注意:以下翻译的准确性尚未经过验证。这是使用 AIP ↗ 从原始英文文本进行的机器翻译。
在 Jupyter® 笔记本中训练模型
模型资产目前不支持 SparkML 库。我们建议切换到单节点机器学习框架,如 PyTorch、TensorFlow、XGBoost、LightGBM 或 scikit-learn。
模型 可以在 代码工作区 的 Jupyter® 笔记本中进行训练。要训练模型,请完成以下步骤:
监督模型训练教程 提供了在 Jupyter® 代码工作区中进行模型训练的额外指导。
创建一个 Jupyter® 代码工作区
- 要为模型训练创建新的 Jupyter® 代码工作区,导航到您的项目文件夹并选择 + New > Jupyter® Code Workspace,或在代码工作区应用中选择 + New code workspace。
- 在代码工作区中,选择 JupyterLab® 作为工作区类型,然后在右下角选择 Continue。
- 根据您正在训练的模型命名您的工作区。您可以选择性地配置其他设置,例如工作区的计算资源或网络策略,方法是在 Code Repository 步骤中选择 Advanced。命名笔记本后,选择 Continue。
- 最后,选择 Create 来创建并启动工作区。

导入数据并编写模型训练代码
建立工作区后,您可以创建一个新笔记本来导入数据并开始编写模型训练代码。
代码工作区可访问其他 Foundry 代码创作环境中可用的软件包,例如代码库。要添加新软件包,打开工作区左侧边栏上的 Packages 选项卡,搜索您需要的软件包,选择,然后点击 Latest 或其他可用版本以打开终端并运行相应的安装命令。
将数据导入工作区
代码工作区应用允许用户导入现有 Foundry 数据集以用作训练数据。在代码工作区中使用的训练数据需要一个人类可读的别名作为其资源标识符。
- 要导入数据集,打开左侧边栏顶部的 Data 选项卡,然后选择 Add dataset > Read existing datasets。
- 选择您要导入到工作区的数据集,输入数据集别名,然后选择 + Add dataset 以完成 Step 1。
- 代码工作区将在 Step 2 中生成一个代码片段,您可以选择数据集格式,例如
pandas DataFrame。要将生成的代码片段复制到您的笔记本中,选择代码片段右上角的剪贴板图标,然后选择 Done。以下是代码工作区生成的代码片段示例:
Copied!1 2 3 4from foundry.transforms import Dataset # 从数据集 "my-alias" 中读取数据,并以 Pandas DataFrame 格式返回 training_data = Dataset.get("my-alias").read_table(format="pandas")
- 将代码片段复制到剪贴板后,通过选择Python [user-default],从
Launcher面板启动一个Notebook,并将代码片段粘贴到第一个单元格中。 - 运行代码以导入数据集,通过在操作工具栏中选择“播放”图标或在菜单栏中选择Run > Run Selected Cells。
编写模型训练代码
在Code Workspaces中可用的开源工具允许您为各种分析应用案例训练您的模型,例如回归或分类。下面是一个使用scikit-learn预测中位数家庭收入的线性回归模型示例。
- 通过在左侧边栏的Data下选择Packages图标,在您的工作区中安装
scikit-learn。 - 在搜索栏左侧的下拉菜单中选择
Conda或PyPi管理器,然后搜索scikit-learn。 - 要在终端中运行安装命令,请在下拉菜单中选择一个软件包版本,然后选择版本按钮。或者,您可以使用
maestro env conda install或maestro env pip install命令,从终端一次性安装多个软件包到您的托管环境。
使用侧边栏进行软件包安装:

从终端进行软件包安装:

在Code Workspaces中编写并运行您的模型后,您可以将其发布到Foundry,以便在其他应用程序中进行集成。下面是一个模型训练代码示例:
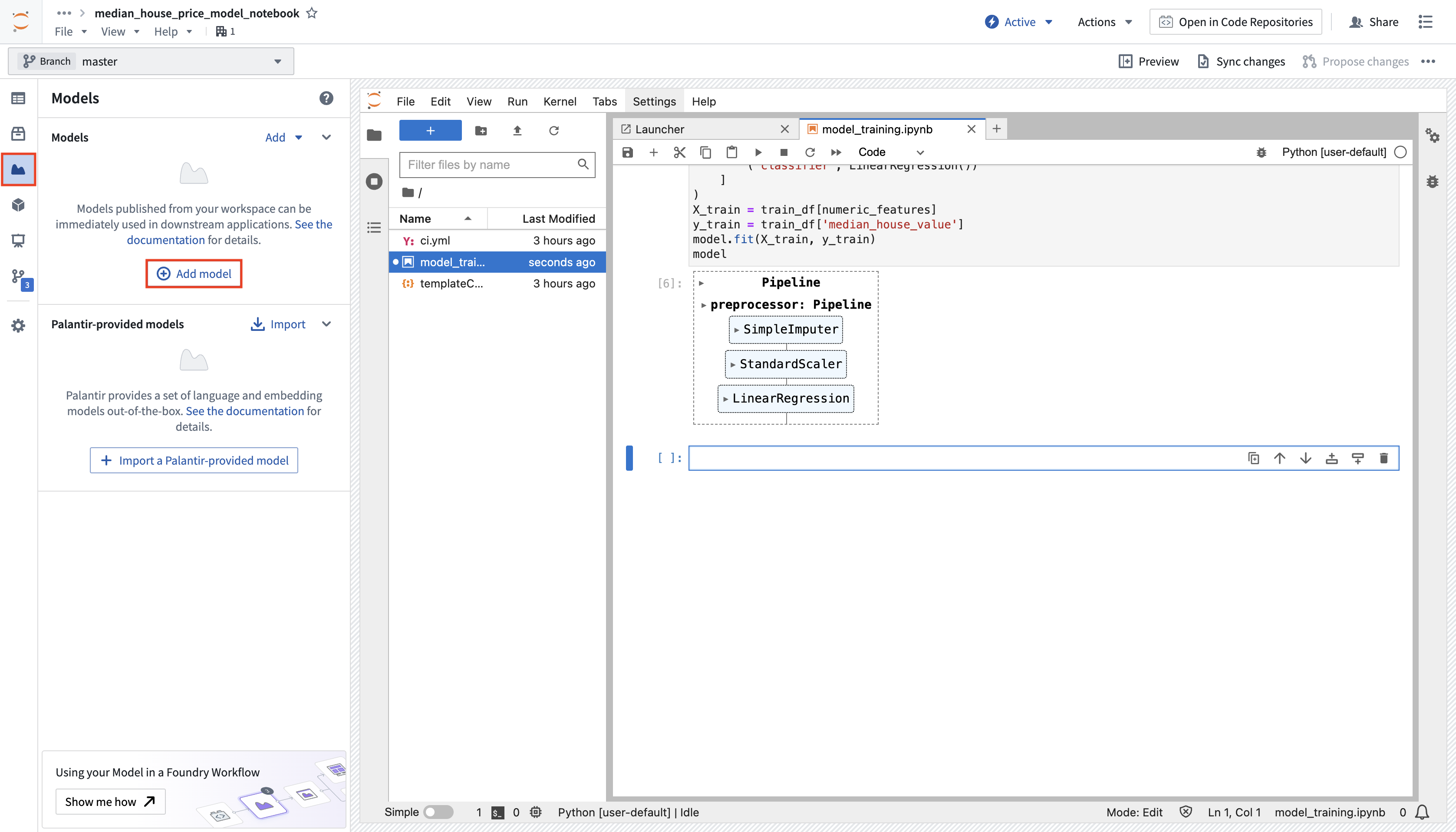
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34from sklearn.impute import SimpleImputer from sklearn.linear_model import LinearRegression from sklearn.pipeline import Pipeline from sklearn.preprocessing import StandardScaler # 数值特征列表 numeric_features = ['median_income', 'housing_median_age', 'total_rooms'] # 创建一个用于数值特征的转换流水线 numeric_transformer = Pipeline( steps=[ # 使用中位数填补缺失值 ("imputer", SimpleImputer(strategy="median")), # 标准化处理 ("scaler", StandardScaler()) ] ) # 创建一个完整的模型流水线 model = Pipeline( steps=[ # 预处理步骤,应用于数值特征 ("preprocessor", numeric_transformer), # 线性回归模型 ("classifier", LinearRegression()) ] ) # 提取训练数据中的特征和目标变量 X_train = training_dataframe[numeric_features] y_train = training_dataframe['median_house_value'] # 拟合模型 model.fit(X_train, y_train)
该代码构建了一个用于预测房价的模型流水线。首先,针对数值特征应用中位数填充缺失值和标准化处理。然后,在线性回归模型中进行训练。通过这种方式,可以轻松管理数据预处理和模型训练的步骤。
添加模型输出并实现模型适配器
要在 Code Workspaces 之外使用模型,必须向工作区添加一个新的模型输出。创建新的模型输出后,Code Workspaces 会在现有工作区中自动创建并存储一个新的 .py 文件,您可以使用该文件来实现模型适配器。模型适配器为 Foundry 中的所有模型提供标准接口,确保平台的生产应用可以在模型创建后立即使用。Foundry 基础设施将加载模型,配置其 Python 依赖项,公开其 API,并启用模型接口。
- 要添加输出,请在左侧边栏的 Packages 下打开 Models 标签,并选择 Add model > Create new model。为模型命名并将其保存到您选择的位置。
-
在您命名并保存模型后,系统会在工作区的左侧面板提示您发布新模型。完成步骤 1:安装
palantir_models,将代码片段复制到剪贴板,并在原始.ipynbnotebook 文件中运行。 -
成功安装
palantir_models后,进行步骤 2:开发您的模型适配器。模型适配器必须实现以下方法:save和load: 为了重用您的模型,您需要定义如何保存和加载模型。Palantir 提供了默认的序列化方法(保存),在更复杂的情况下,您可以实现自定义序列化逻辑。api: 定义模型的 API,并告知 Foundry 您的模型需要什么类型的输入数据。predict: 由 Foundry 调用以向模型提供数据。在这里,您可以将输入数据传递给模型并生成推断(预测)。
有关更多详细信息,请参阅模型适配器 API 参考。
下面的代码示例实现了上述函数,以开发使用 scikit-learn 的线性回归模型的适配器:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30import palantir_models as pm from palantir_models_serializers import DillSerializer class LinearRegressionModelAdapter(pm.ModelAdapter): # 使用自动序列化装饰器,将模型序列化为Dill格式 @pm.auto_serialize( model=DillSerializer() ) def __init__(self, model): self.model = model @classmethod def api(cls): # 定义输入和输出数据框的结构,包含列名和数据类型 columns = [ ('median_income', float), # 中位收入 ('housing_median_age', float), # 房屋中位年龄 ('total_rooms', float), # 房间总数 ] # 定义API输入输出格式,输出中增加了预测结果列 return {"df_in": pm.Pandas(columns)}, \ {"df_out": pm.Pandas(columns + [('prediction', float)])} def predict(self, df_in): # 根据输入数据框进行预测,并在数据框中添加预测结果列 df_in['prediction'] = self.model.predict( df_in[['median_income', 'housing_median_age', 'total_rooms']] ) return df_in
该代码定义了一个线性回归模型适配器类 LinearRegressionModelAdapter。它继承自 pm.ModelAdapter 并使用 DillSerializer 进行模型的序列化。适配器类提供了一个 api 方法来定义输入和输出的 Pandas 数据框格式,并包含一个 predict 方法用于预测输入数据中的目标值。
请参阅模型适配器文档以获取更多指导。
将模型发布到Foundry
要将模型发布到Foundry,请复制左侧边栏中步骤3:发布你的模型下所需发布模型的可用代码片段,将其粘贴到你的笔记本中并运行单元格。以下是使用上面编写的LinearRegressionModelAdapter发布线性回归模型的示例代码片段:
Copied!1 2 3 4 5 6 7 8 9 10 11from palantir_models.code_workspaces import ModelOutput # 模型适配器已在 linear_regression_model_adapter.py 文件中定义 from linear_regression_model_adapter import LinearRegressionModelAdapter # sklearn_model 是在另一个单元格中训练的模型 linear_regression_model_adapter = LinearRegressionModelAdapter(sklearn_model) # "linear_regression_model" 是此示例模型的别名 model_output = ModelOutput("linear_regression_model") model_output.publish(linear_regression_model_adapter)
代码片段应按原样工作,但需要正确地将您训练的模型传递给适配器初始化。代码准备好后,您可以运行单元格以将模型发布到Foundry。
使用模型
模型可以通过提交至建模目标来使用。模型可以提交到建模目标以进行:
模型也可以使用模型部署来使用,这代表了一种超出建模目标的替代模型托管系统。
Jupyter® 和 JupyterLab® 是 NumFOCUS 的商标或注册商标。
提及的所有第三方商标仍然是其各自所有者的财产。不表示任何附属关系或认可。