- Capabilities
- Getting started
- Architecture center
- Platform updates
LLM capacity management
LLM capacity is a limited resource at the industry level, and all providers (Azure, OpenAI, AWS Bedrock, Google Cloud Vertex, etc.) limit the maximum capacity available per account. Palantir AIP consequently follows the market-level constraint set introduced by LLM providers. The standard unit of measure across the industry is tokens per minute (TPM) and requests per minute (RPM).
Enrollment capacity and rate limits
Palantir has set a certain maximum capacity for each enrollment, referred to as "enrollment-level rate limits". This capacity is measured per model using TPM and RPM, and includes all models of all providers enabled on your enrollment, including GPT, Claude, Gemini, Llama, Mixtral, and more. In this way, each model has a separate, independent capacity not affected by the usage of other models.
LLM capacity in AIP is managed at three levels: enrollment-level limits set the overall ceiling, project rate limits control how much of that capacity each project can use, and user rate limits govern individual user consumption for traffic not attributed to a project.
By default, all customers are on the medium tier, which is large enough to build prototypes and scale to a few use cases, even with hundreds of users and large datasets, including millions of documents for example.
Additionally, AIP offers the option to upgrade the enrollment capacity from the medium tier to a large or XL tier if you require additional capacity. If you are constantly hitting enrollment rate limits blocking you from expanding your AIP usage, or if you expect you will increase the volume of your pipelines or total number of users, contact Palantir Support.
Enrollment limits are now displayed on the AIP rate limits tab in the Resource Management application, along with the enrollment tier.
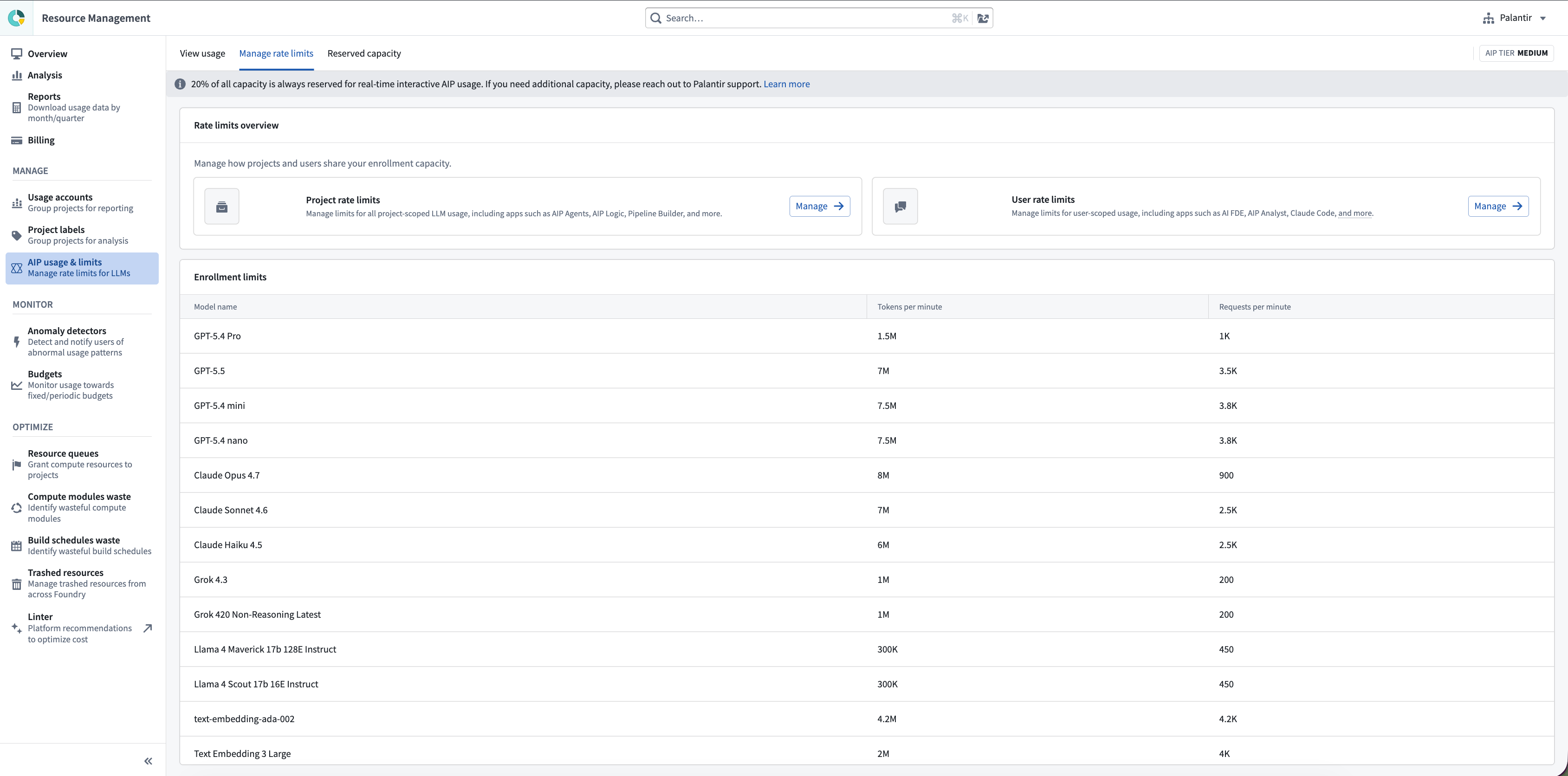
AIP offers enough capacity to build large scale workflows with enrollment tiers, particularly the XL tier. These tiers have provided enough capacity for hundreds of Palantir customers using LLMs at scale, and we continue to increase these limits.
For a full breakdown of enrollment rate limits per model and tier, see LLM enrollment rate limits.
AIP usage and limits
Enrollment administrators can navigate to the AIP usage & limits page in the Resource Management application to:
-
View usage: View LLM token and request usage of all Palantir-provided models for all projects and resources in your enrollment.
-
Manage rate limits: Manage project and user rate limits for your enrollment.
- Project rate limits: Configure the maximum percentage of TPM and RPM that all resources within a given project can use at every given minute combined, per model.
- User rate limits: Configure the maximum TPM and RPM that any single user can use at every given minute, per model.
View usage
The View usage tab provides visibility into LLM token and request usage of all Palantir-provided models for all projects, resources, and users in your enrollment. Administrators can use this view to better manage LLM capacity and handle rate limits.
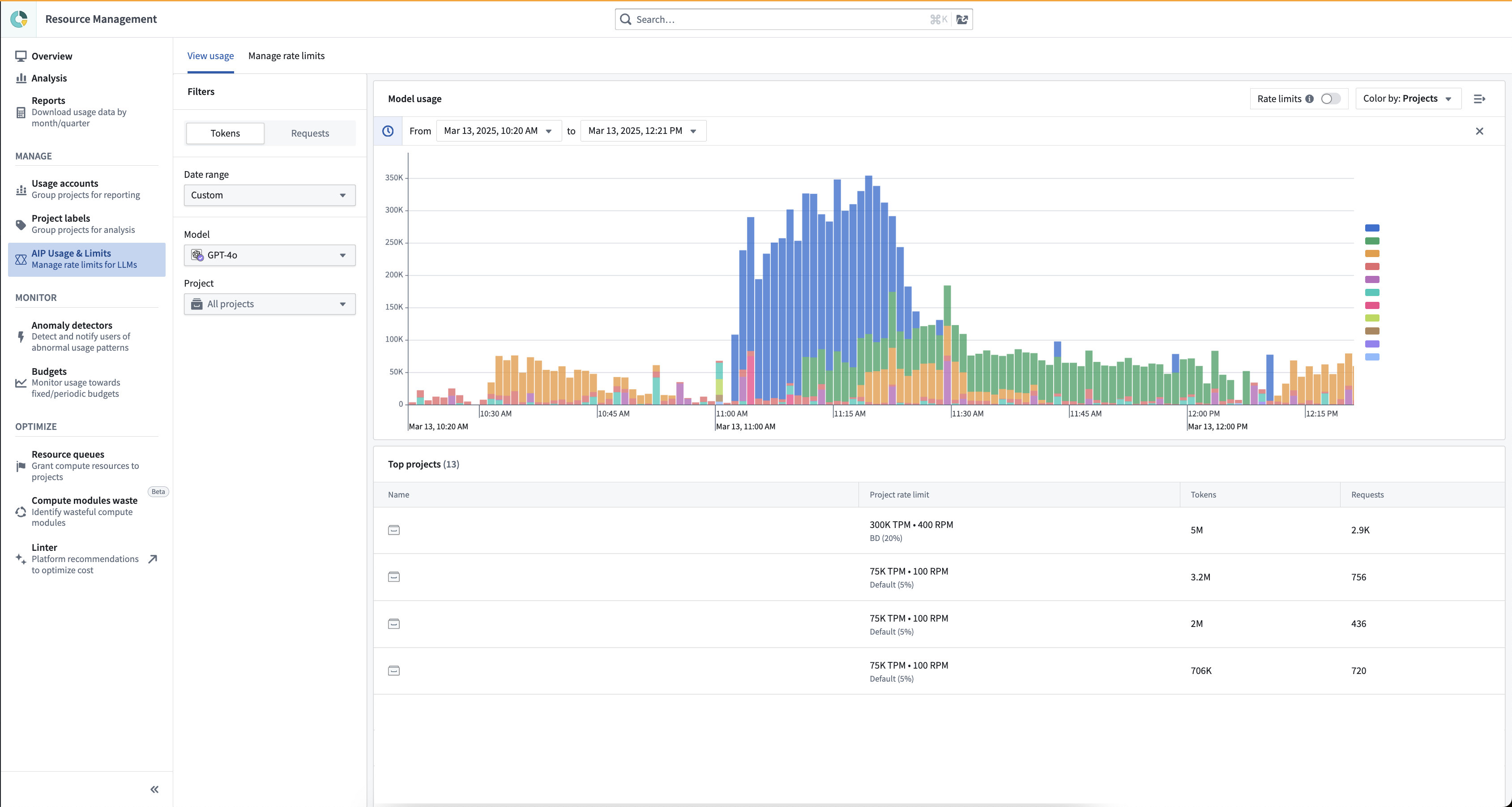
This view allows you to:
- View aggregated usage across all models and a breakdown of usage per individual model.
- Track token and request usage per minute, given that LLM capacity is managed at the token per minute (TPM) and request per minute (RPM) level.
- Drill down to a single model at a time, as capacity is managed for each model separately.
- View both the enrollment usage overview and zoom in to project level usage, given that LLM capacity has both an enrollment-level limit and a project-level limit for each project, as explained above.
- View total user attributed usage for each model.
- View the rate limits threshold. The toggle (on the top right) visualizes when project or enrollment limits are hit, by displaying a dashed line. The limits vary by model and by project. Two rate limit lines are displayed: The enrollment/project limit, and the "batch limit" which is capped to 80% of the total capacity for the specific project and for the entire enrollment. Read more about prioritizing interactive queries below.
- Filter down to a certain time range, two weeks of data, down to the minute. Users can drill down to a specific time range either by using the date range filter on the left sidebar, or by using a drag-and-drop time range filter over the chart itself. When the time range is shorter than 6 hours, the chart will include segmentation to projects (at the enrollment level) or to resources (at the projects level).
- View usage overview in a table. Below the chart, the table includes the aggregate of tokens and requests per project (or per resource when filtered to a single project). The table is affected by all filters (time range, model, project filter if applied).
Note that this view is not optimized to address cost management for LLM usage. Learn how to review LLM cost on AIP-enabled enrollments via the Analysis tab.
Taking action based on AIP usage
If you are hitting rate limits at the enrollment or project level, you may consider taking any of the following actions:
- Adjust project limits to cap the usage of a certain resource or project that might saturate your enrollment capacity.
- Track interactive usage to make sure it is not being rate limited by pipelines. If it is, you can either limit these pipelines at the project level, or move the resource to a separate project with increased limits.
- Schedule builds to different times of day, and large builds to weekends - whenever possible, avoid running multiple large builds at the same time, and when possible schedule regular builds at different times or frequency to avoid clashes.
- Switch your workflows to a different model that your enrollment is not currently leveraging and therefore has significant capacity.
- Request an upgrade to a larger tier.
Manage rate limits
LLM requests are attributed in one of two ways, and the two are mutually exclusive — every request is governed by exactly one of these limit types:
- Project-attributed requests are governed by the enrollment limit and the relevant project limit. This covers workflows where requests originate from a configured project resource (for example, Pipeline Builder pipelines, AIP Logic, Automate, Chatbot Studio, and Workshop applications). Per-user limits do not apply to these requests.
- User-attributed requests are governed by the enrollment limit and the per-user limit for the calling user. This covers workflows where the request originates directly from a user's session rather than from a project resource (for example, AI FDE, AIP Assist, AIP Analyst, native assistant features such as Pipeline Builder Explain and Generate, and IDE integrations such as Continue (VS Code) and Claude Code that connect to Foundry-provided models).

Manage project rate limits
On the Manage rate limits tab under the AIP usage & limits page in Resource Management, administrators have the flexibility to maximize LLM usage for production use cases in case of ambitious use cases in AIP, and limit or disallow experimental projects from saturating the entire enrollment capacity. Enrollment administrators can configure the maximum percent of TPM and RPM that all resources within a given project can use at every given minute combined, per model.
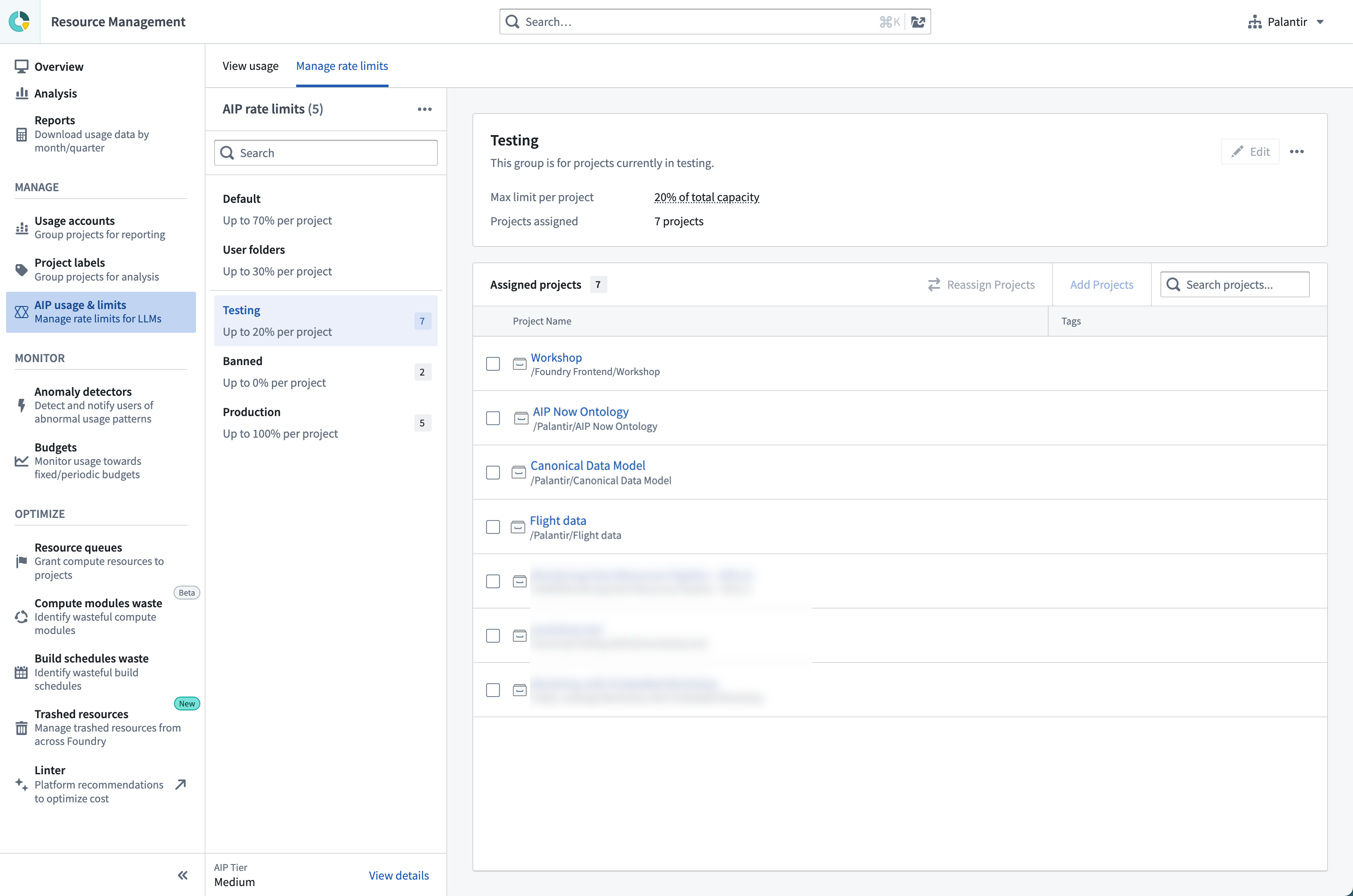
By default, all projects are given a specific limit at which to operate. An admin can create additional project limits, define which projects are included in each limit, and what percent of enrollment capacity can be used.
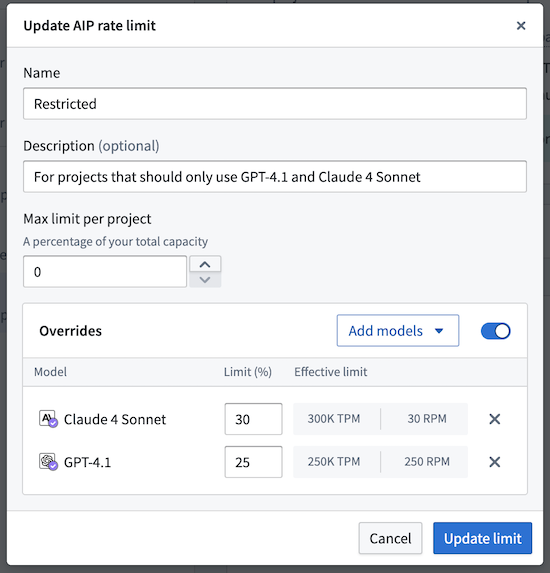
Model overrides
Within each project limit, you can configure model-specific overrides to further control capacity allocation at the model level. Model overrides allow you to set different percentage limits for individual models, overriding the base project limit. These overrides only apply to the projects included in that specific project limit (or for the default limit, all projects not assigned to any other manually created project limit).
Model overrides enable more granular capacity management and allow you to create model "allowlists"; you can set the base project limit to 0%, and then add model overrides with specific percentages for approved models only. You can also explicitly disallow certain models by setting their override limit percentage to 0%.
For example, the steps below explain how to restrict projects in a project limit to only use Claude Sonnet 4 and GPT-4.1:
- Set the base project limit to 0%.
- Add a model override for Claude Sonnet 4 at 30%.
- Add a model override for GPT-4.1 at 25%.
Users in all projects included in this project limit will only be able to access the specified models within their allocated capacity limits.
User rate limits
Per-user rate limits govern the capacity available to a single user for user-attributed requests. They ensure that no single user can exhaust the enrollment's entire capacity for a model through interactive workflows.
User rate limits are managed on the Manage rate limits tab, under the AIP usage & limits page in Resource Management. Enrollment administrators can view default per-user limits, create user-group overrides, and configure per-model overrides.
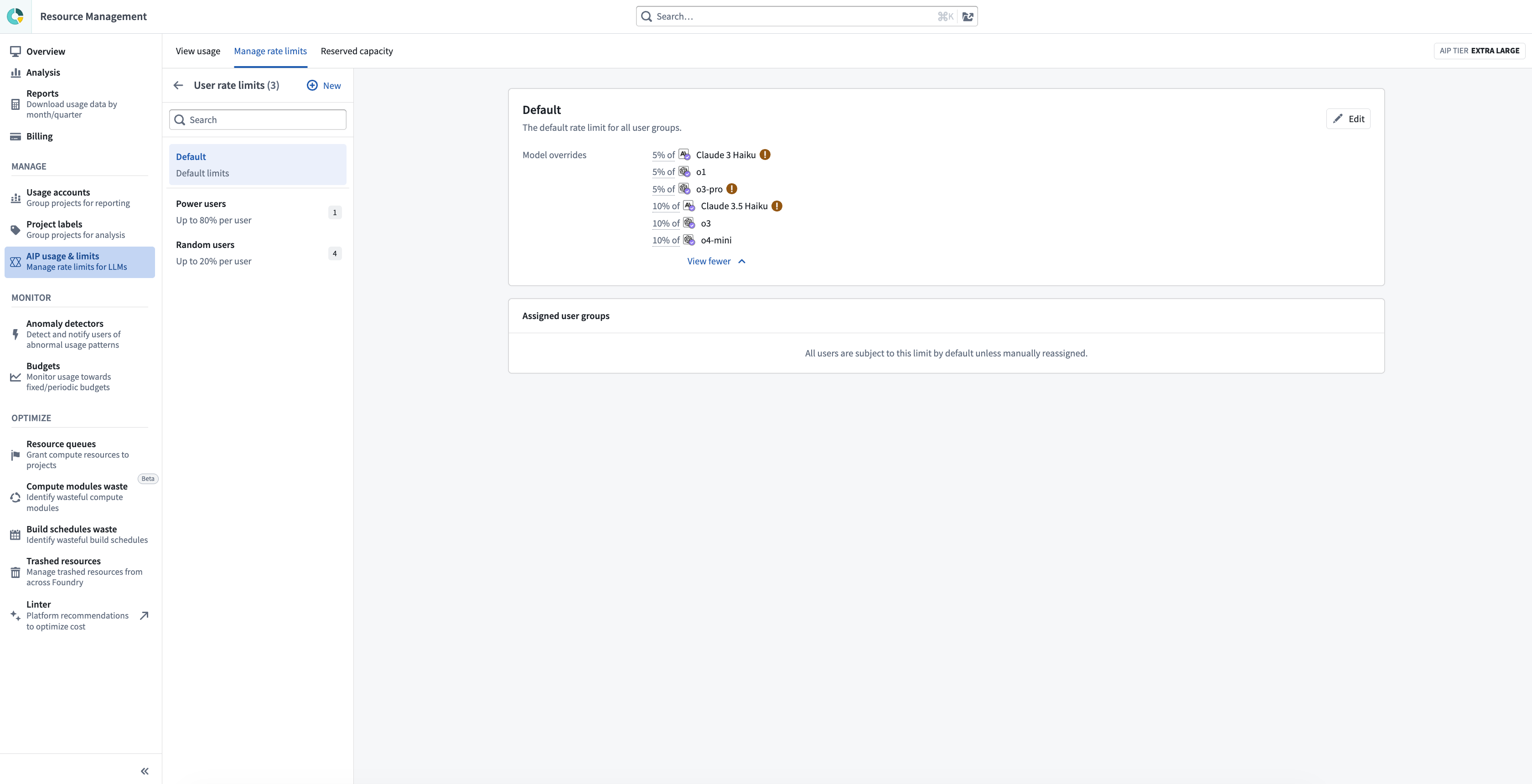
Default per-user limits
The default per-user limit for each model is shown in the User rate limits tab in Resource Management, or in the Per-user Limits column of the enrollment rate limit table. These defaults are set by Palantir and apply to all users unless overridden by an administrator in the User rate limits tab. The default per-user limit for each model is shown in the user rate limits tab in Resource Management, or in the Per-user Limits column of the enrollment rate limit table. These defaults are set by Palantir and apply to all users unless overridden by an administrator in the user rate limits tab.
We recommend using the Palantir default user rate limits. We defined them to balance (a) protecting the enrollment limits from being saturated by a single user; and (b) enabling users to maximize their productivity working on the latest AIP tools in Foundry effectively. If an administrator chooses to set a new custom limit for all models, they should revisit it as new models are released to make sure they are not limiting their users unintentionally.
Per-user overrides
Enrollment administrators can override the per-user defaults to grant specific users (as part of specific groups of users) a different per-user limit. This is useful for power users, service accounts behind interactive applications, or teams whose user-attributed workflows require sustained high throughput, without raising the enrollment's overall capacity tier. It is also a tool to protect the capacity of a certain model used in a production workflow, from accidentally getting saturated by users.
A per-user override can be expressed in one of two ways:
- Percentage of enrollment limit: A value between 1 and 100 representing the percentage of the enrollment-level rate limit. For example, if an enrollment has 4 million TPM for a model and an administrator configures a 25% override, any user covered by that override gets an effective limit of 1 million TPM.
- Absolute TPM and RPM values: Explicit tokens-per-minute and requests-per-minute values. This gives administrators precise control when a percentage-based approach does not match the desired limit.
When an override is configured, it replaces the published per-user default; it is not blended with or floored by the default.
Setting per-user limits below 50,000 TPM or 10 RPM for a model may break some AIP features for affected users. The override form displays a warning when a configured limit falls below these recommended minimums.
Levels of override
Per-user overrides can be configured at three levels, applied in order of specificity:
- Default per-user override: A single percentage that applies to every user in the enrollment, across all models. This becomes the new baseline replacing Palantir's published per-model defaults.
- Per-model override: A different percentage or absolute limit for one or more specific models, on top of the default. Per-model overrides allow administrators to raise or lower per-user limits for individual models without changing them across the catalog.
- User-group override: An override targeted at one or more Foundry user groups. A user-group override defines its own default percentage and, optionally, its own per-model overrides (percentage or absolute). When a user belongs to a group covered by an override, the group's configuration is used instead of the enrollment-wide per-user defaults.
If no override is configured at any level, the published per-user default for the model is used.
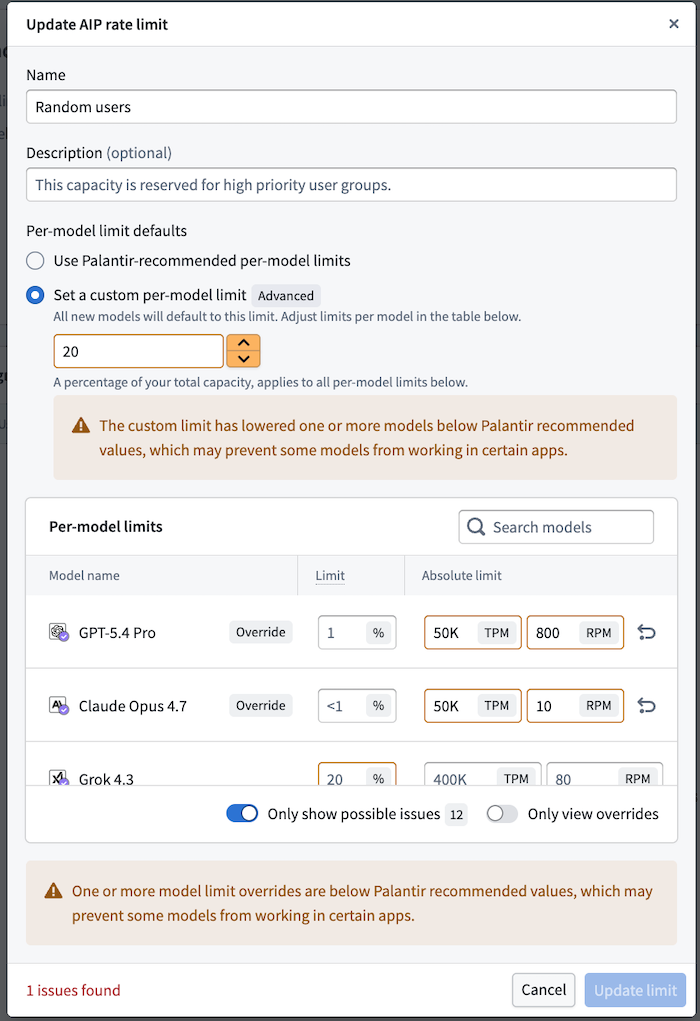
How user-group overrides resolve
A user-group override applies to a named set of Foundry user groups. Each override has a name, an optional description, an optional default percentage, and an optional set of per-model limits. A user is matched against an override when they belong to any group listed in that override.
If a user belongs to groups covered by multiple overrides, the highest resulting limit among those overrides wins for that user and model. This makes overrides additive and predictable: granting a user a higher limit through one group will not be silently undone by their membership in another group with a lower configuration. For example, take an enrollment where the default user limit is 40%. User A is on two groups under two different user limits overrides, one where user limits are defined to 10%, and the other defined to 35% of the enrollment capacity. User A will have user limits of 35%, the highest among the overrides.
When a user-group override is removed, members of the affected groups fall back to the enrollment-wide per-user configuration. If the enrollment has no per-user configuration of its own, they fall back to the published per-user defaults.
AIP reserved capacity
Reserved capacity is an AIP LLM capacity management tool in Resource Management. Reserved capacity can secure tokens per minute (TPM) and requests per minute (RPM) for production workflows in addition to existing enrollment capacity. This aims to secure critical production workflows that should not be limited by project rate limits, enrollment limits, and other resources that compete over the same pool of tokens and RPM.
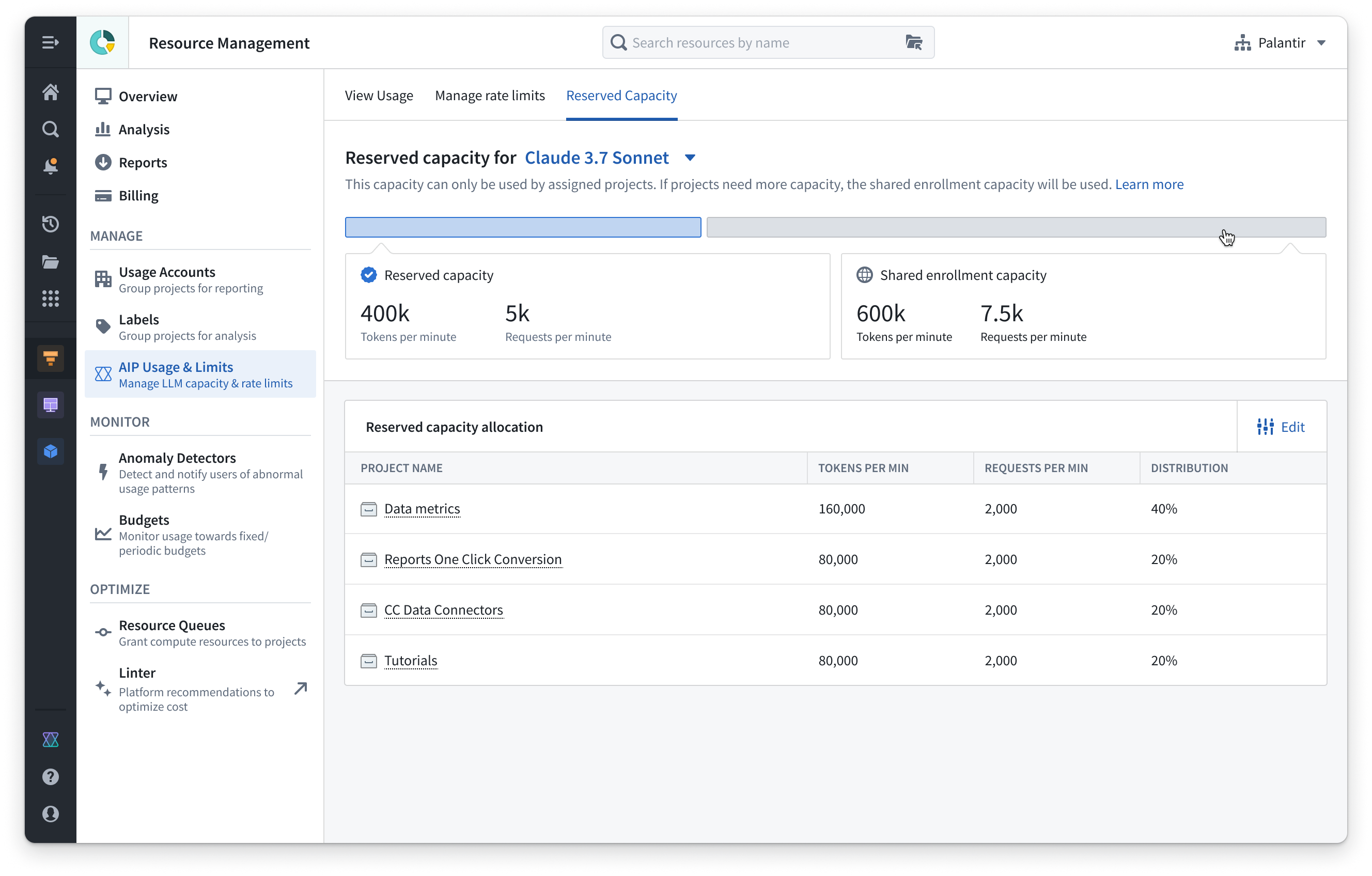
Key features
- Reserved capacity is configured at the project level by allocating a specific amount of TPM and RPM to a designated project. This applies to a single model.
- Projects can be assigned a percentage of the total reserved capacity, allowing you to prioritize the most critical resources and customize LLM allocation to align with your organizational requirements.
- When reserved capacity is expended, projects and resources with allocated reserved capacity will automatically use existing shared project and enrollments limits, since reserved capacity is provided in addition to the existing enrollment capacity.
Availability and costs
We cannot guarantee the availability of reserved capacity for all models at all times. This depends on the availability and offerings of model providers such as Azure, AWS, GCP, xAI, and others. We aim to offer reserved capacity on all industry-leading flagship models.
Reserved capacity has been sufficient for 99.9% uptime based on the performance of AIP in the past year. We cannot guarantee 100% capacity availability, but based on usage patterns in the past year, over 99% of LLM request failures were due to enrollment and project rate limits. These issues can be addressed and solved with the reserved capacity tool.
There is no extra cost for reserved capacity as a service; added costs will depend on additional token usage, as with all other LLM usage in AIP. This is subject to change in the future for new use cases or specific models. If this policy changes, we will not retroactively charge existing workflows for using reserved capacity; these workflows will continue to only incur charges based on additional token usage.
Palantir provides default reserved capacity on the latest LLMs in standard environments. Users with resource management administrator permissions can distribute this reserved capacity across specific projects.
Example usage
Consider the following example to further understand reserved capacity usage:
- Your enrollment has a capacity of 1 million TPM. If you have a project that contains a production application, the default limit for this application is 70% of the enrollment capacity, or 700 thousand TPM.
- To increase the capacity of this production application, you can increase the containing project's capacity to 100% of the enrollment capacity, or 1 million TPM, by increasing project rate limits.
- Although the application's limit is now 100% of the enrollment limit, this application is still competing for this shared capacity with other resources. You can identify competing resources in the View usage tab in the AIP usage & limits section of the Resource Management application. You can then alternate the schedules of competing resources, or migrate resources onto different models.
- To ensure that this production application will have the capacity it needs, even after maximizing efficiency in other ways, you can use default reserved capacity. In this case, suppose that the default reserved capacity provided is 500 thousand TPM for a specific model.
- You can allocate that reserved capacity to critical resources, such as your production application. This application will use the 500 thousand TPM until this additional capacity is expended. It will then tap into the shared enrollment capacity of 1 million TPM, where it will compete with other resources. This allows for a total capacity of 1.5 million TPM, where 500 thousand TPM are used exclusively by this application, and the enrollment's 1 million TPM capacity is shared across resources.
Visibility into LLM cost on AIP enrollments
Use the Analysis page to view the cost of LLM usage on your AIP-enabled enrollment.
From the Analysis page, select Filter by source: All LLMs and Group by source. This will generate a chart of daily LLM cost, segmented by model.
Prioritizing interactive queries
Generally, AIP prioritizes interactive requests over pipelines with batch requests. Interactive queries are defined as any real-time interaction that a user has with an LLM, such as Workshop, Chatbot Studio, preview in the AIP Logic LLM board, and preview in the Pipeline Builder LLM node. Batch queries are defined as a large set of requests sent without a user expecting an immediate response, for example Transforms pipelines, Pipeline Builder, Automate (for Logic).
This principle currently guarantees that 20% of capacity at the enrollment and project level will always be reserved for interactive queries. This means that for a 100,000 TPM capacity for a certain model, only a maximum of 80,000 TPM can be used for pipelines at any given minute, while at least 20,000 TPM (and up to 100,000 TPM) is available for interactive queries.
FAQ
What is an example of how project-level and user-level rate limits are expected to be used?
Consider the following example:
- An enrollment only has a single AIP use case in production, so the project containing that use case is moved under a "Production" limit to access up to 100% of the enrollment limit.
- In addition to this production use case, there is a second use case in the testing stage to consider. This testing stage use case should be able to run tests without taking over the entire production usage. This use case can be added to a "Testing" limit with up to 30% of capacity. The "Production" limit is reduced to 90% to make sure there is always some capacity for testing.
- On top of the previously-mentioned use cases, we add a second use case in production. However, unlike the first one that used GPT-5, this one uses Claude Sonnet 4.6. We can safely add this new use case to the "Production" limit next to the first production use case.
- The same enrollment wants a set of users to be able to experiment with LLMs. The enrollment administrator adds two projects to an "Experimentation" limit with up to 20% capacity.
- The testing project and the two experimental projects could technically expend up to 70% of capacity combined, but historical data shows that actual usage typically falls below this.
- Lastly, this enrollment wants to protect its production use cases from being taken over by single users. Administrators set overrides to the default user rate limits on GPT-5 and Claude Sonnet 4.6 to be 10% of the enrollment capacity, while increasing capacity on Claude Opus 4.6 and GPT-5.4. In addition, they set user home folders capacity to 0% (to discourage building in private folders and encourage collaboration), and grant these specified users LLM builder permissions in the Control Panel AIP settings.
Why is the percent enforced on each project in a limit category rather than shared across projects and users?
- The reason multiple projects and resources can share the same 100% capacity is that based on historical LLM usage patterns across hundreds of customers over the span of more than a year, most projects and resources do not make calls to LLMs. As such, multiple resources can share the same 100% capacity.
- If all projects within a limit category were to share the same usage percentage, a hard limit on usage would be implemented. However, based on existing usage, this is not justified for 99.9% of cases. It is very rare that multiple resources use the maximum capacity at the same minute, and even when this happens, requests will retry until successful.
Why are there AIP usage limits?
-
First, there is significant variance in the offering of different providers in terms of TPM, RPM, and regional availability. While AIP does leverage the capacity of all providers, Palantir cannot bypass limitations imposed by the various cloud service providers.
-
On top of that, LLM capacity provided to a customer by Palantir has a high bar of compliance requirements compared to the common offering from most providers. Palantir guarantees zero data retention (ZDR) and control over routing of data to specific regions (geo-restriction).
-
Most providers, namely Azure OpenAI, AWS Bedrock, GCP Vertex and Palantir-hosted models, all support geo-restrictions but also have smaller LLM capacity guarantees for geo-restricted requests. Other providers, such as OpenAI direct, Anthropic direct and xAI, offer their models in fewer regions.
- The more model providers a customer enables in Control Panel under AIP Settings, the higher the capacity they are granted.
- We offer an upgrade to a larger tier with more capacity for customers with higher usage levels.
- AIP customers with no geo-restriction can use a larger pool of capacity.
- Certain models are still not widely available in certain regions. Sometimes Palantir has early access to them, but it is not always possible.
- Certain capabilities are still unavailable, such as batch API. Batch API supports processing billions of tokens within 24 hours, but requires storing data for that period, which fails Palantir's compliance requirements.
-
As mentioned above, our medium to XL tiers are enough for large scale production workflows. Contact Palantir Support to change your tier.
What are the biggest obstacles to solving the capacity problem?
- Geo-restriction is the strongest cause of capacity issues. If your enrollment is geo-restricted, and you are able to remove geo-restrictions from a legal perspective, you should work with your Palantir team to do so.
- New models often have limited capacity in early stages.
- The capacity problem is much harder with large pipelines that run over many millions of items.