- Capabilities
- Getting started
- Architecture center
- Platform updates
Announcements
REMINDER: Sign up for the Foundry Newsletter to receive a summary of new products, features, and improvements across the platform directly to your inbox. For more information on how to subscribe, see the Foundry Newsletter and Product Feedback channels announcement.
Share your thoughts about these announcements in our Developer Community Forum ↗.
Access the most relevant Workshop modules directly from the new Workflow Lineage landing page
Date published: 2025-06-26
An improved experience is now available when creating new or empty graphs in Workflow Lineage. In addition to using the keyboard shortcuts Cmd + i (macOS) or Ctrl + i (Windows) from a Workshop module, function repository, or, newly, an ontology object to jump into Workflow Lineage, there is now another convenient way to select the most relevant Workshop modules directly from the application. From Workflow Lineage's landing page, you can now see a list of the most recent or the most viewed Workshop modules.
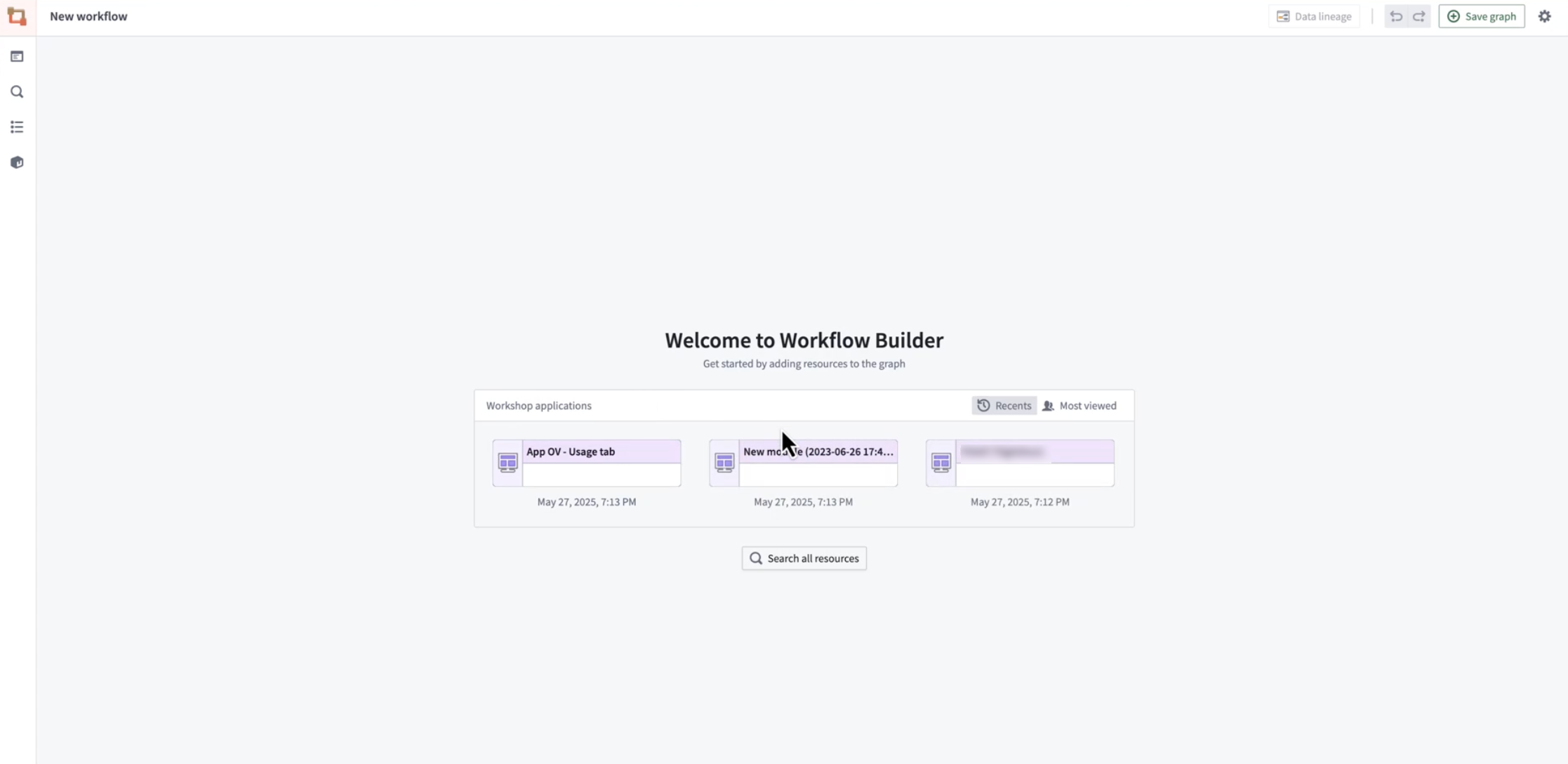
You can now access the most relevant Workshop modules directly from the new Workflow Lineage landing page.
What’s New?
When you open a new or empty graph, you will now see:
- The most recent Workshop applications: Quickly access the most recently opened Workshop applications in your workspace.
- The most viewed Workshop applications: Instantly discover the most popular and impactful workflows being used by your team. This option shows the most viewed Workshop applications in the last 30 days by all users.
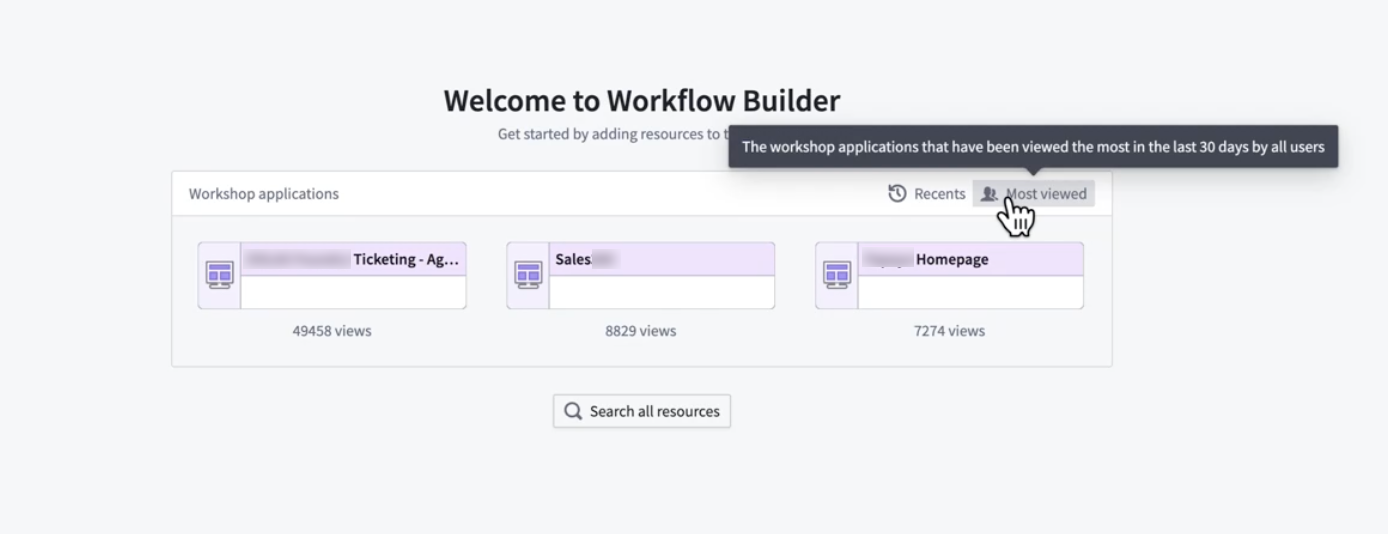
Select from the most viewed Workshop modules.
When you select a Workshop application, Workflow Lineage will automatically populate the Workflow Lineage graph with the backing resources, similar to how it populates the graph when a user uses the Cmd + i keyboard combination directly from a Workshop module.
This update makes it easier than ever to get started; explore, learn, and build with the most important workflows at your fingertips.
Learn more about Workflow Lineage features in the documentation.
We want to hear from you
Share your feedback with us through Palantir Support or our Developer Community ↗.
Version range dependencies for functions
Date published: 2025-06-26
Previously, Foundry applications could only depend on functions at pinned versions. With the introduction of version range dependencies for functions, applications like Workshop, Actions, and Automate can now depend on functions at version ranges. This enables automatic upgrades at runtime, saving you time in your development cycle and ensuring deployed functions upgrade with zero downtime.
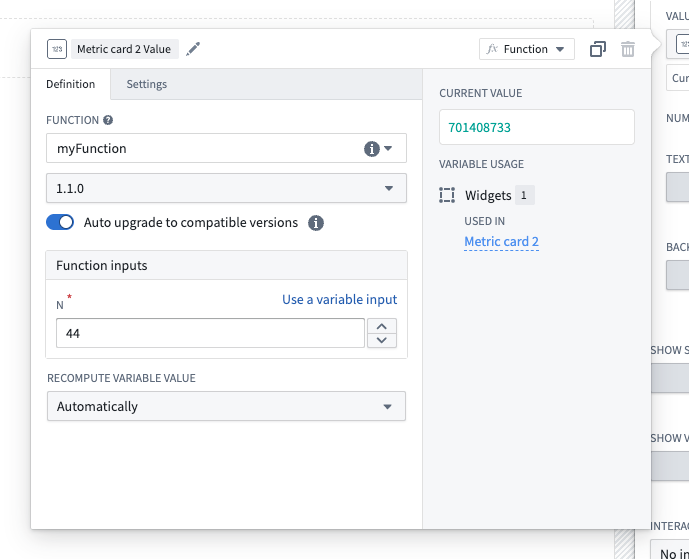
Configure a version range dependency for a function-backed widget in Workshop using the new Auto upgrade toggle.
Versioning your functions
The introduction of version range dependencies makes proper release versioning more critical than ever. To help you in this process, new backward compatibility checks are now available when tagging your functions.
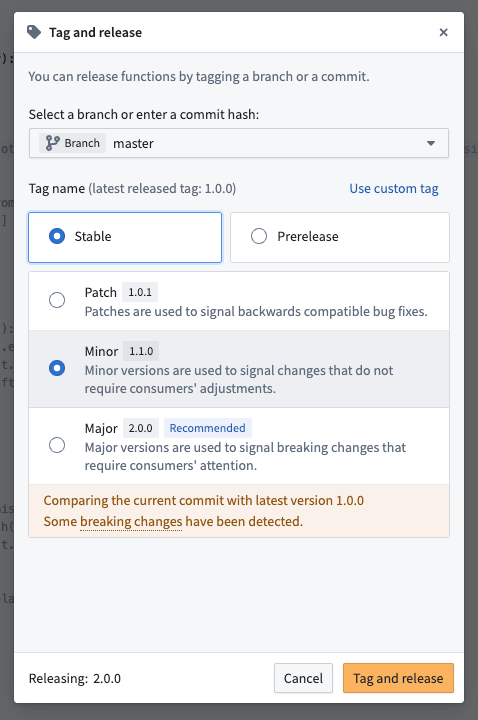
Backward compatibility checks run automatically when you tag a new version of your functions in Code Repositories.
Learn how to properly version your functions to ensure that you provide function consumers with a stable and reliable experience.
Your feedback matters
We want to hear about your experience with functions and welcome your feedback. Share your thoughts with Palantir Support channels or on our Developer Community ↗ using the functions tag ↗.
Python 3.12 support in Code Repositories and VS Code Workspaces now available
Date published: 2025-06-26
Python 3.12 support in Code Repositories and VS Code Workspaces is now available across all enrollments, adding Python startup time improvements, optimized comprehensions, reduced memory footprint, and other new features. This version is available across all Python environments, including during preview, checks, and builds for Python transform operations.
Highlights from Python 3.12 include:
- Faster startup: Reduced interpreter initialization time (10-15% improvement in all Python process startup times)
- Memory optimization: Lower memory usage overall
- Improved multithreading: Enhanced performance with subinterpreters
- Inlined comprehensions: Significantly faster Python comprehensions
To benefit from the latest performance improvements and essential security fixes, upgrade your repositories and set your Python environment to recommended version or explicitly select Python 3.12.
Build an advanced to-do application with OSDK, now available in VS Code workspaces
Date published: 2025-06-24
The advanced to-do application, available through VS Code workspaces, demonstrates how to use advanced features of the Ontology SDK (OSDK) and Platform SDK by building a to-do application as a practical example. You will learn about many OSDK features, including the following:
- Ontology interfaces: Use ontology interfaces to interact seamlessly with backend services.
- Media content handling with media sets: Handle media content efficiently within your to-do application.
- Runtime-derived properties: Leverage runtime-derived properties for dynamic data handling and real-time updates.
- Platform SDKs: Integrate with the platform SDK for enhanced application functionality.
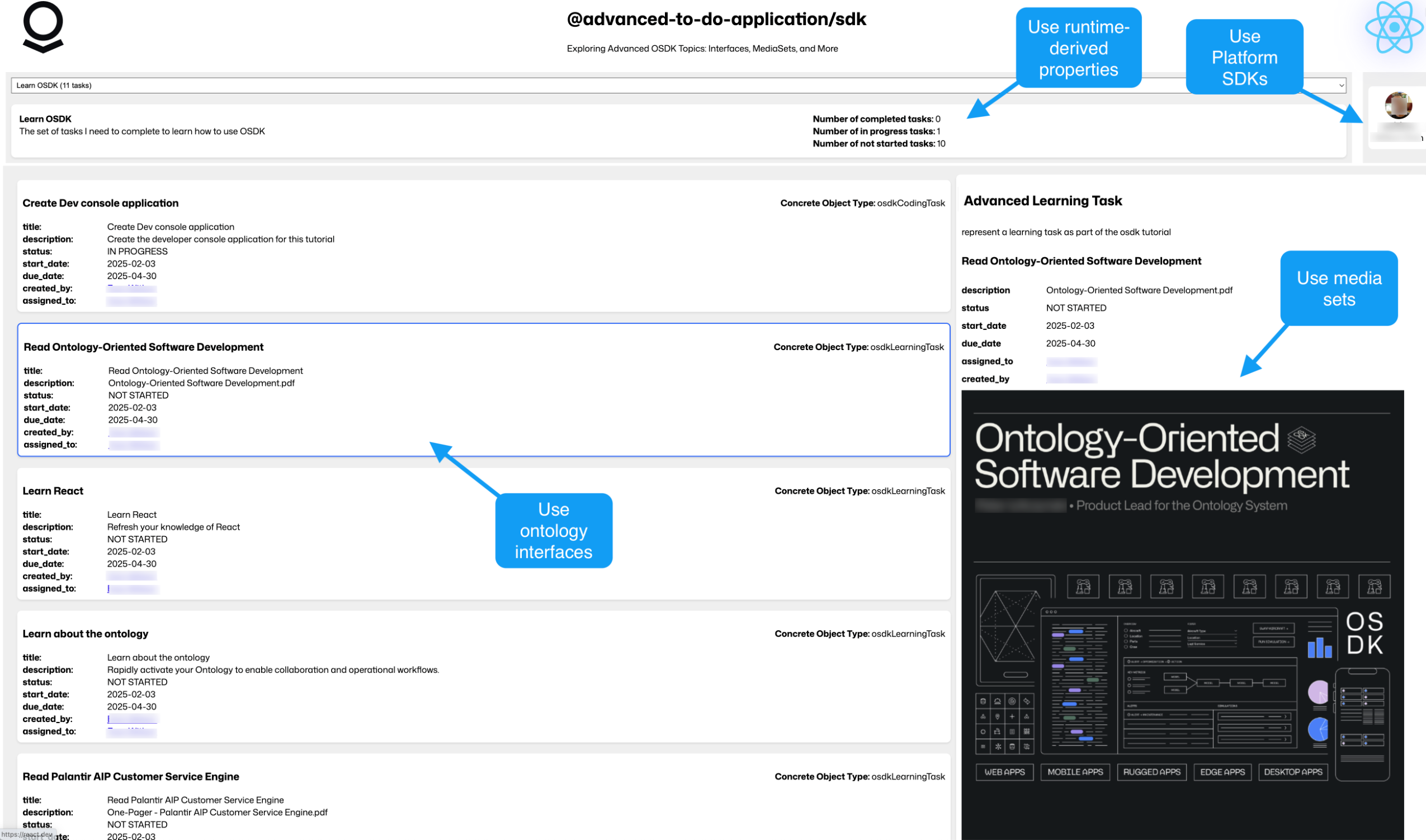
The advanced to-do application, with annotations where advanced OSDK features are used.
Get started
To access and install the advanced to-do application example, open the Code Workspaces application and choose to create a + New Workspace. Then, select VS Code > Applications and find the application in the curated examples list.
You can also search for the application in the platform Examples (Build with AIP), or by searching the Ontology SDK reference examples in Developer Console.
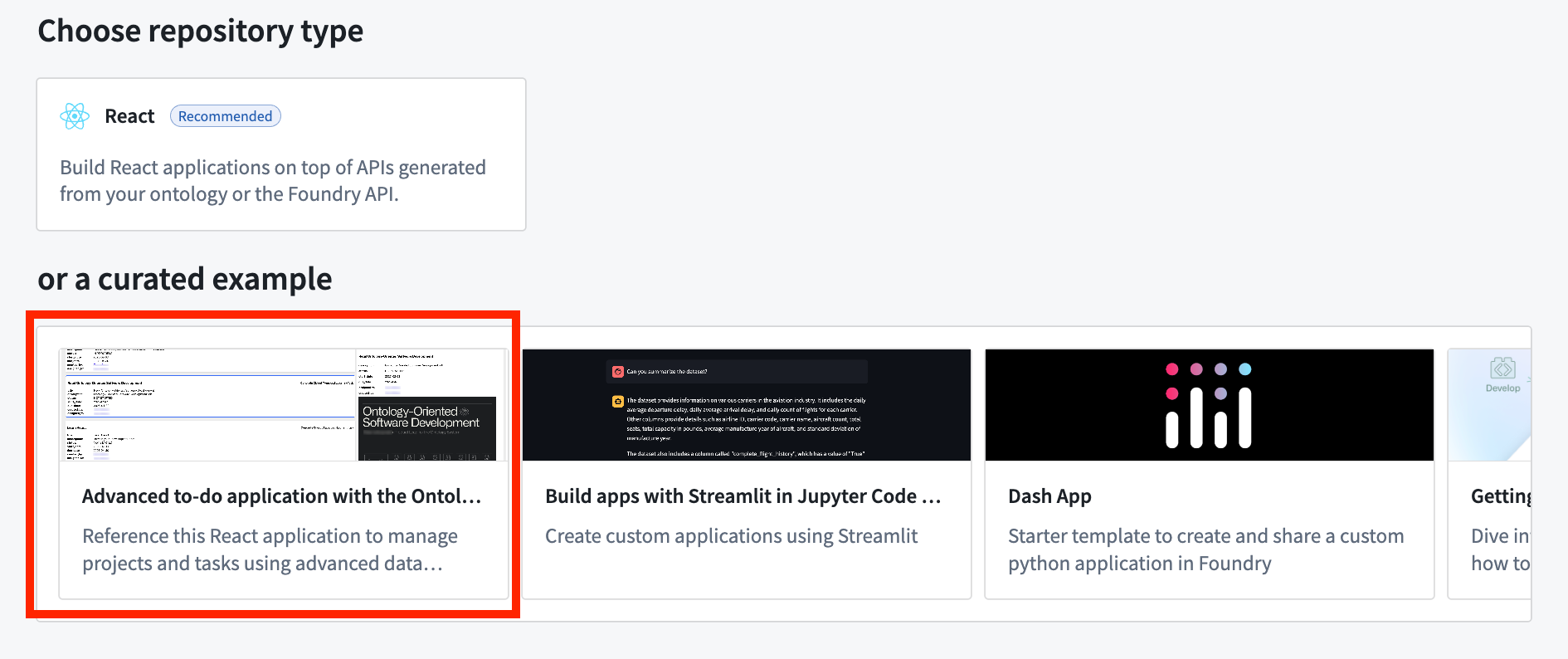
Create an application in a VS Code workspace to choose the advanced to-do application example.
The advanced to-do application application will then be installed through Marketplace.
What's included in this example?
When you first install the example, it will include the Advanced to-do application ontology, an ontology that can be installed only once in each space to ensure API names remain unique and constant. After installation, be sure that all objects were synced to the ontology before you run the application; you can verify this by opening the Advanced to-do object types in Object Explorer. After syncing, the data from the ontology should automatically appear when you open the example.
The installed example will open the code repository and run the application in a VS Code workspace using the Palantir extension for Visual Studio Code. Review the included Markdown documents to learn more about the project and detailed explanations for data services. You can also explore our public documentation to learn more about the architecture and configuration of the application and the custom React hooks used.
What's next?
We are currently working on more examples to demonstrate other features available with the OSDK, including write operations with ontology interfaces and other advanced filtering patterns. Share your feedback with Palantir Support or our Developer Community using the ontology-sdk tag ↗ if you have ideas for more examples and tutorials that you would like to see.
Introducing metric objectives for AIP Evals
Date published: 2025-06-19
Metric objectives are now available in AIP Evals, giving you more control over how your evaluation results are measured and interpreted. Previously, users could see raw metric values for each test case. However, it was difficult to determine at a glance whether a model’s output truly met expectations, especially when dealing with multiple metrics or large suites.
With metric objectives, you can now define what success looks like for each metric in your evaluation suite. For Boolean metrics, you can choose whether true or false indicates a passing result. For numeric metrics, you can select whether higher or lower values are better, and optionally set a threshold for passing. This makes it easier to enforce standards and quickly identify regressions or improvements in your models.
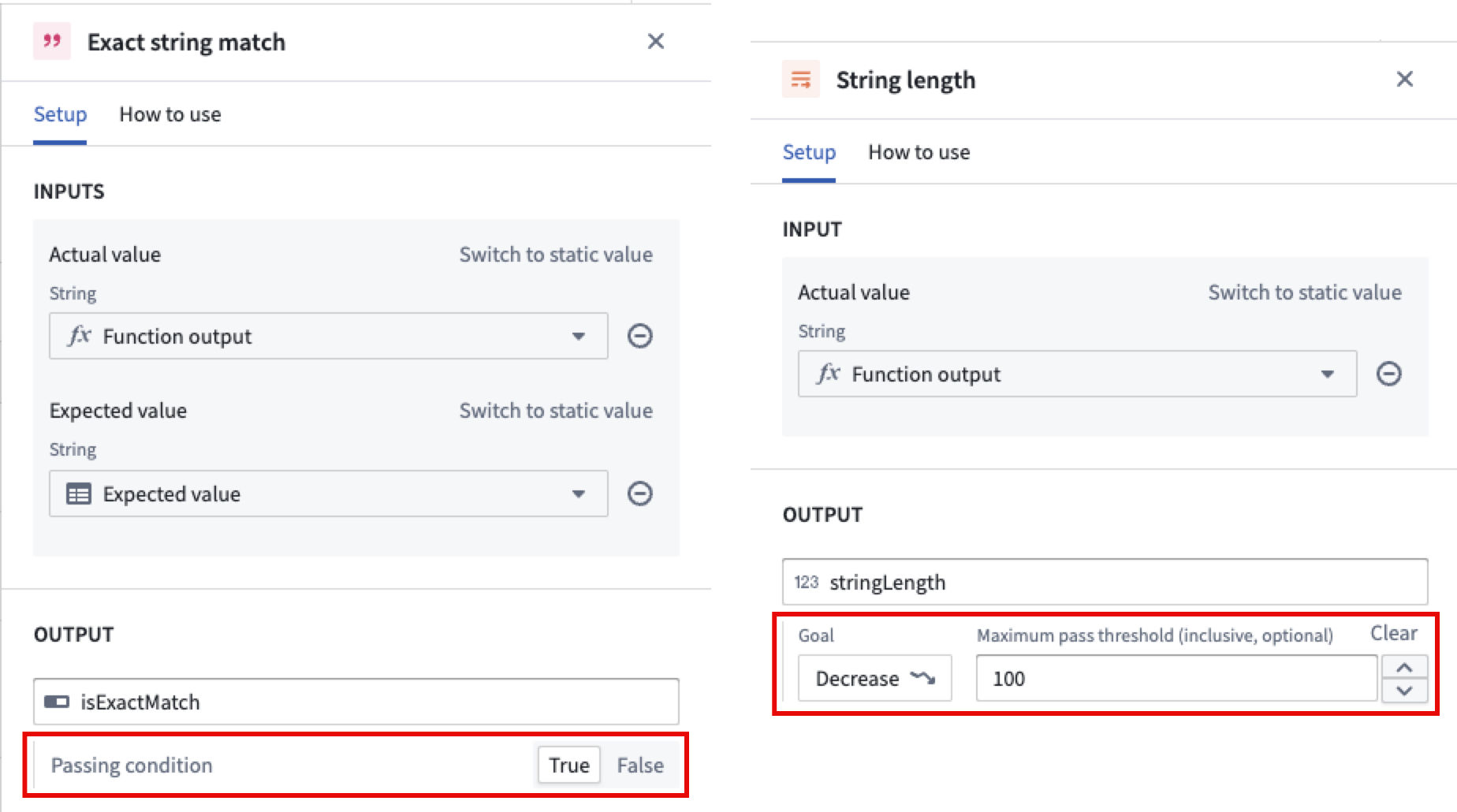
Pass/fail configurations configured for Boolean and numerical metrics.
When you run an evaluation suite, AIP Evals will automatically determine and display the pass/fail status for each metric and test case based on your configured objectives. The run results dialog now clearly visualizes which metrics and test cases passed or failed according to your criteria, making it easier to track quality and communicate results.
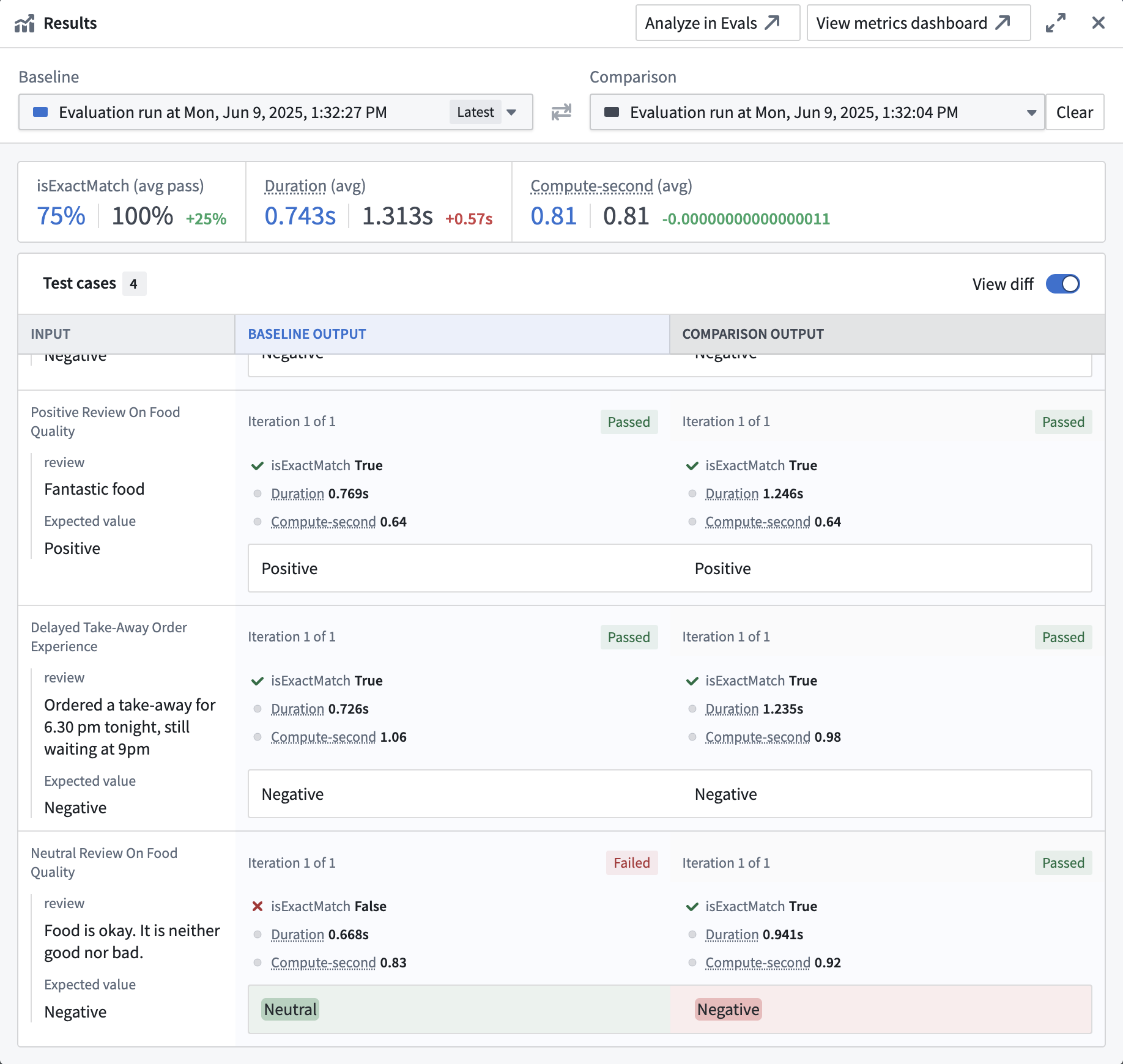
Pass/fail status for metrics and test cases in the run results dialog.
Learn more about metric objectives in AIP Evals.
For additional assistance with metric objectives for AIP Evals, contact Palantir Support or visit our Community Forum ↗.
Introducing multi-type retrieval context support for AIP Agents
Date published: 2025-06-19
AIP Agents now support multiple types within the retrieval context. This means that you can provide multiple object sets, functions, and documents simultaneously as retrieval context. Each context is resolved to a string prompt in the order the types were added to the agent, on each new user message. Multiple contexts of the same type are supported, enabling semantic search on one document collection and full-text extraction on another within the same retrieval context prompt.
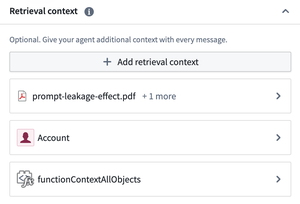
You can now provide your agent additional retrieval context using multiple types.
Citation configuration for agents is now centralized in order to support multiple context types. Previously, citation configuration was nested within individual retrieval context configurations such as document, ontology, or function RAG. As all existing citation configurations have been migrated to the new centralized citation settings, no further user action is required to benefit from multi-type retrieval context.
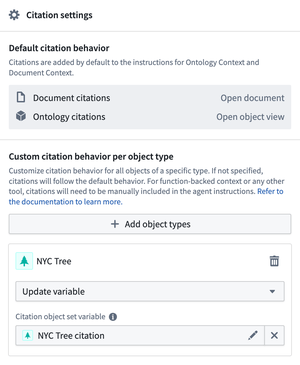
Configure custom citation behavior per object type in the AIP Agent Studio sidebar.
Finally, citations can now be enabled or disabled globally for all retrieval contexts. Citation settings allow configuration of overrides for ontology citations, with each object type mapped to its own citation override. For example, a citation from object type A can be configured to open an external link, while a citation from object type B can be configured to open a media item.
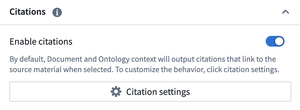
Enable citations to allow users to see the information source used by the AIP Agent.
Share feedback with us
We want to hear about your experiences and welcome your feedback. Share your thoughts with Palantir Support channels or our Developer Community ↗ and use the aip-agent-studio ↗ tag.
Introducing use_sidecar: Run models in dedicated containers within Python transforms
Date published: 2025-06-12
Starting from palantir_models version 0.1673.0, the ModelInput class exposes a use_sidecar parameter in Python transforms. When use_sidecar is set to True, the model is run in a separate container provisioned on top of the machines running the Spark transform itself, thereby ensuring easy, portable and reliable production usage of models across the platform. This feature prevents dependency conflicts that can occur when importing models built in a different repositories or code workspaces into Python transforms for inference. Furthermore, this guarantees that your models operate with the exact dependencies with which they were built, protecting users from unexpected behavior or runtime failures.
Note that use_sidecar is not supported in lightweight transforms, and previewing transforms with a sidecar ModelInput is also not supported.
Key features and benefits
- Dependency isolation:
use_sidecarensures your model runs in a controlled environment with its original dependencies, preventing conflicts with your transform's libraries. - Guaranteed reproducibility: Execute your models with the assurance that they are using the identical library versions with which they were trained and validated for consistency and reliability.
- Simplified cross-repository and multiple model usage: When employing models built in a different repository or a Code Workspace,
use_sidecarautomatically manages the loading of the correct model adapter code. This removes the need to manually update dependencies in your transform's repository and run checks if the adapter code or dependencies changed with a new model version, and allows you to import multiple models into the same repository without worrying about clashes. - Customizable resources: Specify CPU, memory, and GPU resources for the sidecar container via the
sidecar_resourcesparameter.
How to use
To load the model in a container, simply set use_sidecar=True. No other code changes are necessary.
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20from transforms.api import Input, Output, transform, TransformInput, TransformOutput from palantir_models.transforms import ModelInput, ModelAdapter @transform( out=Output('path/to/output'), model_input=ModelInput( "path/to/my/model", use_sidecar=True, sidecar_resources={ "cpus": 2.0, "memory_gb": 4.0, "gpus": 1 } ), data_in=Input("path/to/input") ) def my_transform(out: TransformOutput, model_input: ModelAdapter, data_in: TransformInput) -> None: inference_outputs = model_input.transform(data_in) out.write_pandas(inference_outputs.output_df)
To learn more, review the ModelInput class reference documentation.
Configure custom enrollment roles in Control Panel
Date published: 2025-06-10
You can now create custom roles to grant granular enrollment-level workflows from the Enrollment permissions page in Control Panel.

Configure your enrollment custom roles through the Enrollment permissions configuration page in Control Panel.
Custom roles are useful in situations when users or groups require permissions for particular workflows that do not match existing default roles. For example, by creating a custom IT group, you can allow permissions for that group to add or modify domains without granting permissions to change ingress or egress settings.

Select the individual workflows to grant to members of a new custom role.
To get started creating custom roles, navigate to Enrollment Permissions settings in Control Panel, or learn more in our public documentation.
For additional assistance with custom roles, contact Palantir Support or visit our Community Forum ↗.
Announcing Machinery, for building, automating, and optimizing processes
Date published: 2025-06-05
Machinery is an application for modeling real-world events, such as healthcare procedures, insurance assessments, and government operations, as processes that can be explored in real-time through custom AI-powered applications tailored to your needs. As of the first week of June, Machinery is now generally available across all enrollments.
Use Machinery to mine or implement a process, identify unwanted behaviors, and make measured progress towards achieving desired outcomes. Additionally, facilitate human intervention to reduce inefficiencies and improve your process performance over time.

Implement a process from scratch, review, and optimize with Machinery.
Common workflows for Machinery include:
- Resolving process inefficiencies with the help of AIP and automation
- Managing an AIP use case end-to-end by orchestrating several AI agents
- Building operational applications to supervise AIP workflows with real-time human intervention
- Mining an ongoing process from external event logs to gain visibility into an existing process
- Defining and monitoring performance metrics and expectations to identify process bottlenecks
Optimize your process with automation and AIP
Implementing a process in the Palantir platform involves many individual resources, such as object types, actions, and automations. Machinery now provides a comprehensive view for all these components and lets you define an ordered flow of automations and manual actions. Its unique state-centric perspective allows you to make incremental progress towards desired outcomes while handling and resolving the edge cases of your organization. Value types and submission criteria can then provide an additional layer of conformance guarantees.

Automation nodes can be built into a Machinery graph.
Machinery boasts a custom layout algorithm with the auto-layout feature allowing for visually appealing graphs without need of manual manipulation. Users can also disable this feature and freely move elements, allowing for customized adjustments tailored to individual preferences.
Multiple object type modeling in a single Machinery graph
Create subprocesses and parallel processes to benefit from greater flexibility and control over workflows. Subprocesses allow you to create nested processes within your main Machinery process, providing a structured way to manage complex tasks and enabling seamless integration into the larger workflow. This modular approach also supports parallel processes, allowing multiple processes to run concurrently, thereby enhancing efficiency and reducing bottlenecks.

You can now build multiple linked processes in Machinery, allowing you to model processes acting across your whole organization.
The focus view feature further elevates user experience by allowing users to zoom in on specific subprocesses, providing a detailed view that simplifies navigation and management of intricate workflows. With these capabilities, users can manage complexity across the organization for a higher level of process automation, ultimately leading to improved productivity and streamlined operations.
Mining mode
After configuring the log ontology, users can enter mining mode, which presents a distinct graph highlighting both existing states and potential edits in sepia color. Users can exclude certain states from mining, effectively reducing noise and focusing on relevant data. Use the transition frequency slider to filter out less important nodes, ensuring that only the most critical transitions are highlighted while benefiting from the clean auto-layout graph.

Mining an entire process in Machinery mining mode.

Machinery mining mode, with a transition filter to filter out nodes that have less than 71.5% objects passing through.
Bootstrap your development by generating a Workshop module
To operationalize your process in the Palantir platform, you can quickly bootstrap a Workshop module ("Machinery Express application") with a single click to initiate your application development. The express application serves as a dynamic playground where you can conduct analysis and intervene with your agentic workflows in real-time. Then, jump back into Machinery to refine, update, or optimize your processes with actions, automations, and AIP logic functions.
Whether you choose to use Machinery Express as a ready-to-use analysis tool or as a foundation to build your own applications, it facilitates a fluid interaction between process exploration and refinement. Additionally, the Machinery Express application enables you to immediately share this process with your operational users, providing them with the necessary context to effectively engage with the system in real time.

Generate a Machinery Express application to help get you started on application development in Workshop.
If you prefer to build a new application from scratch or add Machinery to an existing Workshop module, you may add a Machinery Process Overview widget in Workshop.
For more information on Machinery, review the documentation.
We want to hear from you
We want to hear about your experiences and welcome your feedback. Share your thoughts with Palantir Support channels or our Developer Community ↗ and use the machinery ↗ tag.
Databricks enhanced connectivity and compute pushdown now available
Date published: 2025-06-05

As part of Palantir’s partnership with Databricks, enhanced connectivity options offer a range of capabilities on top of data, compute, and models for a more seamless integration of the Palantir and Databricks platforms. In particular, virtual tables, compute pushdown, and external models are now generally available.
| Capability | Status |
|---|---|
| Exploration | 🟢 Generally available |
| Bulk import | 🟢 Generally available |
| Incremental | 🟢 Generally available |
| Virtual tables | 🟢 Generally available |
| Compute pushdown | 🟢 Generally available |
| External models | 🟢 Generally available |
For detailed guides, see Palantir’s updated Databricks documentation.
Virtual tables
Palantir now offers enhanced virtual table capabilities on top of data in Databricks, including:
- Spark and JDBC-based connectivity from a single unified connector
- Enhanced functionality exposes the features of Delta Lake and Apache Iceberg
- Palantir can now access tables using the Unity REST API and Iceberg REST catalog, and read and write data in the underlying storage locations using vended credentials from Unity Catalog
- Bulk and automatic registration of virtual tables
- Virtual table inputs in Contour, Code Repositories, and Pipeline Builder
- Virtual table outputs in Code Repositories and Pipeline Builder
- Incremental pipelines
See the Databricks virtual tables documentation for more details on registering and using virtual tables from Databricks.
Compute pushdown
The ability to push down compute to Databricks is now available. When using virtual tables as inputs and outputs to a pipeline that are registered to the same Databricks source, it is possible to fully federate the compute to Databricks. This capability leverages Databricks Connect ↗ and is currently available in Python transforms.
See the Databricks compute pushdown documentation for syntax details and a quickstart example.
External models
Databricks models registered in Unity Catalog can be integrated into the Palantir platform via externally-hosted models and external transforms. This allows Databricks models to be leveraged operationally by Palantir users, pipelines, and workflow applications.
For more details, see the Databricks external models documentation.
Share your feedback
Share your feedback about Palantir’s Databricks integration by contacting our Palantir Support teams, or let us know in our Developer Community ↗ using the databricks tag ↗.
Introducing virtual table outputs in data transformations
Date published: 2025-06-05
Virtual table outputs are now supported in Pipeline Builder and Code Repositories as a beta feature. A virtual table acts as a pointer to a table in a source system outside the Palantir platform, and allows you to use that data in-platform without ingesting it. Virtual tables were previously only available as inputs to Foundry data transformations, meaning any output datasets would be stored in Foundry. Now you can orchestrate entire pipelines with logic authored in Foundry, and data stored externally.
You can add virtual table outputs as you would any other Pipeline Builder output. Select a node and choose the new virtual table output type.

A virtual table output in Pipeline Builder.
When configuring your output in Code Repositories, select the new virtual table type. You will then be prompted to configure your output source.

Configuring a virtual table output in Code Repositories file templates.
Note that query compute may be split between Foundry and the source system for:
- All queries in Pipeline Builder
- Transformations in Code Repositories that do not explicitly use compute pushdown. Full compute pushdown outside of lightweight transforms is not yet available.
What's next
Table support is improving across the Palantir platform. Upcoming work includes:
- Virtual tables in Code Workspaces.
- Support for Foundry-native Iceberg tables as inputs and outputs.
Share your feedback
Share your feedback about virtual table outputs by contacting our Palantir Support teams Palantir Support teams, or let us know in our Developer Community ↗ using the virtual-tables tag ↗.
Virtual table bulk registration now available
Date published: 2025-06-05
Virtual tables can now be created in bulk for tabular source types, such as Databricks, BigQuery, and Snowflake. Select Create virtual table, and you will now be able to create one or more virtual tables at once for supported sources.

Creating a new virtual table.
To bulk register virtual tables in Data Connection, select external tables in the left panel, and choose where to save your new virtual tables in Foundry in the right panel.

An example of virtual table bulk registration in Data Connection.
Learn more about bulk registering virtual tables.
Share your feedback
Share your feedback about virtual table outputs by contacting Palantir Support, or let us know in our Developer Community ↗ using the virtual-tables tag ↗.
Streamline vision LLM-based PDF extraction with new transform input types
Date published: 2025-06-03
New transform input types are now available to simplify the creation of transforms for vision LLM-based extraction workflows. These transform input types abstract common logic and enable users to select their desired level of customization. Writing transforms to convert PDF content into Markdown is now more efficient, while maintaining flexibility for users that want to customize their workflows.
What is vision LLM-based extraction?
Vision LLMs can extract information from complex documents with mixed content, such as tables, figures, and charts, with high accuracy. To implement these vision LLM-based workflows, custom logic needs to be written in transforms that are applied to media sets containing PDF documents. Previously, multiple complex steps had to be implemented, such as image conversion and encoding. We now provide transform input types that simplify and expedite this process.
The following transform input types are now available:
VisionLLMDocumentsExtractorInput: Processes PDF media sets by taking each media item and splitting it into individual pages. These pages are converted into images and sent to the vision LLM. This option is recommended for cases where custom image processing is not necessary, and a solution that handles every step of the process is preferred.VisionLLMDocumentPageExtractorInput: Processes individual pages of a PDF document. This option is recommended in cases where users want more flexibility and control over the extraction process. For example, users can apply custom image processing, or handle splitting PDF pages with custom logic.
These new transform inputs abstract common document extraction logic, including image conversion, resizing, encoding, and a default prompt that is carefully tuned for document extraction. In addition to a simplified interface, users have the option to provide a custom prompt, and can customize image processing as needed with the VisionLLMDocumentPageExtractorInput type.
Below is a sample implementation, demonstrating a significantly shorter and simplified Python transform:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19from transforms.api import Output, transform from transforms.mediasets import MediaSetInput from palantir_models.transforms import VisionLLMDocumentsExtractorInput @transform( output=Output("ri.foundry.main.dataset.abc"), input=MediaSetInput("ri.mio.main.media-set.abc"), extractor=VisionLLMDocumentsExtractorInput( "ri.language-model-service.language-model.anthropic-claude-3-7-sonnet") ) def compute(ctx, input, output, extractor): extracted_data = extractor.create_extraction(input, with_ocr=False) output.write_dataframe( extracted_data, column_typeclasses={ "mediaReference": [{"kind": "reference", "name": "media_reference"}] }, )
A Python transform implementation using the new VisionLLMDocumentsExtractorInput.
Vision LLM-based document extraction and parsing has become one of the most prevalent workflows in Foundry, and creating transforms for these workflows is now more efficient than ever before. To learn more, review the vision LLM-based extraction documentation.
Your feedback matters
We want to hear about your experiences with transforms, and welcome your feedback. Share your thoughts with Palantir Support channels or on our Developer Community ↗ using the transforms-python ↗ and language-model-service ↗ tags.
Manage platform SDK access in Developer Console
Date published: 2025-06-03
The Platform SDK Resources page is now available in Developer Console, allowing developers to manage application access to Foundry resources. Developers can now configure application access to projects, define client-allowed operations, and control access to designated API namespaces. The Platform SDK Resources page offers comprehensive security and compliance settings to help ensure that integrations align with organizational policies, while facilitating secure and seamless interactions with Foundry resources.

The new Platform SDK Resources page, displaying the Project access and Client-allowed operations sections.
In the example shown above, the Project access section allows developers to choose the projects that an application can interact with, while the Client-allowed operations section allows developers to choose the methods that can be used to interact with the selected projects.
API-level security for client-allowed operations
As of Spring 2025, new Developer Console applications enforce API-level security for scoped applications, ensuring that every endpoint called by these applications is explicitly added to the client-allowed operations in the Platform SDK resources page.
With this new level of security, access is only granted to API namespaces, ensuring that application administrators can control the actions that applications take in their organization. Prior to these changes, granting an API namespace scope provided access to the namespace's endpoints as well as any dependent endpoints in other namespaces. These new, more secure API scopes are isolated, providing access only to the endpoints shown in the Client-allowed operations section.
This new level of security applies to all new Developer Console applications; to benefit from these new security features, migrate your application by following our step-by-step guide.

The migration callout for legacy Developer Console applications.
Get started
To get started with the Platform SDK Resources page, navigate to the SDK section of your Developer Console application and select Resources > Platform SDK Resources.

Navigating to the Platform SDK resources page in Developer Console.
On the Platform SDK Resources page, you can manage the resources and operations that your application client has access to. To add additional resources to the client, select Add Project and choose the project you want to add the client's scope. After saving, your application will have access to the resources in the project.
To modify the operations that can be performed by the client, navigate to the Client-allowed operations section and use the toggle to define the operations that your application has access to. When you make a change in this section it will apply to all existing SDK versions without the need to generate a new SDK.

Using the Platform SDK Resources page to modify the resources and operations available to the application client.
What's next?
We are currently working on documentation for our TypeScript, Python, and Java platform SDKs, in addition to enhancing the application client creation flow to improve the developer experience.
Need support?
We are always happy to engage with you in our Developer Community ↗. Share your thoughts and questions about the OSDK and Developer Console with Palantir Support channels or on our Developer Community using the ontology-sdk ↗ tag.
For more information, refer to the operation scope and API security and migration documentation.