- Capabilities
- Getting started
- Architecture center
- Platform updates
Media set scanning
Sensitive Data Scanner (SDS) can scan media sets for data matching a particular regex. SDS will convert the media items in a media set to text, and then run the regex against the extracted text. The text extraction method used will depend on the type of the media set being scanned.
Text extraction methods are as follows:
- Image and PDF media sets: Optical character recognition (OCR)
- Audio media sets: Transcription
Media sets can only be scanned with content-only regex match conditions.
Issue match actions will automatically be aggregated. This means that for a given media set, even if there are multiple media items that match a given match condition, only a single issue will be opened on the media set.
Text extraction limitations
OCR and audio transcription may not produce exact replicas of the text in the original media content. For example, OCR may split a single word into two strings, capitalize letters, or incorrectly extract text from images that do not contain text. This can lead to unexpected behavior when matching against a regex, especially if the regex assumes that text will conform to certain formatting or capitalization rules.
To see the text that SDS ran a regex against, you can create a Pipeline Builder pipeline that takes a media set as input and applies the following transforms for media set types:
- PDF media sets: Extract text from PDFs using OCR.
- Image media sets: Extract text from images using OCR.
- Audio media sets: Transcribe audio into text.
Inspect media set scanning results
Select the Open scan details button to review the scan configuration and inspect the results. Similar to scanned datasets, the Scan results section is where SDS lists all the media sets with scan matches as well as their exact match conditions.

Hover your cursor over any match condition to render a preview of media items which triggered the match condition.
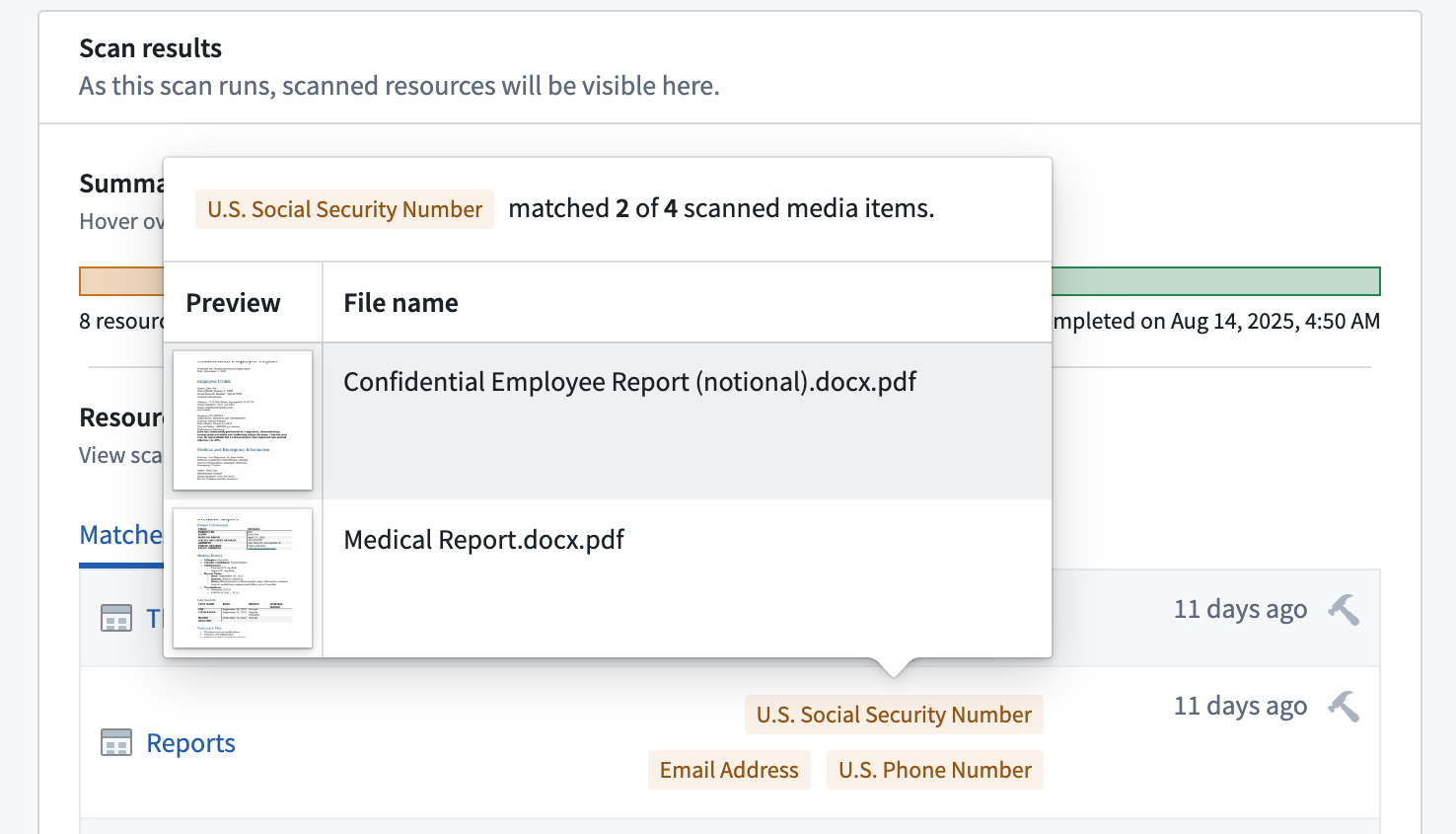
You will also see the total number of matched and scanned media items. If a media set contains a large number of matches, then Foundry displays a preview of the first ten.
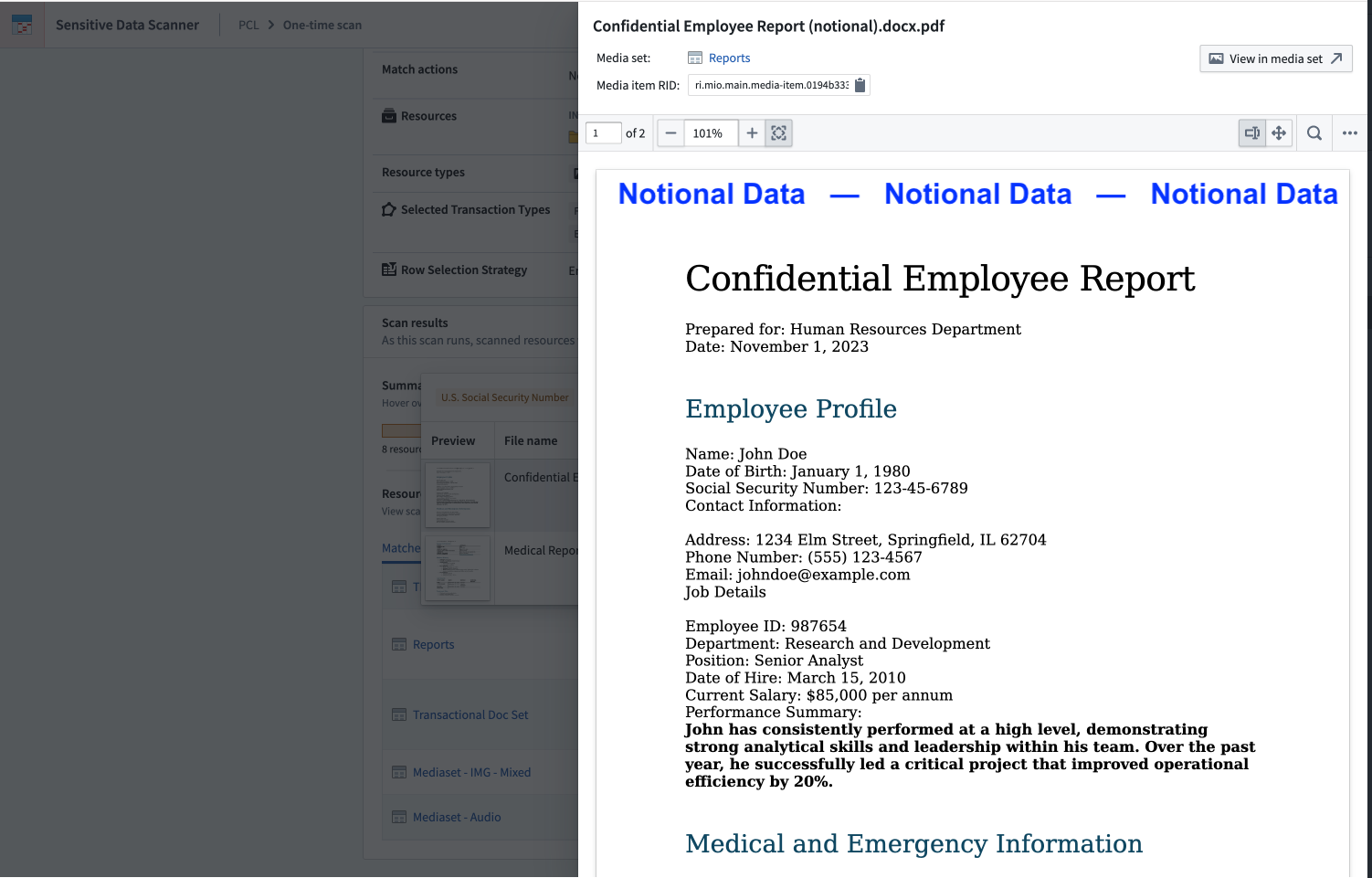
Select a thumbnail to open a detailed view of the media item for further exploration, such as zooming in on an image or reviewing multi-page documents.
Optimize SDS performance
SDS extracts text from every media item, so scanning media sets can be computationally expensive. You can use the following strategies to manage compute costs and optimize scan performance:
- Subset sampling: To limit computational cost and reduce scan durations, you can leverage sampling strategies if you only want to scan a subset of the media items in your media set. Analogous to sampling rows of a dataset, these strategies also apply to sampling media items of a media set.
- Scheduled scans: If you want to run recurring scans on a media set, you can use a low-frequency scheduled scan, such as one that runs on a weekly or monthly basis, instead of a continuous scan. For continuous scans, each update or addition of a media item will trigger a complete re-scan of the entire media set.