- Capabilities
- Getting started
- Architecture center
- Platform updates
Announcements
REMINDER: Sign up for the Foundry Newsletter to receive a summary of new products, features, and improvements across the platform directly to your inbox. For more information on how to subscribe, see the Foundry Newsletter and Product Feedback channels announcement.
Share your thoughts about these announcements in our Developer Community Forum ↗.
Agent proxy egress policies are now generally available
Date published: 2025-09-30
Previously, connecting Foundry to systems that cannot be accessed directly from Foundry (on-premise systems, in most cases) meant sacrificing scalability. While "direct connection" egress policies worked well for resources accessible from Foundry (such as most internet-facing systems), private networks required workloads to run directly on local data connection agents, limiting your ability to leverage Foundry's full computational power.
What's new?
Agent proxy egress policies address this limitation by allowing data connection agents to act as secure bridges between Foundry's scalable compute environment and your private, on-premise systems. This means you can do the following:
- Run demanding workloads at scale while accessing on-premise data.
- Use advanced Foundry capabilities like pro-code transforms, external functions, compute modules, and virtual tables that were previously limited to internet-accessible systems.
Real-world impact
You can now author custom transforms that read and write to SFTP servers, process large datasets from private databases using Foundry's full compute power, and build sophisticated data pipelines that seamlessly bridge cloud and on-premise environments.
The new standard
Agent proxy egress policies with a Foundry worker are now our recommended approach for connecting to systems on separate networks, replacing the previous agent worker method. They also supersede agent proxy runtime (which only supported REST sources and will be sunset soon).
Getting started
Setting up is straightforward:
- Navigate to the Network egress settings in Control Panel, then choose Request network egress policy.
- Specify the domain and port (just like with direct connections).
- Assign one or more agents with connectivity to your target systems. These agents must have inbound connectivity to the domain and port that this policy allows.
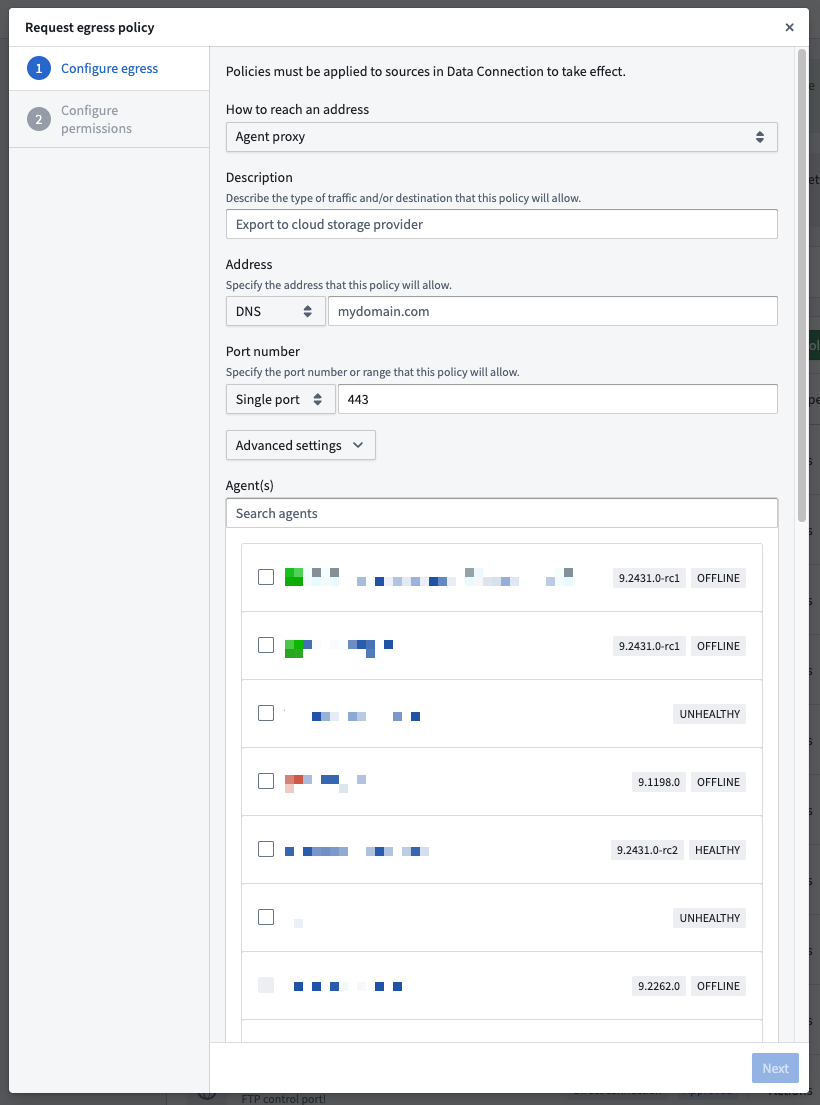
The agent proxy egress policy configuration dialog in Control Panel.
We want to hear from you
As we continue to develop new connectivity features and improvements, we want to hear about your experiences and welcome your feedback. Share your thoughts with Palantir Support channels or our Developer Community ↗ using the data-connection ↗ tag.
Typescript v1 functions are now supported by Foundry Branching
Date published: 2025-09-30
You can now develop, publish, and consume Typescript v1 functions on a Foundry branch. This feature, currently in beta, enables the development of functions that depend on changes made to resources on your Foundry branch, such as newly-created or modified ontology entities. Additionally, prototype and test function changes on the branch before deploying all changes together.
On your Foundry branch, publish pre-release versions of your function that are only accessible from that branch. Select that pre-release version to depend on it in actions or Workshop modules. When you merge your branch, the function publishes on Main and usages that depended on the branched pre-release automatically switch to the stable version published from Main.
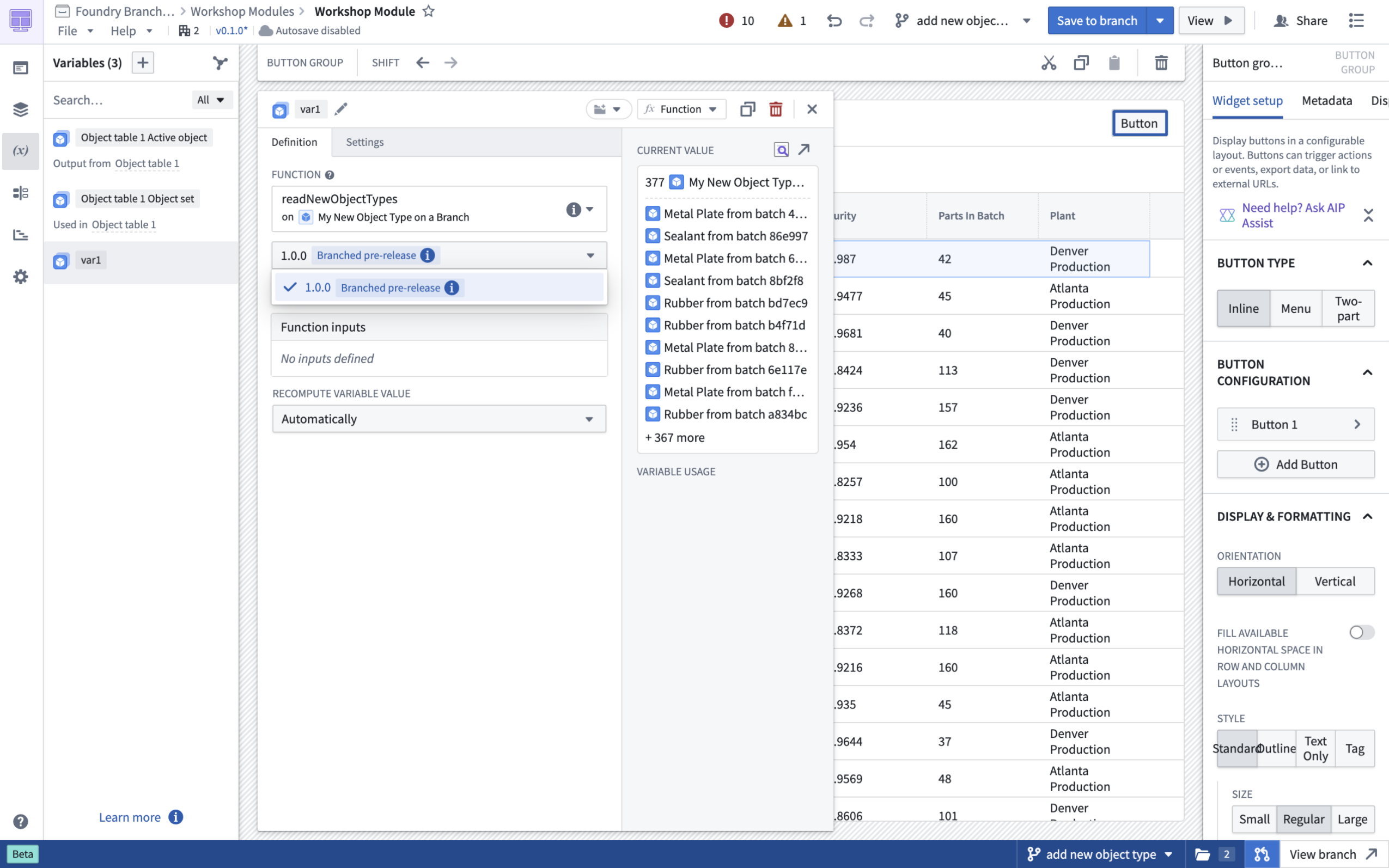
Select a pre-release version of your function to test function changes.
Currently, supported functionality includes depending on the branched pre-release version in actions or Workshop. Depending on branched pre-release functions in other code repositories is not yet supported. To get started, take a look at the Foundry Branching documentation and create or check out a Foundry branch from your Typescript functions v1 code repository.
We want to hear from you
As we continue to develop new features for Foundry Branching, we want to hear about your experiences and welcome your feedback. Share your thoughts with Palantir Support channels or our Developer Community ↗ and use the foundry-branching ↗ tag.
Automatically generate test cases and evaluators for AIP Logic function
Date published: 2025-09-11
AIP Logic users can now automatically generate test cases and evaluators for functions using the new AIP Evals Generate evals feature. This feature, currently in beta, makes it easier for users to get started with evaluating and improving AI functions by generating useful test cases, evaluators, and metrics instead of creating evaluation suites from scratch.
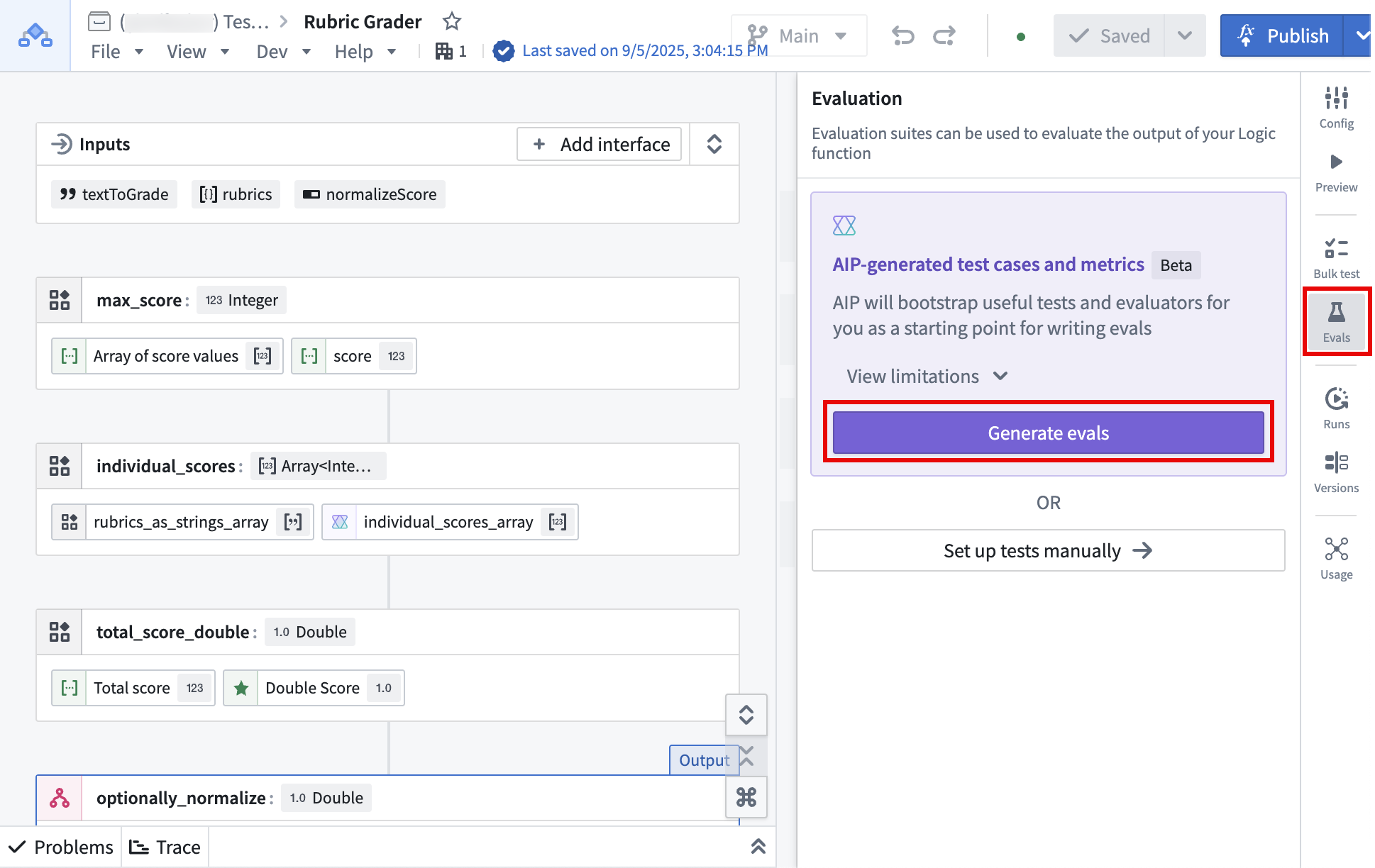
The Generate evals option, found in the Evals tab in the right toolbar.
To generate an evaluation suite, AIP will analyze your logic, select and configure the appropriate evaluators, and create test cases. You then can modify and refine generated test cases and evaluators as needed.
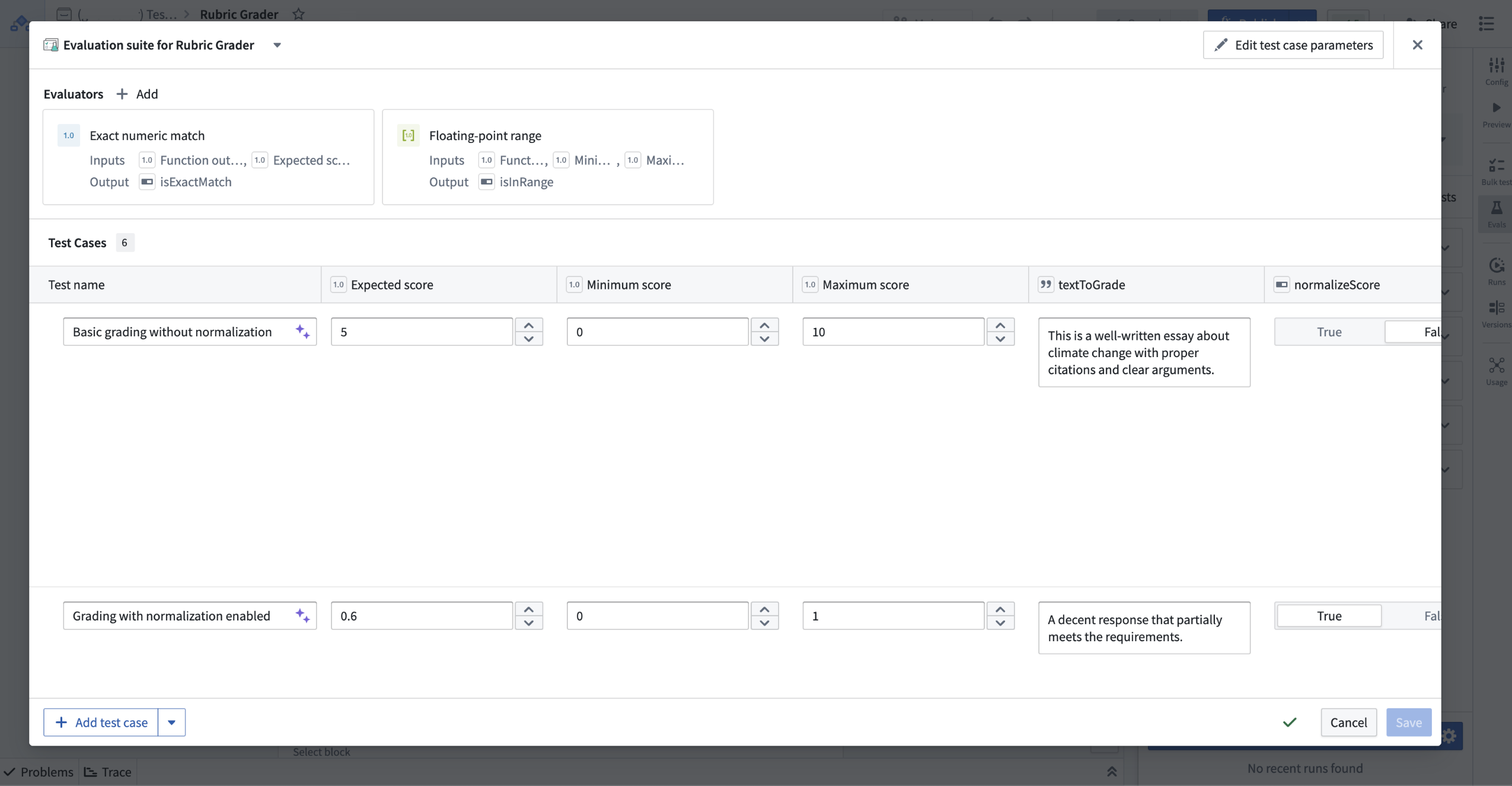
Test cases in an evaluation suite can be edited after generation.
What's next?
To further improve your experience with AIP Evals, we are working on expanding support for more complex Logic functions, improving generation intelligence and capabilities, and adding support for AIP-assisted editing of evaluation suites.
Your feedback matters
We want to hear about your experience with AIP Evals and welcome your feedback. Share your thoughts with Palantir Support channels, or on our Developer Community ↗ using the aip-evals tag ↗.
Ontology Manager now supports virtual table and Iceberg table-backed object creation
Date published: 2025-09-11
You can now create table-backed objects directly in Ontology Manager. This is supported for both virtual tables and Iceberg tables.
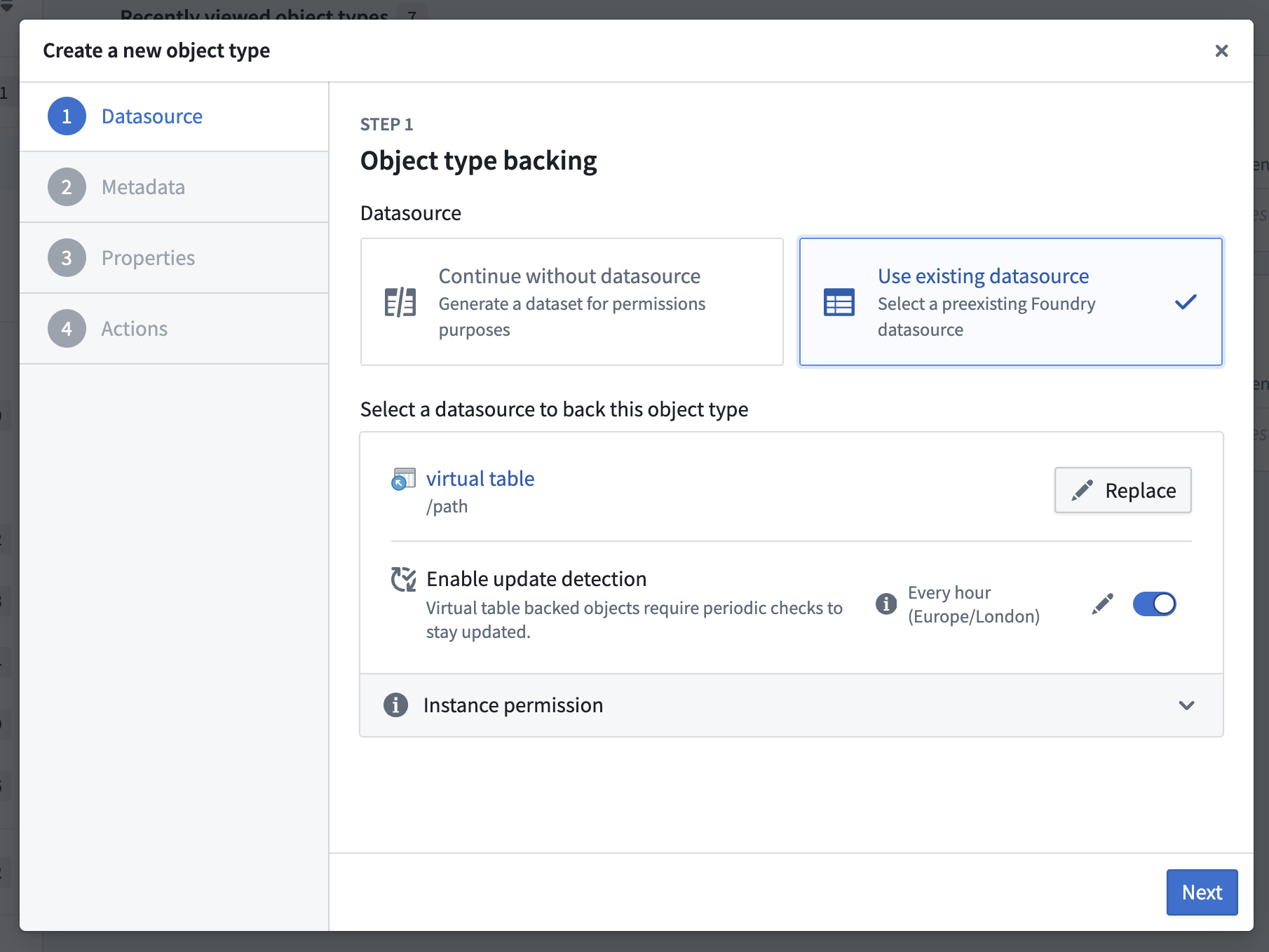
Configuring an object backed by a virtual table in Ontology Manager.
For objects backed by virtual tables, you can automate reindexing by enabling update detection to keep your objects up to date with changes in the the source system. For objects backed by managed Iceberg tables or managed virtual tables (Foundry pipeline outputs), Foundry will automatically trigger object reindexing, as with dataset-backed objects.
We want to hear from you
As we continue to develop new features for virtual tables and Ontology Manager, we want to hear about your experiences and welcome your feedback. Share your thoughts with Palantir Support channels or our Developer Community ↗ using the virtual-tables ↗ and ontology-management ↗ tags.
Configure and monitor Foundry peering with Peer Manager
Date published: 2025-09-09
Peer Manager is available in beta starting the week of September 8.
What is peering?
Peering enables organizations to establish secure, real-time Ontology resource sharing across distinct Foundry enrollments. Peer Manager enables space administrators to view peer connections, monitor peering jobs, and configure peering all in one central place after a peer relationship's creation in Control Panel.
Use Peer Manager to create, view, and monitor peer connections
Peer Manager's home page provides information about all peer connections configured between your enrollment and other enrollments. Peer connections support the import and export of Foundry objects, object sets configured in Object Explorer, and Artifacts.
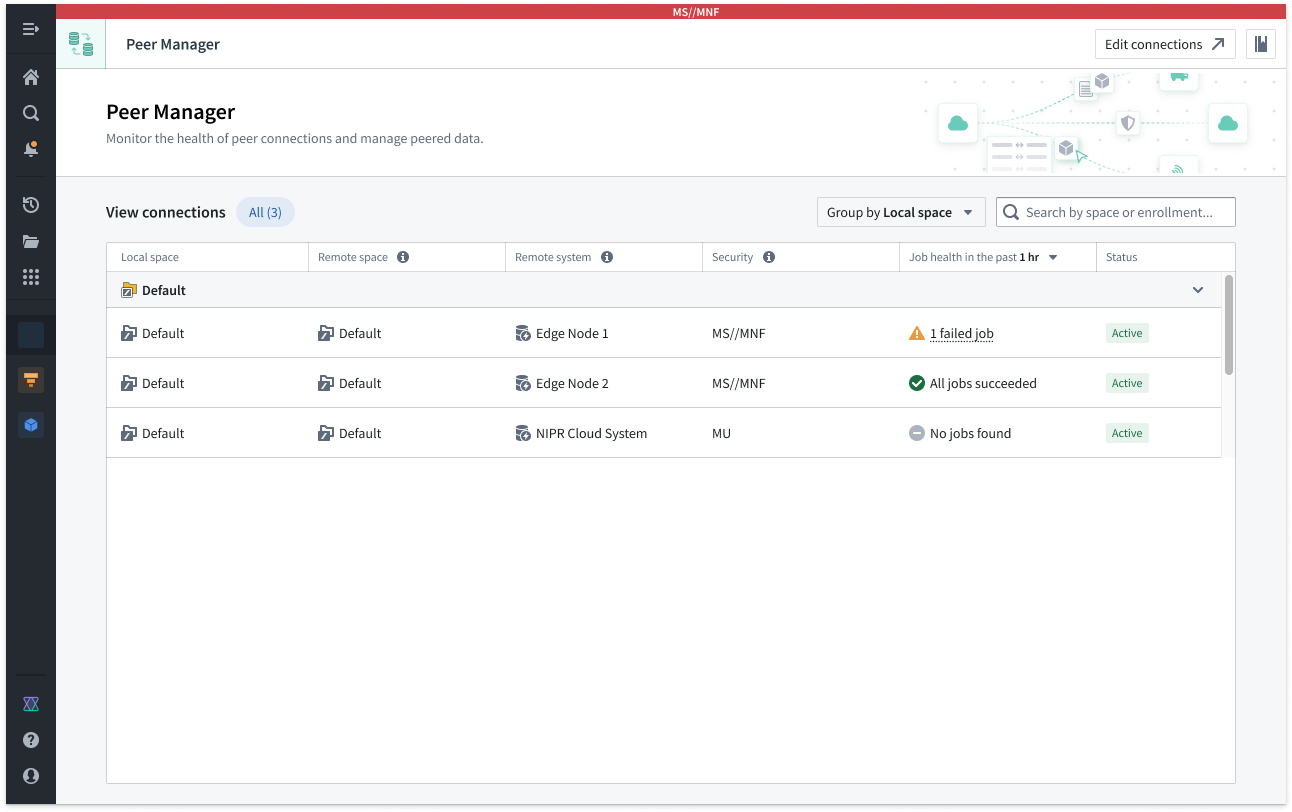
The Peer Manager home page provides an overview of all configured Peer Connections.
Select a connection to launch its Overview window, where you can track the health of each peer connection by viewing the status of individual peering jobs.
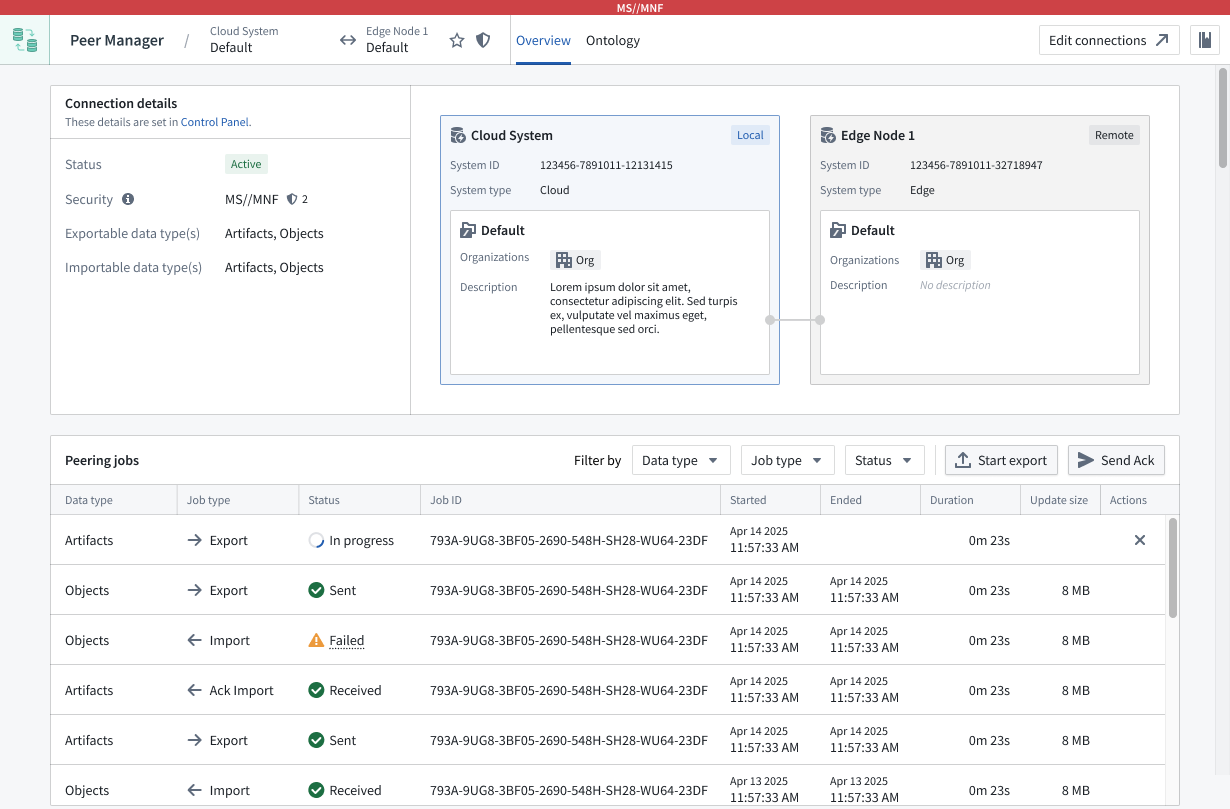
Peer Manager's Overview window offers a unified view of the status and health of peering jobs within a connection.
Select Ontology from the top ribbon to peer objects across an established connection, where Peer Manager enables you to peer all or a selection of properties on the object. Learn more about object peering in Peer Manager.
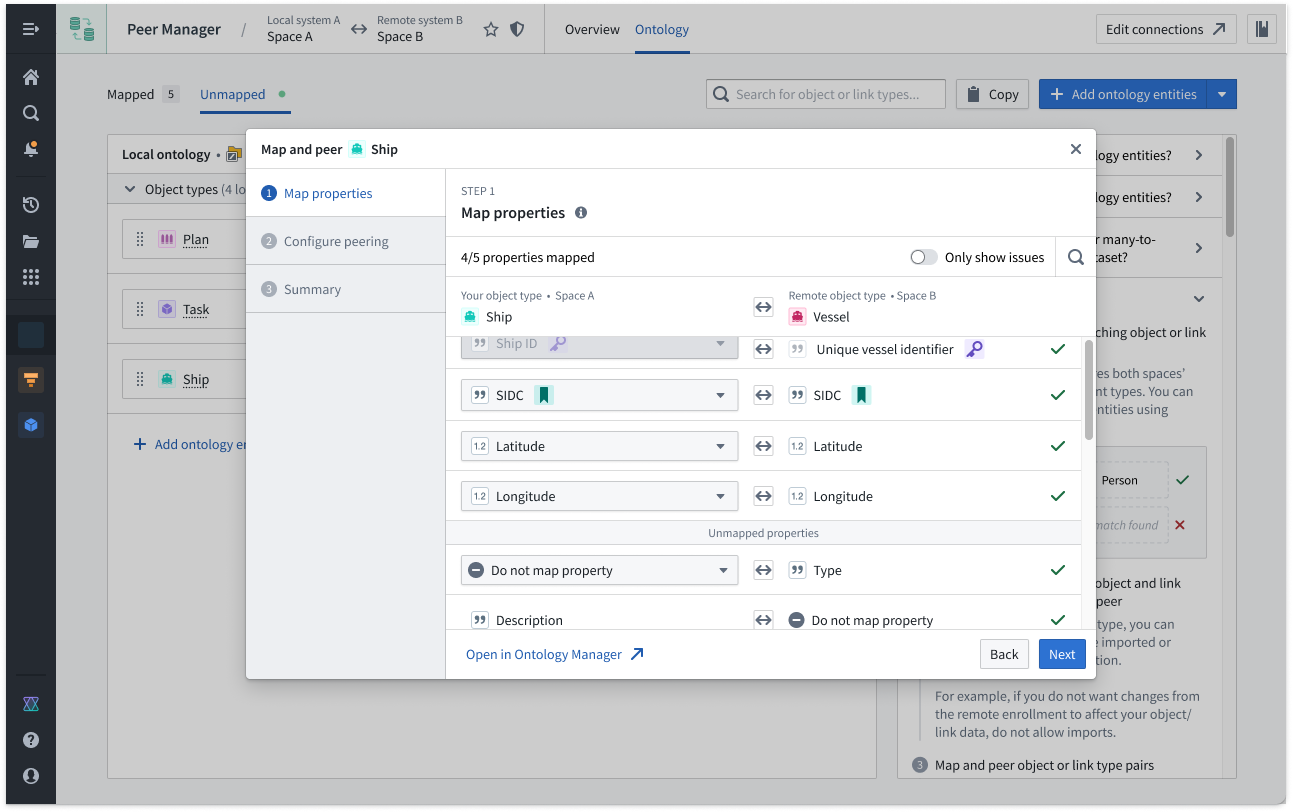
Peer Manager's Ontology window enables you to peer object types across a peer connection.
Next on the development roadmap for Peer Manager is support for Artifact peering configuration, which will be available in beta by the end of 2025. Contact Palantir Support with questions about Peer Manager's availability on your enrollment.
Lightweight Python transforms enhanced with expanded features, better performance, and updated API
Date published: 2025-09-09
Improvements have been made to lightweight Python transforms including expanded feature coverage, increased performance and scalability, and an updated API. When you create a new Python transform, lightweight is now recommended as the default compute option for most use cases, with Spark available for large-scale distributed data processing.
Lightweight allows you to use non-Spark compute engines with Python transforms. This means you can run jobs using single-node (for example, non-distributed) compute and enjoy reduced costs and improved performance. Lightweight transforms are built on open, industry-standard protocols and support multiple engines with a current focus on Polars ↗ and pandas ↗.
Lightweight transforms are composable with Spark transforms in Foundry pipelines, meaning you can build multi-engine, multi-language data pipelines, leveraging the exact right compute at every step along the way.
Some recent improvements and updates to lightweight transforms that are worth checking out:
- Enhanced scalability and performance: Lightweight transforms work well for arbitrary transforms with input data of up to 200 million rows or 50 GB uncompressed data. Additionally, for the right shapes of transforms, lightweight can process even terabyte-scale multi-billion row inputs on a single node. Review our documentation on choosing the right engine for more details.
- Increased feature coverage in Foundry: Lightweight now supports most key transforms functionality, including incremental, media sets, external transforms, and models. See feature support comparison.
- Improved memory usage: Lightweight transforms now require less memory than before, and it is easier to monitor memory usage on jobs with the new metrics telemetry view.
- Updated default lightweight API: With the
transforms.using(...)syntax. - Updated documentation with lightweight as default, including tabbed code examples for Polars, pandas, and PySpark.
- Python transforms overview
- Getting started
- Guidance on compute engine selection
- Optimizations using Polars lazy API
You can also learn more in a recent demo video with a Palantir developer ↗, who converted a fraud detection pipeline from Spark to Polars, with a 10x improvement on compute consumption.
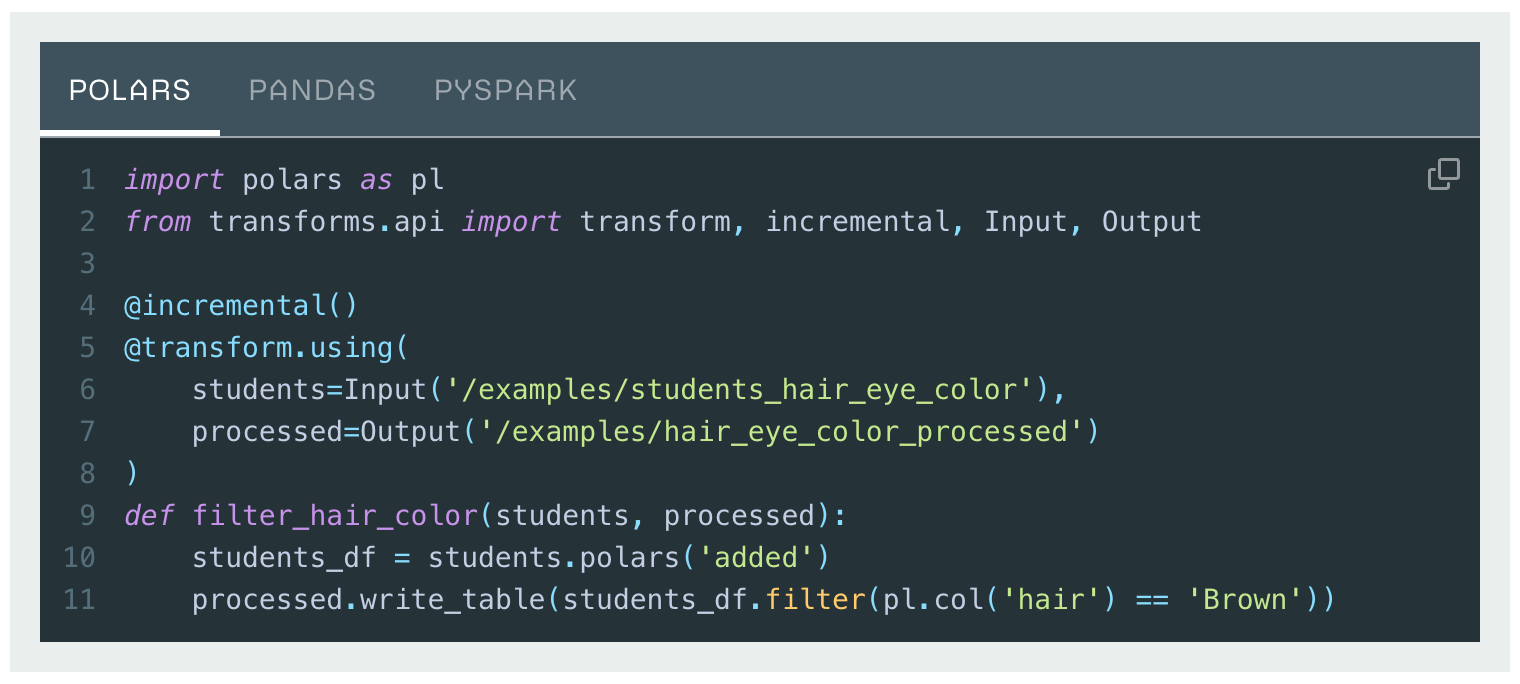
Incremental tabbed code example using the updated API.
Share your feedback
We want to hear about your experience using lightweight Python transforms. Let us know in our Palantir Support channels, or leave a post in our Developer Community ↗ using the transforms-python ↗ tag.
New styling options in the Workshop Pivot Table widget
Date published: 2025-09-09
Workshop’s Pivot Table widget now has new styling options allowing builders to customize the formatting and display of the widget within their applications.
- Layout styling: Further customize how information is displayed in the table with a new "Stacked" layout styling option which merges all configured row groupings into a single column, providing a more compact view of the table.
- Table styling: Customize the styling applied to the cells within the table with two new table styling options including an "Outlined" option which adds an outline above and below each top level row grouping, and a "Banded row" option which additionally adds a light grey background to each alternating row in the table.
- Color styling: Customize the color of the table’s header by applying a custom color in either a minimal or prominent shade.
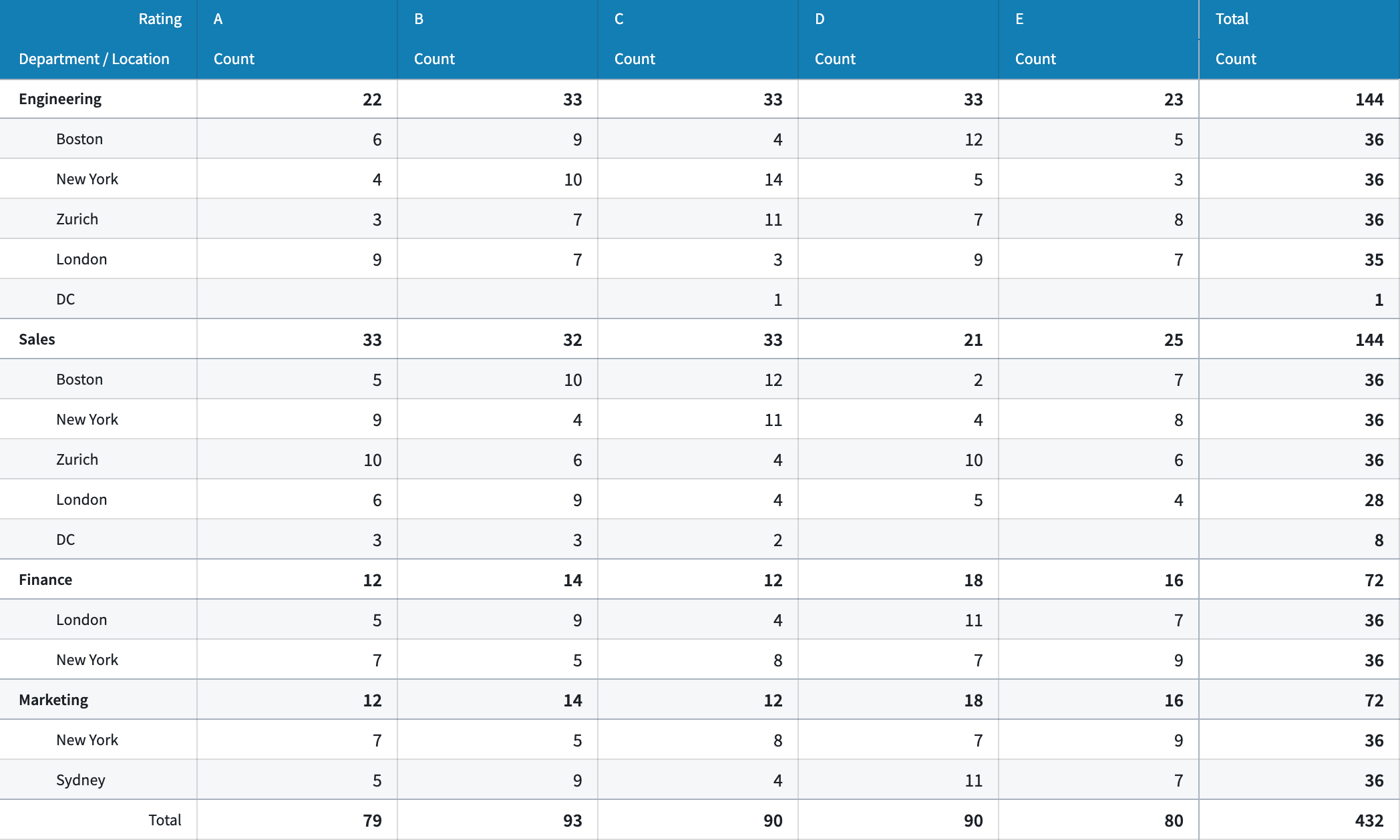
Example of a Pivot Table widget with a custom header color, stacked layout, and banded rows styling options applied.
We want to hear from you
As we continue to develop on Workshop, we want to hear about your experiences and welcome your feedback. Share your thoughts with Palantir Support channels or our Developer Community ↗ and use the workshop ↗ tag.
Automatically scan your code for vulnerabilities with Code Scanning in Jemma CI
Date published: 2025-09-02
Code Scanning in Jemma CI, now available on all enrollments, automatically analyzes code repositories for vulnerabilities, code smells, and coding standard violations across multiple languages and file types. Comprehensive security and quality insights appear directly in the Checks tab.
Getting started
An enrollment admin can activate code scanning for repositories in an enrollment by visiting Control Panel > All Settings > Security & Governance > Code scanning.
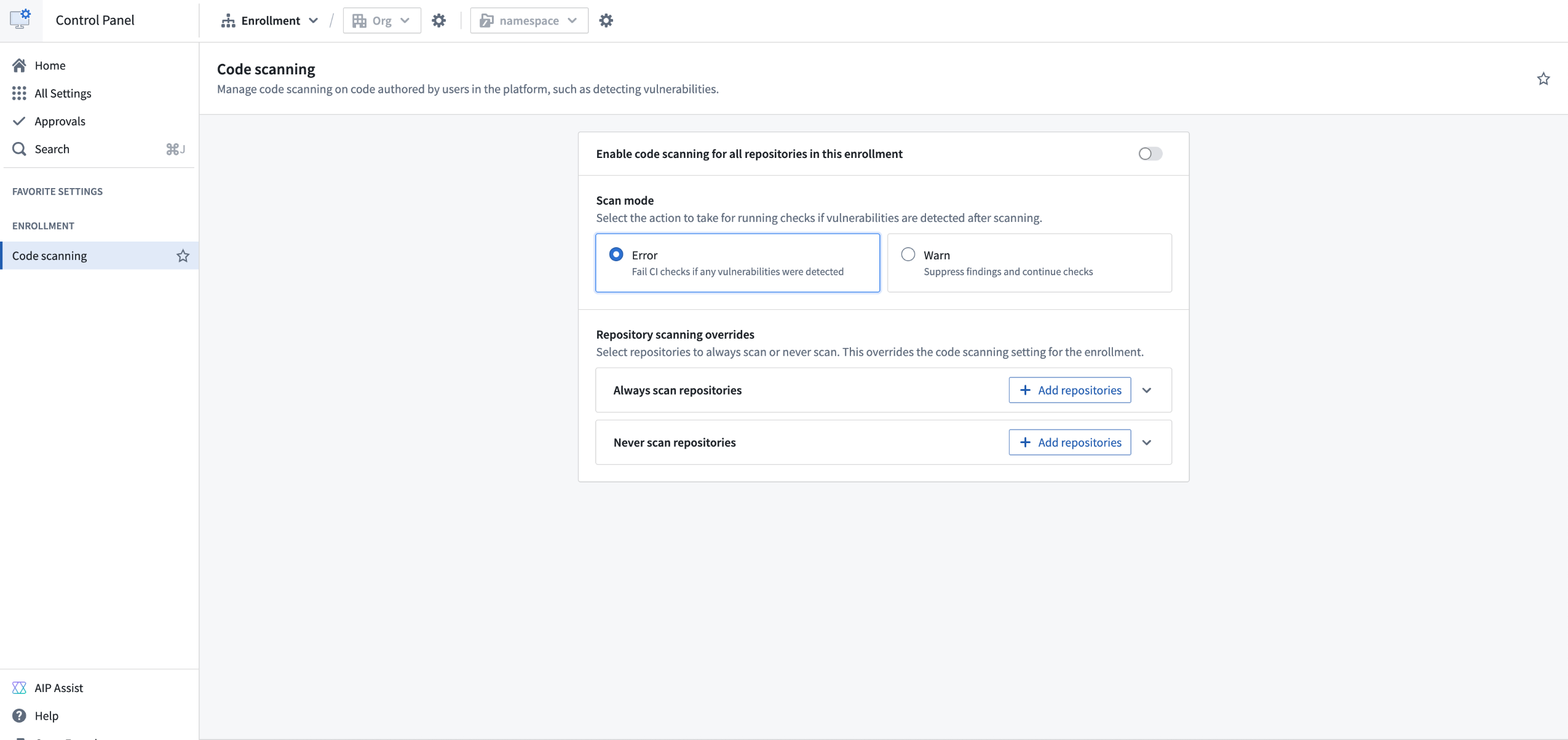
Navigate to the Code scanning page in Control Panel to manage code scanning for an enrollment.
If enabled by your enrollment administrator, every commit in a repository will trigger a code scan. This code scan will analyze the codebase for potential vulnerabilities and code quality issues. Any findings will be displayed in Checks, and a downloadable report will be generated.
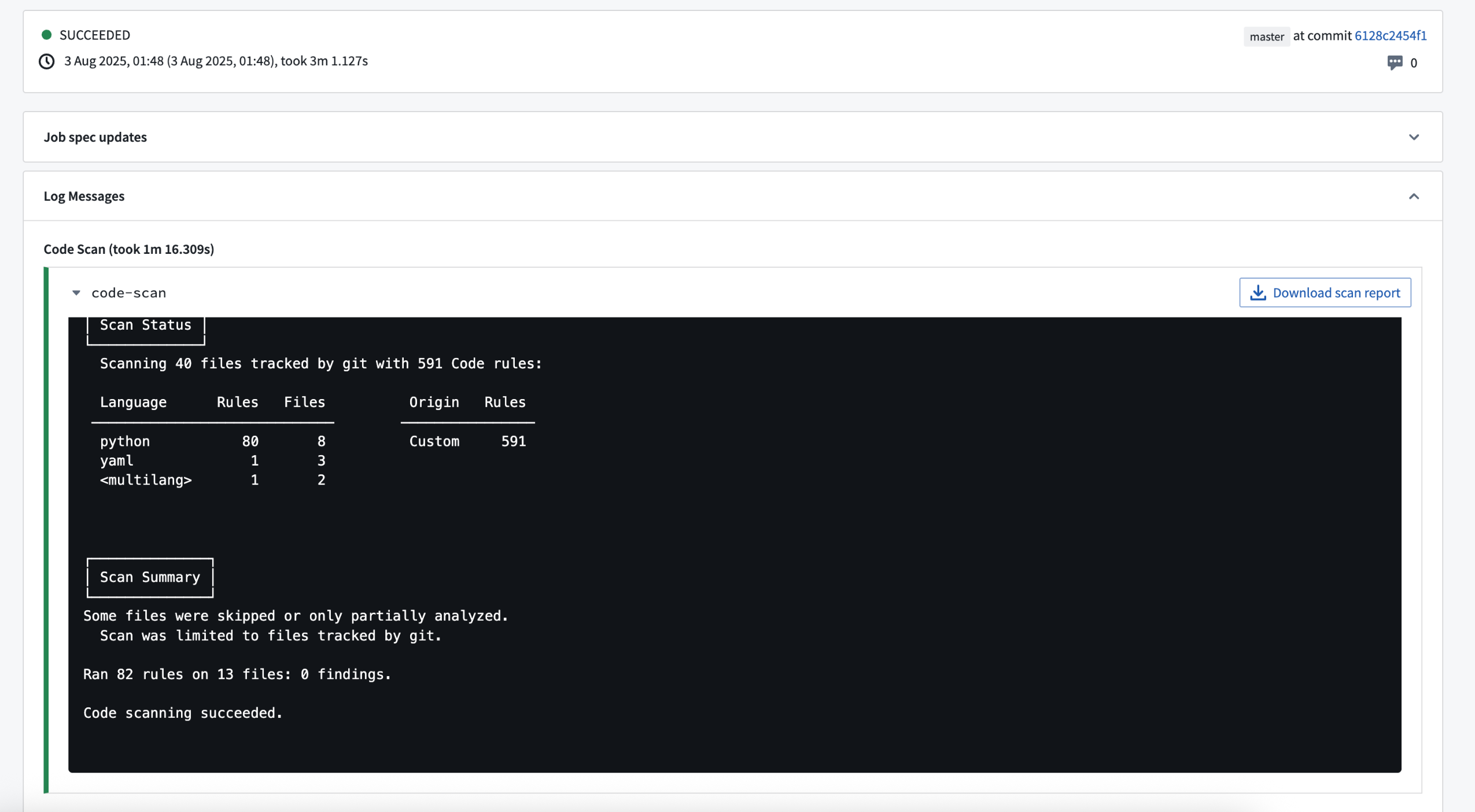
Checks page with the results of a code scan.
After a scan is run, Jemma will continue running checks on the commit if no findings are detected; otherwise, the checks will fail. An enrollment administrator can change this behavior so that findings will result only in a warning, and checks will proceed. For more information on code scanning, visit our documentation.
Share your feedback
Let us know what you think about this code scanning feature by posting your feedback in our Developer Community ↗.
Scan sensitive images, documents, and audio files using Sensitive Data Scanner's media set scanning feature
Date published: 2025-09-02
Media set scanning is now generally available in Sensitive Data Scanner the week of September 1. This capability enables you to scan images, documents, and audio files within media sets for sensitive data that requires heightened protection controls, such as personally identifiable information (PII) or personal health information (PHI). Within Sensitive Data Scanner, Data Governance Officers and administrators can apply uniform data protection policies across both tabular and unstructured data, improving the consistency and comprehensiveness of data protection on multi-modal datasources.
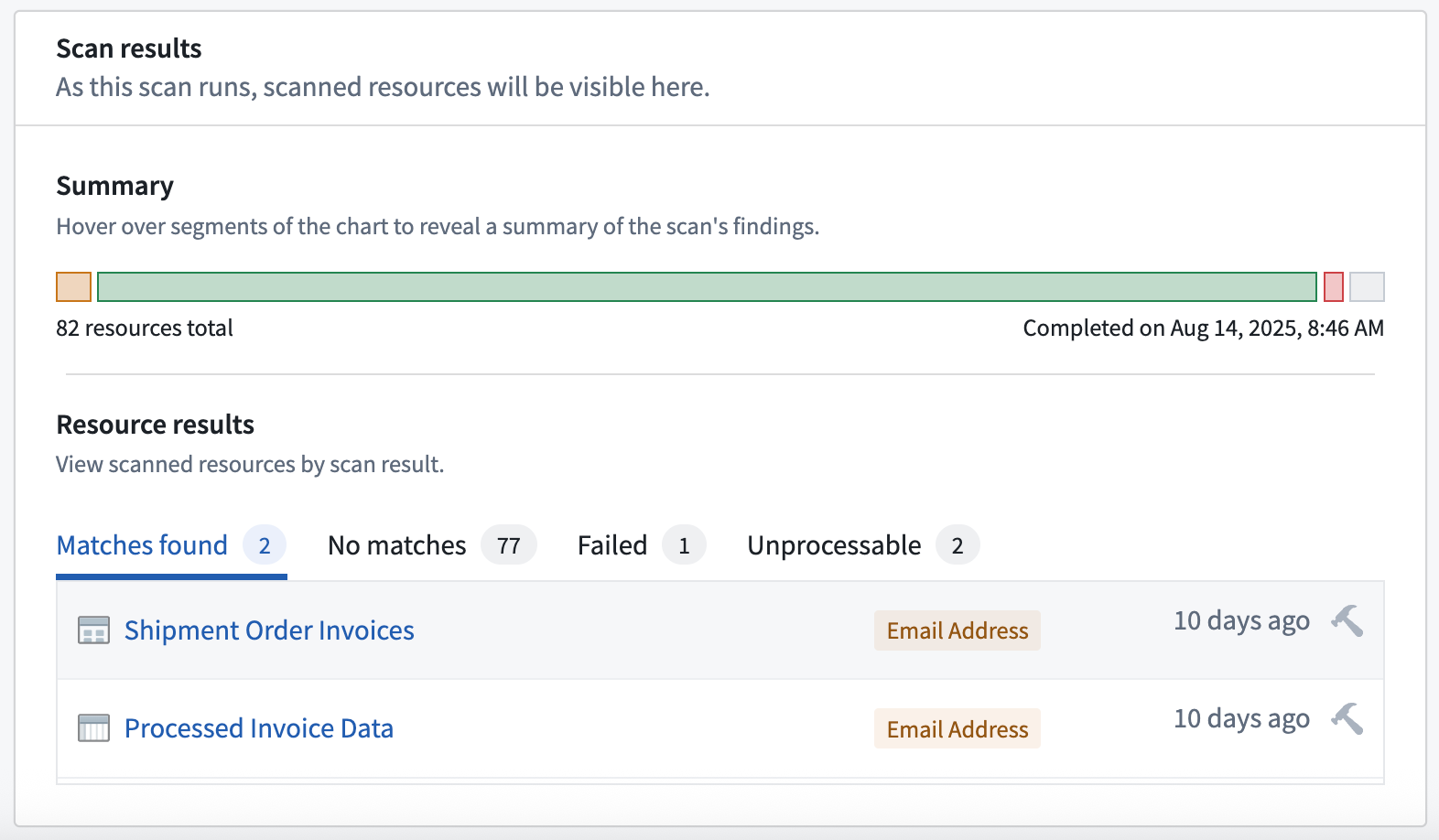
Scan results display Email Address matches in both a media set of documents and a tabular dataset.
When to use media set scanning
Use media set scanning when sensitive content may appear in unstructured data you ingest into Foundry. Existing sensitive data scans need to opt into scanning media set resources, which you can do by editing your scans and selecting the relevant media set resource types. Scanning entire media sets can be computationally expensive, so we recommend using media set scanning in either one-time scans or non-continuous recurring scans, such as those scheduled on a daily, weekly, or monthly basis.
Media set scanning can help improve your organizations's data protection posture by indicating when new unstructured data sources contain media with sensitive data. This will also ensure that platform administrators better understand which unstructured data sources may require Markings to indicate that some of its items contain sensitive data. Additionally, you can further protect sensitive image data using Cipher's Visual Obfuscation capability.
Apply regular expression-based match conditions on media
Sensitive Data Scanner now enables users to apply regular expression-based match conditions against image, document, and audio files in media sets. For image and document files, Sensitive Data Scanner applies Optical Character Recognition (OCR) to convert the unstructured data to text before scanning for the match conditions you configure. For audio files, Sensitive Data Scanner applies a transcription model to extract their text before scanning the files for those match conditions. For more details on these text extraction steps, see the documentation on media set scanning with Sensitive Data Scanner.
We want to hear from you!
Use the sensitive-data-scanner tag in Palantir's Developer Community ↗ forum or contact Palantir Support to share your experience with and feedback for the media set scanning feature in Sensitive Data Scanner.
New geo-variables and geo-transforms in Workshop
Date published: 2025-09-02
Builders can now capture, display, and interact with geographic data in Workshop using new geopoint and geoshape variables. Builders can interact with them using variable transform operations including:
- Geopoint ↔ String: Cast geopoints to strings and geopoint formatted strings to geopoints.
- Geoshape ↔ String: Cast geoshape to strings and geoshape-formatted strings to geoshapes.
- Geohash from geopoint: Converts a geopoint into a geohash value as a string.
- Latitude from geopoint: Returns the numeric latitude value from a given geopoint.
- Longitude from geopoint: Returns the numeric longitude value from a given geopoint.
- MGRS from geopoint: Converts a given geopoint into a MGRS value as a string.
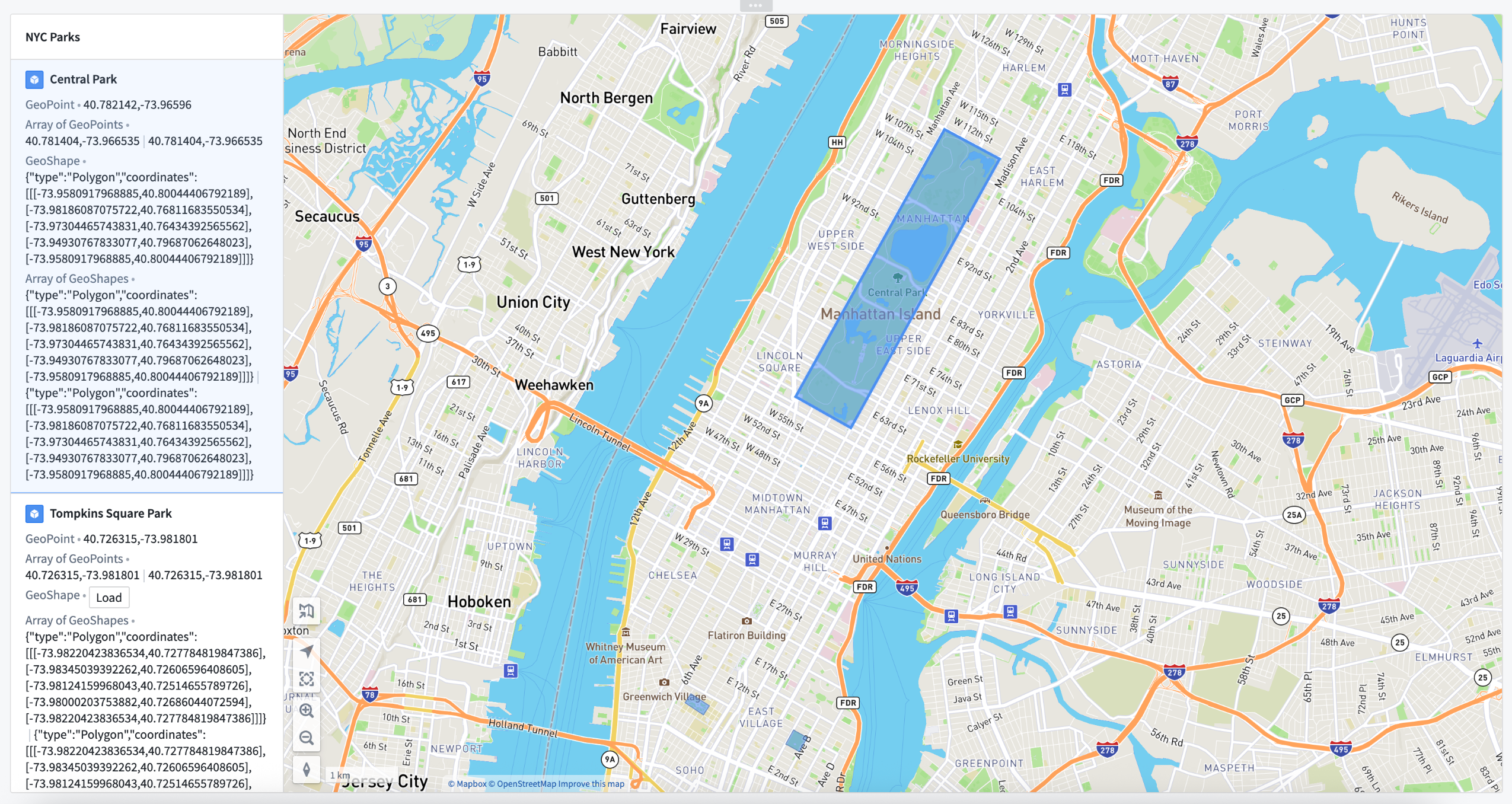
An example of geopoints and geoshapes in use in a Workshop application.
We want to hear from you
As we continue to develop new features for Workshop, we want to hear about your experiences and welcome your feedback. Share your thoughts with Palantir Support channels or our Developer Community ↗ and use the workshop ↗ tag.