- Capabilities
- Getting started
- Architecture center
- Platform updates
Announcements
REMINDER: Sign up for the Foundry Newsletter to receive a summary of new products, features, and improvements across the platform directly to your inbox. For more information on how to subscribe, see the Foundry Newsletter and Product Feedback channels announcement.
Share your thoughts about these announcements in our Developer Community Forum ↗.
Ontology and AIP Observability: Monitoring is now enabled for functions and actions
Date published: 2025-10-24
Monitoring capabilities for functions and actions are now available, empowering you to proactively ensure the reliability of your critical workflows. Monitoring views can be used to track a wide range of resources across the platform and send notifications through multiple channels when alerts are triggered.
What's new?
Monitoring views now support two new monitor rule types for functions and actions:
- Duration p95 monitor: Get alerted when the 95th percentile (p95) of execution duration, calculated over a rolling window of recent data points, exceeds a configurable threshold.
- Failure count monitor: Receive alerts when the number of failures surpasses a configurable threshold within your set time window.
These new monitors can be customized to notify you through a variety of mechanisms so you are always aware when something unexpected occurs.
Why it matters
Running functions and actions in production requires trust that everything is operating as expected. Previously, teams had to rely on end users to report problems, often resulting in delays and potential missed issues. With these new monitoring capabilities, you can detect problems automatically, respond faster, and ensure your services are reliable before your users even notice.
Get started
To start monitoring your functions and actions, follow the steps below:
- Open the Data Health application.
- Navigate to the Monitoring views tab to search for or create a monitoring view.
- Select View details, then navigate to the Manage monitors tab.
- Select Add new alerts > Add monitoring rules.
- From the dropdown menu, choose Functions or Action types as as scope.
- In the dialog that appears, select the resources to monitor. Then choose Confirm selection in the bottom right corner.
- In the + Add monitoring rules dropdown menu, choose the Function duration 95 or Number of action failures in window rule.
- Review the summary and save.
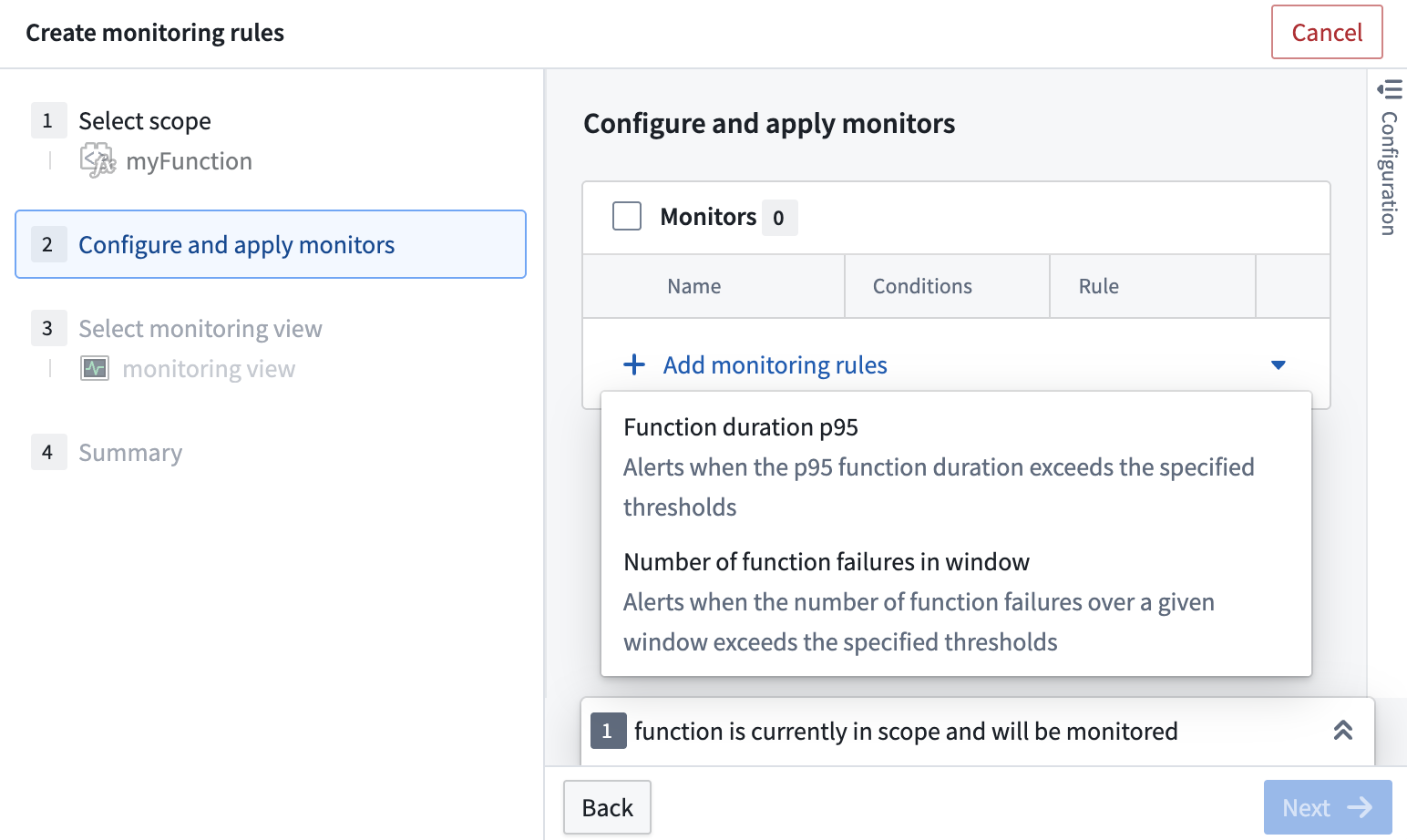
The monitoring rules dialog to configure a function monitor.
Share your feedback
Let us know what you think about our new monitoring capabilities for functions and actions. Contact our Palantir Support channels, or leave your feedback in our Developer Community ↗ using the data-health ↗ tag
Record workflows and automatically generate documentation with Flow Capture
Date published: 2025-10-23
Flow Capture, a new application that enables users to generate documentation from recorded Foundry workflows, will be available in beta the week of November 3. With Flow Capture, you can use LLMs to generate Markdown documentation using recorded or uploaded media as context. Flow Capture's tools include audio recording, on-click screen capture, built-in image editing tools, and prompt customization, allowing you to minimize the time spent creating documentation and efficiently increase documentation coverage.
Key features
Flow Capture tailors the documentation process to your needs with the following features:
- Record Foundry workflows with manually or automatically captured screenshots.
- Record and transcribe descriptive voice overs.
- Upload images or audio to provide additional context.
- Censor or edit images with built-in image editing tools.
- Structure generated documentation with provided templates, including general documentation, feature requests, and bug reports.
- Choose your preferred LLM model and customize prompts and context.
- Export generated documentation as a Walkthrough, Notepad document, ZIP file, or PDF.
Getting started
To get started with Flow Capture, navigate to the Flow Capture application and select + New Flow Capture. From here, you can choose a template and start recording the workflow you want to document. As you navigate your workflow, Flow Capture can take screenshots for every click in Foundry, or you can choose to manually capture screenshots with keyboard shortcuts.

Template options in the Flow Capture application.
After recording your workflow, you can review and edit captured screenshots, choose which assets will be provided to the LLM as context, and create a prompt.
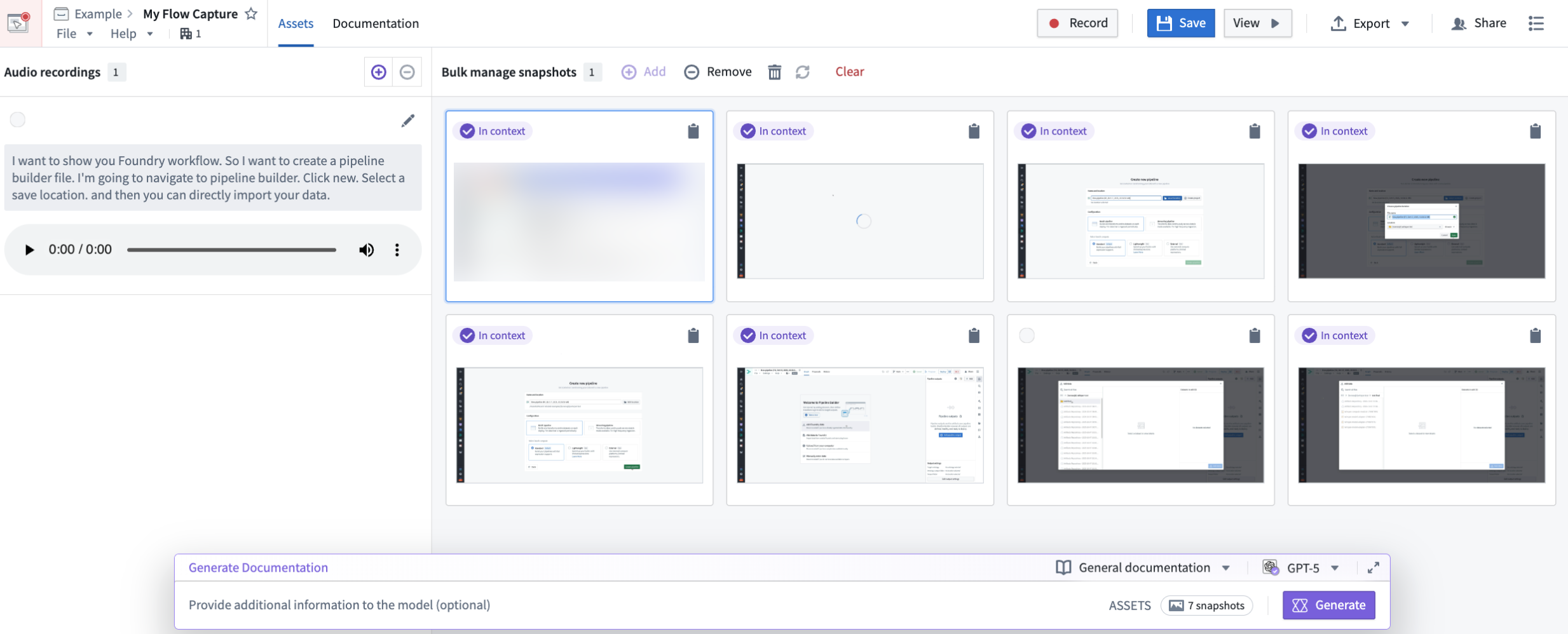
Edit mode in Flow Capture, displaying images added to context with a purple In context tag, and the prompt bar with model and template selectors at the bottom of the page.
You can then use LLM models to generate Markdown documentation based on the provided template, context, and prompt. Once your documentation is generated, you can manually edit or regenerate it with a different prompt if needed, and export it in various formats to facilitate integration with your training workflows.
Real-world impact
Flow Capture is transforming the way teams train and support users in Foundry by streamlining the process of creating, updating, and sharing resources. Flow Capture documentation can also be used as context for AI assistants, allowing you to support users without the time commitment of manual documentation and live support. Whether you are streamlining user onboarding or enriching AI support, Flow Capture can help you share deep, workflow-specific expertise across your organization.
Your feedback matters
As we continue to develop Flow Capture, we want to hear about your experiences and welcome your feedback. Share your thoughts with Palantir Support channels or our Developer Community ↗.
Learn more about Flow Capture.
Analyze restricted views in Jupyter® workspaces with a new restricted outputs mode
Date published: 2025-10-23
For the first time in the Palantir platform, you can now write and execute arbitrary code to analyze restricted views directly within your Jupyter® workspace, unlocking new possibilities for data exploration and advanced analytics on sensitive datasets. You can also publish interactive Dash and Streamlit dashboards based on restricted views that will display different data based on each user's distinct permissions.
How it works
Before today, Contour was the the only tool capable of interacting with restricted views in Foundry, the preferred format for applying differentiated, row-based access controls to sensitive data tabular data. Now, you can access, transform, and analyze them in Jupyter® workspaces with Python and publish custom dashboards with them.
Accessing a restricted view in a code workspace is similar to accessing a standard Foundry dataset. However, Code Workspaces requires you to enable restricted outputs mode, which prevents you from publishing datasets, models, telemetry logs, and other artifacts from the workspace. This ensures that you do not inadvertently take data from a restricted view and publish it in another form that bypasses the access controls.
When you publish an interactive application from a workspace, every user that accesses that application sees their own version of that application—application interfaces are not shared like a traditional website. As a result, the data that a user sees is based completely on their access controls.
Overall, this new feature aims to balance expressiveness and flexibility with security considerations to enable pro-code users to develop analytics and applications with even their most sensitive data.
Get started on using restricted views as inputs
Follow the documented instructions on using restricted views as inputs in a Jupyter® workspace. Select a restricted view to add to your workspace, install the necessary packages, and enable restricted outputs mode for your workspace. Toggling the restricted outputs mode requires a restart of your workspace and the setting persists until you toggle it off.
You may query restricted views in two ways: Either with the containers_sql Python library or a Jupyter® magic command, both of which use Spark SQL. Both options return data in the PyArrow format, which you can easily convert to a Pandas dataframe or another format for easy manipulation.
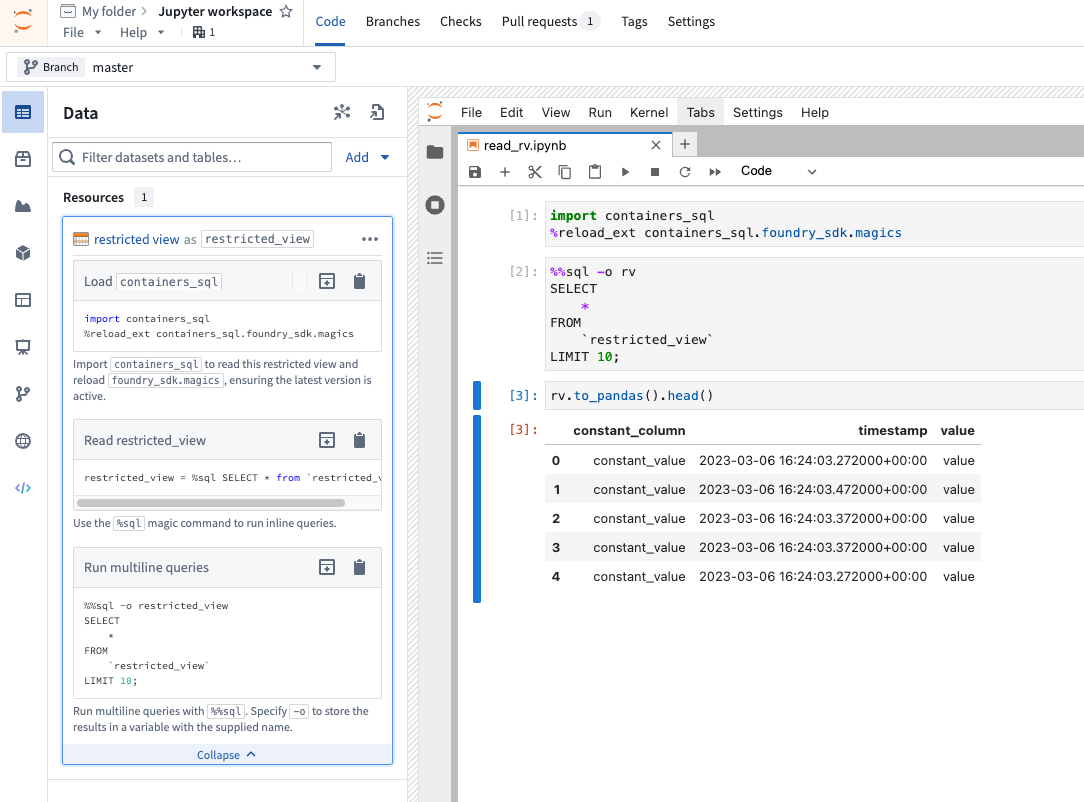
An overview of how to query a restricted view from a code workspace.
We want to hear from you
Share your feedback with us through Palantir Support or our Developer Community ↗ using the code-workspaces tag ↗.
--
Jupyter®, JupyterLab®, and the Jupyter® logos are trademarks or registered trademarks of NumFOCUS.
Enable side effects via actions on branches
Date published: 2025-10-23
Users now have more granular control on how side effects such as webhooks, notifications, and functions making external calls on actions behave on branches. For more information, review the side effects on branches documentation.
Webhooks
By default, if your action type has webhooks configured, the webhooks will not execute when the action is applied on a branch. In such cases, you will see a toast notification indicating this behavior.

Toast notification that shows that the webhook is not executed.
To override the default behavior, you can enable webhook executions on branches in the action type’s Security and submission criteria tab in Ontology Manager.
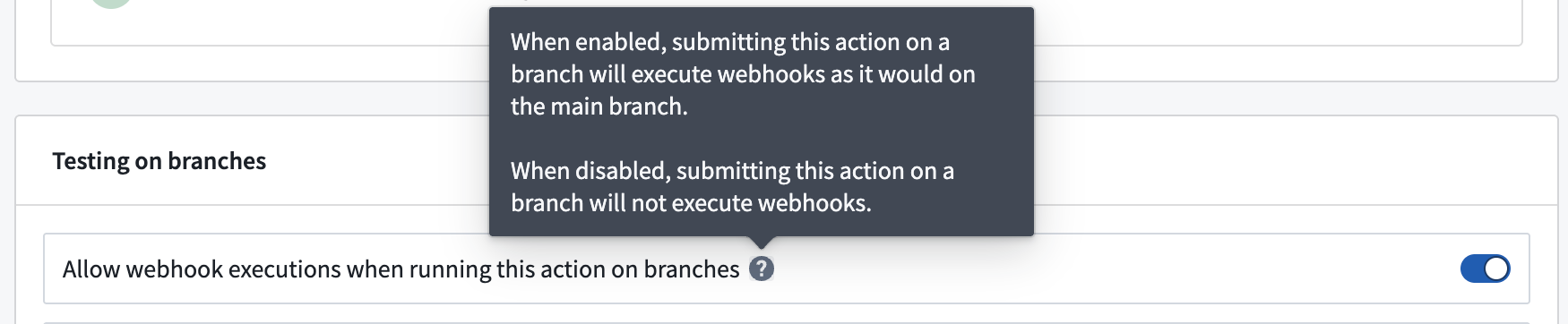
The toggle to allow webhook executions when running an action on a branch is available in the Security and submission criteria tab in Ontology Manager.
Functions with external calls
By default, if your action type is function-backed, and the function makes an external call, the action will fail entirely when executed on a branch. In such cases, you will see a failure toast notification, with an explanation of the behavior.
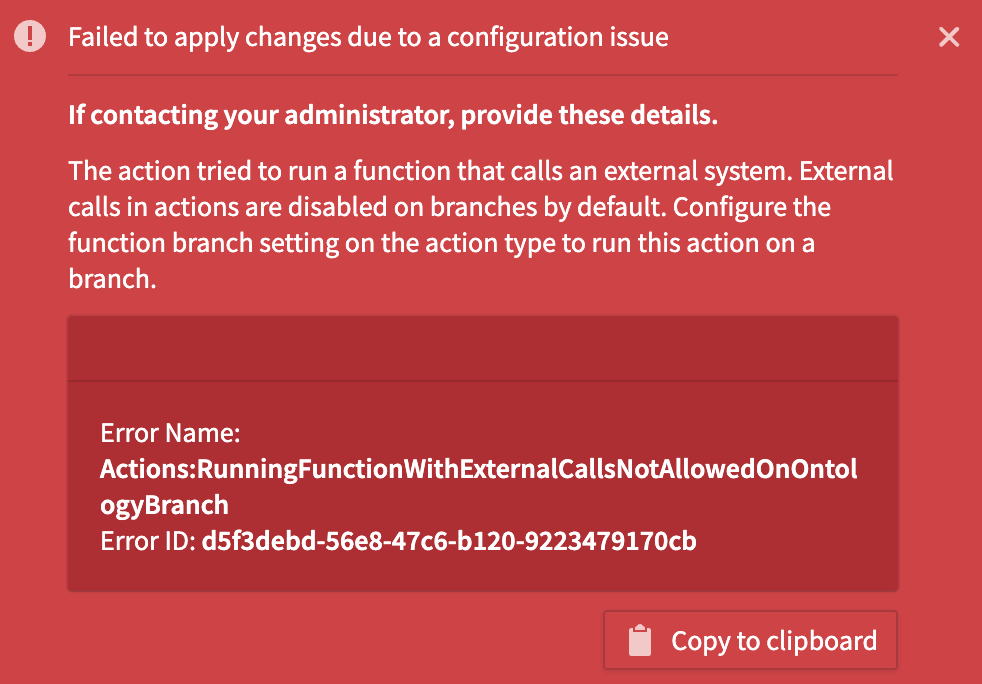
Failure toast for function-backed action executed on branch.
To override the default behavior, you can enable functions with external calls on branches in the Action type’s Security and submission criteria tab in Ontology Manager.

The toggle to allow functions with external calls when running an action on branches is available in the Security and submission criteria tab in Ontology Manager.
Notifications
By default, if your action type has notifications configured, the notifications will not be sent when the action is executed on a branch. In such cases, you will see a toast notification indicating this behavior.

Toast notification indicating the action is applied but notifications are not triggered.
To override the default behavior, you can enable notifications on branches in the Action type’s Security and submission criteria tab in Ontology Manager.
Additionally, you can specify the notification recipients when the action runs on a branch:
- Branch owner: Send all notifications to the branch owner.
- Default recipients: Notify the recipients configured on the original notifications.
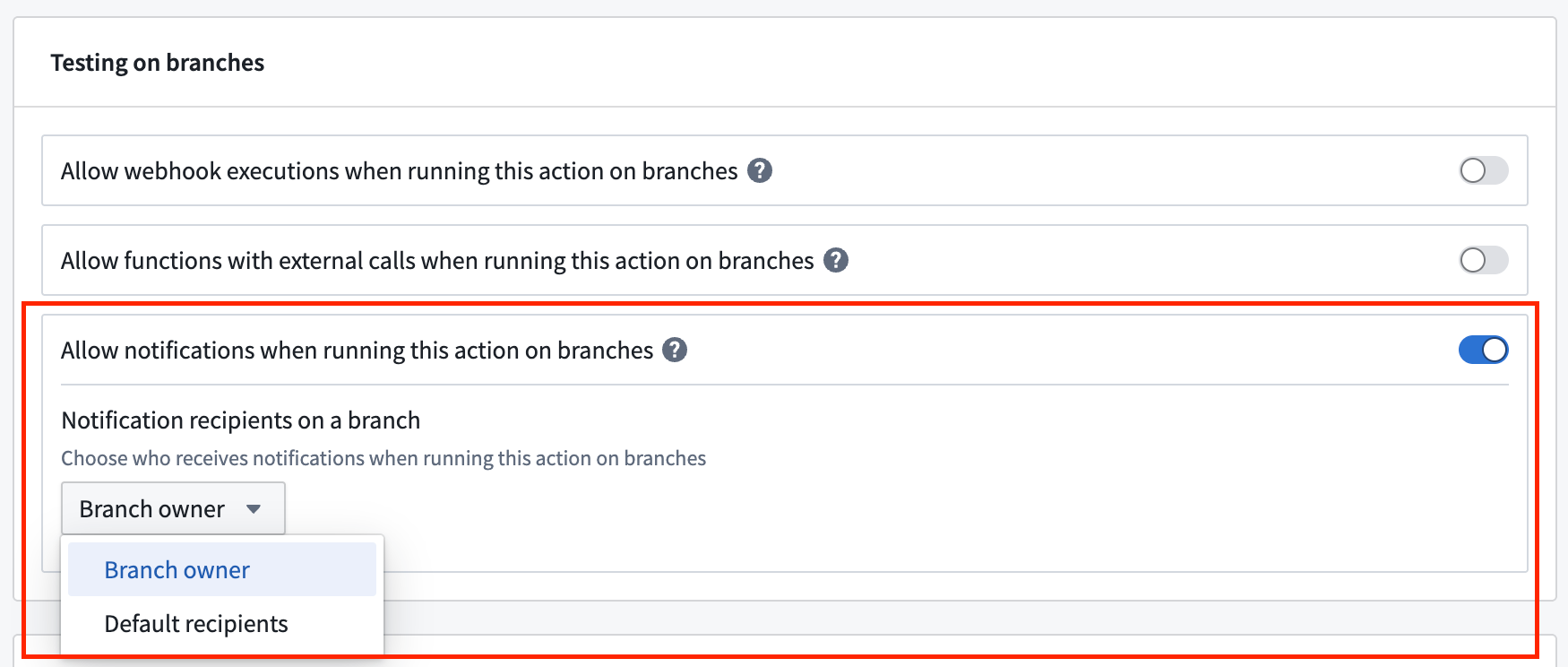
Configure the recipients on a branch when an action is run on a branch.
To understand the updates better, review the documentation.
We want to hear from you
As we continue to develop new features for Foundry Branching, we want to hear about your experiences and welcome your feedback. Share your thoughts with Palantir Support channels or our Developer Community ↗ and use the foundry-branching ↗ tag.
Vibe coding with Ontology SDK using Palantir MCP
Date published: 2025-10-23
Palantir MCP now offers a set of tools that enable you to work with the Ontology SDK directly from your IDE. This enhancement brings SDK management capabilities to your development environment, allowing you to add and remove resources, generate new versions, and install them without context switching. Additionally, we have upgraded the OSDK context tool to include the latest language capabilities, making your AI-assisted development workflow even more productive.
New tools in Palantir MCP
view-osdk-definition tool: Provide instant access to detailed information about your Ontology SDK definition, including SDK name and version, object types with their properties, link types with relationships, action types with parameters, and function definitions with input/output specifications. Use this tool when you need to understand the structure and content of the SDK in your application or get a comprehensive view of all available resources.
Try it out with a prompt like: "Can you describe the content of the Ontology SDK connected to this repo?"
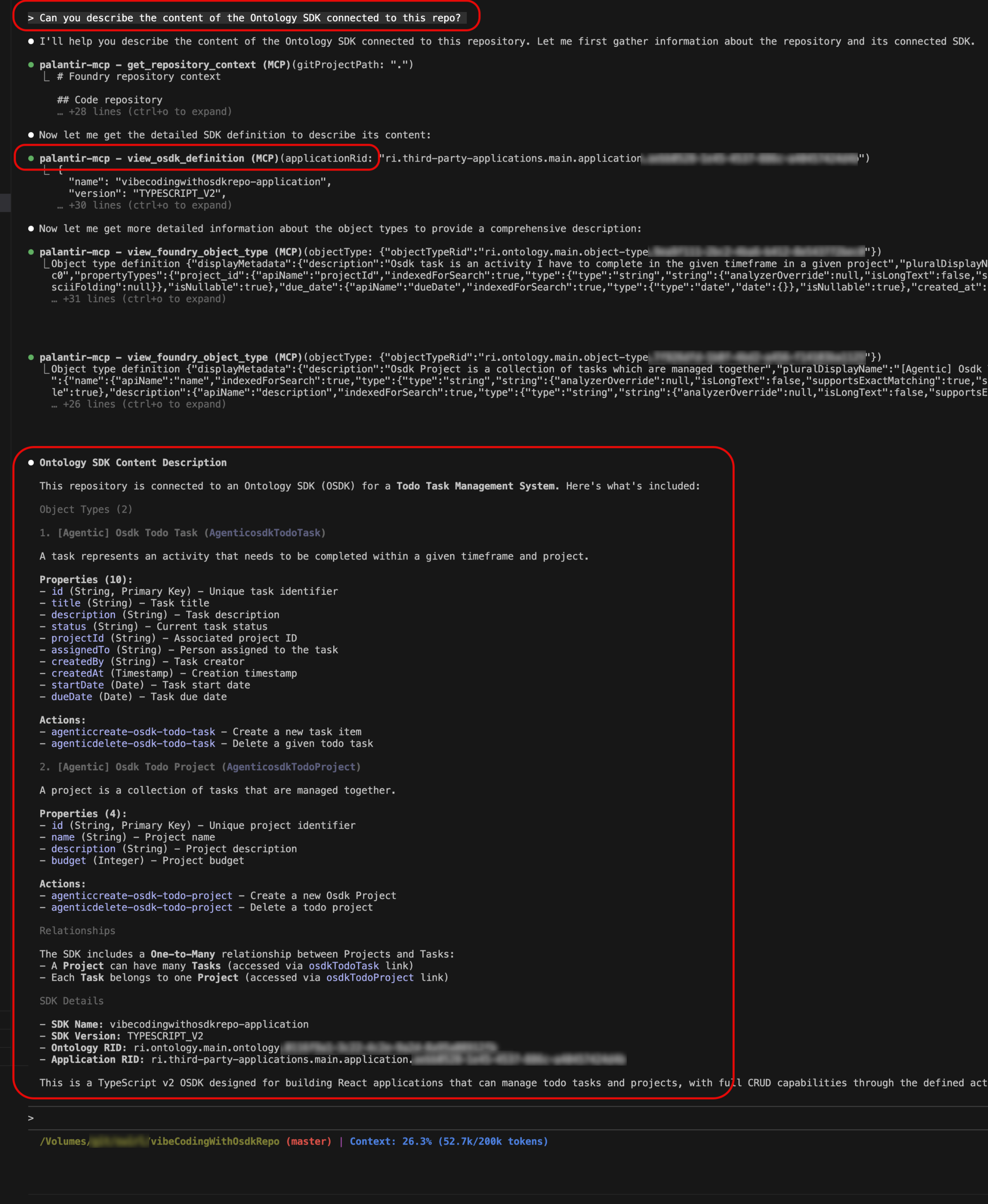
The view-osdk-definition tool displaying SDK structure with object types, properties, and relationships in the IDE.
generate-sdk-version tool: Streamline the process of creating new SDK versions. Whether you are adding new resources to your SDK, removing outdated ones, or updating existing definitions, this tool handles version generation directly from your development environment. Simply describe the changes you want to make, and the tool will generate a new version of your Ontology SDK automatically.
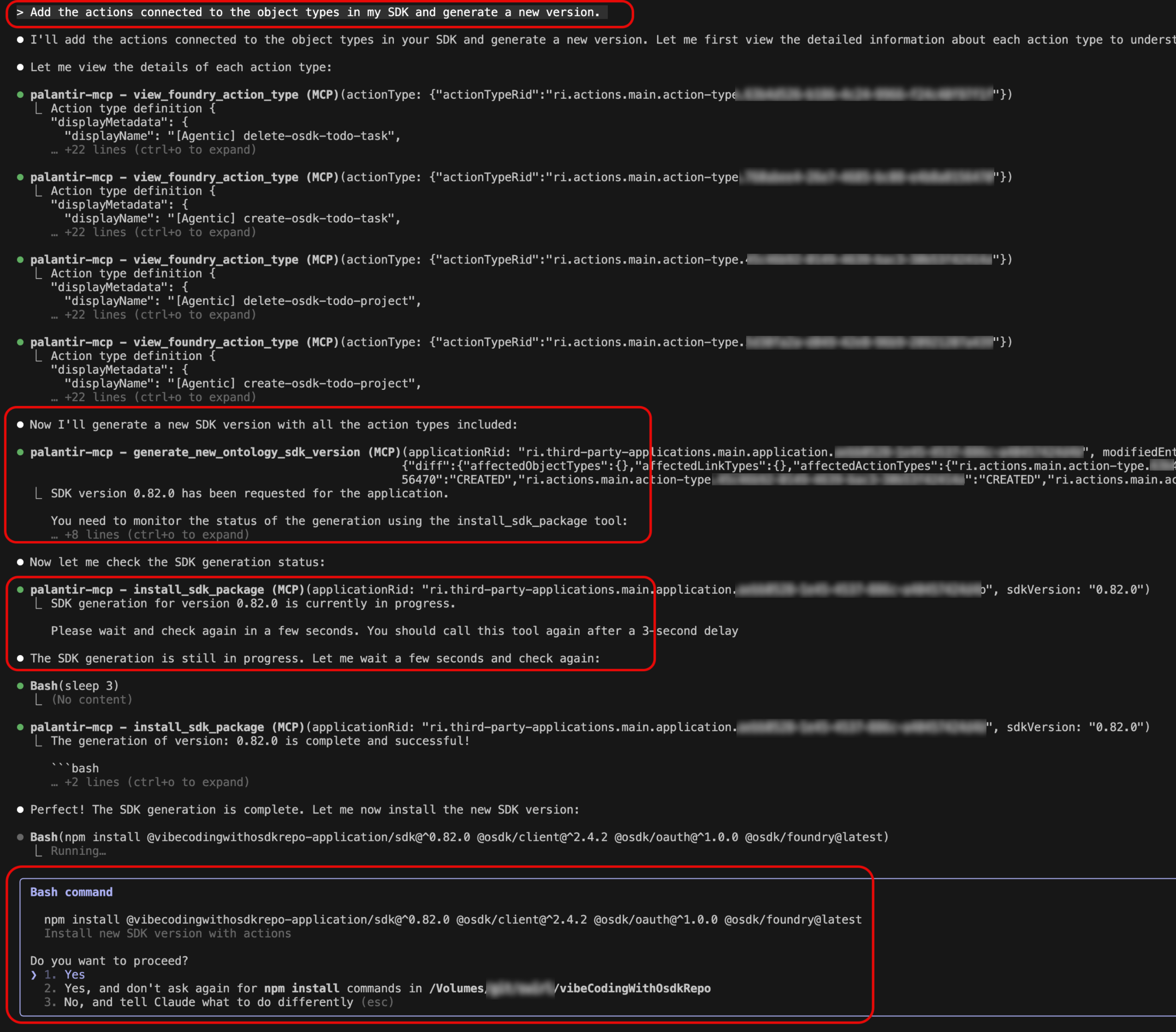
Try it out using a prompt: "Add the actions connected to the object types in my SDK and generate a new version."
Repository connection tool: Connect existing TypeScript repositories to Developer Console applications, making it easy to back your existing applications with Foundry Ontology. When you interact with a repository that is not currently connected to a Developer Console application, the tool intelligently detects this and suggests establishing the connection.
Try this out on any of your TypeScript repositories using the prompt: "Describe the Ontology SDK connected to this repo."
The tool will detect that the repository is not currently connected and will guide you through the connection process.
Enhanced OSDK context
Beyond the above new tools, we have upgraded the OSDK context capabilities within Palantir MCP. The context tool now supports the newest language features and capabilities, ensuring that AI-assisted coding suggestions are aware of the full scope of what is possible with your Ontology SDK.
You can now ask the agent to code OSDK queries using any of the features available in OSDK, including attachments, media sets, derived properties, and aggregations. This means more accurate code generation, better completions, and smarter suggestions that align with the latest SDK patterns and best practices.
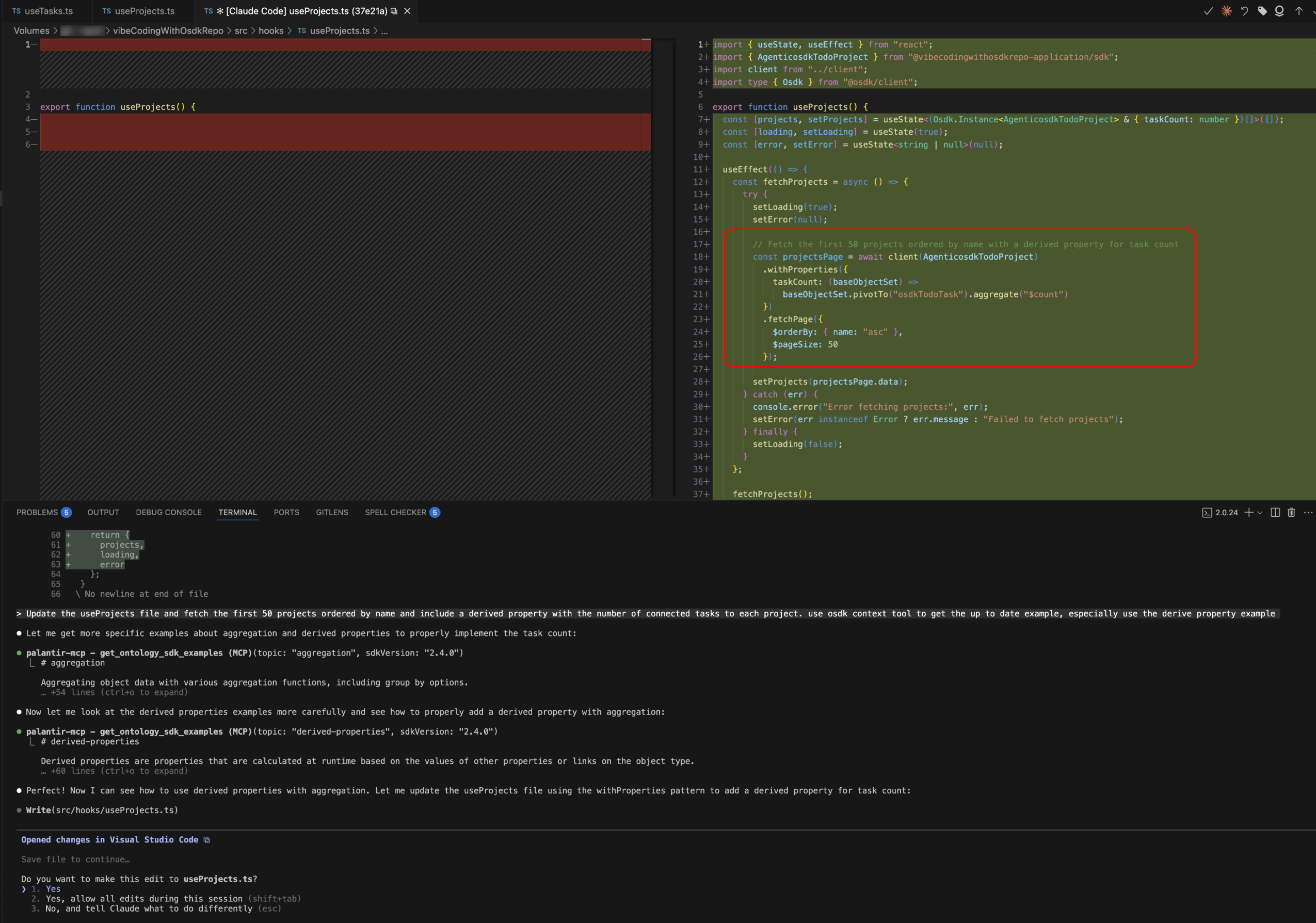
Try this out using the prompt: "Update the useProjects file and fetch the first 50 projects ordered by name and include a derived property with the number of connected tasks to each project."
This example prompt above works on the To Do application example and demonstrates how the enhanced context enables sophisticated query generation with advanced OSDK features.
Platform SDK code generation
Palantir MCP also supports Platform SDK code generation. The Foundry Platform SDK provides APIs that can be used in your OSDK repository to interact with a wide range of Foundry products. You can use this tool to list all the API endpoints available for a given product, making it easy to discover and integrate platform capabilities directly into your application.
These products include AIP Agents (interactive assistants built in AIP Agent Studio equipped with enterprise-specific information and tools), Media sets (representations of media data in Foundry), Ontologies (categorizations of data into real-world concepts with object types, properties, link types, and action types), Admin (managing users, groups, markings and organizations), Connectivity (managing external system connections and APIs), Datasets (representations of data in Foundry), Filesystem (managing filesystem resources, folders, and projects), Orchestration (managing Builds, Jobs and Schedules), SQL Queries (managing SQL queries executed in Foundry), and Streams (real-time operational data analysis and processing with second-level latency).
Getting started
These tools are available now through Palantir MCP in your IDE.
You can review the following documentation:
- Installation instructions
- Palantir MCP overview page and Ontology SDK guide for detailed usage examples
Claude Haiku 4.5 now available in AIP
Date published: 2025-10-21
Claude Haiku 4.5 is now available from Anthropic Direct, Amazon Bedrock, and Google Vertex AI for non-georestricted enrollments, all US enrollments, and all EU enrollments.
Model overview
Claude Haiku 4.5 is a hybrid reasoning model that balances performance with speed and cost. Comparisons between Claude Haiku 4.5 and other models in the Anthropic model family can be found in the Anthropic documentation ↗.
- Context Window: 200,000 tokens
- Modalities: Text and image input | Text output
- Capabilities: Extended thinking, Function calling
Getting started
To use these models:
- Confirm your enrollment administrator has enabled relevant model family or families
- Review token costs and pricing
- See the complete list of all the models available in AIP
Your feedback matters
We want to hear about your experiences using language models in the Palantir platform and welcome your feedback. Share your thoughts with Palantir Support channels or on our Developer Community ↗ using the language-model-service tag ↗.
New audio transcription capabilities in Workshop and Pipeline Builder
Date published: 2025-10-21
The Audio and Transcription Display widget is now available in Workshop for visualizing and interacting with audio files and transcription segments. Additionally, the Transcribe audio transform in Pipeline Builder now supports speaker diarization, enabling automatic speaker identification within audio files when using the More performant mode with Speaker recognition enabled.
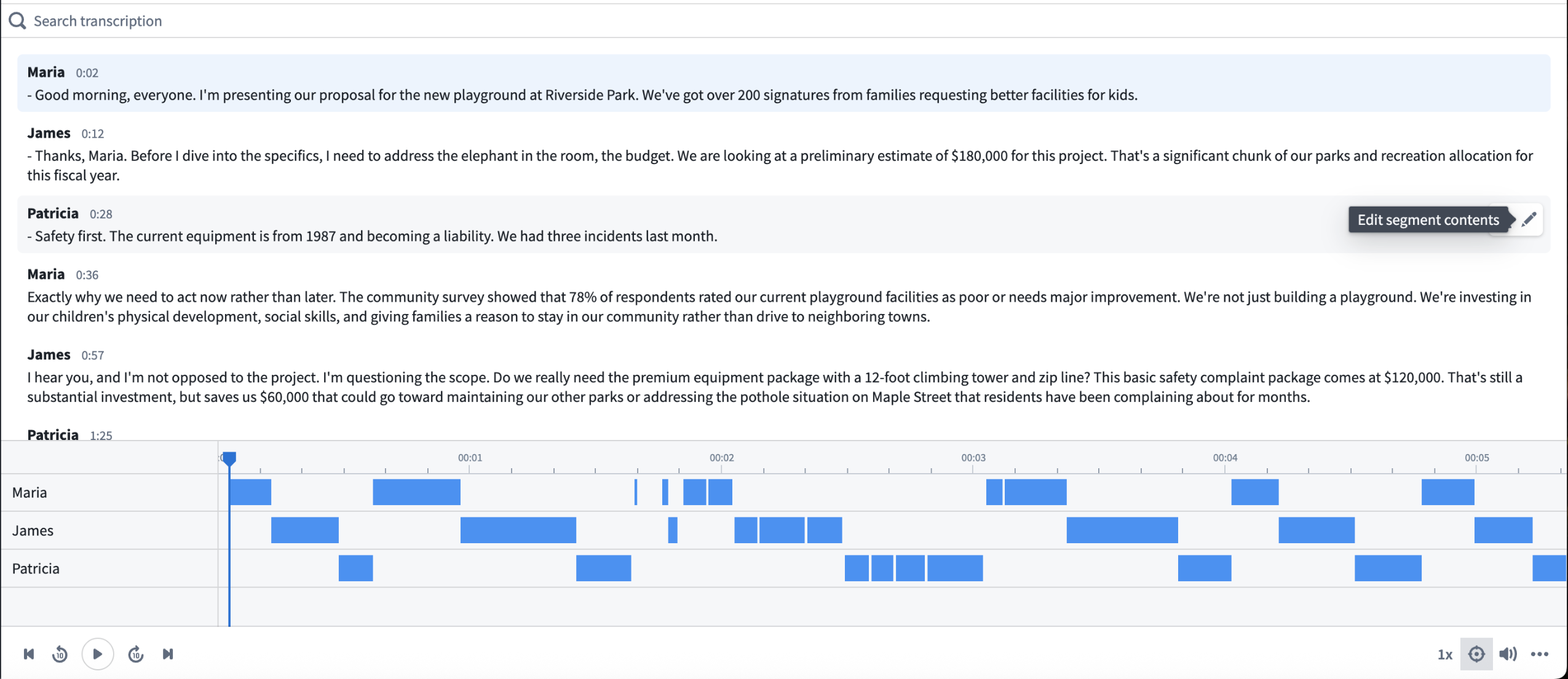
A sample configuration of the Audio and Transcription Display widget in Workshop.
Widget capabilities
The widget accepts an object set containing transcription segment objects with the following properties:
- Transcription contents (string)
- Beginning and end timestamps (milliseconds)
- Speaker ID (string, optional)
Features
- Synchronized playback: View audio waveform visualization with timestamp-aligned transcription scrolling.
- Speaker diarization display: Toggle between Player and Gantt chart visualization formats.
- Search: Access full-text search across transcription segments.
- Custom actions: Configure action types on segment objects (for example, edit speaker names, correct timestamps, and modify segment contents) that appear in a toolbar on segment hover. Use the Selected segment variable to reference the hovered segment in action parameters.
- Seek to timestamp: Optionally configure numeric variable input to programmatically seek audio to specific timestamps.
Pipeline Builder enhancement
The Transcribe audio transform now supports speaker diarization in More performant mode. Enable Speaker recognition to output speaker IDs for each transcription segment. The transform outputs segment details including:
- Segment ID
- Begin and end timestamps
- Transcription contents
- Speaker ID (when speaker recognition is enabled)
Use the Explode array and Extract struct fields transforms to process the segment array output for ontologization into segment objects compatible with the widget. For a step-by-step guide, review our documentation on creating an interactive audio transcription application.
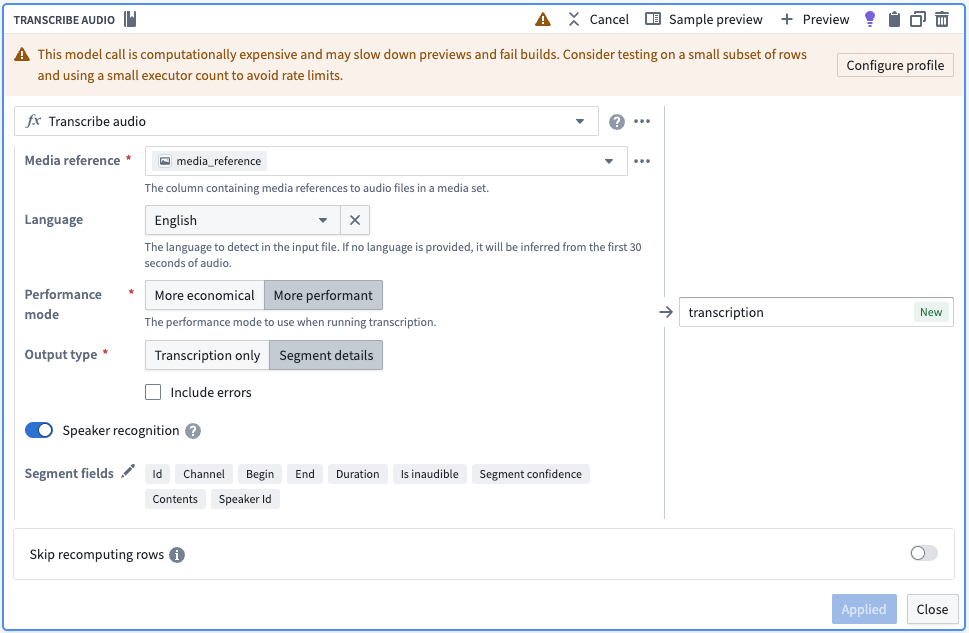
The Transcribe audio transform board in Pipeline Builder, with options selected to output diarization results with transcription.
Your feedback matters
We want to hear about your experience and welcome your feedback as we develop the media set experience for working with audio. Share your thoughts with Palantir Support channels or on our Developer Community ↗ using the media-sets tag ↗ .
Faster builds in Pipeline Builder with the warm pool compute profile
Date published: 2025-10-21
The warm pool compute profile option, now available on all enrollments, is a powerful new type of compute profile designed to speed up your builds in Pipeline Builder.
Warm pool leverages an auto-scaling pool of continuously running virtual machines, reducing job startup latency. With warm pool enabled, your jobs can start processing instantly without waiting for machines to spin up.
- Up to three jobs run concurrently on each virtual machine, sharing resources efficiently.
- Ideal for smaller builds: Ideal for workloads that complete within 30 minutes on an extra small profile.
You can enable warm pool by toggling on Warm pool in the compute profile dialog.
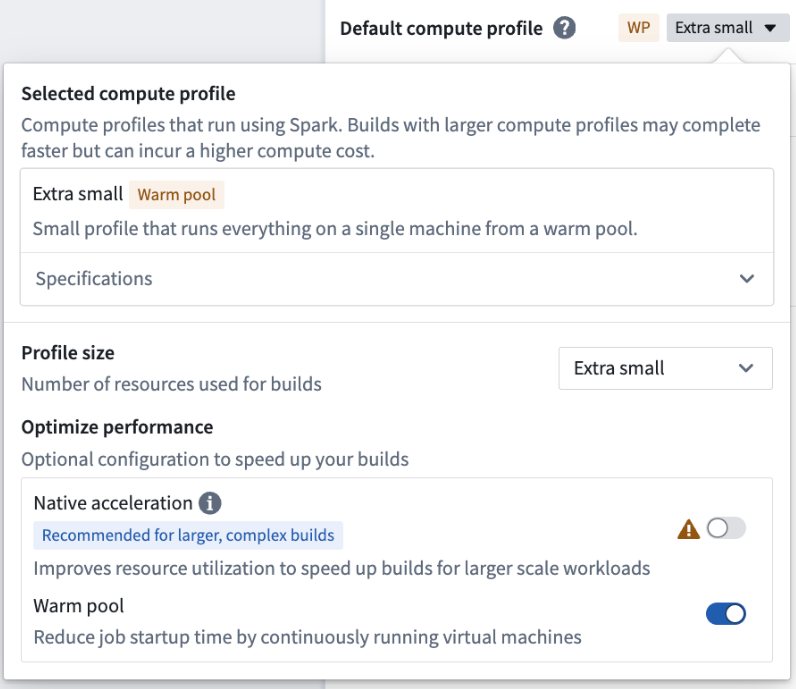
Example of the compute profile dialog with the Warm pool option enabled.
Warm pool is currently supported only for extra small profiles. Larger profiles are not yet supported.
Start using warm pool today and experience faster build times. See the warm pool documentation for more information.
Foundry Connector 2.0 for SAP Applications v2.35.0 (SP35) is now available
Date published: 2025-10-21
Version 2.35.0 (SP32) of the Foundry Connector 2.0 for SAP Applications add-on, used to connect Foundry to SAP systems, is now available for download from within the Palantir platform.
This new major version includes in particular:
- A new version of the Foundry SAP Cockpit providing more functionality to monitor and manage the Foundry SAP Connector. This is accessible via the
/n/palantir/cockpitv2transaction code. HINTkeyword support on SAP HANA databases to allow reading from a secondary database. UseSM30to maintain table/PALANTIR/CFG_05to enable this.- Improved
STXLlong text decompression.
Latest add-on is now available in Data Connection
On top of those improvements, the add-on itself and its release notes can now be downloaded directly from your SAP source configuration in Foundry in a dedicated Download packages section.
To access it, navigate to an existing SAP source, select Connection settings > Download packages. Download the file(s) corresponding to the NetWeaver version of the SAP system to which you are connecting.
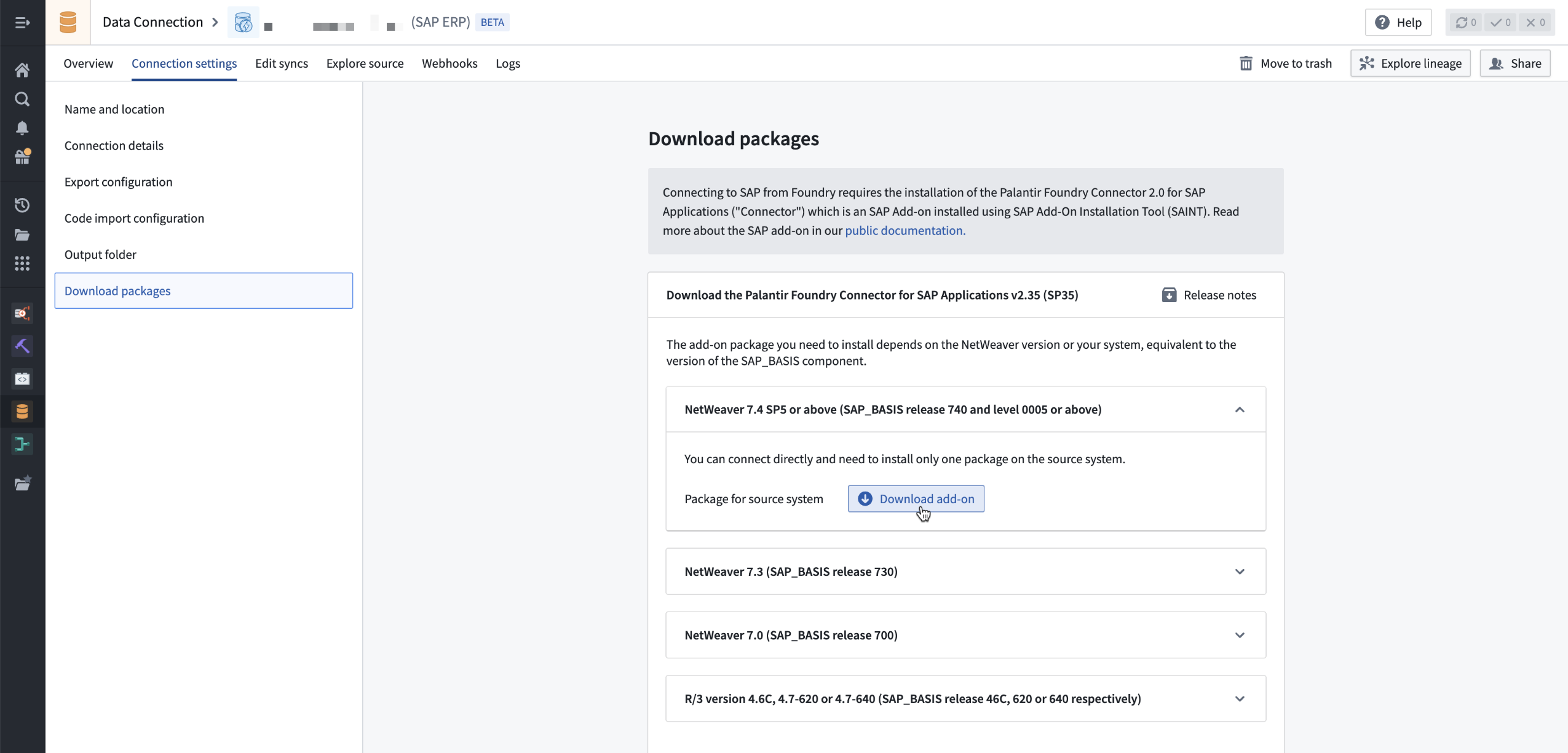
Navigate to an existing SAP source, select Connection settings > Download packages > Download add-on.
Foundry SAP sources connected to an SAP system that does not use the latest SAP add-on will now display a banner flagging that a new version is available.

Banner shown if the SAP system does not use the latest SAP add-on.
We want to hear from you
As we continue to develop support in our platform for connectivity, we want to hear about your experiences and welcome your feedback. Share your thoughts with Palantir Support channels or our Developer Community ↗ and use the data-connection ↗ tag.
Faster, more reliable VS Code previews for lightweight Python transforms
Date published: 2025-10-21
VS Code previews for lightweight Python transforms are now powered by a new, unified architecture, aligning builds and previews for a smoother and more consistent experience. This architectural change eliminates entire classes of schema-related errors and edge cases and delivers significantly faster preview performance.
Technical changes
- Unified execution engine: Previews now use the same code path as builds, eliminating schema drift and environment-specific bugs.
- Performance improvement: Preview execution is up to 10x faster, particularly for Foundry Views.
- Removed PySpark dependency: Code Repository previews no longer require PySpark initialization, reducing startup overhead and eliminating PySpark-specific errors in preview environments.
- Feature parity: New lightweight transform capabilities are now immediately available in previews without requiring separate preview implementation.
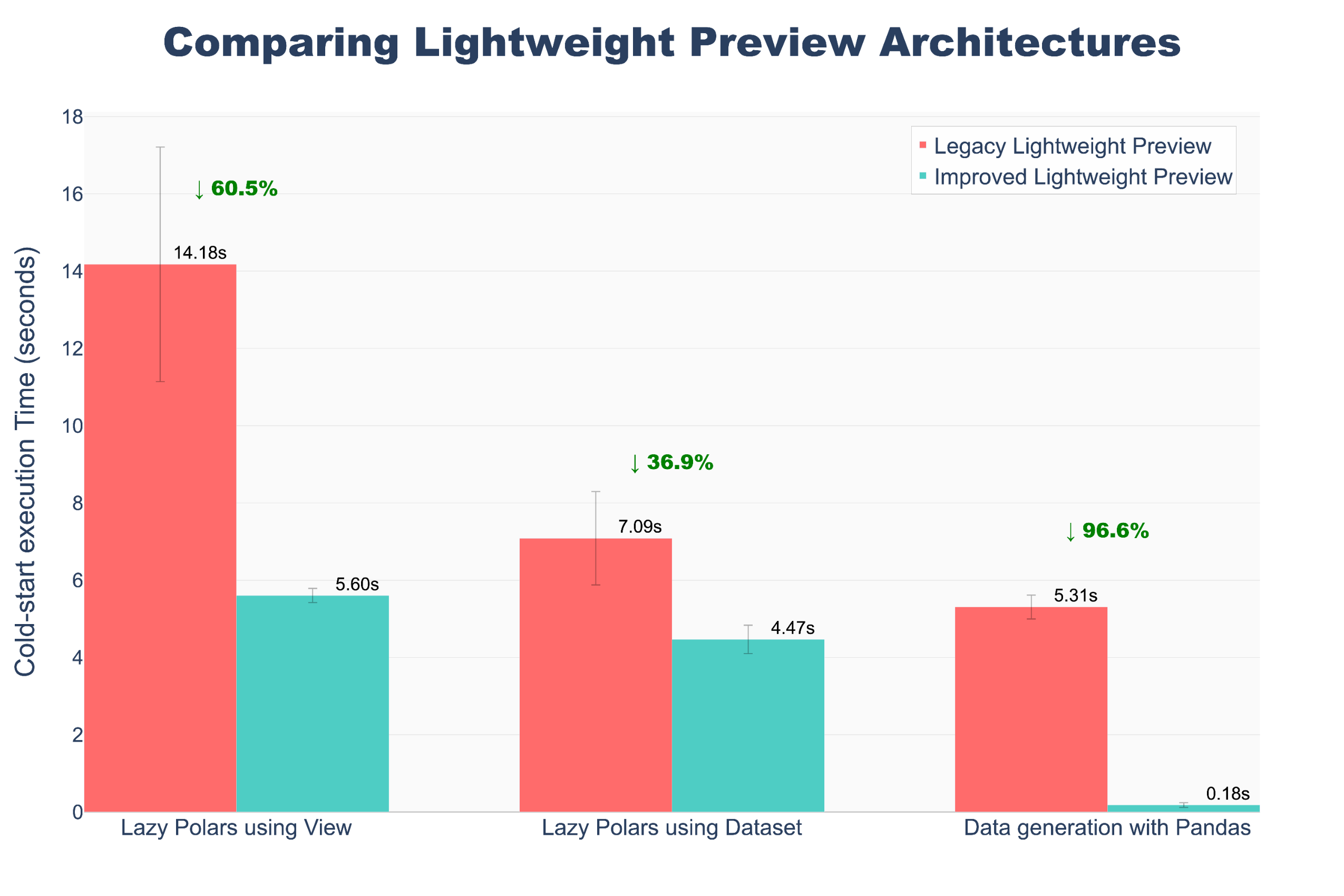
A chart comparing lightweight preview architecture, showing execution up to 10x faster in our updated model.
Learn more about VS Code transform previews in our documentation.
What this means
Schema inconsistencies between preview and build environments are eliminated. Edge cases that previously only manifested during builds (or only during previews) no longer occur. Preview results now accurately reflect build behavior.
Share your feedback
We want to hear about your experience using lightweight Python transforms. Let us know in our Palantir Support channels, or leave a post in our Developer Community ↗ using the transforms-python ↗ tag.
New Media Set Transformation API in Python transforms
Date published: 2025-10-16
A new media set transformation API is now available in Python transforms across all enrollments. This API enables users to perform both media and tabular transformations on media sets, with the ability to output both media sets and datasets. Previously, users needed to construct complex requests to interact with media set transformations. Now, the API provides comprehensive methods for all supported transformations across different media set schema types.
With this new API, users no longer need to write custom logic for tasks such as iterating over pages in document media sets or implementing parallel processing. Transformations can be applied to entire media sets or individual media items. Additionally, the API supports chaining transformations for media-to-media workflows. For example, you can slice a document media set and then convert the resulting pages to images in a single line.
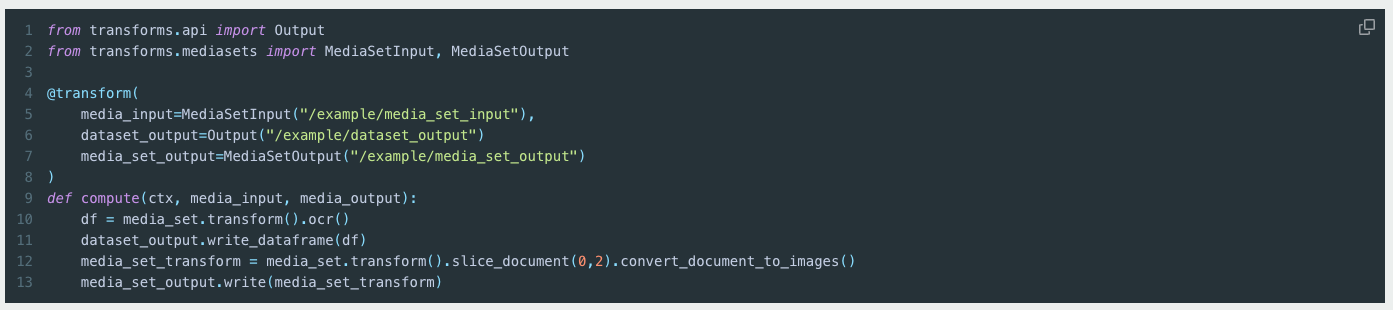
Code example using the new API.
Your feedback matters
We want to hear about your experience and welcome your feedback as we develop the media set experience in Python transforms. Share your thoughts with Palantir Support channels or on our Developer Community using the media-sets tag.
Remove inherited organization markings from inputs in Pipeline Builder
Date published: 2025-10-16
In Pipeline Builder, you can now remove inherited organizations from outputs, in addition to markings. Note that this removal will only apply to current organizations - future organization changes will not be automatically removed, and data access continues to rely on project-level organizations.
Remove inherited organizations
Previously, you could only remove inherited markings from outputs. Now, with the right permissions, you can also remove inherited organizations at an input level directly in Pipeline Builder. Note that data access continue to rely on project-level organizations and any future organization changes will not be automatically removed.
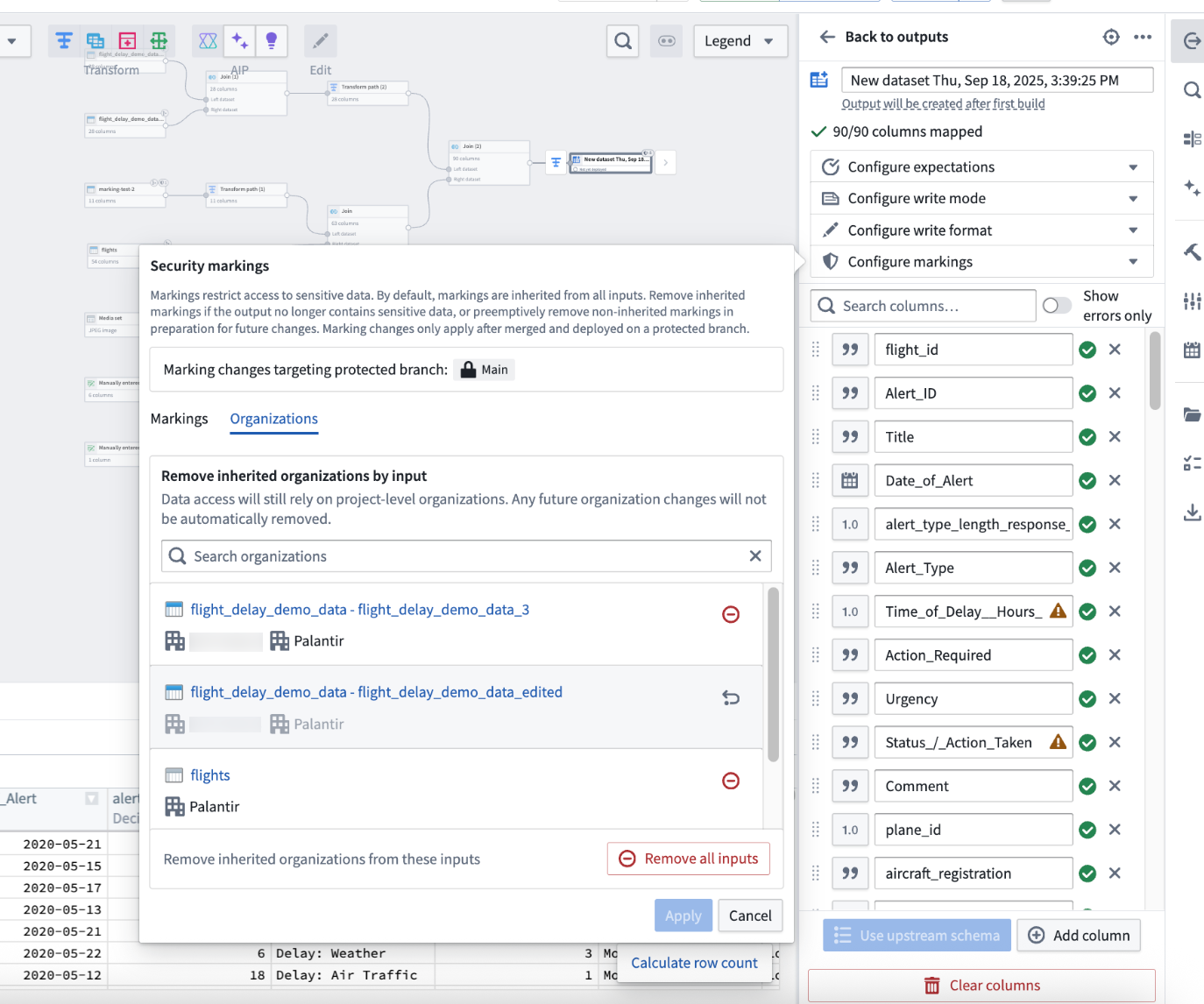
Use the Remove all inputs option or remove inputs one by one to remove inherited organizations from a set of inputs.
To do this, first protect your main branch, and make a branch off of that protected branch. Then, navigate to Pipeline outputs on the right side of your screen and select Edit on the output.
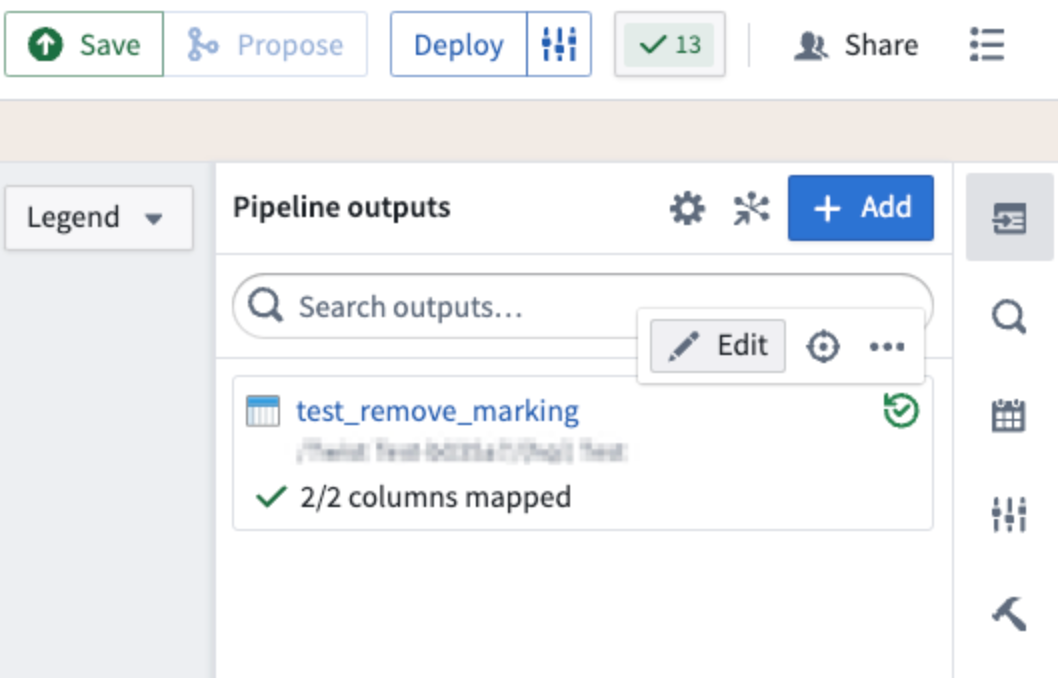
Select Edit on the output on which you would like to remove inherited markings and organizations.
After going to your output, select Configure Markings, and then navigate to the Organizations tab. On this tab, you can remove inherited organizations by using the Remove all inputs option, or you can remove them on an input level. This gives you greater flexibility and control over access requirements for your outputs, aligning with how you manage markings.
Example of an organization marking removal
To fully remove an organization marking, you must remove all inputs containing that organization. For example, if you wanted to remove the Testers organization in the screenshot below, you would need to remove both the first and second inputs (assuming none of the other inputs have Testers organization).
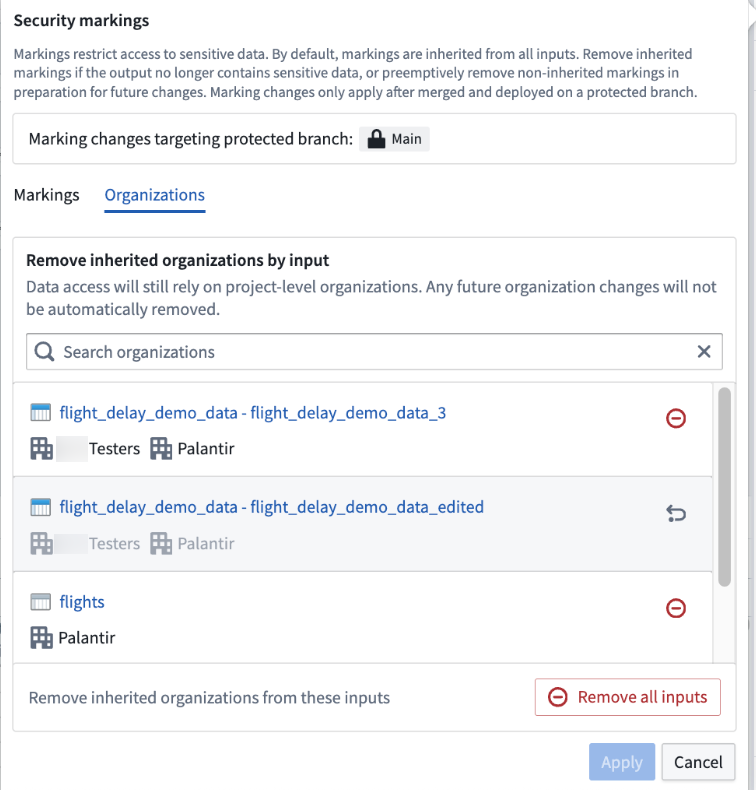
Remove an organization marking by deleting all inputs containing it. In this example, this means both inputs with the Testers organization).
Learn more about removing organization and markings in Pipeline Builder.
Your feedback matters
We want to hear about your experience with Pipeline Builder and welcome your feedback. Share your thoughts with Palantir Support channels, or on our Developer Community ↗ using the pipeline-builder tag ↗.
Ontology resources now support branch protection and project-level policies
Date published: 2025-10-16
The Ontology now supports fine-grained governance through main branch protection and project-level policies when using Foundry Branching. This capability is available for resources that have been migrated to project permissions, extending the same change control processes previously available only for Workshop modules.
What’s new
- Resource protection: Protect Ontology resources individually or in bulk from your file system. Protected resources require changes to be made through branches, ensuring greater oversight.
- Customizable approval policies: Define granular approval policies that apply to protected resources in a given project, specifying which users or groups must approve proposed changes before deployment.
Why it matters
This enhancement is part of an ongoing commitment to empower and expand the builder community, while still maintaining tight controls over change management. By extending these change control processes to ontology resources, project and resource owners benefit from more flexibility, security, and confidence when collaborating with others when using Foundry Branching.
To read more about about this feature, review documentation on protecting resources.
You may also review the previous Workshop announcement when this feature was first released for more information.
Claude 4.5 Sonnet now available in AIP
Date published: 2025-10-14
Claude 4.5 Sonnet is now available from Vertex, Bedrock, and Anthropic Direct for US and EU enrollments.
Model overview
Claude 4.5 Sonnet is a high-performance model that is currently regarded as Anthropic’s best model for complex agents and coding capabilities. Comparisons between Sonnet 4.5 and other models in the Anthropic family can be found in the Anthropic documentation ↗.
- Context Window: 200,000 tokens
- Modalities: Text and image input | Text output
- Capabilities: Extended thinking, Function calling
Getting started
To use these models:
- Confirm your enrollment administrator has enabled relevant model family or families
- Review token costs and pricing
- See the complete list of all the models available in AIP
Your feedback matters
We want to hear about your experiences using language models in the Palantir platform and welcome your feedback. Share your thoughts with Palantir Support channels or on our Developer Community ↗ using the language-model-service tag ↗.
No-code model training and deployment with Model Studio
Date published: 2025-10-14
Model Studio, a new workspace that allows users to train and deploy machine learning models, will be available in beta the week of October 13. Model Studio transforms the complex task of building production-grade models into a streamlined no-code process that makes advanced machine learning more accessible. Whether you are a data scientist looking to accelerate your workflow, or a business user eager to unlock insights from your data, Model Studio provides essential tools and a user-friendly interface that simplifies the journey from data to model.
The Model Studio home page, displaying recent training runs and run details.
What is Model Studio?
Model Studio is a no-code model development tool that allows you to train models in tasks such as forecasting, classification, and regression. With Model Studio, you can maximize model performance for your use cases by training models with custom data while retaining customization and control over the training process with optional parameter configuration.
Building useful, production-ready models traditionally requires deep technical expertise and significant time investment, but Model Studio changes that by providing the following features:
- A streamlined point-and-click interface for configuring model training jobs; no coding required.
- Built-in production-grade model trainers tailored for common use cases such as time series forecasting, regression, and classification.
- Smart defaults and guided workflows that empower you get started quickly, even if you are new to machine learning.
- In-depth experiment tracking with integrated performance metrics that allow you to monitor and refine your models with confidence.
- Full data lineage and secure access controls built on top of the Palantir platform, ensuring transparency and security at every step.
Who should use Model Studio?
Model Studio is perfect for technical and non-technical users alike. Business users who want to leverage machine learning without coding and data scientists who want to accelerate prototyping and model deployment can both benefit from Model Studio's tools and simplified process. Additionally, organizations can benefit from Model Studio by lowering the barrier to AI adoption and empowering more teams to build and use models.
Getting started
To get started with Model Studio, navigate to the Model Studio application and create your own model studio. From there, you can take the following steps to get started with model training:
- Select the best model trainer for your use case (time series forecasting, classification, or regression).
- Choose your input datasets.
- Configure your model using intuitive options, or stick with the recommended defaults.
After configuring your model, you can launch a training run and review model performance in real time with clear metrics and experiment tracking.
What's next on the development roadmap?
As Model Studio continues to evolve, we are committed to enhancing the user experience. To do so, we will introduce features such as enhanced experiment logging for deeper training performance insights, and an expanded set of supported modeling tasks.
Tell us what you think
As we continue to develop Model Studio, we want to hear about your experiences and welcome your feedback. Share your thoughts with Palantir Support channels or our developer community ↗.
Learn more about Model Studio.
Optimize AI performance and cost with experiments in AIP Evals
Date published: 2025-10-09
Experiments are now available in AIP Evals, enabling users to test function parameters such as prompts and models to identify the values that deliver the highest quality outputs and the best balance between performance and cost. Previously, systematic testing of parameter values in AIP Evals was a time-consuming manual process that required individual runs for each parameter value. With experiments, users can automate testing and optimize AI solutions more efficiently.
What are experiments?
Experiments in AIP Evals allow you to launch a collection of parameterized evaluation runs to help optimize the performance and cost of your tested functions. You can define multiple parameter values at once, which AIP Evals will test in all possible combinations using grid search in separate evaluation suite runs. Afterwards, you can analyze experiment results to identify the parameter values with the best performance.
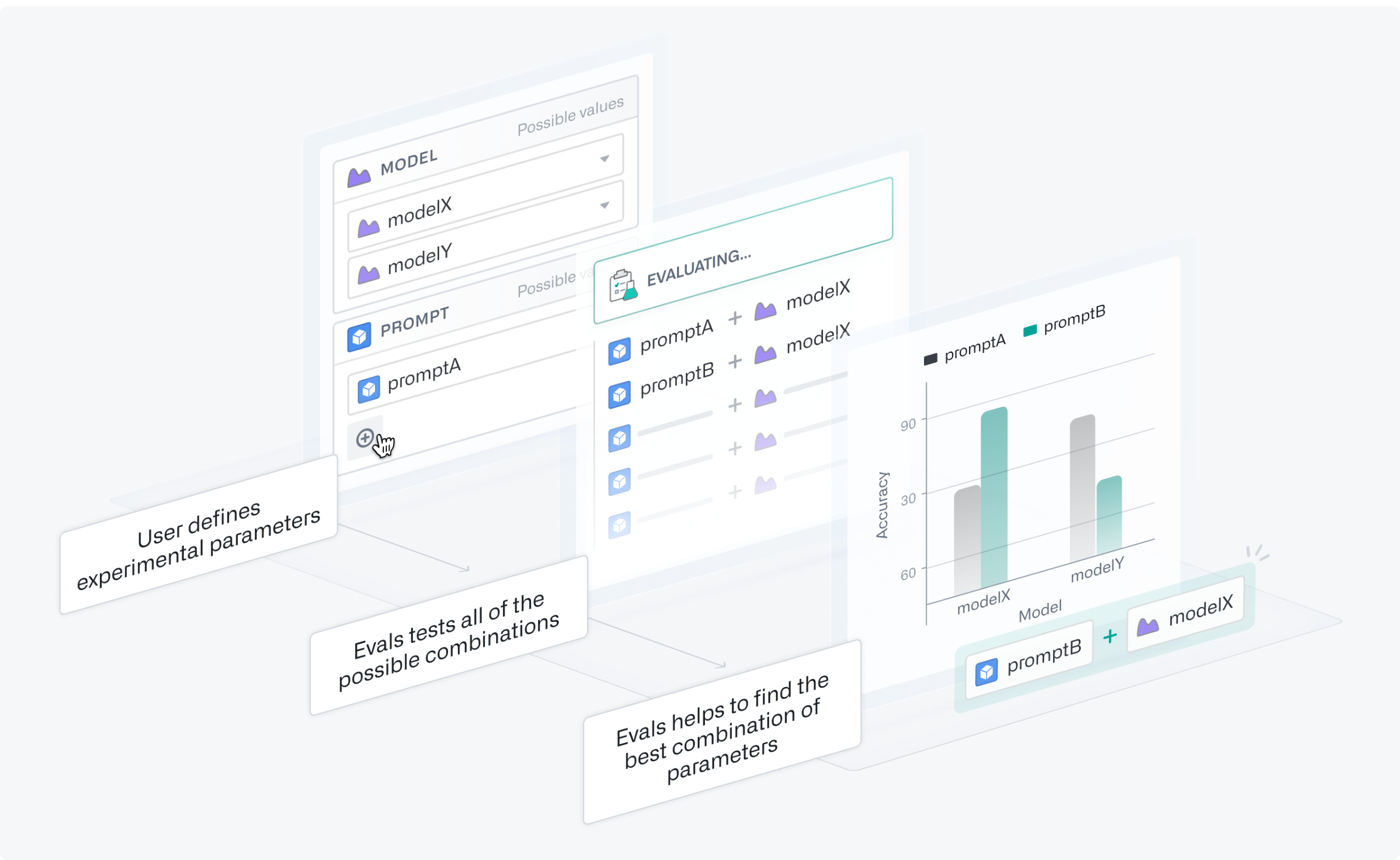
A step-by-step representation of the experiments process.
Leverage experiments
Experiments have been used to discover significant optimization opportunities, and can be used with AIP Logic functions, agents published as functions, and functions on objects.
Some example use cases include the following:
- Testing whether lightweight LLMs can deliver high consistency with prior production outputs at a fraction of the cost of flagship models.
- Identifying common tasks that can be implemented using regular models before defaulting to premium options.
- Improving prompt engineering by efficiently testing how changes such as adding context or few-shot examples, affect performance.
Getting started
To get started with experiments, refer to the documentation on preparing your function and setting up your experiment. You can parameterize parts of your function, define the experiment parameters you want to test with different values, and specify the value options you want to explore in the experiment.
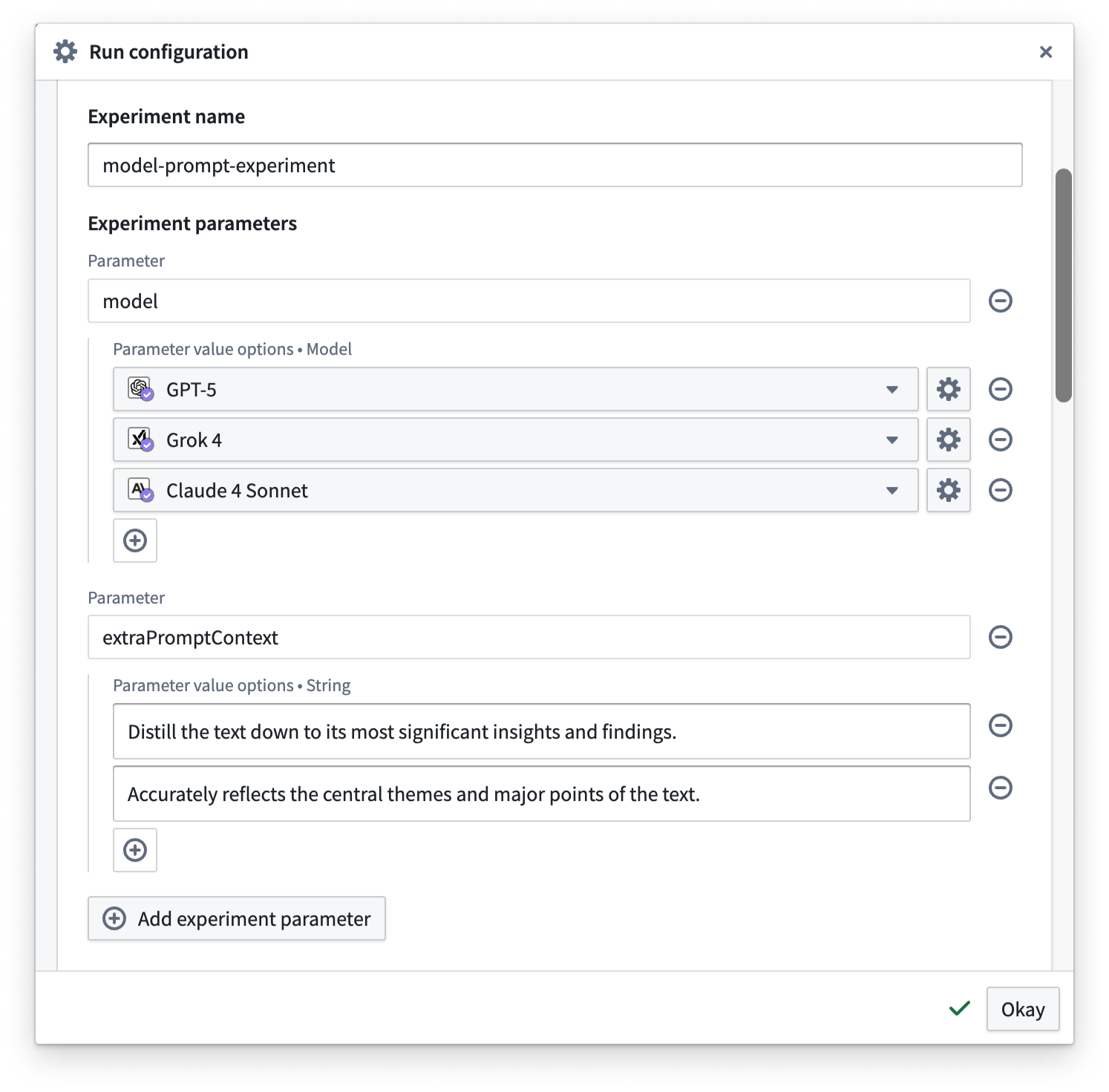
Defining experiment parameters in the Run configuration dialog.
When the evaluation runs have been completed, you can analyze the results in the Runs table, where you can group by parameter values to easily compare aggregate metrics and determine which option performed best. You can select up to four runs to compare, and drill down into test case results and logs.
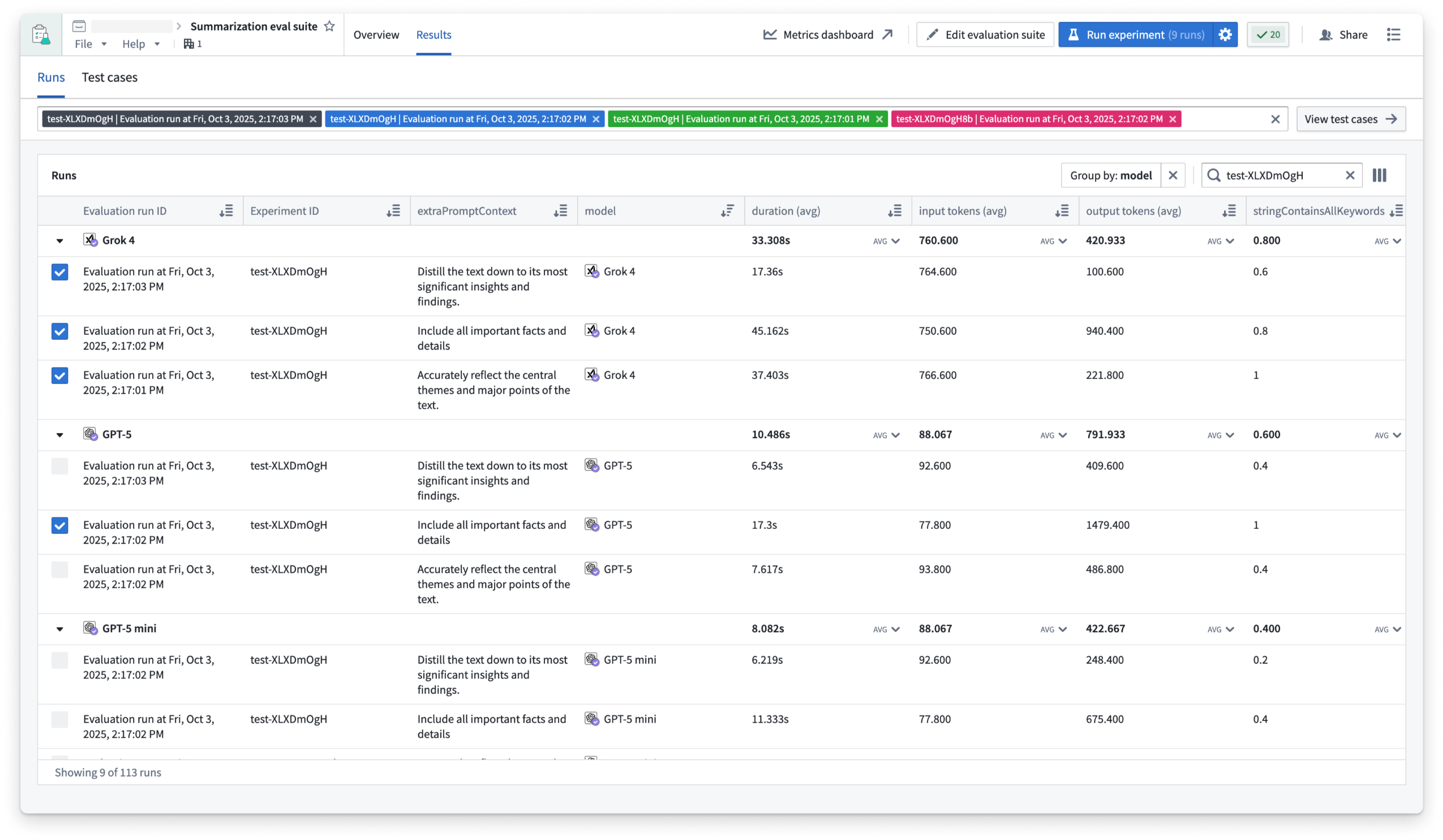
The Runs table in AIP Evals, filtered down to an experiment with evaluation runs grouped by model.
Through automating parameter testing and surfacing the best-performing configurations, experiments can help you refine your AI workflows and deliver higher quality results. Explore this feature to streamline your evaluation process and unlock new opportunities to optimize AI-driven initiatives.
Learn more about experiments in AIP Evals.
Your feedback matters
As we continue to develop new AIP Evals features and improvements, we want to hear about your experiences and welcome your feedback. Share your thoughts with Palantir Support channels or our Developer Community ↗ using the aip-evals tag ↗.
Extract and analyze document context with AIP Document Intelligence
Date published: 2025-10-08
AIP Document Intelligence is now available in beta, enabling you to extract and analyze content from document media sets in Foundry. As a beta product, functionality and appearance may change as we continue active development.
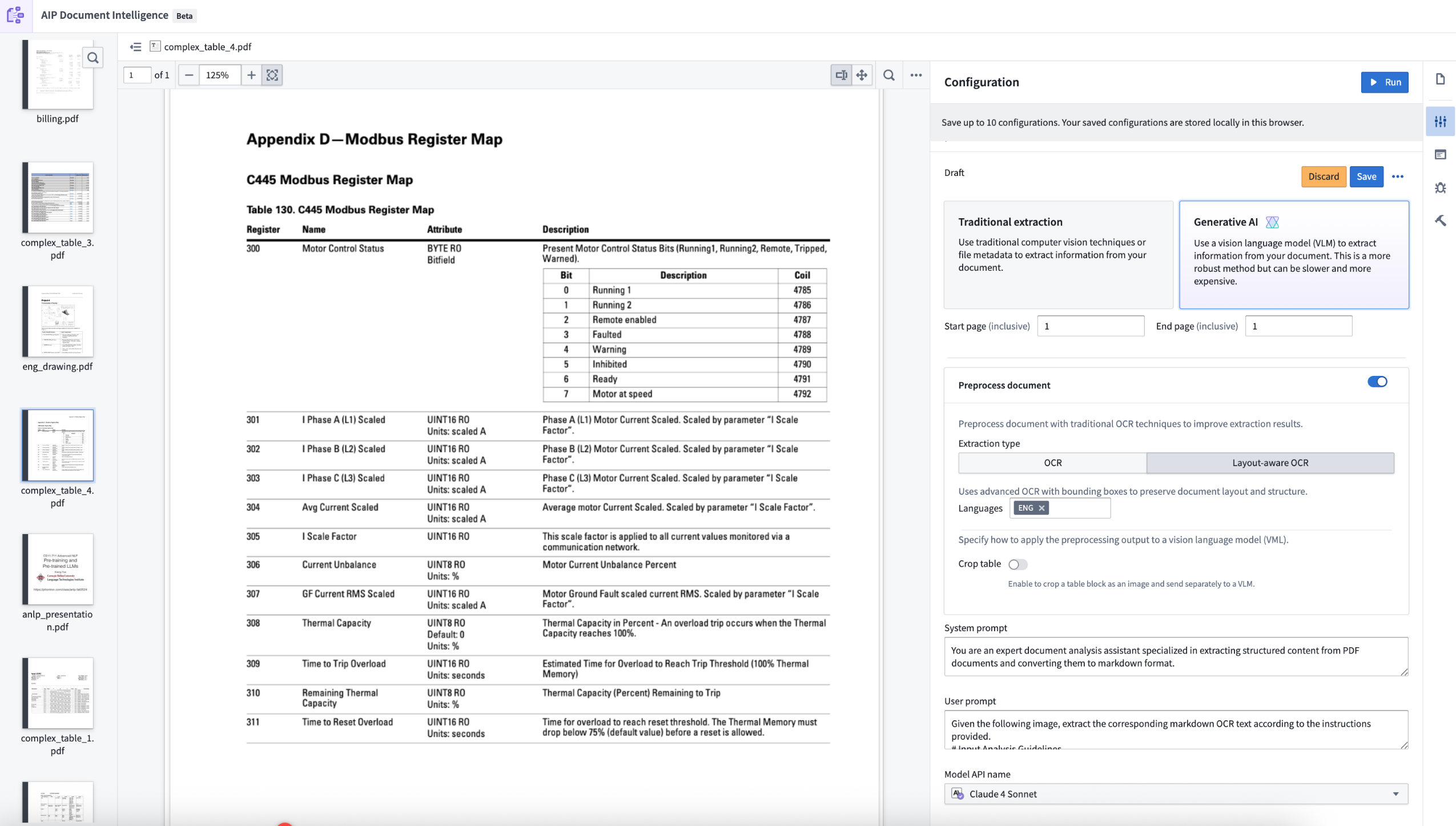
The AIP Document Intelligence application, displaying the configuration page for document extraction.
Why this matters
Document extraction is foundational to enterprise AI workflows. The quality of AI solutions depends heavily on extracting and preparing domain-specific data for LLMs. Our most critical customers consistently highlight document extraction as essential yet time-consuming; complex strategies leveraging VLMs (Vision Language Models), OCR (Optical Character Recognition), and layout extraction often require hours of developer time and workarounds for product limitations.
Key capabilities
AIP Document Intelligence streamlines this process. Users can now:
- Choose between traditional extraction methods (raw text, OCR, layout-aware OCR) and generative AI approaches
- Combine preprocessing techniques with VLMs for complex documents, giving models additional context for better accuracy
- Quickly execute state-of-the-art extraction strategies on sample enterprise documents
- View evaluations of quality, speed, and token cost across different approaches
- Deploy the optimal extraction strategy to a Python transform with a single click to process entire media sets
This beta release supports text and table extraction into Markdown format. Future releases will expand to entity extraction and complex engineering diagrams.
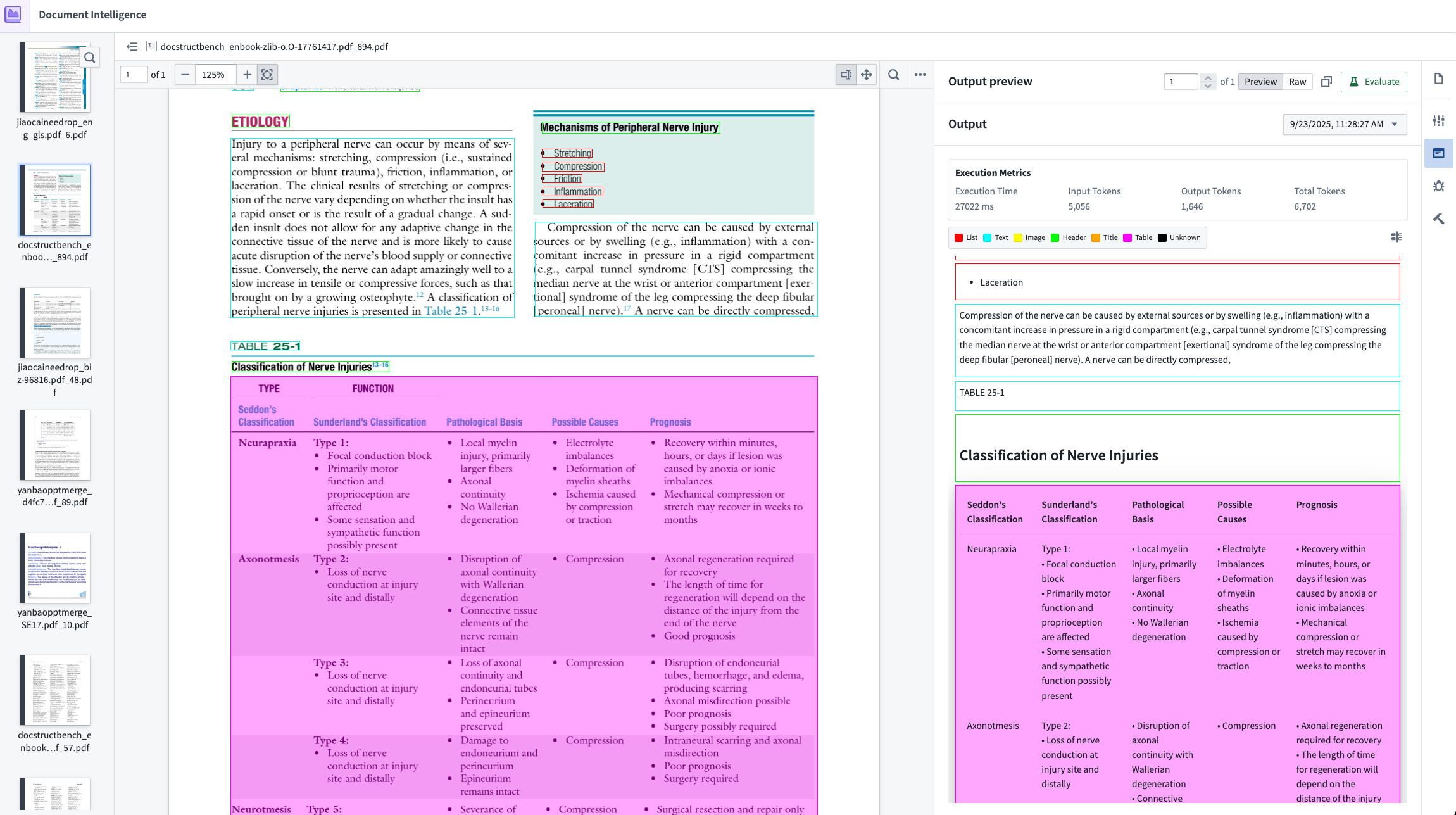
An example of an output preview against a raw PDF in AIP Document Intelligence.
Getting started
To enable AIP Document Intelligence on your enrollment, navigate to Application access in Control Panel.
We want to hear from you
With this beta release, we are eager to hear about your experience and feedback using extraction methods with AIP Document Intelligence. Share your feedback with our Support channels or in our Developer Community ↗ using the aip-document-intelligence tag ↗ .
Debug view for AIP Evals now available in AIP Logic and Agent Studio sidebars
Date published: 2025-10-07
AIP Evals now provides an integrated debug view directly within the Results dialog accessible from the AIP Logic and Agent Studio sidebars. This new view allows you to access debugging information without opening the separate metrics dashboard, making it easier to analyze evaluation results. The debug view allows you to:
-
Navigate between test case results and debug information in a single view
-
Use the native Logic debugger for tested functions and evaluation functions
-
Preview syntax-highlighted code for TypeScript and Python functions
-
Review evaluator inputs and pass/fail reasoning
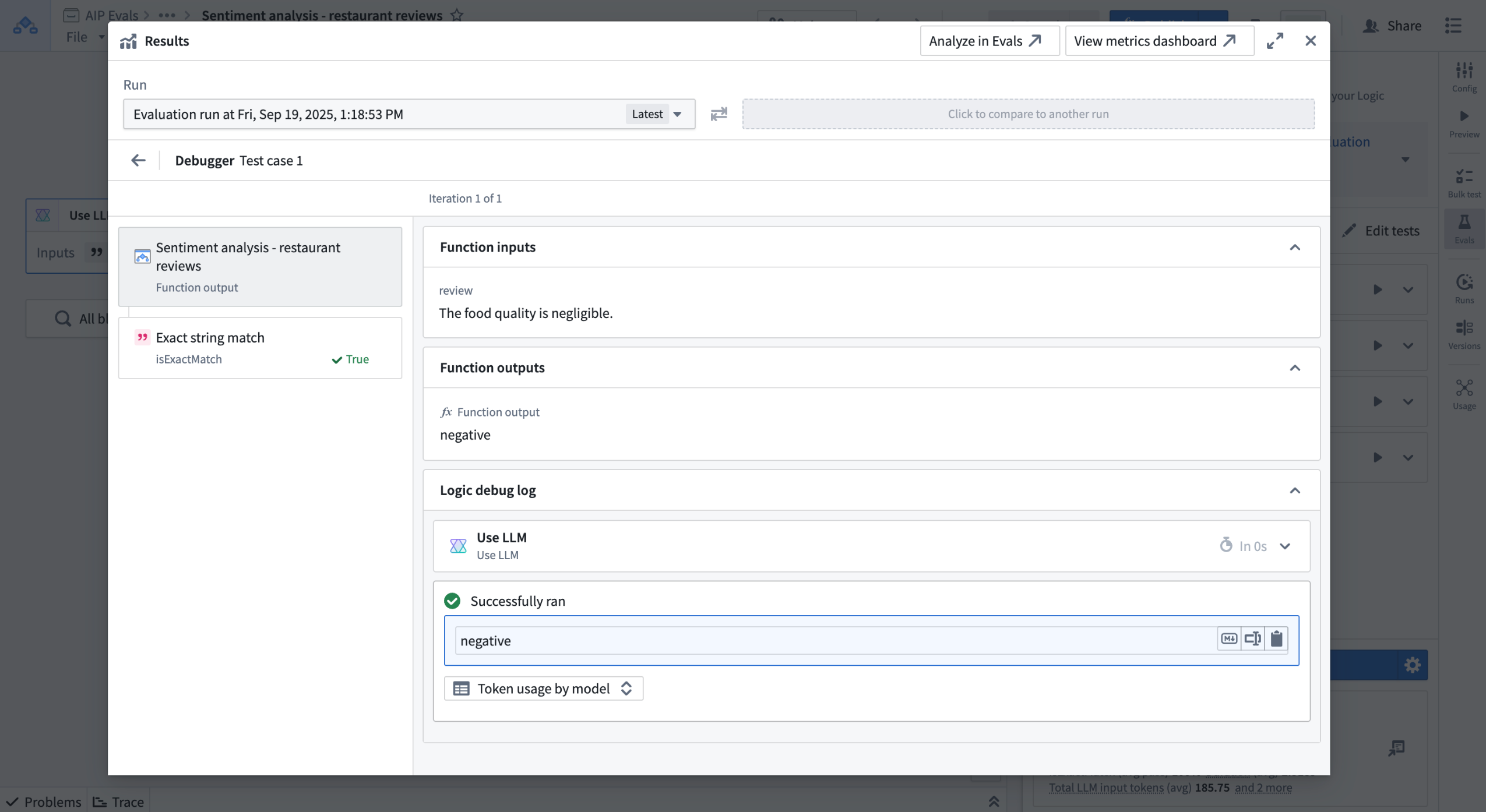
Debug view for a test case.
For more information, review the documentation.
What's next
The debug view will be integrated into the native AIP Evals application in a future release. As we continue to refine the design and user experience, you may notice incremental UI improvements over time.
Share your feedback
Let us know what you think about this feature by sharing your thoughts with Palantir Support channels, or on our Developer Community ↗ using the aip-evals tag ↗.
Grok 4 Fast Reasoning, Grok 4 Fast Non-Reasoning, and Grok Code Fast 1 (xAI) are now available in AIP
Date published: 2025-10-07
Three new Grok models from xAI are now available in AIP: Grok 4 Fast Reasoning, Grok 4 Fast Non-Reasoning, and Grok Code Fast 1. These models are available for enrollments with xAI enabled in the US and other supported regions. Enrollment administrators can enable these models for their teams.
Model overview
Grok 4 Fast Reasoning is best suited for complex reasoning tasks, advanced analysis, and decision-making. It delivers high-level performance for complex decision support, research, and operational planning at a fraction of the cost of Grok 4.
Grok 4 Fast Non-Reasoning is optimized for lightweight tasks such as summarization, extraction, and routine classification.
Grok Code Fast 1 is designed for high-speed code generation and debugging, making it ideal for software development, automation, and technical problem-solving.
Comparisons between these Grok models and guidance on their optimal use cases can be found in xAI’s documentation ↗. As with all new models, use-case-specific evaluations are the best way to benchmark performance on your task.
Getting started
To use these models:
-
Confirm your enrollment administrator has enabled the xAI model family.
-
Review Token costs and pricing.
-
See the complete list of all the models available in AIP.
Your feedback matters
We want to hear about your experiences using language models in the Palantir platform and welcome your feedback. Share your thoughts with Palantir Support channels or on our Developer Community ↗ using the language-model-service tag ↗.
Spreadsheets are now supported as a media set schema type
Date published: 2025-10-02
Spreadsheet media sets are now generally available, allowing you to upload, preview, and process spreadsheet (XLSX) files directly within Foundry's media sets and enabling powerful LLM-driven workflows with tabular data that was previously difficult to handle.
Organizations frequently need to archive and process data from various poorly defined sources like manufacturing quotes, progress reports, and status updates that come in spreadsheet format. Until now, media sets did not support previews for spreadsheets, and tools for converting spreadsheets to datasets were not suitable for the workflows.
What are spreadsheet media sets?
Spreadsheet media sets allow you to work with tabular data designed for human consumption that is difficult to automate using traditional programming methods. The primary format supported is XLSX (Excel) files.
Spreadsheet media sets are ideal for processing unstructured spreadsheets in scenarios such as:
- Files with significant formatting differences between versions
- Spreadsheets where the structure is not known ahead of time (including email attachments, ad-hoc reports, and third-party vendors)
- Storing and displaying source data alongside processed datasets
- Supporting LLM-driven extraction and analysis workflows
Spreadsheet media sets are also an excellent way to maintain your original source of truth for referencing from downstream transformations or ingestions.
Key capabilities
- Upload and preview: Upload XLSX files to media sets and view interactive previews that render spreadsheet content directly in Foundry. The preview provides a familiar tabular view of your data without requiring file downloads.
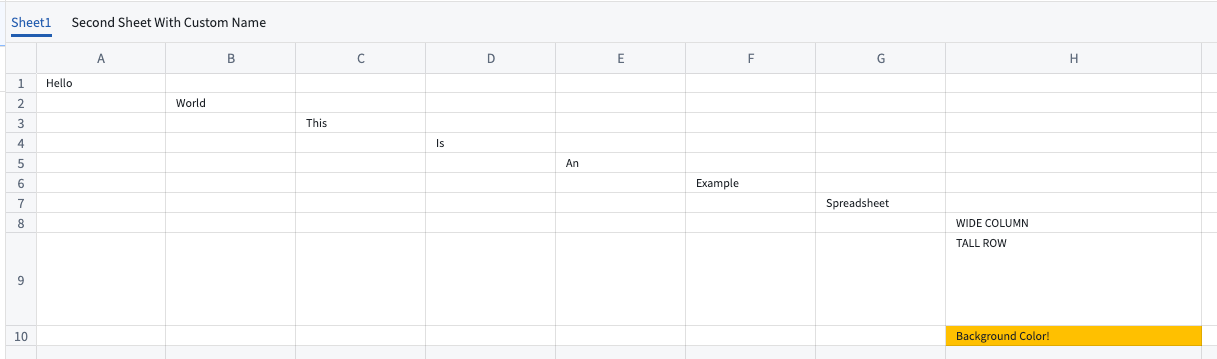
A preview of spreadsheet content uploaded to a media set.
- Text extraction for LLM processing: Extract spreadsheet content as JSON for use in LLM-powered workflows. This enables intelligent processing of tabular data that might have inconsistent formatting or meaningful layout structure such as merged cells.
- Workshop integration: Spreadsheet media sets are fully integrated with Workshop, allowing you to preview spreadsheets directly in your workflow, view and create annotations, and scroll through content seamlessly.
- Pipeline Builder support: Use Pipeline Builder expressions to extract and transform spreadsheet data within your pipelines, making it easy to incorporate spreadsheet processing into your workflows.
- Python transforms in Code Workspaces: Perform advanced transformations in Code Workspaces using the
transforms-mediapackage.
What's next?
In upcoming releases, we plan to enhance spreadsheet media sets with additional Workshop annotation features, enhanced formatting extraction, more options for text extraction, and improved support for edge cases and embedded data.
Your feedback matters
We want to hear about your experience with spreadsheet media sets and welcome your feedback. Share your thoughts with Palantir Support channels, or on our Developer Community ↗ using the media-sets tag ↗.