注意:以下翻译的准确性尚未经过验证。这是使用 AIP ↗ 从原始英文文本进行的机器翻译。
基于源的外部变换
基于源的外部变换是一种从代码库连接到外部系统的新方法,通过导入包含外部系统设置的数据连接源在单一资源中实现。
基于源的外部变换的关键优势包括支持以下功能:
- 连接无法从互联网访问的系统。
- 旋转/更新凭据而无需代码更改。
- 在多个库之间共享连接配置。
- 为选定的源类型提供开箱即用的Python客户端。
- 改进和简化的治理工作流程,用于启用和管理外部变换库。
- 在数据沿袭中可视化连接到外部源的外部变换。
外部变换允许从Python变换库连接到外部系统。
外部变换主要用于执行批量同步、导出和媒体同步工作流程,当以下条件之一为true时:
- 不存在现有的数据连接源类型。
- 目标源类型所需的功能不可用。
- 数据连接用户界面提供的功能不具备所需特性。
这些情况的解决方案可能包括以下内容:
- 连接到REST API,无论是通过互联网还是在私有网络内。
- 连接到数据库以安排数据连接用户界面当前无法实现的自定义查询逻辑。
- 在同步或导出期间根据需要变换数据。这可能包括在写入Foundry之前将文件批量处理在一起,在传输过程中处理数据的自定义加密/解密等。
任何使用虚拟表的变换也被视为外部变换,因为变换任务必须能够访问包含虚拟数据的外部系统。要在Python变换中使用虚拟表,请按照下面的说明了解如何设置源。
设置指南
在本设置指南中,我们将逐步创建一个连接到免费的Pokemon数据公共API↗的Python变换库。然后示例将使用此API解释外部变换的各种功能以及如何与API一起使用。
本设置指南中使用的Pokemon API与Palantir无关,并且可能随时更改。本教程不是对该API进行生产应用案例的认可、推荐或建议。
前提条件:创建一个Python变换库
在遵循本指南之前,请确保首先创建一个Python变换库,并按照我们的教程了解如何编写Python变换。Python变换的所有功能都与外部变换兼容。
前提条件:创建一个数据连接源
在您可以从Python库连接到外部系统之前,您必须创建一个可以导入代码的数据连接源。在本教程中,我们将创建一个连接到上述PokeAPI的REST API源。
选项1:在外部系统侧边栏中创建源
在外部变换中使用源的最快方法是从Python变换代码库中创建源。初始化库后,完成以下步骤以设置通用源:
- 从左侧面板中打开外部系统选项卡。
- 选择添加 > 创建新的。
- 为您的源选择一个名称和一个项目来存储它。创建后,新创建的源将在左侧面板中显示。任何出口策略、密钥和可导出权限标记都可以直接从此面板中配置。
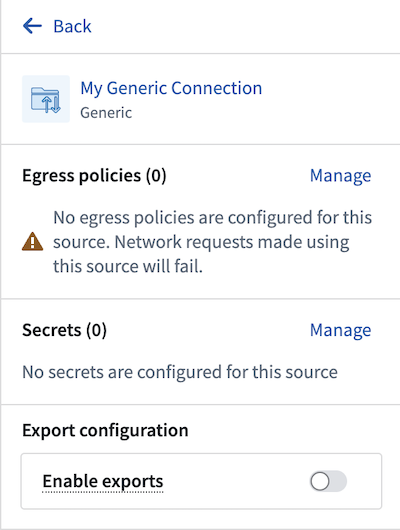
-
对于本教程,您应该为PokeAPI添加一个出口策略:
pokeapi.co。您无需任何密钥,因为此API不需要身份验证,并且可以暂时跳过出口控制。然而,它们将是使用Foundry数据输入与此源所必需的。 -
由于此连接是到REST API的,您将被自动提示将您的通用连接器转换为REST API源,以便您可以使用内置的Python请求客户端。
选项2:在数据连接中创建源
您还可以从数据连接应用程序中创建源或使用您已配置的现有源。要使用此选项,请按照以下步骤操作:
- 在Foundry中导航到数据连接应用程序并选择新源。从选项列表中选择REST API。
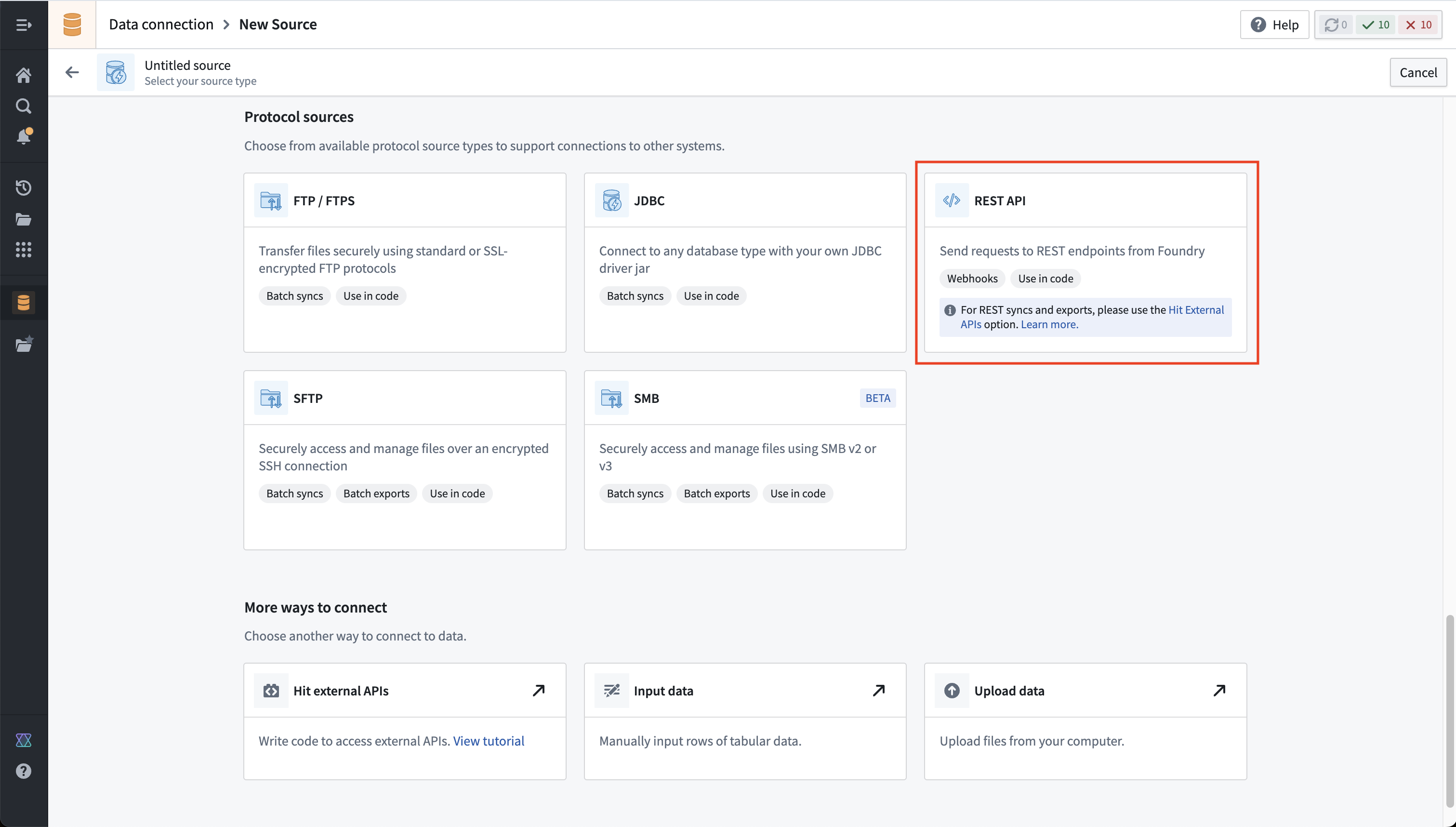
-
查看概述页面,然后在右下角选择继续。您将被提示选择连接运行时:直接连接、通过代理或通过代理代理(测试版)。由于代理连接不支持外部变换,请选择使用直接连接到互联网以连接到PokeAPI。
-
为您的源选择一个名称,并选择一个项目以保存它。
-
在域部分填写API源的连接信息。PokeAPI示例的配置如下所示:

- 对于此示例,我们还需要创建必要的出口策略。如果您完成了上一步,策略将在网络连接部分中自动建议:
 6. 选择保存,然后选择保存并继续以完成源设置。
6. 选择保存,然后选择保存并继续以完成源设置。
前提条件:将源导入代码
具有多个域的REST API源可能无法导入。相反,如果在同一外部变换中需要多个域,您应为每个域创建单独的REST API源。
-
首先,您必须允许REST API源导入代码。要配置此设置,请导航到数据连接中的源,然后进入连接设置 > 代码导入配置选项卡。
-
切换选项以允许此源导入代码库。任何导入此源的代码库将在此页面上显示。

- 您现在可以返回您的代码库。要使用外部变换,您必须首先导入
transforms-external-systems库。在左侧面板的库选项卡中搜索所需的库,然后选择安装以安装库。
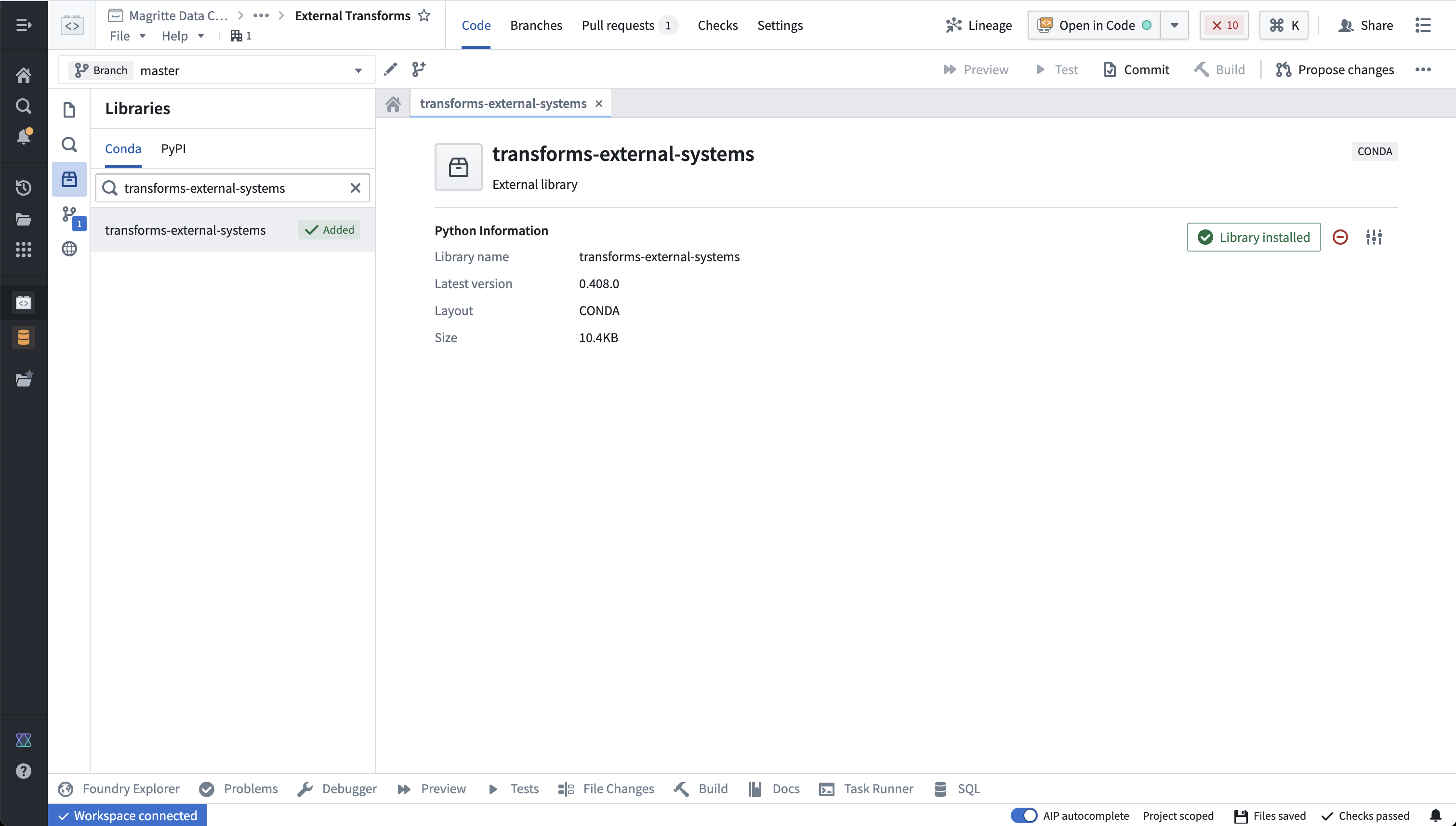
- 现在,您必须导入源。在库中,导航到左侧面板并选择由地球图标表示的外部系统选项卡。在侧边栏中,选择添加,然后搜索您之前创建的PokeAPI源。选择此源,然后确认选择以导入。

编写外部变换
一旦您设置了一个导入PokeAPI源的Python变换库,您就可以开始编写使用该源进行外部连接的Python变换代码。
导入和配置@external_systems装饰器
要使用基于源的外部变换,您必须从transforms.external.systems库中导入external_systems装饰器和Source对象:
Copied!1 2from transforms.external.systems import external_systems, Source # 从transforms.external.systems模块导入external_systems和Source类
然后应该通过使用 external_systems 装饰器来指定应该在变换中包含的源:
Copied!1 2 3@external_systems( pokeSource=Source("ri.magritte..source.e301d738-b532-431a-8bda-fa211228bba6") )
这个代码片段展示了一个装饰器 @external_systems 的使用,装饰器用于为函数或方法指定外部系统的依赖。pokeSource 是一个参数,其值是一个 Source 对象。Source 的构造函数接受一个字符串,这个字符串通常是一个标识符,用于指明具体的外部数据源。在这里,标识符是 "ri.magritte..source.e301d738-b532-431a-8bda-fa211228bba6",这可能是一个表示外部系统的唯一标识符。
数据源将自动渲染为链接,以在数据连接中打开,并显示数据源名称而不是资源标识符。
访问数据源属性和凭据
一旦将数据源导入到您的变换中,您可以使用内置连接Object的get_https_connection()方法访问数据源的属性。下面的示例展示了如何获取我们在上一步配置的PokeAPI数据源的基本URL。
Copied!1 2# 获取HTTPS连接的URL并存储在变量pokeUrl中 pokeUrl = pokeSource.get_https_connection().url
源上存储的其他密钥或凭证也可以从源访问。要识别可以访问的密钥名称,请导航到变换中的左侧面板。
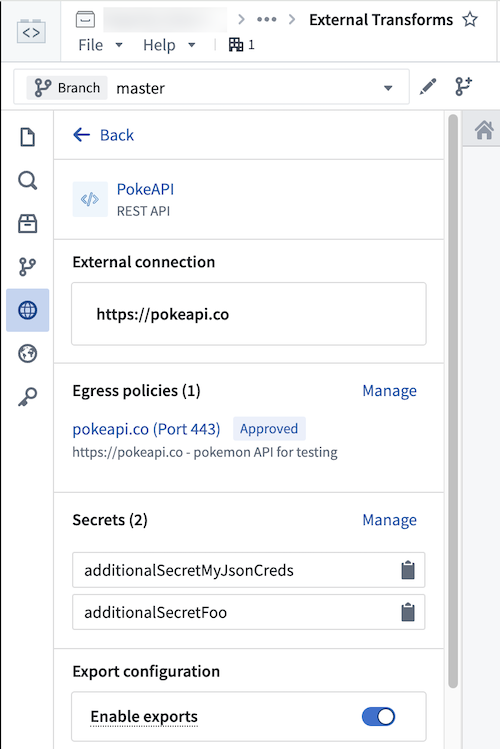
使用以下语法在代码中访问密钥:
Copied!1 2pokeSource.get_secret("additionalSecretFoo") # 从 pokeSource 获取名为 "additionalSecretFoo" 的秘密
目前,如果源没有提供HTTPS客户端,则无法访问非凭证的源属性。例如,在PostgreSQL源上,您将无法访问hostname或其他非机密属性。
使用内置HTTP客户端
对于提供RESTful API的源,源对象允许您与内置HTTPS客户端进行交互。该客户端将预先配置源上指定的所有详细信息,包括任何服务器或客户端证书,您可以直接开始向外部系统发出请求。
Copied!1 2 3 4 5 6 7pokeUrl = pokeSource.get_https_connection().url pokeClient = pokeSource.get_https_connection().get_client() # pokeClient 是从 Python `requests` 库中预配置的 Session 对象。 # GET 请求的示例: response = pokeClient.get(pokeUrl + "/api/v2/pokemon/" + name, timeout=10) # 这里我们使用 GET 方法从 PokeAPI 获取特定名称的宝可梦数据,超时时间设置为 10 秒。
当使用代理代理连接到本地系统时,您_必须_使用内置客户端,因为它将自动配置必要的代理代理配置。
代理代理是一个测试功能,可能不包括在您的注册中。
示例:从 PokeAPI 导入数据
以下示例展示了一个完整的变换,该变换以每次100批的形式分页浏览API返回的所有pokemon,并将所有pokemon名称输出到一个数据集中。
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37from transforms.api import transform_df, Output from transforms.external.systems import external_systems, Source from pyspark.sql import Row import json import logging logger = logging.getLogger(__name__) @external_systems( # 指定导入到存储库的源 pokeSource=Source("ri.magritte..source.e301d738-b532-431a-8bda-fa211228bba6") ) @transform_df( # 这个转换不使用任何输入,只指定一个输出数据集 Output("/path/to/output/dataset") ) def compute(pokeSource, ctx): poke = pokeSource.get_https_connection().get_client() pokeUrl = pokeSource.get_https_connection().url data = [] startUrl = pokeUrl + "/api/v2/pokemon?limit=100&offset=0" while startUrl is not None: # 循环直到没有更多的页面可用 logger.info("Fetched data from PokeAPI:" + startUrl) # 使用为PokeAPI源内置的HTTPS客户端获取每页最多100个宝可梦 response = poke.get(startUrl) responseJson = json.loads(response.text) for pokemon in responseJson["results"]: data.append(Row(name=pokemon["name"])) startUrl = responseJson["next"] # 从外部系统获取并解析的数据被写入输出数据集 return ctx.spark_session.createDataFrame(data)
代码解释
- external_systems 和 transform_df 装饰器用于定义从外部系统拉取数据并将其转换为输出数据集的过程。
pokeSource从指定的源获取连接,用于访问 PokeAPI。compute函数负责从 PokeAPI 获取数据,将每个宝可梦的名字提取出来并存储在一个列表中。- 最终,这些数据被转换为 Spark 的 DataFrame 格式,并写入到指定的输出路径。
在外部变换中使用 Foundry 输入
外部变换通常需要使用 Foundry 输入数据。例如,您可能希望查询一个 API,以为表格数据集中的每一行收集额外的元数据。或者,您可能有一个需要将 Foundry 数据导出到外部软件系统的工作流。
此类情况被视为受出口管制的工作流,因为它们开启了将安全的 Foundry 数据导出到另一个具有未知安全保证和中断数据沿袭的系统的可能性。在配置源连接时,源所有者必须指定是否可以导出 Foundry 的数据,并提供可能导出的安全权限标记和组织集。Foundry 提供治理控制,以确保开发人员可以清晰地编码安全意图,信息安全官员可以审计与外部系统交互的工作流的范围和意图。
在源上配置出口控制
出口是通过权限标记控制的。在配置源时,出口配置用于指定哪些权限标记和组织可以安全地导出到外部系统。这是通过导航到数据连接应用程序中的源,然后导航到 连接设置 > 出口配置 选项卡来完成的。然后,您应切换开启启用导出到此源的选项,并选择可能导出的权限标记和组织集。
执行此操作需要权限以移除相关数据和组织上的权限标记,因为导出被视为相当于移除 Foundry 中数据的权限标记。
必须切换开启启用导出到此源的设置,以允许以下操作:
- 使用数据集、媒体集和流作为导入此源的 Python 变换代码的输入。
- 在 Python 变换中使用注册在此源上的虚拟表。
下面您可以看到 PokeAPI 源的一个出口配置示例,允许来自 Palantir 组织且没有额外权限标记的数据导出到 PokeAPI:

请注意,即使您实际上并没有将数据导出到此系统,启用导出到此源仍必须切换开启,因为允许 Foundry 数据输入到与此系统有开放连接的同一计算任务中意味着数据_可能_被导出。
示例:将 Foundry 导入与 PokeAPI 的数据结合使用
在此示例中,我们从一个包含宝可梦名称的输入数据集开始,并使用 PokeAPI 输出一个丰富的数据集,其中包括每个宝可梦的身高和体重。它还展示了基于响应状态代码的基本出错处理。
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46from transforms.api import transform_df, Output, Input from transforms.external.systems import external_systems, Source from pyspark.sql import Row import json import logging logger = logging.getLogger(__name__) # 定义外部数据源,使用 PokeAPI 的源 @external_systems( pokeSource=Source("ri.magritte..source.e301d738-b532-431a-8bda-fa211228bba6") ) # 定义数据转换函数 @transform_df( # 输出数据集,包含从 PokeAPI 获取的增强型宝可梦数据 Output("/path/to/output/dataset"), # 输入数据集,包含宝可梦的名称 pokemonList=Input("/path/to/input/dataset") ) def compute(pokeSource, pokemonList, ctx): # 获取HTTPS连接的客户端 poke = pokeSource.get_https_connection().get_client() # 获取HTTPS连接的URL pokeUrl = pokeSource.get_https_connection().url def make_request_and_enrich(row: Row): name = row["name"] # 向PokeAPI发送请求获取宝可梦数据 response = poke.get(pokeUrl + "/api/v2/pokemon/" + name, timeout=10) if response.status_code == 200: # 解析返回的JSON数据 data = json.loads(response.text) height = data["height"] # 获取宝可梦的高度 weight = data["weight"] # 获取宝可梦的体重 else: logger.warn(f"Request for {name} failed with status code {response.status_code}.") height = None weight = None # 返回包含宝可梦名称、高度和体重的行 return Row(name=name, height=height, weight=weight) # 将输入数据集映射到新的数据集,其中包含增强后的数据 return pokemonList.rdd.map(make_request_and_enrich).toDF()
权限
下表概述了配置和运行外部变换所需的权限。
| 操作 | 所需权限 |
|---|---|
| 允许将源导入到代码中 | 源的Owner角色 |
| 修改源的导出配置 | 源的Owner角色。此外,配置可导出权限标记的用户必须具有从任何组织或他们添加为可安全导出到所选源的安全权限标记中移除权限标记的权限。注意:这在使用外部变换中的Foundry输入时是必需的。 |
| 将源导入到存储库 | 源和存储库的Editor角色 |
| 从存储库取消导入源 | 源的Editor角色或存储库的Editor角色 |
| 搭建导入源的外部变换 | 代码存储库的Editor角色 |
当源被导入到代码存储库时,具有代码存储库访问权限的用户可以使用为该源配置的连接详细信息编写自定义代码,包括访问秘密值。
这意味着导入源到代码中和授予Editor访问源的能力应被谨慎管理,仅可信用户应被授予源和存储库的访问权限。
基于源的和常规外部变换的比较
以下是基于源的和常规外部变换之间的一些关键工作流差异:
- 基于源的外部变换的导入源的标签将始终自动显示。以前,仅在信息安全官员切换了在存储库设置中使用外部系统的能力之后,才会显示添加出口策略和凭证的标签。
- 允许外部连接和使用输入的设置不再位于存储库设置中。相反,这些设置在每个单独的源上进行控制。
- 凭证、出口政策和可导出权限标记不再在代码中指定。相反,这些设置从导入到变换中的源中获取,并自动应用于任务。
- 如果在源级别更改了这些配置,它将自动被导入该源的变换所捕获,无需任何代码更改或版本升级。这允许凭证、出口和可导出权限标记的集中治理,立即传播到下游工作流中。
- 更改将在搭建开始时生效,不会影响正在运行的搭建。
- 装饰器已从
@use_external_systems()更改为@external_systems()。
基于源的外部变换的主要优势包括以下内容:
- 支持连接到无法从互联网访问的系统
- 支持旋转/更新凭证而无需代码更改
- 支持在多个存储库之间共享连接配置
- 选定源类型的开箱即用Python客户端
- 改进和简化的治理工作流,用于启用和管理外部变换存储库
- 在数据沿袭中可视化连接到外部源的外部变换
迁移到基于源的外部变换
目前没有自动迁移路径将外部变换更新为基于源的外部变换。然而,大多数工作流所需的手动操作预计是最小的。
以下是手动迁移到基于源的外部变换的主要步骤:
- 确定在现有外部变换代码中使用的凭证、出口政策和出口控制权限标记集合
- 确定或配置数据连接源,这些源连接到您希望从外部变换中连接的系统。确保这些源配置为允许导入到代码中。
- 将步骤2中的相关源导入到现有的Python变换存储库中。
- 更改您的代码以导入和使用带有源引用的新
@external_systems()装饰器,然后移除任何@use_external_systems()装饰器的实例。这可能涉及更新变换逻辑中对凭证的任何引用,以改为引用从现在导入的源中检索到的凭证。 - 在分支上测试您的更改,以确保您的变换继续成功搭建。
- 合并更新后的变换代码后,您现在可以取消切换存储库设置。
轻量级基于源的外部变换
基于源的外部变换兼容@lightweight装饰器。使用此装饰器可以显著提高在小型和中型数据上运行的变换的执行速度。
以下示例显示了如何将@lightweight装饰器与@external_systems装饰器一起添加到变换中。有关配置轻量级变换的选项的更多信息,请参见轻量级变换文档。
Copied!1 2 3 4 5 6 7 8@lightweight @external_systems( pokeSource=Source("ri.magritte..source.e301d738-b532-431a-8bda-fa211228bba6") ) # 该代码片段使用了两个装饰器:@lightweight 和 @external_systems。 # @lightweight 通常用于指示该函数或方法是轻量级的,可能在资源消耗上较低。 # @external_systems 装饰器用于定义与外部系统的交互。在这个例子中,它指定了一个名为 pokeSource 的外部资源。 # Source("ri.magritte..source.e301d738-b532-431a-8bda-fa211228bba6") 是该外部资源的标识符。