注意:以下翻译的准确性尚未经过验证。这是使用 AIP ↗ 从原始英文文本进行的机器翻译。
设置批量同步
批量同步功能支持将数据从外部系统同步到Foundry 数据集。批量同步是最广泛支持的功能,几乎在所有连接器上都可用。批量同步允许同步具有模式的表格数据以及没有模式的原始文件。
创建批量同步时,还会创建一个新的Foundry 数据集,同步的数据将写入其中。一旦配置好同步,您可以手动运行它或者设置一个计划来触发搭建,从外部系统读取数据并将其写入输出数据集。
请按照以下步骤设置批量同步。本设置指南假设您已成功配置支持批量同步的源连接。
创建新的批量同步
首先,在数据连接应用程序中导航到您的源连接,然后从概览页面中选择新建批量同步。如果这是一个新配置的源,您应该会看到如下所示的可用功能,并在批量同步选项旁选择创建。
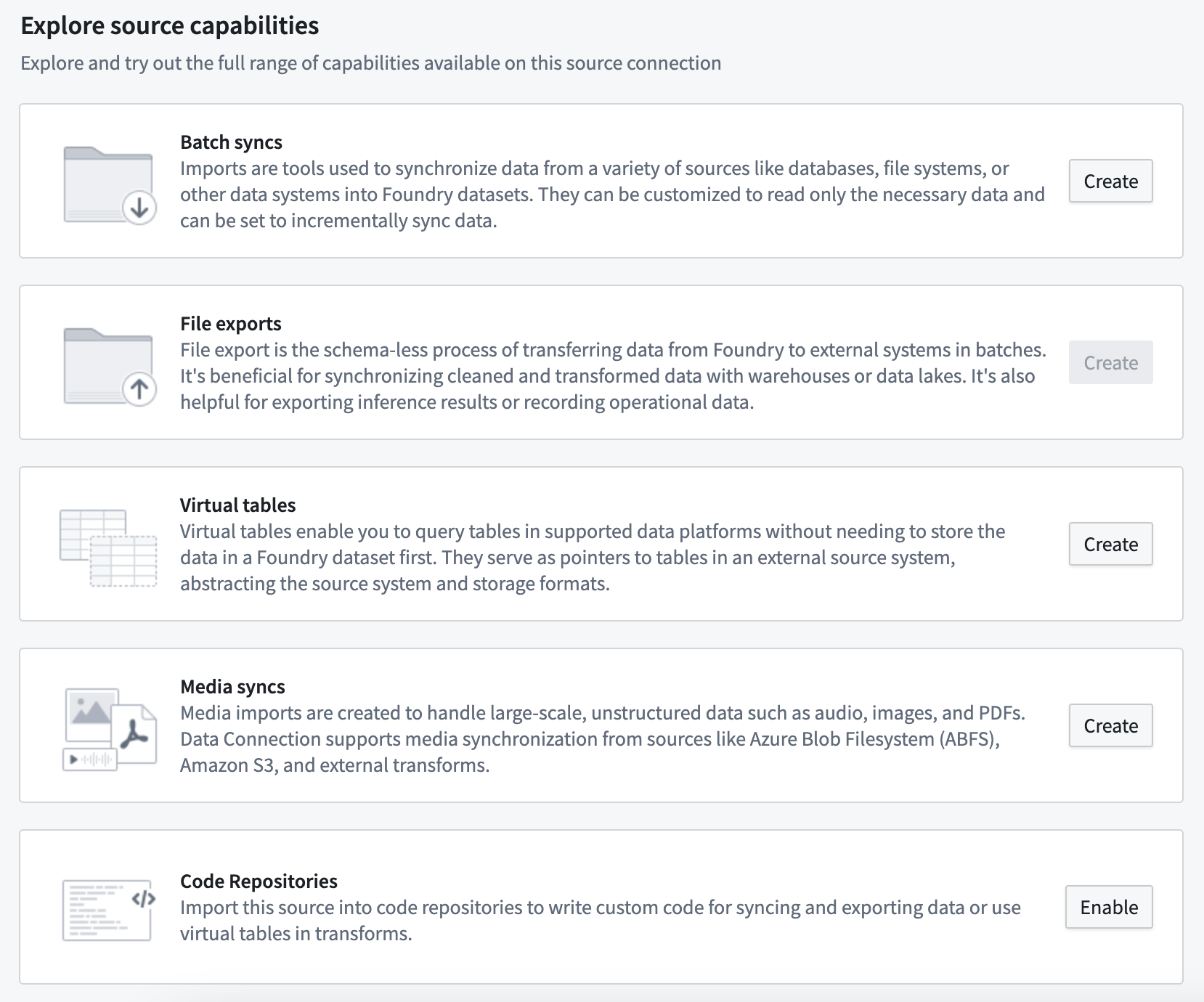
如果您的连接器支持源探索,您还可以选择探索并创建同步来探索您的数据源,并直接从探索视图开始创建同步。有关详细信息,请参阅源探索文档。
指定输出位置
输出位置定义了同步数据的数据集将被创建的位置,并将根据项目级权限决定谁有权访问结果数据。可以为源指定默认输出文件夹,如果需要,可以为每次同步覆盖该文件夹。
创建同步数据集的推荐最佳实践是将其与连接器一起保存。这种模式可以统一授权来自给定连接器的所有数据,这在创建数据管道时非常有用。了解有关数据管道推荐项目结构的更多信息。
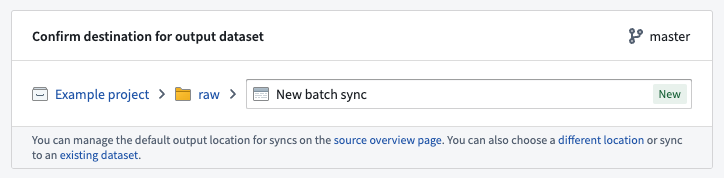
同步到现有数据集是支持的,但不推荐,因为同步可能会覆盖选定数据集中已经存在的任何数据。
配置批量同步
在与目标相同的页面上,您将看到用于配置批量同步的各种设置。
根据源的不同,可能会提供不同的选项。两种最常见的批量同步类型是:
大多数系统支持文件或表批量同步,但某些系统可能同时支持这两种类型。
文件批量同步示例
以下示例展示了从S3进行文件批量同步的配置,该配置在每次搭建时进行SNAPSHOT更新。您可以选择性地指定子目录和筛选以缩小要同步到输出数据集的文件集。我们的示例没有指定子目录或筛选,这意味着在设置源连接时选择的根目录下找到的所有文件都将被同步。
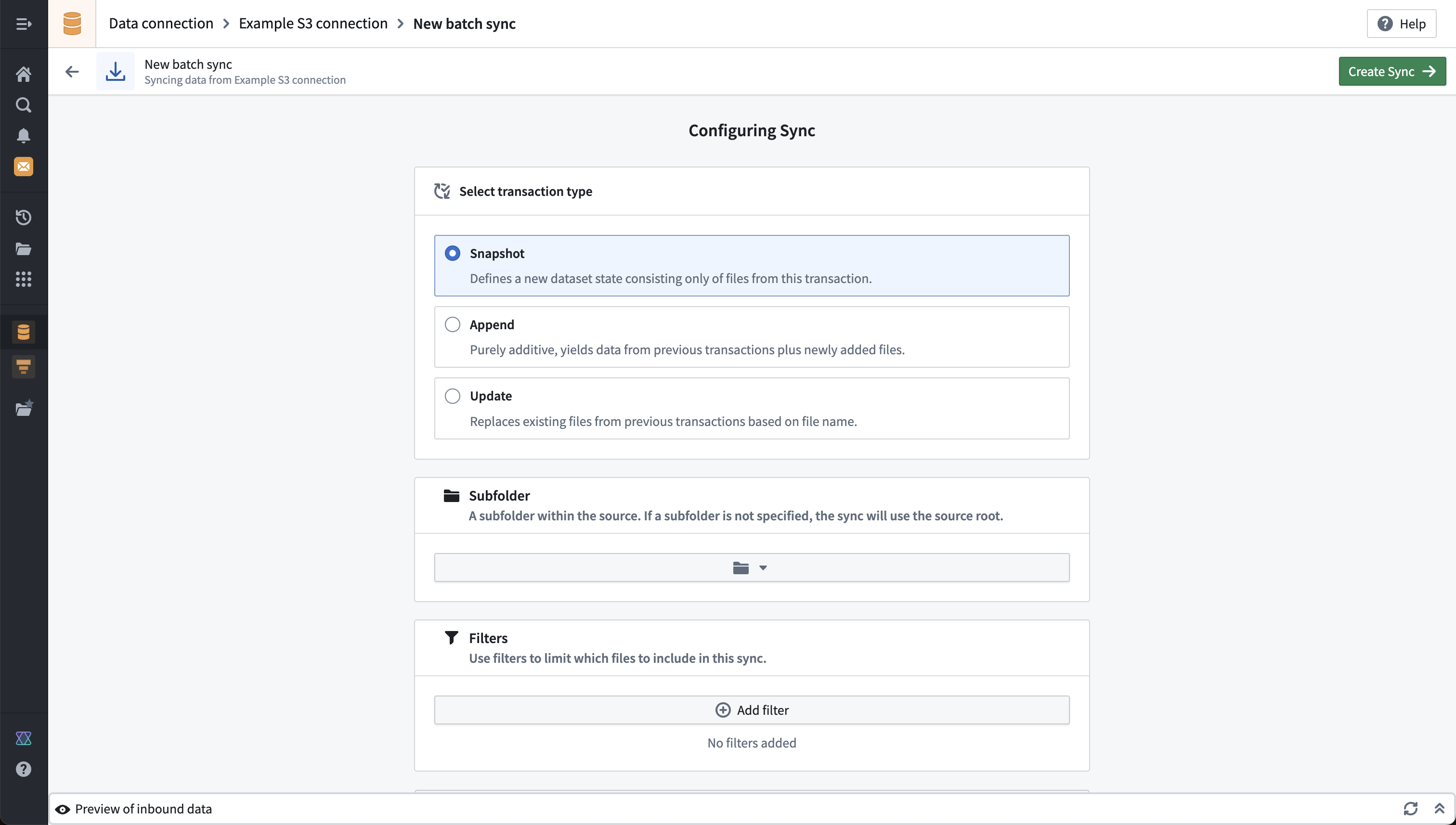
有关文件批量同步的其他设置,请参阅文件批量同步的参考文档,其中包括可用筛选的详细文档。
表批量同步示例
此示例展示了从Microsoft SQL Server进行表批量同步的配置。查询定义了将从目标系统提取哪些数据。在这种情况下,还启用了增量批量同步设置,允许基于单调递增列增量更新数据。
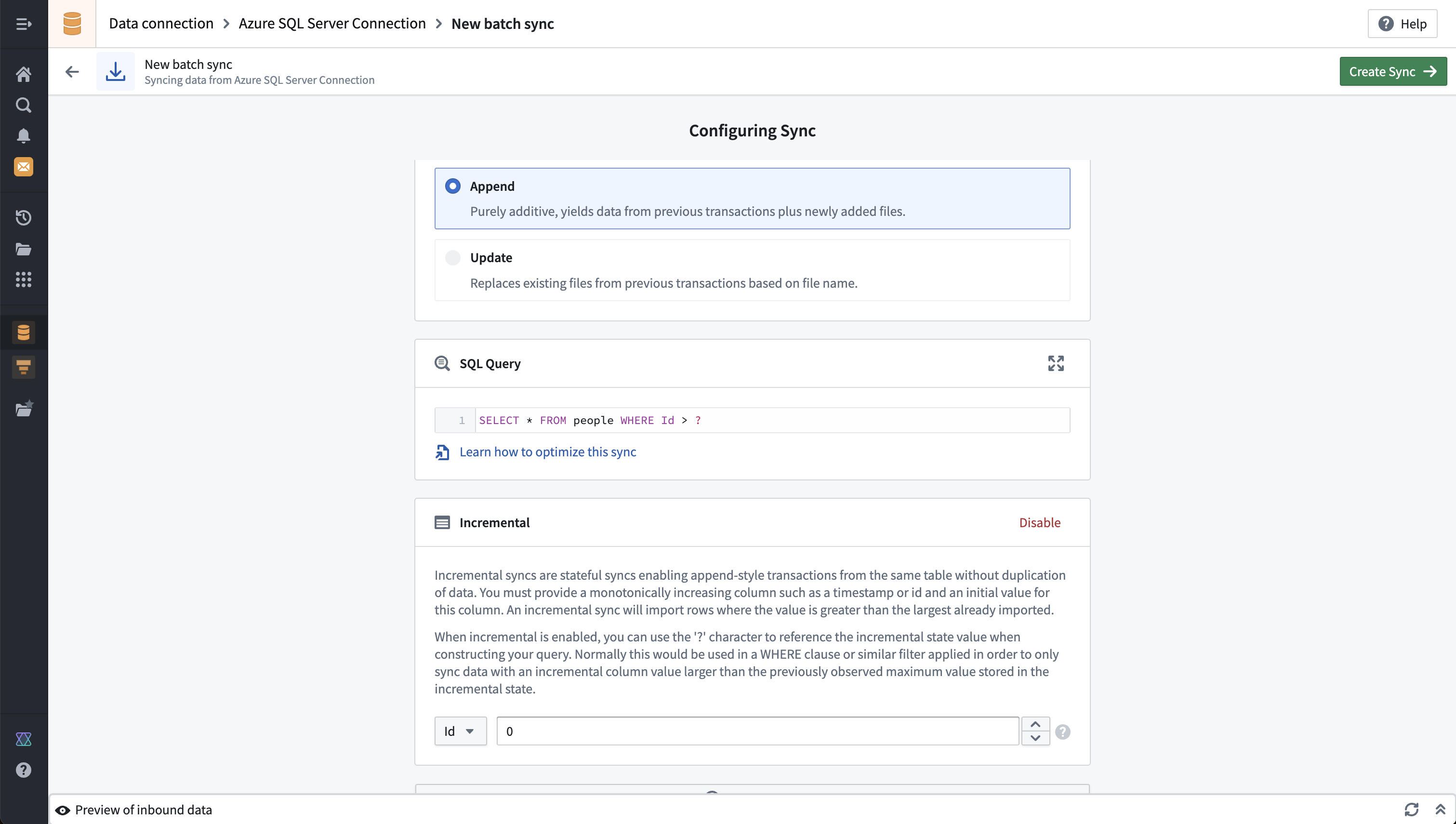
虽然您无法在探索源选项卡上可视化SQL存储过程,但您可以通过在SQL查询字段中运行EXEC命令并后接相应的过程来运行SQL存储过程。
其他选项
大多数批量同步还有许多其他选项,可能因连接器而异。以下是一些广泛可用的批量同步配置选项示例:
- 事务类型决定了摄取的数据是覆盖之前摄取的数据(
SNAPSHOT)还是增量添加(APPEND)。了解更多关于增量同步的信息。 - 计划允许您配置使用Foundry的搭建系统同步数据的频率。我们建议为您新创建的同步设置一个计划。了解更多关于计划的最佳实践。
- 搭建策略允许您限制同步允许运行的时间,而不管配置的计划如何。
- 最大持续时间允许您自动取消超过指定时间限制运行的同步。如果同步时间超过大约48小时,所有同步将自动取消。
以下选项仅适用于表批量同步:
- 无时区的时间戳设置允许您自定义在同步到Foundry时如何处理无时区的时间戳数据。默认情况下,无时区的时间戳将作为字符串同步,但您可以选择以手动指定的时区同步为
timestamp,或同步为long。 - 允许模式更改。此设置允许您在外部系统中发生模式更改时阻止批量同步运行。默认情况下,允许模式更改,并将覆盖Foundry数据集的模式,这可能会影响下游管道。
预览您的同步输出
在继续之前,您可以运行预览以查看根据您配置的设置将要同步的数据。您应该使用此功能来验证您的同步是否按预期配置。
- 对于文件批量同步,预览将显示文件列表。
- 对于表批量同步,预览将显示选定表的结果,限制为前20行。
下方展示了一个S3文件批量同步的示例预览,筛选到一个名为csv_files的子文件夹:
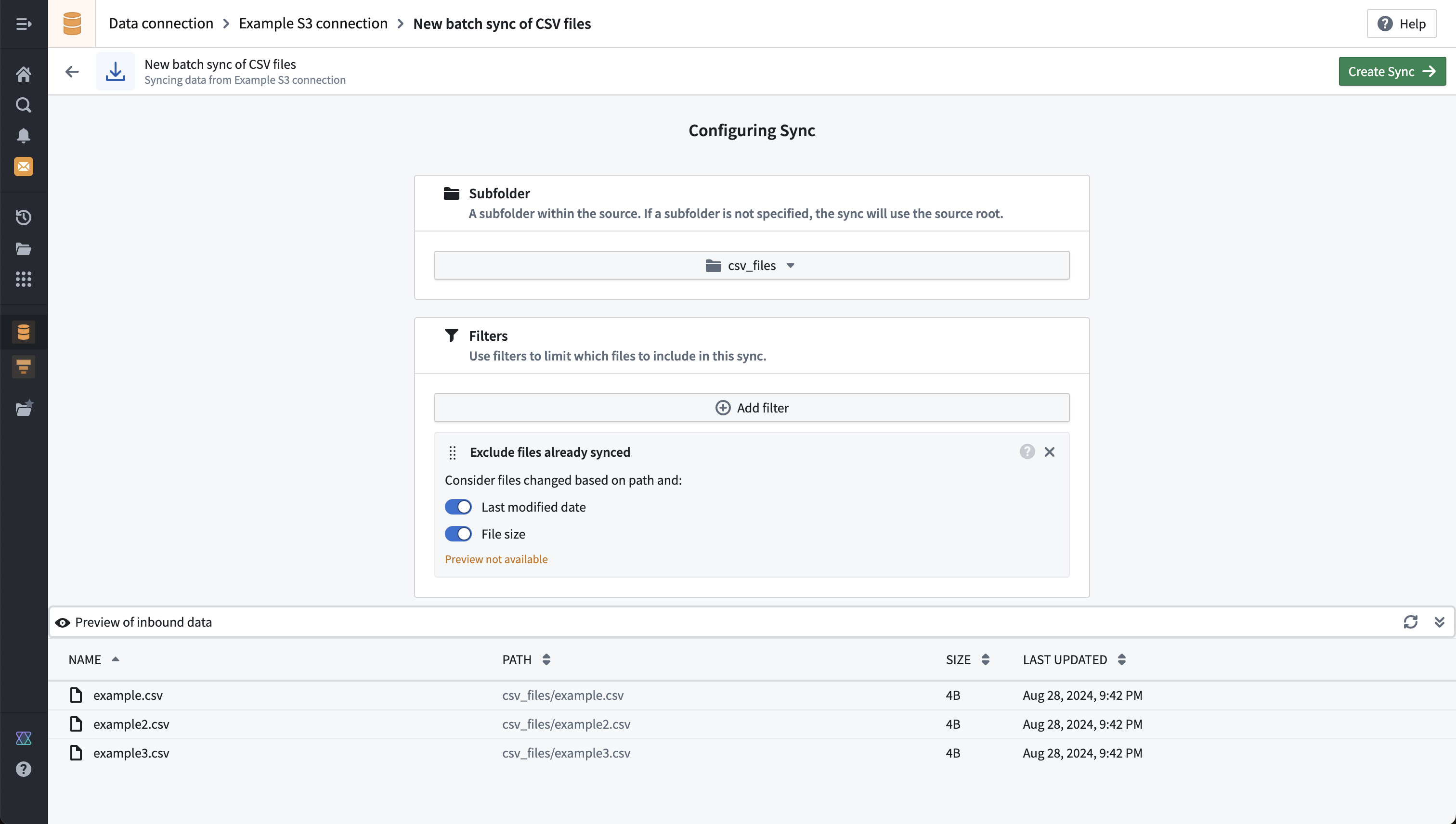
上面的示例在使用排除已同步文件筛选时显示了一个警告预览不可用。这是因为此筛选不反映在所显示的预览结果中,只有在计划同步或手动运行时才会应用。
搭建或计划您的批量同步
保存批量同步后,您可以选择何时以及如何运行它。
使用同步概览页面上显示的运行按钮手动运行您的批量同步:

配置搭建计划以定期触发批量同步运行:
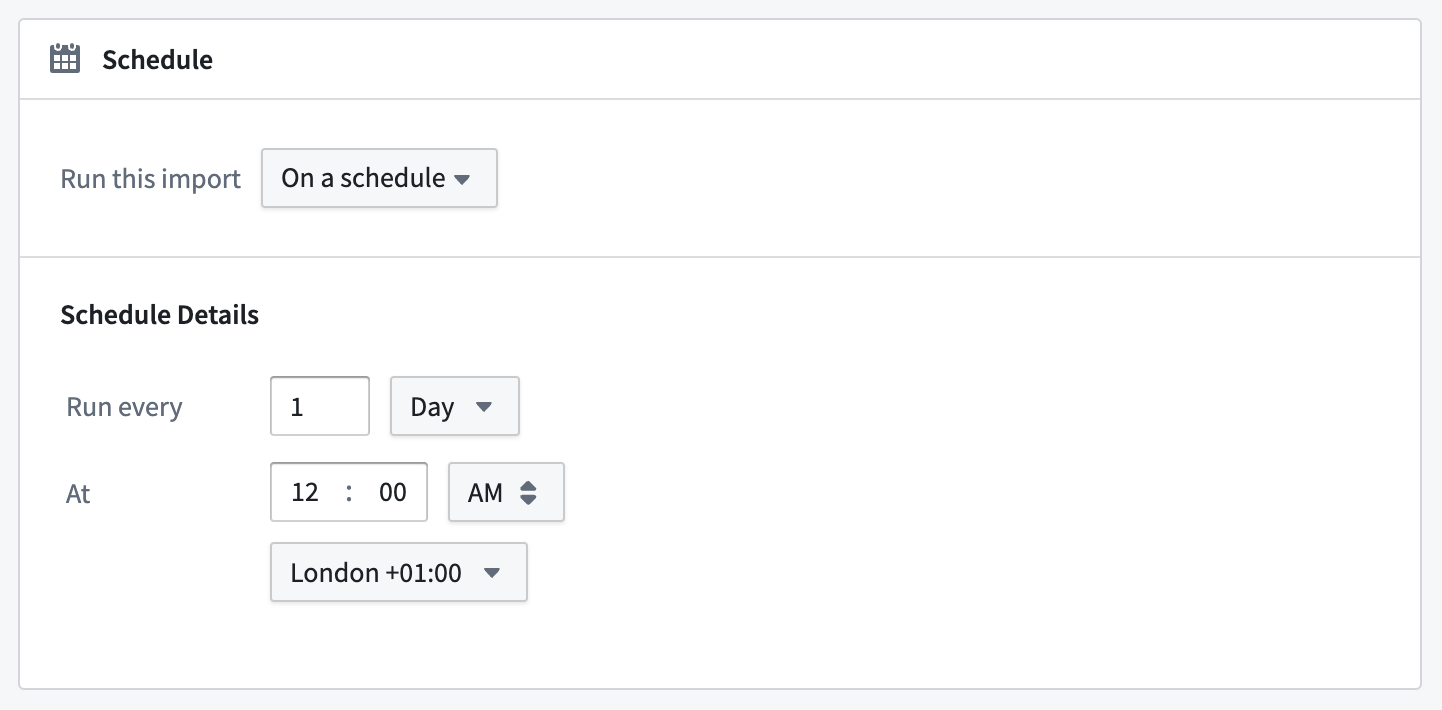
不应在数据连接和数据沿袭中为同一批量同步配置计划。从数据沿袭配置的计划在构建数据连接同步时应始终使用强制搭建选项。
下一步
在本设置指南中,您学习了如何创建批量同步以将数据从连接器带入Foundry数据集。以下是我们推荐的一些其他资源: