钟的延迟,直到搜索索引更新。
最简单的方法是在编辑查询和获取所有行查询之间插入一个toast。在q_postEditEvent.success事件上触发toast,并设置3-4秒的持续时间(3000-4000毫秒)。然后可以在w_editSuccessToast.closed事件上触发q_getAllRows查询,这样的延迟应提供足够时间更新索引。
对于更复杂的工作流,您可能需要进行额外的工作以将显示在Slate应用中的状态与编辑索引的状态分开。为此,在页面加载时,您需要使用q_getAllRows查询的结果填充Slate变量,这将成为您的“前端状态”。所有的编辑/删除/更新事件将更改此前端状态变量,而不是直接触发后端的查询。您可以定期将前端变量的状态与查询的数据进行对比,并创建批量查询的负载以应用所有更改。
您可能还希望通过toast或“未保存更改”计数器以及手动保存按钮为用户提供一些反馈。此设置对于复杂、长期运行的应用程序以外的任何东西来说都是繁重的。在大多数情况下,toast方法就足够了,对Get Rows和Get All Rows端点的改进应该很快会使这种方法在几乎所有情况下都变得多余,所以如果您在考虑这个选项,最好还是与Palantir团队进一步讨论。
聚合
search端点也支持聚合以生成统计数据和对索引数据进行分组。
支持ElasticSearch 2.0 聚合 ↗语法的子集:value_count、max、geohash_grid、terms、top_hits、sum、cardinality、avg、nested、filter、histogram、min。
请注意,由于Elasticsearch的限制,某些聚合的结果可能是近似值。在使用任何类型的聚合之前,请参阅Elasticsearch文档并了解其是精确值还是近似值。如果是近似值,您应决定这对于您的应用案例是否可以接受,然后再继续。
以下是语法的简单示例。请注意,必须使用visits字段的原始版本,并且需要启用“精确匹配”,因为我们正在以字符串字段进行聚合。

Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16{ "tableRids": [ "{{f_getTableId}}" ], "filter": { "type": "matchAll", // 使用matchAll类型的过滤器,表示匹配所有记录 "matchAll": {} // matchAll的具体实现为空对象,适用于匹配所有数据 }, "aggregations": { "visits": { "terms": { "field": "visits.raw" // 基于visits.raw字段进行词条聚合 } } } }
上述查询将根据查询中筛选部分的visits字段的值对所有行进行分组,并返回计数。如果您只对聚合值感兴趣,可以将pageSize设置为0,以从结果中移除单个记录命中,从而减少应用程序的加载时间和内存压力。
返回格式将如下所示:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21"aggregations": { "genders": { // 聚合结果的名称 "doc_count_error_upper_bound": 0, // 文档计数的误差上限 "sum_other_doc_count": 30, // 其他文档的总计数 "buckets": [ // 桶集合,表示不同类别的文档计数 { "key": "daily", // 桶的键,表示类别名称 "doc_count": 148 // 此类别的文档数量 }, { "key": "often", // 桶的键,表示类别名称 "doc_count": 141 // 此类别的文档数量 }, { "key": "weekly", // 桶的键,表示类别名称 "doc_count": 129 // 此类别的文档数量 }, ... ] } }
每种聚合类型将具有略微不同的返回语法,但您可能会发现行到列函数在处理此类数据时对图表或表格等Slate微件非常有价值。