注意:以下翻译的准确性尚未经过验证。这是使用 AIP ↗ 从原始英文文本进行的机器翻译。
BigQuery
将Foundry连接到Google BigQuery,以读取和同步BigQuery表与Foundry数据集之间的数据。
支持的功能
| 功能 | 状态 |
|---|---|
| 探索 | 🟢 一般可用 |
| 批量导入 | 🟢 一般可用 |
| 增量 | 🟢 一般可用 |
| 虚拟表 | 🟢 一般可用 |
| 导出任务 | 🟡 已终止 |
数据模型
来自BigQuery的表被导入到Foundry中,数据以Avro格式保存。BIGNUMERIC和TIME类型的列在导入时不被支持。
当从Foundry导出数据到BigQuery时,除MAPS、STRUCTS和ARRAYS外的所有列类型都被支持。
性能和限制
当从非标准BigQuery表同步超过20GB的数据时,必须启用临时存储表。单次同步可以导入的数据量取决于磁盘上的可用空间。对于通过直接连接运行的同步,这通常限制在600GB。使用增量同步以导入更大的表。
设置
- 打开数据连接应用程序并在屏幕右上角选择**+ 新建源**。
- 从可用的连接器类型中选择BigQuery。
- 选择使用直接连接通过互联网连接,或者通过中介代理连接。
- 根据以下部分的信息,按照额外的配置提示继续设置您的连接器。
了解更多关于在Foundry中设置连接器的信息。
您必须拥有一个Google Cloud IAM服务帐户 ↗才能继续进行BigQuery身份验证和设置。
身份验证
使用BigQuery连接器需要以下身份和访问管理(IAM)角色:
读取BigQuery数据:
BigQuery Read Session User: 授予BigQuery项目BigQuery Data Viewer: 授予BigQuery数据以读取数据和元数据BigQuery Job User(非必填): 授予视图摄取和运行自定义查询
从Foundry导出数据到BigQuery:
BigQuery Data Editor: 授予BigQuery数据集或项目BigQuery Job User: 授予BigQuery项目Storage Object Admin: 如果通过Google Cloud Storage导出数据,则授予桶
使用临时表:
BigQuery Data Editor: 如果数据集由连接器自动创建,则授予BigQuery项目BigQuery Data Editor: 授予提供的数据集作为存储临时表的位置
在Google Cloud文档关于访问控制 ↗中了解更多关于所需角色的信息。
选择以下可用的身份验证方法之一:
-
**GCP实例帐户:**请参阅Google Cloud文档 ↗以了解如何设置基于实例的身份验证。
- 请注意,GCP实例身份验证仅适用于在GCP中适当配置的实例上运行的代理操作的连接器。
- 请注意,虚拟表不支持GCP实例身份验证凭据。
-
**服务账户密钥文件:**请参阅Google Cloud文档 ↗以了解如何设置服务账户密钥文件身份验证。密钥文件可以作为JSON或PKCS8凭据提供。
-
**工作负载身份联合(OIDC):**按照显示的源系统配置说明设置OIDC。请参阅Google Cloud文档 ↗了解工作负载身份联合的详细信息,并参阅我们的文档以了解OIDC如何与Foundry一起使用。
网络
BigQuery连接器需要通过443端口访问以下域:
bigquery.googleapis.combigquerystorage.googleapis.comstorage.googleapis.comwww.googleapis.com
可能需要对以下域的额外访问:
oauth2.googleapis.comaccounts.google.com
如果您在Google Cloud Platform (GCP)上的Foundry与GCP上的BigQuery之间建立直接连接,您还必须通过相关的VPC服务控件启用连接。如果您的设置需要此连接,请联系Palantir支持以获取额外指导。
连接详情
BigQuery连接器可用的配置选项如下:
| 选项 | 必填? | 描述 |
|---|---|---|
Project ID | 是 | BigQuery项目的ID;无论同步了什么数据,此项目都将为BigQuery计算使用收费 |
Credentials settings | 是 | 根据上面显示的身份验证指南进行配置。 |
Cloud Storage bucket | 否 | 添加一个Cloud Storage bucket的名称,用作写入数据到BigQuery的暂存位置。 |
Proxy settings | 否 | 启用以允许代理连接到BigQuery。 |
Settings for temporary tables | 否* | 启用以使用临时表。 |
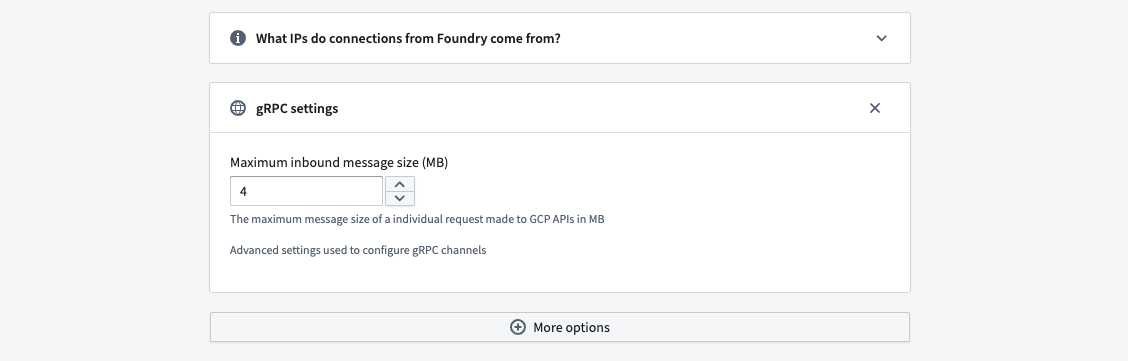
gRPC Settings | 否 | 用于配置gRPC通道的高级设置。 |
Additional projects | 否 | 添加必须通过同一连接访问的任何其他项目的ID;用于此连接器的Google Cloud帐户需要有权访问这些项目。连接器Project Id将为任何BigQuery数据访问或计算使用收费。 |
* 注册BigQuery视图 ↗通过虚拟表时必须启用临时表。
从BigQuery同步数据
要设置BigQuery同步,请在源概览屏幕的右上角选择探索和创建同步。接下来,选择要同步到Foundry的表。当您准备好同步时,选择为x个数据集创建同步。
了解更多关于在Foundry中源探索的信息。
临时表
当从非标准BigQuery表同步超过20GB的数据时,必须启用临时表。临时表允许BigQuery从大型查询输出导入结果,从视图和其他非标准表中导入数据,并允许进行大型增量导入和摄取。
要使用临时表,请在连接器配置中启用临时表设置。
- **自动创建数据集:**选择此选项以创建一个
Palantir_temporary_tables数据集来存储临时表。此选项要求BigQuery帐户在项目上拥有BigQuery Data Editor角色。 - **提供要使用的数据集:**选择此选项以手动添加要用于存储临时表的数据集的
Project ID和Dataset name。此选项要求BigQuery帐户在提供的数据集上拥有BigQuery Data Editor角色。
请注意,使用BigQuery视图 ↗与虚拟表时,必须启用临时表。
配置BigQuery同步
BigQuery连接器允许为大型数据同步和自定义查询进行高级同步配置。
在探索可用同步并将其添加到连接器后,导航到编辑同步。从左侧的同步面板中,找到要配置的同步并选择右侧的**>**。
导入设置
选择将从BigQuery同步到Foundry的数据。
同步完整表
输入以下信息以同步整个表到Foundry:
| 选项 | 必填? | 描述 |
|---|---|---|
BigQuery project Id | 否 | 表所属项目的ID。 |
BigQuery dataset | 是 | 表所属数据集的名称。 |
BigQuery table | 否 | 正在同步到Foundry的表的名称。 |
自定义SQL
可以运行任何任意查询,结果将保存在Foundry中。查询输出必须小于20GB(BigQuery表的最大大小),或者必须启用临时表使用。查询必须以关键字select或with开头。例如:SELECT * from table_name limit 100;。
增量同步
通常,同步将从目标表中导入所有匹配的行,无论同步之间数据是否更改。相反,增量同步维护关于最近一次同步的状态,并且只摄取目标中的新匹配行。
在从BigQuery摄取大型表时,可以使用增量同步。要使用增量同步,表必须包含一个严格单调递增的列。此外,正在读取的表或查询必须包含具有以下数据类型之一的列:
INT64FLOAT64NUMERICBIGNUMERICSTRINGTIMESTAMPDATETIMEDATETIME
示例:一个5 TB的表包含数十亿行数据,我们希望将其同步到BigQuery。该表有一个单调递增列,名为id。同步可以配置为每次摄取5000万行,使用id列作为增量列,初始值为-1,并配置限制为5000万行。
当同步最初运行时,前5000万行(基于id升序)包含一个id值大于-1的行将被摄取到Foundry中。例如,如果此同步运行多次并且在此同步的最后一次运行期间摄取的最大id为19384004822,则下一次同步将从第一个id大于19384004822的行开始摄取接下来的5000万行,依此类推。
增量同步需要以下配置:
| 选项 | 必填? | 描述 |
|---|---|---|
| 列 | 是 | 选择将用于增量摄取的列。如果表不包含任何支持的列类型, 下拉列表将为空。 |
初始值 | 是 | 从此值开始同步数据。 |
限制 | 否 | 单次同步下载的记录数。 |
自定义查询的增量同步
要为自定义查询同步启用增量查询,查询必须更新为匹配以下格式:
SELECT * from table_name where incremental_column_name > @value order by incremental_column_name asc limit @limit
导出数据到BigQuery
连接器可以通过两种方式导出到BigQuery:
- 通过Google Cloud Storage作为中间存储(推荐)。请参阅下面关于通过Cloud Storage导出的部分以获取更多信息。
- 通过BigQuery APIs请参阅从本地文件读取数据 ↗以了解所使用的API的详细信息
通过API写入适用于数百万行的数据规模。此模式的预期性能是大约两分钟内导出一百万行。如果您的数据规模范围达到数十亿行,请改用Google Cloud Storage。
任务配置
要开始导出数据,您必须配置一个导出任务。导航到包含要导出到的连接器的项目文件夹。右键选择连接器名称,然后选择创建数据连接任务。
在数据连接视图的左侧面板中,验证源名称与您要使用的连接器匹配。然后,将输入数据集添加到输入字段。输入数据集必须称为inputDataset,它是正在导出的Foundry数据集。导出任务还需要配置一个输出。输出数据集必须称为outputDataset并指向Foundry数据集。输出数据集用于运行、调度和监控任务。
在数据连接视图的左侧面板中:
- 验证
源名称与您要使用的连接器匹配。 - 添加一个名为
inputDataset的输入。输入数据集是正在导出的Foundry数据集。 - 添加一个名为
outputDataset的输出。输出数据集用于运行、调度和监控任务。 - 最后,在文本字段中添加一个YAML块以定义任务配置。
连接器和输入数据集在左侧面板中显示的标签不反映YAMl中定义的名称。
在创建导出任务YAML时使用以下选项:
| 选项 | 必填? | 默认 | 描述 |
|---|---|---|---|
project | 否 | 连接器的项目ID | 目标表所属项目的ID。 |
dataset | 是 | 数据集的名称,数据将导出到该数据集中。 | |
table | 是 | 数据将导出到的表的名称。 | |
incrementalType | 是 | SNAPSHOT | 值可以是SNAPSHOT或REQUIRE_INCREMENTAL。 **• 快照模式导出:**目标表的内容将被替换。 **• 增量模式导出:**内容将被追加到现有表。 |
要设置增量导出,请首先以SNAPSHOT模式运行第一个导出,然后将incrementalType更改为REQUIRE_INCREMENTAL。
示例任务配置:
Copied!1 2 3 4 5 6 7type: magritte-bigquery-export-task config: table: dataset: datasetInBigQuery table: tableInBigQuery project: projectId #(可选:除非导出项目与连接器配置的项目不同,否则不要指定。) incrementalType: SNAPSHOT | REQUIRE_INCREMENTAL # 增量类型:SNAPSHOT 表示快照,REQUIRE_INCREMENTAL 表示需要增量更新
只有包含以Parquet格式存储的行的数据集支持以BigQuery格式导出。
配置导出任务后,选择右上角的保存。
将行追加到输出表
如果需要将行追加到目标表,可以使用REQUIRE_INCREMENTAL而不是替换数据集。
增量同步要求仅将行追加到输入数据集中,并且BigQuery中的目标表必须与Foundry中的输入数据集的模式匹配。
通过Cloud Storage导出(推荐)
要通过Cloud Storage导出,必须在连接器的配置设置中配置一个Cloud Storage bucket。此外,Cloud Storage bucket必须仅用于连接器的临时表,以便任何临时写入bucket的数据尽可能少地被用户访问。
我们建议通过Cloud Storage而不是BigQuery APIs导出到BigQuery;Cloud Storage在规模上操作更好,并且不会在BigQuery中创建临时表。
通过BigQuery APIs导出
导出任务会在目标表旁创建一个临时表;此临时表不会应用额外的访问限制。此外,SNAPSHOT导出会删除并重新创建表,这意味着额外的访问限制也将被删除。
在通过BigQuery APIs导出时,数据被导出到临时表datasetName.tableName_temp_$timestamp。一旦导出完成,行将自动从临时表转移到目标表。
Hive表分区不支持通过BigQuery APIs导出。对于使用Hive表分区的数据集,请通过Cloud Storage导出。
如果导出以REQUIRE_INCREMENTAL模式运行,可以共享目标表。以SNAPSHOT模式运行会在每次运行时重新创建表,必须重新应用共享。
为成功通过BigQuery APIs导出,请不要对导出表应用BigQuery的行级或列级权限。
虚拟表
本节提供有关将虚拟表与BigQuery源一起使用的其他详细信息。本节不适用于同步到Foundry数据集。
| 虚拟表功能 | 状态 |
|---|---|
| 源格式 | 🟢 一般可用:表、视图和物化视图 |
| 手动注册 | 🟢 一般可用 |
| 自动注册 | 🟢 一般可用 |
| 下推计算 | 🟢 一般可用;通过BigQuery Spark连接器 ↗可用 |
| 增量管道支持 | 🟢 一般可用:仅APPEND [1] |
确保由虚拟表支持的增量管道基于仅APPEND的源表,因为BigQuery不提供UPDATE或DELETE变更信息。有关更多详细信息,请参阅官方BigQuery文档 ↗。
使用虚拟表时,请记住以下源配置要求:
- 必须将源设置为直接连接。虚拟表不支持使用中介代理。
- 确保已建立双向连接性和白名单,如本文件的网络部分所述。
- 如果在代码库中使用虚拟表,请参考虚拟表文档,了解所需的其他源配置细节。
- 使用服务帐户密钥文件凭据或工作负载身份联合(OIDC)。基于实例的身份验证不支持虚拟表。
- 必须启用临时表才能注册BigQuery视图 ↗,并且必须将相关角色添加到身份验证凭据。
[1] 要启用由BigQuery虚拟表支持的管道的增量支持,请确保启用时间旅行 ↗并设置适当的保留期。此功能依赖于变更历史 ↗,目前仅支持追加。支持Python变换中的current和added读取模式。_CHANGE_TYPE和_CHANGE_TIMESTAMP列将在Python变换中可用。
故障排除
未找到:在位置<location>中未找到数据集<dataset>
BigQuery根据查询中使用的输入或查询结果的存储位置确定查询运行的位置。当使用临时表时,输出设置为临时表数据集中的临时表;此数据集的位置将决定查询的运行位置。确保同步的所有输入和临时表数据集都在同一地区。如果启用了自动创建数据集设置,请使用Google Cloud控制台或Google的SDKs/APIs确定名为Palantir_temporary_tables的数据集的位置。
gRPC消息超过最大大小
如果同步数据时包含大型内容(如JSON列),传输可能会因上述错误而失败。在源的gRPC设置中调整BigQuery的最大入站消息大小以增加单个API调用中的数据传输。请记住,单个调用会获取多行,因此设置为最大行大小可能还不够。
您可以通过导航到连接设置 > 连接详细信息,然后滚动到更多选项并选择gRPC设置来找到此配置选项。