- Capabilities
- Getting started
- Architecture center
- Platform updates
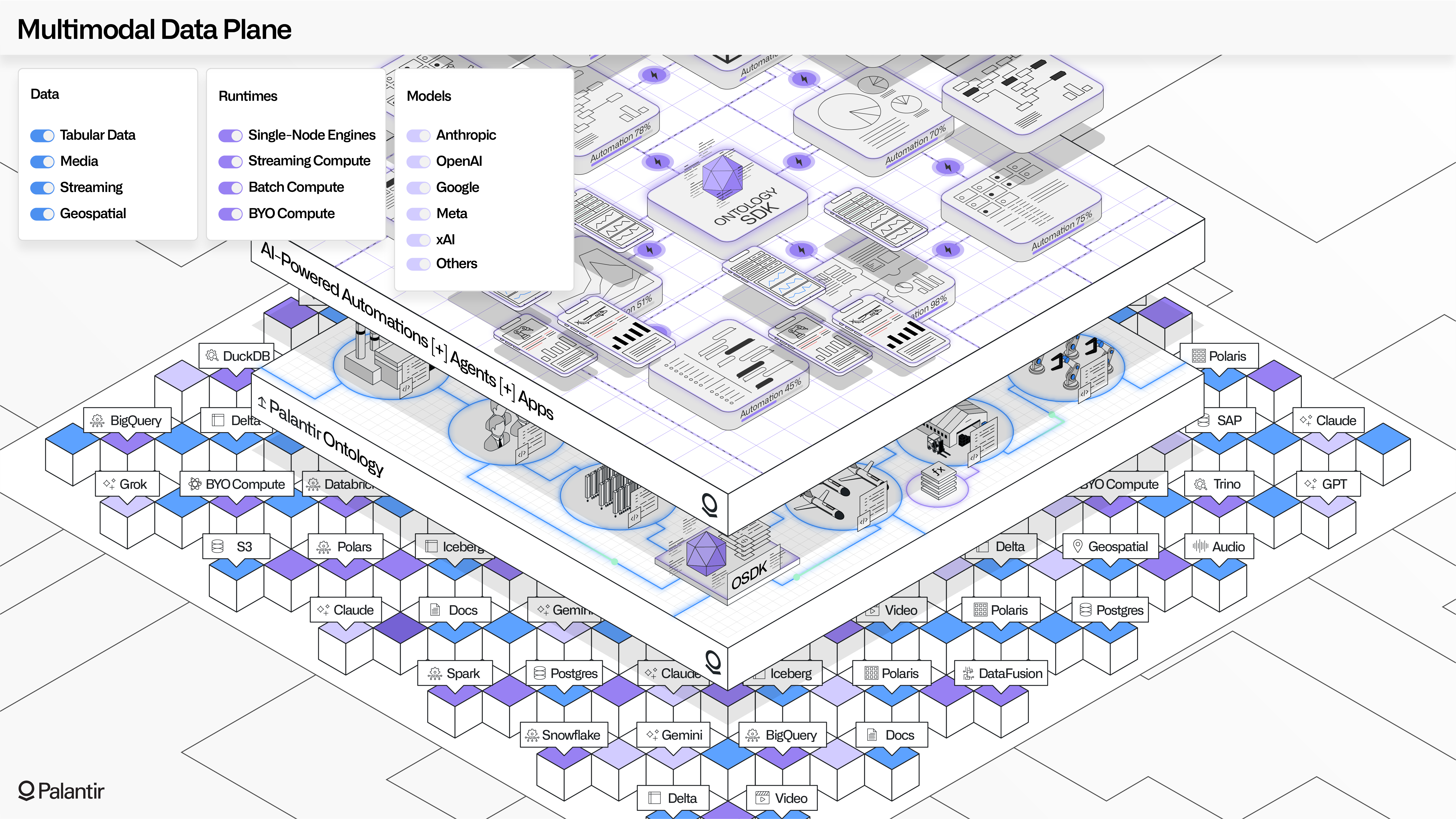
Multimodal Data Plane (MMDP)
The Multimodal Data Plane (MMDP) is Palantir’s open data and compute architecture. MMDP reflects the learnings of two decades of forging battle-tested solutions on the frontline of customer missions, and wrestling with the design tradeoffs that often create tension between analytical and operational system designs.
Concretely, most platform architectures are built around particular compute runtimes or data storage modalities. While this can function for narrow use cases, these dependencies can quickly become a hindrance when scaling to interconnected use cases which require complex interplays of, for example, structured, unstructured, time series, geospatial, or geometric data, which must each be transformed and manipulated through different forms of compute, before being holistically made available in seamless end user experiences.
In the age of AI, moving beyond fragmented data and compute is no longer just a “nice to have”, but essential to unlocking enterprise autonomy.

Any data: MMDP's open data architecture
The bedrock of MMDP is an open data architecture. This starts with a commitment to Apache Iceberg as the primary table format for Foundry and AIP.
Iceberg is being embraced as an open standard across key Palantir partners, including AWS, Google Cloud, Microsoft Azure, Databricks, and Snowflake.
MMDP allows Iceberg catalogs to be managed within Palantir, or as virtual catalogs and virtual tables that are registered from these (or other) providers. This means that leveraging data in the Ontology for operational applications and AI-driven automations never requires data to be duplicated.
Adopting Iceberg also means that standard tools such as SQL applications and analytical notebooks can securely interact with and manipulate data in Foundry and AIP as in any other environment.
Many organizations are building a “data mesh” (or now, an “AI mesh”) that incorporates Palantir as one participant in a wider, more heterogenous enterprise architecture. It is an explicit goal of MMDP to support these types of mixed architectures by providing an “unwalled garden” that enables end-to-end delivery of outcomes, while ensuring that every layer of the architecture can be deeply integrated with existing data lakes, lakehouses, conventional warehouses, data governance tools, and other key storage repositories.
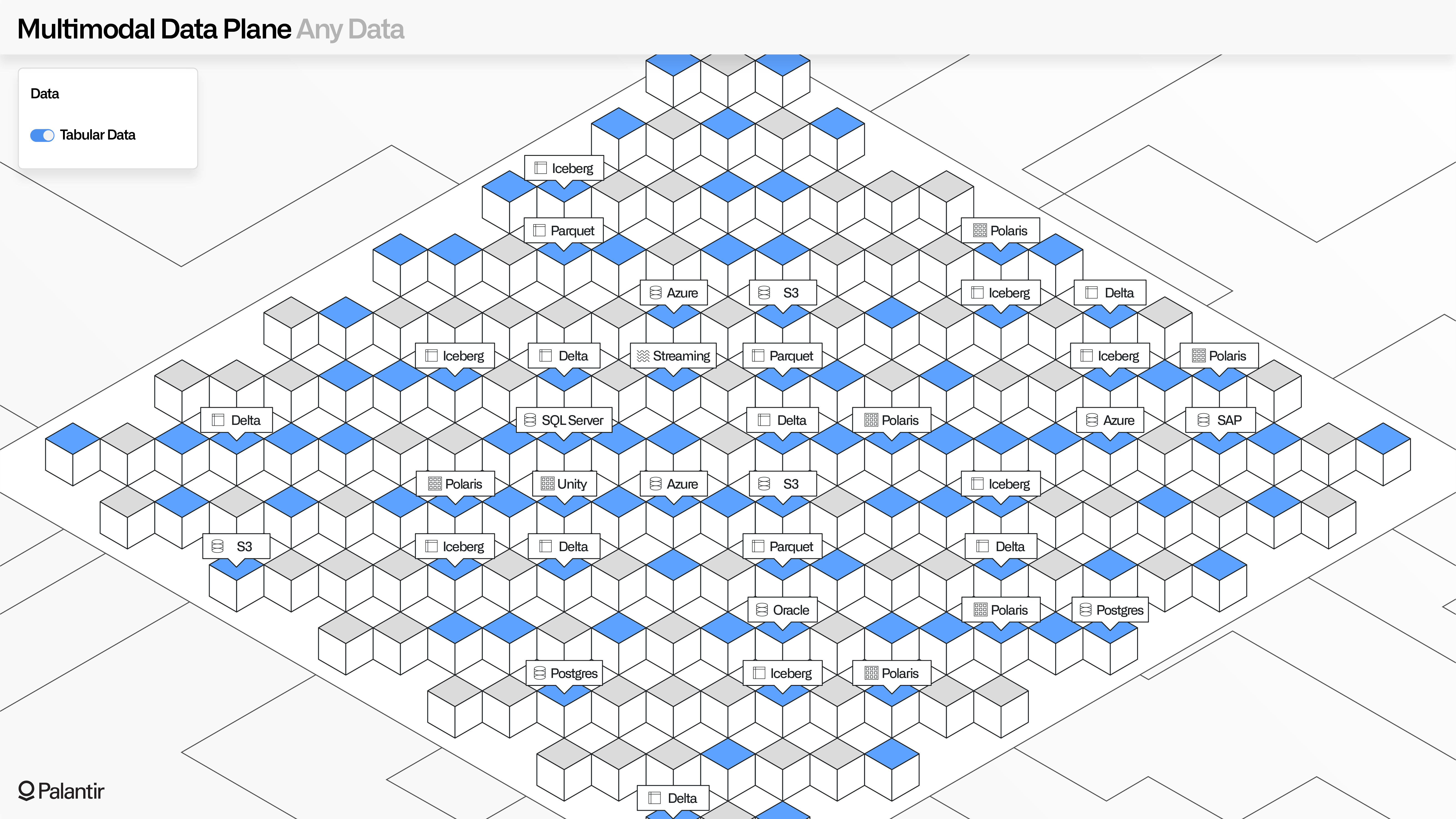
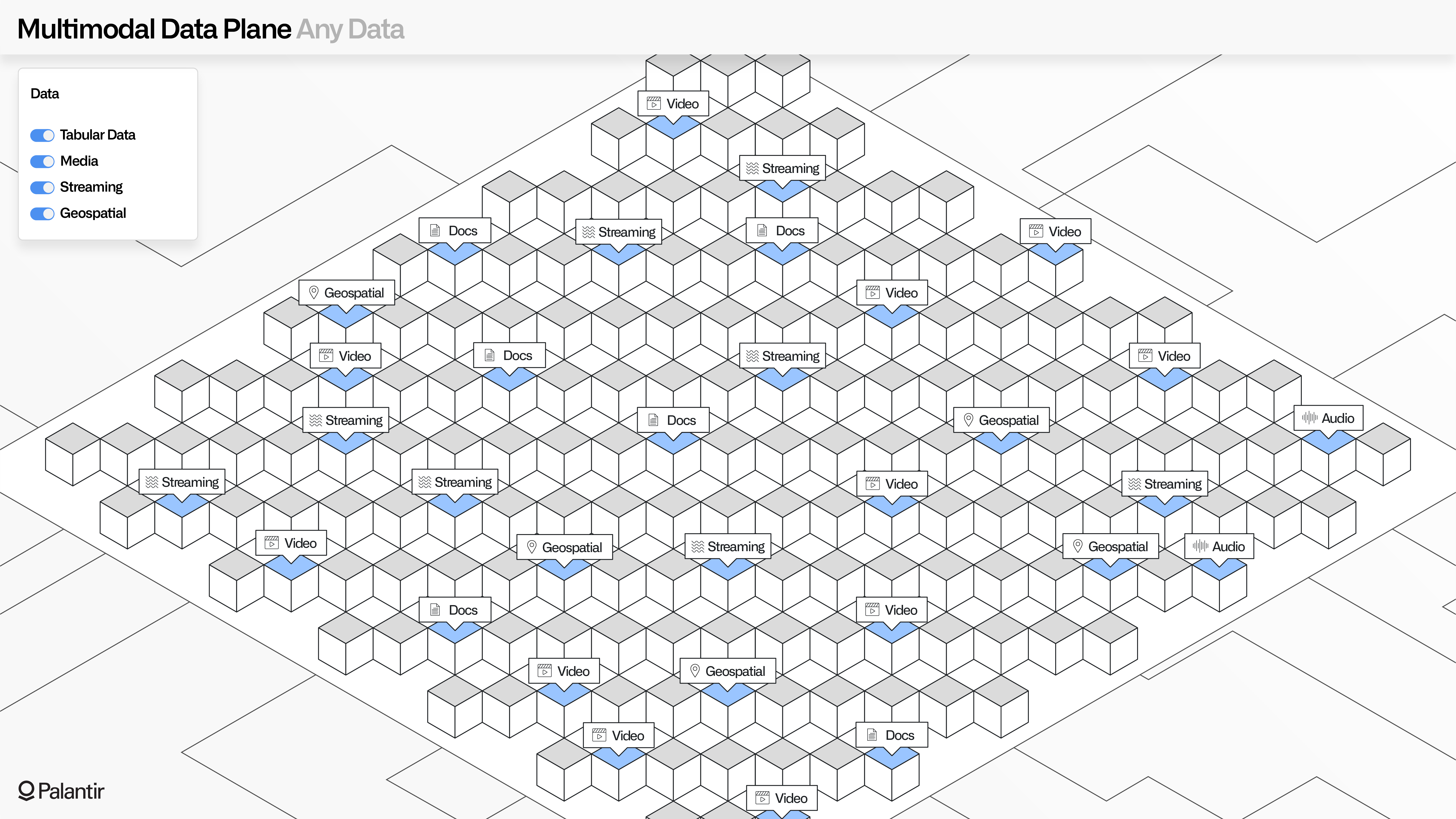
MMDP: Openness beyond tabular data
In addition to tabular data, MMDP extends the same open guarantees to media, documents, streaming data, geospatial data, and the vast expanse of multimodal data types.
Media data can be synchronized with minimal assumptions about the underlying format; where there are recognized formats, analytical tools can immediately help with interactive parsing; and where custom or niche formats are integrated, metadata can be lazily affixed from other sources.
The same is true for streaming and geo-temporal data, which might have associative metadata (e.g., sensor tags) that require processing in a data pipeline that flows parallel to the primary ingress pipeline.
Regardless of how data is ingested and transformed, all underlying files and points can be securely accessed through standard REST APIs, as well as the Python and TypeScript SDKs.
Export jobs and Ontology-based webhooks provide simple and secure methods of synchronizing any data (regardless of modality) to external systems, and the Source-based Transforms paradigm enables developers to use the full power of the Foundry toolchain to customize data egress as needed, at the granularity of individual workflow steps.
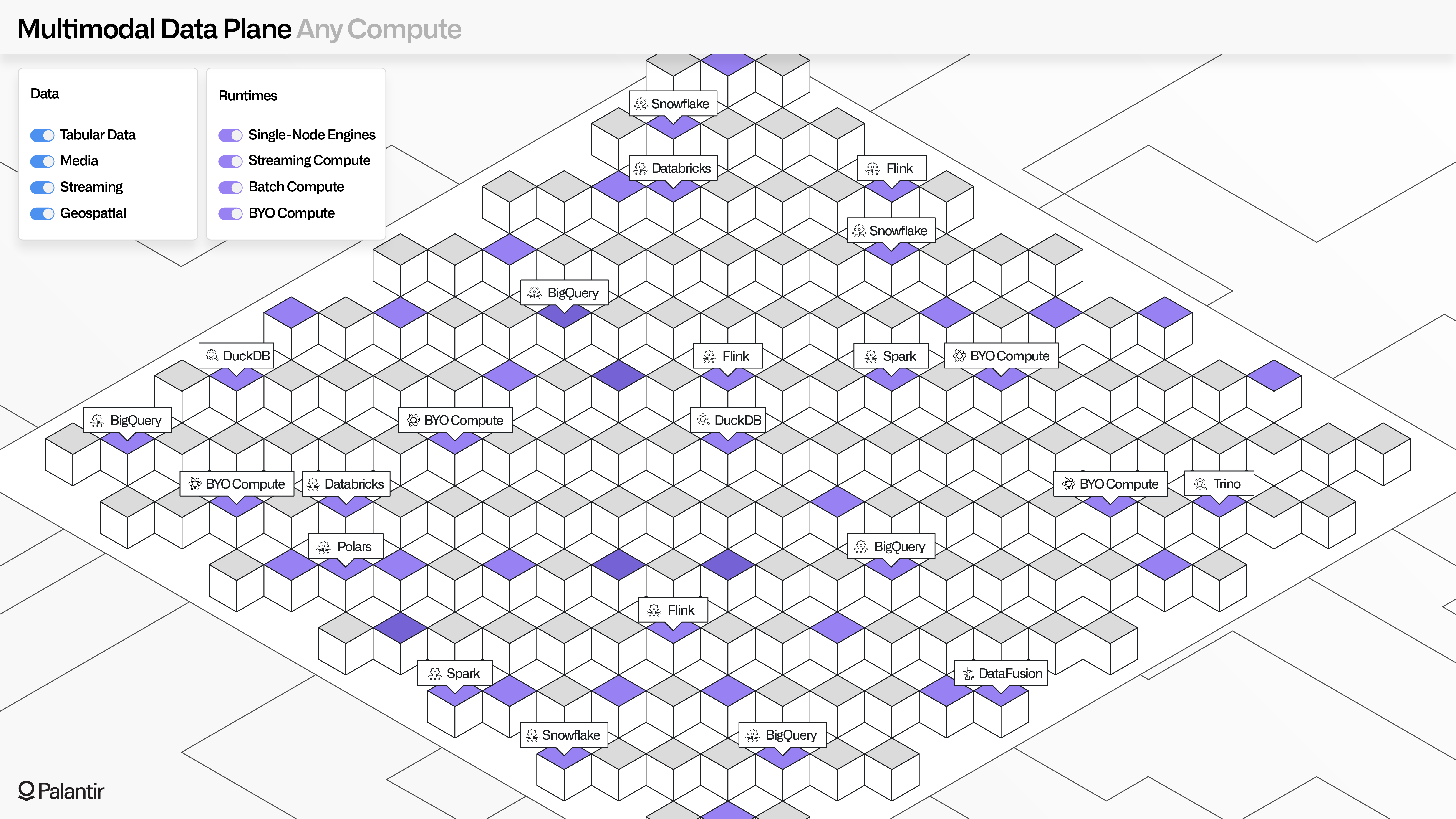
Any compute: MMDP's open compute architecture
MMDP’s open compute architecture unlocks the value of the open data architecture. Foundry and AIP come with an array of out-of-the-box runtimes, which all use a hardened, autoscaling Kubernetes-based compute mesh (Palantir Rubix).
Rubix operates on zero-trust principles and enforces a rigorous security posture across every runtime and service it manages; for instance, to defend against advanced persistent threats, every container is destroyed and cycled within 72 hours. This requires the dependent compute infrastructure to be highly available, and generally resilient to the failure of single nodes.
Users across roles and functions, whether technical data engineers or analytical data scientists or operational business users, can leverage batch, streaming, and interactive compute engines within the platform (and through APIs and SDKs). This includes autoscaling Spark for batch compute; autoscaling Flink for streaming compute; and a range of open and high-performance single-node engines such as Apache DataFusion, Polars, and DuckDB.
Data transformations that are managed "South of the Ontology" (from raw data to Ontology data) as well as interactive functions that are used "North of the Ontology" (from Ontology data to end users) can leverage these runtimes and others in a resilient and governed manner.
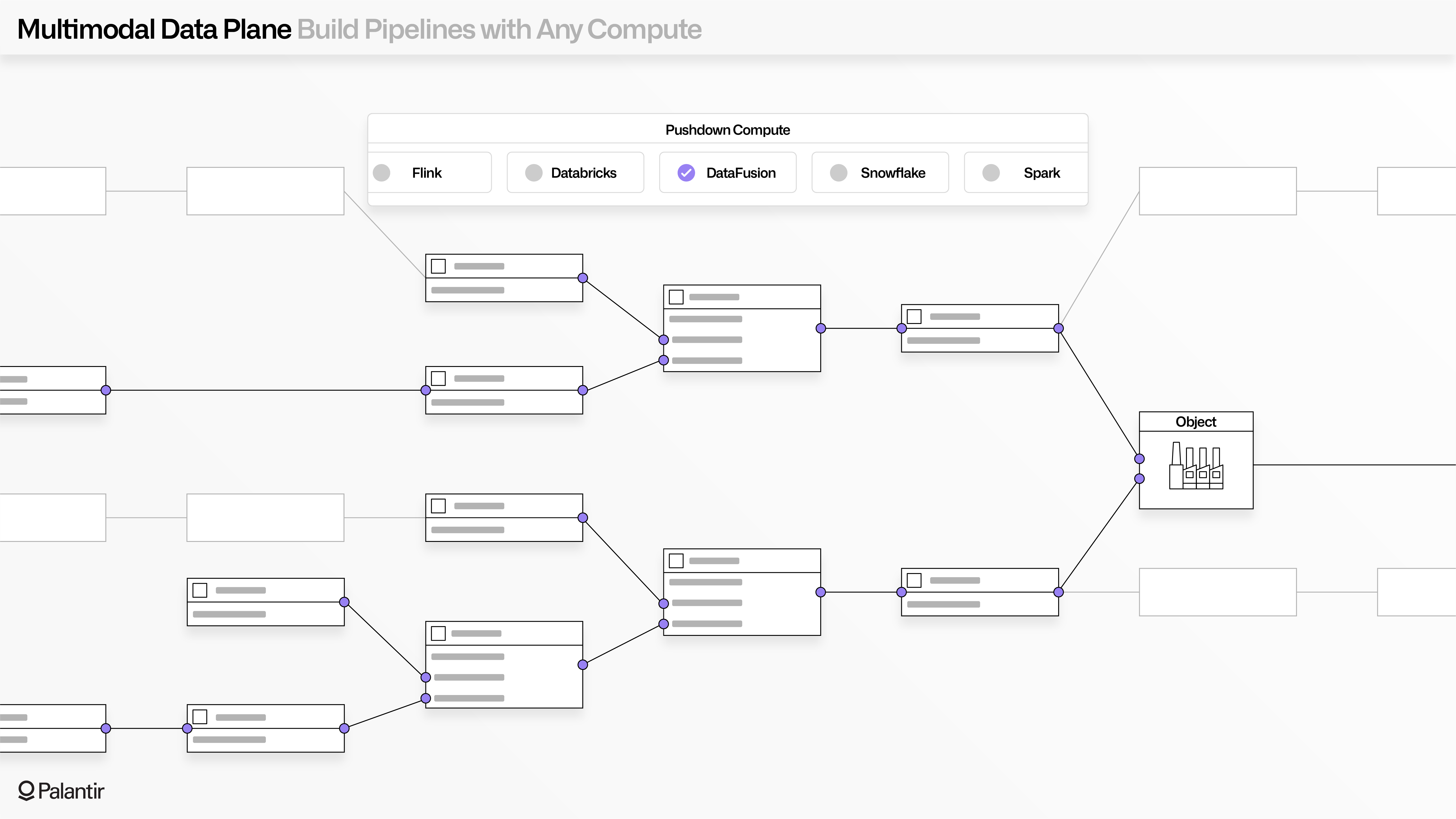
MMDP: Build with any compute
The Compute Modules framework enables "Bring your own compute" ("BYO Compute"), where any containerized resource can be imported and securely surfaced through batch, streaming, and interactive functions.
Across operational workflows, the most important executables and models are often trapped within domain-specific artifacts, or legacy packages that are no longer actively developed. Compute Modules enable these fragmented compute artifacts to be securely liberated and then hosted and used across AI-enabled workflows and alongside more modern logic artifacts (such as Python, Java, SQL, Go, or Rust programs).
Foundry and AIP can also orchestrate with compute resources that are located outside of the Palantir environment, including existing model inference infrastructure, Spark clusters, cloud-hosted optimization engines, and high-performance computing resources that run on-premises.
MMDP also enables native and seamless pushdown of compute to cloud-native runtimes (such as Databricks or Snowflake), allowing developers to use tools like Pipeline Builder and Code Workspaces with their existing compute resources.
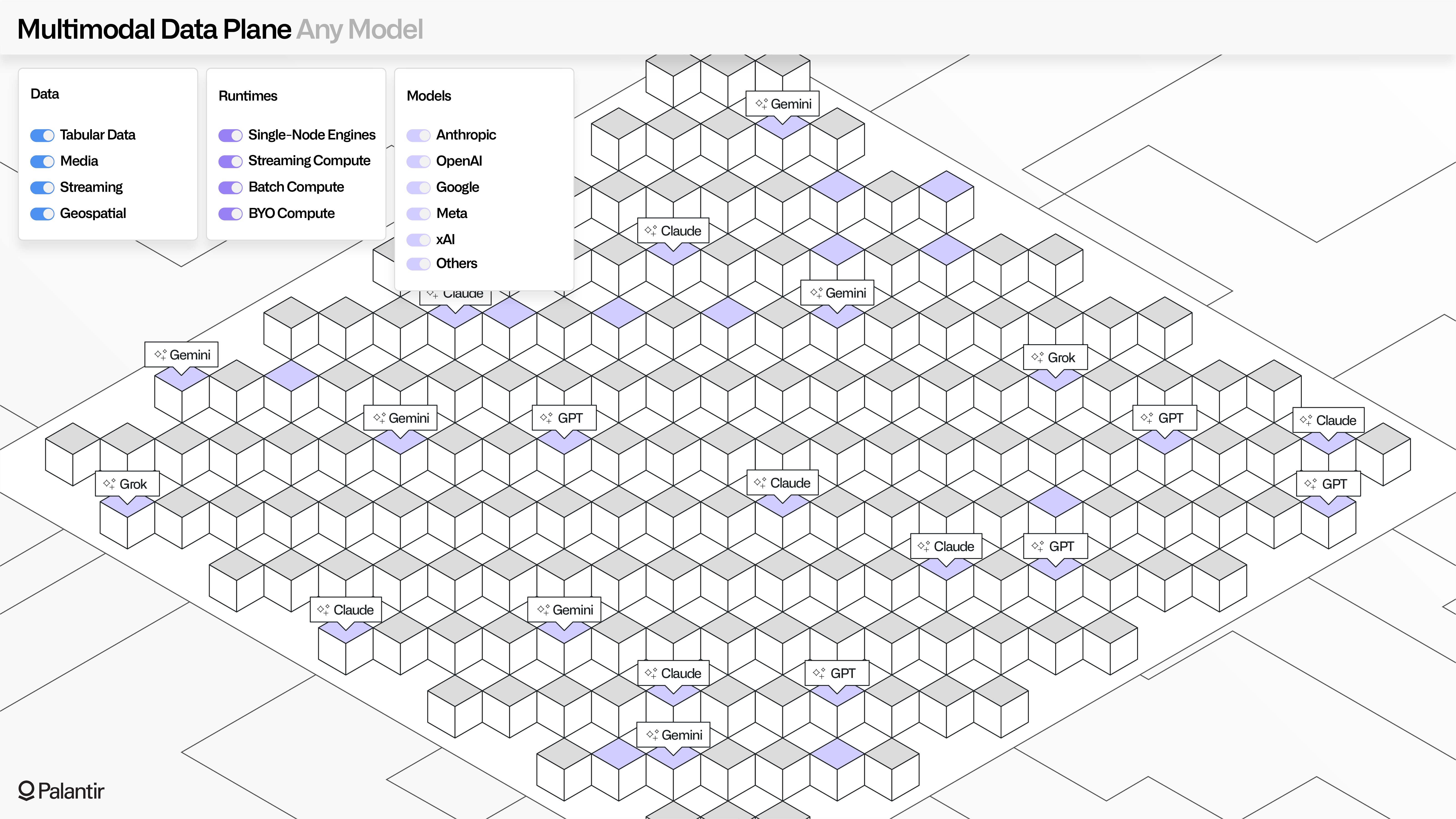
Any model: Palantir's commitment to model access
Palantir’s commitment to openness and optionality extends to generative AI. MMDP's "any model" philosophy reflects the ongoing commitment to offer the latest generative AI models through AIP’s Model Catalog (including those from OpenAI, Anthropic, Google, Meta, and xAI), and providing a level playing field for enterprises to register and use their own models in equal measure.
LLMs and multimodal models, whether Palantir-provided or custom-registered, can be seamlessly used throughout Foundry and AIP applications, including Pipeline Builder, Workshop, AIP Logic, and the developer toolchain.
To assist in administration, access to models can be governed with precision, with token limits can be set across all use-cases and lines of effort. Meanwhile, resource management capabilities extend cohesively across all data, compute, and AI models connected through MMDP, regardless of the specific underlying modality, runtime, or format.
Anywhere: MMDP's commitment to openness
MMDP bridges the analytical and operational worlds by resisting the easy answers provided by monolithic storage and compute architectures.
The open data architecture leverages open standards like Apache Iceberg, while providing parity for media, documents, streams, and multimodal data types.
The open compute architecture bundles in common runtimes, allows teams to bring their own compute resources, and provides rich interfaces for orchestrating with existing compute infrastructure throughout the enterprise.
This openness extends to generative AI, with a wide variety of LLMs available through the Model Catalog and the ability to easy register custom, fine-tuned, and existing enterprise models.
And with Palantir Apollo, all of this flexibility, along all of these dimensions, is agnostic to the underlying infrastructure provider and continuously evolving in response to the most demanding requirements seen on the frontlines.
MMDP's philosophy: "Any data, any compute, any model, anywhere."