注意:以下翻译的准确性尚未经过验证。这是使用 AIP ↗ 从原始英文文本进行的机器翻译。
Foundry SAP 同步
应为每个要提取到 Foundry 的 SAP 对象(如表、视图等)创建一个新的同步配置。
数据连接文档包含有关如何创建新同步的逐步说明。
要配置 Palantir Foundry Connector 2.0 for SAP Applications 的同步:
-
配置标准设置,如同其他任何同步一样(名称、目标数据集和计划)。
-
将事务类型设置为追加以进行增量更新或快照以进行完整加载。有关增量更新的更多详细信息,请查看增量更新。
-
从以下选项中选择一个SAP 对象类型:
- ERP 表 – 用于标准 SAP ERP 表
- BW InfoProvider – 用于 BW InfoProvider(涵盖 InfoCubes、DataStore 对象、InfoObjects)
- BW BEx 查询 – 用于 BW BEx 查询
- SLT – 从 SAP Landscape Transformation Replication Server 提取数据
- BW 内容提取器 – 用于 ERP 业务内容提取器
- 函数 – 运行 BAPI 函数
- ERP 表数据模型 – 用于表之间关系的详细信息
- 远程 ERP 表 – 用于远程系统中的标准 SAP 表
- 远程 BW InfoProvider – 用于远程系统中的 BW InfoProvider
- 远程 BW BEx 查询 – 用于远程系统中的 BW BEx 查询
- 远程函数 – 在远程系统中运行 BAPI 函数
更多详细信息,请参阅SAP 对象类型。
-
如果您使用 SLT 或连接到远程系统,还需要选择一个上下文。有关上下文的更多详细信息,请参阅安装远程代理。
-
接下来,输入对象名称—一旦您开始在此字段中输入内容,系统将根据SAP 对象类型(以及上下文,如果使用)为您提供建议列表。
-
如果您正在配置增量更新,则需要提供一个增量字段。请查看下面有关此设置的部分以获取更多详细信息。
-
非必填,您可以通过点击附加选项标签来指定其他参数(请参阅下面的完整详细信息)。
有关使用 SLT 配置同步的完整详细信息,请参阅配置 SAP SLT。
增量类型
了解更多关于增量更新的信息。
筛选
筛选设置用于筛选从 SAP 提取的数据。
筛选语法中支持以下操作符:
- 逗号(
,)表示“或” - 分号(
;)表示“和” - 冒号(
:)表示“之间” - 等号(
=)表示“等于” - 感叹号和等号(
!=)表示“不等于” - 大于(
>)、大于或等于(>=)、小于(<)或小于或等于(<=)均受支持。
所有字段名称应与数据字典中的名称相同。
示例:
-
按价格在 500 和 650 之间
PRICE=500:650 -
按客户 A、B 或 C
CUSTOMER=A,B,C -
按价格在 500 和 650 之间且客户 A、B 或 C
PRICE=500:650;CUSTOMER=A,B,C -
按以
PAL、DIS和SAP开头的材料,使用以下带有通配符的筛选MATERIAL=PAL*,DIS*,SAP* -
按日期列大于或等于 09.08.2019
DATE>=20190809
请注意,SAP 数据库中的日期格式为 YYYYMMDD。
删除列
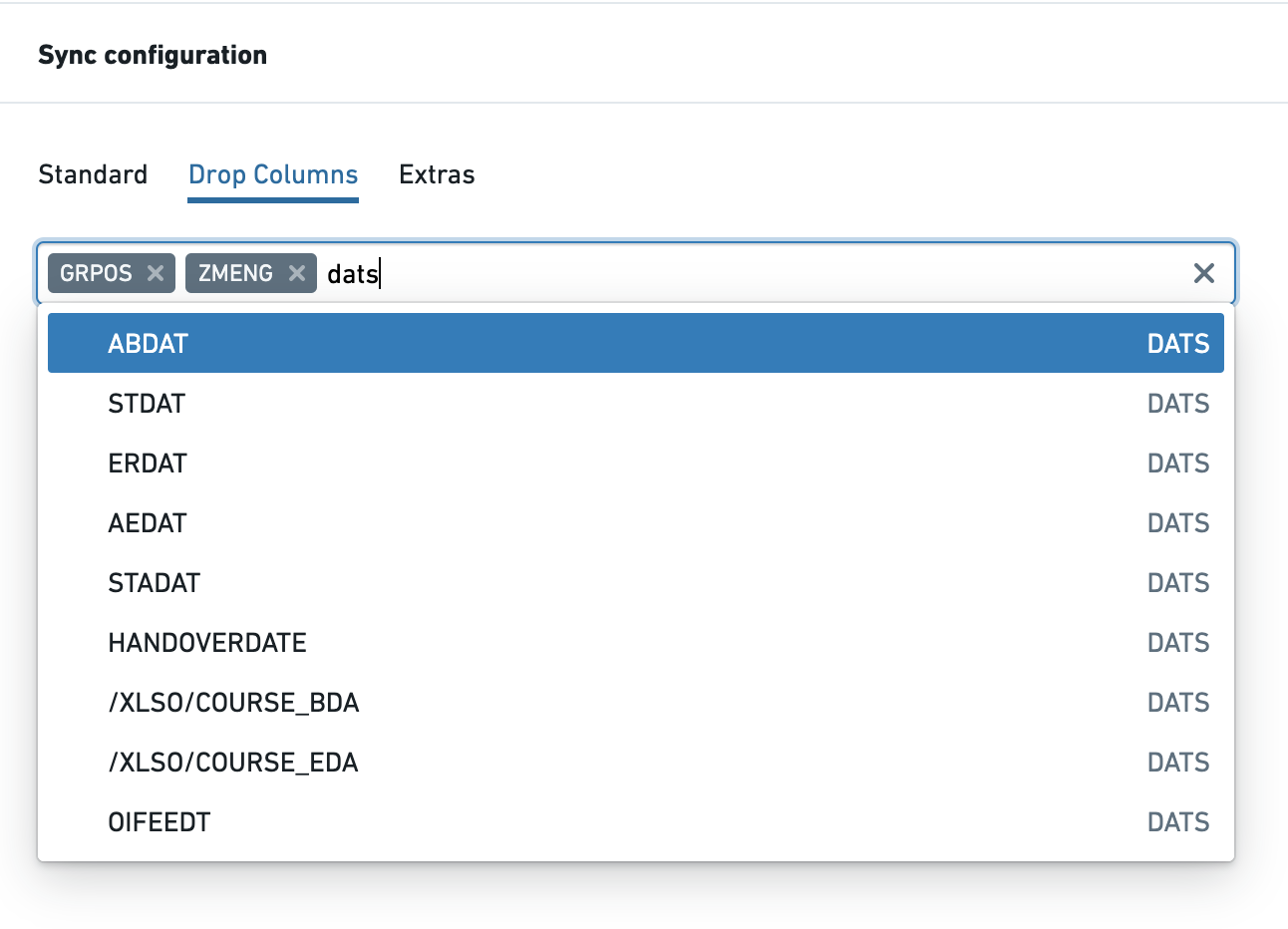
删除列仅支持表和远程表对象类型,允许您在从 SAP 提取数据之前删除列。给定表的模式中的所有字段都列在一个多选框中。您可以根据字段名称或类型进行搜索(如本例中显示的“dats”)。
如果您在 SAP 中有包含敏感数据的字段或想避免导入 Foundry 中不需要的数据,可以使用此功能。性能将比使用列掩码/哈希/加密功能好得多。
时间戳
当时间戳设置为开时,数据将包含一个显示数据何时被获取的时间戳和一个行序号。此信息可用于在需要时在管道后续步骤中去重 SAP 数据。
- 对于任何给定主键,
/PALANTIR/ROWNO的最大值对于/PALANTIR/TIMESTAMP的最大值保证是 SAP 中该记录的最新版本 /PALANTIR/TIMESTAMP列指示数据同步运行的时间(不是 SAP 系统中更新发生的时间)/PALANTIR/ROWNO列跟踪在给定数据同步中记录从 SAP 返回的顺序- 此值仅在使用 SLT 复制服务器进行基于触发器的变更数据捕获(CDC)或使用 CDPOS 或 CDHDR 增量模式时相关
- 在这些情况下,单个数据同步将包含自上次数据同步以来对记录进行的_所有_更改;
/PALANTIR/ROWNO的值越高,变更就越近期
参数名称
一个函数可以返回多个表。此参数用于确定选择哪个表并写入 Foundry 数据集。
深度
当 SAP 类型为数据模型时,此设置用于定义在查找表关系时要遵循的链接数量。设置为 1 仅限于一阶关系,2 为二阶关系,依此类推。
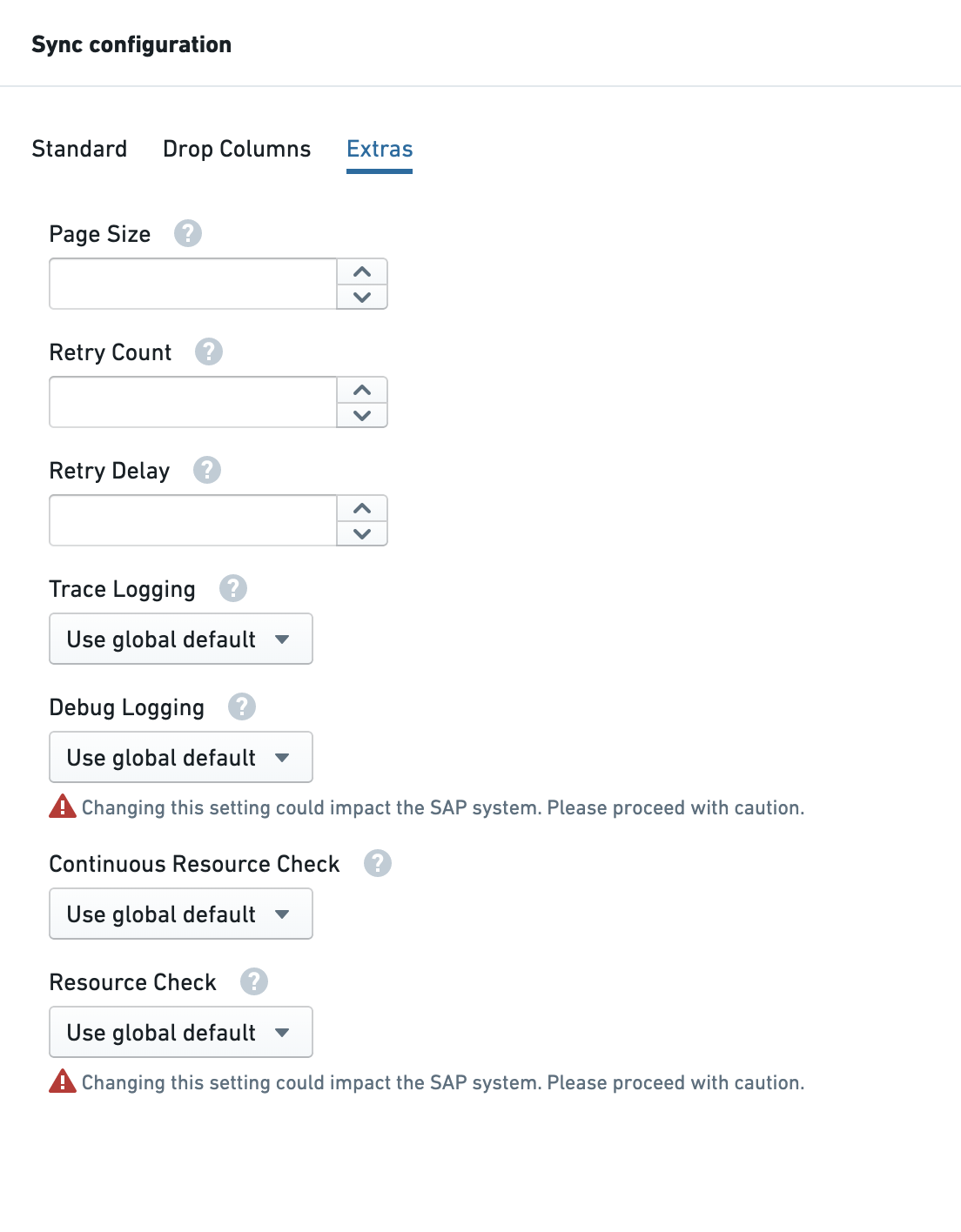
页大小
设置从 SAP 系统检索数据时每页返回的行数。请注意,此设置的系统默认值为 50,000 行,只有在更改高于该值时才会应用。如果您希望设置较低的系统默认值,则需要进行系统调用来实现。
重试次数
请求因资源短缺而失败时的重试次数。
重试延迟
两次重试尝试之间的延迟(以秒为单位)。
跟踪日志记录
设置为开以开启此同步的跟踪日志记录。
调试日志记录
开启调试日志记录将在 SAP 系统中启动一个后台进程,该进程将在同步期间运行,用于实时调试复杂问题。此过程可能会消耗资源并影响系统用户,因此请谨慎操作。
设置为开以开启此同步的调试日志记录。
连续资源检查
当设置为开时,所有分页请求都需要进行资源检查(内存、CPU 等);当设置为关时,只有初始页面请求需要进行资源检查。有关详细信息,请参阅性能参数。
资源检查
关闭资源检查设置会导致同步运行,而不考虑可用内存、CPU 和进程是否达到配置的阈值。这可能意味着同步对 SAP 系统施加过多负载,影响用户和其他进程。请谨慎操作。
设置为关以关闭此同步的所有资源检查(内存、CPU、进程)。有关详细信息,请参阅性能参数。
获取选项(仅限 SLT)
当获取选项设置为XML时,连接器将使用压缩数据获取从 SLT 获取数据。当设置为直接时,它将以字符串形式从 SLT 获取数据。XML 数据获取选项比直接方法更快。除非遇到与获取数据内容相关的错误,否则您应使用 XML 选项。
maxRowsPerSync(仅限 SLT)
设置后,连接器将返回每次从 Foundry 运行的同步大约 maxRowsPerSync (可能略高或略低)行数。这允许您将非常大表的初始同步(如果后续增量也包含许多行)划分为一系列较小的同步。如果间歇性问题导致长时间同步中断,这非常有用,因为您可以从最后一次成功同步恢复,而无需重新导入整个表。
要启用此设置,您需要从同步配置的基本视图切换到高级视图。
Copied!1maxRowsPerSync: 500000 # 每次同步的最大行数
BEx 设置 (仅限 BEx)
从 Connector 版本 SP22 和 Magritte 插件 0.11.0 开始,以下 BEx 查询参数启用 BEx 分页支持。
bexPaging: 打开 BEx 查询的分页(通过筛选支持)。SAP 附加组件会自动为每个页面生成单独的筛选。这意味着可以运行大型 BEx 查询而无需手动拆分同步。如果未设置此项,默认值(在 SAP 附加组件中定义)为 false。
bexMemberLimit: Connector 使用阈值来防止不必要的维度被用作筛选候选。如果一个 InfoObject 的发布值超过 bexMemberLimit,则被认为过于细化,并在生成筛选时被丢弃。如果未设置此项,默认值(在 SAP 附加组件中定义)为 200。该值不能低于 2。
要启用此设置,您需要从同步配置的基本视图切换到高级视图。
Copied!1 2 3bexSettings: bexPaging: true # 启用分页功能 bexMemberLimit: 10 # 每页的成员数量限制为10
忽略意外值
运行同步时,您可能会遇到以下形式的出错:
# 遇到SAP数据中的意外值
# 无法解析字段YYY中的值XXX
如果日期或数字值格式错误且无法解析,可能会发生这种情况。理想情况下,应该通过在源系统中更正问题来解决此问题;如果此解决方案不可行且您仍希望运行同步,可以忽略意外值。
要启用此设置,您需要从同步配置的基本视图切换到高级视图。(请注意,一旦添加此设置,您将无法返回到基本视图。)在高级视图中,将以下行添加到同步的YAML定义中:
Copied!1ignoreUnexpectedValues: true # 忽略意外的值
这将忽略日期和数字解析异常。无法解析的值将被设置为null,并在同步结束时记录警告,其中包含发现的解析异常的摘要。
配置每个 Parquet 文件的最大大小
在 Foundry 数据集中,每个 Parquet 文件的最大文件大小可以在源上定义,适用于所有同步,也可以在同步上定义,适用于特定同步。
如果您想更改 特定 同步的每个 Parquet 文件的最大大小,请使用 outputSettingsOverride 参数。
Copied!1 2 3 4 5outputSettingsOverride: maxFileSize: type: rows # 文件大小限制的单位为行数 rows: max: 10000 # 最大行数限制为10000行
Copied!1 2 3 4 5outputSettingsOverride: maxFileSize: type: bytes # 指定文件大小的单位为字节 bytes: approximateMax: 400MB # 设定文件大小的最大值为400MB
- 指定的最大字节大小只是一个近似值。生成的文件大小可能略小或略大。
- 如果指定最大字节大小,字节数需要至少是Parquet写入器内存缓冲区大小的两倍(默认值为128 MB)。