- Capabilities
- Getting started
- Architecture center
- Platform updates
Announcements
REMINDER: Sign up for the Foundry Newsletter to receive a summary of new products, features, and improvements across the platform directly to your inbox. For more information on how to subscribe, see the Foundry Newsletter and Product Feedback channels announcement.
Share your thoughts about these announcements in our Developer Community Forum ↗.
Evaluate and ship directly with AIP Evals in AI FDE
Date published: 2026-04-14
AI FDE now supports a full workflow with AIP Evals, allowing you to author evaluation suites, run them, and review results without leaving the agent. When tests fail, AI FDE can read the results, diagnose the issue, update the function or suite, and rerun until they pass.
Getting started
Open AI FDE's Write functions mode and enable the Include Evals tools toggle. With automatic mode switching enabled, AI FDE will turn this on for you. You can also find individual AIP Evals tools via the tool icon or search bar.
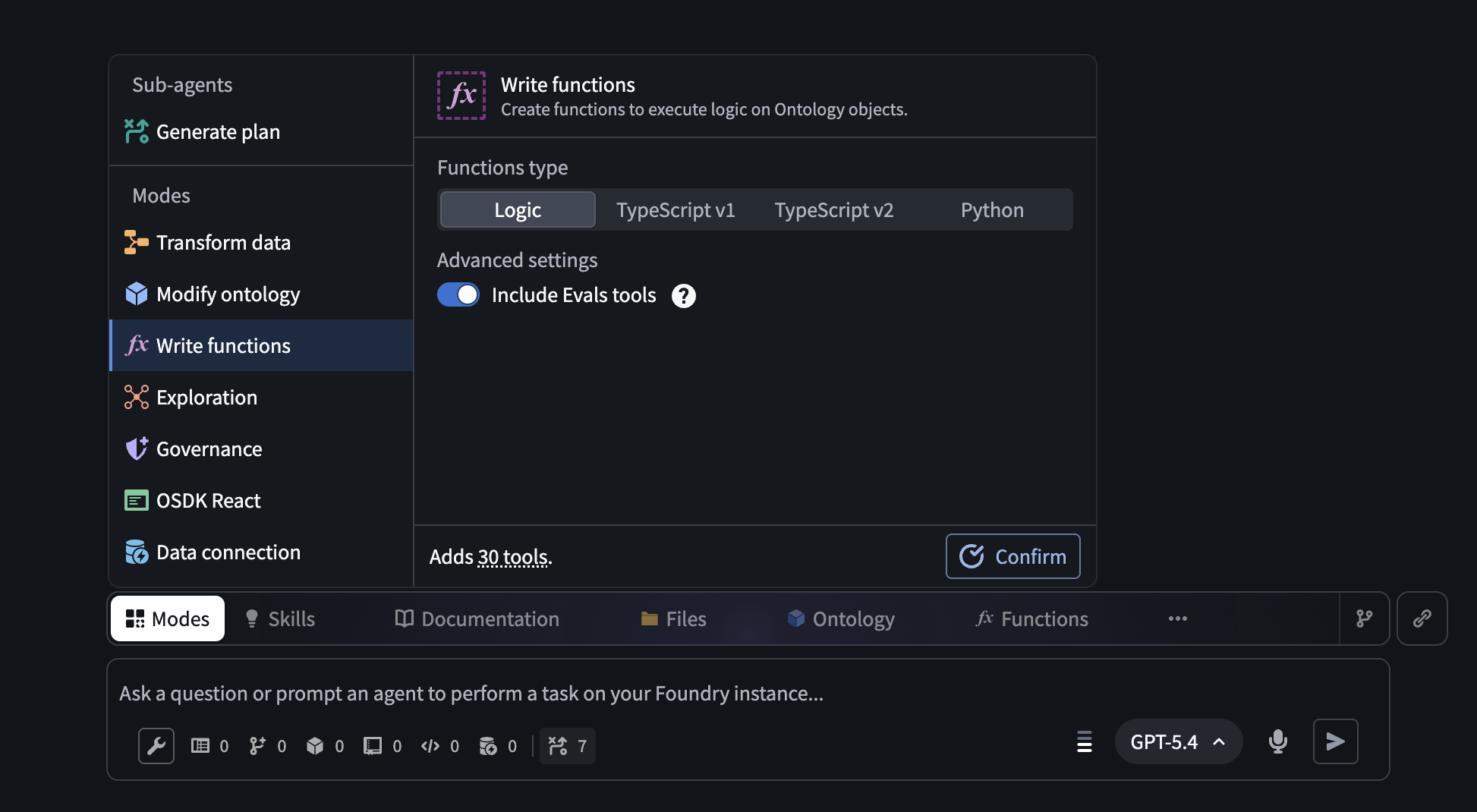
The Write functions mode in AI FDE, with the option to turn on Evals tools.
Key capabilities
- Full evals workflow: Author evaluation suites, run them, and review results without leaving AI FDE. When tests fail, AI FDE can diagnose the issue, update the suite, and rerun until they pass.
- Manual test cases: Supports primitive, array, struct, model, object, and object set types.
- Nineteen built-in evaluators: Includes exact match, regex, ranges, Levenshtein distance, keyword checker, and LLM-as-a-judge, plus function-backed custom evaluators.
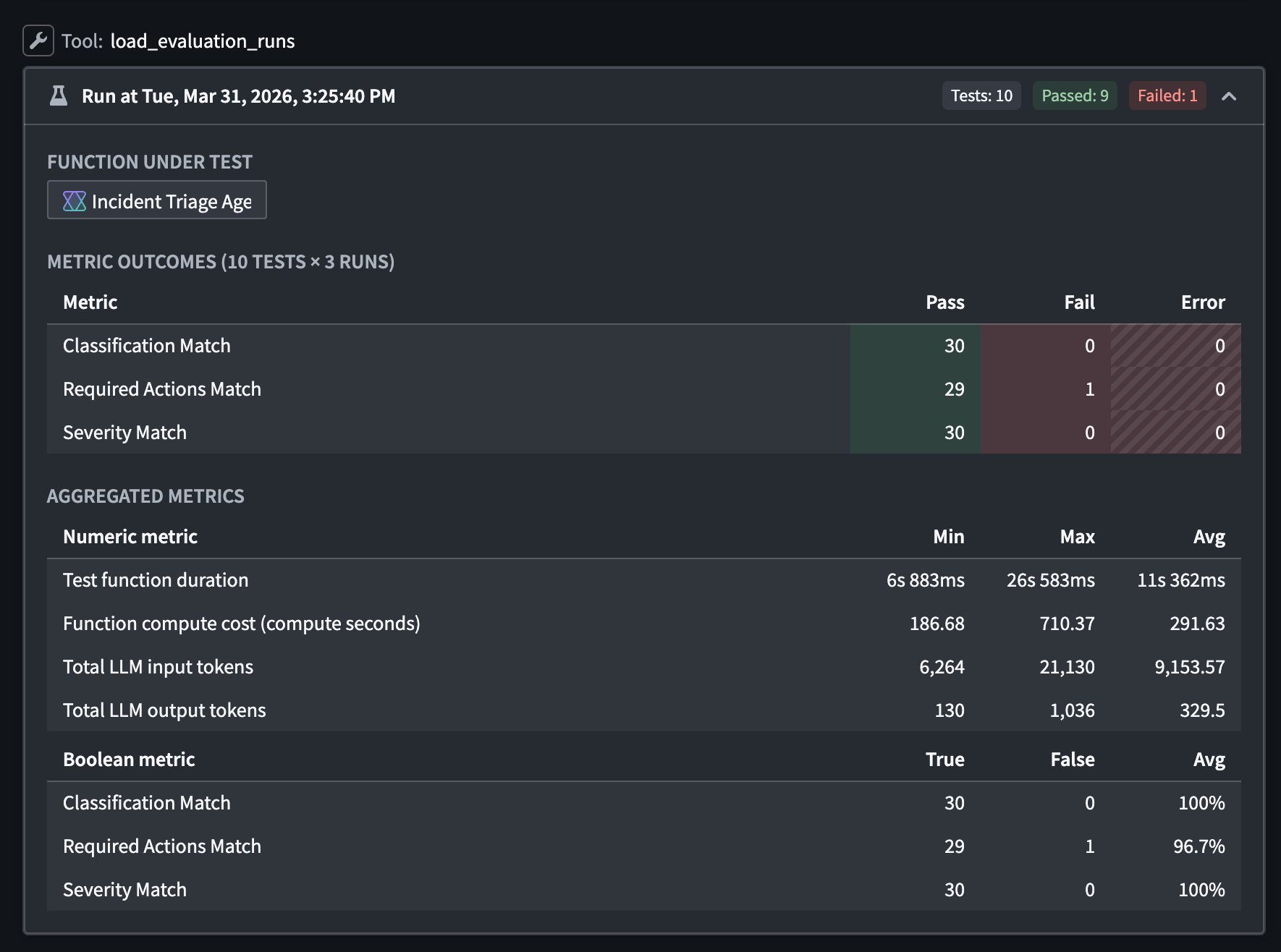
Results from an evaluation suite run in AI FDE, reporting a failure in the Required Actions Match metric.
Current limitations
Object set-backed test cases, multi-target suites, run datasets, and Marketplace evaluators (such as Rubric Grader, Contains Key Details, and ROUGE) are not yet supported in AI FDE.
What's next
Support for the above features are actively in development.
For more information on AI FDE, view our DevCon 5 keynote demo (16 min) on Youtube ↗.
We want to hear from you
Share your experiences using AI FDE and AIP Evals by contacting our Palantir Support channels or joining the conversation in our Developer Community.
GPT-5.1 now available on Azure OpenAI-enabled IL2, IL4, and IL5 enrollments
Date published: 2026-04-14
GPT-5.1 is now available from Azure OpenAI for IL2, IL4, IL5 enrollments.
Model overview
GPT-5.1 balances intelligence and speed by dynamically adapting how much time the model spends thinking based on the complexity of the task. It also features a "no reasoning" mode to respond faster on tasks that does not require deep thinking. For more information, review OpenAI’s documentation on the model ↗, and their GPT-5.1 prompting guide ↗.
- Context window: 400,000 tokens
- Modalities: Text, image
- Capabilities: Structured outputs, function calling, reasoning effort
Getting started
To use these models:
- Confirm your enrollment administrator has enabled relevant model family or families
- Review token costs and pricing
- See the complete list of all the models available in AIP
Your feedback matters
We want to hear about your experiences using language models in the Palantir platform and welcome your feedback. Share your thoughts with Palantir Support channels or on our Developer Community ↗ using the language-model-service tag ↗.
Quiver redesigned graph mode
Date published: 2026-04-14
Quiver's redesigned graph mode is generally available for all enrollments starting from the week of April 13. The redesigned graph mode improves performance and introduces new tools for navigating and organizing large analyses. The redesign replaces inline node previews with a compact node design, adds features for organizing complex analyses, and uses a more space-efficient left-to-right layout. When first opening the redesigned graph mode, you will see an option to reposition your existing nodes for the new layout.
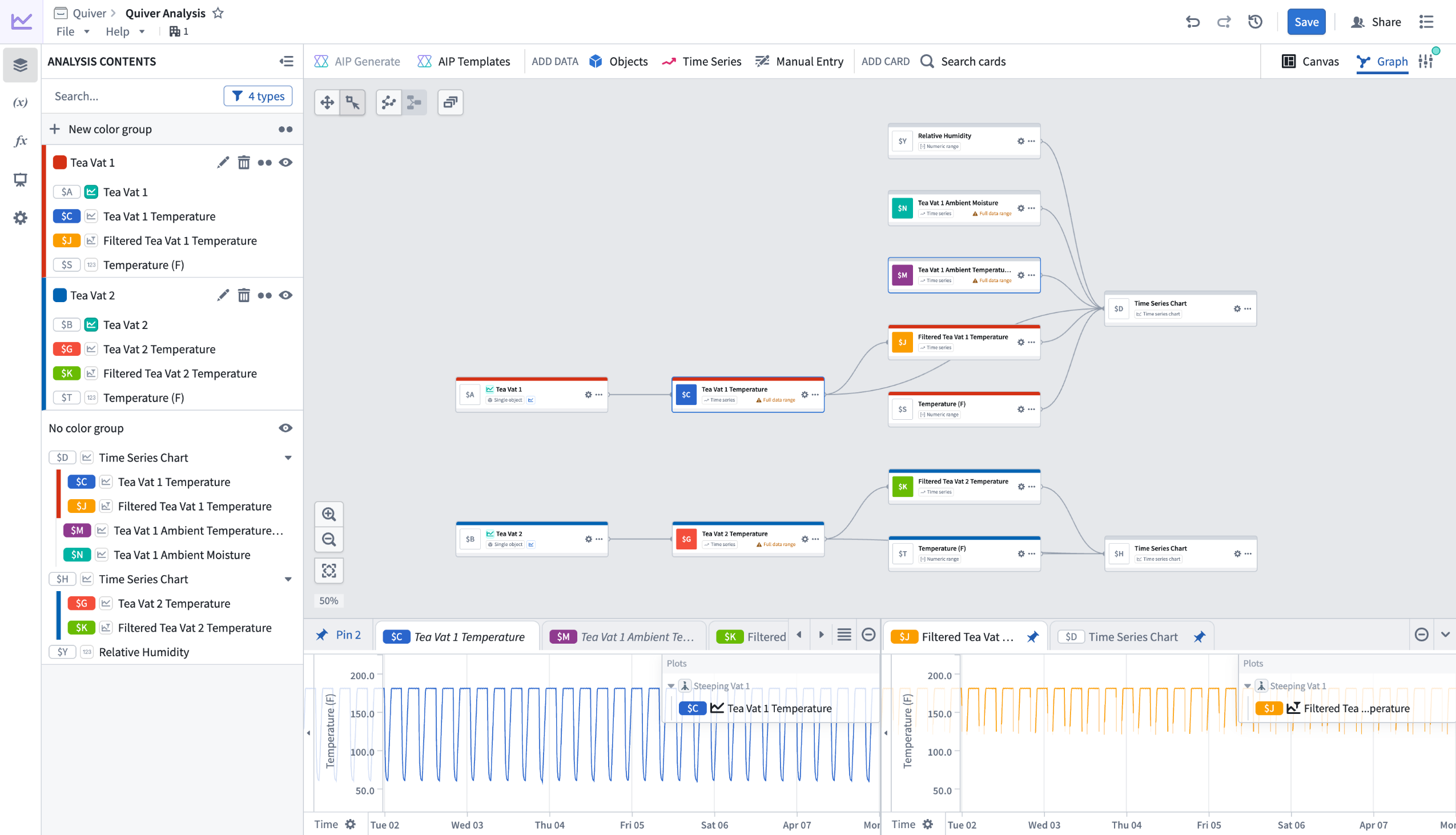
Preview of redesigned graph mode in Quiver.
What's new?
- Compact nodes with a dedicated preview panel: Instead of rendering full content inline, nodes display a summary of title, identifier, type, and basic actions. Selecting a node shows its output in a dedicated bottom panel. Previews can be pinned to stay visible as you navigate the graph, or viewed side by side in a split-screen layout.
- Color groups: Assign colors to related nodes to visually distinguish sections of your analysis. For example, color all nodes downstream of one object blue and those downstream of another red to make the graph readable at a glance.
- Collapse and hide: Collapse entire color groups into a single node to reduce visual clutter, or hide individual nodes and groups to focus on a specific part of the graph. Expand or unhide them when you need to see the full picture.
- Filtering: The Analysis Contents panel includes filters to control which nodes are visible in the graph. Filter by node type, or narrow down to nodes present on a particular canvas, dashboard, or function. This makes it possible to focus on one area of your analysis without losing the broader context.
- Bulk actions: Switch to selection mode and drag to select multiple nodes. Then add them to a color group, hide them, manage their canvas placement, or delete them.
- Graph and canvas isolation: Nodes added in graph mode are no longer placed on a canvas by default. You can add or remove nodes from a canvas at any time through a node's actions menu. In canvas mode, deleting a card gives you the option to remove it from just the canvas or from the analysis entirely.
- Input selection from graph: When configuring a node in graph mode, you can select its inputs by picking nodes directly from the graph instead of searching through a list.
Your feedback matters
We want to hear about your experiences using Quiver's redesigned graph mode and welcome your feedback. Share your thoughts with our Palantir Support channels or Developer Community using the quiver tag.
Scale compute resources with managed profiles in Pipeline Builder
Date published: 2026-04-14
Pipeline Builder now features a managed profile strategy for compute resources. When you select this strategy, Pipeline Builder analyzes the resource usage of your last five builds and adjusts your compute resources if those builds used fewer resources than your current selection.
For example, if you selected a large profile but your last five builds used significantly fewer resources, Pipeline Builder will automatically scale down your compute resources to match your actual usage.
Learn more about profile management strategies in Pipeline Builder.
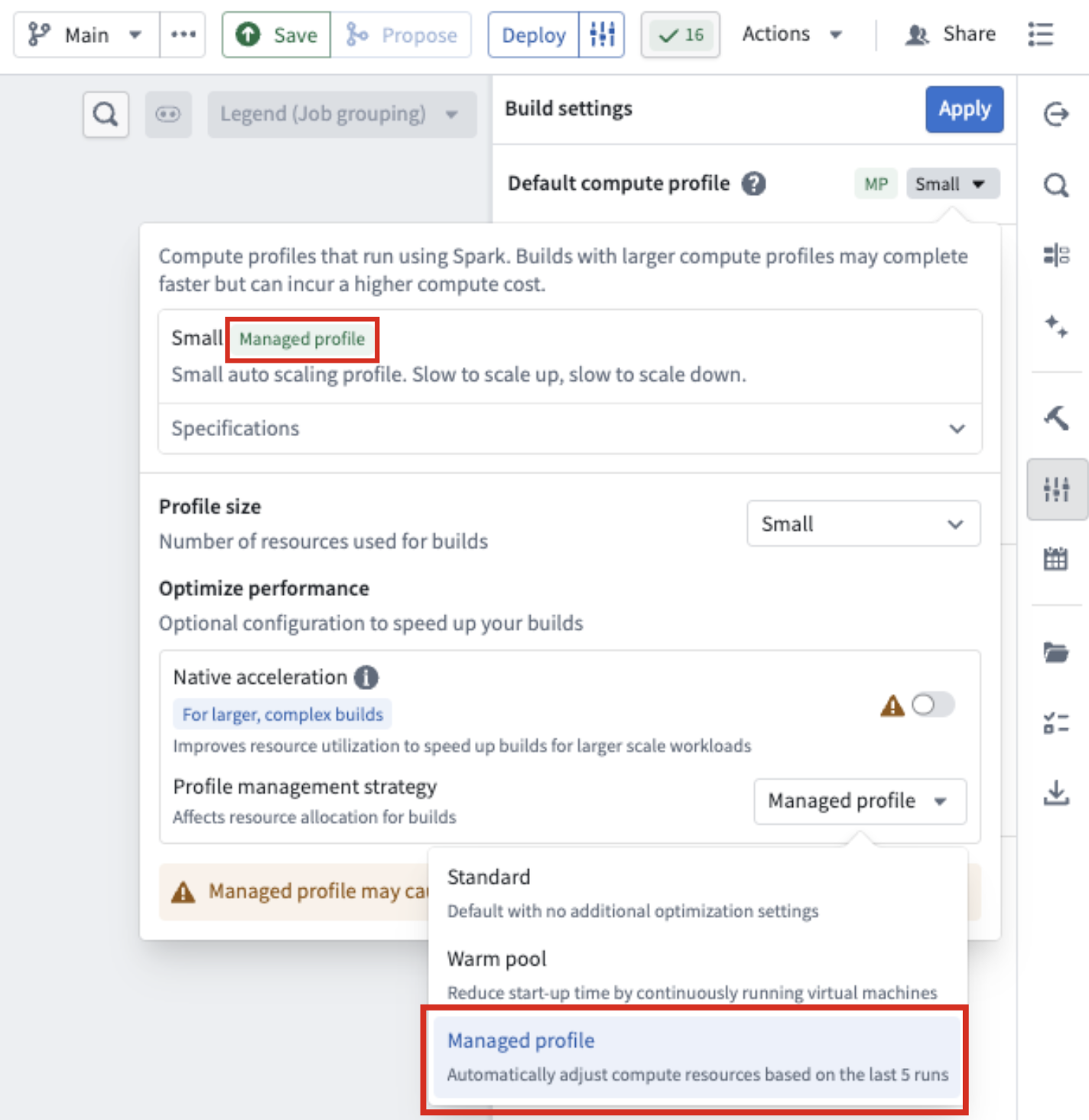
The Managed profile option under Profile management strategy in Build settings.
How to turn on the managed profile feature
- Go to Build settings in the right-hand panel.
- Open the Default compute profile.
- Under Profile management strategy, select Managed profile from the drop-down menu.
The profile management strategy appears as a tag next to your build profile type at the top of the build compute profile panel.
Additional notes about the feature
- Managed profile will only scale down; it will not scale above your originally selected profile.
- Builds may fail if your data size or workload changes drastically between builds, because the managed profile bases its scaling on previous usage.
- Managed profiles in Pipeline Builder are not currently supported for native acceleration builds.
We want to hear from you
To share feedback or tell us about your experience using this feature, contact us through our Palantir Support channels or join the conversation in our Developer Community using the pipeline-builder tag ↗ .
Migrate from legacy mode of the AIP Agent widget to Agent Studio
Date published: 2026-04-09
On May 1 2026, the legacy mode of the AIP Agent widget (formerly the AIP Interactive widget) in Workshop will be fully deprecated and deleted from Foundry.
Legacy mode has been marked as deprecated in Workshop since January 2025. It has not received new features since work on AIP Agent Studio began over two years ago, and removing it is necessary to support the architectural changes required to deliver the next generation of AIP Agents.
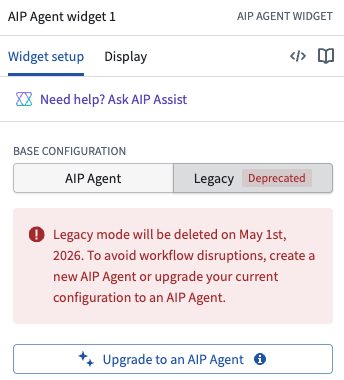
The deprecated legacy configuration of the AIP Agent widget in Workshop.
The most recent LLMs supported in legacy mode are GPT-4o and Claude 3 Haiku, compared to the latest models and additional feature development available in AIP Agent Studio.
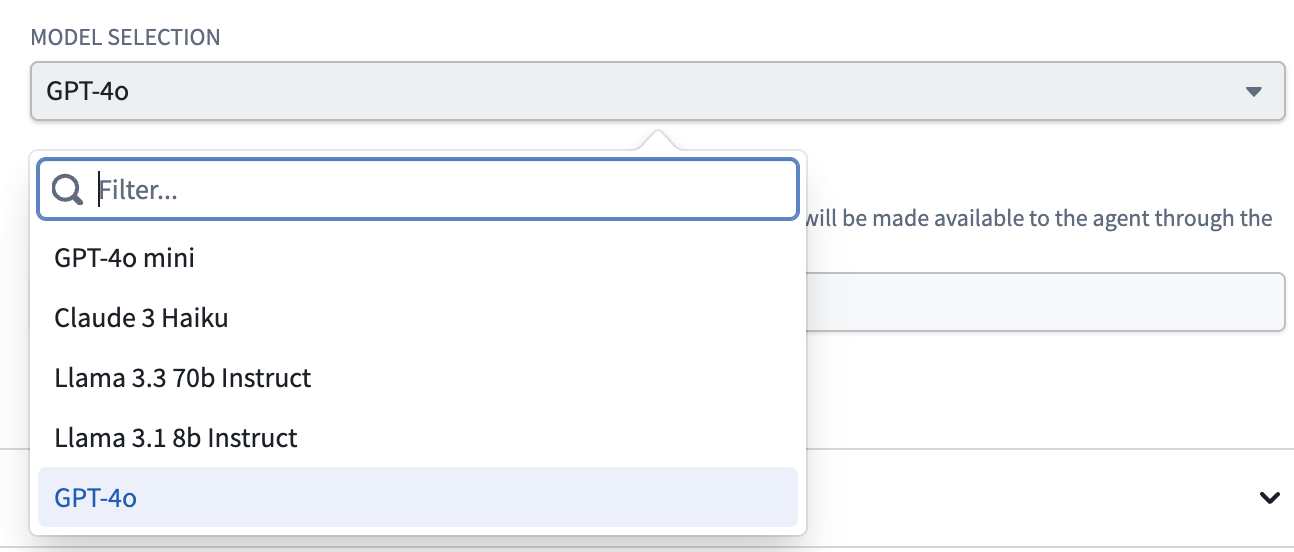
The available LLMs in legacy mode of the AIP Agent widget.
Review the AIP Agent Studio documentation and AIP Agent widget documentation for more information.
Required action
If you are still using legacy mode in your Workshops, select Upgrade to an AIP Agent in the Legacy tab of the widget's configuration panel or create a new AIP Agent before May 1 to avoid disruptions.
Ingest and transform emails with media sets
Date published: 2026-04-09
The ability to upload, preview, and transform email (.eml) files directly within media sets is now generally available across Foundry enrollments, enabling you to parse email content at scale.
What are email media sets?
Email media sets allow you to work with .eml files as first-class media items in Foundry. They are particularly useful when you need to extract and process attachments from emails—such as spreadsheets, documents, or images—while also retaining access to email metadata and body content for downstream processing.
Key capabilities
- Upload and preview content: Upload
.emlfiles to media sets and view interactive previews that render email content directly in Foundry, such as within a Workshop module's Media Preview widget. The preview displays message headers, content, metadata, and a list of attachments.
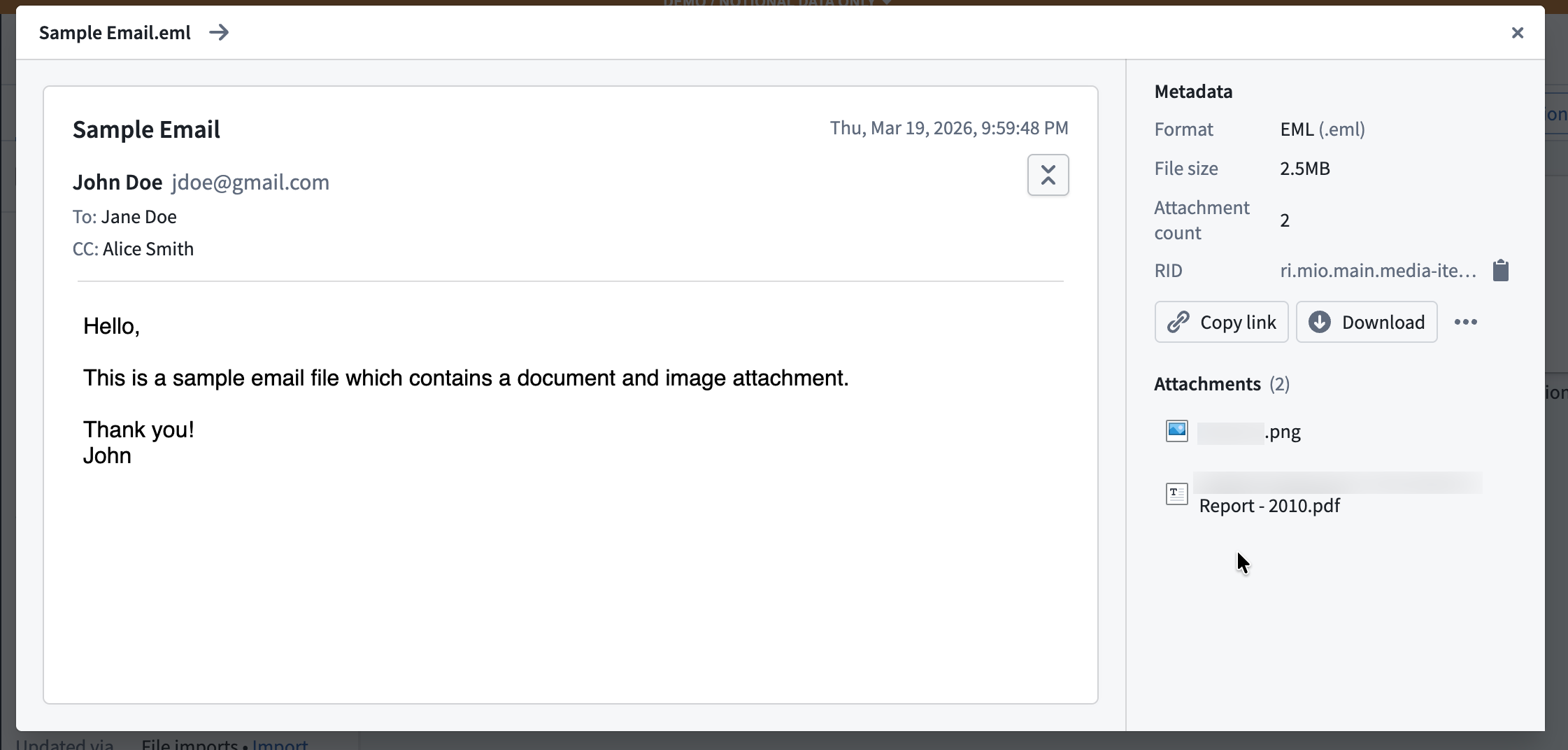
A preview of an email uploaded to a media set.
- Preview and download attachments: View attachment previews directly within the email preview for any supported media format. You can download unsupported attachment file types.
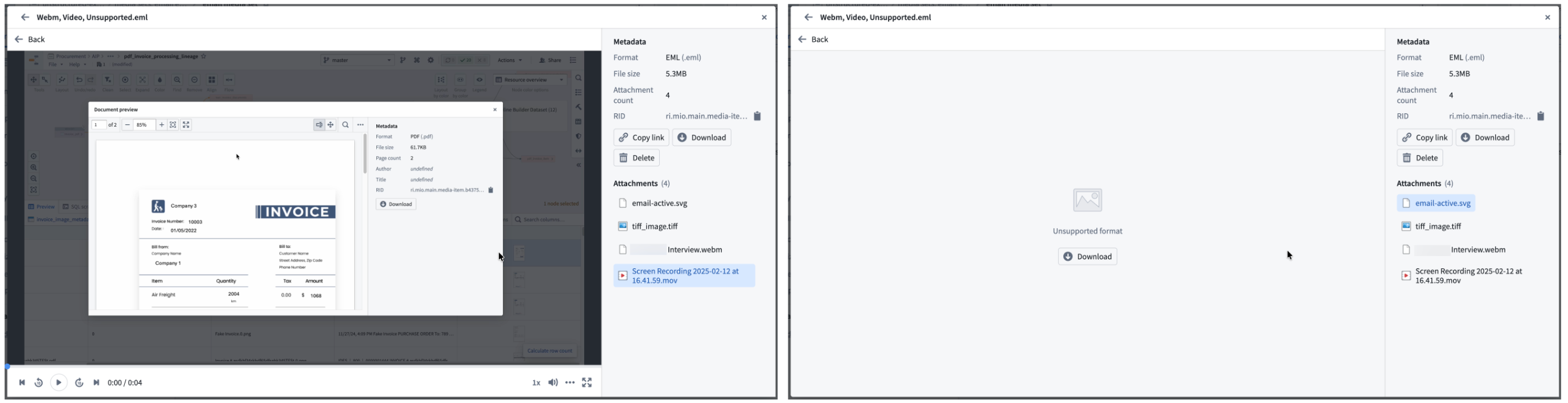
View attachment previews for supported media formats or download unsupported attachment file types.
- Process email files downstream: Use Pipeline Builder expressions or Python transforms in Code Workspaces to:
- Extract and output email attachments to other media sets for further processing.
- Extract email content as plain text or HTML for use in LLM-powered workflows.
Your feedback matters
We want to hear about your experience with email media sets and welcome your feedback. Share your thoughts with Palantir Support channels or on our Developer Community ↗ using the media-sets tag ↗.
Grok 4.20 from xAI is now available in AIP
Date published: 2026-04-07
Grok 4.20 (Reasoning) and Grok 4.20 (Non-Reasoning) are now available for enrollments with xAI enabled in the US and other supported regions.
Model overviews
Grok 4.20 (Reasoning) is designed for complex, multi-step logic, high-accuracy tasks, and deep analysis.
Grok 4.20 (Non-Reasoning) is focused on high-speed, efficient responses for straightforward queries, simple summarization, and other lightweight tasks as part of agentic workflows.
Getting started
To use these models:
- Confirm your enrollment administrator has enabled the xAI model family.
- Review token costs and pricing.
- See the complete list of all the models available in AIP.
Your feedback matters
We want to hear about your experiences using language models in the Palantir platform and welcome your feedback. Share your thoughts with Palantir Support channels or on our Developer Community ↗ using the language-model-service tag ↗.
Nvidia Nemotron 3 models are now available in AIP
Date published: 2026-04-07
Nvidia's Nemotron 3 Super 120B and Nemotron 3 Nano 30B models hosted by AWS Bedrock are now available for enablement in AIP on non-georestricted enrollments as well as enrollments georestricted in select regions.
Model overviews
Nvidia Nemotron 3 Super 120B ↗ is Nvidia's leading model for coding, reasoning, math, and long context tasks suitable for high-volume enterprise automation, multi-agent collaboration, and advanced coding tasks. Currently available on non-georestricted enrollments as well as enrollments georestricted in the US, EU, UK, and JP regions.
Nvidia Nemotron 3 Nano 30B ↗ is Nvidia's model optimized for high-throughput, low-latency, and low-cost deployments. Optimized for single-agent tasks and fast inference, it is most effective for chatbots, local edge deployment, summarization, and data extraction tasks. Currently available on non-georestricted enrollments and enrollments georestricted in the US.
Getting started
To use these models:
- Confirm that your enrollment administrator has enabled the Nvidia | AWS Bedrock model family in Control Panel.
- Review token costs and pricing.
- See the complete list of all models available in AIP.
Share your feedback
We want to hear about your experiences using language models in the Palantir platform and welcome your feedback. Share your thoughts with Palantir Support channels or on our Developer Community ↗ using the language-model-service ↗ tag.
Incremental media set inputs now available in Pipeline Builder
Date published: 2026-04-07
Pipeline Builder now supports incremental processing for media set inputs. Select a media set input node and choose Incremental to enable this feature. By leveraging the build history of the media set, incremental computation avoids the need to recompute the entire output every time a transform is run, saving time and compute costs.
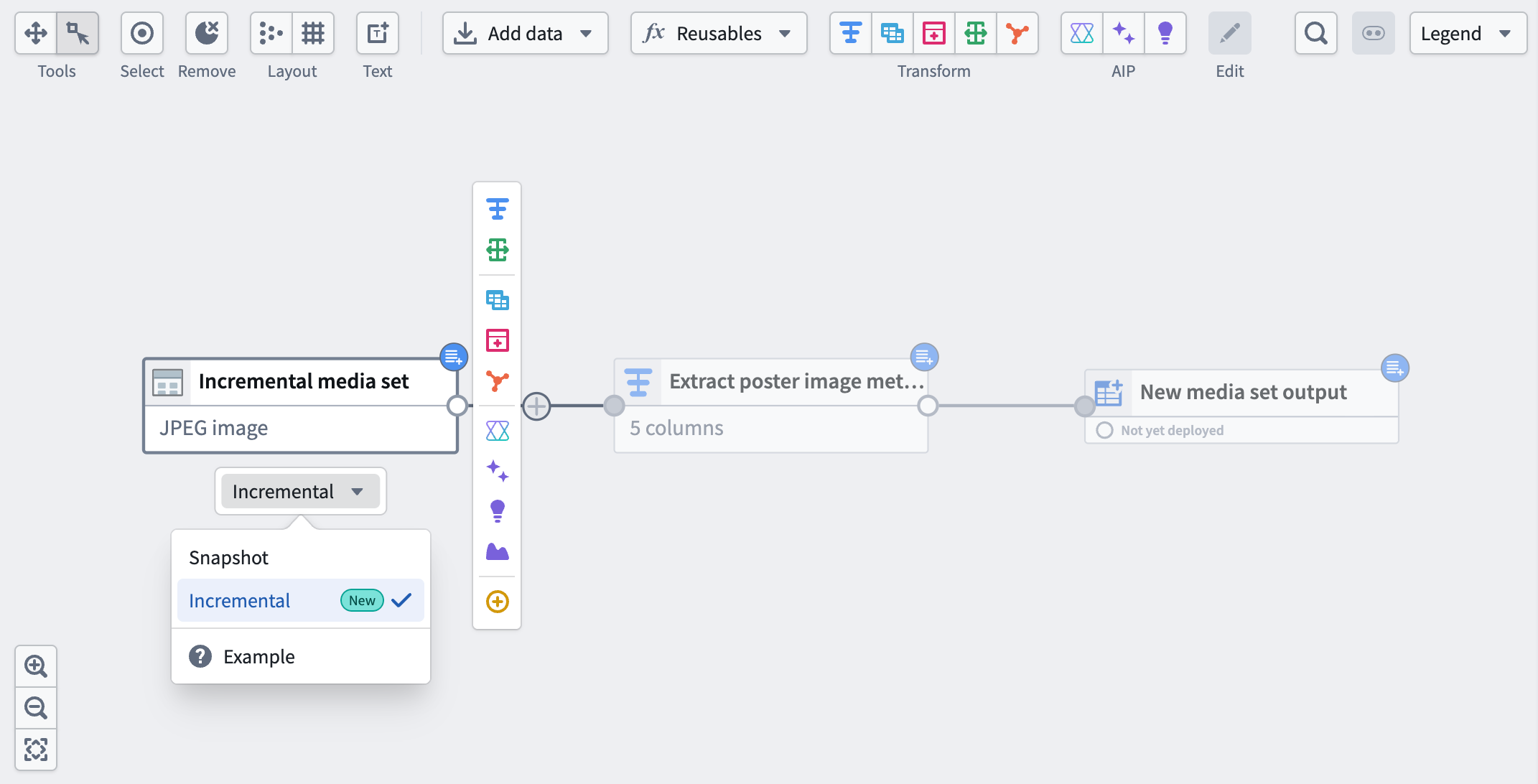
A media set input with the incremental option selected.
How it works
- First build: Pipeline Builder will process your entire media set as usual.
- Subsequent builds: Only new or changed data since the last build will be processed, saving you time and compute costs.
What’s next?
- Mix incremental dataset and media set Inputs: Combining incremental media sets and incremental datasets within the same pipeline is not yet supported. The team is actively working to make it possible in a future update.
- Incremental media set outputs: Support for incremental processing with media set outputs is also on the way.
Your feedback matters
Share your feedback through Palantir Support channels or our Developer Community ↗ using the pipeline-builder tag ↗.
Introducing Models in Pipeline Builder: No-Code Model Inference
Date published: 2026-04-02
Users can now use machine learning models for inference directly in Pipeline Builder — no code required. By bringing models into Pipeline Builder, we have significantly lowered the barrier to building and iterating on inference workflows. Together with Model Studio, this enables a fully no-code path from model training to production inference.
Only Spark (batch) pipelines are supported. Streaming and Lightweight pipelines are not yet available. Models must have exactly one tabular input and one tabular output, and time series models are not yet fully supported.
Key features
- Faster iteration: Make changes to your inference pipeline and run builds immediately — no CI checks to wait on, no code to debug. Pipeline Builder makes it easy to validate results and iterate quickly.
- Branch-aware auto-upgrades: At build time, pipelines automatically resolve the latest published model version from the current branch of your build. If no version exists on that branch, resolution falls back to your configured fallback branches. If no fallback branches are configured, it defaults to master. This ensures your inference pipelines always use the most recent trained version of your model without manual intervention.
- Resource configuration: Models run as isolated sidecar processes alongside your Spark executors, each with dedicated compute resources. Configure CPU, memory, and GPU for model sidecars independently from your pipeline's compute profile, ensuring even resource-intensive models run reliably.
Getting started
1. Configure your pipeline: Ensure you are working with a Spark (batch) pipeline and that warm pool is turned off.
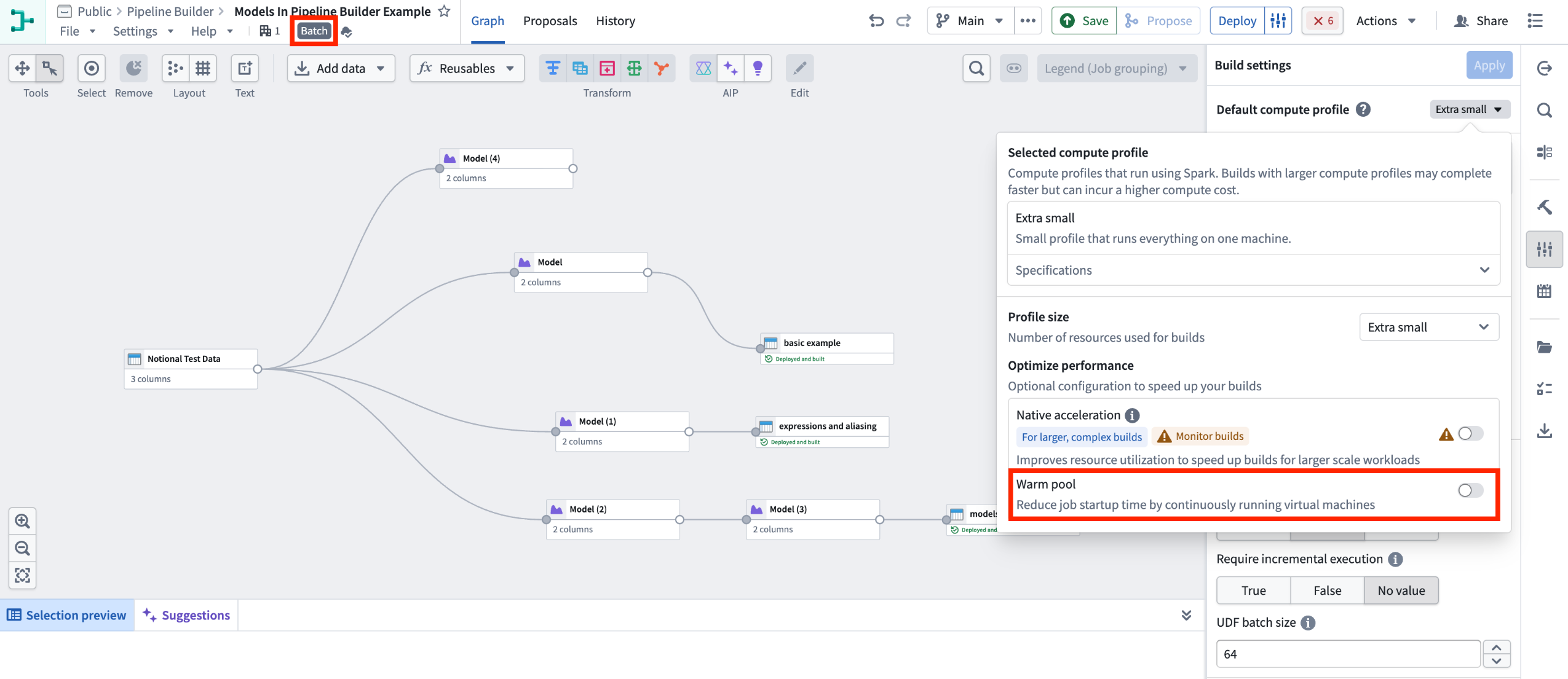
Batch Pipeline Builder with warm pool turned off.
2. Import your model: Navigate to Reusables > Trained models in the import menu and follow the resource import flow to make your model available to the pipeline.
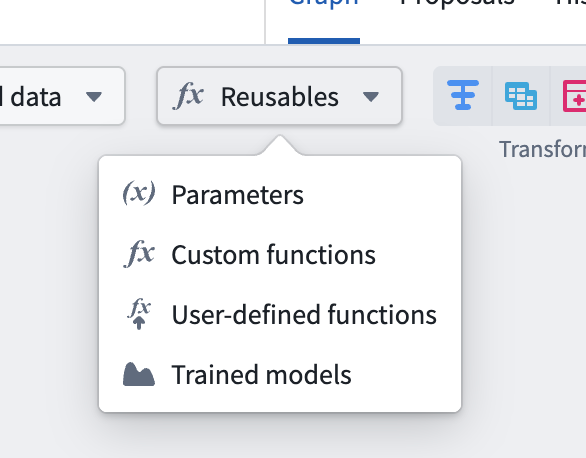
Reusable logic selector.
3. Add the model node: Select a node in your pipeline canvas and select Trained model to insert it.
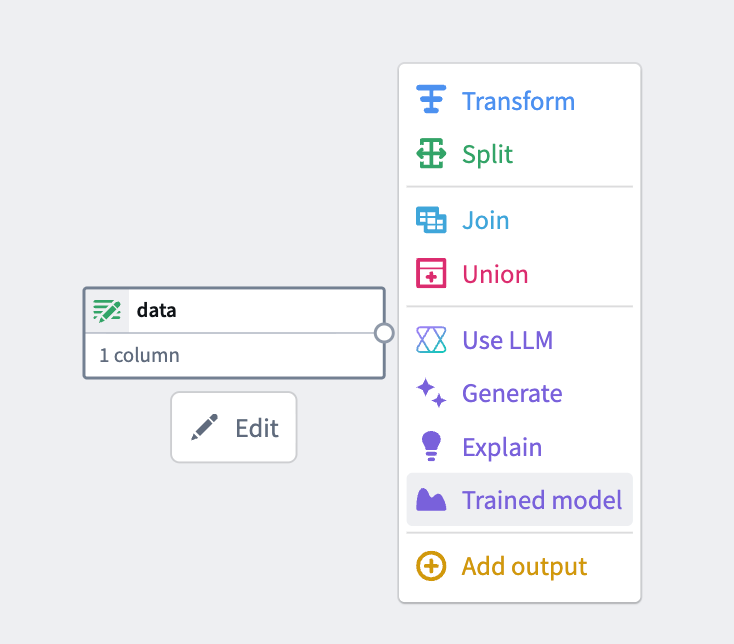
From the available options, select Trained model.
4.Configure inputs and outputs: Map your input and output columns to the model's expected API schema.
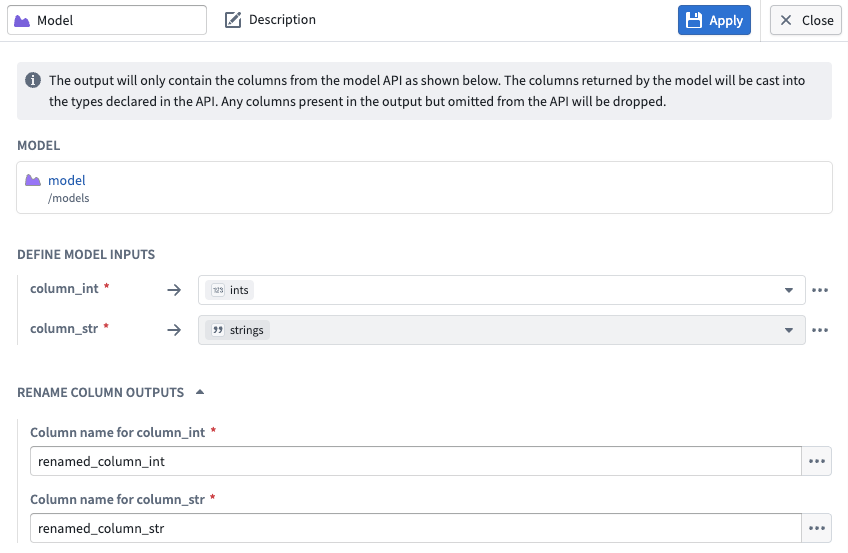
Input and output configuration for a model node in Pipeline Builder.
What’s next?
Preview and streaming support are coming soon. We are actively working on adding Lightweight support, additional input types, time series support, and Marketplace integration.
To learn more, review the Pipeline Builder documentation on Trained models.
We want to hear from you
To share feedback or tell us about your modeling use case, contact our Palantir Support channels or join the conversation in our Developer Community using the modeling tag ↗ .