- Capabilities
- Getting started
- Architecture center
- Platform updates
Announcements
REMINDER: Sign up for the Foundry Newsletter to receive a summary of new products, features, and improvements across the platform directly to your inbox. For more information on how to subscribe, see the Foundry Newsletter and Product Feedback channels announcement.
Share your thoughts about these announcements in our Developer Community Forum ↗.
View raw prompts and outputs in Pipeline Builder
Date published: 2024-11-26
We are excited to announce that you can now view the raw prompts and outputs in the Use LLM node in Pipeline Builder. To access this new feature, navigate to the Trial run section in the Use LLM node and select the </> icon for the specific trial run you want to analyze.
This enhancement provides greater visibility into the data being sent to the LLM, improving transparency and making it easier to debug your LLM runs.
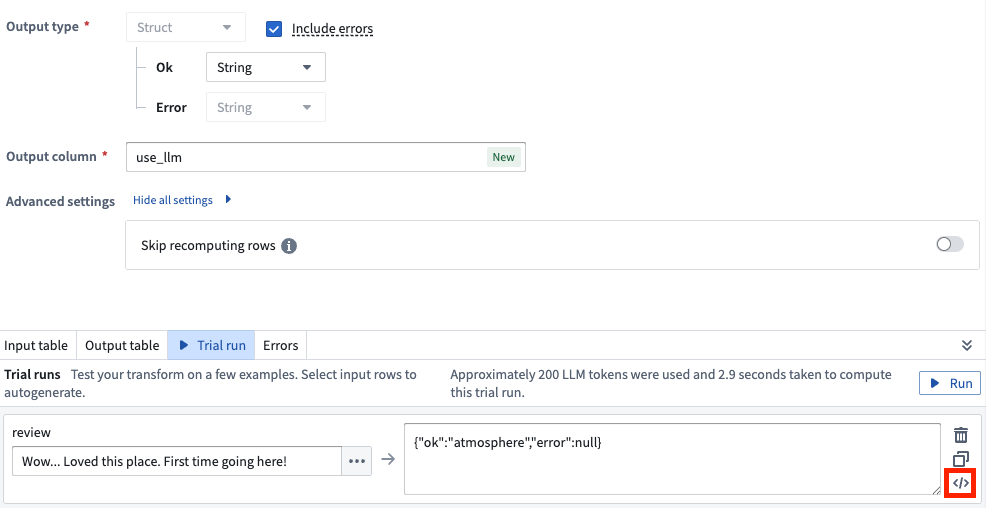
Select the </> icon to view the raw prompts and outputs from the Use LLM node.
The Use LLM node now displays:
- Initial Prompt: The exact prompt sent to the model, including any modifications or additions made by Pipeline Builder.
- Intermediate LLM Outputs: All outputs from the LLM, including any failed outputs.
- Corrections: Details on corrections made for any failures.
- Final Output: The ultimate result provided by the LLM.
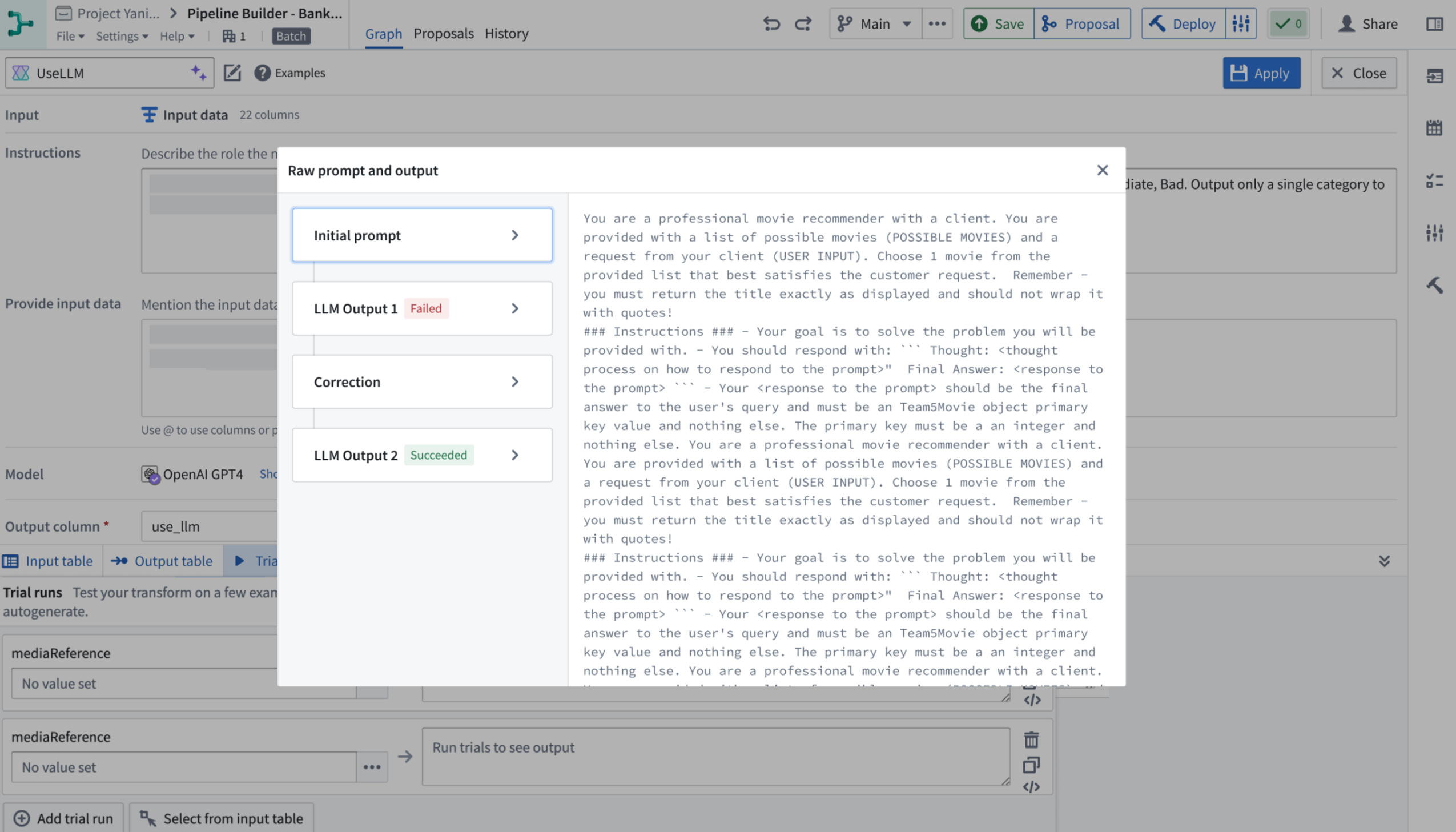
Example raw prompts and output displayed by the Use LLM node.
Learn more in the trial run documentation.
Create custom in-platform tutorials with Walkthroughs [Beta]
Date published: 2024-11-26
This feature is now generally available; read the latest announcement.
Register any external LLM as a specialized Typescript function and use it in Logic [GA]
Date published: 2024-11-21
It is now much easier to integrate your own LLM and use it in the Palantir platform. You can now use your models in the useLLM board in AIP Logic by externally querying them from a specialized TypeScript function that implements the new function interface primitive.
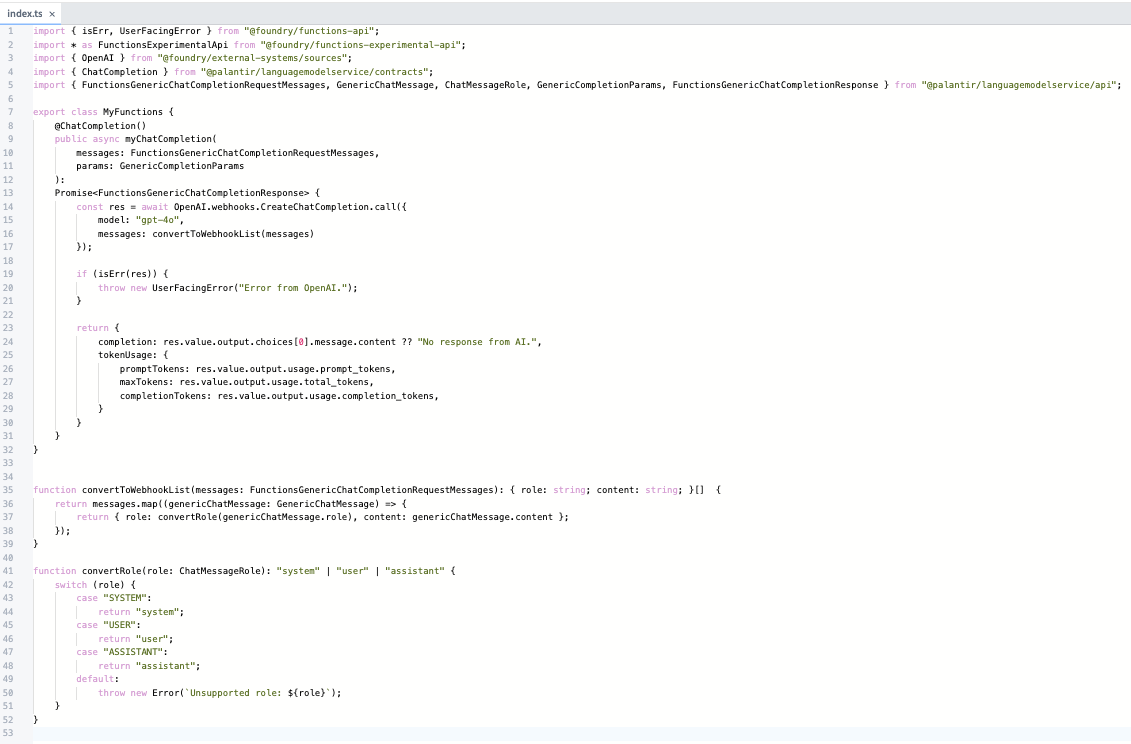
A view of the ChatCompletion function.
Rapid integration of new models: Increasingly, there are models being released that are faster and cheaper for specific workflows and use cases. Although Palantir will continue to provide quick support for first-class models from providers like OpenAI, Anthropic, and Gemini, we want you to be able to experiment with any new LLM immediately after its release. With this feature, you can connect a new LLM into the Palantir platform in less than 15 minutes.
First-class accessibility across the Palantir platform: External model sources are no longer confined to Code repositories. LLMs registered with this feature are immediately available in Logic's useLLM. Additionally, support for accessing these models in Builder's useLLM board and AIP Agent Studio is currently in beta and will be generally available (GA) early next year. Contact your Palantir representative if you would like to try this new feature in Pipeline Builder.
Improved authoring experience: The TypeScript code authoring environment streamlines the work needed for you to register your external LLM under a unified, yet customizable, API. Simply implement the function interface with the types provided and call the external source of your choice.
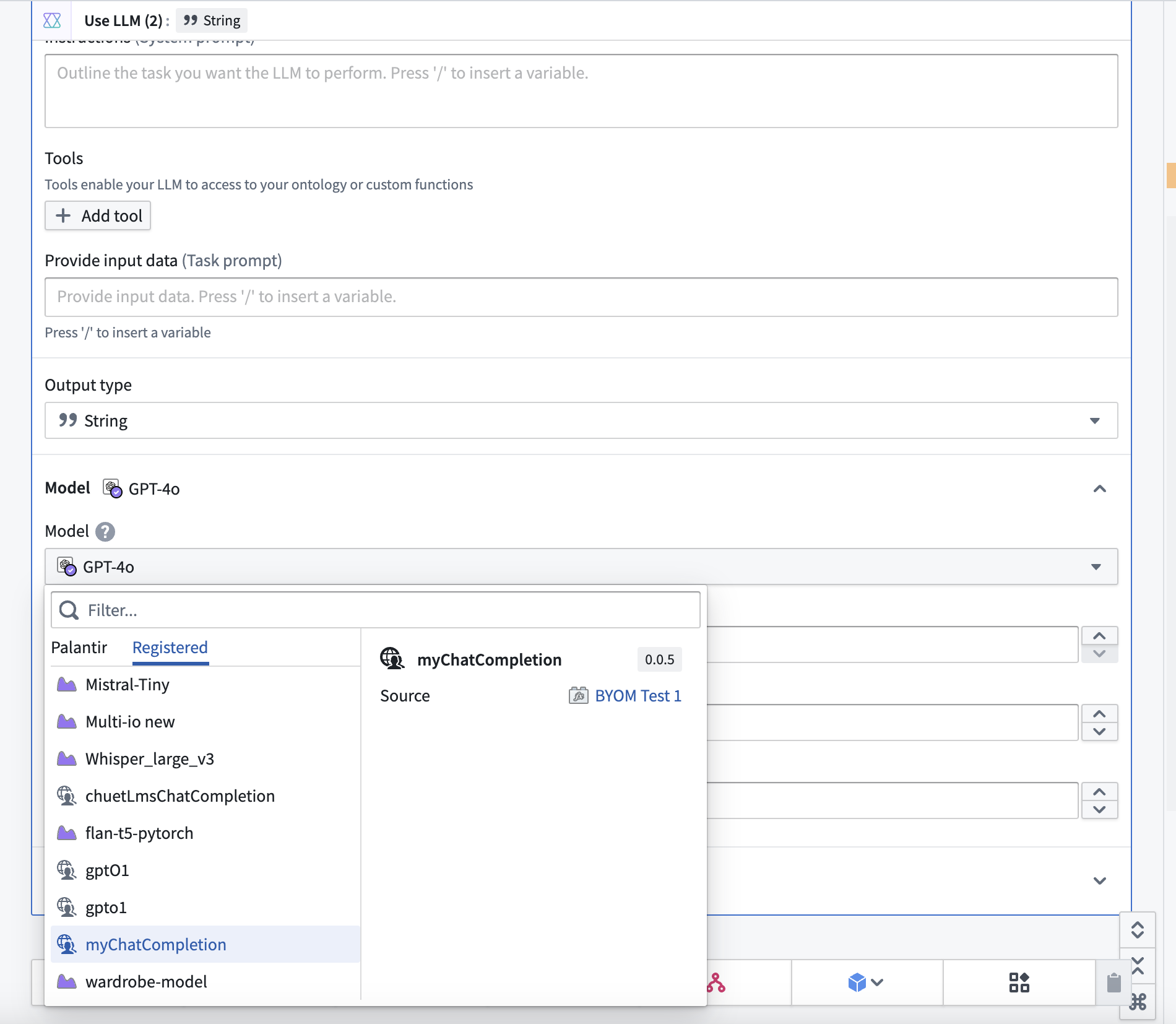
Using your custom model in AIP Logic is now easier. Select your model from the dropdown menu to begin.
Review the Function interface documentation to learn more.
Protect sensitive image data using the visual obfuscation algorithm in Cipher [GA]
Date published: 2024-11-21
The visual obfuscation algorithm is now generally available when you create a Cipher channel to reversibly obfuscate portions of images. As a core Foundry security and governance service, Cipher enables users to obfuscate data through cryptographic operations managed through channels, which describe a specific protocol for an encryption framework. Unlike traditional image redaction, the visual obfuscation algorithm is commutative, reversible, and obscures portions of images by scrambling their RGB pixel values. Users can encrypt and decrypt images with the appropriate Cipher licenses that control permissions to use cryptographic operations defined in a channel. Additionally, you can use the visual obfuscation algorithm in Python transforms to redact entire images or portions containing sensitive contents.
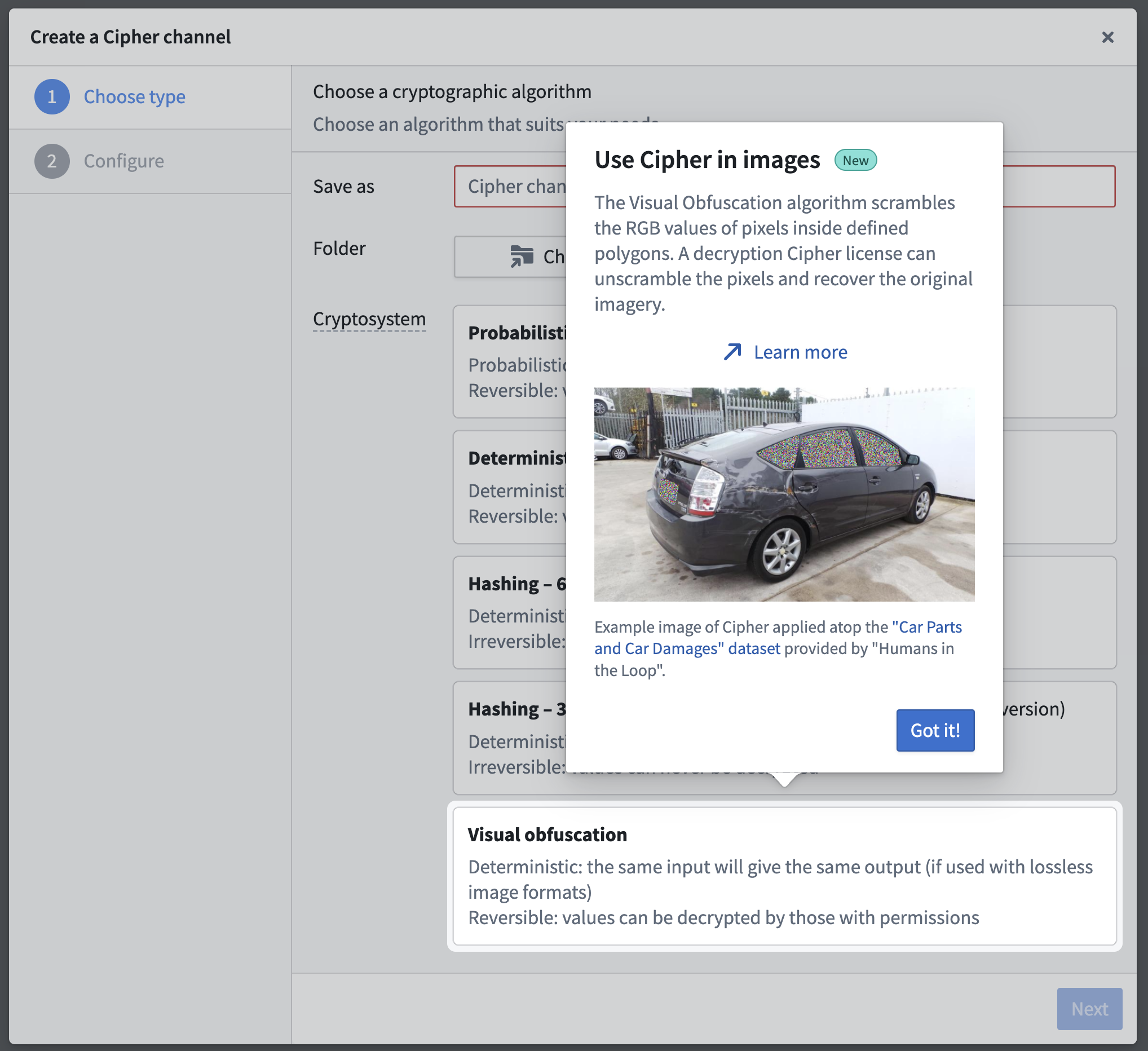
The visual obfuscation algorithm is now generally available when you create a new Cipher channel.
Media sets serve as key data assets powering a variety of Foundry workflows. Images contained in media sets, much like tabular text-based data, often require strict protection of their potentially sensitive content through granular data governance. Visual obfuscation's reversibility provides an additional level of data minimization and permission management for an image's sensitive content, as a user with the necessary access granted through a Cipher decryption license can recover an image's obfuscated sections. Users can share an image across different access groups for analysis as a singular data asset - users in one group may be able to view the image's original content, while users in another will only be able to view the image with sensitive regions obfuscated by default.
Apply visual obfuscation to improve image security and access
Administrators can configure a visual obfuscation decryption license to impose limits on decryption frequency. An administrator may also require users to submit a checkpoint as justification for viewing sensitive imagery, which collects records of image interactions.
As an example, a user trained to tag the damaged areas of a car can complete their workflow by viewing an image of the car with its sensitive regions obfuscated, such as the license plate and windows showing the interior. Another user trained to provide customer support can access the same image and decrypt the license plate region to confirm that the vehicle belongs to a specific customer. Additionally, an administrator can verify that the customer support user's interactions adhere to the decryption license's prescribed data governance policy.

Users can apply the visual obfuscation algorithm to obscure potentially sensitive regions of an image. Image source: Car Parts and Car Damages ↗ provided under a CC0 license.
How and when to use visual obfuscation
Since its beta release, Foundry users have applied visual obfuscation in tandem with object detection models to identify and obscure personally identifiable attributes within images before human access, reducing bias during analytical workflows. You should use PNG files, as other image file types may not support pixel scrambling during encryption and decryption.
You can use visual obfuscation to:
- Redact image sections containing PII (Personally Identifiable Information) or PHI (Protected Health Information) before providing an image to an OCR (Optical Character Recognition) or text extraction model.
- Reduce an image's sensitivity level by selectively obfuscating certain sections in order to broaden user access to support analysis.
- Hide parts of images that may introduce bias into a workflow and require a justification to reveal the obfuscated section.
- Add an additional layer of protection against possible data leaks or permission misconfigurations.
- [Beta] Interact with obfuscated imagery using the Image Display widget in Workshop, as seen below.

Window areas which have been visually obfuscated are selected and decrypted using the beta Image Display widget in Workshop.
Contact your Palantir representative to install visual obfuscation on your Foundry enrollment if it is not currently available.
For more information, review Cipher's visual obfuscation documentation.
Introducing Portfolios, a new way to organize Projects [GA]
Date published: 2024-11-21
We are excited to introduce Portfolios, a new way to organize Projects. Editors of Spaces can add Projects to a Portfolio to create a one-stop catalog of datasets, applications, and other important resources. This is especially useful for enrollments with many Projects, as administrators can curate a few Portfolios for users to navigate rather than hundreds of Projects.
Portfolios can group Projects in a number of ways. Administrators can curate Portfolios to represent:
- A business unit or department. All the resources under that team's oversight are grouped together, making navigation and discovery easy for users.
- A specific product or workstream. All the product or workstream's resources are brought into a single view while respecting the separation of concerns for Projects that individually handle data integration, analysis, and operational applications.
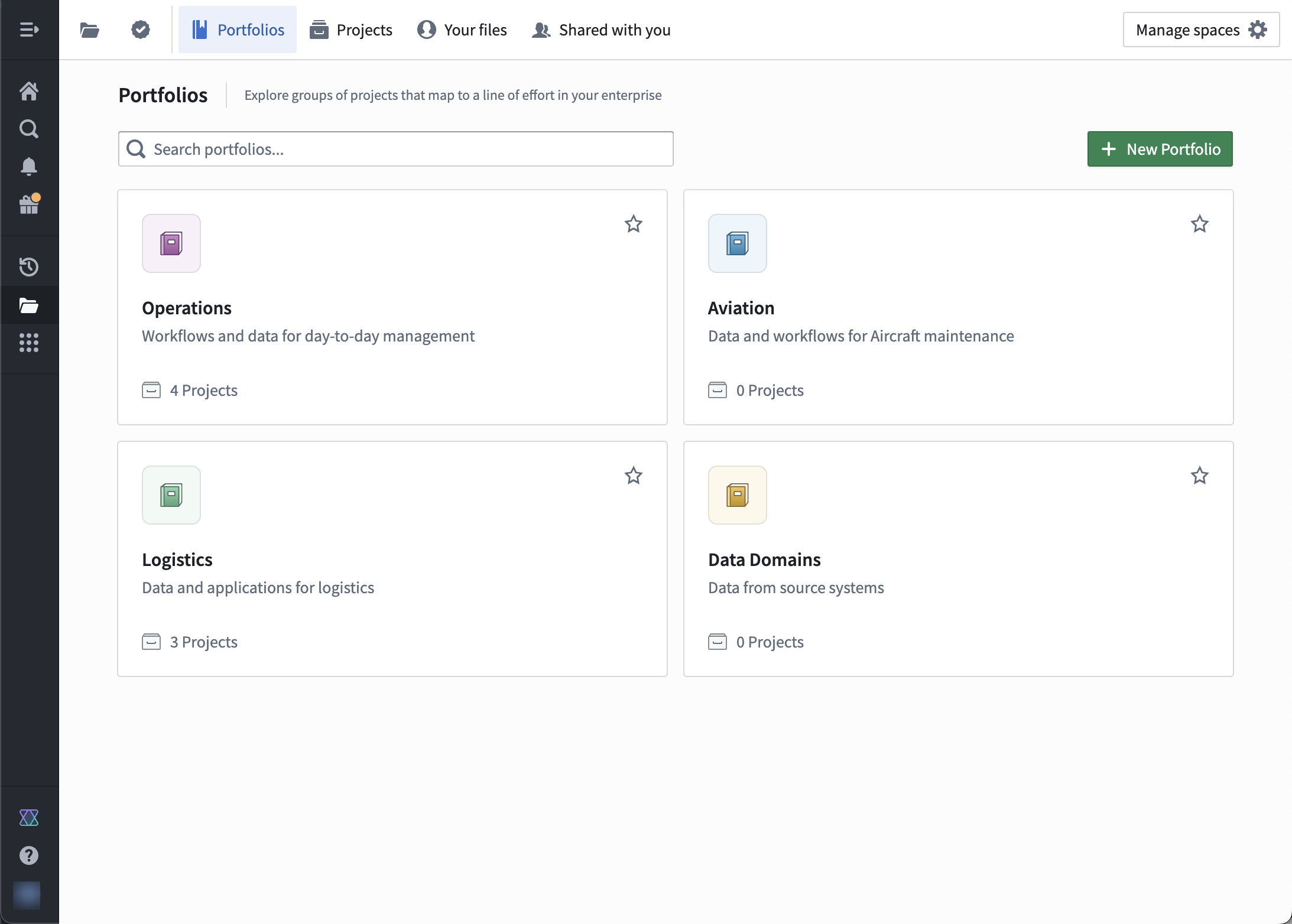
Example of Portfolios for different use cases.
Each Portfolio contains many Projects, but each Project belongs to at most a single Portfolio. Any user with access to a Space can view its Portfolios, but users still separately need permissions to view the Projects inside a Portfolio.
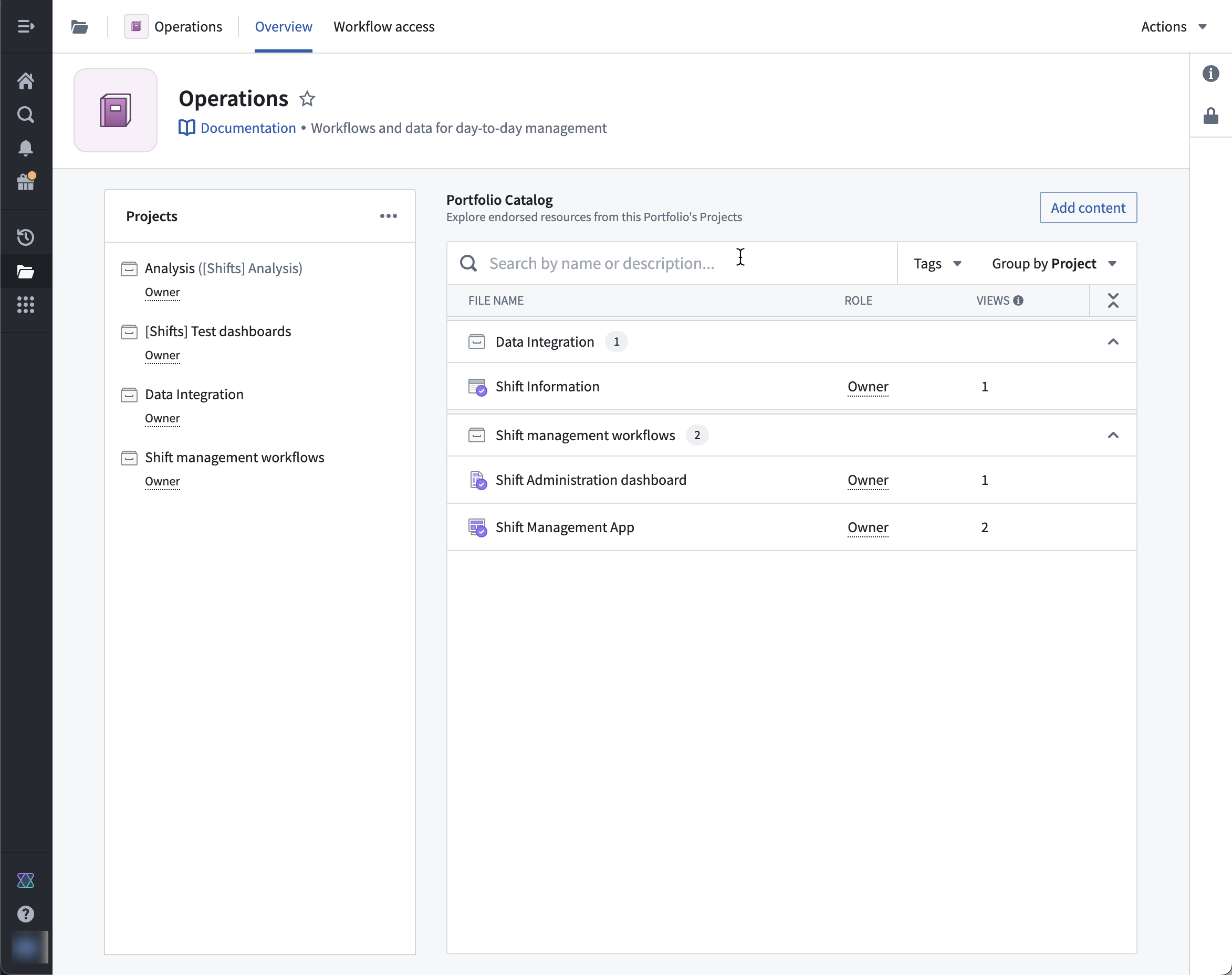
Example Portfolio that contains four Projects.
Important resources that have been added to a Project catalog or collection appear in the Portfolio catalog for ease of access.
Key features of Portfolios
- Users can easily discover and navigate to the Projects in their line of effort.
- Users can view Projects by Portfolio, and no longer need to navigate the entire Project list at once.
- Portfolios provide a single-pane view for all the Projects that make up a work area.
For more information, see the Portfolios documentation.
Authentication and user management through intake forms [GA]
Date published: 2024-11-21
Intake forms are generally available the week of November 18, 2024.
Platform administrators can create authentication intake forms from Foundry's Control Panel to capture, review, and supplement user information not provided through their identity provider integrations. Intake forms can be used to gather and enhance user data required for platform access management, particularly in instances where certain information may not be obtained from identity providers.
User attributes captured through intake forms need to be reviewed and approved before they are assigned to a user. Additionally, intake forms can also gate access to the platform until appropriate approval.
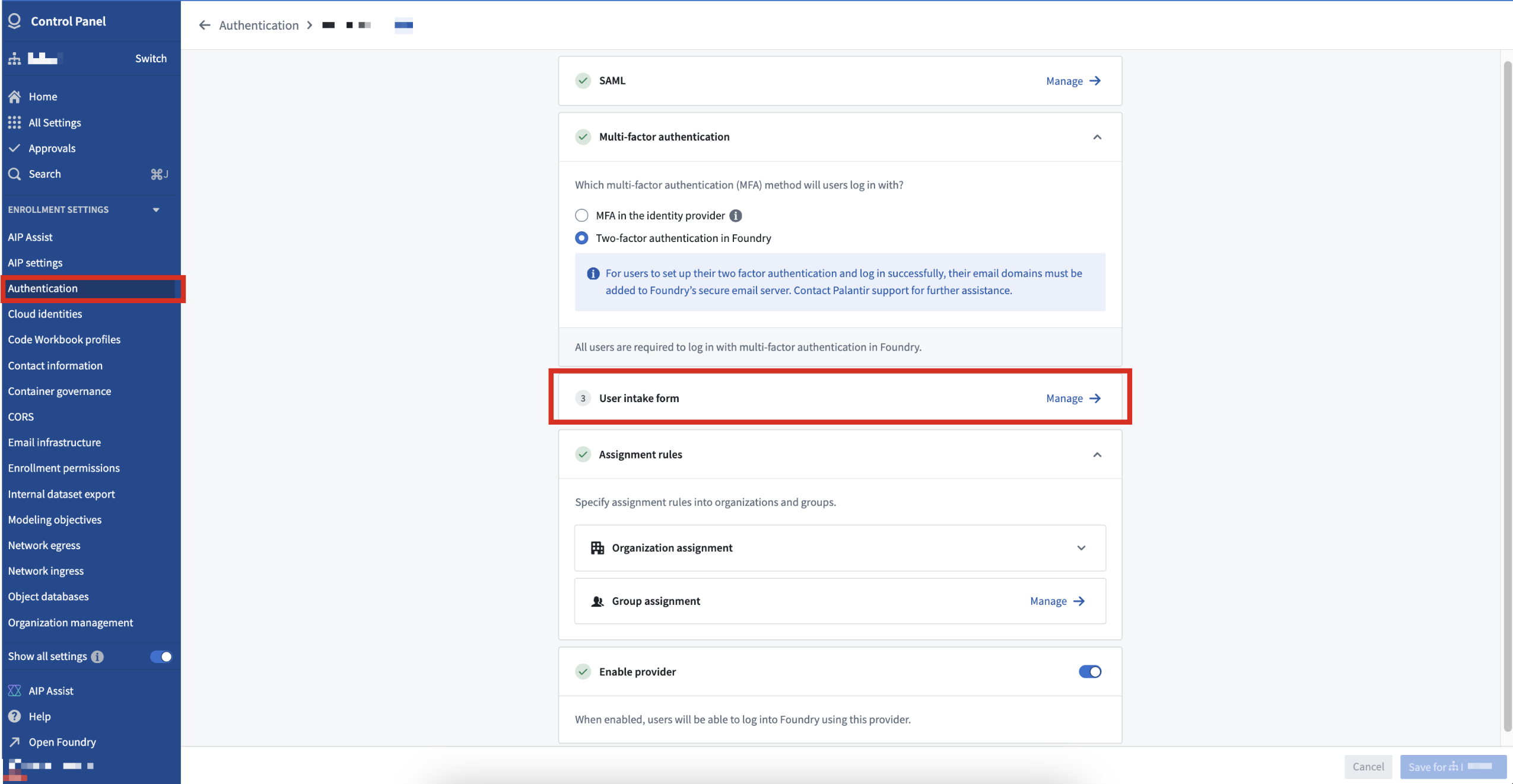
User intake forms created in the Control Panel supplement authentication information not inherited from an identity provider.
After a platform administrator publishes an intake form, users complete the form at the time of their first login and receive platform access upon approval. After submission, users can view their intake form's status and resubmit a new form, if necessary.
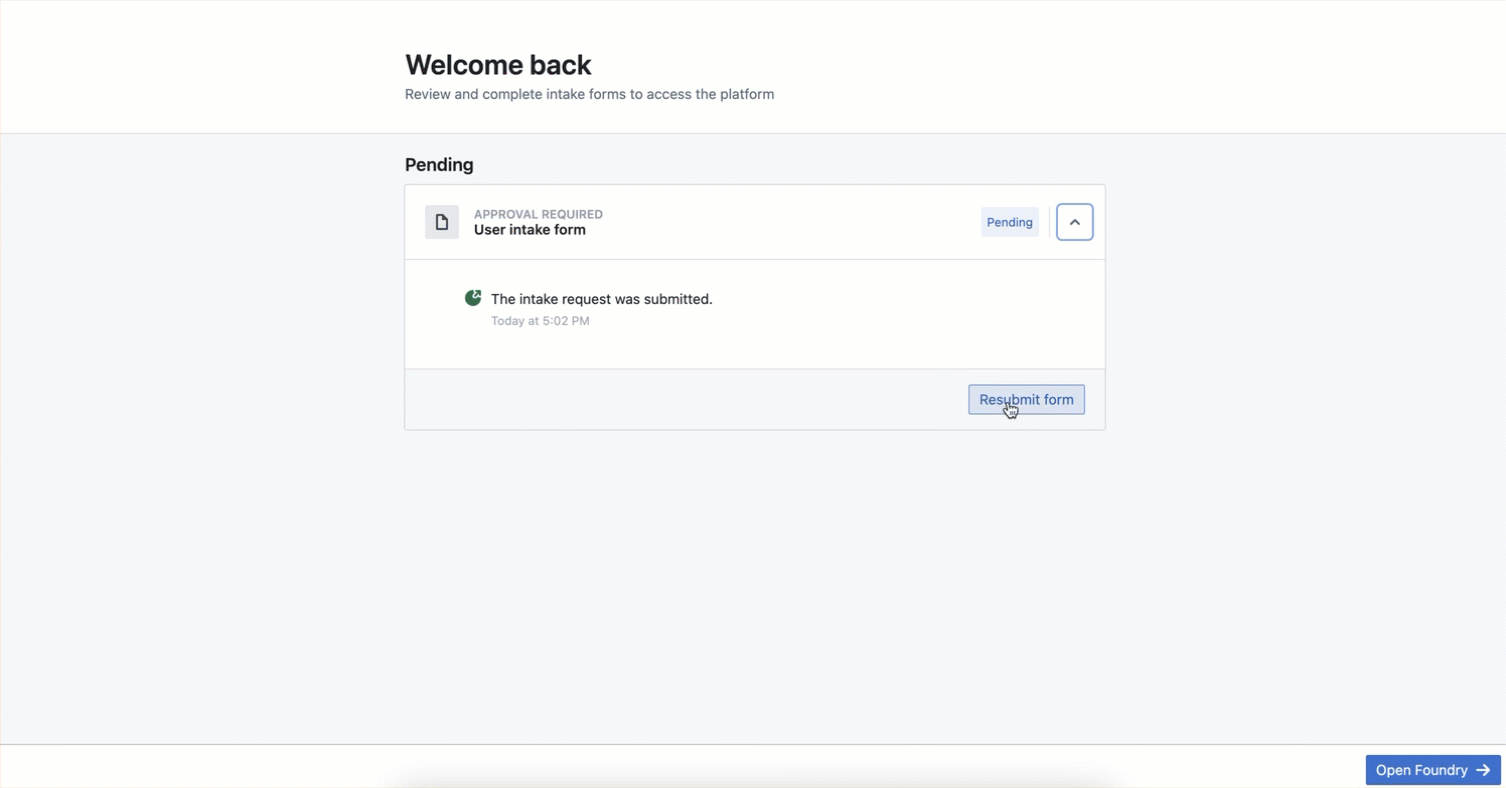
Users can view their intake form's review status or resubmit a new form to garner platform access.
Since their introduction, intake forms have been used in combination with automatic group assignment based on user attributes to streamline effective authorization management.
Palantir's platform authentication documentation offers additional detail about intake forms.
Create, configure sources and data syncs in Pipeline Builder
Date published: 2024-11-18
We are thrilled to announce that you can now create and configure sources and sync datasets directly within the Pipeline Builder user interface on all enrollments.
Two new ways to import a source
You can now easily import any Data Connection source to your Pipeline Builder pipeline. There are two ways to do this: If your input data was created from a Data Connection sync, you can add the source to the Pipeline Builder graph by selecting the input data node and using the Add source to graph option.

The Add source to graph option makes it easy to import any Data Connection source.
Alternatively, you can use the Add data toolbar button or the Import data to Foundry action to search for, import, or create sources. Select Import data to Foundry, then choose a new source type to create or search for an existing source to connect.
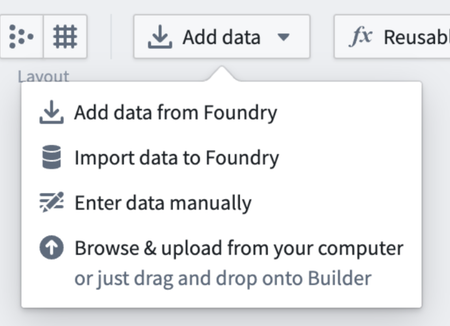
Choose from a selection of options to bring your data into Foundry.
Overall, this enhances the ease of integrating various data sources. This ensures that you can quickly connect to and utilize your data without long configuration processes, making your data operations more efficient and reducing setup time.
Directly input source configuration
Once the source is imported, you can configure it directly in Pipeline Builder. Under the Configure source section, you can specify required source-specific configurations. Pipeline Builder supports Foundry-supported JDBC sources that require only mandatory fields.
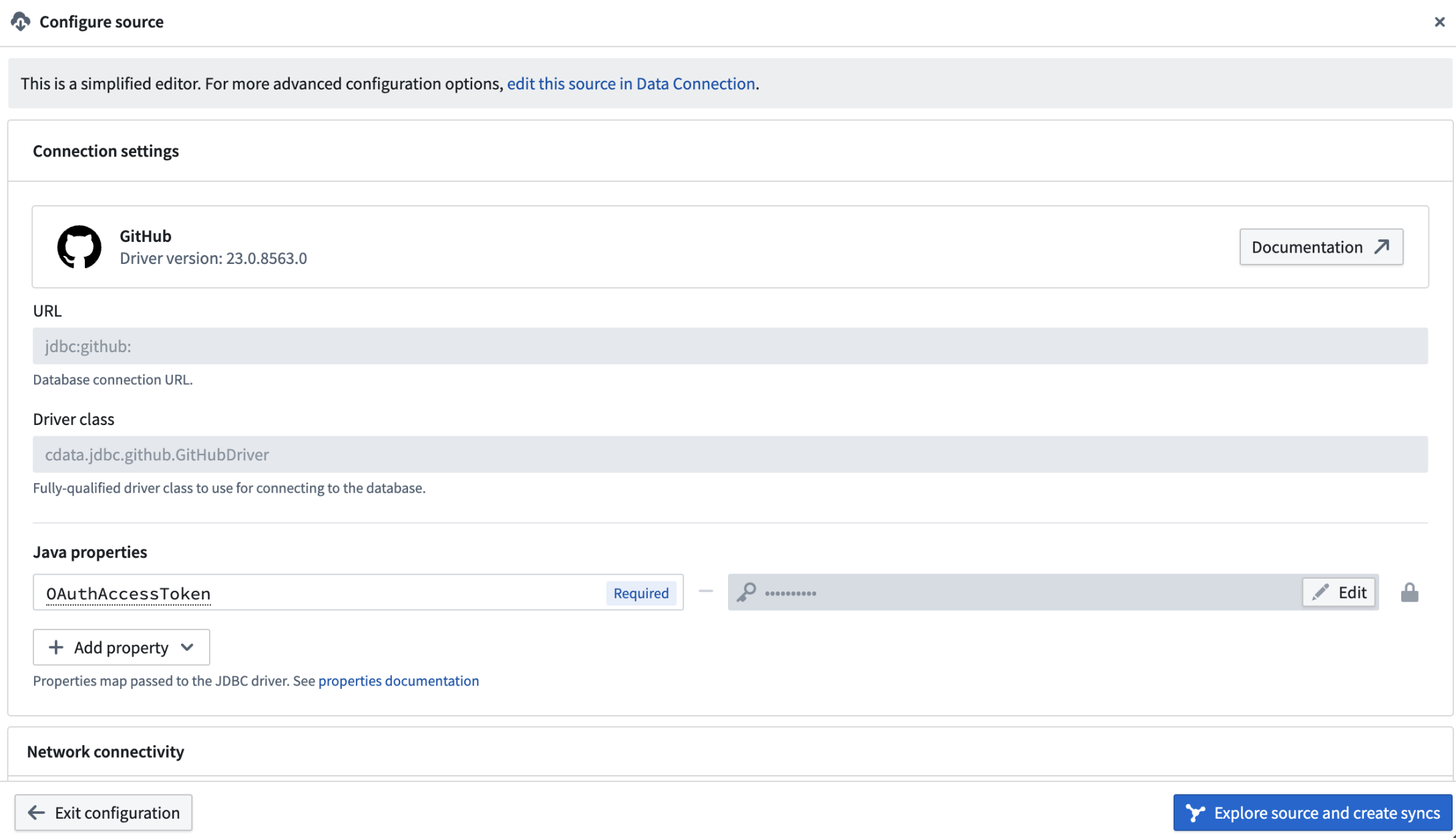
Use the Configure source section to input source-specific configurations.
This streamlines source creation by centralizing all necessary configurations with the data pipeline logic, ensuring optimal data flow.
Greater focus with integrated sync creation
The ability to explore sources and create syncs for batch datasets directly in Pipeline Builder significantly enhances your data management capabilities. This feature allows you to easily identify and sync the data you need, improving data accessibility and ensuring that your datasets are up-to-date. The streamlined sync process means you can focus on leveraging your data rather than managing it.
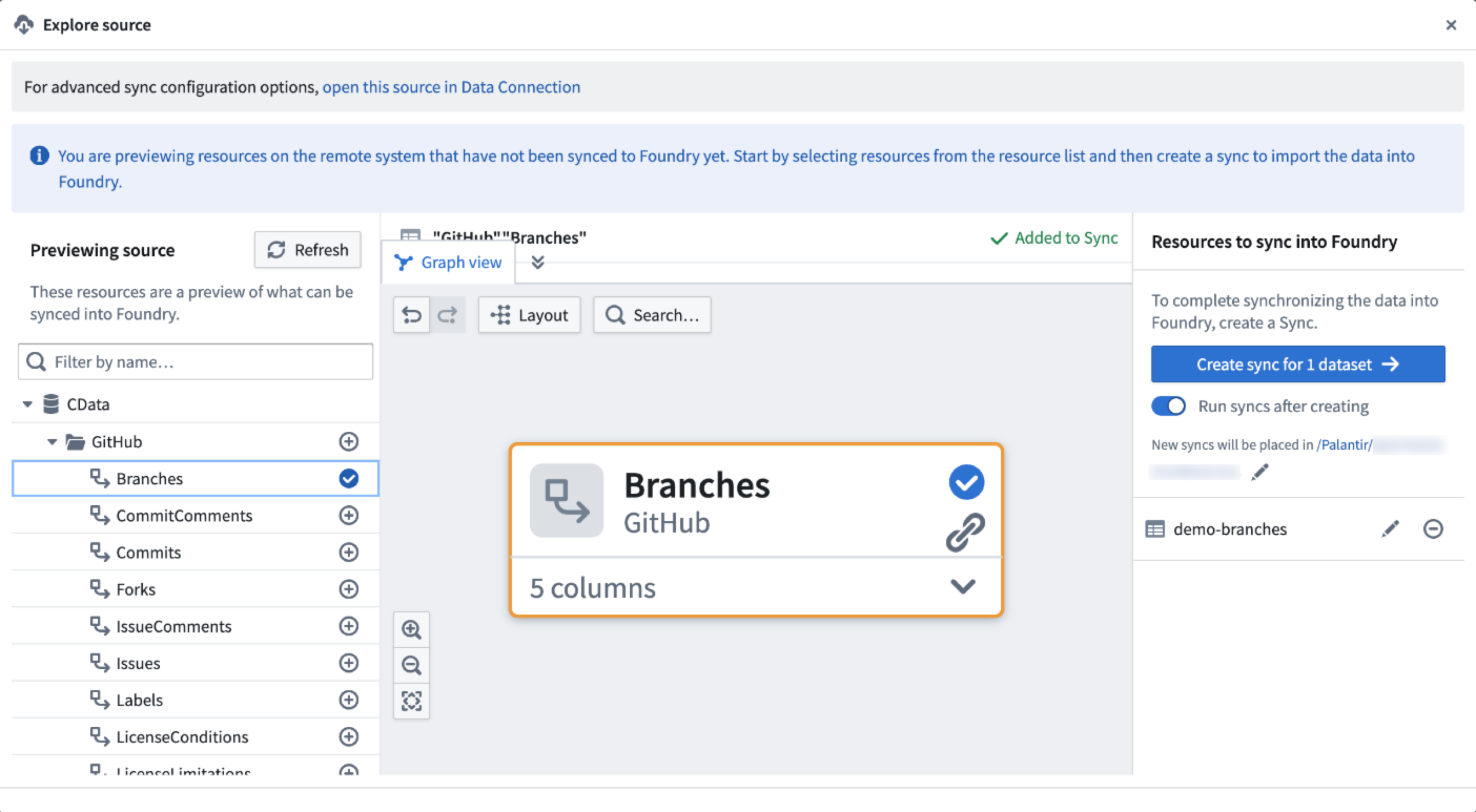
Leverage your data with the Explore source view.
Run serverless Docker images with compute modules [Beta]
Date published: 2024-11-11
We are excited to launch compute modules, a developer-focused way to run serverless Docker images in Foundry. With compute modules, you can scale your Docker containers dynamically based on load. Plus, bring your own logic without needing to rewrite it in a Foundry-supported language while augmenting Palantir platform capabilities.
The Compute Modules application is now available in a beta state. Contact Palantir Support to enable Compute Modules in your enrollment.
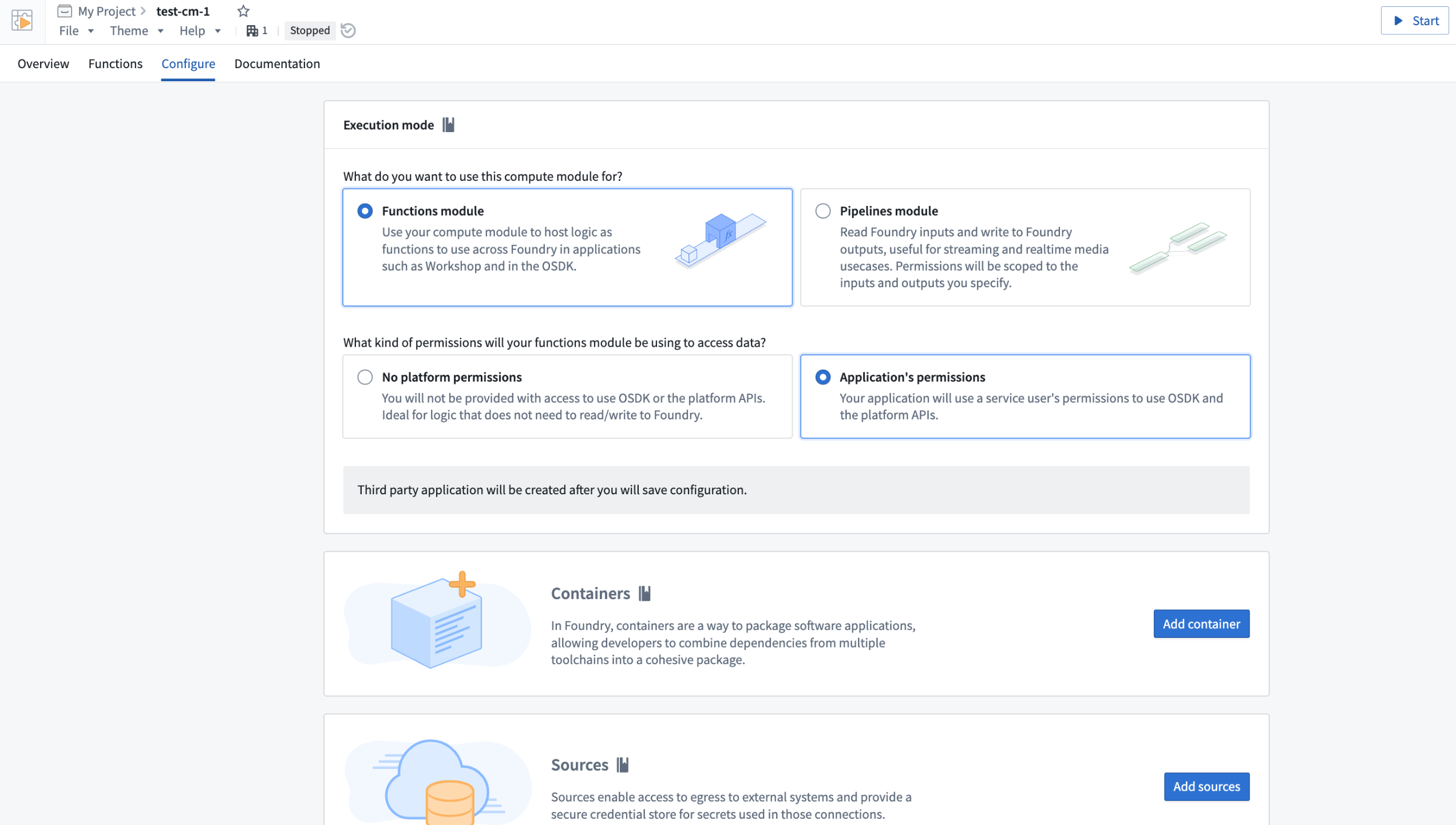
The Compute Modules application on the Configure page.
Key features
Compute modules are built to cater directly to developers, offering a variety of significant features to make the best use of Foundry capabilities while using your own logic and preferred language:
- Custom APIs and functions: Set up your own APIs and functions to be used seamlessly within Workshop, Slate, Ontology SDK applications, and other Foundry environments.
- Dynamic and predictive horizontal scaling: If you expect to serve a varying number of requests, compute modules can ensure higher availability by scaling the number of available replicas up or down based on current and historic load.
- Internal connections: Create complex Foundry orchestrations across products, including datasets, Ontology resources, schedules, and builds, using Foundry API endpoints.
- External connections: Write custom logic to create programmatic connections to external systems using whichever protocols those systems support, such as REST, WebSockets and SSE.
- Upgrade without downtime: Update a compute module without any downtime.
- Marketplace compatible: Compute modules can be published to Marketplace so others can leverage your work.
Practical applications
Once you get started with a compute module, use it to expand the potential of your critical workflows:
- Real-time data streaming: Connect to arbitrary data sources and ingest data into streams, datasets, or media sets in real time.
- Rapid code integration: Bring in business-critical code in any language with no translation needed. Use this code to back pipelines, Workshop modules, AIP Logic functions, or custom Ontology SDK applications.
- Model deployment: Host custom or open-source models from platforms like Hugging Face ↗; call them in a pipeline or as a function.
- Third-party integration: Pull in essential proprietary logic from other companies and offer them the opportunity to sell their products in Marketplace.
For more information on getting started with compute modules, review our public documentation, or navigate to the platform documentation in the Compute Modules application.
Introducing Workflow Lineage, an interactive workspace for understanding your workflows
Date published: 2024-11-09
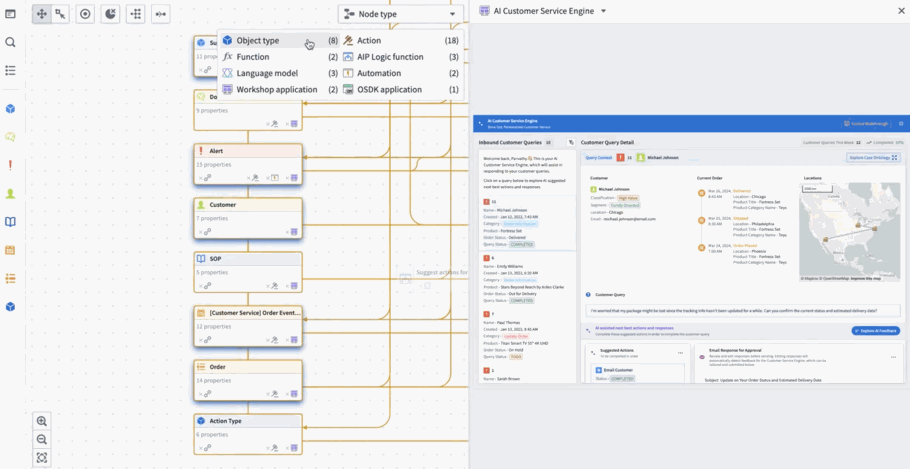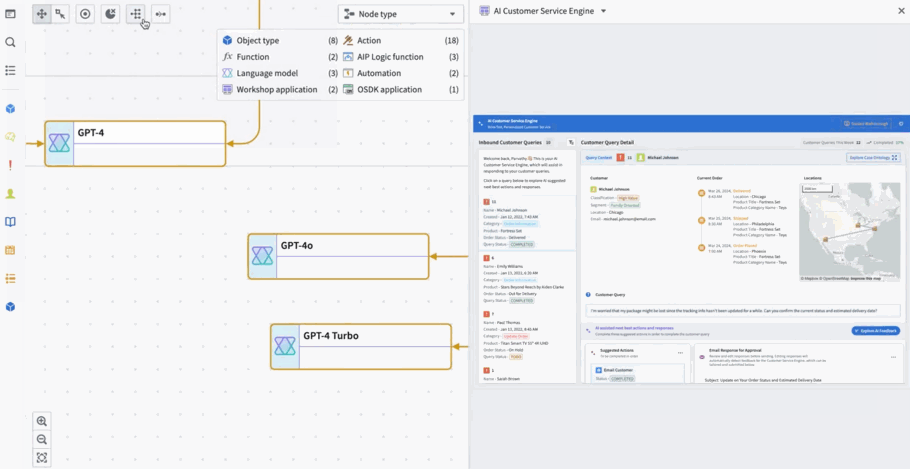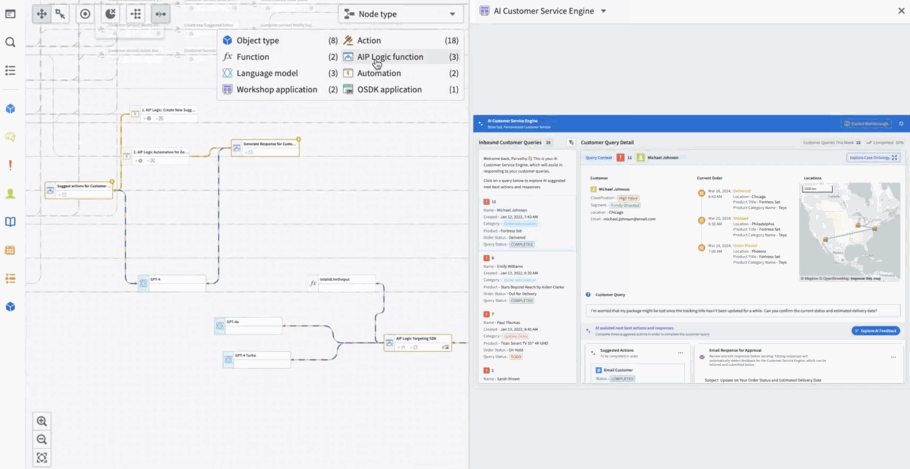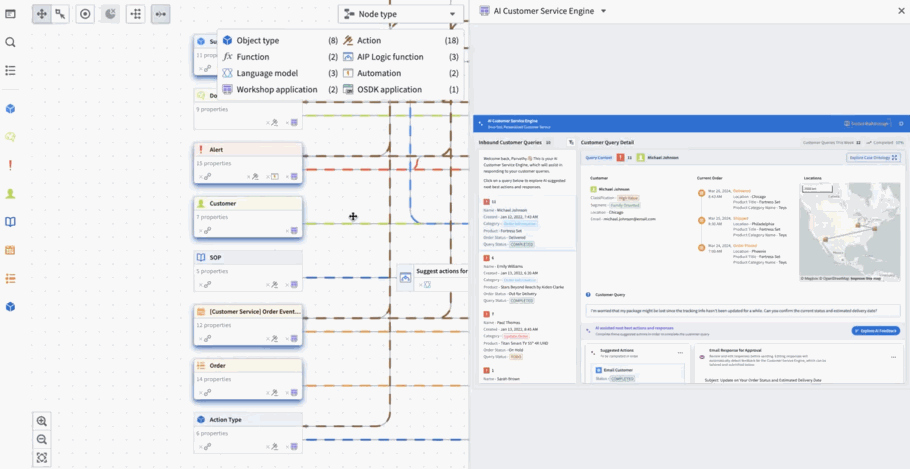
Workflow Lineage is a new application designed to help with building, debugging and managing workflows. Available across all enrollments the week of November 11, you can add Ontology resources – objects, LLMs, models, actions, functions, applications – to the graph and expand to other resources with logical references.
Workflow Lineage graphs are autogenerated - simply use the keyboard shortcut CMD + i (macOS) or Ctrl + i (Windows) when viewing any Workshop application to get started immediately.
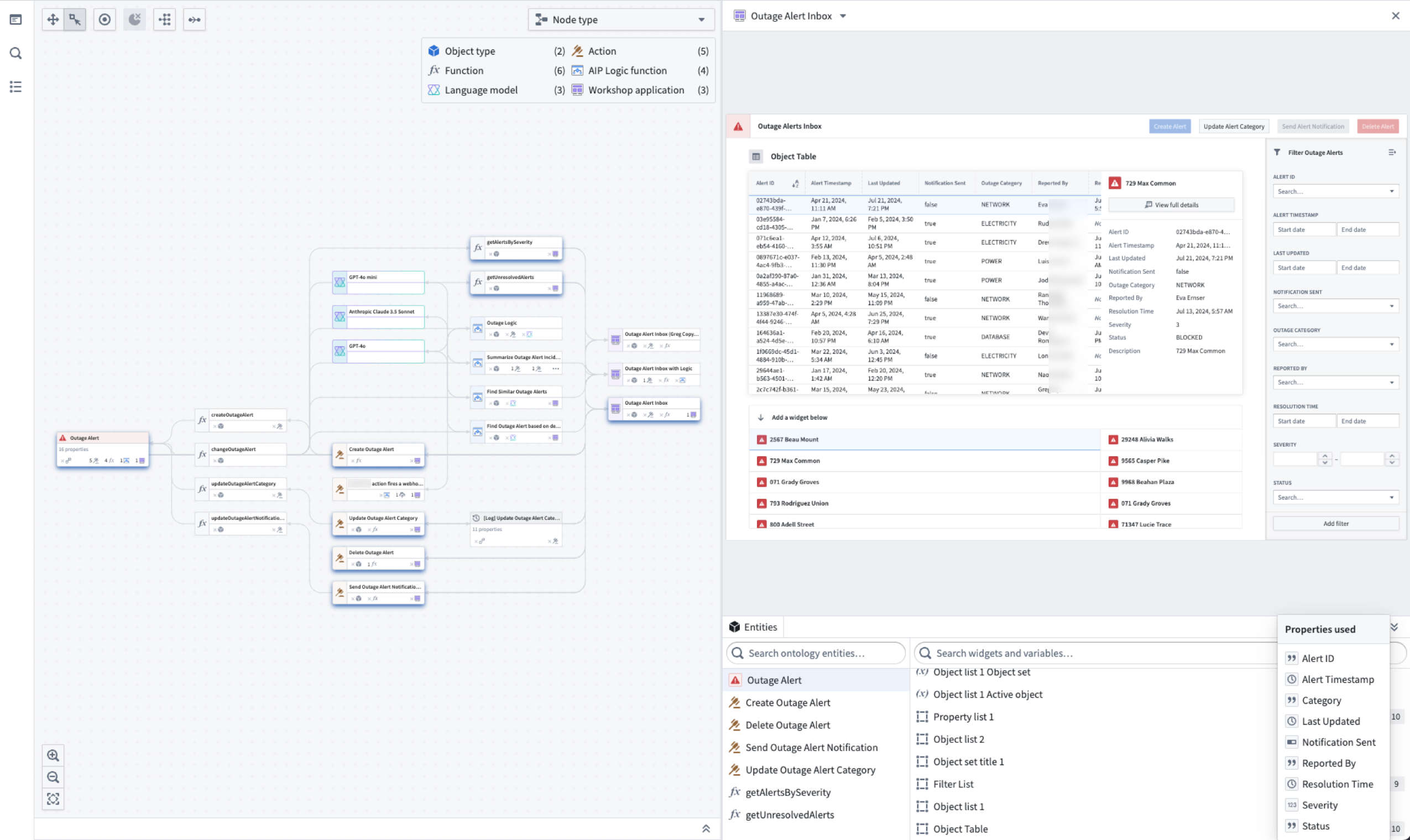
Workflow Lineage is an interactive workspace for understanding and managing applications.
Optimize your workflow management
See all usages downstream for a specific column in an object: Including dependent Actions, Functions, and Workshop applications.
- See all usages downstream for a specific column in an object: Including dependent Actions, Functions, and Workshop applications.
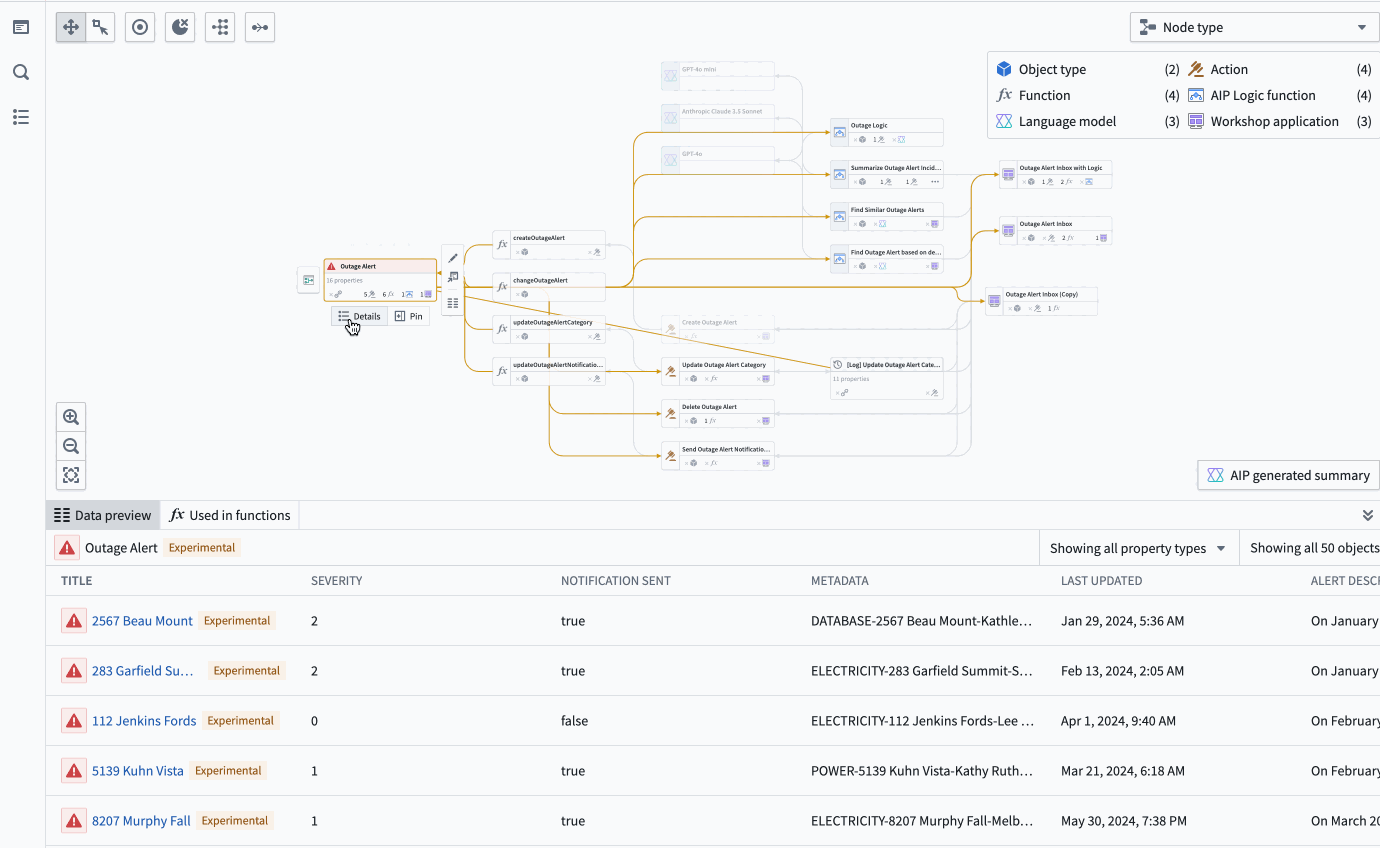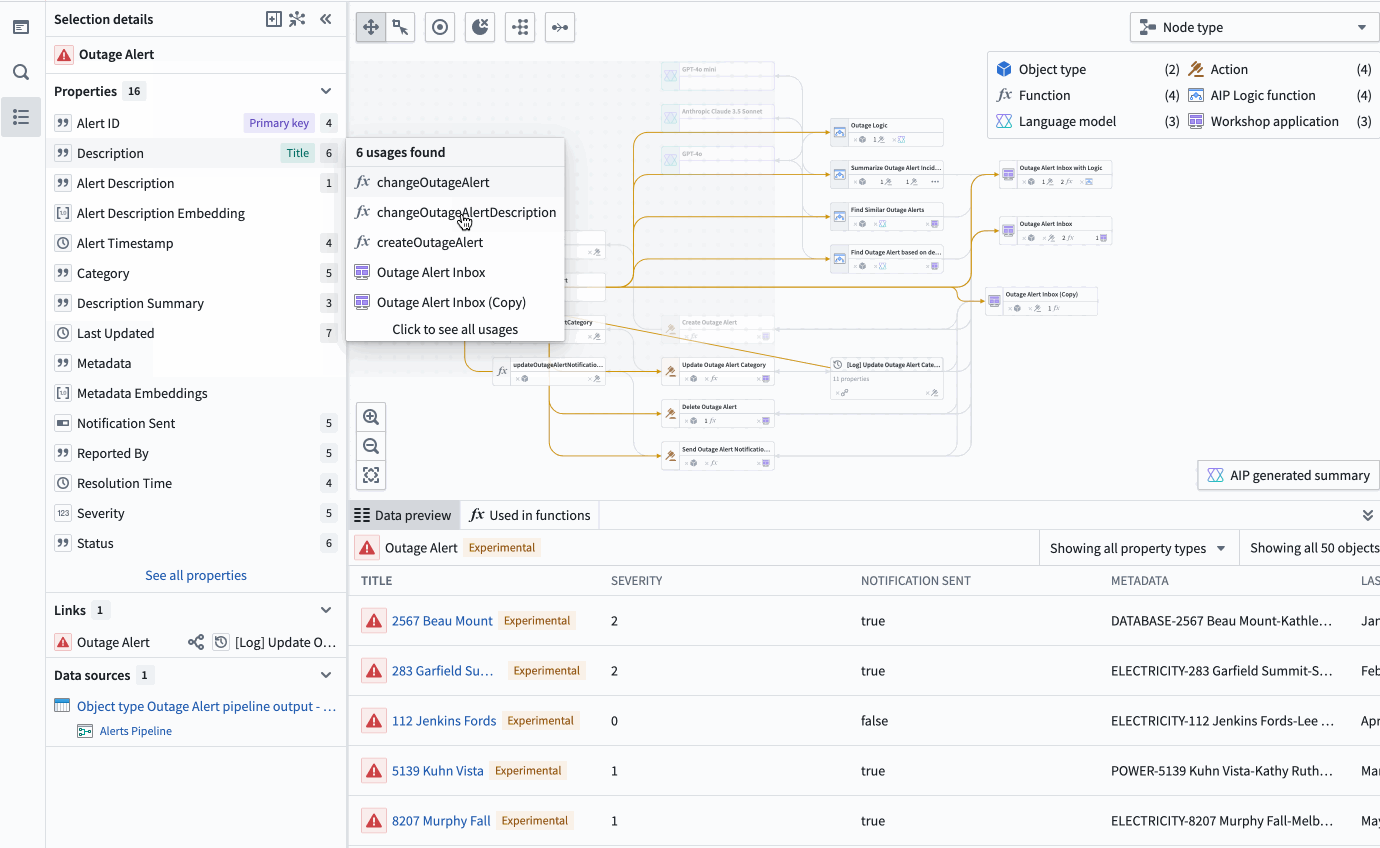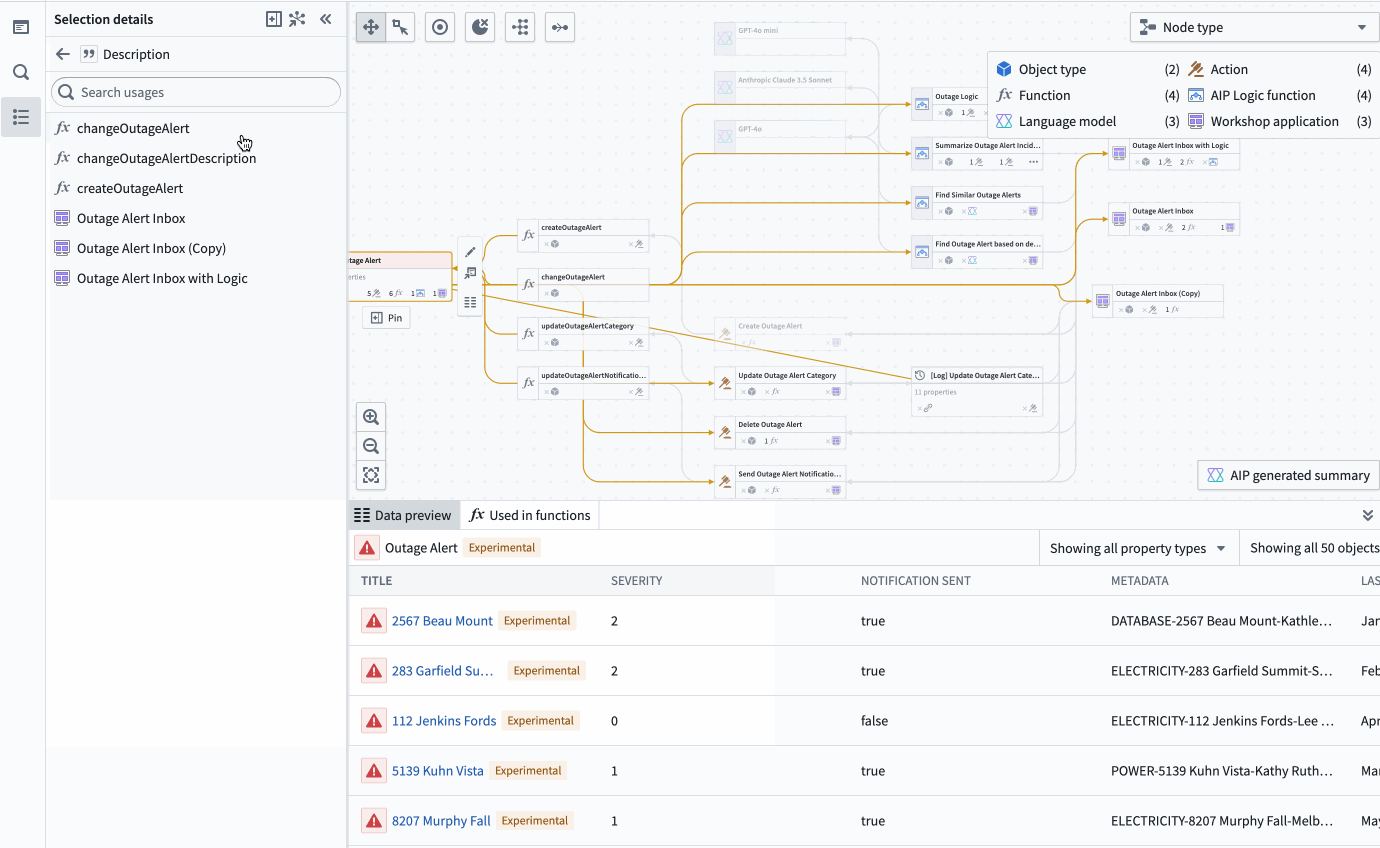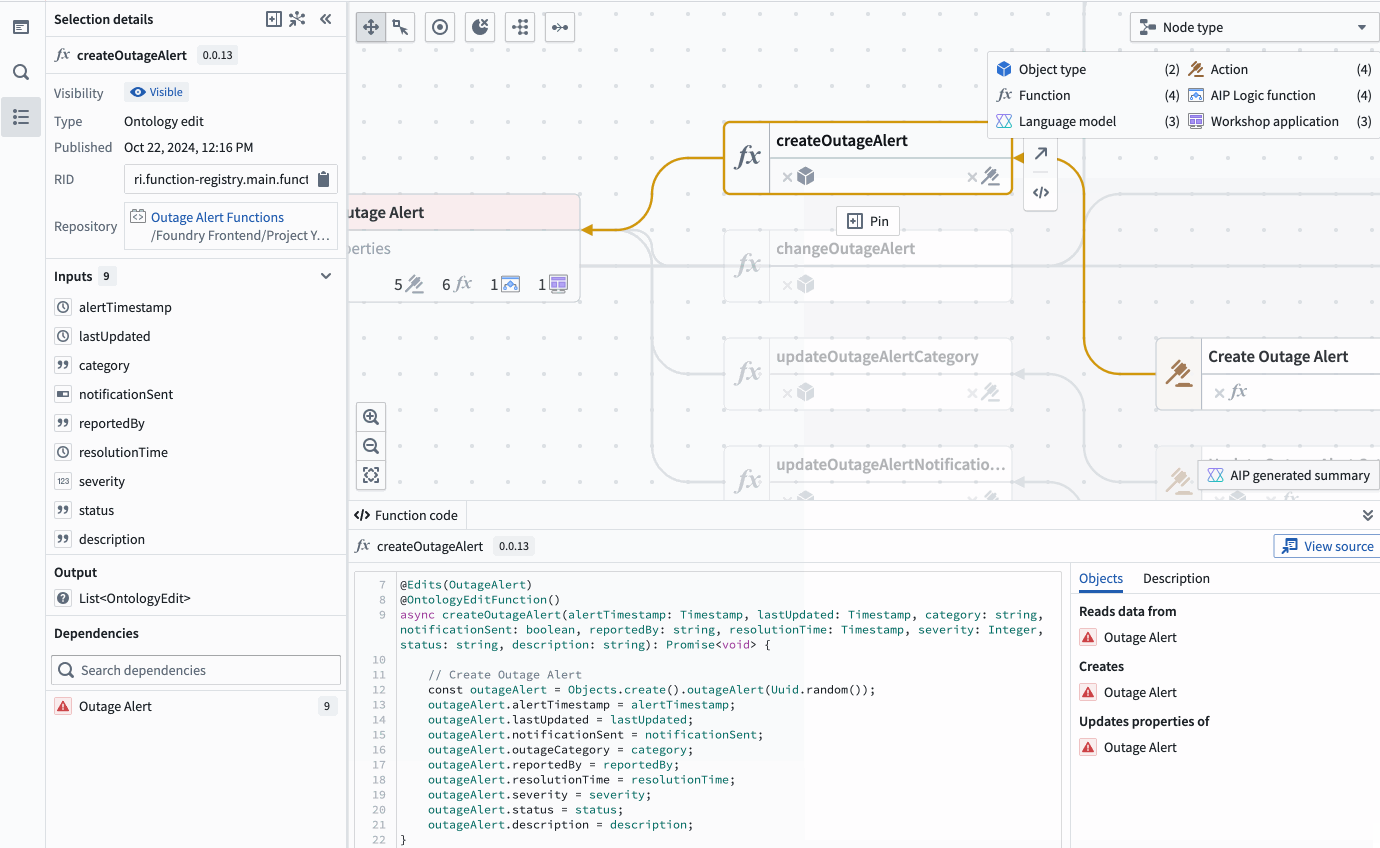 The property list of a selected object, complete with all the applications of a specific property, and a preview of the backing function.
The property list of a selected object, complete with all the applications of a specific property, and a preview of the backing function. - Bulk update Actions: Easily select outdated Actions backed by Functions and update those Functions to a specific version all at once.
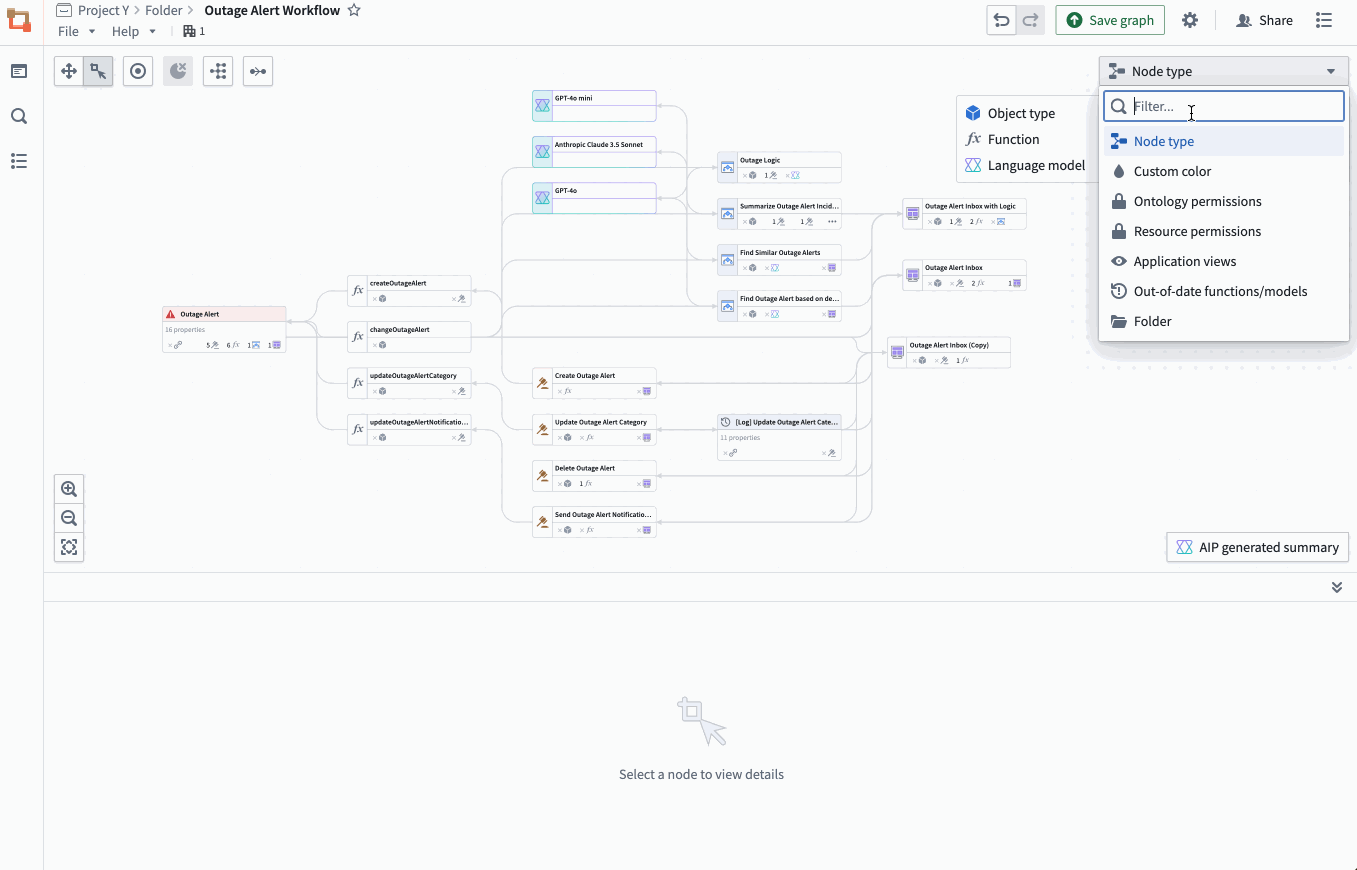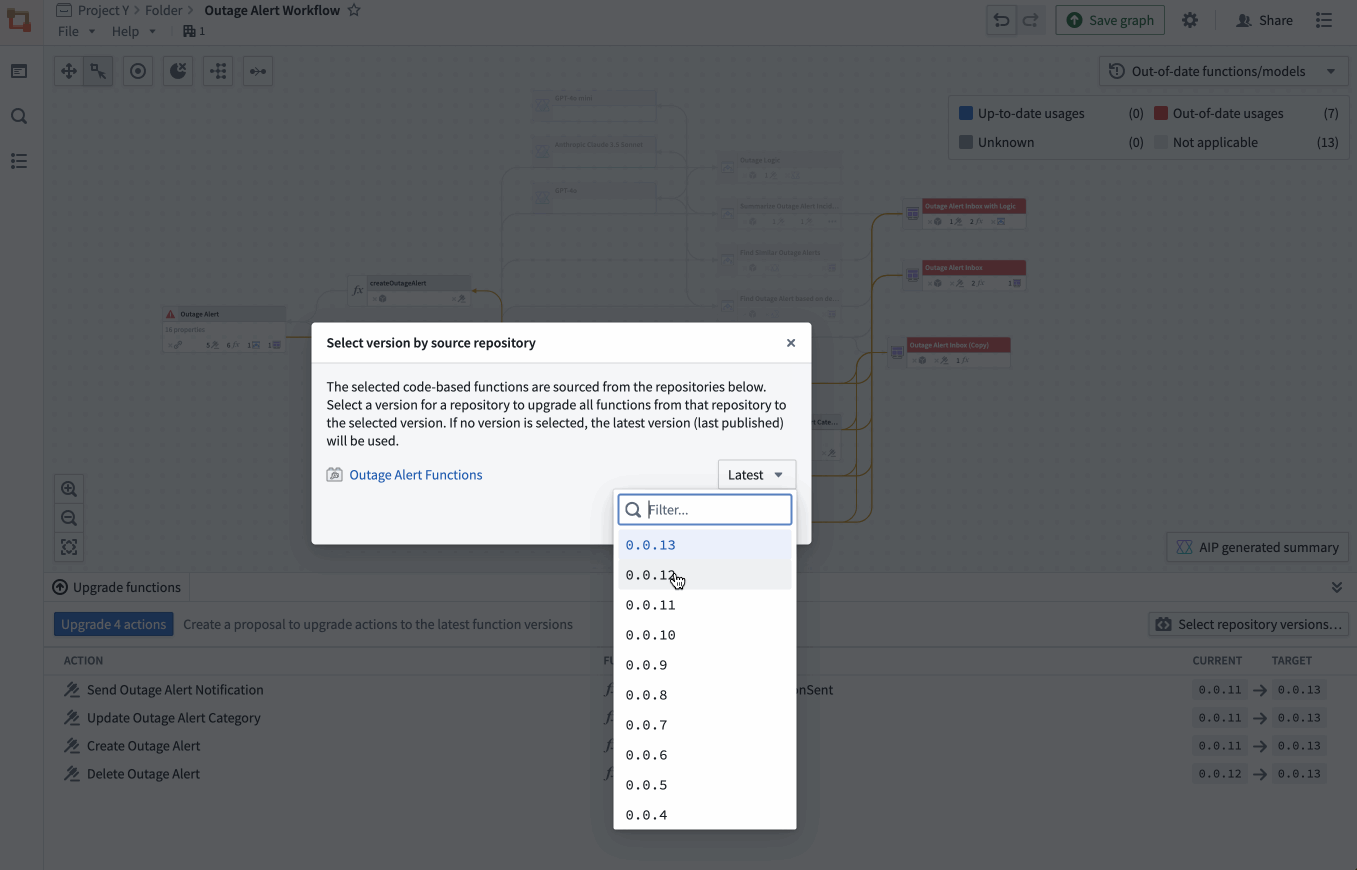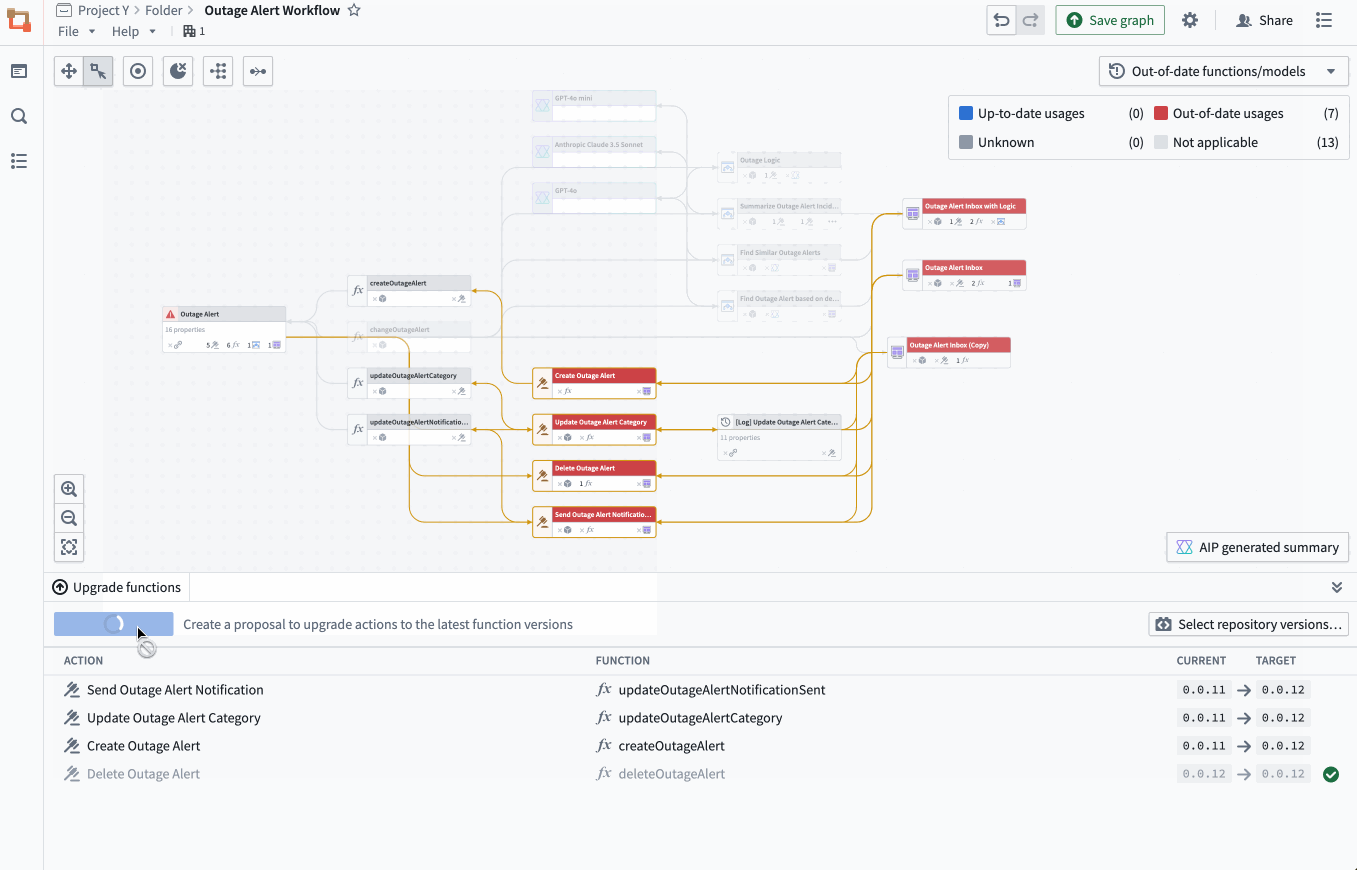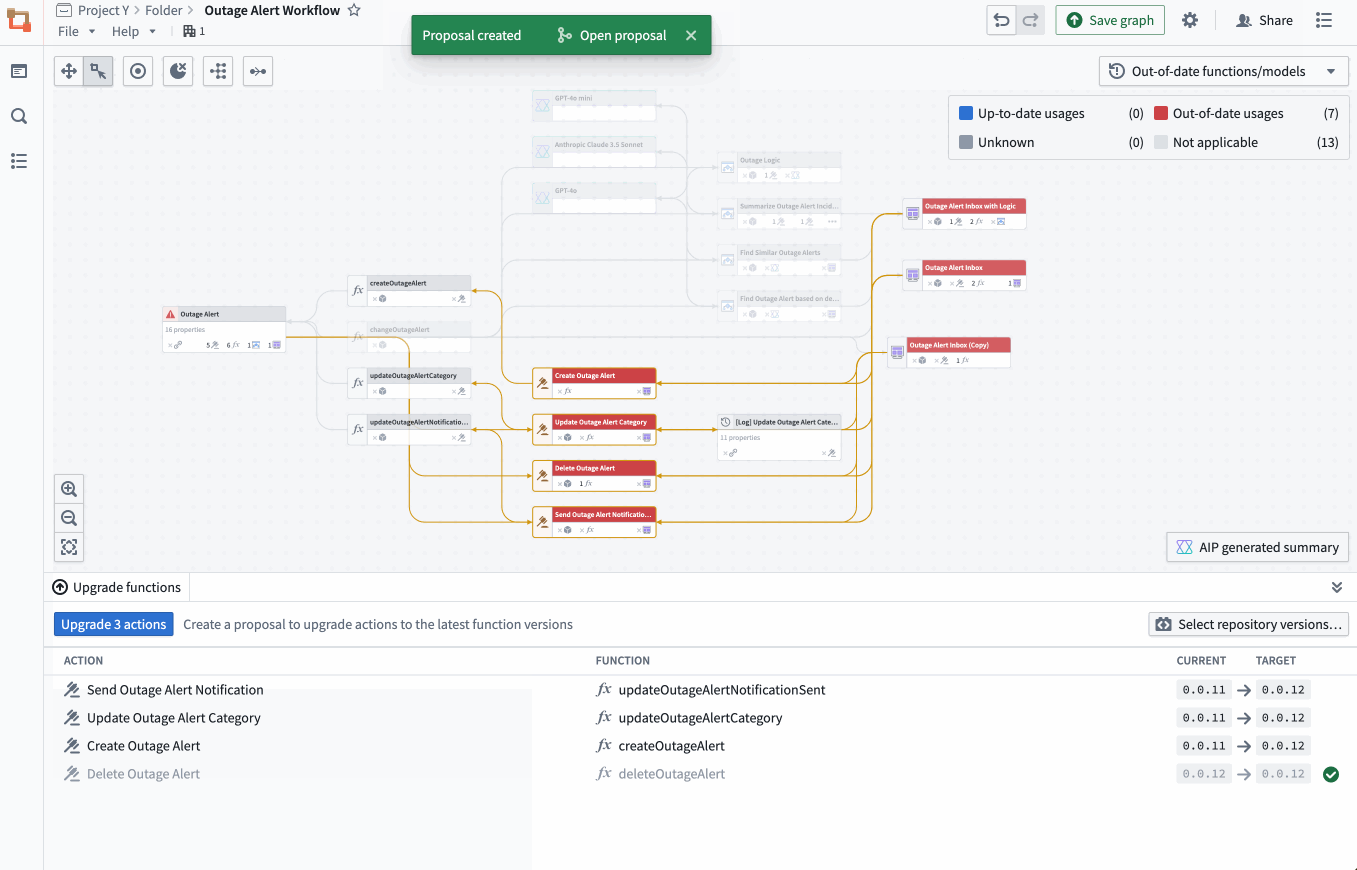 Bulk select outdated Actions backed by Functions to complete an update on the Functions.
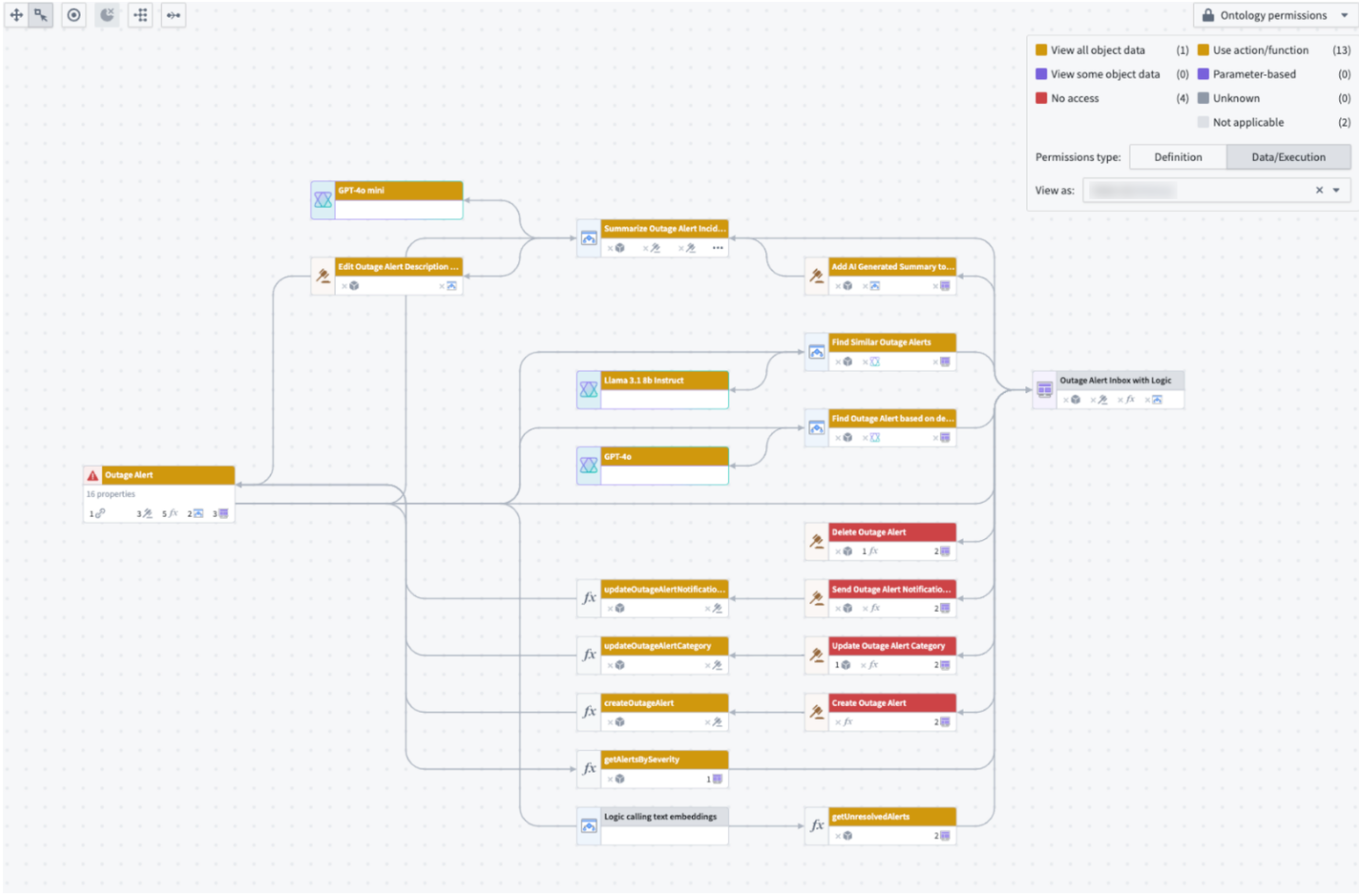
Bulk select outdated Actions backed by Functions to complete an update on the Functions. - Review Ontology security permissions with the new color legend: See Actions with matching submission criteria across all Actions, Workshop application views, and more.
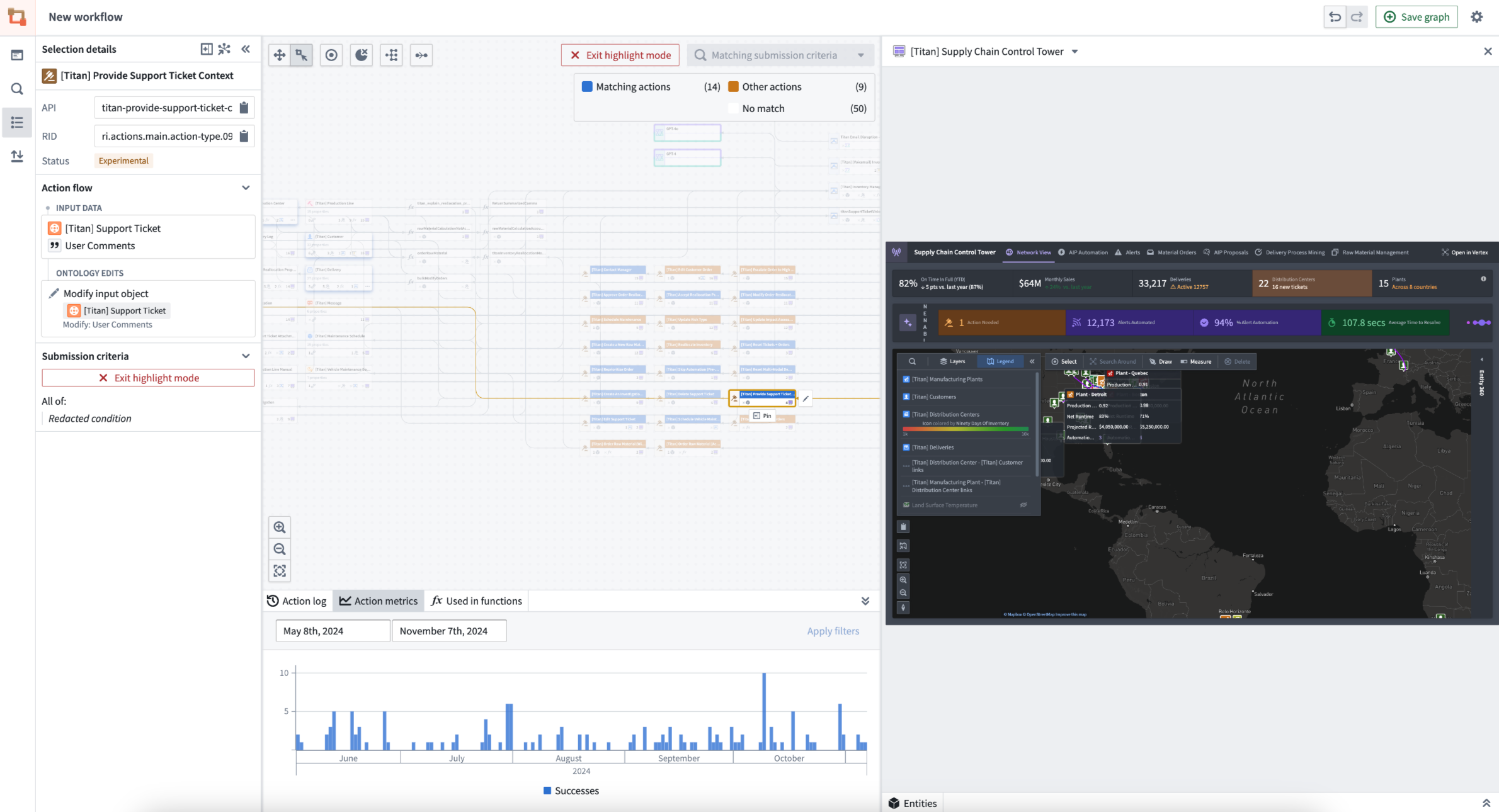 Actions that match the submission criteria rule are highlighted in one color, with a chart of Action metrics at the bottom.
Actions that match the submission criteria rule are highlighted in one color, with a chart of Action metrics at the bottom.
 When a user is selected under "View as", the Ontology permissions color legend will show which Actions they have access to.
When a user is selected under "View as", the Ontology permissions color legend will show which Actions they have access to. - Explore the nuances in your workflows: See details on objects, Actions, functions, large language models, and applications. Details include API names, inputs, Ontology edits, submission criteria, and even code snippets.
Use the legend to navigate Workflow Lineage with ease.
To immediately get started with Workflow Lineage, navigate to any Workshop application and use the keyboard shortcut CMD + i to open a Workflow Lineage graph with the specified Workshop application showing the relevant objects, actions, and Functions that back it.
Zoom around Workflow Lineage with keyboard shortcuts
- Open Workflow Lineage:
CMD + i(macOS) orCTRL + i(Windows) from within a Workshop application - Layout nodes in cluster by node type formation:
Option + L(macOS) orAlt + L(Windows).CMD + A(macOS) orCtrl + A(Windows) to select all. - Navigate by legend when selecting each of the legend types.
For more information on Workflow Lineage, review the public documentation.
Configure Code Repositories settings in Control Panel [GA]
Date published: 2024-11-07
You can now configure many Organization-wide Code Repositories settings within Control Panel. To modify these settings, you will need the User experience administrator role in your Organization, also configurable in Control Panel under Organization permissions.
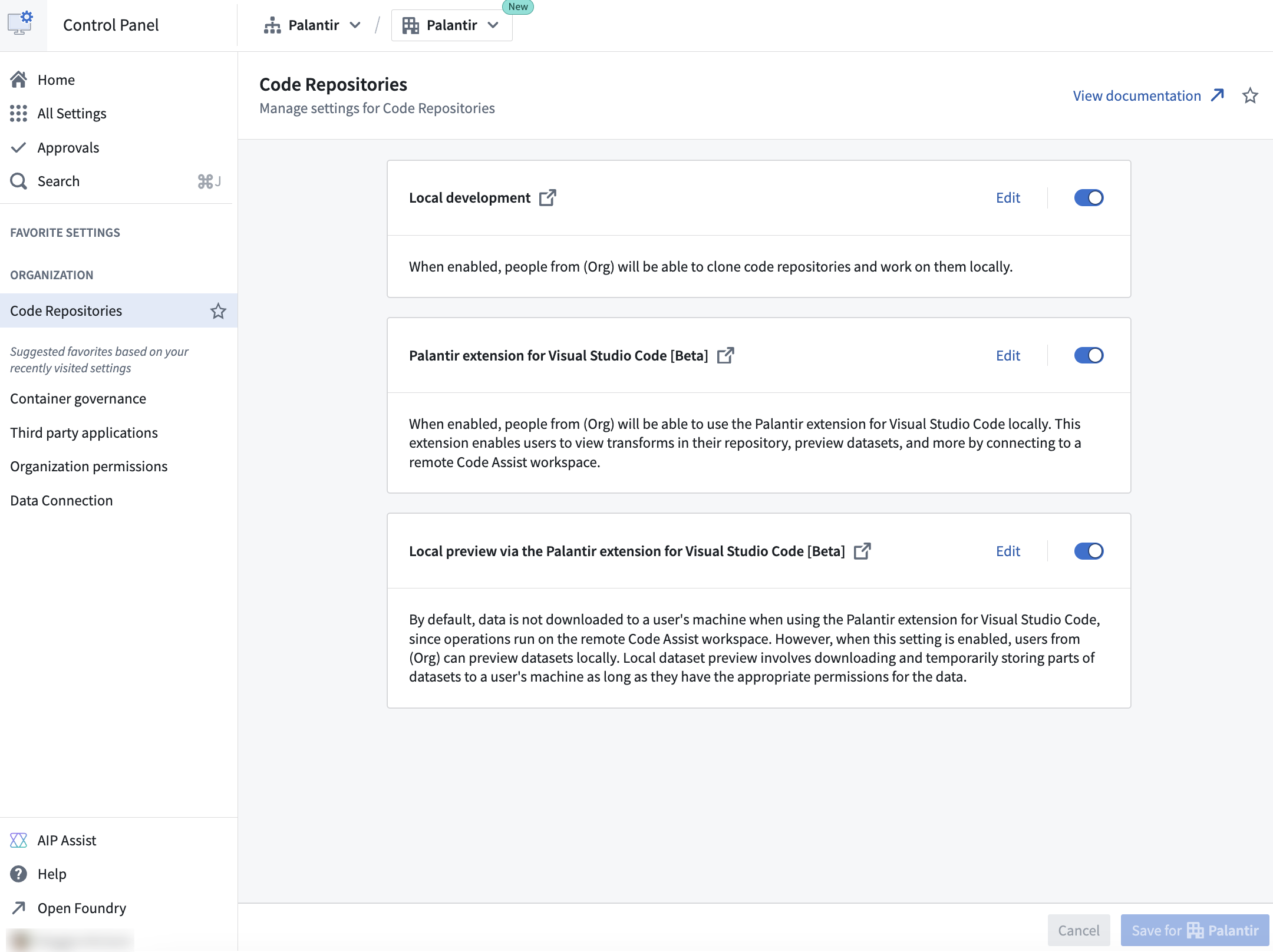
The Code Repositories settings available to configure in Control Panel.
With Code Repositories configurable in Control Panel, platform administrators can manage and track all users in an Organization who have access to local development, allowing for easier access customization and more usage transparency. Available configurations for Code Repositories in Control Panel include the following:
Local development: Enabled by default, you can allow users in your Organization to clone code repositories and work on them locally in their own code environments
Palantir extension for Visual Studio Code: Also enabled by default, you can allow users in your Organization to use the Palantir extension for Visual Studio Code in their local environment. This extension connects to a remote Code Assist workspace, letting users view transforms in their repository, preview datasets, and more.
Note that the Palantir extension for Visual Studio Code is in a beta state and only available to certain users for local development. The settings related to the extension will only apply to users who have access to the extension. For other users, these settings will have no effect. Contact Palantir Support to enable local development with the Palantir extensions for Visual Studio Code.
Local preview through the Palantir extension for Visual Studio Code: Allow users in your Organization to preview datasets locally. Local dataset preview involves downloading and temporarily storing parts of datasets to a local machine, provided users have appropriate permissions for the data. This setting is disabled by default.
For more information about Control Panel and its various configuration, review our documentation.
Introducing Python compute modules in VS Code workspaces [Beta]
Date published: 2024-11-07
We are excited to announce that you can now develop Python compute modules directly in VS Code workspaces, available by default in all Organizations where Code Workspaces is enabled.
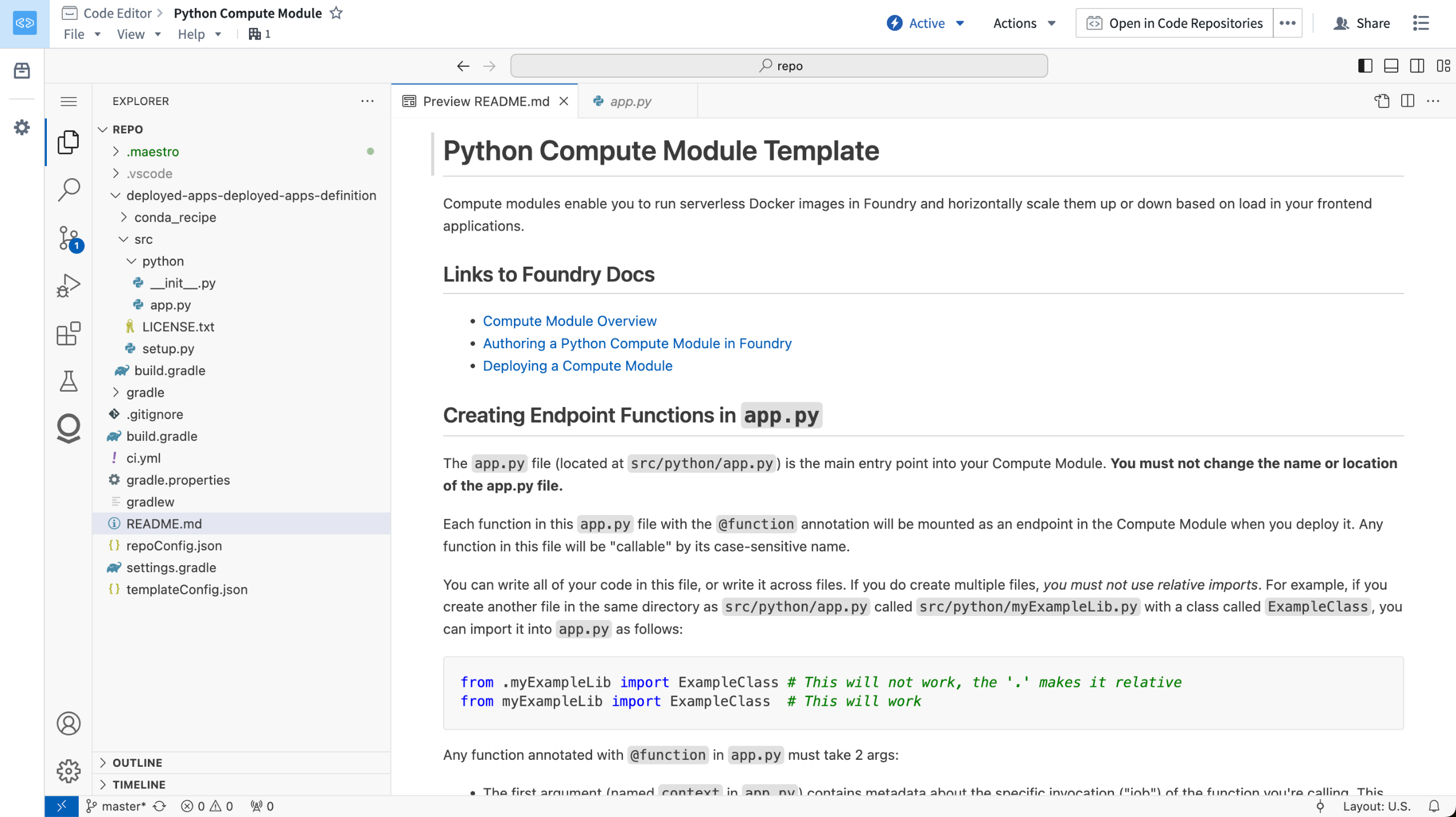
A Python compute module repository, opened in a VS Code workspace.
This feature allows you to use the powerful developer capabilities provided by VS Code to build your Python compute module. The Palantir extension for Visual Studio Code will automatically set up your Python development environment, allowing you to interactively run and debug your Python code.
To get started, first open your Python compute module in the Code Repositories application. From here, select Open in VS Code in the top right corner of the screen, which will take you to a VS Code workspace where you can start developing your compute module.
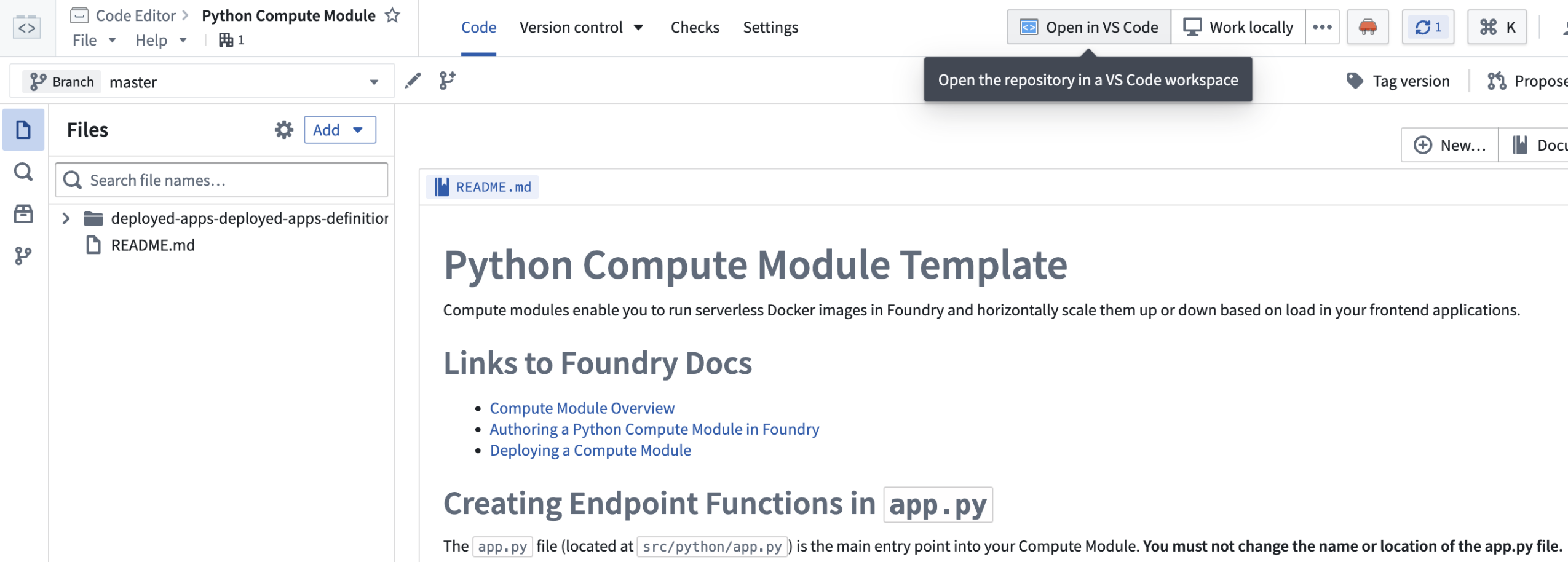
A Python compute module in the Code Repositories application, with the option to open in a VS Code workspace.
What's next in the development roadmap?
In the coming weeks, we plan to release VS Code workspaces for Python transforms, also available in a beta state.
Build OSDK React applications using VS Code workspaces [Beta]
Date published: 2024-11-07
VS Code workspaces now support OSDK React applications. With this new feature, you can now develop and deploy your OSDK React applications entirely within the Palantir platform using the familiar and powerful VS Code environment. This integration allows you to leverage the Ontology SDK to build sophisticated React applications, taking full advantage of Foundry’s robust capabilities for high-scale queries granular governance controls, and seamless data interactions.
To start building, navigate to Applications > Developer Console on your workspace navigation bar.
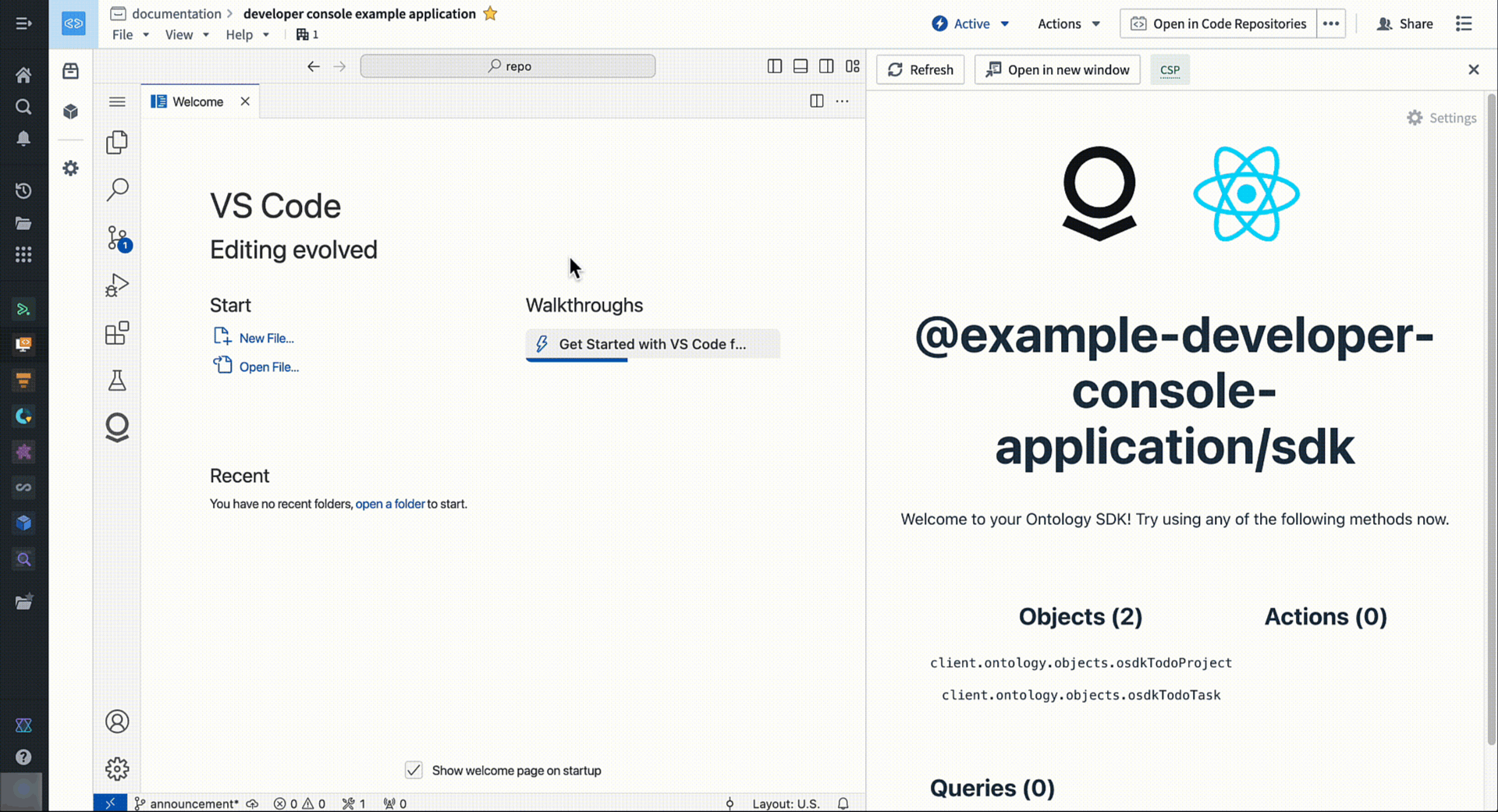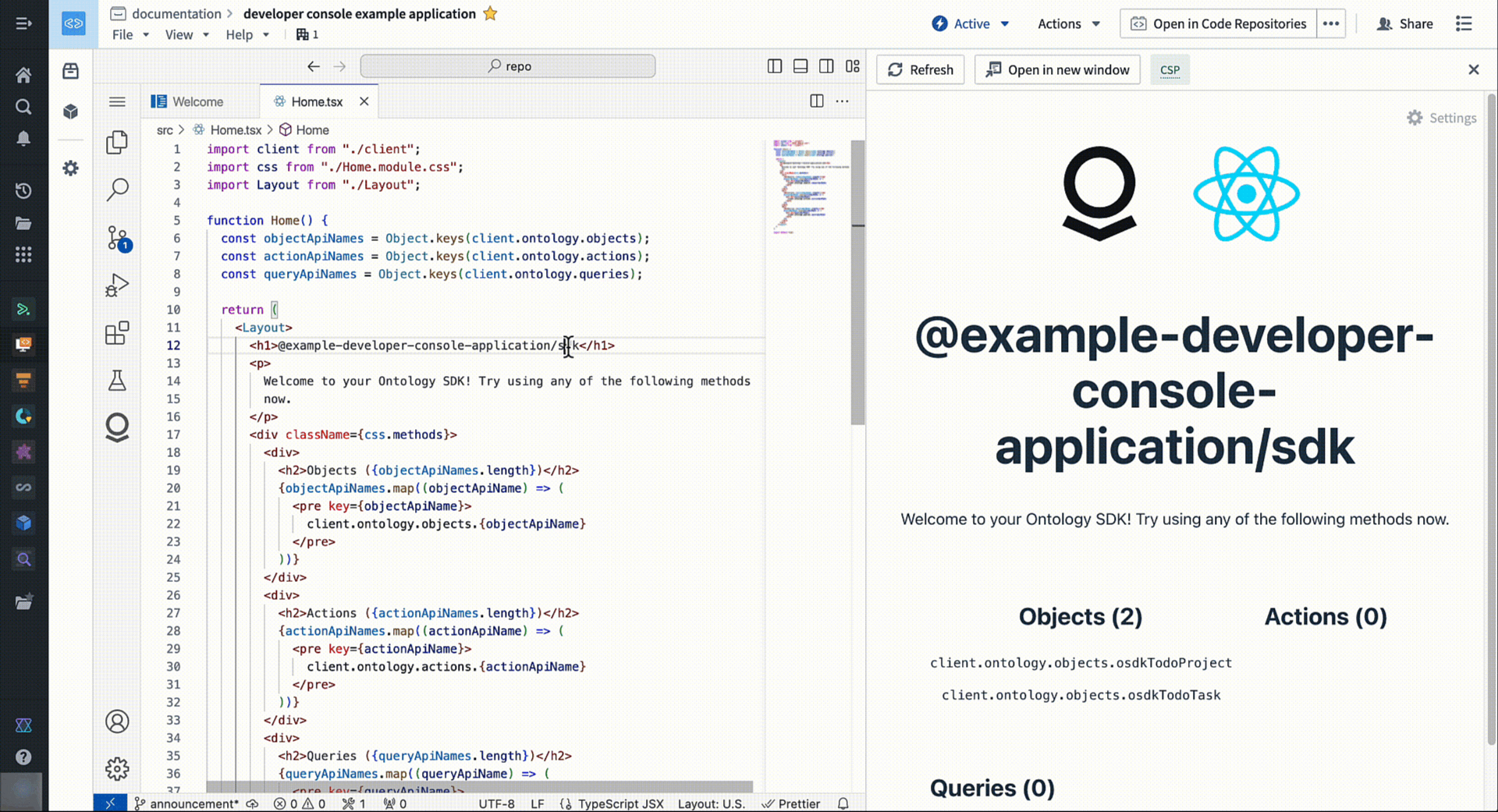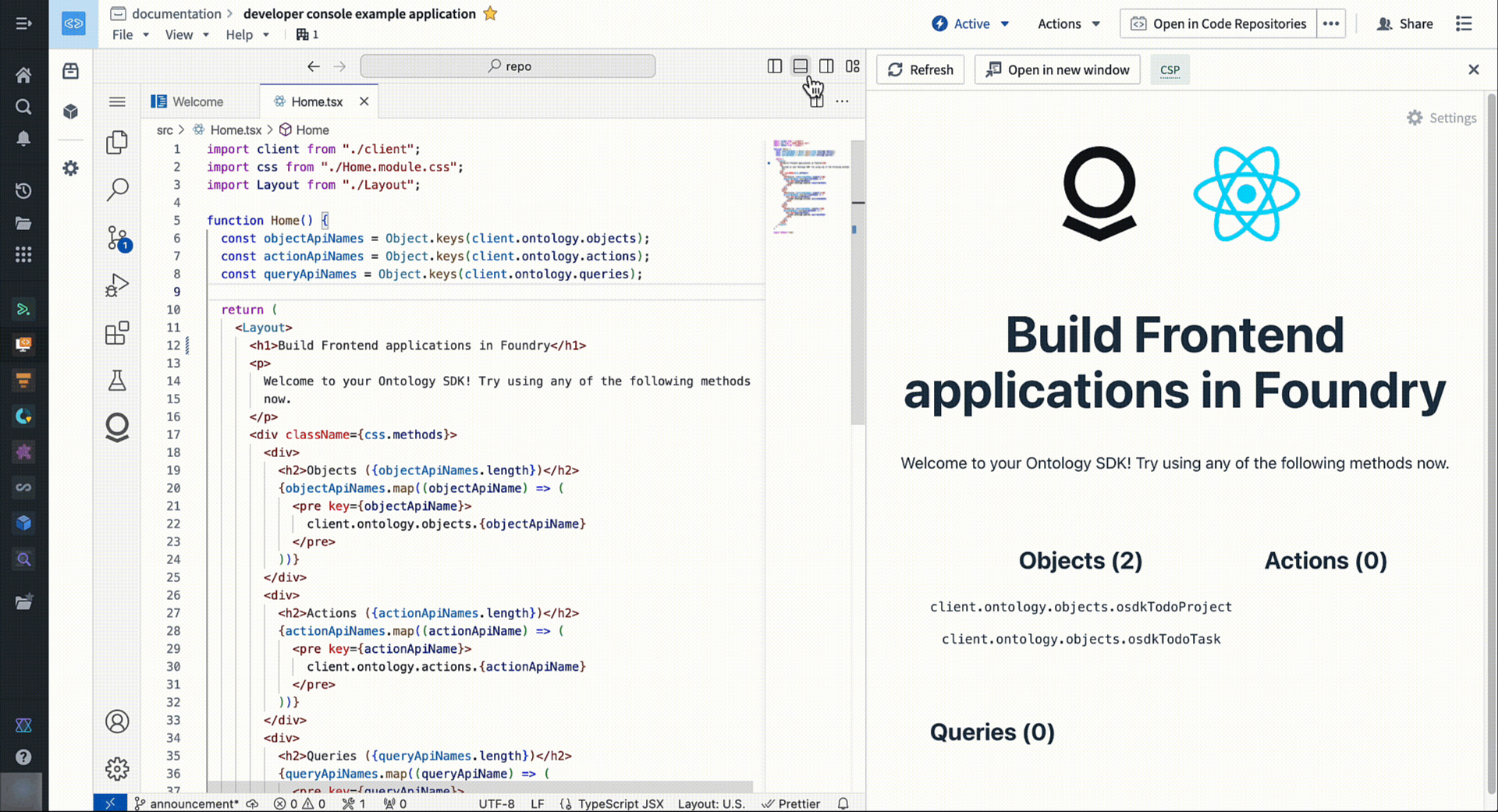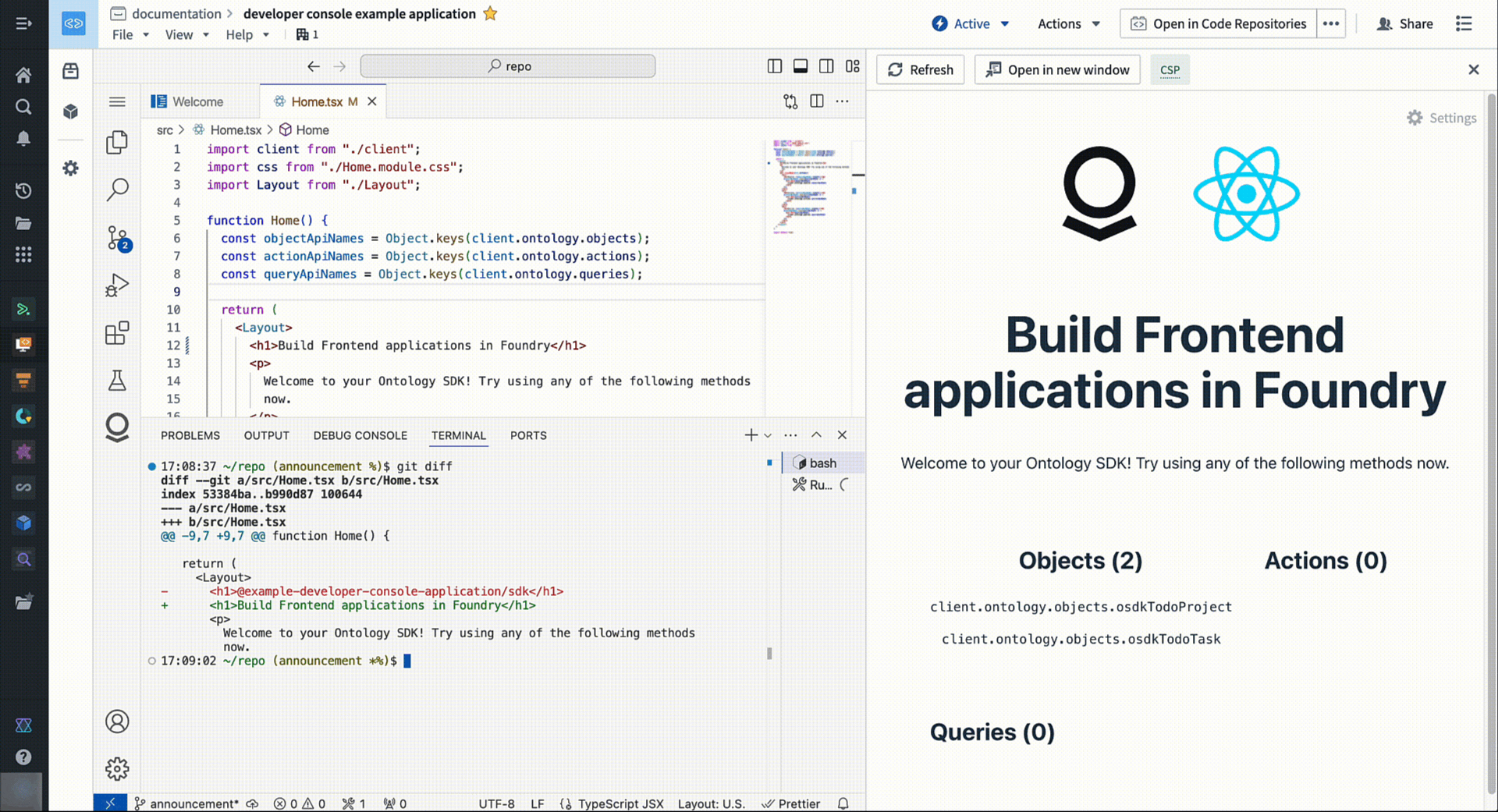
Access a familiar and powerful VS Code environment directly from within the Palantir platform.
Use the new file template configuration wizard in Code Repositories to create transforms with ease
Date published: 2024-11-07
Instead of modifying an example file when configuring new Python transforms in Code Repositories, you can now use our new file template configuration wizard for an immediate output that fits your needs. Use the configuration wizard by creating a new Python Transforms repository, or by selecting Add > New file from template using the Files side panel.
This new feature facilitates the personalization of the default file in new repositories by enabling you to choose the transformation type along with necessary inputs and outputs.
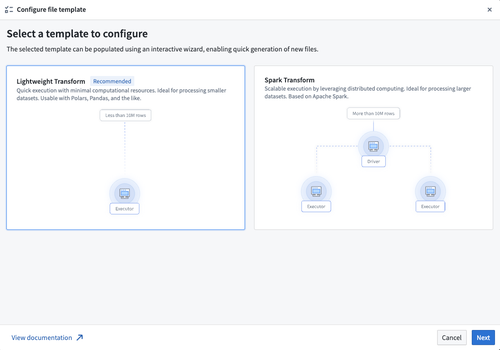
Starting configuration in the new file template wizard.
To start, select a transform type from the available options which matches your use-case. Next, provide values required by the selected transform type. Changing any of the values in the configurator will automatically update the code displayed in the preview section.
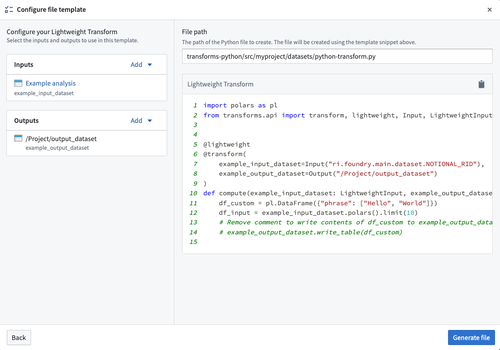
You can review the output transform code snippet immediately after supplying the file template wizard with inputs and outputs.
Once all values are valid for the selected transform type, select Generate file to create a new file with the code snippet displayed in the preview section. This will create a new file in your repository with the provided contents that can later be committed to save your changes.
Accelerate your newly-made repository to an active Python transform with our new file template wizard.
Explore new Agent details panel for configuration insight in AIP Agent Studio [Beta]
Date published: 2024-11-07
AIP Agent Studio now features an Agent details panel to the right of the conversation window which provides insight into the chosen model, prompting strategy, available resources, retrieval context, and reasoning methods of an agent deployed in AIP Threads or Workshop. The panel aims to provide additional transparency to help users obtain the clarity necessary to configure and best leverage their Agent.
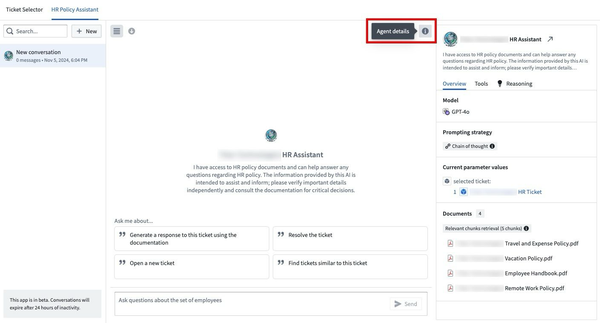
The Agent details right-hand panel provides extensive insight into the Agent's configuration.
The Overview tab displays details like the Agent's backing model and parameters it references for analytical context, such as a set of documents or a filtered object set. The Tools tab lists artifacts, such as Ontology types and actions, which the Agent may also leverage as it responds to user prompts.
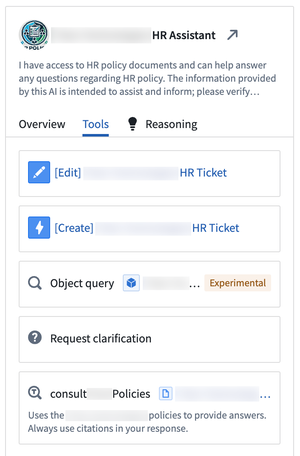
The Tools tab lists artifacts an Agent may access to respond to user prompts.
Users can view the Reasoning tab through the right side panel or by selecting the light bulb icon in the top right corner of an Agent's response. AIP Agent Studio automatically selects the latest response to view within the Reasoning panel.
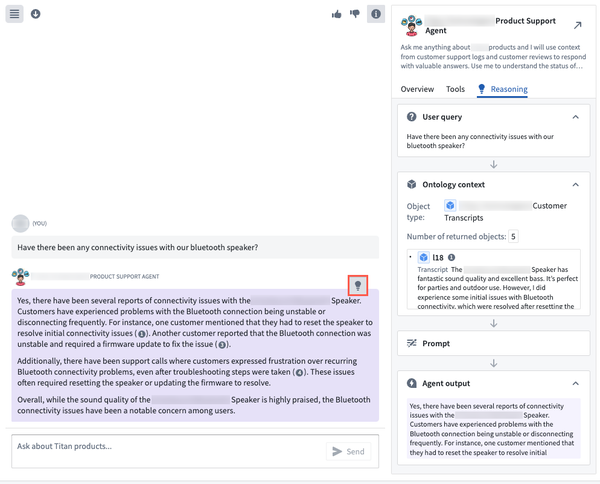
The Reasoning tab outlines Agent logic and is accessible through the right side panel or the response's light bulb icon.
When in edit mode in AIP Agent Studio, users can view the Prompt used to inform the Agent's query response logic to streamline troubleshooting or debugging efforts when investigating unexpected Agent behavior.
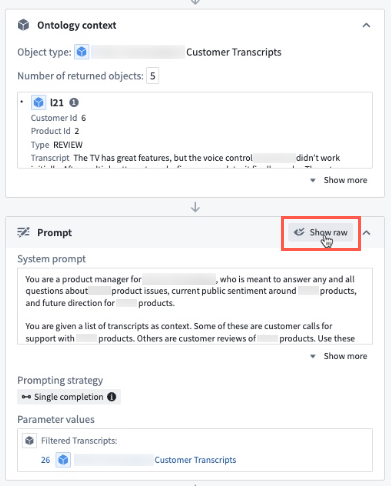
Users can view the prompt provided to the Agent when in edit mode in AIP Agent Studio.
Additionally, users can view the agent's chain-of-thought reasoning for each tool call in the Reasoning section to help understand why an Agent may not respond as intended in the context of having a tool available.
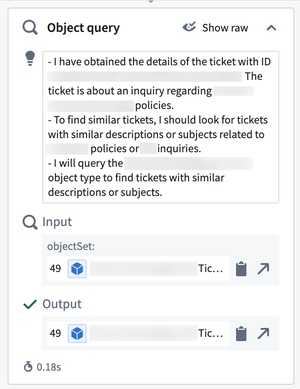
The Reasoning tab's Object query section displays an Agent's chain-of-thought reasoning.
Need support?
AIP Agent Studio's documentation contains additional detail regarding agent parameters, tools, and retrieval context. To obtain access to AIP Agent Studio on your enrollment, contact your Palantir representative for enablement.
Improved developer support with context-aware attachments in Code Repositories [Beta]
Date published: 2024-11-07
A new integration between Code Repositories and AIP Assist will be available in a beta state the week of November 11th. This integration introduces context-aware attachments for AIP Assist that allow users to attach existing code snippets, files, and even entire repositories to conversations. This provides context that enriches AIP Assist knowledge of user workflows, allowing Assist to respond to code-specific questions more accurately and with greater detail.
Start by attaching an entire repository, one or multiple files, or a highlighted snippet of code to have AIP Assist:
- Explain the relationship between different files.
- Optimize code snippets.
- Search for particular code across the repository.
- Summarize or explain snippets, files, or the entire repository.
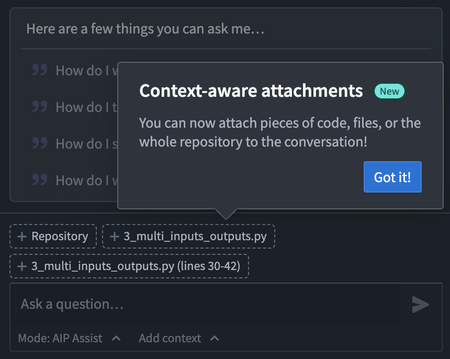
Context-aware attachments in the AIP Assist sidebar in Code Repositories.
Once attached, AIP Assist will have access to the code and related metadata, allowing Assist to aid users with code related tasks.
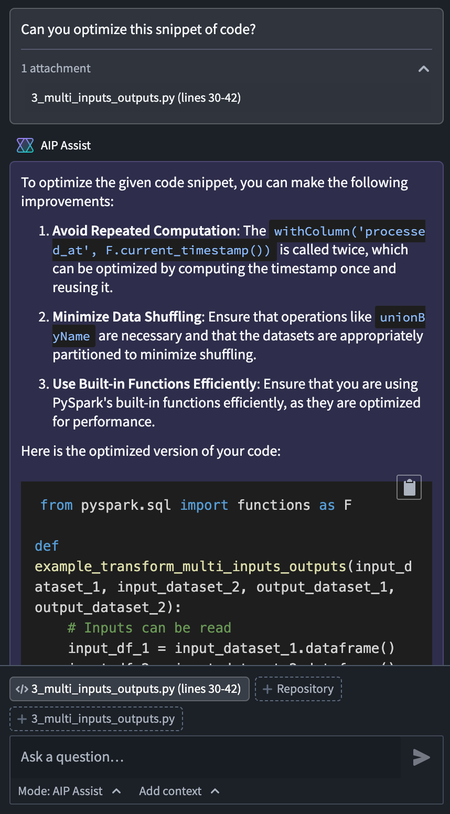
An example of AIP Assist providing optimized code.
AIP Assist will also have access to the metadata of referenced datasets and objects in attachments, enabling users to ask specific questions about Ontology objects and input or output datasets.
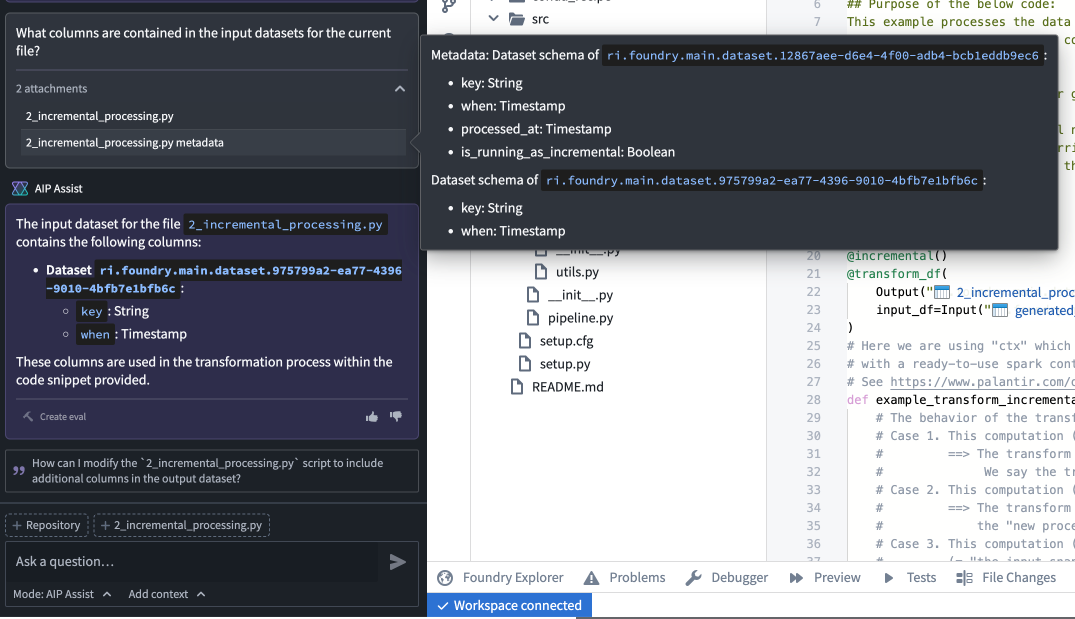
A sample question about input dataset metadata, and AIP Assist's response.
With context-aware attachments, developers will benefit from improved support that provides immediate, customized answers to their coding questions and aids the development process.
Learn more about context-aware attachments and other AIP Assist application integrations.
Note: AIP feature availability is subject to change and may differ between customers.
Performance and usability improvements in AIP Assist
Date published: 2024-11-07
An enhanced AIP Assist user experience will be generally available starting the week of November 11th. This update brings performance and usability upgrades designed to improve the overall AIP Assist experience. With this new release, you can look forward to improved product behaviors and new features, like the ability to extend the sidebar, improved keyboard navigation, and real-time synchronization across tabs.
Performance enhancements
- Improved loading behavior: Experience more controlled and predictable loading times for Agents, citations, and suggested actions. This means no more unexpected delays or rapid loads; just consistent performance.
- Cross-tab synchronization: AIP Assist now shares context across multiple tabs, updating in real-time to ensure you never lose sync. This feature enhances your ability to work seamlessly across different parts of the platform.
Usability upgrades
-
Updated mode and Agent selector: The mode and Agent selector has been relocated, and is now under the prompt text field. When selected, a pop-up window will allow users to switch between modes and Agents, and a message will be displayed in the chat after switching.
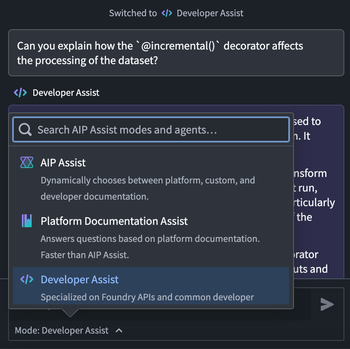
The updated mode and Agent selector under the prompt text field. -
Cycle through suggested questions: Suggested questions are now displayed in a smaller panel that allows users to cycle through available questions. Suggestions are automatically updated every 30 seconds, providing users with relevant questions as the conversation progresses.
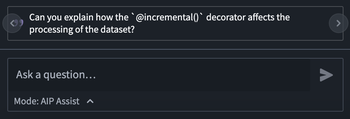
The new suggestion questions interface, featuring arrows for cycling through questions. -
Auto-scroll with new messages: Stay focused on the latest information with automatic scrolling when new messages arrive.
-
Increased sidebar size: The AIP Assist sidebar can now extend wider, providing a better view of your input window and results. The input fields will automatically resize when you adjust the sidebar, ensuring optimal readability.
The updated AIP Assist sidebar that now extends wider. -
Keyboard navigation: Navigate your message history effortlessly with the up and down arrow keys, allowing for quick access to previous messages.
-
Improved copying: Copy messages smoothly without cursor jumps, making it easier to share information.
We invite you to explore these updates and experience the improvements firsthand. Learn more about how you can leverage AIP Assist to generate value from the Palantir platform.
Note: AIP feature availability is subject to change and may differ between customers.
The Palantir platform is now a fully fledged development ecosystem
Date published: 2024-11-04
The Palantir platform is the Ontology-powered operating system for the modern enterprise, and it now comes with powerful developer tools that allow users to interact with the platform programmatically. Along with existing generally available features, APIs, and SDKs, we have released new beta functionality and will continue to expand our suite of developer tools in the coming weeks and months as part of our commitment to a development ecosystem tailored to your business and operational needs.
Ontology APIs and SDKs
The Palantir platform's foundation as a development ecosystem is the Ontology. With the Ontology, you don’t need to maintain a mental model of tables or data sources; instead, you can think in terms of the real-world objects and concepts that are essential to your operations. This enables a development ecosystem where the objects and methods are your business’s operations, and you can read and write to the Ontology with minimal code.
To leverage the Ontology's robust ability to perform high-scale queries and granular governance controls, we offer Ontology APIs and SDKs that put your organization’s concepts front and center. If you need to manage landing slots at airports, for example, add an Airport object and a landingSlots link to your Ontology, and our SDKs will generate types and functions based on your specific Ontology that can be used in your applications across the platform.
New Palantir platform APIs and SDKs
We have heard substantial feedback from users whose work relies on the Palantir platform, and we are investing heavily in developer tooling to support these users and create new ways to build with the Palantir platform. To facilitate these user workflows, we now offer APIs that enable programmatic management of platform access and the data backing your Ontology, along with existing Ontology APIs.
These APIs include:
Beta platform SDKs are also available for Python ↗ and Typescript ↗. These are usable alongside Ontology SDKs with the same Palantir platform clients, but require a Developer Console application that is not bound to an Ontology. Documentation for these beta SDKs is forthcoming; for now, early adopters can use the READMEs in each repository to get started.
On-demand developer support from AIP Assist
AIP Assist is equipped with Developer Assist, a mode designed to provide immediate, tailored assistance to support development initiatives. Starting the week of November 11th, Developer Assist will provide in-depth explanations and examples directly from platform API reference documentation to help developers make the most of our features and APIs. Developer Assist includes AIP Assist's features for accelerating your workflow, including multi-language support, a user-friendly interface, and iterative improvements powered by user feedback.
Modular developer tools
In addition to APIs and SDKs, we offer modular developer tools that will provide you with everything you need to build powerful applications that leverage the Ontology and other Palantir platform features:
- Developer Console: helps users develop applications that leverage the Palantir platform using our SDKs and OAuth clients.
- Web hosting: Allows developers to host frontend-only applications built with our SDKs on the Palantir platform, removing the need for an additional hosting infrastructure.
- Application-specific documentation: Each Ontology SDK application comes with custom API documentation tailored to the SDK content.
- Hosted Git repositories: The Code Repositories application provides a web-based integrated development environment (IDE) for writing and collaborating on production-ready code with a user-friendly way to interact with the underlying Git repository.
- Hosted Visual Studio Code: VS Code Workspaces provides an IDE for writing and collaborating on production-ready code in the Palantir platform.
The modular nature of these developer tools allows users to use what they need and combine it with existing tools and workflows, providing flexibility and promoting seamless integration.
Development roadmap
In the coming months, we are committed to expanding these APIs and SDKs, as well as the tooling surrounding them. Some features coming up in our development roadmap include:
- Developer Console support for managing granular OAuth2 scopes for Platform APIs and Ontology resources.
- An AIP Agents API that will allow users to programmatically build and deploy interactive assistants.
- A Connectivity API to create connections to external systems and set up data imports and exports.
- A Streams API for low-latency use cases, to create streaming datasets and publish records to streams.
To get started with development on the Palantir platform, refer to the Ontology SDK and platform API reference documentation.
API and feature availability is subject to change and may differ between customers.
Introducing cover pages for discoverable sensitive projects [GA]
Date published: 2024-11-04
We are excited to announce the GA release of Project cover pages, available now on all enrollments. The Project Cover Page section offers a Markdown-based rich-text editor for writing comprehensive documentation about the Project.
Cover pages can be configured to be discoverable by all users in the Project's Organization, even in cases when a Project has markings applied to it. Users without access to the Project and its files can still discover and view its cover page. This can be useful for Projects containing sensitive data and applications that should still be discoverable so that relevant users can request access to them.
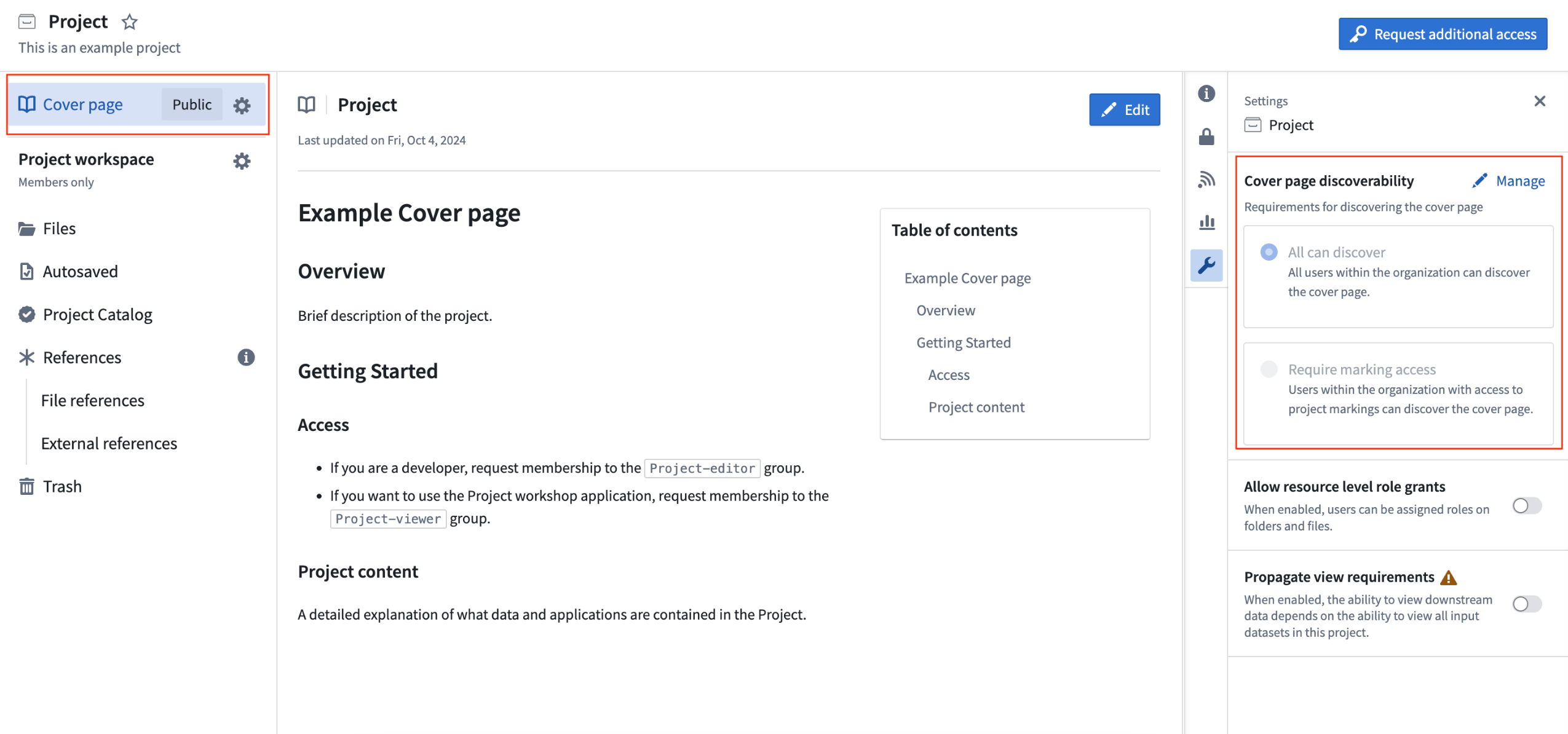
An example of a cover page for a Project.